

この記事は、mysql データベースのインデックス作成に関する関連知識を提供するもので、インデックス作成のほぼすべての知識ポイントが含まれています。

Mysql インデックスの公式紹介インデックスは、MySQL が効率的にデータを取得するのに役立つ データ構造 です。より一般的に言うと、データベース インデックスは書籍の冒頭にある目次のようなもので、データベース クエリを高速化できます。
インデックスはディスク上のファイルに保存されることがよくあります (別のインデックス ファイルに保存されるか、データ ファイル内のデータと一緒に保存される可能性があります)。
通常、インデックスと呼ばれるものには、クラスター化インデックス、カバリング インデックス、結合インデックス、プレフィックス インデックス、一意インデックスなどが含まれます。特別な指示がなければ、B ツリー構造は次のように使用されます。デフォルト。組織化された (多方向検索ツリー、必ずしもバイナリではない) インデックス。
利点:
はい書籍のカタログと同様に、データ検索の効率を向上させ、データベース の IO コストを削減します。
インデックス列 を介してデータを並べ替えることで、データの並べ替えコストと CPU 消費量を削減します。
インデックス タイプ
複合インデックス
に従う必要があります。一般に、条件が許せば、複数の単一列インデックスの代わりに結合インデックスが使用されます。
インデックス データ構造
二分探索木二分木というと、誰もが頭の中にイメージがあると思います。
バイナリ ツリーの特徴: 各ノードには最大 2 つのフォークがあり、左サブツリーと右サブツリーのデータ順序は左側が小さく、右側が大きい。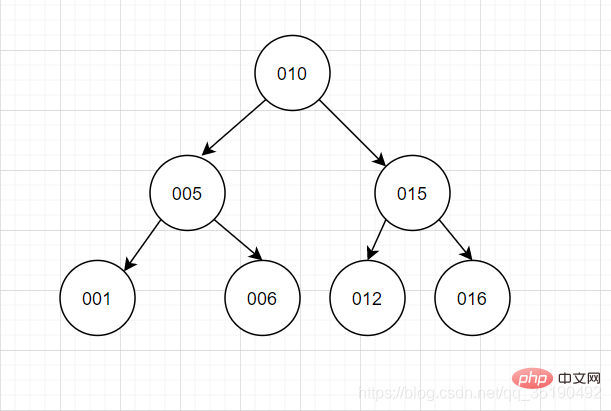 この機能は、各検索を半分にして IO 回数を削減することを目的としていますが、同時実行性が確保されやすいため、バイナリ ツリーは最初のルート ノードの値をテストすることになります。この機能で実現したいのですが、「木が分岐しない」という状況は非常に不快で不安定です。
この機能は、各検索を半分にして IO 回数を削減することを目的としていますが、同時実行性が確保されやすいため、バイナリ ツリーは最初のルート ノードの値をテストすることになります。この機能で実現したいのですが、「木が分岐しない」という状況は非常に不快で不安定です。
#この状況は明らかに不安定であり、この状況を必然的に回避する設計を選択します。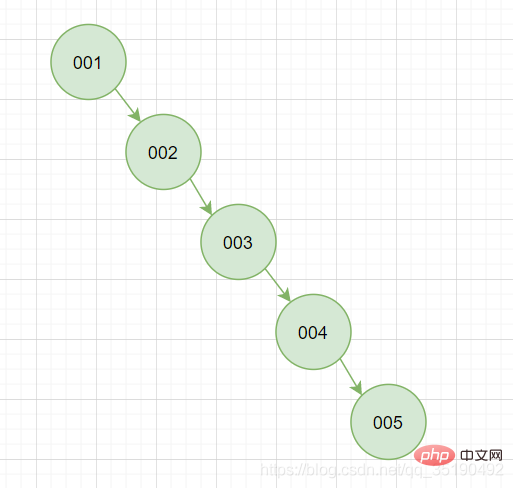
バランス バイナリ ツリーバランス型二分木は二分法の考え方を採用しています。二分木の特徴に加えて、バランス型二分探索木の最も重要な特徴は、ツリーの左右の部分木のレベルが最大で 1 異なることです。 。データの挿入と削除の際には、二分木のバランスを保つために左巻き/右巻き操作が使用され、左側の部分木はあまり高くならず、右側の部分木は低くなります。
バランス二分探索ツリー クエリを使用したパフォーマンスは二分探索法に近く、時間計算量は O(log2n) です。 id=6 のクエリに必要な IO は 2 つだけです。
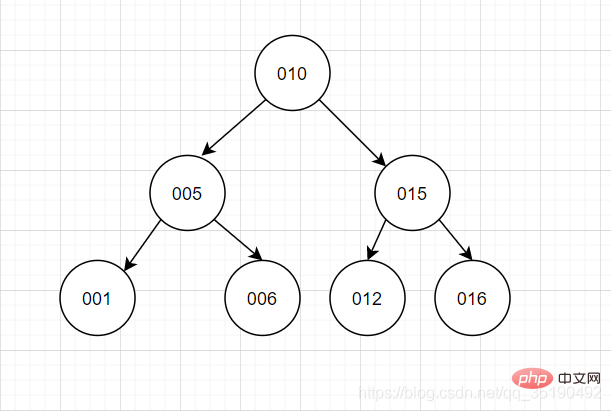
この機能を見ると、これは非常に優れており、バイナリ ツリーの理想的な状況を実現できると思われるかもしれません。ただし、まだいくつかの問題があります。
時間計算量は木の高さに関係します。ツリーを何回取得する必要があるかはツリーの高さによって異なり、各ノードの読み取りはディスク IO 操作に相当します。ツリーの高さは、データがクエリされるたびのディスク IO 操作の数に等しくなります。各ディスクのシーク時間は 10 ミリ秒であり、テーブル データの量が多い場合、クエリのパフォーマンスは非常に低下します。 (データ量が 100 万の場合、log2n はディスク IO 回の 20 回にほぼ等しく、時間は 20*10=0.2 秒です)
バランスのとれたバイナリ ツリーは範囲をサポートしません。高速検索のためにクエリを実行し、範囲クエリを実行する必要があります。ルート ノードが複数回走査されるため、クエリ効率は高くありません。
MySQL データはディスク ファイルに保存されます。データのクエリや処理を行うときは、ディスクからデータをロードする必要があります。ディスク IO 操作は非常に時間がかかるため、最適化の焦点はディスク IO 操作を最小限に抑えることです。バイナリ ツリーの各ノードにアクセスすると IO が発生するため、ディスク IO 操作を減らしたい場合は、ツリーの高さをできるだけ減らす必要があります。では、木の高さを低くするにはどうすればよいでしょうか?
キーが bigint=8 バイトの場合、各ノードには 2 つのポインターがあり、各ポインターは 4 バイトで、1 つのノードは 16 バイトのスペースを占有します (8 4*2=16)。
MySQL の InnoDB ストレージ エンジンは 1 回の IO で 1 ページのデータ量 (デフォルトのページは 16K) を読み取りますが、バイナリ ツリーの 1 回の IO で有効なデータ量はわずか 16 バイトであるため、スペース使用率は非常に低いです。 1 つの IO スペースを最大限に活用するための簡単なアイデアは、各ノードに複数の要素を格納し、各ノードにできるだけ多くのデータを格納することです。各ノードには 1000 個のインデックス (16k/16=1000) を格納できるため、バイナリ ツリーはマルチフォーク ツリーに変換され、ツリーのフォーク ツリーを増やすことで、高くて細いツリーから短くて太いツリーに変化します。 100 万個のデータを構築するには、ツリーの高さは 2 レベル (1000*1000=100 万) だけ必要です。つまり、データのクエリに必要なディスク IO は 2 回だけです。ディスク IO の数が削減され、データのクエリの効率が向上します。
このデータ構造を B ツリーと呼びます。B ツリーはマルチフォークのバランス型検索ツリーです。主な機能は次のとおりです。 B ツリーのノードは複数の要素に格納され、各内部ノードには複数のフォークがあります。
ノード内の要素にはキー値とデータが含まれており、ノード内のキー値は大きいものから小さいものへと並べられています。つまり、データはすべてのノードに保存されます。
親ノードの要素は子ノードには表示されません。
すべてのリーフ ノードは同じレイヤー上に配置され、リーフ ノードの深さは同じで、リーフ ノード間にはポインタ接続はありません。
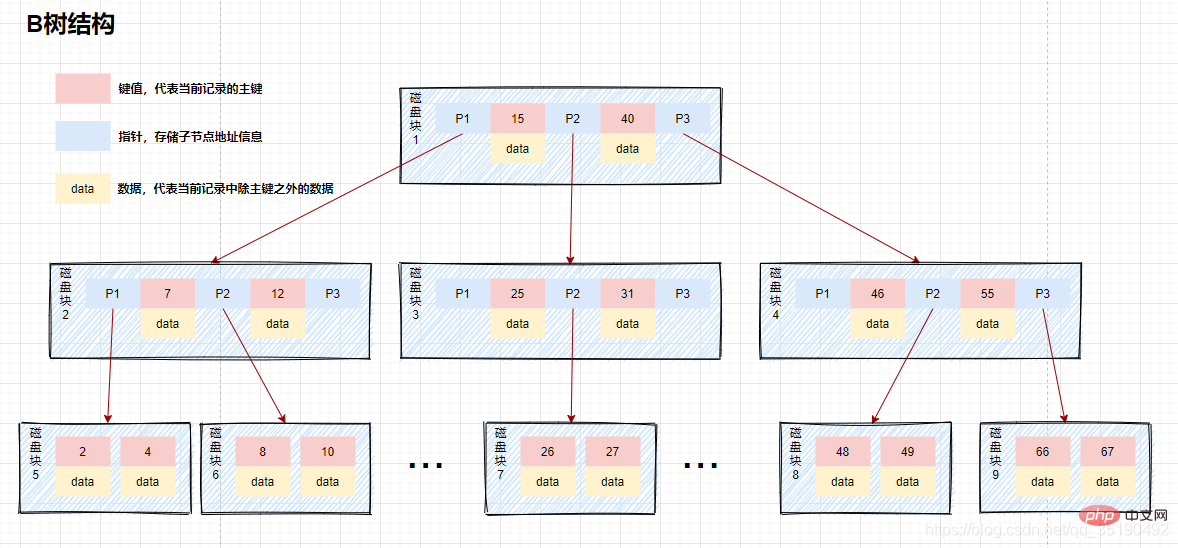
2 番目のディスク IO: ディスク ブロック 2 をメモリにロードし、メモリ内を先頭 (7
3 番目のディスク IO: ディスク ブロック 5 をメモリにロードし、メモリ内を先頭から走査して比較します。10=10、10 を見つけて、データに格納されている行レコードがあれば、データを取り出します。取り出されると、クエリは終了します。ディスク アドレスが保存されている場合は、ディスク アドレスに従ってデータをディスクからフェッチする必要があり、クエリは終了します。
バイナリ平衡検索ツリーと比較すると、検索プロセス全体でデータ比較の数は大幅に減りませんが、ディスク IO の数は大幅に削減されます。同時に、比較はメモリ内で実行されるため、比較時間は無視できます。 B ツリーの高さは通常 2 ~ 3 レイヤーであり、ほとんどのアプリケーション シナリオを満たすことができるため、B ツリーを使用してインデックスを構築すると、クエリ効率が大幅に向上します。
プロセスは次のとおりです。
これを見ると、B-tree が理想的だと思うはずですが、先輩たちはこう言います。まだ存在しており、最適化できることをお知らせします。場所: 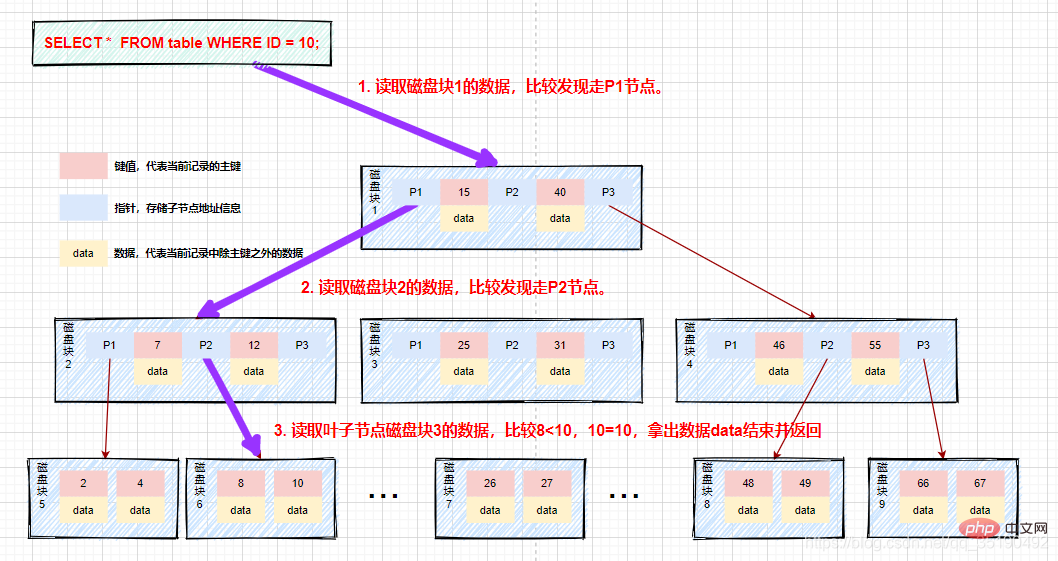
データが行レコードを格納する場合、列の数が増えると行のサイズも増加し、占有されるスペースも増加します。このとき、ページに格納できるデータ量は減少し、ツリーの高さは増加し、ディスク IO の数は増加します。
B ツリーは、B ツリーのアップグレード バージョンとして、B ツリーに基づいており、MySQL は B に基づいて変換を続けます。 B ツリーを使用してインデックスを構築します。 B ツリーと B ツリーの主な違いは、非リーフ ノードにデータが保存されるかどうかです。
- B ツリー: 非リーフ ノードとリーフノードにはデータが格納されます。
- B ツリー: リーフ ノードのみがデータを保存し、非リーフ ノードはキー値を保存します。リーフ ノードは双方向ポインタを使用して接続され、最下位のリーフ ノードは双方向の順序付きリンク リストを形成します。
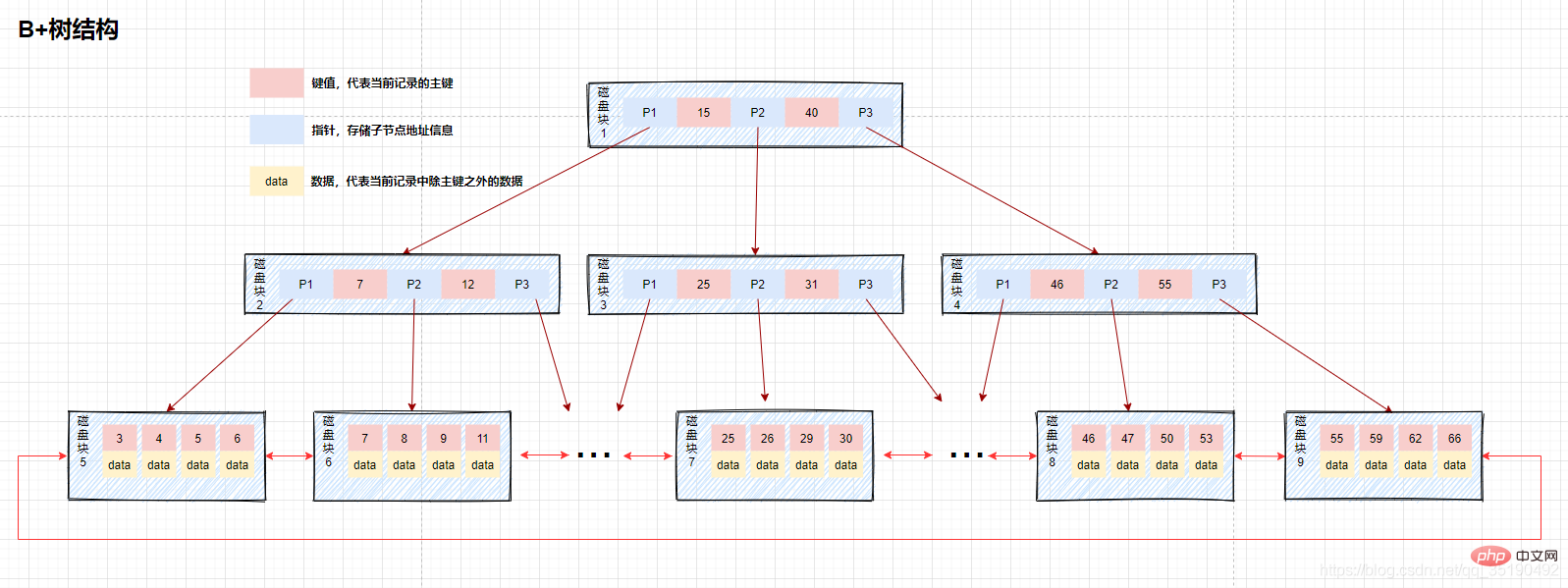
#B ツリーの最下位のリーフ ノードには、すべてのインデックス項目が含まれます。図からわかるように、B ツリーがデータを検索する場合、データは最下位のリーフ ノードに格納されているため、各検索ではデータをクエリするためにリーフ ノードを取得する必要があります。したがって、データをクエリする必要がある場合、各ディスクの IO はツリーの高さに直接関係しますが、一方で、データはリーフ ノードに配置されるため、ディスク ブロック ロックに格納されるインデックスの数が増加します。これに伴いインデックスの値が増加するため、B ツリーに比べて理論上は B ツリーの高さは B ツリーよりも低くなります。インデックスがクエリをカバーする場合もあります。インデックス内のデータは、現在のクエリ ステートメントで必要なデータをすべて満たしています。この場合、最下位のリーフ ノードを取得せずに、ただちに返すインデックスを見つけるだけで済みます。例:
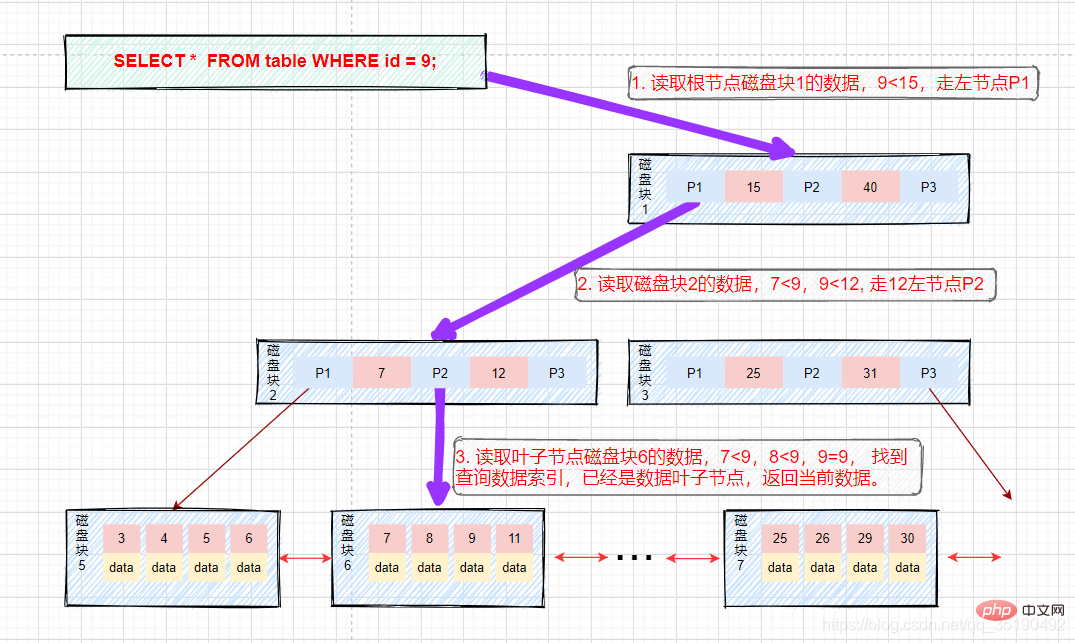
クエリ値が次の場合9 データ。クエリ パス ディスク ブロック 1-> ディスク ブロック 2-> ディスク ブロック 6。
- 等しい値クエリ:
プロセスは図に示すとおりです。
- 最初のディスク IO: ディスク ブロック 1 をメモリにロードし、メモリ内を先頭 (9
- 2 番目のディスク IO: ディスク ブロック 2 をメモリにロードし、メモリ内を最初から 7
- 3 番目のディスク IO: ディスク ブロック 6 をメモリにロードし、メモリを先頭から走査して比較し、3 番目のインデックスで 9 を見つけ、データがあればデータを取り出します。が格納されています。 レコードを並べてデータを取り出し、クエリは終了します。ディスク アドレスが保存されている場合は、ディスク アドレスに従ってデータをディスクからフェッチする必要があり、クエリは終了します。 (ここで区別する必要があるのは、InnoDB のデータは行データを格納するのに対し、MyIsam はディスク アドレスを格納するということです。)
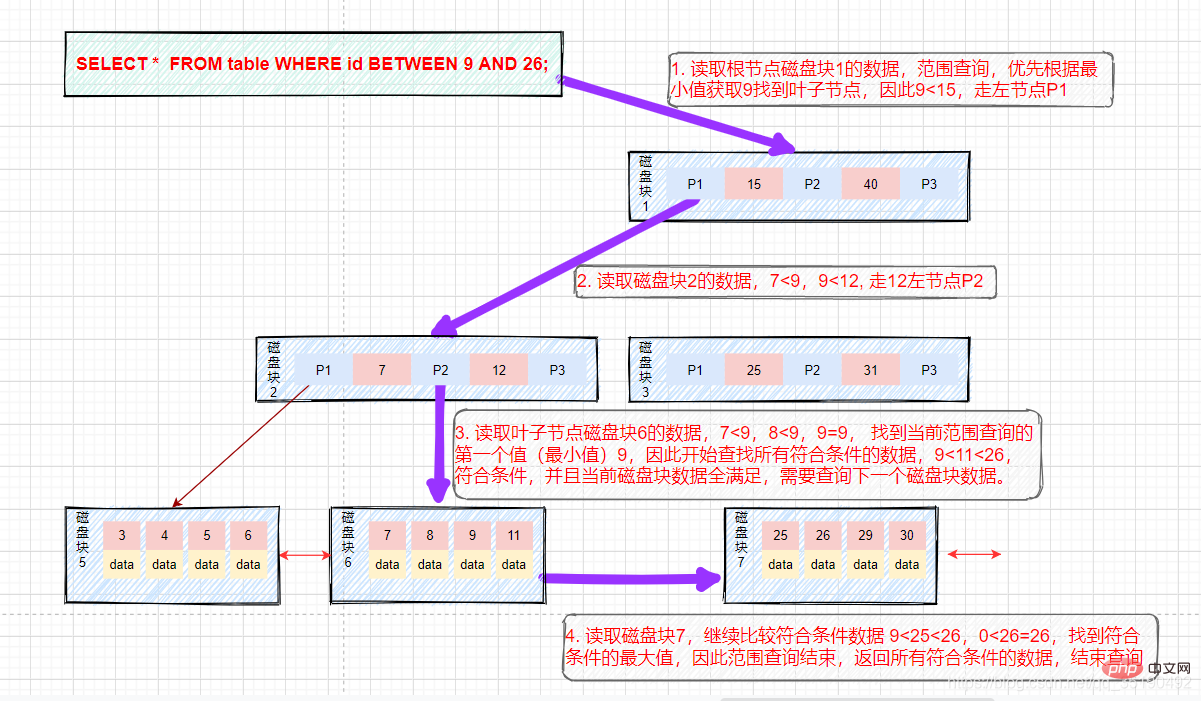
範囲クエリ:まず、値が 9 のデータを検索し、値が 9 のデータを結果セットにキャッシュします。この手順は前述の同等のクエリ プロセスと同じであり、3 つのディスク IO が発生します。
- 9 から 26 までのデータを検索したい場合。検索パスは、ディスク ブロック 1 -> ディスク ブロック 2 -> ディスク ブロック 6 -> ディスク ブロック 7 です。
- 15 を見つけた後、基になるリーフ ノードは順序付きリストになります。ディスク ブロック 6 とキー値 9 から開始して逆方向にたどって、フィルター条件を満たすすべてのデータをフィルターします。
- 4 番目のディスク IO: ディスク 6 の後続ポインタに従ってディスク ブロック 7 をアドレス指定して配置し、ディスク 7 をメモリにロードし、メモリ内を最初からたどって比較します。9< ;25
- 主キーは一意であるため (後で 26 以下のデータは存在しません)、過去を振り返る必要はなく、クエリは終了します。結果セットをユーザーに返します。
B ツリーにより、等しい値と範囲のクエリを高速に検索できることがわかります。MySQL のインデックスは B ツリーを使用しています。データ構造。
Mysql インデックスの実装
インデックス データ構造を導入した後、実際の使用シナリオを確認するには、それを Mysql に取り込む必要があるため、ここでは Mysql インデックス実装の 2 つの保存方法を分析します。エンジンの:InnoDB IndexMyIsam Index
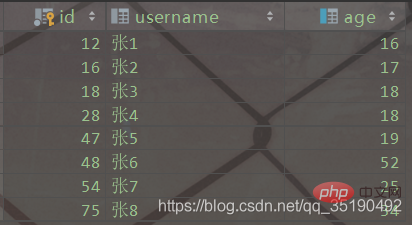
例として、単純なユーザー テーブルを取り上げます。 user テーブルには 2 つのインデックスがあり、id 列は主キー インデックス、age 列は通常のインデックスです。CREATE TABLE `user`( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(20) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_age` (`age`) USING BTREE) ENGINE = MyISAM AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
MyISAM のデータ ファイルとインデックス ファイル別々に保管されます。 MyISAM が B ツリーを使用してインデックス ツリーを構築する場合、リーフ ノードに格納されるキー値はインデックス列の値であり、データはインデックスが配置されている行のディスク アドレスです。 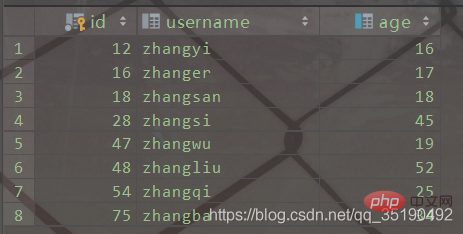
テーブル user のインデックスはインデックス ファイル  user.MYI
user.MYI
user.MYD に保存されます。 クエリ中のディスク IO 状況を簡単に分析します:
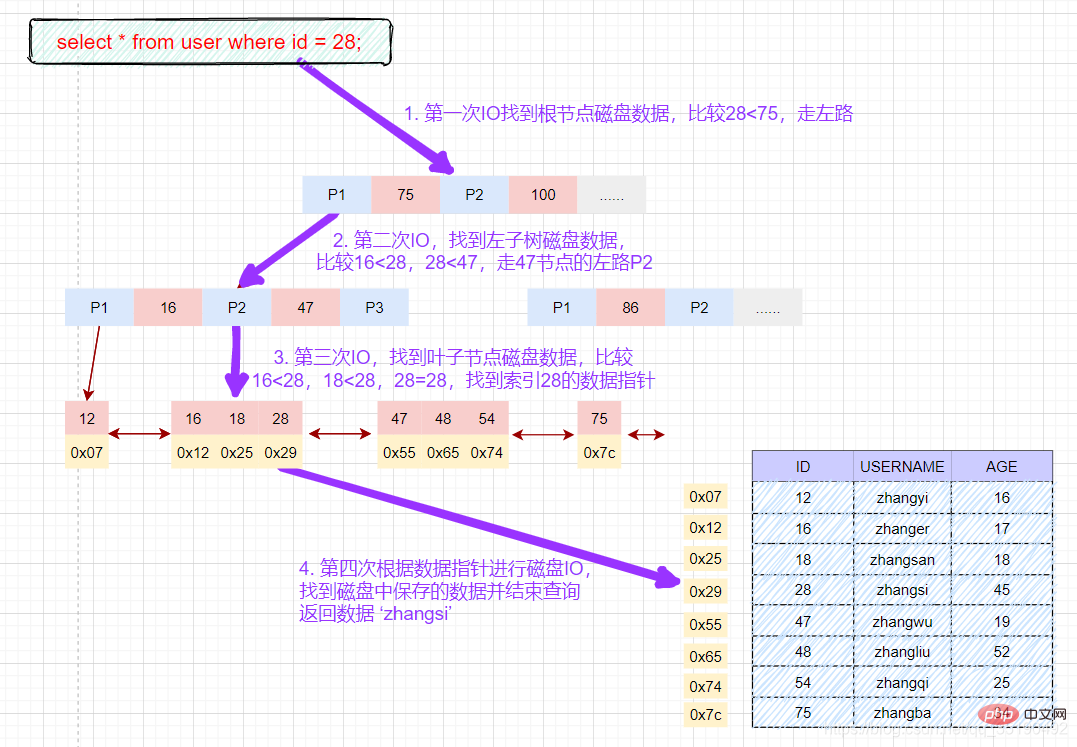
主キーに相当するデータに基づいてデータをクエリします:
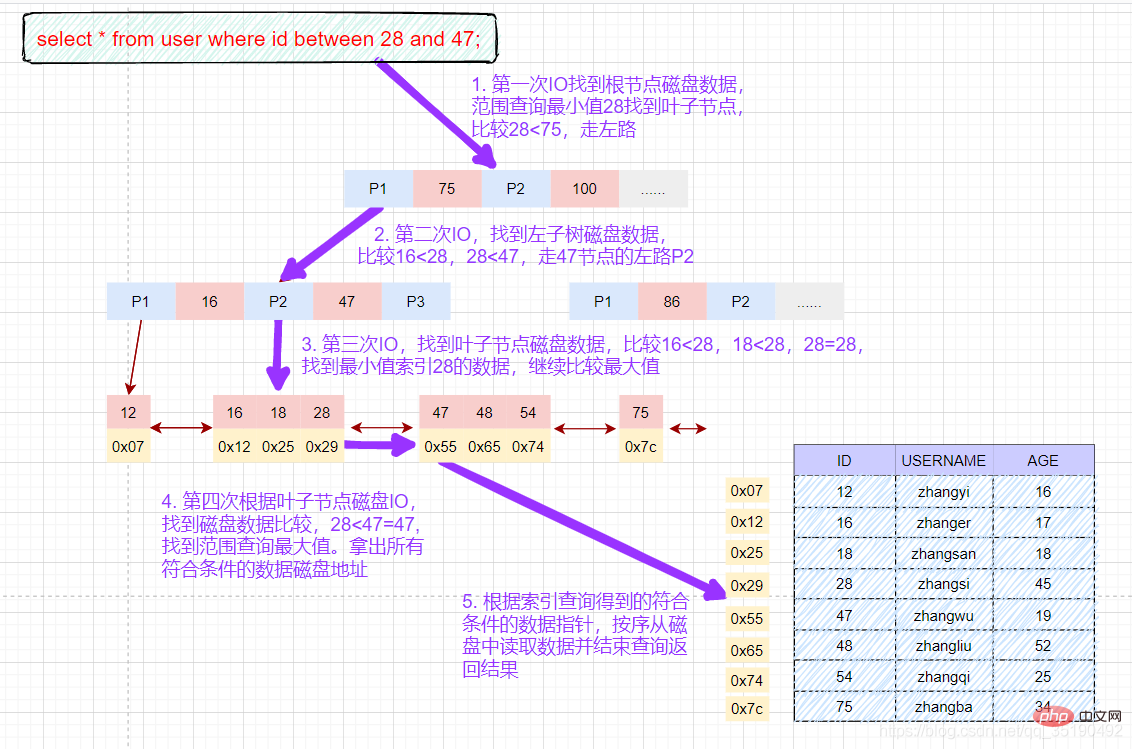
select * from user where id = 28;
磁盘IO次数:3次索引检索+记录数据检索。
根据主键范围查询数据:
select * from user where id between 28 and 47;
先在主键树中从根节点开始检索,将根节点加载到内存,比较28
将左子树节点加载到内存中,比较16
检索到叶节点,将节点加载到内存中遍历比较16
根据磁盘地址从数据文件中获取行记录缓存到结果集中。(1次磁盘IO)
我们的查询语句时范围查找,需要向后遍历底层叶子链表,直至到达最后一个不满足筛选条件。
向后遍历底层叶子链表,将下一个节点加载到内存中,遍历比较,28
最后得到两条符合筛选条件,将查询结果集返给客户端。
磁盘IO次数:4次索引检索+记录数据检索。
**备注:**以上分析仅供参考,MyISAM在查询时,会将索引节点缓存在MySQL缓存中,而数据缓存依赖于操作系统自身的缓存,所以并不是每次都是走的磁盘,这里只是为了分析索引的使用过程。
在 MyISAM 中,辅助索引和主键索引的结构是一样的,没有任何区别,叶子节点的数据存储的都是行记录的磁盘地址。只是主键索引的键值是唯一的,而辅助索引的键值可以重复。
查询数据时,由于辅助索引的键值不唯一,可能存在多个拥有相同的记录,所以即使是等值查询,也需要按照范围查询的方式在辅助索引树中检索数据。
每个InnoDB表都有一个聚簇索引 ,聚簇索引使用B+树构建,叶子节点存储的数据是整行记录。一般情况下,聚簇索引等同于主键索引,当一个表没有创建主键索引时,InnoDB会自动创建一个ROWID字段来构建聚簇索引。InnoDB创建索引的具体规则如下:
- 在表上定义主键PRIMARY KEY,InnoDB将主键索引用作聚簇索引。
- 如果表没有定义主键,InnoDB会选择第一个不为NULL的唯一索引列用作聚簇索引。
- 如果以上两个都没有,InnoDB 会使用一个6 字节长整型的隐式字段 ROWID字段构建聚簇索引。该ROWID字段会在插入新行时自动递增。
除聚簇索引之外的所有索引都称为辅助索引。在中InnoDB,辅助索引中的叶子节点存储的数据是该行的主键值都。 在检索时,InnoDB使用此主键值在聚簇索引中搜索行记录。
这里以user_innodb为例,user_innodb的id列为主键,age列为普通索引。
CREATE TABLE `user_innodb`( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(20) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_age` (`age`) USING BTREE) ENGINE = InnoDB;
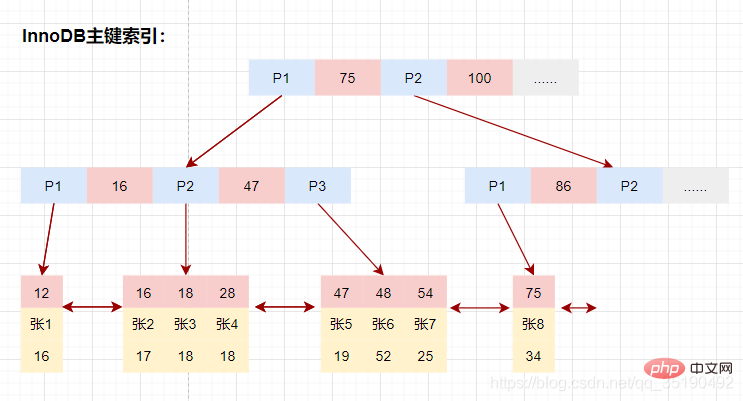
InnoDB的数据和索引存储在一个文件t_user_innodb.ibd中。InnoDB的数据组织方式,是聚簇索引。
主键索引的叶子节点会存储数据行,辅助索引只会存储主键值。
等值查询数据:
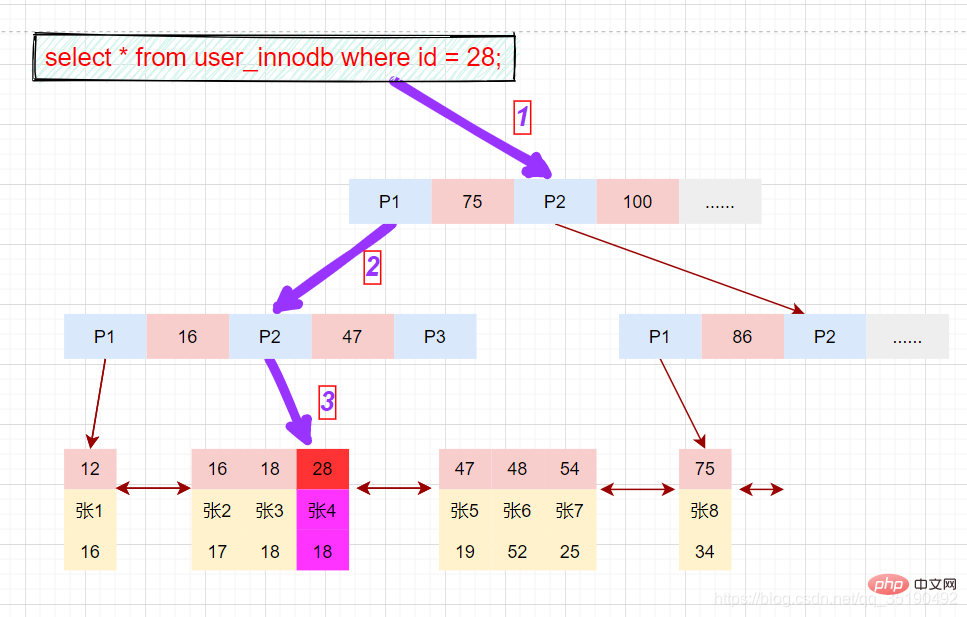
select * from user_innodb where id = 28;
先在主键树中从根节点开始检索,将根节点加载到内存,比较28
将左子树节点加载到内存中,比较16
检索到叶节点,将节点加载到内存中遍历,比较16
磁盘IO数量:3次。
除聚簇索引之外的所有索引都称为辅助索引,InnoDB的辅助索引只会存储主键值而非磁盘地址。
以表user_innodb的age列为例,age索引的索引结果如下图。
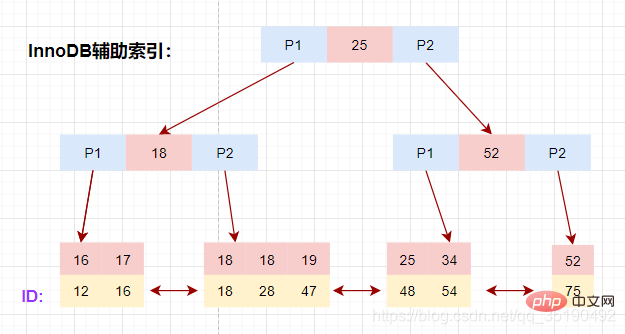
底层叶子节点的按照(age,id)的顺序排序,先按照age列从小到大排序,age列相同时按照id列从小到大排序。
使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后使用主键到主索引中检索获得记录。
画图分析等值查询的情况:
select * from t_user_innodb where age=19;
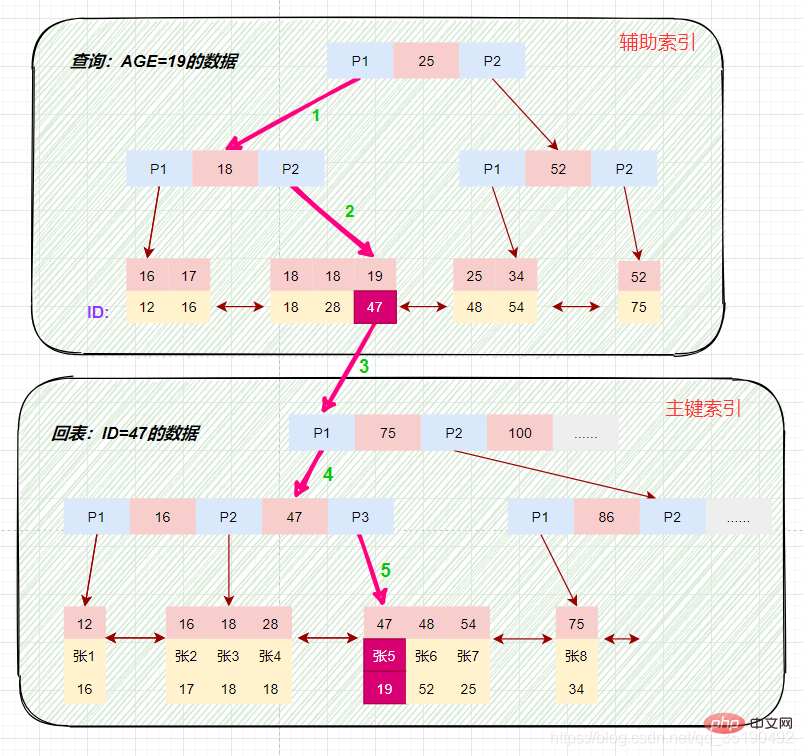
根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。
磁盘IO数:辅助索引3次+获取记录回表3次
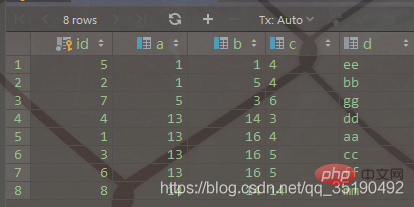
还是以自己创建的一个表为例:表 abc_innodb,id为主键索引,创建了一个联合索引idx_abc(a,b,c)。
CREATE TABLE `abc_innodb`( `id` int(11) NOT NULL AUTO_INCREMENT, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` varchar(10) DEFAULT NULL, `d` varchar(10) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_abc` (`a`, `b`, `c`)) ENGINE = InnoDB;
select * from abc_innodb order by a, b, c, id;
组合索引的数据结构:
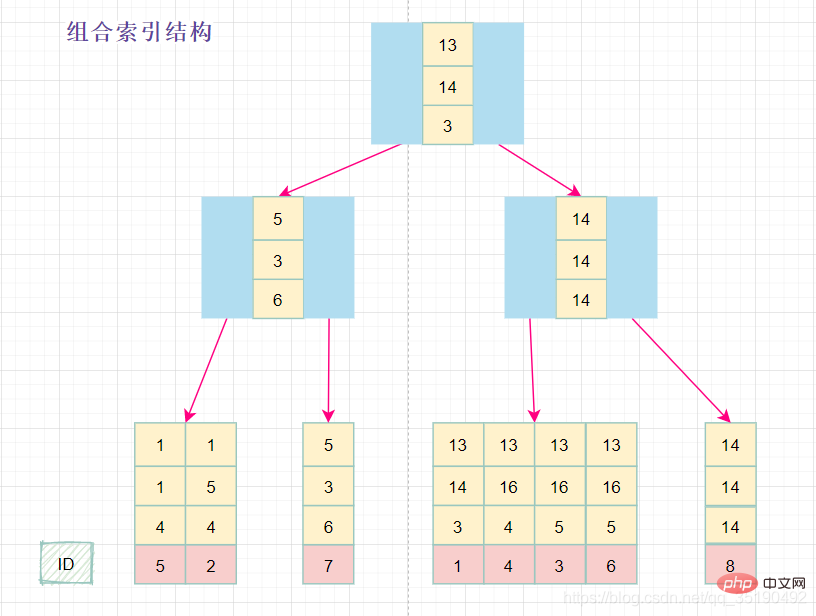
组合索引的查询过程:
select * from abc_innodb where a = 13 and b = 16 and c = 4;
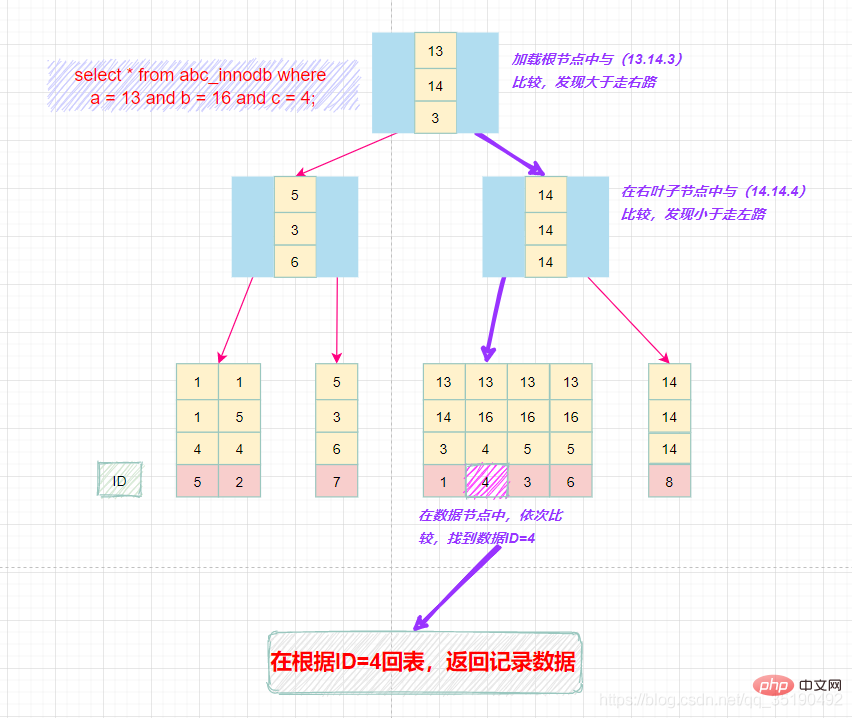
最左匹配原则:
最左前缀匹配原则和联合索引的索引存储结构和检索方式是有关系的。
在组合索引树中,最底层的叶子节点按照第一列a列从左到右递增排列,但是b列和c列是无序的,b列只有在a列值相等的情况下小范围内递增有序,而c列只能在a,b两列相等的情况下小范围内递增有序。
就像上面的查询,B+树会先比较a列来确定下一步应该搜索的方向,往左还是往右。如果a列相同再比较b列。但是如果查询条件没有a列,B+树就不知道第一步应该从哪个节点查起。
可以说创建的idx_abc(a,b,c)索引,相当于创建了(a)、(a,b)(a,b,c)三个索引。、
组合索引的最左前缀匹配原则:使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询(>、
覆盖索引并不是说是索引结构,覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到主键值,相当于获取数据还需要再根据主键查询主键索引再获取到数据。但是试想下这么一种情况,在上面abc_innodb表中的组合索引查询时,如果我只需要abc字段的,那是不是意味着我们查询到组合索引的叶子节点就可以直接返回了,而不需要回表。这种情况就是覆盖索引。
可以看一下执行计划:
覆盖索引的情况:

未使用到覆盖索引:

看到这里,你是不是对于自己的sql语句里面的索引的有了更多优化想法呢。比如:
在InnoDB的存储引擎中,使用辅助索引查询的时候,因为辅助索引叶子节点保存的数据不是当前记录的数据而是当前记录的主键索引,索引如果需要获取当前记录完整数据就必然需要根据主键值从主键索引继续查询。这个过程我们成位回表。想想回表必然是会消耗性能影响性能。那如何避免呢?
使用索引覆盖,举个例子:现有User表(id(PK),name(key),sex,address,hobby…)
シナリオの場合、select id,name,sex from user where name ='zhangsan';このステートメントはビジネスで頻繁に使用されますが、user テーブルの他のフィールドはあまり使用されません。この場合、名前フィールドのインデックスを作成するときに単一のインデックスを使用せず、結合インデックス (名前、性別) を使用すると、このクエリ ステートメントを実行すると、結果は補助インデックスに基づいて取得されますか? ? 現在のステートメントの完全なデータを取得できます。これにより、性別データを取得するためにテーブルに戻ることを効果的に回避できます。
ここでは、カバーインデックスを使用してテーブルの収益を削減する典型的な最適化戦略を示します。
ジョイント インデックス インデックスを作成するときは、ジョイント インデックスが複数の単一列インデックスで使用できるかどうかを判断してください。ジョイントインデックスを使用すると、スペースが節約されるだけでなく、インデックスカバレッジの使用も容易になります。想像してみてください。インデックスが作成されるフィールドが多いほど、クエリによって返されるデータを満たすのが容易になります。たとえば、結合インデックス (a_b_c) は、a、a_b、a_b_c という 3 つのインデックスを持つことに相当します。これによりスペースが節約されますか? もちろん、節約されるスペースは 3 つのインデックス (a、a_b、a_b_c) の 3 倍ではありません。インデックス ツリー内のデータは変更されていませんが、インデックス データ フィールド内のデータは実際に保存されているためです。
結合インデックス作成の原則 結合インデックスを作成するときは、頻繁に使用される列と差別化の高い列を前に配置する必要があります。頻繁に使用されるということは、インデックスの利用率と差別化が高いことを意味します。フィルタリングの粒度が大きい。これらは、インデックスを作成するときに考慮する必要がある最適化シナリオです。クエリとしてよく返されるフィールドも結合インデックスに追加できます。フィールドが結合インデックスに追加され、カバレッジが使用される場合、インデックス、この場合には、ジョイント インデックスを使用することをお勧めします。
結合インデックスの使用
現在のインデックスには、戻りフィールドとして頻繁に使用される列が含まれています。この時点で、クエリ ステートメントでカバー インデックスを使用できるように、現在の列を既存のインデックスに追加できるかどうかを検討できます。 。
[推奨: mysql ビデオ チュートリアル ]
以上がMySQL インデックスのすべてのナレッジポイントを 1 つの記事で理解する (収集することをお勧めします)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



