

mysqlのインデックス作成スキル(サマリー共有)を完全マスター

この記事では、mysql の論理構造や SQL 実行ステートメントなど、mysql インデックスに関する関連知識を提供します。

1. MySQL の 3 層論理アーキテクチャ
MySQL のストレージ エンジン アーキテクチャは、クエリ処理をデータの保存/取得から分離します。以下は MySQL の論理アーキテクチャ図です:

1. 最初の層は接続管理、認可認証、セキュリティなどを担当します。
各クライアント接続はサーバー上のスレッドに対応します。スレッド プールは、接続ごとにスレッドが作成および破棄されることを避けるために、サーバー上で維持されます。クライアントが MySQL サーバーに接続すると、サーバーはクライアントを認証します。認証は、ユーザー名とパスワード、または SSL 証明書を通じて実行できます。ログイン認証に合格した後、サーバーはクライアントに特定のクエリを実行する権限があるかどうかも検証します。
2. 2 番目の層は、クエリの解析を担当します。
SQL のコンパイルと最適化 (テーブルの読み取り順序の調整、適切なインデックスの選択など) 。)。 SELECT ステートメントの場合、クエリを解析する前に、サーバーはまずクエリ キャッシュをチェックします。対応するクエリ結果がその中に見つかった場合、クエリの解析や最適化などを必要とせずに、クエリ結果が直接返されます。ストアド プロシージャ、トリガー、ビューなどはすべてこの層に実装されます。
3. 3 番目の層はストレージ エンジンです。
ストレージ エンジンは、MySQL へのデータの保存、データの抽出、トランザクションの開始などを担当します。ストレージ エンジンは、API を介して上位層と通信します。これらの API は、異なるストレージ エンジン間の差異を保護し、上位層のクエリ プロセスに対してこれらの差異を透過的にします。ストレージ エンジンは SQL を解析しません。
2. InnoDB と MyISAM の比較
1. ストレージ構造
MyISAM: 各 MyISAM はディスク上の 3 つのファイルに保存されます。それらは、テーブル定義ファイル、データ ファイル、インデックス ファイルです。最初のファイルの名前はテーブルの名前で始まり、拡張子はファイルの種類を示します。 .frm ファイルにはテーブル定義が保存されます。データ ファイルの拡張子は .MYD (MYData) です。インデックスファイルの拡張子は.MYI(MYIndex)です。
InnoDB: すべてのテーブルは同じデータ ファイル (または複数のファイル、または独立したテーブル スペース ファイル) に保存されます。InnoDB テーブルのサイズは、オペレーティング システム ファイルのサイズによってのみ制限されます。通常は 2GB。
2. ストレージ スペース
MyISAM: MyISAM は 3 つの異なるストレージ形式をサポートしています: 静的テーブル (デフォルト。ただし、データの末尾にスペースを含めることはできないことに注意してください)削除されます)、動的テーブル、圧縮テーブル。テーブルが作成され、データがインポートされた後は、変更操作は実行されません。圧縮テーブルを使用すると、ディスク領域の使用量を大幅に削減できます。
InnoDB: より多くのメモリとストレージが必要です。データとインデックスをキャッシュするためにメイン メモリ内に独自の専用バッファ プールを確立します。
3. 移植性、バックアップ、リカバリ
MyISAM: データはファイルの形式で保存されるため、クロスプラットフォームのデータ転送に非常に便利です。バックアップおよびリカバリ中にテーブルに対して個別に操作を実行できます。
InnoDB: 無料のソリューションには、データ ファイルのコピー、binlog のバックアップ、または mysqldump の使用が含まれますが、データ ボリュームが数十 GB に達すると比較的困難になります。
4. トランザクション サポート
MyISAM: パフォーマンスに重点を置いています。各クエリはアトミックであり、その実行時間は InnoDB タイプよりも高速ですが、取引のサポートも致します。
InnoDB: トランザクション サポート、外部キー、その他の高度なデータベース機能を提供します。トランザクション (コミット)、ロールバック (ロールバック)、およびクラッシュ回復機能を備えたトランザクションセーフ (ACID 準拠) テーブル。
5. AUTO_INCREMENT
MyISAM: 他のフィールドとの結合インデックスを作成できます。エンジンの自動拡張列はインデックスである必要があります。結合インデックスの場合、自動拡張列は最初の列である必要はありません。前の列に従って並べ替えてから増分できます。
InnoDB: InnoDB には、このフィールドのみを含むインデックスが含まれている必要があります。エンジンの自動拡張列はインデックスである必要があり、それが複合インデックスの場合は、複合インデックスの最初の列でもある必要があります。
6. テーブル ロックの違い
MyISAM: テーブル レベルのロックのみがサポートされており、ユーザーが myisam テーブルを操作する場合、select、update、delete、insert ステートメントはすべてサポートされます。ロックすると、ロックされたテーブルが挿入同時実行性を満たしている場合、テーブルの最後に新しいデータを挿入できます。
InnoDB: トランザクションと行レベルのロックのサポートは、innodb の最大の機能です。行ロックにより、マルチユーザーの同時操作のパフォーマンスが大幅に向上します。ただし、InnoDB の行ロックは WHERE の主キーに対してのみ有効であり、主キー以外の WHERE はテーブル全体をロックします。
7. フルテキスト インデックス
MyISAM: FULLTEXT 型のフルテキスト インデックスをサポートします
InnoDB: FULLTEXT 型のフルテキスト インデックスをサポートしません、ただし innodb は使用できます。 sphinx プラグインは全文インデックス作成をサポートしており、効果はより優れています。
8. テーブルの主キー
MyISAM: インデックスと主キーのないテーブルの存在を許可します。インデックスは行が保存されるアドレスです。
InnoDB: 主キーまたは空でない一意のインデックスが設定されていない場合、6 バイトの主キー (ユーザーには表示されません) が自動的に生成されます。データは主インデックスの一部であり、追加のインデックスにより保存されます。プライマリインデックスの値。
9. テーブル内の特定の行数
MyISAM: テーブル内の総行数を保存します。テーブル; 直接取り出されます。
InnoDB: テーブル内の総行数は保存されません。select count(*) from table を使用すると、テーブル全体を走査することになり、大量のコストがかかります。 wehre 条件を追加した後、myisam と innodb がそれを処理します。10. CRUD 操作
MyISAM: 多数の SELECT を実行する場合は、MyISAM の方が良い選択です。 InnoDB: データで大量の INSERT または UPDATE が実行される場合は、パフォーマンス上の理由から InnoDB テーブルを使用する必要があります。11. 外部キー
MyISAM: サポートされていませんInnoDB: サポートされています 3. SQL 最適化の概要1. SQL の最適化はどのような状況で実行する必要がありますか?
パフォーマンスが低い、実行時間が長すぎる、待ち時間が長すぎる、接続クエリ、およびインデックスの失敗。2. SQL文実行処理
(1) 書き込み処理select distinct ... from ... join ... on ... where ... group by ... having ... order by ... limit ...
from ... on ... join ... where ... group by ... having ... select distinct ... order by ... limit ...
3. SQL の最適化はインデックスを最適化することです
インデックスは本の目次に相当します。 インデックスのデータ構造は B ツリーです。 4. インデックス1. インデックスのメリット
(1) クエリ効率の向上 (IO 使用量の削減) ( 2) CPU 使用率を削減します。たとえば、年齢記述による順序をクエリする場合、B インデックス ツリー自体がソートされているため、クエリによってインデックスがトリガーされた場合、再度クエリを実行する必要はありません。2. インデックスの欠点
(1) インデックス自体は大きく、メモリまたはハードディスク (通常はハードディスク) に保存できます。 (2) インデックスは、①データ量が少ない、②頻繁に変更されるフィールド、③ほとんど使用されないフィールドなど、すべての状況で使用されるわけではありません。 (3) インデックスは追加の効率を低下させます。削除と変更
3. インデックス分類
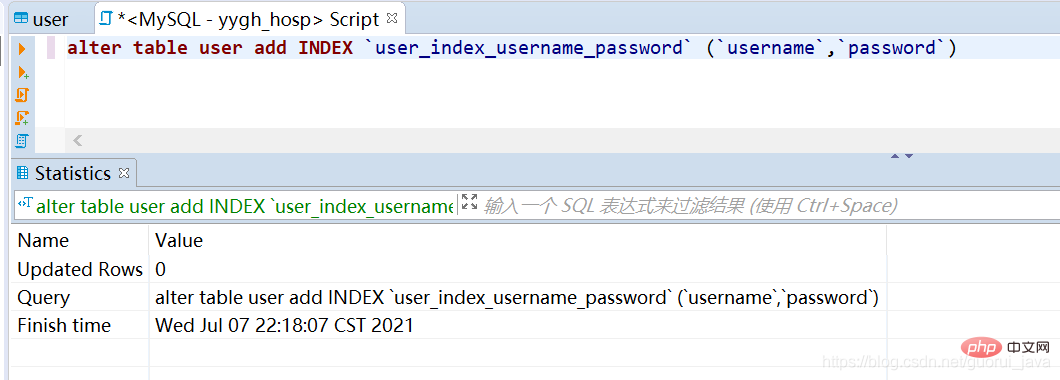
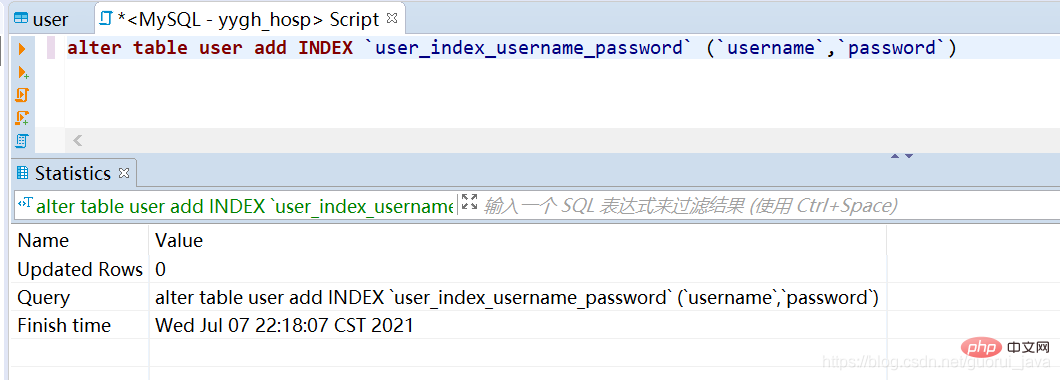
(1) 単一値インデックス(2) 一意のインデックス(3) ) ユニオン インデックス(4) 主キー インデックス注: 一意インデックスと主キー インデックスの唯一の違い: 主キー インデックスを null にすることはできません4 .インデックスの作成 alter table user add INDEX `user_index_username_password` (`username`,`password`)
ログイン後にコピー
alter table user add INDEX `user_index_username_password` (`username`,`password`)
すべてのリーフ ノード間にリンク ポインタがあります。
データ レコードはリーフ ノードに保存されます。
前節でB-Treeを最適化します。B Treeの非リーフノードはキー値情報のみを格納するため、各ディスクブロックに4つのキー値とポインタ情報を格納できると仮定すると、 の構造になります。 B ツリー: 以下の図に示すように:
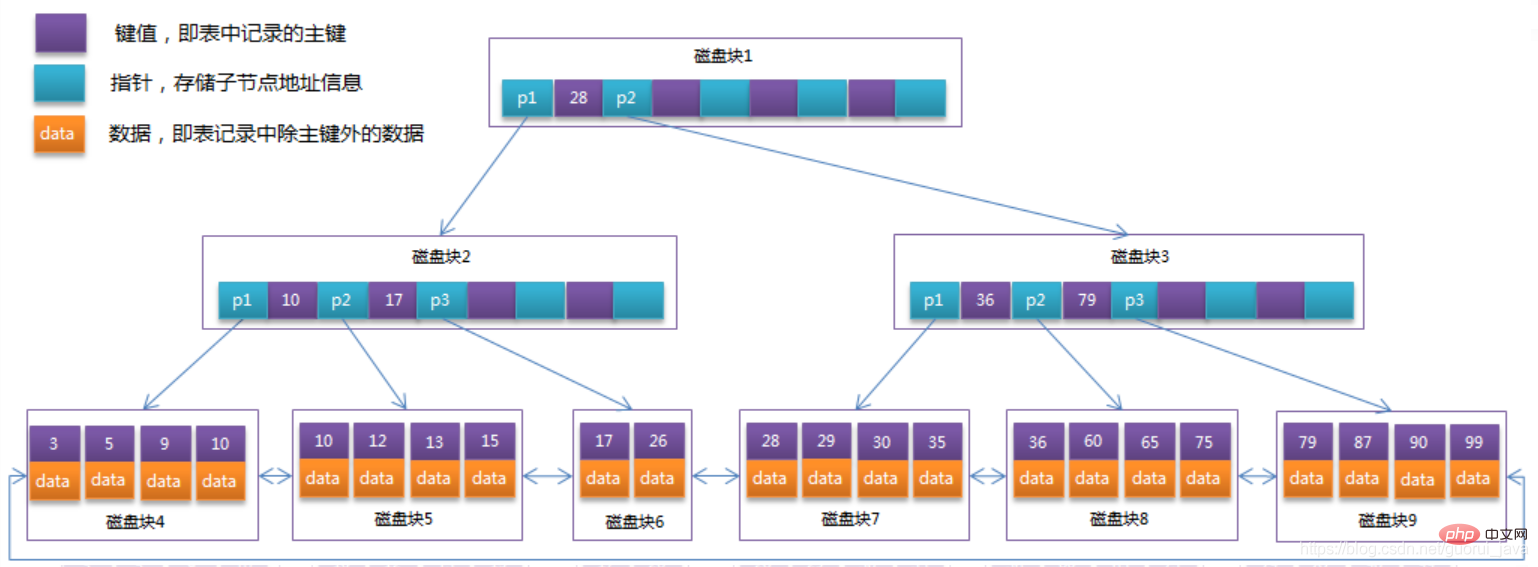
データベース内の B ツリー インデックスは、クラスター化インデックスとセカンダリ インデックスに分けることができます。上記の B ツリーの例の図は、クラスター化インデックスとしてデータベースに実装されており、クラスター化インデックスの B ツリー内のリーフ ノードには、テーブル全体の行レコード データが格納されます。補助インデックスとクラスター化インデックスの違いは、補助インデックスのリーフ ノードには行レコードのすべてのデータが含まれるのではなく、対応する行データを格納するクラスター化インデックス キー、つまり主キーが含まれることです。セカンダリ インデックスを通じてデータをクエリする場合、InnoDB ストレージ エンジンはセカンダリ インデックスを走査して主キーを見つけ、その後主キーを通じてクラスター化インデックス内の完全な行レコード データを見つけます。
5. ジョイント インデックスをトリガーする方法
1. ユーザー テーブルのユーザー名、パスワード
2 にジョイント インデックスを作成します。ジョイント インデックスのトリガー
(1) ジョイント インデックスのすべてのインデックス キーを使用すると、ジョイント インデックスをトリガーできます
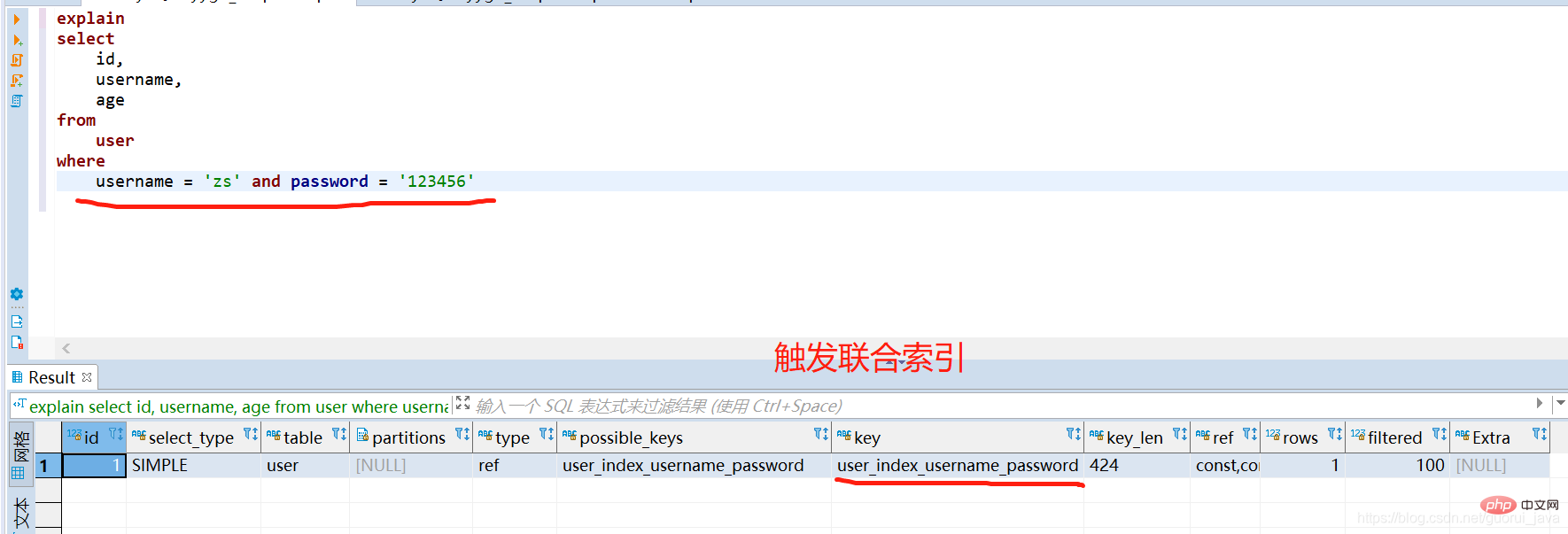
(2) すべてのインデックス キーを使用
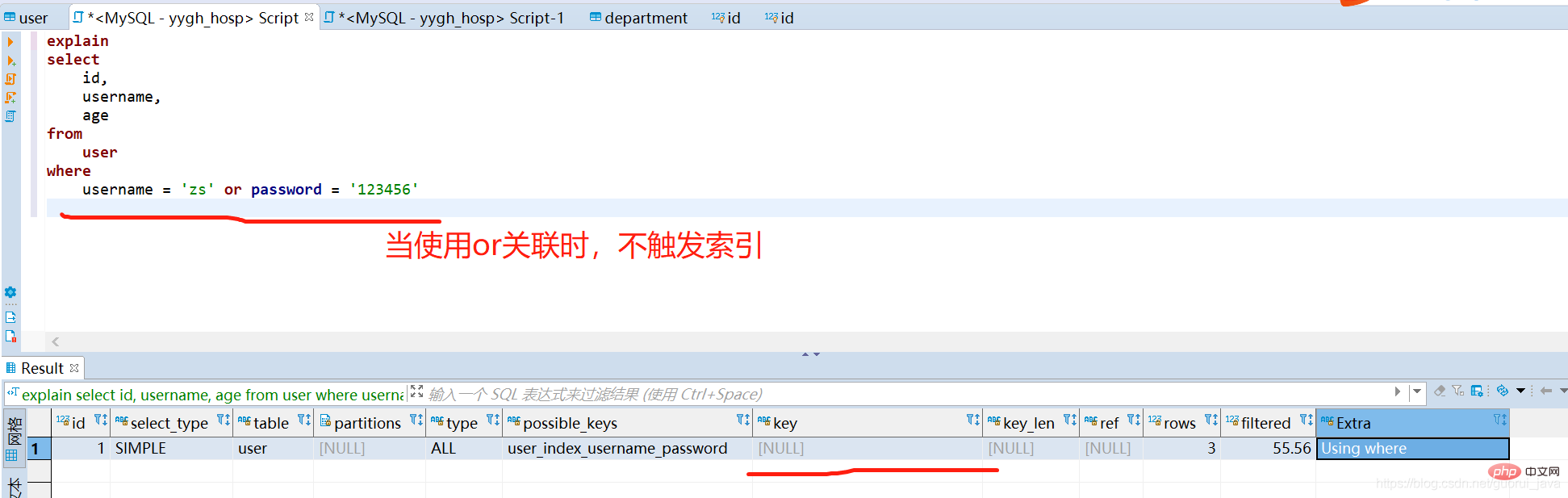
(3) ジョイント インデックスの左側の最初のフィールドが単独で使用される場合、ジョイント インデックスをトリガーできます

(4) ジョイント インデックスの他のフィールドを単独で使用する場合、ジョイント インデックスをトリガーできません

6. SQL 実行計画の分析---explain
explain は SQL 最適化をシミュレートし、SQL ステートメントを実行できます。
1. explan の使い方の概要
(1) ユーザー テーブル

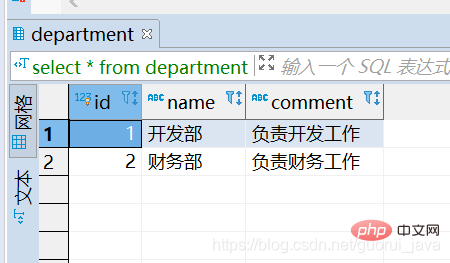
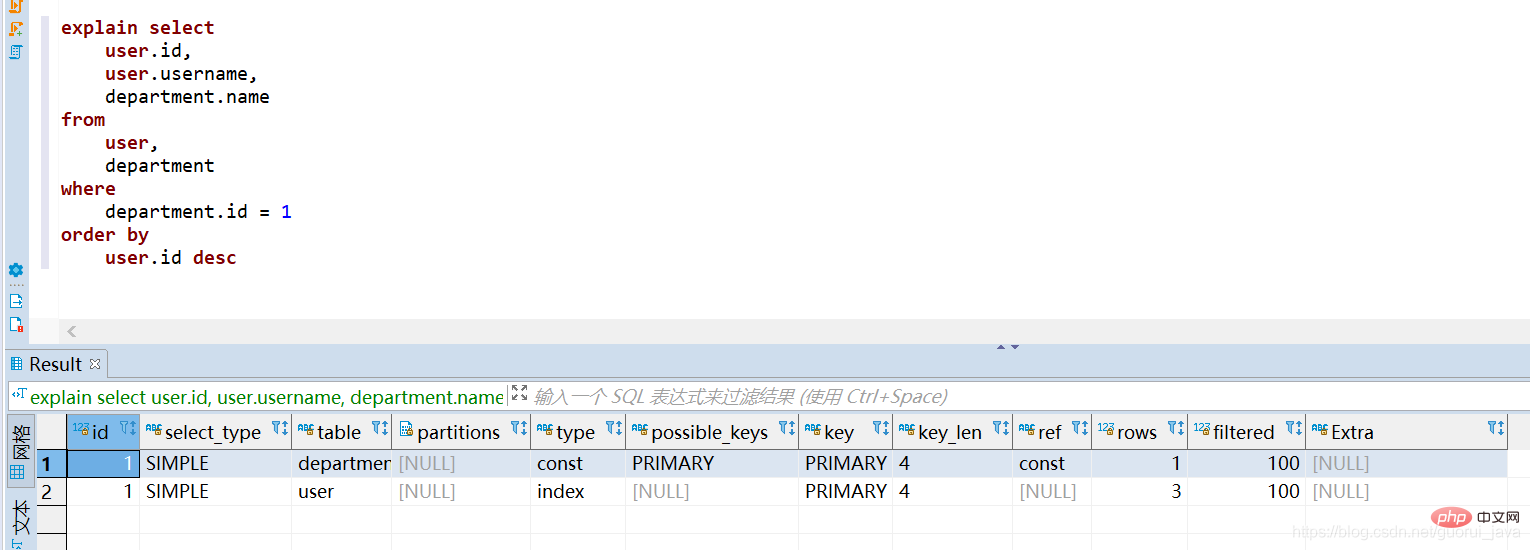
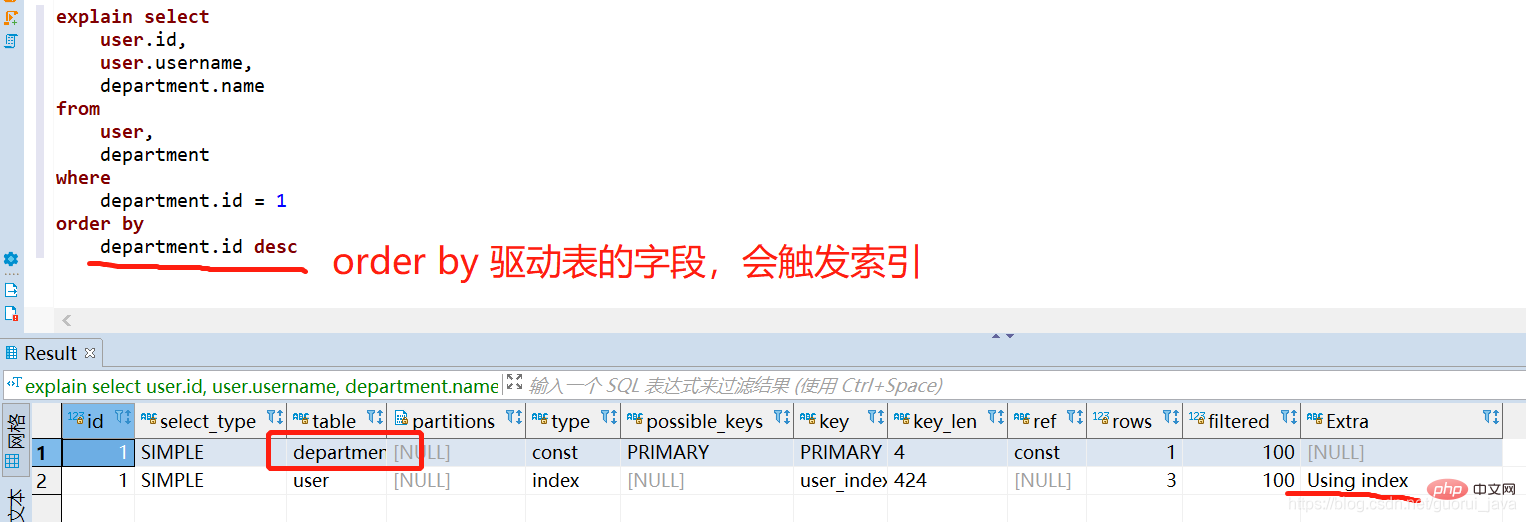
Explain の最初の行に表示されるテーブルはドライバー テーブルです。
- ##結合条件を指定した場合、クエリ条件を満たす行数が少ないテーブルは[駆動テーブル]
- 指定なし 条件を結合する場合、行数が少ないテーブルは [駆動テーブル]
- です。駆動テーブルを直接ソートするとインデックスがトリガーされ、非駆動テーブルはソートされます。インデックスはトリガーされません。
2. クエリ結果の説明の概要
(1) id: SELECT 識別子。 SELECTのクエリシーケンス番号です。
(2) select_type: SELECT タイプ:
- SIMPLE: 単純な SELECT (UNION やサブクエリを使用しません)
- PRIMARY: 最も外側の SELECT
- UNION: UNION の 2 番目以降の SELECT ステートメント
- DEPENDENT UNION: UNION の 2 番目の SELECT ステートメントまたは後続の SELECT ステートメントは、外部クエリ
- UNION RESULT: UNION の結果
- SUBQUERY: サブクエリ A SELECT
- DEPENDENT SUBQUERY: 外部クエリに応じたサブクエリ内の最初の SELECT
- ##DERIVED: 派生テーブルの SELECT (FROM 句のサブクエリ)
- (3) table: テーブル名
- const: テーブルには一致する行が 1 つだけあり、クエリの先頭で読み取られます。行が 1 つしかないため、この行の列値はオプティマイザーの残りの部分によって定数として扱われます。 const は、PRIMARY KEY または UNIQUE インデックスのすべての部分を定数値と比較するときに使用されます。
- eq_ref: 前のテーブルの行の組み合わせごとに、このテーブルから 1 行を読み取ります。これは、const 型以外ではおそらく最適な結合型です。これは、インデックスのすべての部分が結合で使用され、インデックスが UNIQUE または PRIMARY KEY である場合に使用されます。 eq_ref は、= 演算子を使用して比較したインデックス付き列で使用できます。比較値には、定数、またはこのテーブルの前に読み取られたテーブルの列を使用する式を指定できます。
- ref: 前のテーブルの行の組み合わせごとに、一致するインデックス値を持つすべての行がこのテーブルから読み取られます。結合でキーの左端のプレフィックスのみが使用される場合、またはキーが UNIQUE または PRIMARY KEY ではない場合 (つまり、結合でキーに基づいて単一の行を選択できない場合)、ref を使用します。この結合タイプは、少数の行のみに一致するキーを使用している場合に適しています。 ref は、= 演算子または <=> 演算子を使用してインデックス付き列で使用できます。
- ref_or_null: この結合タイプは ref に似ていますが、NULL 値を含む行を特別に検索するための MySQL が追加されています。この結合タイプの最適化は、サブクエリを解決する際によく使用されます。
index_merge: この結合タイプは、インデックス マージ最適化メソッドが使用されることを示します。この場合、key 列には使用されるインデックスのリストが含まれ、key_len には使用されるインデックスの最長のキー要素が含まれます。
unique_subquery: このタイプは、次の形式の IN サブクエリの ref を置き換えます: value IN (SELECT Primary_key FROMsingle_table WHERE some_expr); unique_subquery は、サブクエリを完全に置き換えることができるインデックス検索関数です。 、より高い効率。
index_subquery: この結合タイプは unique_subquery に似ています。 IN サブクエリは置換できますが、次の形式のサブクエリの一意でないインデックスに限ります。 value IN (SELECT key_column FROM single_table WHERE some_expr)
range: 指定された範囲の行のみを取得します。 、インデックスを使用して行を選択します。キー列には、どのインデックスが使用されたかが表示されます。 key_len には、使用されるインデックスの最長のキー要素が含まれます。この型では ref 列は NULL です。 =、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN または IN 演算子を使用する場合、キー列を定数と比較するときに range# を使用できます。
- #index: この結合タイプは、インデックス ツリーのみがスキャンされることを除いて、ALL と同じです。通常、インデックス ファイルはデータ ファイルよりも小さいため、これは通常 ALL よりも高速です。
- all: 前のテーブルの行の組み合わせごとに完全なテーブル スキャンを実行します。これは、テーブルが const とマークされていない最初のテーブルである場合には通常良くありません。その場合は、通常は良くありません。通常、ALL を使用せずにインデックスを追加して、前のテーブルの定数値または列の値に基づいて行を取得できるようにすることができます。
- Distinct: MySQL は最初に一致する行を見つけた後、現在の行の組み合わせに対するさらなる行の検索を停止します。
- 存在しません: MySQL はクエリに対して LEFT JOIN 最適化を実行できます。LEFT JOIN 標準に一致する行が見つかった後は、テーブル内の以前の行の組み合わせをさらにチェックしなくなります。わかりました。
- 各レコードの範囲チェック (インデックス マップ: #): MySQL は使用する適切なインデックスを見つけられませんでしたが、列の値が次の場合に部分インデックスが可能である可能性があることがわかりました。以前のテーブルは使用できることがわかっていました。 MySQL は、前述のテーブルの行の組み合わせごとに、range またはindex_merge アクセス メソッドを使用して行を取得できるかどうかをチェックします。
- filesort の使用: MySQL では、ソートされた順序で行を取得する方法を理解するために 1 つの追加パスが必要です。並べ替えは、結合タイプに基づいてすべての行を参照し、WHERE 句に一致するすべての行の並べ替えキーと行へのポインターを保存することによって実行されます。次に、キーがソートされ、ソートされた順序で行が取得されます。
- インデックスの使用: それ以上の検索を行わずに、インデックス ツリー内の情報のみを使用して実際の行を読み取ることにより、テーブルから列情報を取得します。この戦略は、クエリで単一のインデックスの一部である列のみを使用する場合に使用できます。
- 一時テーブルの使用: クエリを解決するには、MySQL は結果を保持する一時テーブルを作成する必要があります。一般的な状況は、さまざまな状況に応じて列をリストできる GROUP BY 句と ORDER BY 句がクエリに含まれている場合です。
- where の使用: WHERE 句は、次のテーブルに一致する行、または顧客に送信される行を制限するために使用されます。テーブルのすべての行を特にリクエストまたはチェックしない限り、Extra 値が using where ではなく、テーブル結合タイプが ALL またはインデックスである場合、クエリにエラーが発生する可能性があります。
- sort_union(...) の使用、union(...) の使用、intersect(...) の使用: これらの関数は、index_merge 結合タイプのインデックス スキャンをマージする方法を示します。
- group-by にインデックスを使用: テーブルにアクセスするインデックスを使用する方法と同様に、group-by にインデックスを使用すると、MySQL が GROUP のクエリに使用できるインデックスを見つけたことを意味します。実際のテーブルにアクセスするためにハードドライブをさらに検索する必要がなく、すべての列の BY または DISTINCT クエリを実行できます。また、各グループで少数のインデックス エントリのみが読み取られるように、最も効率的な方法でインデックスを使用してください。
推奨学習: mysql ビデオ チュートリアル
以上がmysqlのインデックス作成スキル(サマリー共有)を完全マスターの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7547
7547
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 mysql インデックス障害のいくつかの状況
Feb 21, 2024 pm 04:23 PM
mysql インデックス障害のいくつかの状況
Feb 21, 2024 pm 04:23 PM
一般的な状況: 1. 関数または演算を使用する; 2. 暗黙的な型変換; 3. 等しくない (!= または <>) を使用する; 4. LIKE 演算子を使用し、ワイルドカードで始める; 5. OR 条件; 6. NULL値、7. 低いインデックス選択性、8. 複合インデックスの左端の接頭辞の原則、9. オプティマイザーの決定、10. FORCE INDEX および IGNORE INDEX。
 どのような状況で mysql インデックスが失敗しますか?
Aug 09, 2023 pm 03:38 PM
どのような状況で mysql インデックスが失敗しますか?
Aug 09, 2023 pm 03:38 PM
MySQL インデックスは、インデックス カラムを使用せずにクエリを実行した場合、データ型が一致していない場合、プレフィックス インデックスが不適切に使用された場合、クエリに関数や式を使用した場合、インデックス カラムの順序が正しくない場合、データ更新が頻繁に行われる場合、インデックスが多すぎるか少なすぎる場合に失敗します。 1. クエリにはインデックス列を使用しないでください。この状況を回避するには、クエリで適切なインデックス列を使用する必要があります。2. データ型が一致しません。テーブル構造を設計するときは、インデックス列がクエリの構造と一致していることを確認する必要があります。クエリのデータ型; 3. 、プレフィックス インデックスの不適切な使用、プレフィックス インデックスを使用できます。
 MySQLでインデックスを使用するよりも、フルテーブルスキャンがいつ速くなるのでしょうか?
Apr 09, 2025 am 12:05 AM
MySQLでインデックスを使用するよりも、フルテーブルスキャンがいつ速くなるのでしょうか?
Apr 09, 2025 am 12:05 AM
完全なテーブルスキャンは、MySQLでインデックスを使用するよりも速い場合があります。特定のケースには以下が含まれます。1)データボリュームは小さい。 2)クエリが大量のデータを返すとき。 3)インデックス列が高度に選択的でない場合。 4)複雑なクエリの場合。クエリプランを分析し、インデックスを最適化し、オーバーインデックスを回避し、テーブルを定期的にメンテナンスすることにより、実際のアプリケーションで最良の選択をすることができます。
 mysqlインデックスの分類は何ですか?
Apr 22, 2024 pm 07:12 PM
mysqlインデックスの分類は何ですか?
Apr 22, 2024 pm 07:12 PM
MySQL インデックスは次のタイプに分類されます: 1. 通常のインデックス: 値、範囲、またはプレフィックスに一致します。 2. 固有のインデックス: 値が一意であることを確認します。 3. 主キー インデックス: 主キー列の一意のインデックス。キー インデックス: 別のテーブルの主キーを指します。 5. フルテキスト インデックス: 全文検索。 7. 空間インデックス: 地理空間検索。列。
 MySQL インデックスの左プレフィックス マッチング ルール
Feb 24, 2024 am 10:42 AM
MySQL インデックスの左プレフィックス マッチング ルール
Feb 24, 2024 am 10:42 AM
MySQL インデックスの左端の原則とコード例 MySQL では、インデックス作成はクエリ効率を向上させる重要な手段の 1 つです。その中でも、インデックスの左端の原則は、インデックスを使用してクエリを最適化するときに従う必要がある重要な原則です。この記事では、MySQL インデックスの左端の原則を紹介し、具体的なコード例をいくつか示します。 1. インデクス左端原則の原則 インデクス左端原則とは、インデクスにおいて問合せ条件が複数の列で構成される場合、問合せ条件を完全に満たすにはインデクスの左端の列のみを問合せできることを意味します。
 さまざまなタイプのMySQLインデックス(Bツリー、ハッシュ、フルテキスト、空間)を説明します。
Apr 02, 2025 pm 07:05 PM
さまざまなタイプのMySQLインデックス(Bツリー、ハッシュ、フルテキスト、空間)を説明します。
Apr 02, 2025 pm 07:05 PM
MySQLは、Bツリー、ハッシュ、フルテキスト、および空間の4つのインデックスタイプをサポートしています。 1.B-Treeインデックスは、等しい値検索、範囲クエリ、ソートに適しています。 2。ハッシュインデックスは、等しい値検索に適していますが、範囲のクエリとソートをサポートしていません。 3.フルテキストインデックスは、フルテキスト検索に使用され、大量のテキストデータの処理に適しています。 4.空間インデックスは、地理空間データクエリに使用され、GISアプリケーションに適しています。
 MySQL インデックスを合理的に使用し、データベースのパフォーマンスを最適化するにはどうすればよいでしょうか?技術系の学生が知っておくべき設計プロトコル!
Sep 10, 2023 pm 03:16 PM
MySQL インデックスを合理的に使用し、データベースのパフォーマンスを最適化するにはどうすればよいでしょうか?技術系の学生が知っておくべき設計プロトコル!
Sep 10, 2023 pm 03:16 PM
MySQL インデックスを合理的に使用し、データベースのパフォーマンスを最適化するにはどうすればよいでしょうか?技術系の学生が知っておくべき設計プロトコル!はじめに: 今日のインターネット時代では、データ量は増加し続けており、データベースのパフォーマンスの最適化が非常に重要なテーマになっています。最も人気のあるリレーショナル データベースの 1 つである MySQL では、データベースのパフォーマンスを向上させるためにインデックスを合理的に使用することが重要です。この記事では、MySQL インデックスを合理的に使用し、データベースのパフォーマンスを最適化し、技術系の学生向けにいくつかの設計ルールを提供する方法を紹介します。 1. なぜインデックスを使用するのでしょうか?インデックスは、以下を使用するデータ構造です。
 PHP および MySQL インデックスのデータ更新とインデックス保守のためのパフォーマンス最適化戦略と、それらがパフォーマンスに及ぼす影響
Oct 15, 2023 pm 12:15 PM
PHP および MySQL インデックスのデータ更新とインデックス保守のためのパフォーマンス最適化戦略と、それらがパフォーマンスに及ぼす影響
Oct 15, 2023 pm 12:15 PM
PHP および MySQL インデックスのデータ更新とインデックス保守のためのパフォーマンス最適化戦略と、それらがパフォーマンスに与える影響 概要: PHP および MySQL の開発において、インデックスはデータベース クエリのパフォーマンスを最適化するための重要なツールです。この記事では、インデックスの基本原則と使用法を紹介し、データの更新とメンテナンスに対するインデックスのパフォーマンスへの影響を検討します。同時に、この記事では、開発者がインデックスをよりよく理解して適用できるように、いくつかのパフォーマンス最適化戦略と具体的なコード例も提供します。インデックスの基本原則と使用法 MySQL では、インデックスは特別な番号です。
