Oracleのストアドプロシージャとは何ですか

Oracle では、ストアド プロシージャは、特定の関数を完了するために使用される SQL ステートメントのセットです。これらはコンパイルされてデータベースに保存されます。最初のコンパイル後、再度呼び出されたときに再度コンパイルする必要はありません。ユーザーはストアド プロシージャを指定し、ストアド プロシージャを呼び出すための名前とパラメータを指定します。

このチュートリアルの動作環境: Windows 7 システム、Oracle 11g バージョン、Dell G3 コンピューター。
1. ストアド プロシージャとは何ですか?
##) は、大規模な## 内の特定の関数を完了するための のグループです。 # データベース システム SQL ステートメント セットはデータベースに保存されており、最初にコンパイルした後に再度コンパイルする必要はありません。名前はユーザーが指定します。ストアド プロシージャの名前を取得し、パラメータを指定します (ストアド プロシージャにパラメータがある場合)ストアド プロシージャを呼び出します。 簡単に言うと、これは 1 つのことを具体的に実行する SQL ステートメントです。 データベース自体または Java プログラムによって呼び出すことができます。 Oracle データベースのストアド プロシージャはプロシージャです。 2. ストアド プロシージャを作成する理由
1. 高効率 ストアド プロシージャは一度コンパイルされると、データベースに保存され、毎回直接実行されます。と呼ばれた。通常の SQL ステートメントを他の場所 (メモ帳など) に保存したい場合は、実行前に分析してコンパイルする必要があります。したがって、ストアドプロシージャの方が効率的だと思います。 2. ネットワーク トラフィックの削減コンパイルされたストアド プロシージャはデータベースに配置され、リモートで呼び出すときに大量の文字列型 SQL ステートメントを送信しません。 3. 高い再利用性 ストアド プロシージャは特定の関数用に作成されることが多く、この特定の関数を完了する必要がある場合は、ストアド プロシージャを再度呼び出すことができます。 4. 高い保守性機能要件に小さな変更がある場合、以前のストアド プロシージャを変更する方が簡単で、労力もかかりません。 5. 高いセキュリティ特定の機能を完了するストアド プロシージャは、通常、特定のユーザーのみが使用でき、使用 ID 制限があるため、安全性が高まります。 3. ストアド プロシージャの基本1. ストアド プロシージャの構造(1)、基本構造
Oracle
ストアド プロシージャは、処理宣言部、実行処理部、ストアド プロシージャ例外の 3 つの部分で構成されます (記述してもしなくても構いません。スクリプトのフォールト トレランスとデバッグの利便性を高めるために、例外処理を記述します) )
(2)、パラメーターなしストアド プロシージャ
CREATE OR REPLACE PROCEDURE demo AS/IS 变量2 DATE; 变量3 NUMBER; BEGIN --要处理的业务逻辑 EXCEPTION --存储过程异常 END
a. パラメーター付きストアド プロシージャ
CREATE OR REPLACE PROCEDURE 存储过程名称(param1 student.id%TYPE) AS/IS name student.name%TYPE; age number :=20; BEGIN --业务处理..... END
行 1: param1 はパラメータで、型は Student テーブルの ID フィールドと同じです。
行 3: 変数名を宣言します。型は Student テーブルの名前フィールドの型です (上記と同じ)。- 行 4: 変数 age を宣言し、数値を入力し、20 に初期化します
- b. パラメーターと割り当てを含むストアド プロシージャ
CREATE OR REPLACE PROCEDURE 存储过程名称( s_no in varchar, s_name out varchar, s_age number) AS total NUMBER := 0; BEGIN SELECT COUNT(1) INTO total FROM student s WHERE s.age=s_age; dbms_output.put_line('符合该年龄的学生有'||total||'人'); EXCEPTION WHEN too_many_rows THEN DBMS_OUTPUT.PUT_LINE('返回值多于1行'); ENDログイン後にコピー上記のスクリプト: - ##
パラメータ IN は入力パラメータを表し、パラメータのデフォルト モードです。
OUT は戻り値パラメータを表し、その型は Oracle の任意の有効な型を使用できます。
OUT モードで定義されたパラメータは、プロセス本体内でのみ割り当てることができます。つまり、パラメータは、呼び出し元のプロセスに特定の値を渡すことができます。
IN OUT は、パラメータが値をプロセスに渡すことができることを意味します。プロセス、または特定の値をプロセスに渡すことができます。値は渡されます。行 7: クエリ ステートメント。パラメーター s_age をフィルター条件として使用し、 INTO キーワードを使用し、見つかった結果を total 変数に代入します。
# 行 8: クエリ結果を出力します。データベースでは、文字列
# を接続するために「||」が使用されます。 # 行 9 ~ 11: 例外処理
(1)、演算子
ここで、s、m、n は変数、型は数値です;Category
演算子
##意味
式の例
#算術演算子
## #### ########################追加################ #######- マイナス ##s := 3 – 1 ;######################*################## ######かける## mod(,)#s := 2 * 3;
########/########################取り除く###### ##########
モジュラスを取得し、剰余を取得します
#電力
10**2 =100
関係演算子
#=
## は ## に等しい
#s = 2 #< > ; または != または ~=
## は# と等しくありません##s != 2
#<
## は
s 未満です < ; 3
#>
は
##s > 0 ## より大きいです
#<=
##以下 #s <= 9
以上です s >= 1
比較演算子
##LIKE一致は true
##'li' like '%i' true を返す
BETWEEN
1 ~ 3 の範囲内ですか
##2 true を返します
##IN
セット内かどうか
##'x' in ('x','y ') true を返す
##IS NULL
変数が空かどうかを判断する
#論理演算子
#AND
論理 AND
s=3 かつ c は null
##OR #論理 or##s=3 または c が null #############################ない################ ####
その他
:=
s : = 0;
#..
範囲
#1..9、つまり、1 から 2 までの範囲です。 9
#||
##文字列の連結
##'hello'||'world'
(2)、SELECT INTO STATEMENT语句
该语句将select到的结果赋值给一个或多个变量,例如:
CREATE OR REPLACE PROCEDURE DEMO_CDD1 IS s_name VARCHAR2; --学生名称 s_age NUMBER; --学生年龄 s_address VARCHAR2; --学生籍贯 BEGIN --给单个变量赋值 SELECT student_address INTO s_address FROM student where student_grade=100; --给多个变量赋值 SELECT student_name,student_age INTO s_name,s_age FROM student where student_grade=100; --输出成绩为100分的那个学生信息 dbms_output.put_line('姓名:'||s_name||',年龄:'||s_age||',籍贯:'||s_address); END
ログイン後にコピー上面脚本中:
存储过程名称:DEMO_CDD1, student是学生表,要求查出成绩为100分的那个学生的姓名,年龄,籍贯
(3)、选择语句
a、IF..END IF
学生表的sex字段:1-男生;0-女生
IF s_sex=1 THEN dbms_output.put_line('这个学生是男生'); END IF
ログイン後にコピーb、IF..ELSE..END IF
IF s_sex=1 THEN dbms_output.put_line('这个学生是男生'); ELSE dbms_output.put_line('这个学生是女生'); END IF
ログイン後にコピー(4)、循环语句
a、基本循环
LOOP IF 表达式 THEN EXIT; END IF END LOOP;ログイン後にコピーb、while循环
WHILE 表达式 LOOP dbms_output.put_line('haha'); END LOOP;
ログイン後にコピーc、for循环
FOR a in 10 .. 20 LOOP dbms_output.put_line('value of a: ' || a); END LOOP;
ログイン後にコピー(5)、游标
Oracle会创建一个存储区域,被称为上下文区域,用于处理SQL语句,其中包含需要处理的语句,例如所有的信息,行数处理,等等。
游标是指向这一上下文的区域。 PL/SQL通过控制光标在上下文区域。游标持有的行(一个或多个)由SQL语句返回。行集合光标保持的被称为活动集合。
a、下表是常用的游标属性:
属性
描述
%FOUND
如果DML语句执行后影响有数据被更新或DQL查到了结果,返回true。否则,返回false。
%NOTFOUND
如果DML语句执行后影响有数据被更新或DQL查到了结果,返回false。否则,返回true。
%ISOPEN
游标打开时返回true,反之,返回false。
%ROWCOUNT
返回DML执行后影响的行数。
b、使用游标
声明游标定义游标的名称和相关的SELECT语句:
CURSOR cur_cdd IS SELECT s_id, s_name FROM student;
ログイン後にコピー打开游标游标分配内存,使得它准备取的SQL语句转换成它返回的行:
OPEN cur_cdd;
ログイン後にコピー抓取游标中的数据,可用LIMIT关键字来限制条数,如果没有默认每次抓取一条:
FETCH cur_cdd INTO id, name ;
ログイン後にコピー关闭游标来释放分配的内存:
CLOSE cur_cdd;
ログイン後にコピー3、pl/sql处理存储过程
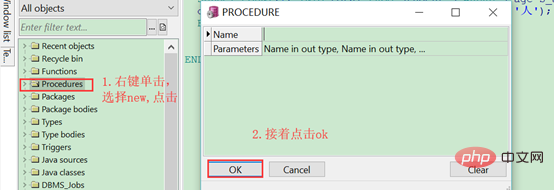
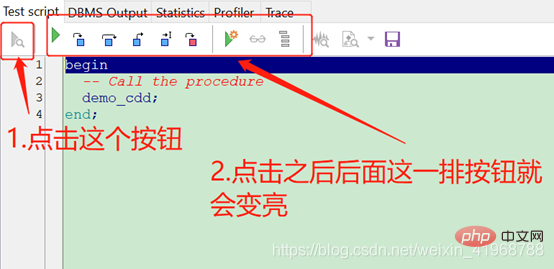
(1)、新建存储过程:右键procedures,点击new,弹出PROCEDURE框,再点击OK,如下图:

(2)、在下面的编辑区,编写存储过程脚本
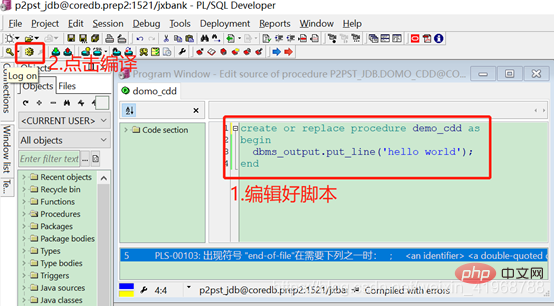
(3)、在这里我们编写一个demo_cdd存储过程,要求输出“hello world”,如下图:
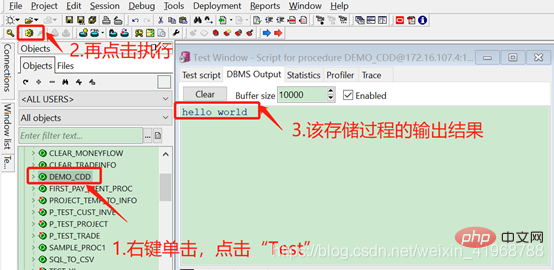
(4)、右键刚才新建的存储过程名称,点击“Test”,在点击执行按钮
4.案例实战
场景:
有表student(s_no, s_name, s_age, s_grade),其中s_no-学号,也是主键,是从1开始向上排的(例如:第一个学生学号是1,第二个是2,一次类推);s_name-学生姓名;s_age-学生年龄;s_grade-年级;这张表的数据量有几千万甚至上亿。一个学年结束了,我要让这些学生全部升一年级,即,让s_grade字段加1。
这条sql,写出来如下:
update student set s_grade=s_grade+1
ログイン後にコピー分析:
如果我们直接运行运行这条sql,因数据量太大会把数据库undo表空间撑爆,从而发生异常。那我们来写个存储过程,进行批量更新,我们每10万条提交一次。
CREATE OR REPLACE PROCEDURE process_student is total NUMBER := 0; i NUMBER := 0; BEGIN SELECT COUNT(1) INTO total FROM student; WHILE i<=total LOOP UPDATE student SET grade=grade+1 WHERE s_no=i; i := i + 1; IF i >= 100000 THEN COMMIT; END IF; END LOOP; dbms_output.put_line('finished!'); END;ログイン後にコピー上面案例中存在问题,应粉丝要求,把改后的案例sql更新到原文中,如下案例,方便大家阅读。
CREATE OR REPLACE PROCEDURE process_student is total NUMBER := 0; i NUMBER := 0; BEGIN SELECT COUNT(1) INTO total FROM student; WHILE i<=total LOOP UPDATE student SET grade=grade+1 WHERE s_no=i; i := i + 1; IF mod(i,100000) = 0 THEN -- 每10万条提交一次 COMMIT; END IF; END LOOP; COMMIT; -- 最后一批不够10万条的提交一次 dbms_output.put_line('finished!'); END;ログイン後にコピー四、存储过程进阶
在上面的案例中,我们的存储过程处理完所有数据要多长时间呢?事实我没有等到它执行完,在我可接受的时间范围内它没有完成。那么对于处理这种千万级数据量的情况,存储过程是不是束手无策呢?答案是否定的,接下来我们看看其他绝招。
我们先来分析下执行过程的执行过程:一个存储过程编译后,在一条语句一条语句的执行时,如果遇到pl/sql语句就拿去给pl/sql引擎执行,如果遇到sql语句就送到sql引擎执行,然后把执行结果再返回给pl/sql引擎。遇到一个大数据量的更新,则执行焦点(正在执行的,状态处于ACTIVE)会不断的来回切换。
Pl/SQL与SQL引擎之间的通信则称之为上下文切换,过多的上下文切换将带来过量的性能负载。最终导致效率降低,处理速度缓慢。
从Oracle8i开始PL/SQL引入了两个新的数据操纵语句:FORALL、BUIK COLLECT,这些语句大大滴减少了上下文切换次数(一次切换多次执行),同时提高DML性能,因此运用了这些语句的存储过程在处理大量数据时速度简直和飞一样。
1、BUIK COLLECT
Oracle8i中首次引入了Bulk Collect特性,Bulk Collect会能进行批量检索,会将检索结果结果一次性绑定到一个集合变量中,而不是通过游标cursor一条一条的检索处理。可以在SELECT INTO、FETCH INTO、RETURNING INTO语句中使用BULK COLLECT,接下来我们一起看看这些语句中是如何使用BULK COLLECT的。
(1)、SELECT INTO
查出来一个结果集合赋值给一个集合变量。
语法结构是:
SELECT field BULK COLLECT INTO var_conllect FROM table where colStatement;
ログイン後にコピー说明:
field:要查询的字段,可以是一个或多个(要保证和后面的集合变量要向对应)。
var_collect:集合变量(联合数组等),用来存放查到的结果。
table:表名,要查询的表。
colStatement:后面过滤条件语句。比如s_age < 10;
例子:查出年龄小于10岁的学生姓名赋值给数组arr_name变量
SELECT s_name BULK COLLECT INTO arr_name FROM s_age < 10;
ログイン後にコピー(2)、FETCH INTO
从一个集合中抓取一部分数据赋值给一个集合变量。
语法结构如下:
FETCH cur1 BULK COLLECT INTO var_collect [LIMIT rows]
ログイン後にコピー说明:
cur1:是个数据集合,例如是个游标。
var_collect:含义同上。
[LIMIT rows]:可有可无,限制每次抓取的数据量。不写的话,默认每次一条数据。
例子:给年龄小于10岁的学生的年级降一级。
--查询年龄小于10岁的学生的学号放在游标cur_no里 CURSOR cur_no IS SELECT s_no FROM student WHERE s_age < 10; --声明了一个联合数组类型,元素类型和游标cur_no每个元素的类型一致 TYPE ARR_NO IS VARRAY(10) OF cur_no%ROWTYPE; --声明一个该数组类型的变量no no ARR_NO; BEGIN FETCH cur_no BULK COLLECT INTO no LIMIT 100; FORALL i IN 1..no.count SAVE EXCEPTONS UPDATE student SET s_grade=s_grade-1 WHERE no(i); END;
ログイン後にコピー说明:先查出年龄小于10岁的学生的学号放在游标里,再每次从游标里拿出100个学号,进行更新,给他们的年级降一级。
(3)、RETURNING
BULK COLLECT除了与SELECT,FETCH进行批量绑定之外,还可以与INSERT,DELETE,UPDATE语句结合使用,可以返回这些DML语句执行后所影响的记录内容(某些字段)。
再看一眼学生表的字段情况:student(s_no, s_name, s_age, s_grade)
语法结构如下:
DMLStatement RETURNING field BULK COLLECT INTO var_field;ログイン後にコピー说明:
DMLStatement:是一个DML语句。
field:是这个表的某个字段,当然也可以写多个逗号隔开(field1,field2, field3)。
var_field:一个类型为该字段类型的集合,多个的话用逗号隔开,如下:
(var_field1, var_field2, var_field3)
例子:获取那些因为年龄小于10岁而年级被将一级的学生的姓名集合。
TYPE NAME_COLLECT IS TABLE OF student.s_name%TYPE; names NAME_COLLECT; BEGIN UPDATE student SET s_grade=s_grade-1 WHERE s_age < 10 RETURNING s_name BULK COLLECT INTO names; END;
ログイン後にコピー说明:
NAME_COLLECT:是一个集合类型,类型是student表的name字段的类型。
names:定义了一个NAME_COLLECT类型的变量。
(4)、注意事项
a.不能对使用字符串类型作键的关联数组使用BULK COLLECT 子句。
b.只能在服务器端的程序中使用BULK COLLECT,如果在客户端使用,就会产生一个不支持这个特性的错误。
c.BULK COLLECT INTO 的目标对象必须是集合类型。
d.复合目标(如对象类型)不能在RETURNING INTO 子句中使用。
e.如果有多个隐式的数据类型转换的情况存在,多重复合目标就不能在BULK COLLECT INTO 子句中使用。
f.如果有一个隐式的数据类型转换,复合目标的集合(如对象类型集合)就不能用于BULK COLLECTINTO 子句中。
2、FORALL
(1)、语法
FORALL index IN bounds [SAVE EXCEPTIONS] sqlStatement;ログイン後にコピー说明:
index是指下标;
bounds是一个边界,形式是start..end
[SAVE EXCEPTIONS] 可写可不写,这个下面介绍;
sqlStatement是一个DML语句,这里有且仅有一个sql语句;
例子:
--例子1:移除年级是5到10之间的学生 FORALL i IN 5..10 DELETE FROM student where s_grade=i;ログイン後にコピー--例子:2,arr是一个数组,存着要升高一年级的学生名称 FORALL s IN 1..arr.count SAVE EXCEPTIONS UPDATE student SET s_grade=s_grade+1 WHERE s_name=arr(i);ログイン後にコピー(2)、SAVE EXCEPTIONS
通常情况写我们在执行DML语句时,可能会遇到异常,可能致使某个语句或整个事务回滚。如果我们写FORALL语句时没有用SAVE EXCEPTIONS语句,那么DML语句会在执行到一半的时候停下来。
如果我们的FORALL语句后使用了SAVE EXCEPTIONS语句,当在执行过程中如果遇到异常,数据处理会继续向下进行,发生的异常信息会保存到SQL%BULK_EXCEPTONS的游标属性中,该游标属性是个记录集合,每条记录有两个字段,例如:(1, 02300);
ERROR_INDEX:该字段会存储发生异常的FORALL语句的迭代编号;
ERROR_CODE:存储对应异常的,oracle错误代码;
SQL%BULK_EXCEPTONS这个异常信息总是存储着最近一次执行的FORALL语句可能发生的异常。而这个异常记录集合异常的个数则由它的COUNT属性表示,即:
SQL%BULK_EXCEPTONS.COUNT,SQL%BULK_EXCEPTIONS有效的下标索引范围在1到%BULK_EXCEPTIONS.COUNT之间。
(3)、INDICES OF
在Oracle数据库10g之前有一个重要的限制,该数据库从IN范围子句中的第一行到最后一行,依次读取集合的内容,如果在该范围内遇到一个未定义的行,Oracle数据库将引发ORA-22160异常事件:ORA-22160: element at index [N] does not exist。针对这一问题,Oracle后续又提供了两个新语句:INDICES OF 和 VALUES OF。
接下来我们来看看这个INDICES OF语句,用于处理稀疏数组或包含有间隙的数组(例如:一个集合的某些元素被删除了)。
该语句语法结构是:
FORALL i INDICES OF collection [SAVE EXCEPTIONS] sqlStatement;ログイン後にコピー说明:
i:集合(嵌套表或联合数组)下标。
collection:是这个集合。
[SAVE EXCEPTIONS]和sqlStatement上面已经解释过。
例子:arr_std是一个联合数组,每个元素包含(name,age,grade),现在要向student表插入数据。
FORALL i IN INDICES OF arr_stu INSERT INTO student VALUES( arr_stu(i).name, arr_stu(i).age, arr_stu(i).grade );ログイン後にコピー(4)、VALUES OF
VALUES OF适用情况:绑定数组可以是稀疏数组,也可以不是,但我只想使用该数组中元素的一个子集。VALUES OF选项可以指定FORALL语句中循环计数器的值来自于指定集合中元素的值。但是,VALUES OF在使用时有一些限制:
如果VALUES OF子句中所使用的集合是联合数组,则必须使用PLS_INTEGER和BINARY_INTEGER进行索引,VALUES OF 子句中所使用的元素必须是PLS_INTEGER或BINARY_INTEGER;
当VALUES OF 子句所引用的集合为空,则FORALL语句会导致异常;
该语句的语法结构是:
FORALL i IN VALUES OF collection [SAVE EXCEPTIONS] sqlStatement;ログイン後にコピー说明:i和collection含义如上
联合数组请看文章(或自行百度):PL/SQL 联合数组与嵌套表_乐沙弥的世界-CSDN博客
3、pl/sql调试存储过程
首先,当前这个用户得有能调试存储过程的权限,如果没有的话,以数据库管理员身份给你这个用户授权:
--userName是你要拿到调试存储过程权限的用户名 GRANT DEBUG ANY PROCEDURE,DEBUG CONNECT SESSION TO username;
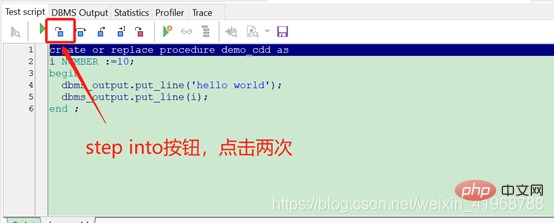
ログイン後にコピー(1)、右键一个存储过程名称,点击测试,如下图:
这里我用的pl/sql是12.0.4版本的,下面截图中与低版本的pl/sql按钮位置都相同,只是图标不一样。
(2).点击两次step into按钮,进入语句调试,如下图:
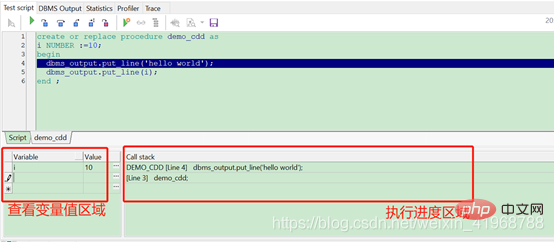
(3).每点击一次step into按钮,会想下执行一条语句,也可以查看变量和表达式的值,如下图:
查看变量值:在查看变量区域,在Variable列输入变量i,在Value列点击下,该变量的值就显示出来了。
4、案例实战
场景和上面的案例实战是同一个,如下:
有表student(s_no, s_name, s_age, s_grade),其中s_no-学号,也是主键,是从1开始向上排的(例如:第一个学生学号是1,第二个是2,一次类推);s_name-学生姓名;s_age-学生年龄;s_grade-年级;这张表的数据量有几千万甚至上亿。一个学年结束了,我要让这些学生全部升一年级,即,让s_grade字段加1。
这条sql,写出来如下:
update student set s_grade=s_grade+1
编写存储过程:
(1)、存储过程1
名称为:process_student1,student表的s_no字段类型为varchar2(16)。
CREATE OR REPLACE PROCEDURE process_student1 AS CURSOR CUR_STUDENT IS SELECT s_no FROM student; TYPE REC_STUDENT IS VARRAY(100000) OF VARCHAR2(16); students REC_STUDENT; BEGIN OPEN CUR_STUDENT; WHILE (TRUE) LOOP FETCH CUR_STUDENT BULK COLLECT INTO students LIMIT 100000; FORALL i IN 1..students.count SAVE EXCEPTIONS UPDATE student SET s_grade=s_grade+1 WHERE s_no=students(i); COMMIT; EXIT WHEN CUR_STUDENT%NOTFOUND OR CUR_STUDENT%NOTFOUND IS NULL; END LOO; dbms_output.put_line('finished'); END;ログイン後にコピー说明:
把student表中要更新的记录的学号拿出来放在游标CUR_STUDENT,每次从这个游标里抓取10万条数据赋值给数组students,每次更新这10万条记录。循环进行直到游标里的数据全部抓取完。
FETCH .. BULK COLLECT INTO .. LIMIT rows语句中:这个rows我测试目前最大可以为10万条。
(2)、存储过程2(ROWID)
如果我们这个student表没有主键,也没有索引呢,该怎么来做呢?
分析下:
ROWNUM是伪列,每次获取结果后,然后在结果集里会产生一列,从1开始排,每次都是从1开始排。
ROWID在每个表中,每条记录的ROWID都是唯一的。在这种情况下,我们可以用ROWID。但要注意的是,ROWID是一个类型,注意它和VARCHAR2之间的转换。有两个方法:ROWIDTOCHAR()是把ROWID类型转换为CHAR类型;CHARTOROWID()是把CAHR类型转换为ROWID类型。
接下来我们编写存储过程process_student2,脚本如下:
CREATE OR REPLACE PROCEDURE process_student1 AS CURSOR CUR_STUDENT IS SELECT ROWIDTOCHAR(ROWID) FROM student; TYPE REC_STUDENT IS VARRAY(100000) OF VARCHAR2(16); students REC_STUDENT; BEGIN OPEN CUR_STUDENT; WHILE (TRUE) LOOP FETCH CUR_STUDENT BULK COLLECT INTO students LIMIT 100000; FORALL i IN 1..students.count SAVE EXCEPTIONS UPDATE student SET s_grade=s_grade+1 WHERE ROWID=CHARTOROWID(students(i)); COMMIT; EXIT WHEN CUR_STUDENT%NOTFOUND OR CUR_STUDENT%NOTFOUND IS NULL; END LOO; dbms_output.put_line('finished'); END;ログイン後にコピー说明:
我们首先查到记录的ROWID并把它转换为CHAR类型,存放到游标CUR_STUDENT里,
再每次抓取10万条数据赋值给数组进行更新,更新语句的WHERE条件时,又把数组元素是CAHR类型的rowid串转换为ROWID类型。
推荐教程:《Oracle教程》
以上がOracleのストアドプロシージャとは何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
このウェブサイトの声明この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。
ホットAIツール
Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ
AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。
Undress AI Tool
脱衣画像を無料で
Clothoff.io
AI衣類リムーバー
AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
R.E.P.O.説明されたエネルギー結晶と彼らが何をするか(黄色のクリスタル)1 か月前 By 尊渡假赌尊渡假赌尊渡假赌R.E.P.O.最高のグラフィック設定1 か月前 By 尊渡假赌尊渡假赌尊渡假赌アサシンのクリードシャドウズ:シーシェルリドルソリューション3週間前 By DDDWindows11 KB5054979の新しいものと更新の問題を修正する方法2週間前 By DDDWill R.E.P.O.クロスプレイがありますか?1 か月前 By 尊渡假赌尊渡假赌尊渡假赌
ホットツール
メモ帳++7.3.1
使いやすく無料のコードエディター
SublimeText3 中国語版
中国語版、とても使いやすい
ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境
ドリームウィーバー CS6
ビジュアル Web 開発ツール
SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
Gmailメールのログイン入り口はどこですか? 7552
7552
 15
CakePHP チュートリアル
1382
52
Steamのアカウント名の形式は何ですか
83
11
NYTの接続はヒントと回答です
22
95
See all articles
Oracleの表空間サイズを確認する方法
Apr 11, 2025 pm 08:15 PM
15
CakePHP チュートリアル
1382
52
Steamのアカウント名の形式は何ですか
83
11
NYTの接続はヒントと回答です
22
95
See all articles
Oracleの表空間サイズを確認する方法
Apr 11, 2025 pm 08:15 PM
Oracle Tablespaceサイズを照会するには、次の手順に従ってください。クエリを実行して、TableSpace名を決定します。DBA_TABLESPACesからTableSpace_Nameを選択します。クエリを実行してテーブルスペースのサイズをクエリします:sum(bytes)をtotal_size、sum(bytes_free)asavail_space、sum(bytes) - sum(bytes_free)as sum(bytes_free)as dba_data_files from tablespace_
オラクルで時間を取得する方法
Apr 11, 2025 pm 08:09 PM
Oracleで時間を取得するには、次の方法があります。Current_Timestamp:現在のシステム時間を秒に正確に返します。 systimestamp:current_timestampよりも正確で、ナノ秒。 sysdate:時間部分を除く現在のシステム日付を返します。 to_char(sysdate、 'yyy-mm-dd hh24:mi:ss'):現在のシステムの日付と時刻を特定の形式に変換します。抽出:1年、月、時間など、時間の値から特定の部分を抽出します。
Oracleのインスタンス名を表示する方法
Apr 11, 2025 pm 08:18 PM
Oracleでインスタンス名を表示するには3つの方法があります。「sqlplus」と「v $ instanceからselect instance_name;」を使用します。」コマンドラインのコマンド。 「show instance_name;」を使用しますSQL*Plusのコマンド。オペレーティングシステムのタスクマネージャー、Oracle Enterprise Manager、またはオペレーティングシステムを介して、環境変数(LinuxのOracle_Sid)を確認してください。
Oracleビューを暗号化する方法
Apr 11, 2025 pm 08:30 PM
Oracle View暗号化により、ビュー内のデータを暗号化でき、それにより機密情報のセキュリティが強化されます。手順には以下が含まれます。1)マスター暗号化キー(MEK)の作成。 2)暗号化されたビューを作成し、暗号化されるビューとMEKを指定します。 3)暗号化されたビューにアクセスすることをユーザーに許可します。暗号化されたビューがどのように機能するか:ユーザーが暗号化されたビューを求めてクエリをするとき、OracleはMEKを使用してデータを復号化し、認定ユーザーのみが読み取り可能なデータにアクセスできるようにします。
Oracleのインストールをアンインストールする方法は失敗しました
Apr 11, 2025 pm 08:24 PM
Oracleインストール障害のためのアンインストールメソッド:Oracleサービスを閉じ、Oracleプログラムファイルとレジストリキーを削除し、Oracle環境変数をアンインストールし、コンピューターを再起動します。アンインストールが失敗した場合、Oracle Universal Uninstallツールを使用して手動でアンインストールできます。
無効な数のOracleを確認する方法
Apr 11, 2025 pm 08:27 PM
Oracle無効な数値誤差は、データ型の不一致、数値オーバーフロー、データ変換エラー、またはデータの破損によって引き起こされる場合があります。トラブルシューティング手順には、データ型のチェック、デジタルオーバーフローの検出、データ変換のチェック、データの破損のチェック、nls_numeric_charactersパラメーターの構成、データ検証ロギングの有効化など、他の可能なソリューションの調査が含まれます。
Oracleのユーザーをセットアップする方法
Apr 11, 2025 pm 08:21 PM
Oracleでユーザーを作成するには、次の手順に従ってください。Createユーザーステートメントを使用して新しいユーザーを作成します。助成金ステートメントを使用して必要な権限を付与します。オプション:リソースステートメントを使用してクォータを設定します。デフォルトの役割や一時テーブルスペースなど、他のオプションを構成します。
Oracle Cursorを閉じる問題を解決する方法
Apr 11, 2025 pm 10:18 PM
Oracle Cursorの閉鎖問題を解決する方法には、次のものが含まれます。 Scopeが終了した後に自動的に閉じるように、for update句のカーソルを宣言します。使用句のカーソルを宣言して、関連するPL/SQL変数が閉じられたときに自動的に閉じるようにします。例外処理を使用して、例外の状況でカーソルが閉じていることを確認します。接続プールを使用して、カーソルを自動的に閉じます。自動送信を無効にし、カーソルの閉鎖を遅延させます。