この記事では、Redis の関連知識を紹介し、Redis レベルをより高いレベルに引き上げるために、マスター/スレーブ レプリケーション、Sentinel、およびクラスタリングについて説明します。
1. マスター/スレーブ レプリケーション
1. はじめに
マスター/スレーブ レプリケーションは、Redis ディストリビューションと高可用性の基礎です。 Redis Assure の。 Redisでは、複製されるサーバーをマスターサーバー(Master)と呼び、マスターサーバーを複製するサーバーをスレーブサーバー(Slave)と呼びます。 [関連する推奨事項: Redis ビデオ チュートリアル ]
マスター/スレーブ レプリケーションの構成は非常にシンプルで、3 つの方法があります (IP マスターを含む)サーバーの IP アドレス/ポート - メイン サーバー Redis サービス ポート):
構成ファイル - redis.conf ファイル、slaveof ip port
コマンド- Redis クライアントは、slaveof ip port
スタートアップ パラメータを実行します——./redis-server --slaveof ip port
2 を入力します。Master-スレーブ レプリケーションの進化
Redis のマスター/スレーブ レプリケーション メカニズムは、当初は 6.x バージョンほど完璧ではありませんでしたが、バージョンごとに反復されました。通常、次の 3 つのバージョンの反復を経ています:
#Before 2.8
##2.8~4.0
4.0
バージョンが成長するにつれて、Redis のマスター/スレーブ レプリケーション メカニズムは徐々に改善されますが、その本質は同期 (sync) とコマンド伝播 (コマンド伝播) の 2 つの操作を中心に展開します。 :
同期 (sync): スレーブ サーバーのデータ ステータスをメイン サーバーの現在のデータ ステータスに更新することを指します。これは主に初期化またはその後の完全同期中に発生します。
コマンド伝播: マスターサーバーのデータステータスが変更(書き込み/削除など)され、マスターとスレーブ間のデータステータスが不一致になると、マスターサービスが変更されます。コマンドはスレーブ サーバーに伝播され、マスター サーバーとスレーブ サーバー間のステータスが一貫した状態に戻ります。
2.1 バージョン 2.8 より前
2.1.1 同期
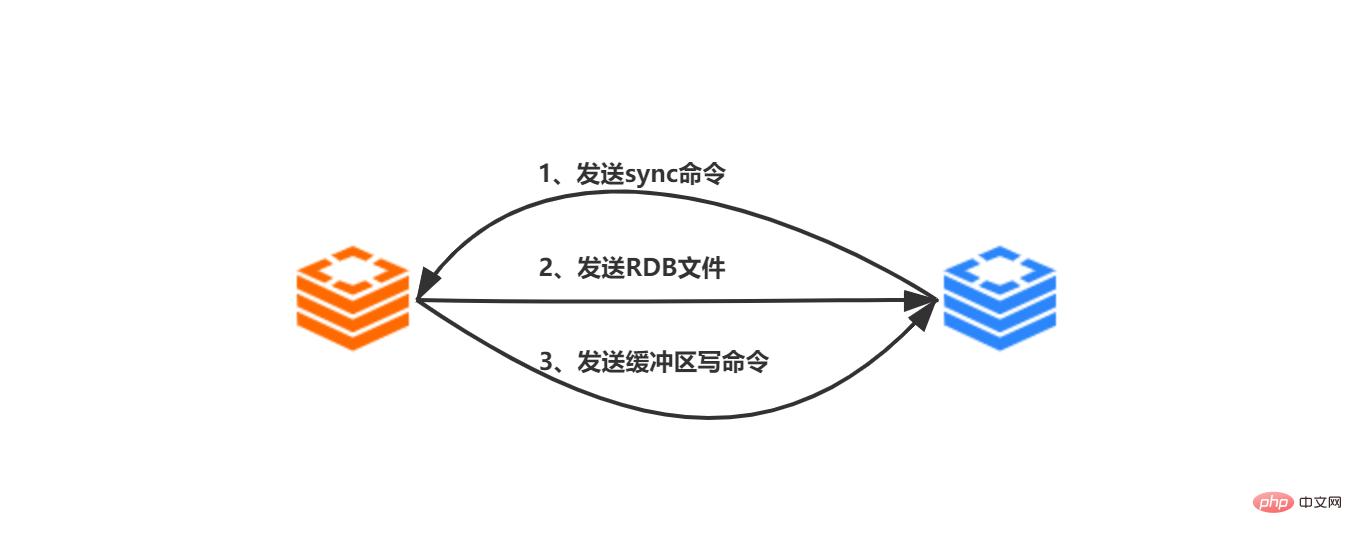
バージョン 2.8 より前のバージョンでは、スレーブ サーバーからマスター サーバーへの同期にはスレーブ サーバーが必要です。マスター サーバーへの同期コマンドが発生して完了します:
スレーブ サーバーは、クライアントから送信された smileof ip prot コマンドを受信し、スレーブ サーバーはip:port に基づいてマスター サーバーにそれを作成します。 ソケット接続
ソケットがメイン サーバーに正常に接続された後、スレーブ サーバーは、レプリケーションの処理に特に使用されるファイル イベント ハンドラーを関連付けます。マスター サーバー
によって送信された後続の RDB ファイルと伝播されたコマンドのコピーが開始され、スレーブ サーバーはマスター サーバー ## に同期コマンドを送信します。
#マスター サーバー sync コマンドを受信した後、bgsave コマンドを実行します。メイン サーバーのメイン プロセス フォークのサブプロセスは、RDB ファイルを生成し、RDB スナップショットが生成された後のすべての書き込み操作を記録します。
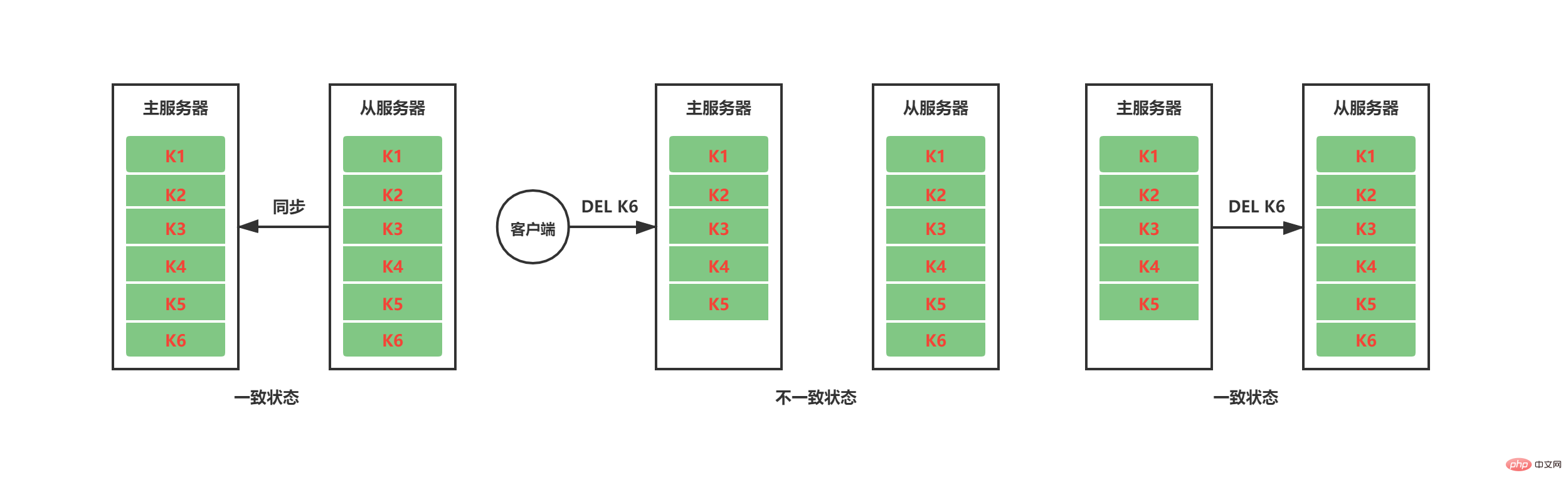
同期作業が完了すると、マスター/スレーブ レプリケーション コマンドの伝播を通じてデータの状態の一貫性を維持する必要があります。下図に示すように、現在のマスターサーバーとスレーブサーバー間の同期作業が完了した後、マスターサービスはクライアントからの DEL K6 命令を受信した後、K6 を削除しますが、この時点ではスレーブサーバーには K6 がまだ存在しており、マスターとスレーブのデータ状態が不一致です。マスターサーバーとスレーブサーバーの一貫したステータスを維持するために、マスターサーバーは自身のデータステータスを変更するコマンドをスレーブサーバーに伝播して実行します。スレーブサーバーも同じコマンドを実行すると、マスターサーバー間のデータステータスはスレーブサーバーに伝播されます。マスターサーバーとスレーブサーバーは一貫性を保ちます。
上記のことから、2.8 より前のバージョンのマスター/スレーブ レプリケーションに欠陥は見られませんが、これはネットワークの変動を考慮していないためです。分散を理解している兄弟なら CAP 理論を聞いたことがあるでしょう。CAP 理論は分散ストレージ システムの基礎です。CAP 理論では P (パーティション ネットワーク パーティション) が存在する必要があり、Redis のマスター/スレーブ レプリケーションも例外ではありません。マスターサーバーとスレーブサーバー間でネットワーク障害が発生し、スレーブサーバーとマスターサーバー間の通信が一定時間停止した場合 スレーブサーバーがマスターサーバーに再接続した際、マスターサーバーのデータステータスが低下した場合この間にマスタ/スレーブサーバ間でデータの状態に不整合が発生します。 Redis 2.8 より前のマスター/スレーブ レプリケーション バージョンでは、このデータ状態の不一致を解決する方法は、同期コマンドを再送信することです。同期によりマスター サーバーとスレーブ サーバーのデータ ステータスの一貫性が保証されますが、同期が非常にリソースを消費する操作であることは明らかです。
sync コマンドが実行されると、マスター サーバーとスレーブ サーバーに必要なリソース:
2.2 バージョン 2.8-4.0
2.2.1 改善点
以前のバージョンとの完全同期 ( sync) Consistent
サーバーからの切断と再接続後に増分同期を実現するために、Redis は 3 つの補助パラメータを追加します。
レプリケーション オフセット
##レプリケーション オフセットはマスター サーバーとスレーブ サーバーの両方で維持されます
#マスターサーバーはスレーブ サービスにデータを送信し、N バイトのデータを伝播します。マスター サービスのレプリケーション オフセットはスレーブ サーバーから N
だけ増加します。マスター サーバーによって送信されたデータを受信します。 、N バイトのデータを受信し、スレーブ サーバーのレプリケーション オフセットを N
通常の同期状況は次のとおりです。
A/B が正常に伝播し、C がサーバーから切断されたと仮定すると、次の状況が発生します。
しかし、マスター サーバーは、スレーブ サーバーにどのデータが欠けているかをどのようにして知るのでしょうか?
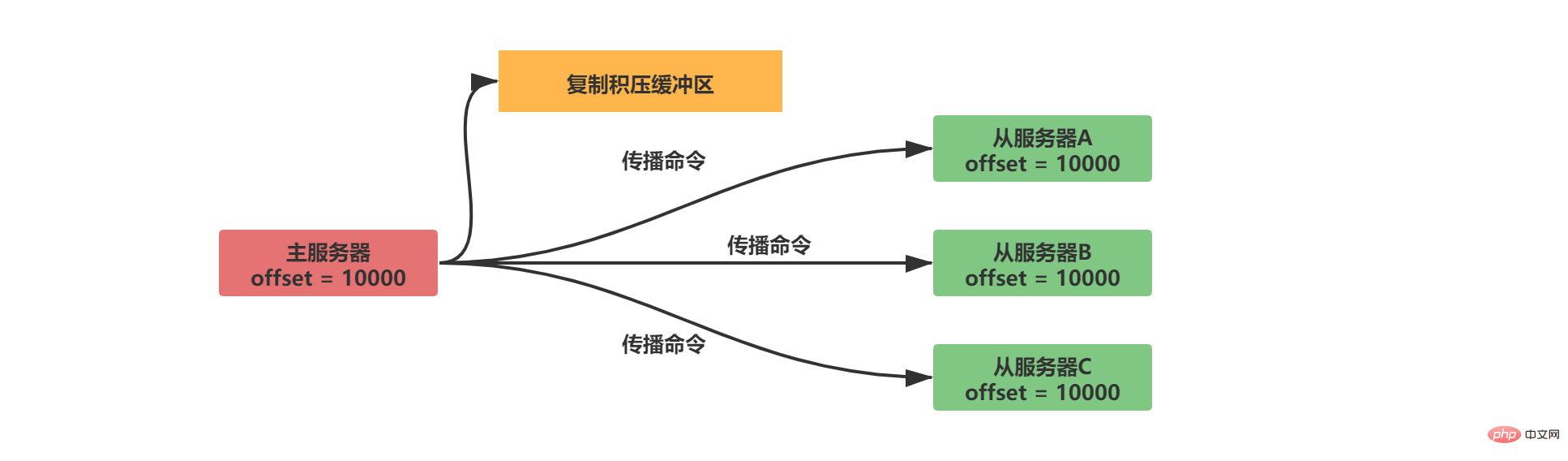
2.2.2.2 コピー バックログ バッファ
コピー バックログ バッファは、デフォルト サイズが 1MB の固定長キューです。マスター サーバーのデータ ステータスが変化すると、マスター サーバーはデータをスレーブ サーバーに同期し、コピーをレプリケーション バックログ バッファに保存します。
#オフセットを一致させるために、コピー バックログ バッファーはデータの内容を保存するだけでなく、各バイトに対応するオフセットも記録します。
オフセット 1 のデータがまだコピー バックログ バッファーにある場合は、増分同期操作を実行します。
それ以外の場合は、完全同期操作を実行します。同期との一貫性を保つ
Redis のデフォルトのコピー バックログ バッファ サイズは 1MB ですが、カスタマイズする必要がある場合はどのように設定すればよいですか? 当然のことながら、できる限り増分同期を使用したいと考えていますが、バッファーがあまりにも多くのメモリ領域を占有することは望ましくありません。次に、Redis スレーブ サービスが切断された後の再接続時間 T と、Redis マスター サーバーが 1 秒あたりに受信する書き込みコマンドのメモリ サイズ M を見積もることにより、レプリケーション バックログ バッファーのサイズ S を設定できます。
S = 2 * M * T
ここでの 2 倍の拡張は、ある程度の余地を残すためであることに注意してください。ほとんどのブレークの増分同期を回線の再接続に使用できるようにします。
2.2.2.3 ID
これを見た後、切断と再接続の増分同期はすでに実現できており、次の実行も必要だと思いますか? IDドライ さて?実はこれまで考慮されていなかった、マスターサーバーがダウンした場合にスレーブサーバーが新たなマスターサーバーとして選出される場合もあり、この場合は稼働中のIDを比較することで区別することができます。
#実行 ID (実行 ID) は、サーバーの起動時に自動的に生成される 40 個のランダムな 16 進文字列です。マスター サービスとスレーブ サーバーの両方が実行 ID を生成します
スレーブ サーバーがマスター サーバーのデータを初めて同期するとき、マスター サーバーはその実行 ID をスレーブ サーバーに送信し、スレーブ サーバーはそれを RDB ファイルに保存します
スレーブ サーバーが切断され、再接続されると、スレーブ サーバーは以前に保存したマスター サーバーの実行 ID をマスター サーバーに送信します。サーバーの実行 ID が一致する場合、マスター サーバーが変更されていないことが証明されます。増分同期を試すことができます
サーバー実行 ID が一致しない場合は、完全同期が実行されます
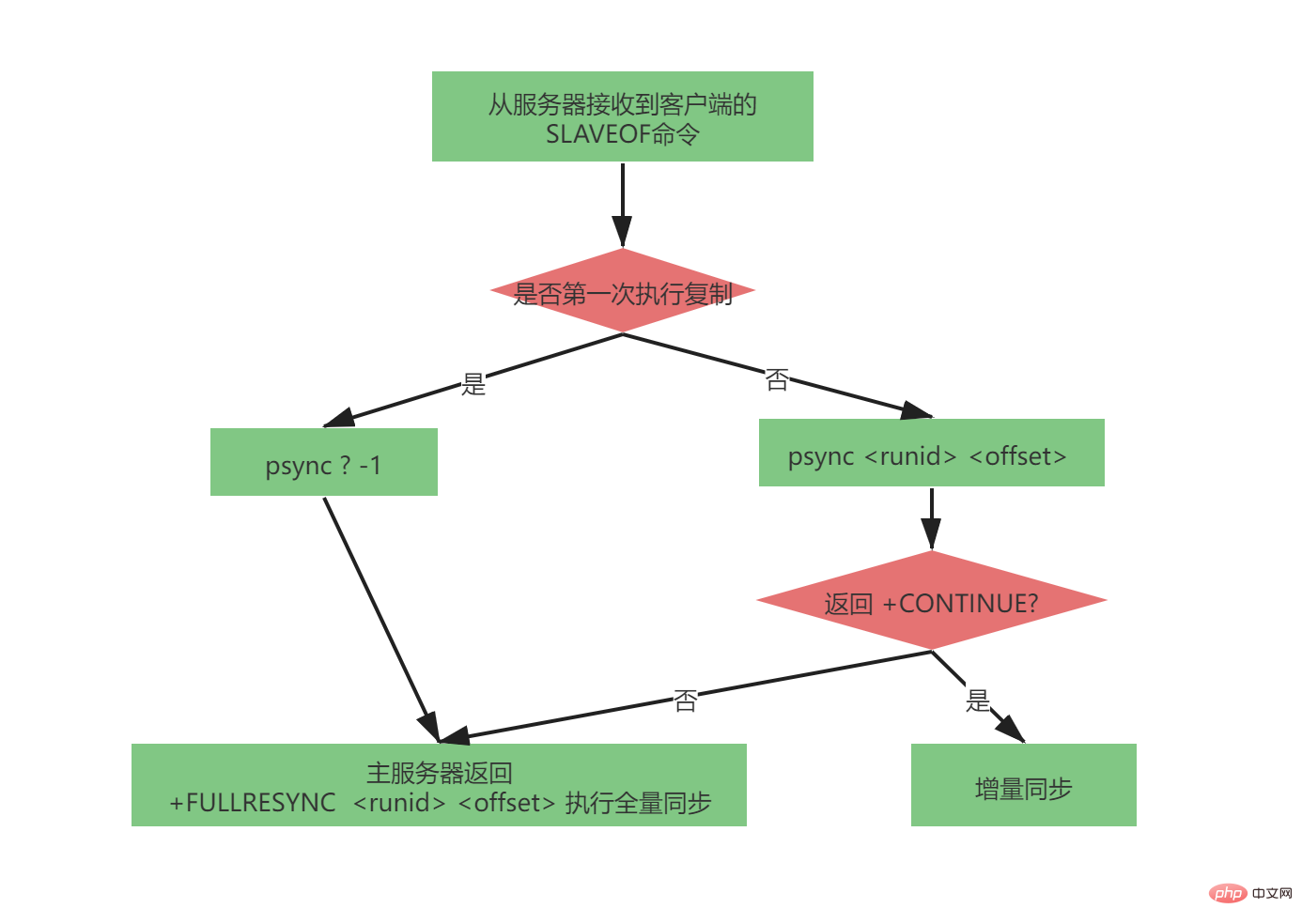
##2.2.3 完全な psync
完全な psync プロセスは非常に複雑ですが、マスター/スレーブ レプリケーション バージョン 2.8 ~ 4.0 では非常に完璧でした。 psync コマンドによって送信されるパラメータは次のとおりです。
psync
スレーブ サーバーがマスター サーバーを複製していない場合 (マスター サーバーが複製されていない場合)初めてマスター/スレーブがレプリケートされたとき、マスター サーバーは変更される可能性がありますが、スレーブ サーバーは初めて完全に同期されるため)、スレーブ サーバーは次のメッセージを送信します:
psync ? -1
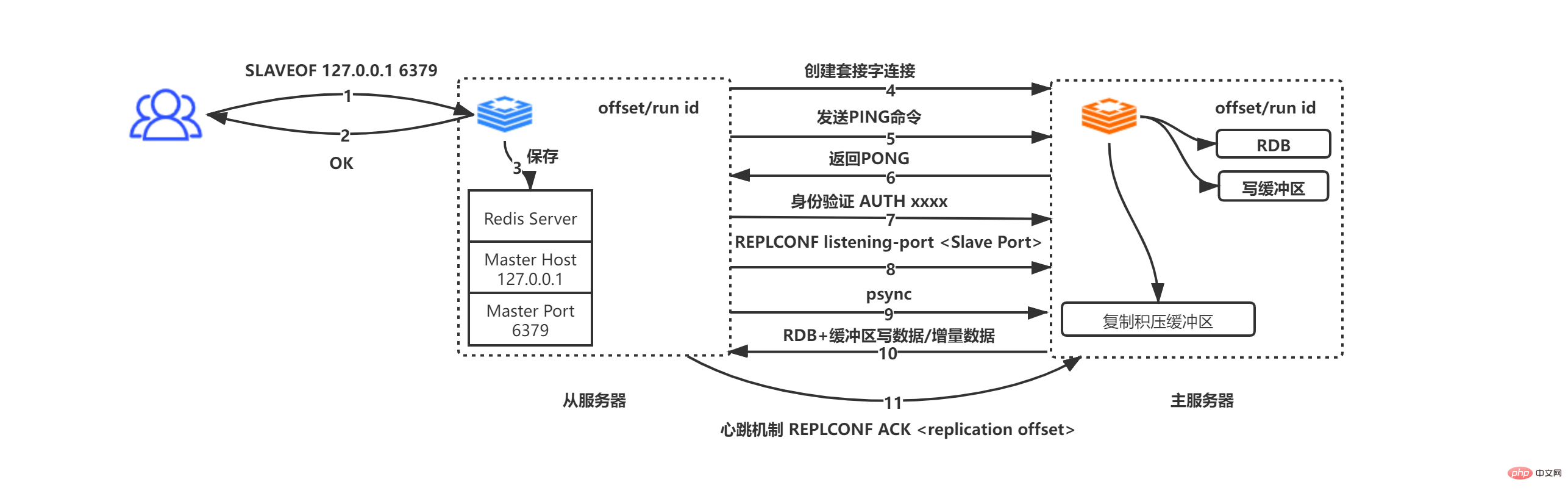
完全な psync プロセスは次のとおりです:
サーバーから受信 SLAVEOF 127.0.0.1 6379 コマンドに移動
#サーバーからコマンド開始側に OK を返します (これは非同期操作です。OK を返します)最初にアドレスとポート情報を保存します)
スレーブ サーバーは IP アドレスとポート情報をマスター ホストとマスター ポートに保存します
スレーブ サーバーは、マスター ホストとマスター ポートの接続に基づいてマスター サーバーへのソケットをアクティブに開始し、同時にスレーブ サービスは、ファイルのコピーに特に使用されるファイル イベント ハンドラーを後続の RDB 用のこのソケット接続に関連付けます。ファイルコピーやその他の作業
マスターサーバー スレーブサーバーからソケット接続リクエストを受信した後、そのリクエストに対応するソケット接続を作成し、スレーブサーバーをクライアントとして見ます(マスター/スレーブ レプリケーションでは、マスター サーバーとスレーブ サーバーは実際には互いのクライアントです。エンドとサーバー)
ソケット接続が確立され、スレーブ サーバーがアクティブに PING コマンドを送信します。指定されたタイムアウト期間内にメインサーバーが PONG を返した場合、ソケットは接続可能であることが証明され、それ以外の場合は切断して再接続します
マスターサーバーがパスワードを設定している場合(masterauth) の場合、スレーブ サーバーは認証のために AUTH masterauth コマンドをマスター サーバーに送信します。スレーブ サーバーがパスワードを送信してもマスター サービスがパスワードを設定していない場合、マスター サーバーはパスワードが設定されていないエラーを送信することに注意してください。マスター サーバーがパスワードを要求しているのにスレーブ サーバーがパスワードを送信しない場合、マスター サーバーはパスワードが設定されていないことを示すエラーを送信します。サーバーは NOAUTH エラーを送信し、パスワードが一致しない場合、マスター サーバーは無効なパスワード エラーを送信します。
スレーブ サーバーは、REPLCONF listen-port xxxx (xxxx はスレーブ サーバーのポートを表します) をマスター サーバーに送信します。コマンドを受信した後、マスター サーバーはデータを保存します。クライアントが INFO レプリケーションを使用してマスターとスレーブの情報を照会すると、データを返すことができます。
スレーブ サーバーは、 psync コマンド。この手順については上記を参照してください。図 2 の psync の状況
マスター サーバーとスレーブ サーバーは相互にクライアントであり、データの要求/応答を実行します
マスター サーバー サーバーとスレーブ サーバーの間でハートビート パケット メカニズムが使用され、接続が切断されているかどうかが判断されます。スレーブ サーバーは、REPLCONF ACL オフセット (スレーブ サーバーのレプリケーション オフセット) というコマンドを 1 秒ごとにマスター サーバーに送信します。このメカニズムにより、マスターとスレーブ間のデータの正しい同期が保証されます。オフセットが等しくない場合、マスター サーバーはサーバーは増分/完全同期手段を使用して、マスターとスレーブの間で一貫したデータ状態を確保します (増分/完全の選択は、オフセット 1 のデータがまだレプリケーション バックログ バッファーにあるかどうかによって決まります)
2.3 バージョン 4.0
Redis バージョン 2.8 ~ 4.0 にはまだ改善の余地がありますが、メイン サーバーを切り替えたときに増分同期を実行できますか?したがって、Redis 4.0 バージョンはこの問題に対処するために最適化され、psync は psync2.0 にアップグレードされました。 pync2.0 はサーバーの実行 ID を放棄し、代わりに replid と replid2 を使用しました。Replid には現在のメイン サーバーの実行 ID が保存され、replid2 には以前のメイン サーバーの実行 ID が保存されます。
メイン サーバーは replid と replid2 によって解決できます。切り替え時の増分同期の問題は次のとおりです。
2. Sentinel
1. はじめに
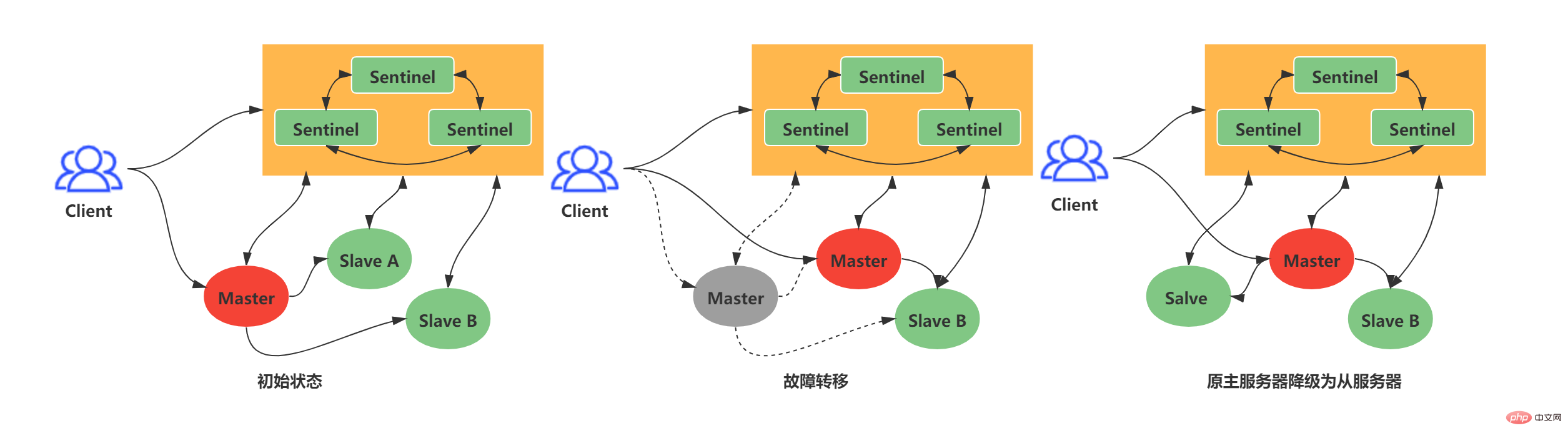
マスター/スレーブ レプリケーションは、 Redis ディストリビューション 基本ですが、通常のマスター/スレーブ レプリケーションでは高可用性を実現できません。通常のマスタ・スレーブ型レプリケーション方式では、マスタサーバがダウンした場合、運用保守担当者は手動でマスタサーバを切り替えることしかできず、当然ながらお勧めできません。上記の状況に対応して、Redis はノード障害に耐えられる高可用性ソリューションである Redis Sentinel を正式にリリースしました。 Redis Sentinel: 1 つ以上の Sentinel インスタンスで構成される Sentinel システム。任意の数のマスター サーバーとスレーブ サーバーを監視できます。監視対象のマスター サーバーがダウンすると、マスター サーバーは自動的にオフラインになり、スレーブ サーバーは新しいサーバーにアップグレードされますマスターサーバー。
次の例: 古いマスターのオフライン時間がユーザーによって設定されたオフライン時間の上限を超えると、Sentinel システムは古いマスター上でフェイルオーバー操作を実行します。フェイルオーバー操作には 3 つのステップが含まれます:
スレーブ内の最新データを新しいマスターとして選択します
新しいレプリケーション命令を他のスレーブに送信して、他のスレーブ サーバーを新しいマスターのスレーブにします
古いマスターの監視を継続し、オンラインになった場合は、古いマスターを新しいマスターのスレーブとして設定します
この記事は、次のリソース リストに基づいています:
IP アドレス
ノードの役割 #ポート 192.168.211.104
Redis スレーブ/センチネル ##6379/26379
Redis スレーブ/センチネル
6379/26379
2. Sentinel の初期化とネットワーク接続
Sentinel には特に魔法のような機能はありません。これはより単純な Redis サーバーです。Sentinel が起動すると、さまざまなコマンド テーブルと設定ファイルが読み込まれます。したがって、本質的に Sentinel は少ないコマンドといくつかの特別な機能を備えた Redis サービス。 Sentinel が起動したら、次の手順を実行する必要があります。
Sentinel サーバーを初期化する
#通常の Redis コードを Sentinel に置き換えます。特定のコード
Sentinel ステータスの初期化
ユーザーが指定した Sentinel 設定ファイルに基づいて、Sentinel によって監視されるメイン サーバー リストを初期化します
マスター サーバーへのネットワーク接続の作成
#マスター サービスに基づいてスレーブ サーバーの情報を取得し、スレーブ サーバーへのネットワーク接続を作成します
リリースによると /Subscribe して Sentinel 情報を取得し、Sentinel 間のネットワーク接続を作成します
2.1 Sentinel サーバーを初期化します
2.2 通常の Redis コードを Sentinel 固有のコードに置き換える
2.3 Sentinel 状態の初期化
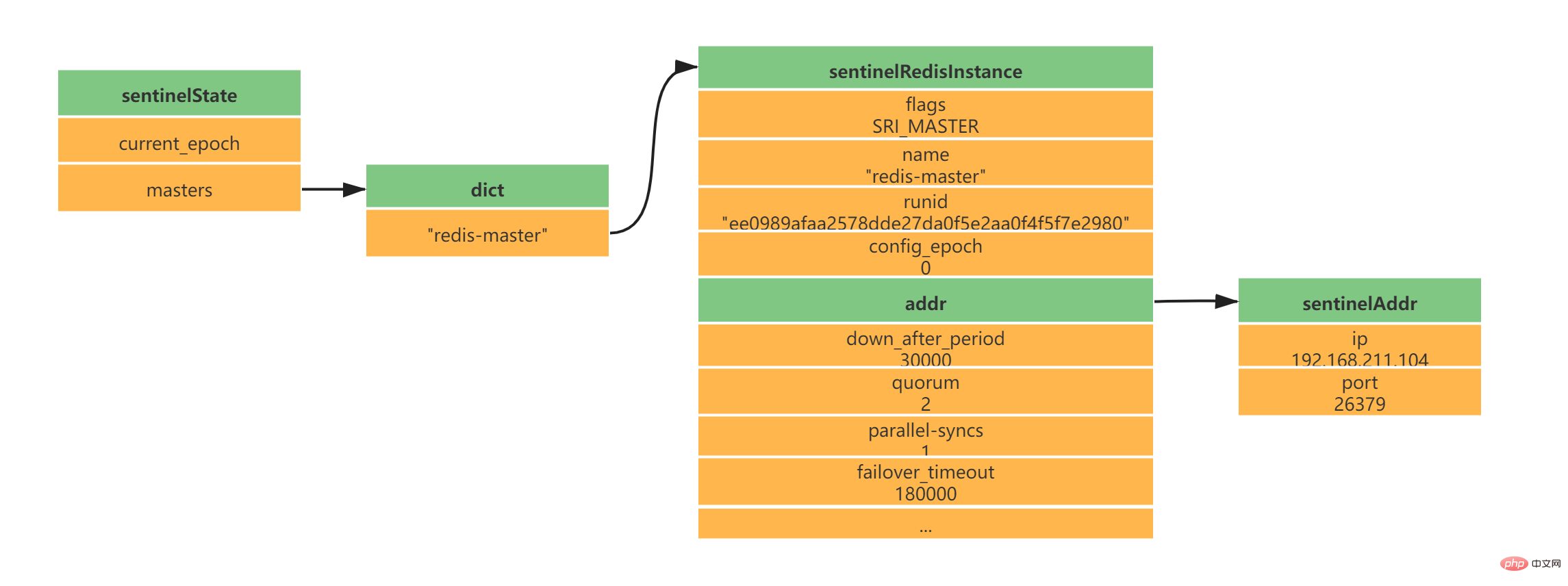
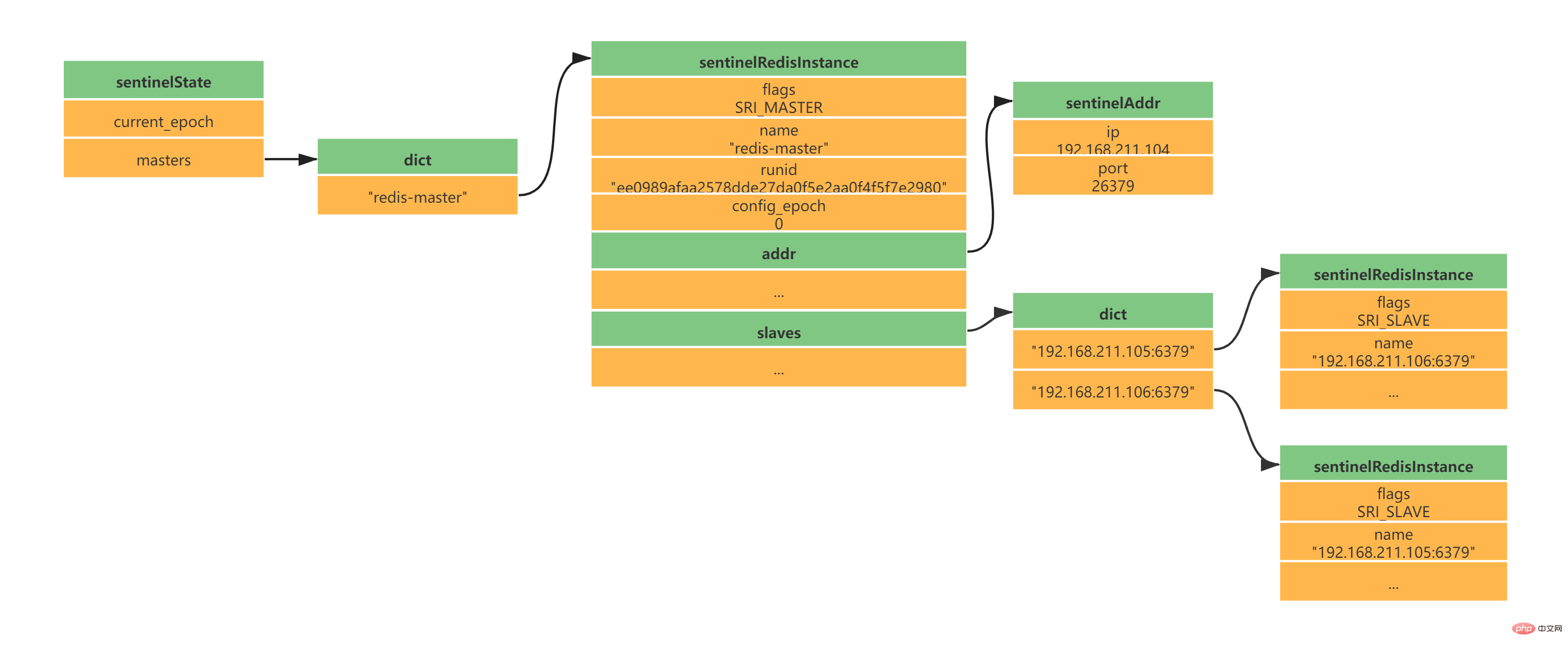
struct sentinelState {
//当前纪元,故障转移使用
uint64_t current_epoch;
// Sentinel监视的主服务器信息
// key -> 主服务器名称
// value -> 指向sentinelRedisInstance指针
dict *masters;
// ...
} sentinel; ログイン後にコピー
masters のキーはメイン サービスの名前です
masters の値は SentinelRedisInstance へのポインタです
daemonize yes
port 26379
protected-mode no
dir "/usr/local/soft/redis-6.2.4/sentinel-tmp"
sentinel monitor redis-master 192.168.211.104 6379 2
sentinel down-after-milliseconds redis-master 30000
sentinel failover-timeout redis-master 180000
sentinel parallel-syncs redis-master 1 ログイン後にコピー
typedef struct sentinelRedisInstance {
// 标识值,标识当前实例的类型和状态。如SRI_MASTER、SRI_SLVAE、SRI_SENTINEL
int flags;
// 实例名称 主服务器为用户配置实例名称、从服务器和Sentinel为ip:port
char *name;
// 服务器运行ID
char *runid;
//配置纪元,故障转移使用
uint64_t config_epoch;
// 实例地址
sentinelAddr *addr;
// 实例判断为主观下线的时长 sentinel down-after-milliseconds redis-master 30000
mstime_t down_after_period;
// 实例判断为客观下线所需支持的投票数 sentinel monitor redis-master 192.168.211.104 6379 2
int quorum;
// 执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量 sentinel parallel-syncs redis-master 1
int parallel-syncs;
// 刷新故障迁移状态的最大时限 sentinel failover-timeout redis-master 180000
mstime_t failover_timeout;
// ...
} sentinelRedisInstance; ログイン後にコピー
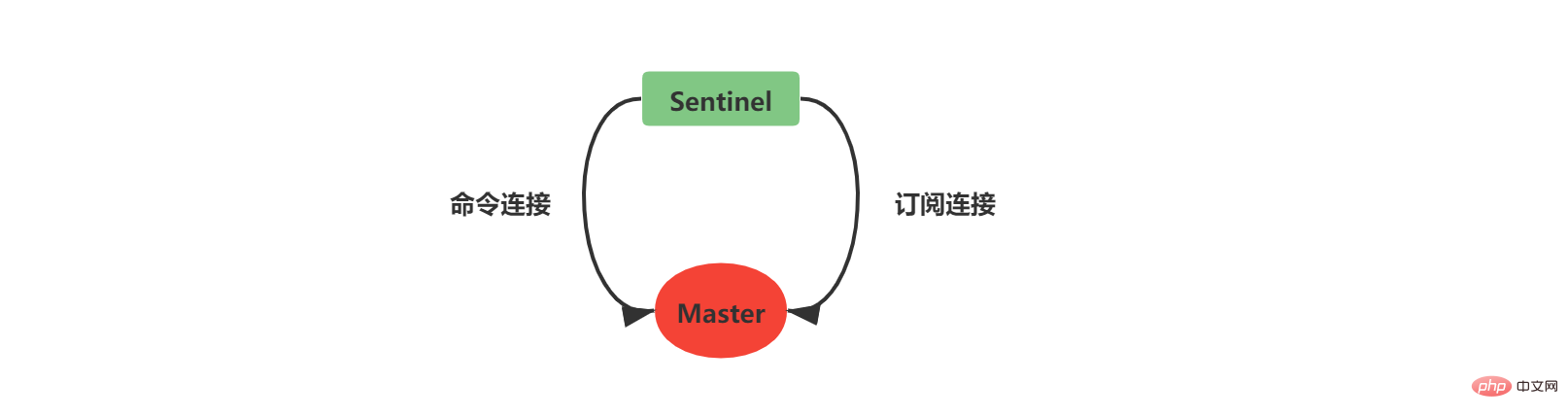
2.5 メインへのネットワーク接続を作成します。 server
コマンド接続はマスターとスレーブの情報を取得するために使用されます
サブスクリプション接続が使用されます Sentinel 間のブロードキャスト情報。各 Sentinel とそれが監視するマスター/スレーブ サーバーは、_sentinel_:hello チャネルにサブスクライブします (Sentinel 間にサブスクリプション接続は作成されないことに注意してください。Sentinel は、_sentinel_:hello チャネルにサブスクライブすることで他の Sentinel を取得します。初期情報)
#マスター自身の情報##2.6 スレーブ サーバーへのネットワーク接続の作成
当Sentinel和Slave之间创建网络连接之后,Sentinel成为了Slave的客户端,Sentinel也会每隔10秒钟通过INFO指令请求Slave获取服务器信息。 到这一步Sentinel获取到了Master和Slave的相关服务器数据。这其中比较重要的信息如下:
此时实例结构信息如下所示:
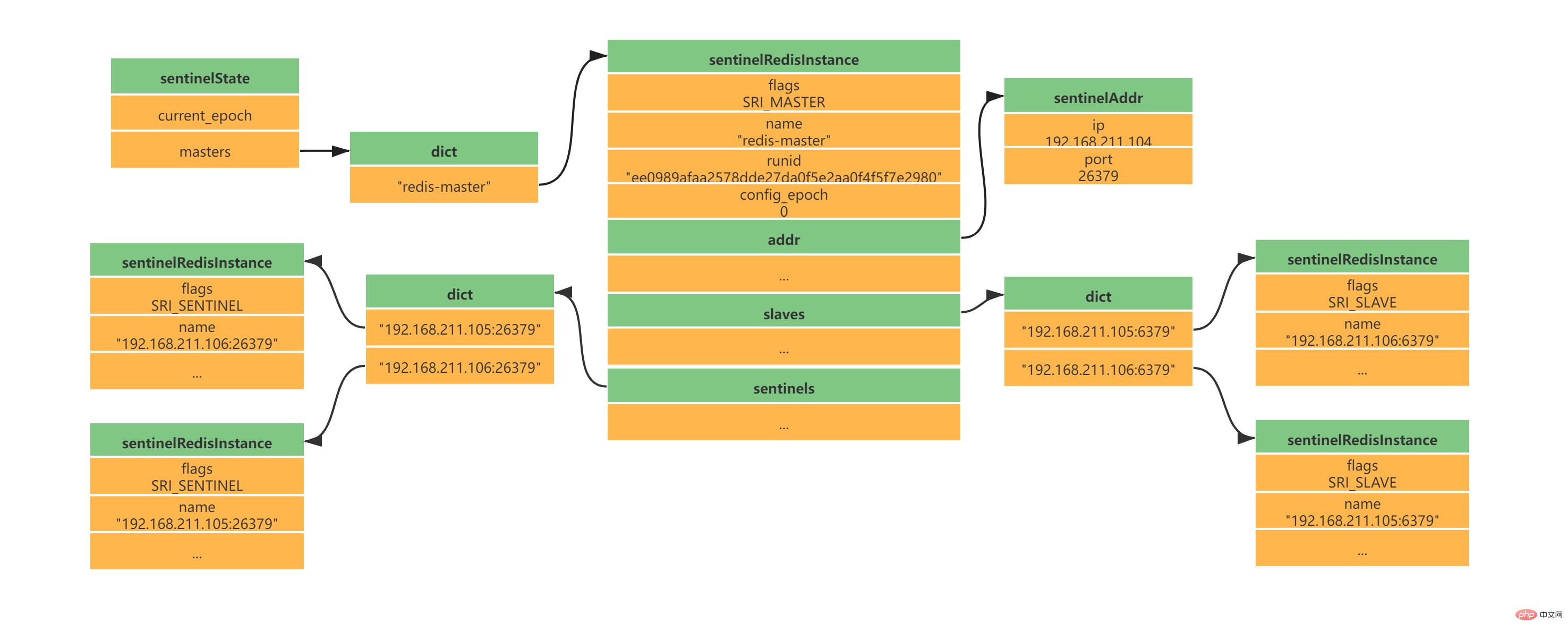
2.7 创建Sentinel之间的网络连接 此时是不是还有疑问,Sentinel之间是怎么互相发现对方并且相互通信的,这个就和上面Sentinel与自己监视的主从之间订阅_sentinel_:hello频道有关了。 Sentinel会与自己监视的所有Master和Slave之间订阅_sentinel_:hello频道,并且Sentinel每隔2秒钟向_sentinel_:hello频道发送一条消息,消息内容如下:
PUBLISH sentinel :hello ",,,,,,,"
其中s代码Sentinel,m代表Master;ip表示IP地址,port表示端口、runid表示运行id、epoch表示配置纪元。
多个Sentinel在配置文件中会配置相同的主服务器ip和端口信息,因此多个Sentinel均会订阅_sentinel_:hello频道,通过频道接收到的信息就可获取到其他Sentinel的ip和port,其中有如下两点需要注意:
Sentinel之间不会创建订阅连接,它们只会创建命令连接:
此时实例结构信息如下所示:
3、Sentinel工作 Sentinel最主要的工作就是监视Redis服务器,当Master实例超出预设的时限后切换新的Master实例。这其中有很多细节工作,大致分为检测Master是否主观下线、检测Master是否客观下线、选举领头Sentinel、故障转移四个步骤。
3.1 检测Master是否主观下线 Sentinel每隔1秒钟,向sentinelRedisInstance实例中的所有Master、Slave、Sentinel发送PING命令,通过其他服务器的回复来判断其是否仍然在线。
sentinel down-after-milliseconds redis-master 30000 ログイン後にコピー
在Sentinel的配置文件中,当Sentinel PING的实例在连续down-after-milliseconds配置的时间内返回无效命令,则当前Sentinel认为其主观下线。Sentinel的配置文件中配置的down-after-milliseconds将会对其sentinelRedisInstance实例中的所有Master、Slave、Sentinel都适应。
无效指令指的是+PONG、-LOADING、-MASTERDOWN之外的其他指令,包括无响应
如果当前Sentinel检测到Master处于主观下线状态,那么它将会修改其sentinelRedisInstance的flags为SRI_S_DOWN
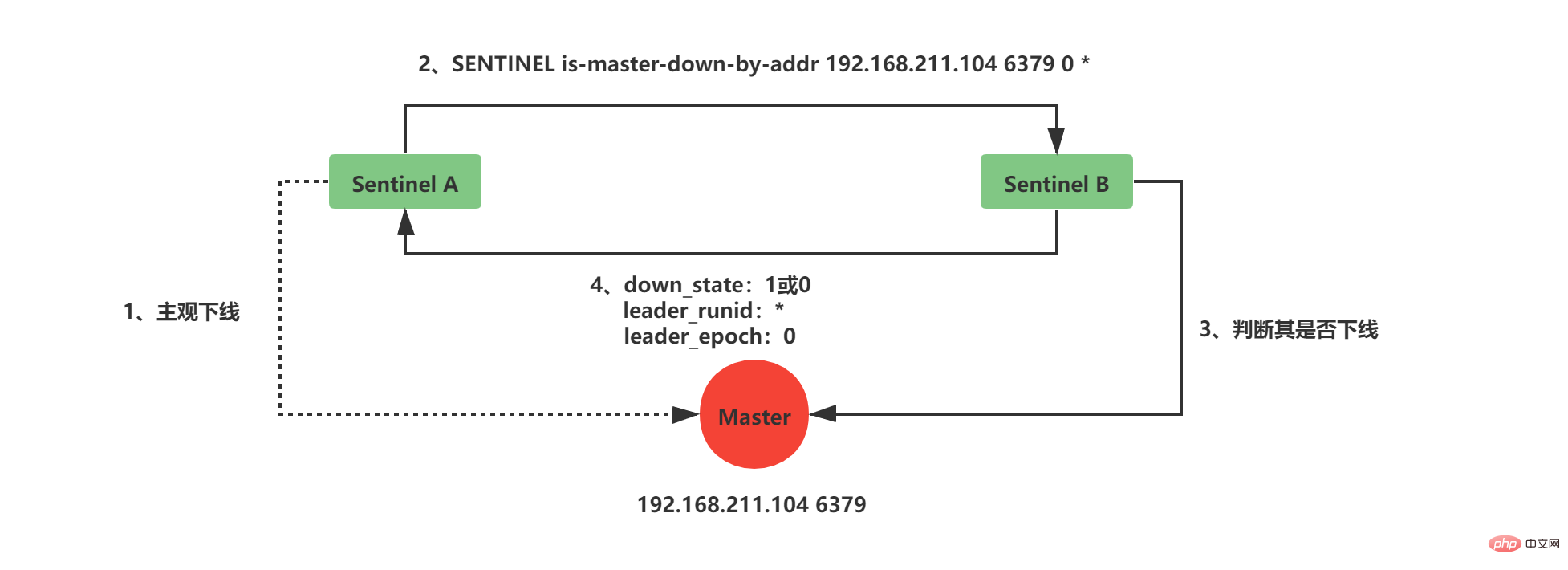
3.2 检测Master是否客观下线 当前Sentinel认为其下线只能处于主观下线状态,要想判断当前Master是否客观下线,还需要询问其他Sentinel,并且所有认为Master主观下线或者客观下线的总和需要达到quorum配置的值,当前Sentinel才会将Master标志为客观下线。
当前Sentinel向sentinelRedisInstance实例中的其他Sentinel发送如下命令:
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid> ログイン後にコピー
ログイン後にコピー
current_epoch和runid均用于Sentinel的选举,Master下线之后,需要选举一个领头Sentinel来选举一个新的Master,current_epoch和runid在其中发挥着重要作用,这个后续讲解。
接收到命令的Sentinel,会根据命令中的参数检查主服务器是否下线,检查完成后会返回如下三个参数:
down_state:检查结果1代表已下线、0代表未下线
leader_runid:返回*代表判断是否下线,返回runid代表选举领头Sentinel
leader_epoch:当leader_runid返回runid时,配置纪元会有值,否则一直返回0
3.3 选举领头Sentinel down_state返回1,证明接收is-master-down-by-addr命令的Sentinel认为该Master也主观下线了,如果down_state返回1的数量(包括本身)大于等于quorum(配置文件中配置的值),那么Master正式被当前Sentinel标记为客观下线。 此时,Sentinel会再次发送如下指令:
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid> ログイン後にコピー
ログイン後にコピー
此时的runid将不再是0,而是Sentinel自己的运行id(runid)的值,表示当前Sentinel希望接收到is-master-down-by-addr命令的其他Sentinel将其设置为领头Sentinel。这个设置是先到先得的,Sentinel先接收到谁的设置请求,就将谁设置为领头Sentinel。 发送命令的Sentinel会根据其他Sentinel回复的结果来判断自己是否被该Sentinel设置为领头Sentinel,如果Sentinel被其他Sentinel设置为领头Sentinel的数量超过半数Sentinel(这个数量在sentinelRedisInstance的sentinel字典中可以获取),那么Sentinel会认为自己已经成为领头Sentinel,并开始后续故障转移工作(由于需要半数,且每个Sentinel只会设置一个领头Sentinel,那么只会出现一个领头Sentinel,如果没有一个达到领头Sentinel的要求,Sentinel将会重新选举直到领头Sentinel产生为止)。
3.4 故障转移 故障转移将会交给领头sentinel全权负责,领头sentinel需要做如下事情:
这其中最难的一步是如果选择最佳的新Master,领头Sentinel会做如下清洗和排序工作:
判断slave是否有下线的,如果有从slave列表中移除
删除5秒内未响应sentinel的INFO命令的slave
删除与下线主服务器断线时间超过down_after_milliseconds * 10 的所有从服务器
根据slave优先级slave_priority,选择优先级最高的slave作为新master
如果优先级相同,根据slave复制偏移量slave_repl_offset,选择偏移量最大的slave作为新master
如果偏移量相同,根据slave服务器运行id run id排序,选择run id最小的slave作为新master
新的Master产生后,领头sentinel会向已下线主服务器的其他从服务器(不包括新Master)发送SLAVEOF ip port命令,使其成为新master的slave。
到这里Sentinel的的工作流程就算是结束了,如果新master下线,则循环流程即可!
三、集群 1、简介 Redis集群是Redis提供的分布式数据库方案,集群通过分片(sharding)进行数据共享,Redis集群主要实现了以下目标:
在1000个节点的时候仍能表现得很好并且可扩展性是线性的。
没有合并操作(多个节点不存在相同的键),这样在 Redis 的数据模型中最典型的大数据值中也能有很好的表现。
書き込み安全性。システムは、大部分のノードに接続されているクライアントによって実行されたすべての書き込み操作を保存しようとします。ただし、Redis はデータがまったく失われないことを保証することはできず、非同期および同期のマスター/スレーブ レプリケーションではいずれにせよデータ損失が発生します。
可用性: マスター ノードが利用できない場合、スレーブ ノードがマスター ノードを置き換えることができます。
Redis クラスターの学習に関して、まったくの経験がない場合は、まず次の 3 つの記事 (中国語シリーズ) を読むことをお勧めします: Redis クラスターチュートリアル
REDIS クラスター チュートリアル -- Redis 中国情報ステーション -- Redis 中国ユーザー グループ (CRUG)
Redis クラスターの仕様
REDIS クラスター仕様 -- Redis Chinese Information Station -- Redis China User Group (CRUG)
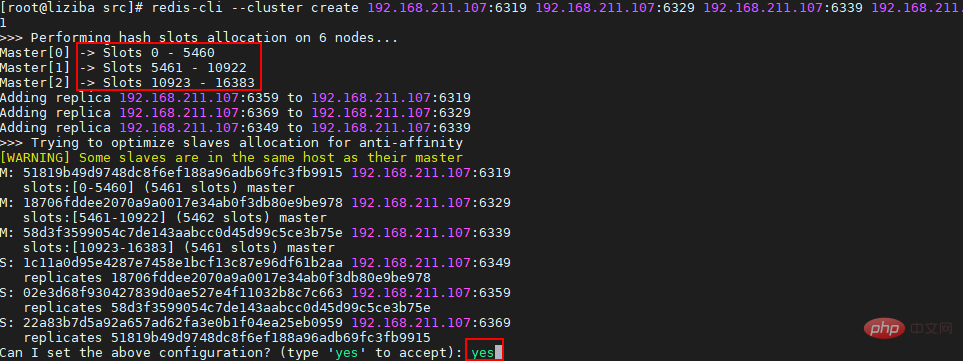
Redis3 マスター 3 スレーブ擬似クラスター展開
CentOS 7 スタンドアロン インストールRedis クラスター (3 マスター、3 疑似クラスター)、必要な手順は 5 つだけです_Li Ziba のブログ - CSDN ブログ
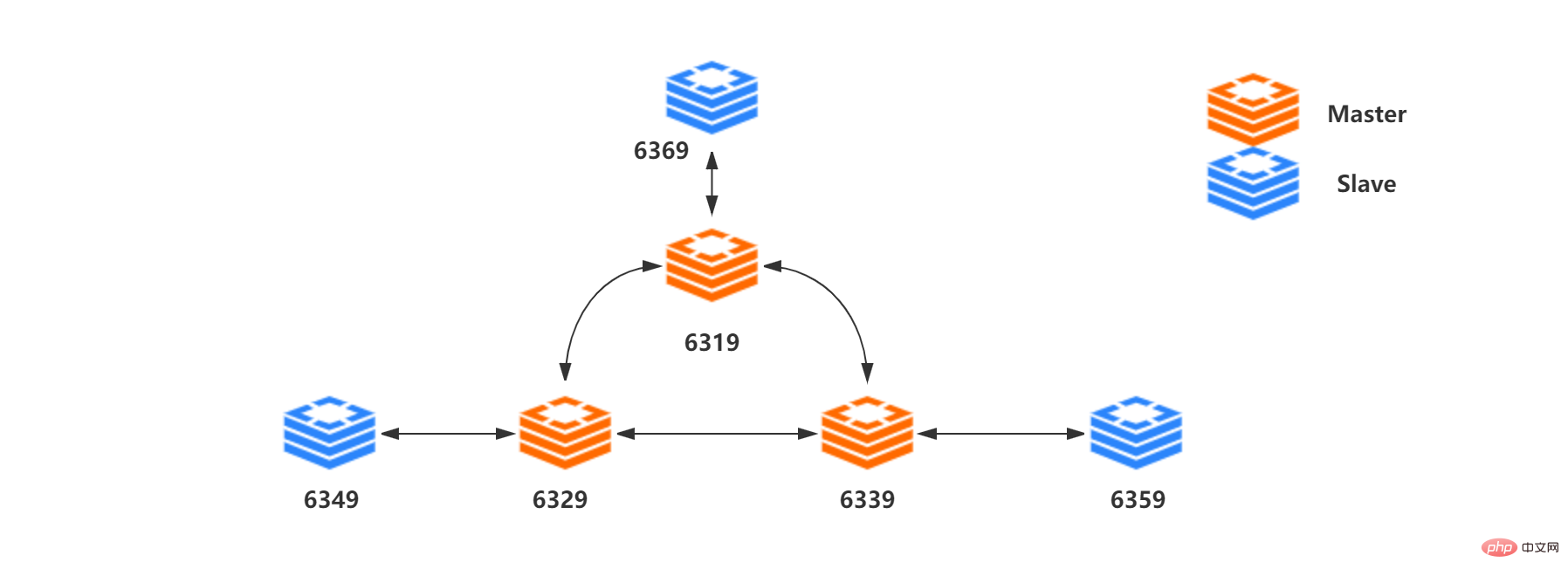
次の内容は、図の 3 つのマスターと 3 つのスレーブ構造に依存しています。以下:
リソースリスト:
##Node IP スロット範囲 ##マスター[0]192.168 .211.107:6319 スロット 0 - 5460 192.168.211.107:6329 スロット 5461 ~ 10922 192.168.211.107:6339 スロット 10923 ~ 16383 192.168.211.107:6369 192.168.211.107: 6349##スレーブ[2] 192.168.211.107:6359
Redis でのマスター/スレーブ レプリケーション、Sentinel、クラスタリングについて説明します。
2、集群内部 Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念。Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,这种结构很容易添加或者删除节点。集群的每个节点负责一部分hash槽,比如上面资源清单的集群有3个节点,其槽分配如下所示:
节点 Master[0] 包含 0 到 5460 号哈希槽
节点 Master[1] 包含5461 到 10922 号哈希槽
节点 Master[2] 包含10923到 16383 号哈希槽
深入学习Redis集群之前,需要了解集群中Redis实例的内部结构。当某个Redis服务节点通过cluster_enabled配置为yes开启集群模式之后,Redis服务节点不仅会继续使用单机模式下的服务器组件,还会增加custerState、clusterNode、custerLink等结构用于存储集群模式下的特殊数据。
如下三个数据承载对象一定要认真看,尤其是结构中的注释,看完之后集群大体上怎么工作的,心里就有数了,嘿嘿嘿;
2.1 clsuterNode clsuterNode用于存储节点信息,比如节点的名字、IP地址、端口信息和配置纪元等等,以下代码列出部分非常重要的属性:
typedef struct clsuterNode {
// 创建时间
mstime_t ctime;
// 节点名字,由40位随机16进制的字符组成(与sentinel中讲的服务器运行id相同)
char name[REDIS_CLUSTER_NAMELEN];
// 节点标识,可以标识节点的角色和状态
// 角色 -> 主节点或从节点 例如:REDIS_NODE_MASTER(主节点) REDIS_NODE_SLAVE(从节点)
// 状态 -> 在线或下线 例如:REDIS_NODE_PFAIL(疑似下线) REDIS_NODE_FAIL(下线)
int flags;
// 节点配置纪元,用于故障转移,与sentinel中用法类似
// clusterState中的代表集群的配置纪元
unit64_t configEpoch;
// 节点IP地址
char ip[REDIS_IP_STR_LEN];
// 节点端口
int port;
// 连接节点的信息
clusterLink *link;
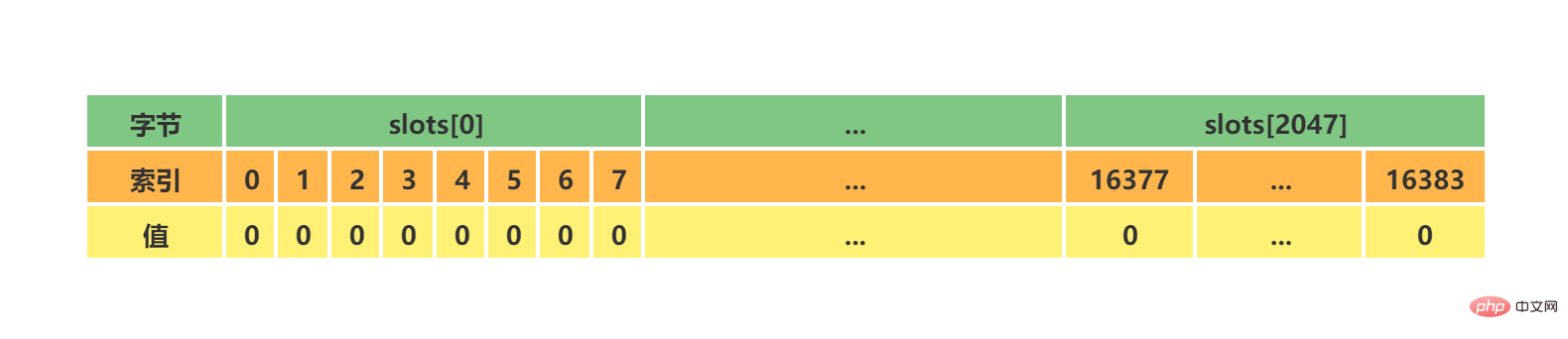
// 一个2048字节的二进制位数组
// 位数组索引值可能为0或1
// 数组索引i位置值为0,代表节点不负责处理槽i
// 数组索引i位置值为1,代表节点负责处理槽i
unsigned char slots[16384/8];
// 记录当前节点处理槽的数量总和
int numslots;
// 如果当前节点是从节点
// 指向当前从节点的主节点
struct clusterNode *slaveof;
// 如果当前节点是主节点
// 正在复制当前主节点的从节点数量
int numslaves;
// 数组——记录正在复制当前主节点的所有从节点
struct clusterNode **slaves;
} clsuterNode; ログイン後にコピー
上述代码中可能不太好理解的是slots[16384/8],其实可以简单的理解为一个16384大小的数组,数组索引下标处如果为1表示当前槽属于当前clusterNode处理,如果为0表示不属于当前clusterNode处理。clusterNode能够通过slots来识别,当前节点处理负责处理哪些槽。 初始clsuterNode或者未分配槽的集群中的clsuterNode的slots如下所示:
假设集群如上面我给出的资源清单,此时代表Master[0]的clusterNode的slots如下所示:
2.2 clusterLink clusterLink是clsuterNode中的一个属性,用于存储连接节点所需的相关信息,比如套接字描述符、输入输出缓冲区等待,以下代码列出部分非常重要的属性:
typedef struct clusterState {
// 连接创建时间
mstime_t ctime;
// TCP 套接字描述符
int fd;
// 输出缓冲区,需要发送给其他节点的消息缓存在这里
sds sndbuf;
// 输入缓冲区,接收打其他节点的消息缓存在这里
sds rcvbuf;
// 与当前clsuterNode节点代表的节点建立连接的其他节点保存在这里
struct clusterNode *node;
} clusterState; ログイン後にコピー
2.3 custerState 每个节点都会有一个custerState结构,这个结构中存储了当前集群的全部数据,比如集群状态、集群中的所有节点信息(主节点、从节点)等等,以下代码列出部分非常重要的属性:
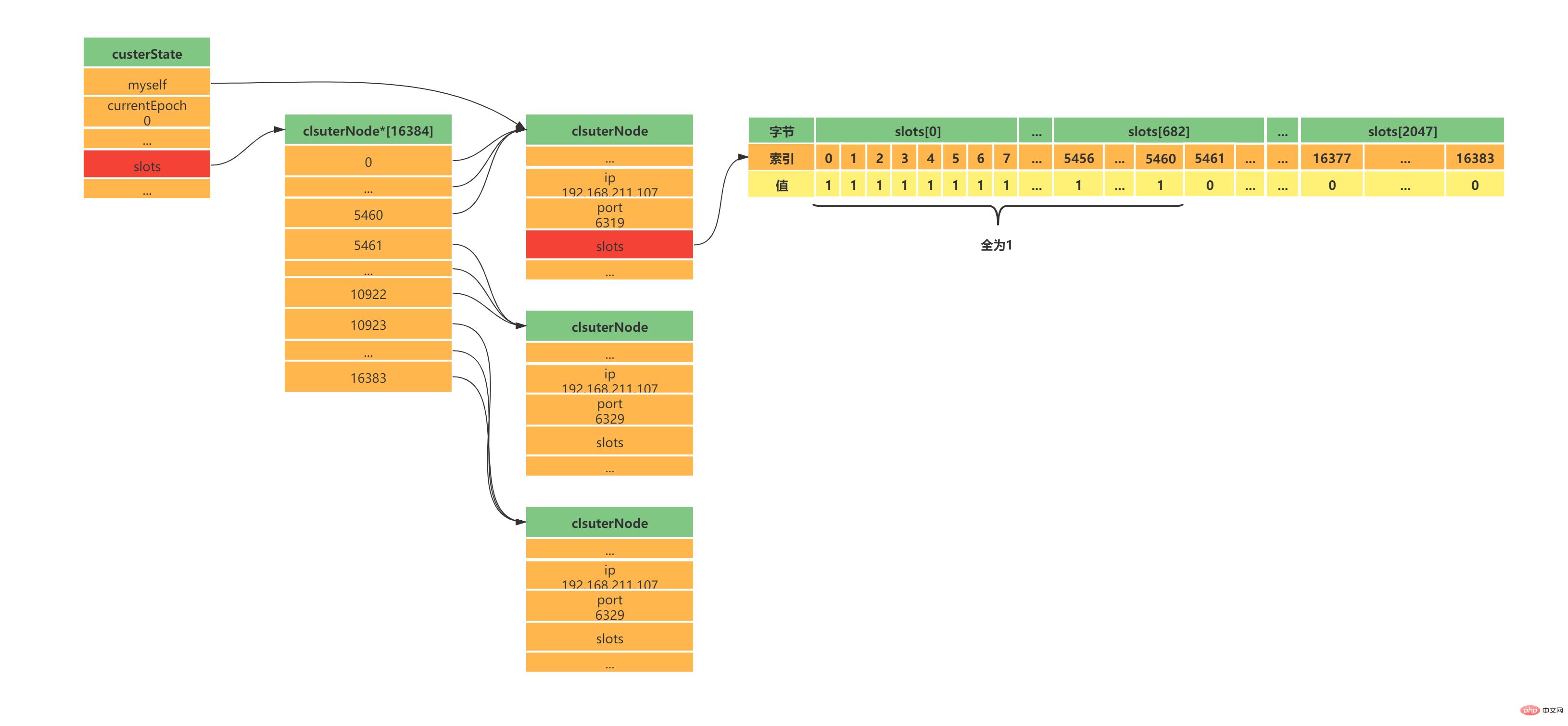
typedef struct clusterState {
// 当前节点指针,指向一个clusterNode
clusterNode *myself;
// 集群当前配置纪元,用于故障转移,与sentinel中用法类似
unit64_t currentEpoch;
// 集群状态 在线/下线
int state;
// 集群中处理着槽的节点数量总和
int size;
// 集群节点字典,所有clusterNode包括自己
dict *node;
// 集群中所有槽的指派信息
clsuterNode *slots[16384];
// 用于槽的重新分配——记录当前节点正在从其他节点导入的槽
clusterNode *importing_slots_from[16384];
// 用于槽的重新分配——记录当前节点正在迁移至其他节点的槽
clusterNode *migrating_slots_to[16384];
// ...
} clusterState; ログイン後にコピー
在custerState有三个结构需要认真了解的,第一个是slots数组,clusterState中的slots数组与clsuterNode中的slots数组是不一样的,在clusterNode中slots数组记录的是当前clusterNode所负责的槽,而clusterState中的slots数组记录的是整个集群的每个槽由哪个clsuterNode负责,因此集群正常工作的时候clusterState的slots数组每个索引指向负责该槽的clusterNode,集群槽未分配之前指向null。
如图展示资源清单中的集群clusterState中的slots数组与clsuterNode中的slots数组:
Redis集群中使用两个slots数组的原因是出于性能的考虑:
当我们需要获取整个集群中clusterNode分别负责什么槽时,只需要查询clusterState中的slots数组即可。如果没有clusterState的slots数组,则需要遍历所有的clusterNode结构,这样显然要慢一些
此外clusterNode中的slots数组也有存在的必要,因为集群中任意一个节点之间需要知道彼此负责的槽,此时节点之间只需要互相传输clusterNode中的slots数组结构就行。
第二个需要认真了解的结构是node字典,该结构虽然简单,但是node字典中存储了所有的clusterNode,这也是Redis集群中的单个节点获取其他主节点、从节点信息的主要位置,因此我们也需要注意一下。 第三个需要认真了解的结构是importing_slots_from[16384]数组和migrating_slots_to[16384],这两个数组在集群重新分片时需要使用,需要重点了解,后面再说吧,这里说的话顺序不太对。
3. クラスターの作業 3.1 スロットを割り当てる方法は? Redis クラスターには合計 16384 のスロットがあります。上記のリソース リストに示すように、3 つのマスターと 3 つのスレーブのクラスター内にあります。各マスター ノードは、独自の対応するスロットを担当します。ただし、上記の 3 つのマスターと 3 つのスレーブのデプロイメント プロセスでは、スロットが対応するマスター ノードに割り当てられていることがわかります。これは、Redis クラスター自体が内部でスロットを分割しているためです。自分でスロットを割り当てますか?次のコマンドをノードに送信して、現在のノードに 1 つ以上のスロットを割り当てることができます:
CLUSTER ADDSLOTS
たとえば、次のようにします。スロット 0 と 1 をマスター [0] に割り当てたい場合は、次のコマンドをマスター [0] ノードに送信するだけです:
#CLUSTER ADDSLOTS 0 1
ノードにスロットが割り当てられると、clusterNode のスロット配列が更新され、ノードは処理を担当するスロット (スロット配列) をクラスター内の他のノードに送信します。メッセージを受信した後、他のノードがメッセージを受信します。clusterNode に対応するスロット配列と、clusterState の solts 配列を更新します。
3.2 Redis クラスター内で ADDSLOTS はどのように実装されますか? これは実際には比較的単純です。CLUSTER ADDSLOTS コマンドを Redis クラスター内のノードに送信すると、現在のノードはまず、clusterState のスロット配列を使用して、現在のノードに割り当てられているスロットが割り当てられているかどうかを確認します。他のノードが割り当てられている場合、例外が直接スローされ、割り当てられたクライアントにエラーが返されます。現在のノードに割り当てられているすべてのスロットが他のノードに割り当てられていない場合、現在のノードはそれらのスロットを自分自身に割り当てます。割り当てには主に 3 つの手順があります。
clusterState のスロット配列を更新し、指定されたスロット [i] が現在のクラスタノードを指すようにします。
クラスターノード配列のスロットを更新し、指定されたスロット[i]の値を 1
クラスター内の他のノードにメッセージを送信し、クラスターノードのスロット配列を他のノードに送信します。 、および他のノードはそれを受信します メッセージの後、clusterState の対応するスロット配列と、clusterNode のスロット配列も更新されます。クライアントはどのノードをリクエストすればよいか知っていますか?
現時点では、クライアントがノードにリクエストを送信するために接続するとき, 現在コマンドを受信しているノードは、まず現在のキーが属するスロット i をアルゴリズムによって計算します。計算後、現在のノードは、clusterState のスロット i が自身の責任であるかどうかを判断します。自身の責任で、現在のノードはクライアントのリクエストに応答します。リクエストが現在のノードによって処理されない場合は、次の手順を実行します:
ノードは MOVED リダイレクトを返します。エラーがクライアントに送信され、計算されたキーは MOVED リダイレクト エラーで正しく処理されます。クライアントが MOVED リダイレクトを受信すると、clusterNode の IP とポートがクライアントに返されます。ノードによってエラーが返された場合、IP とポート、およびプロセス全体に基づいてコマンドが正しいノードに転送されます。このプロセスはプログラマーには透過的であり、Redis クラスターのサーバーとクライアントによって共同で完了します。
##CLUSTER ADDSLOTS スロット 1 [スロット 2] … [スロット N]
クラスター DELSLOTS スロット 1 [スロット 2] … [スロット N]
クラスター セットスロット スロット ノード ノード
#CLUSTER SETSLOT スロット移行ノード
CLUSTER 用于槽分配的指令主要有如上这些,ADDSLOTS 和DELSLOTS主要用于槽的快速指派和快速删除,通常我们在集群刚刚建立的时候进行快速分配的时候才使用。CLUSTER SETSLOT slot NODE node也用于直接给指定的节点指派槽。如果集群已经建立我们通常使用最后两个来重分配,其代表的含义如下所示:
当一个槽被设置为 MIGRATING,原来持有该哈希槽的节点仍会接受所有跟这个哈希槽有关的请求,但只有当查询的键还存在原节点时,原节点会处理该请求,否则这个查询会通过一个 -ASK 重定向(-ASK redirection)转发到迁移的目标节点。
当一个槽被设置为 IMPORTING,只有在接受到 ASKING 命令之后节点才会接受所有查询这个哈希槽的请求。如果客户端一直没有发送 ASKING 命令,那么查询都会通过 -MOVED 重定向错误转发到真正处理这个哈希槽的节点那里。
上面这两句话是不是感觉不太看的懂,这是官方的描述,不太懂的话我来给你通俗的描述,整个流程大致如下步骤:
redis-trib(集群管理软件redis-trib会负责Redis集群的槽分配工作),向目标节点(槽导入节点)发送CLUSTER SETSLOT slot IMPORTING node命令,目标节点会做好从源节点(槽导出节点)导入槽的准备工作。
redis-trib随即向源节点发送CLUSTER SETSLOT slot MIGRATING node命令,源节点会做好槽导出准备工作
redis-trib随即向源节点发送CLUSTER GETKEYSINSLOT slot count命令,源节点接收命令后会返回属于槽slot的键,最多返回count个键
redis-trib会根据源节点返回的键向源节点依次发送MIGRATE ip port key 0 timeout命令,如果key在源节点中,将会迁移至目标节点。
迁移完成之后,redis-trib会向集群中的某个节点发送CLUSTER SETSLOT slot NODE node命令,节点接收到命令后会更新clusterNode和clusterState结构,然后节点通过消息传播槽的指派信息,至此集群槽迁移工作完成,且集群中的其他节点也更新了新的槽分配信息。
3.5 如果客户端访问的key所属的槽正在迁移怎么办? 优秀的你总会想到这种并发情况,牛皮呀!大佬们!
这个问题官方也考虑了,还记得我们在聊clusterState结构的时候么?importing_slots_from和migrating_slots_to就是用来处理这个问题的。
typedef struct clusterState {
// ...
// 用于槽的重新分配——记录当前节点正在从其他节点导入的槽
clusterNode *importing_slots_from[16384];
// 用于槽的重新分配——记录当前节点正在迁移至其他节点的槽
clusterNode *migrating_slots_to[16384];
// ...
} clusterState; ログイン後にコピー
有了上述两个相互数组,就能判断当前槽是否在迁移了,而且从哪里迁移来,要迁移到哪里去?搞笑不就是这么简单……
此时,回到问题中,如果客户端请求的key刚好属于正在迁移的槽。那么接收到命令的节点首先会尝试在自己的数据库中查找键key,如果这个槽还没迁移完成,且当前key刚好也还没迁移完成,那就直接响应客户端的请求就行。如果该key已经不在了,此时节点会去查询migrating_slots_to数组对应的索引槽,如果索引处的值不为null,而是指向了某个clusterNode结构,那说明这个key已经被迁移到这个clusterNode了。这个时候节点不会继续在处理指令,而是返回ASKING命令,这个命令也会携带导入槽clusterNode对应的ip和port。客户端在接收到ASKING命令之后就需要将请求转向正确的节点了,不过这里有一点需要注意的地方**(因此我放个表情包在这里,方便读者注意)。**
前述したように、ノードは現在のスロットが自分の処理に属さないと判断すると MOVED 命令を返しますが、マイグレーション時にスロットをどのように処理するのでしょうか?これがこの Redis クラスターの目的です。ノードは、スロットが移行中であることを検出すると、クライアントに ASKING コマンドを返します。クライアントは、スロットの移行先のクラスターノードのノード IP とポートを含む ASKING コマンドを受け取ります。次に、クライアントは最初に ASKING コマンドを移行中のクラスターノードに送信します。このコマンドの目的は、このスロットは移行されているため、このリクエストを処理するために例外を作成する必要があることを現在のノードに伝えることである必要があります。直接拒否してください ( したがって、Redis が ASKING コマンドを受信しない場合、ノードのクラスター状態を直接クエリし、移行中のスロットはクラスター状態に更新されていないため、MOVED を直接返すことしかできず、ループし続けます。何度も...)、受信 ASKING コマンドを持つノードは、このリクエストを強制的に 1 回実行します (1 回のみ。次回は事前に ASKING コマンドを再度送信する必要があります)。
4. クラスターの障害
Redis クラスターの障害は比較的単純です。これは、センチネルのマスター ノードがダウンしているか、指定された最大時間内に応答しないことに関連しています。新しいマスター ノードを再選択します。スレーブノードからの場合、方法は実際には同様です。もちろん、Redis クラスター内の各マスター ノードに対して、事前にスレーブ ノードを設定していることが前提となります。そうしないと役に立ちません...
REDIS クラスター仕様 - - Redis 中国情報ステーション - Redis 中国ユーザー グループ (CRUG)
http://redis.cn/topics/cluster -spec.html
または、Huang Jianhong 先生の著書「Redis の設計と実装」は非常によく書かれており、私もその内容の多くを参照しました。
プログラミング関連の知識について詳しくは、
プログラミング ビデオをご覧ください。 !
以上がRedis でのマスター/スレーブ レプリケーション、Sentinel、クラスタリングについて説明します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
このウェブサイトの声明
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。
著者別の最新記事
2023-04-26 17:59:18
2023-04-26 17:47:48
2023-04-26 17:41:42
2023-04-26 17:37:05
2023-04-26 17:31:25
2023-04-26 17:27:32
2023-04-25 19:57:58
2023-04-25 19:53:11
2023-04-25 19:49:11
2023-04-25 19:41:54


 2.1.3 欠陥
2.1.3 欠陥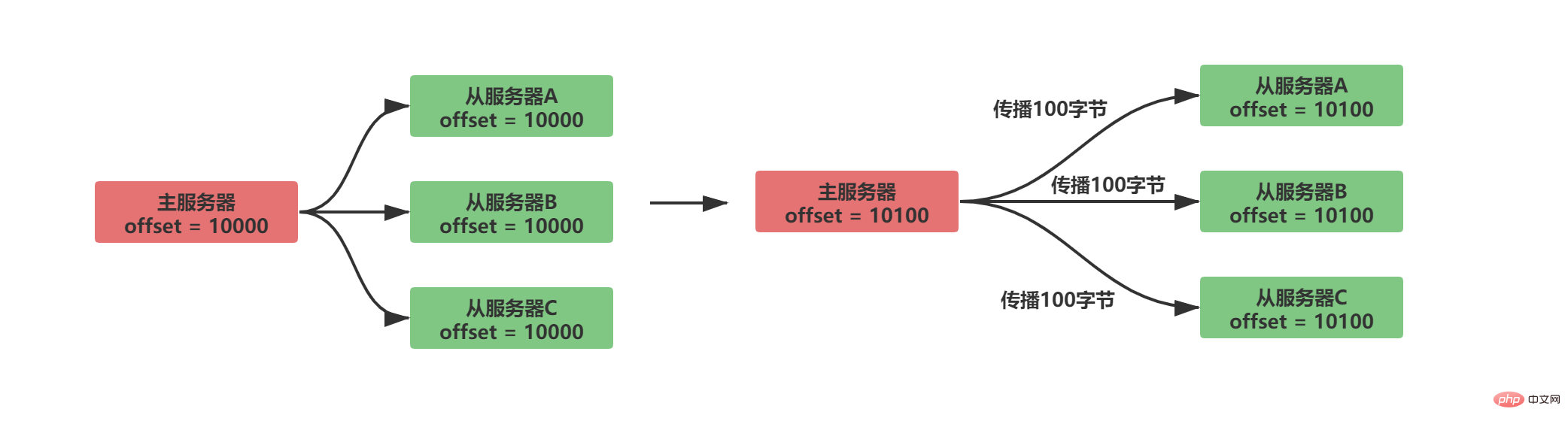
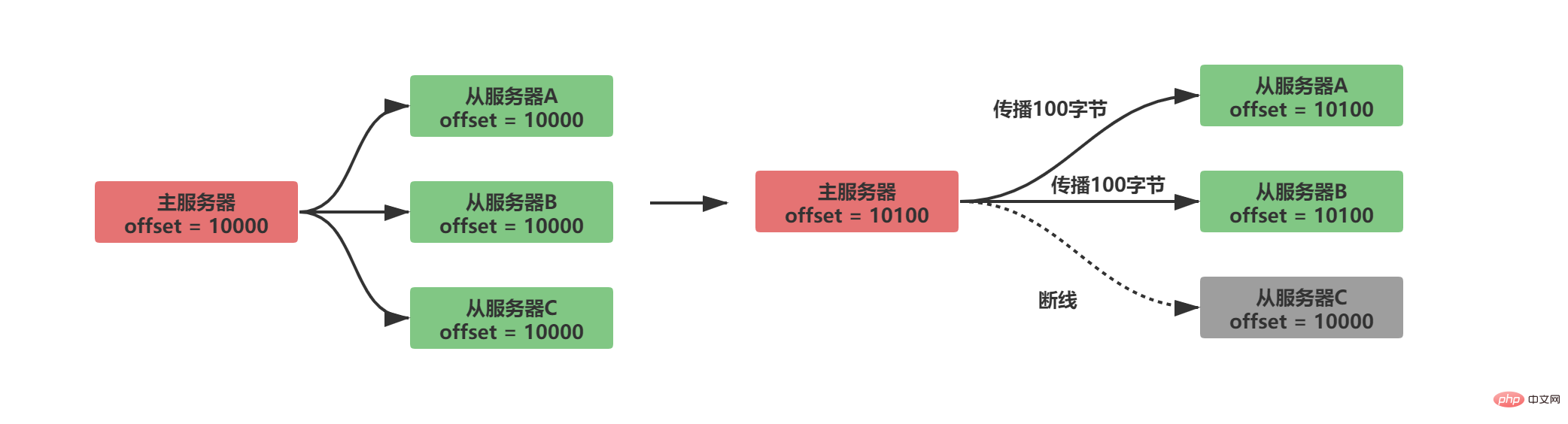
 #スレーブ サーバーが切断され、再接続されると、スレーブ サーバーは psync コマンドを通じてそのレプリケーション オフセット (オフセット) をマスター サーバーに送信し、マスター サーバーはこのオフセットを使用できます。増分伝播または完全同期を実行します。
#スレーブ サーバーが切断され、再接続されると、スレーブ サーバーは psync コマンドを通じてそのレプリケーション オフセット (オフセット) をマスター サーバーに送信し、マスター サーバーはこのオフセットを使用できます。増分伝播または完全同期を実行します。 


 #コマンド接続が作成された後、Sentinel は 10 秒ごとにマスターに INFO コマンドを送信し、マスターの応答情報を使用します。
#コマンド接続が作成された後、Sentinel は 10 秒ごとにマスターに INFO コマンドを送信し、マスターの応答情報を使用します。  メイン サービスに従ってスレーブ サーバーの情報を取得します。Sentinel はスレーブへのネットワーク接続を作成し、ネットワークも作成できます。 Sentinel とスレーブ間の接続 コマンド接続とサブスクリプション接続
メイン サービスに従ってスレーブ サーバーの情報を取得します。Sentinel はスレーブへのネットワーク接続を作成し、ネットワークも作成できます。 Sentinel とスレーブ間の接続 コマンド接続とサブスクリプション接続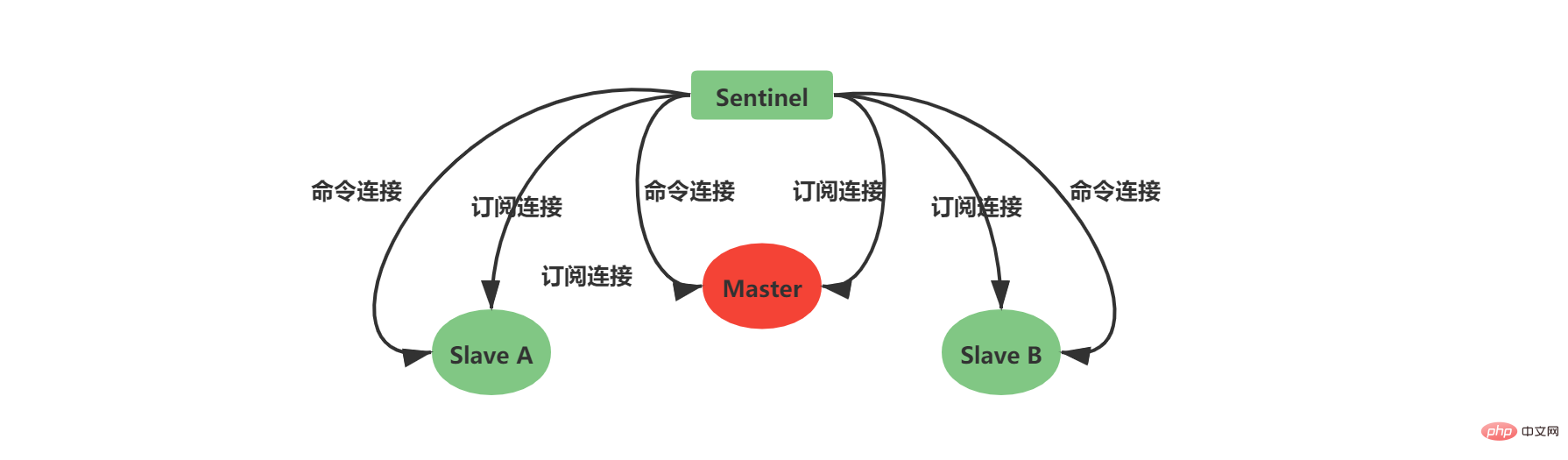























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



