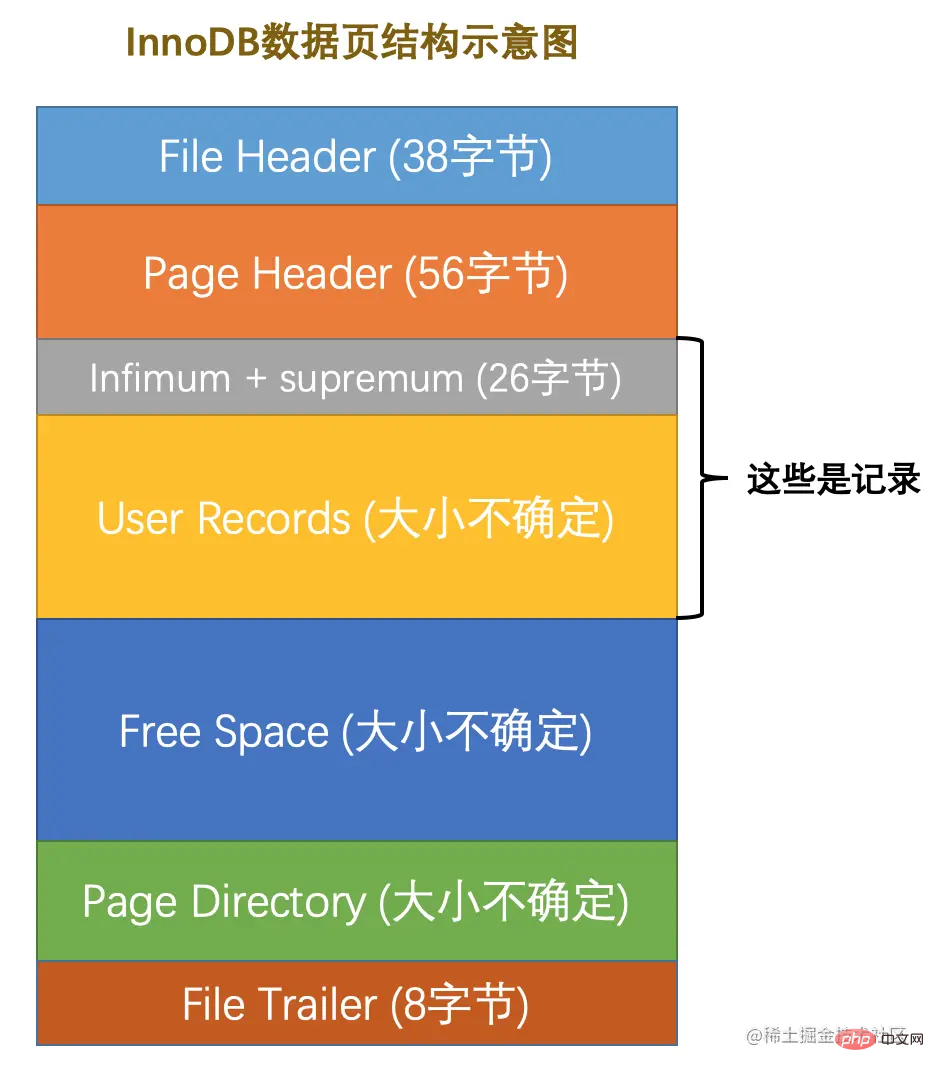
<p>由于我们现在主要在唠叨<code>记录头信息的作用,所以为了大家理解上的方便,我们只在page_demo表的行格式演示图中画出有关的头信息属性以及c1、c2、c3列的信息(其他信息没画不代表它们不存在啊,只是为了理解上的方便在图中省略了~),简化后的行格式示意图就是这样:

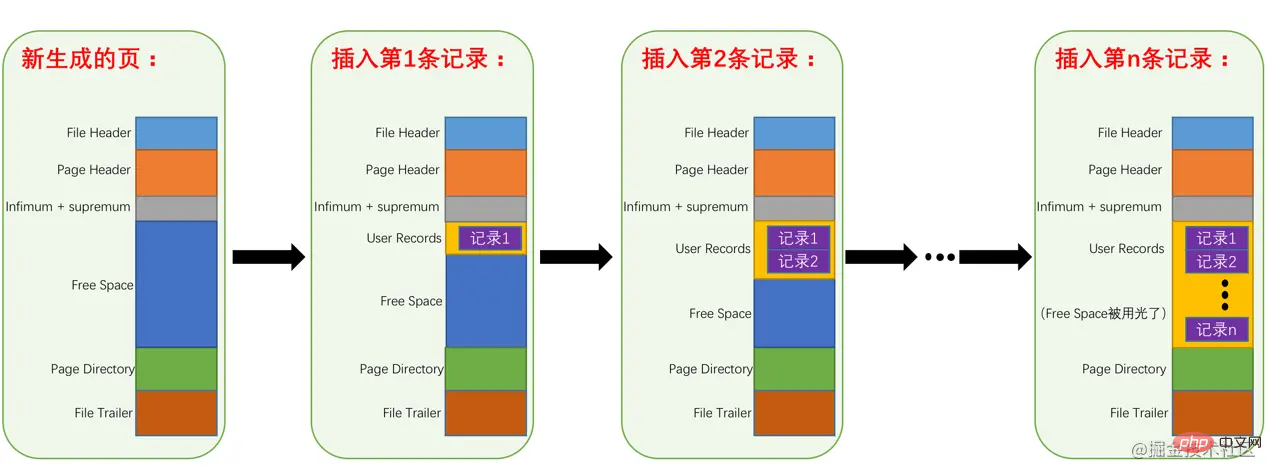
下边我们试着向page_demo表中插入几条记录:
mysql> INSERT INTO page_demo VALUES(1, 100, 'aaaa'), (2, 200, 'bbbb'), (3, 300, 'cccc'), (4, 400, 'dddd');
Query OK, 4 rows affected (0.00 sec)
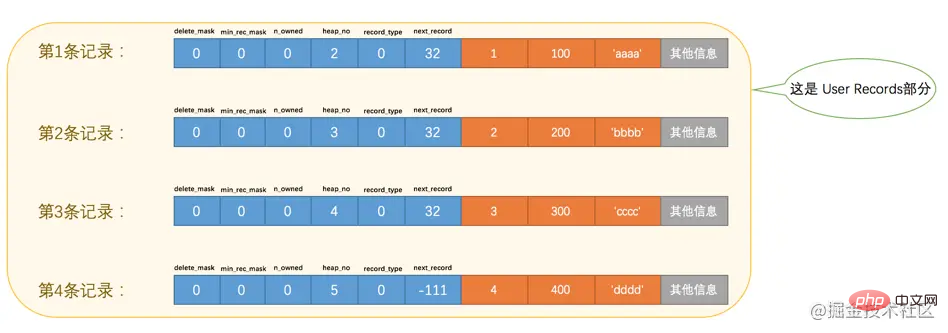
Records: 4 Duplicates: 0 Warnings: 0 ログイン後にコピー 为了方便大家分析这些记录在页的User Records部分中是怎么表示的,我把记录中头信息和实际的列数据都用十进制表示出来了(其实是一堆二进制位),所以这些记录的示意图就是:
看这个图的时候需要注意一下,各条记录在User Records中存储的时候并没有空隙,这里只是为了大家观看方便才把每条记录单独画在一行中。我们对照着这个图来看看记录头信息中的各个属性是啥意思:
-
delete_mask
这个属性标记着当前记录是否被删除,占用1个二进制位,值为0的时候代表记录并没有被删除,为1的时候代表记录被删除掉了。
啥?被删除的记录还在页中么?是的,摆在台面上的和背地里做的可能大相径庭,你以为它删除了,可它还在真实的磁盘上[摊手](忽然想起冠希~)。这些被删除的记录之所以不立即从磁盘上移除,是因为移除它们之后把其他的记录在磁盘上重新排列需要性能消耗,所以只是打一个删除标记而已,所有被删除掉的记录都会组成一个所谓的垃圾链表,在这个链表中的记录占用的空间称之为所谓的可重用空间,之后如果有新记录插入到表中的话,可能把这些被删除的记录占用的存储空间覆盖掉。
-
min_rec_mask
B+树的每层非叶子节点中的最小记录都会添加该标记,什么是个B+树?什么是个非叶子节点?好吧,等会再聊这个问题。反正我们自己插入的四条记录的min_rec_mask值都是0,意味着它们都不是B+树的非叶子节点中的最小记录。
-
n_owned
这个暂时保密,稍后它是主角~
-
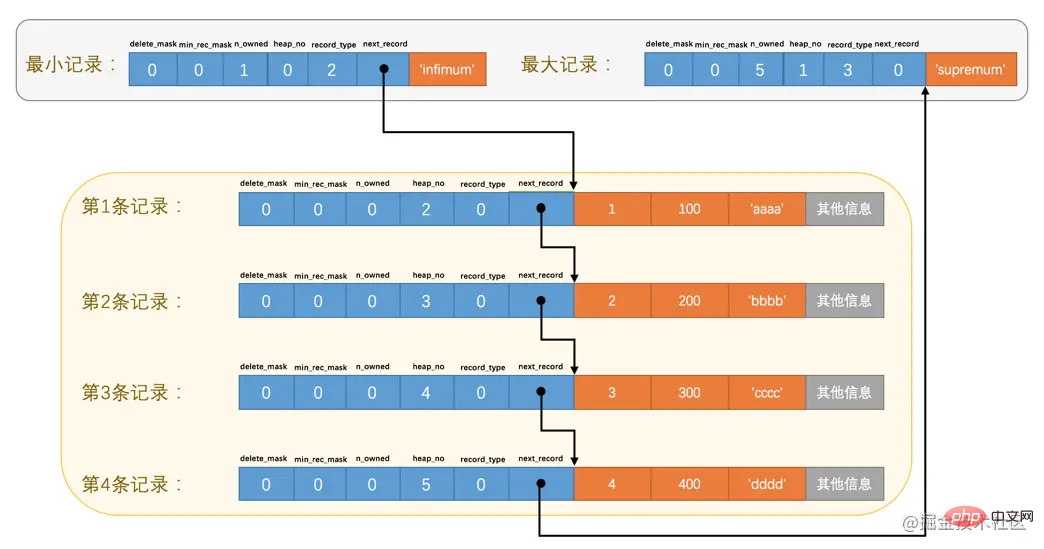
heap_no
这个属性表示当前记录在本页中的位置,从图中可以看出来,我们插入的4条记录在本页中的位置分别是:2、3、4、5。是不是少了点啥?是的,怎么不见heap_no值为0和1的记录呢?
这其实是设计InnoDB的大叔们玩的一个小把戏,他们自动给每个页里边儿加了两个记录,由于这两个记录并不是我们自己插入的,所以有时候也称为伪记录或者虚拟记录。这两个伪记录一个代表最小记录,一个代表最大记录,等一下哈~,记录可以比大小么?
是的,记录也可以比大小,对于一条完整的记录来说,比较记录的大小就是比较主键的大小。比方说我们插入的4行记录的主键值分别是:1、2、3、4,这也就意味着这4条记录的大小从小到大依次递增。
-
但是不管我们向页中插入了多少自己的记录,设计InnoDB的大叔们都规定他们定义的两条伪记录分别为最小记录与最大记录。这两条记录的构造十分简单,都是由5字节大小的记录头信息和8字节大小的一个固定的部分组成的,如图所示
由于这两条记录不是我们自己定义的记录,所以它们并不存放在页的User Records部分,他们被单独放在一个称为Infimum + Supremum的部分,如图所示:
从图中我们可以看出来,最小记录和最大记录的heap_no值分别是0和1,也就是说它们的位置最靠前。
-
record_type
这个属性表示当前记录的类型,一共有4种类型的记录,0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3表示最大记录。从图中我们也可以看出来,我们自己插入的记录就是普通记录,它们的record_type值都是0,而最小记录和最大记录的record_type值分别为2和3。
至于record_type为1的情况,我们之后在说索引的时候会重点强调的。
-
next_record
这玩意儿非常重要,它表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量。比方说第一条记录的next_record值为32,意味着从第一条记录的真实数据的地址处向后找32个字节便是下一条记录的真实数据。如果你熟悉数据结构的话,就立即明白了,这其实是个链表,可以通过一条记录找到它的下一条记录。但是需要注意注意再注意的一点是,下一条记录指得并不是按照我们插入顺序的下一条记录,而是按照主键值由小到大的顺序的下一条记录。而且规定 Infimum记录(也就是最小记录) 的下一条记录就是本页中主键值最小的用户记录,而本页中主键值最大的用户记录的下一条记录就是 Supremum记录(也就是最大记录) ,为了更形象的表示一下这个next_record起到的作用,我们用箭头来替代一下next_record中的地址偏移量:
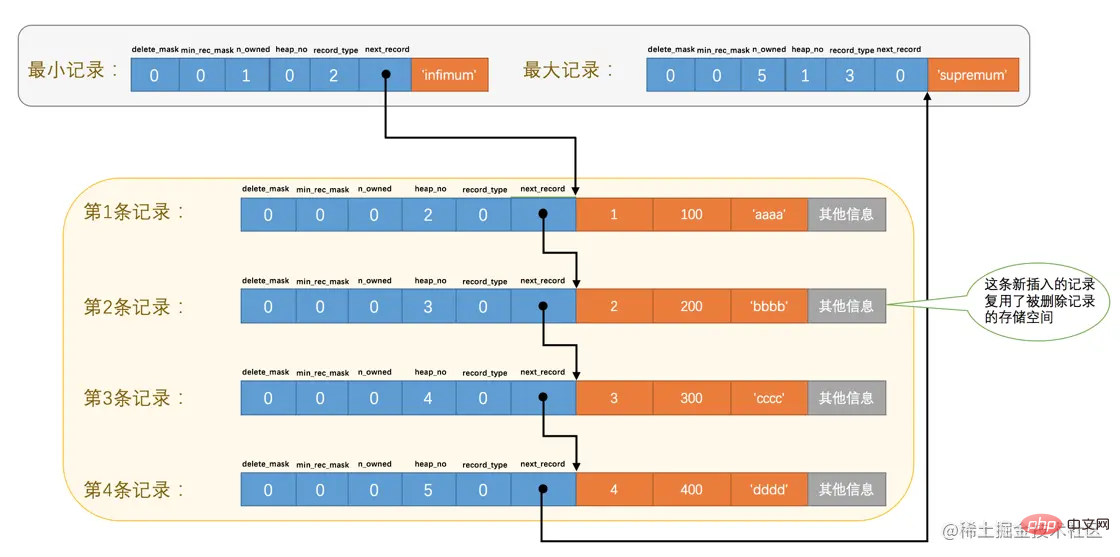
从图中可以看出来,我们的记录按照主键从小到大的顺序形成了一个单链表。最大记录的next_record的值为0,这也就是说最大记录是没有下一条记录了,它是这个单链表中的最后一个节点。如果从中删除掉一条记录,这个链表也是会跟着变化的,比如我们把第2条记录删掉:
mysql> DELETE FROM page_demo WHERE c1 = 2;
Query OK, 1 row affected (0.02 sec) ログイン後にコピー 删掉第2条记录后的示意图就是:
从图中可以看出来,删除第2条记录前后主要发生了这些变化:
- 第2条记录并没有从存储空间中移除,而是把该条记录的
delete_mask值设置为1。
- 第2条记录的
next_record值变为了0,意味着该记录没有下一条记录了。
- 第1条记录的
next_record指向了第3条记录。
- 还有一点你可能忽略了,就是
最大记录的n_owned值从5变成了4,关于这一点的变化我们稍后会详细说明的。
所以,不论我们怎么对页中的记录做增删改操作,InnoDB始终会维护一条记录的单链表,链表中的各个节点是按照主键值由小到大的顺序连接起来的。
再来看一个有意思的事情,因为主键值为2的记录被我们删掉了,但是存储空间却没有回收,如果我们再次把这条记录插入到表中,会发生什么事呢?
mysql> INSERT INTO page_demo VALUES(2, 200, 'bbbb');
Query OK, 1 row affected (0.00 sec) ログイン後にコピー 我们看一下记录的存储情况:
从图中可以看到,InnoDB并没有因为新记录的插入而为它申请新的存储空间,而是直接复用了原来被删除记录的存储空间。
Page Directory(页目录)
现在我们了解了记录在页中按照主键值由小到大顺序串联成一个单链表,那如果我们想根据主键值查找页中的某条记录该咋办呢?比如说这样的查询语句:
SELECT * FROM page_demo WHERE c1 = 3; ログイン後にコピー 最笨的办法:从Infimum记录(最小记录)开始,沿着链表一直往后找,总有一天会找到(或者找不到[摊手]),在找的时候还能投机取巧,因为链表中各个记录的值是按照从小到大顺序排列的,所以当链表的某个节点代表的记录的主键值大于你想要查找的主键值时,你就可以停止查找了,因为该节点后边的节点的主键值依次递增。
この方法は、ページに保存されているレコードの数が比較的少ない場合には問題ありません。たとえば、テーブルには挿入したレコードが 4 のみであるため、検索できるのは のみです。すべてのレコードは 4 回走査できますが、ページに多数のレコードが保存されている場合、そのような検索では依然としてパフォーマンスが低下するため、この種の走査検索は Stupid であると言われます。 ### 方法。しかし、InnoDB を設計したおじさんたちは誰ですか? そんな愚かな方法が使えるでしょうか? もちろん、もっと良い検索方法を設計しなければなりません。彼らは本の目次からインスピレーションを得ました。 私たちが本の中で何かを見つけたいときは、通常、最初に目次を見て、見つけたい内容に対応する本のページ番号を見つけてから、対応するページに移動します。コンテンツを表示するには番号を入力します。 InnoDB を設計したおじさんたちも、私たちのレコード用に同様のディレクトリを作成しました。彼らの作成プロセスは次のとおりです:
- すべての通常のレコード (最大レコードと最小レコードを含む) を変換します(削除済みとしてマークされたレコードを除く) はいくつかのグループに分けられます。
- 各グループの最後のレコード (つまり、グループ内の最大のレコード) のヘッダー情報の
n_owned 属性は、レコードに含まれるレコードの数を示します。 . 、つまり、このグループにレコードがいくつあるかを示します。
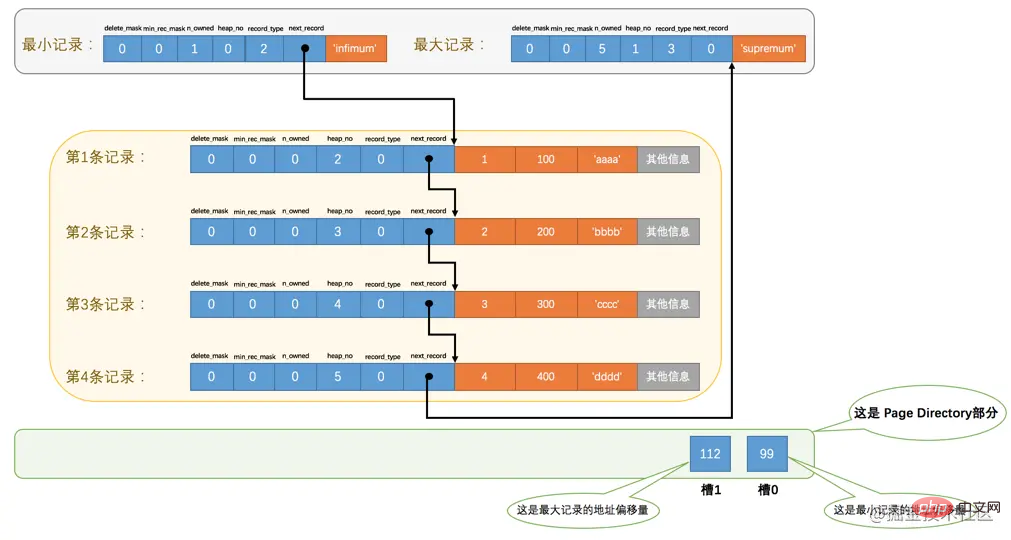
- 各グループの最後のレコードのアドレス オフセットを個別に抽出し、
ページ の終わり近くに順番に格納します。この場所はいわゆる です。ページ ディレクトリ 、これは ページ ディレクトリ です (この時点で、先頭に戻ってページの各部分の図を確認してください)。ページ ディレクトリ内のこれらのアドレス オフセットは slot (英語名: Slot) と呼ばれ、このページ ディレクトリは slot で構成されます。
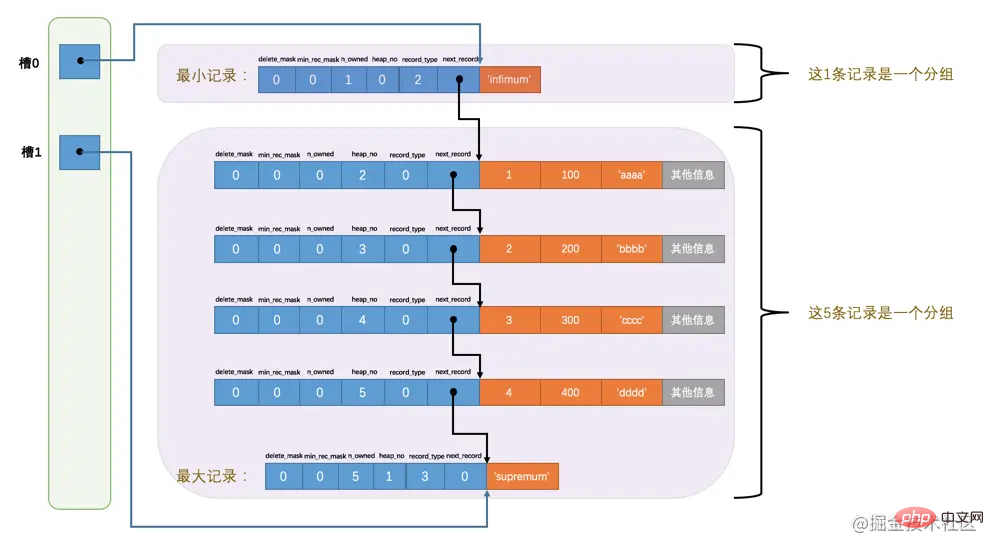
たとえば、page_demo テーブルには現在 6 つの通常のレコードがあります。InnoDB はそれらを 2 つのグループに分割します。最小レコードは 1 つだけあり、2 番目のグループには残りの 5 レコードが含まれています。下の図を見てください:
この図から次の点に注意する必要があります。 :
99 や 112 のようなアドレス オフセットは非常に直感的ではありません。次のように、数字の代わりに矢印を使用して数字を指します。分かりやすいので、修正した模式図は次のようになります:
ああ、奇妙に見えます。このような乱雑な図は、強迫性障害の私には本当に耐えられません次に、ストレージ デバイス上の各レコードの配置を一時的に無視し、論理的な観点からこれらのレコードとページ ディレクトリ間の関係を単純に調べます。見た目も楽しそうです。たくさんありすぎます!最小レコードの n_owned 値が 1 であるのに、最大レコードの n_owned 値が 5 なのはなぜですか? ここに何か怪しい点はありますか? InnoDB を設計したおじさんたちは、各グループのレコード数について規制を設けています。最も小さいレコードを持つグループは、 # しか持つことができません。 ## レコード、最大のレコードが存在するグループが所有するレコードの数は 1 ~ 8 の範囲内のみであり、残りのグループのレコードの数は範囲が指定できます。 4~8 の間のみです。したがって、グループ化は次の手順に従って実行されます。 最初、データ ページには最小レコードと最大レコードの 2 つのレコードのみが存在し、それらは 2 つのグループに属します。 。
レコードが挿入されるたびに、主キー値がこのレコードの主キー値より大きく、差が最も小さいスロットが
由于现在page_demo表中的记录太少,无法演示添加了页目录之后加快查找速度的过程,所以再往page_demo表中添加一些记录:
mysql> INSERT INTO page_demo VALUES(5, 500, 'eeee'), (6, 600, 'ffff'), (7, 700, 'gggg'), (8, 800, 'hhhh'), (9, 900, 'iiii'), (10, 1000, 'jjjj'), (11, 1100, 'kkkk'), (12, 1200, 'llll'), (13, 1300, 'mmmm'), (14, 1400, 'nnnn'), (15, 1500, 'oooo'), (16, 1600, 'pppp');
Query OK, 12 rows affected (0.00 sec)
Records: 12 Duplicates: 0 Warnings: 0 ログイン後にコピー 哈,我们一口气又往表中添加了12条记录,现在页里边就一共有18条记录了(包括最小和最大记录),这些记录被分成了5个组,如图所示:
因为把16条记录的全部信息都画在一张图里太占地方,让人眼花缭乱的,所以只保留了用户记录头信息中的n_owned和next_record属性,也省略了各个记录之间的箭头,我没画不等于没有啊!现在看怎么从这个页目录中查找记录。因为各个槽代表的记录的主键值都是从小到大排序的,所以我们可以使用所谓的二分法来进行快速查找。5个槽的编号分别是:0、1、2、3、4,所以初始情况下最低的槽就是low=0,最高的槽就是high=4。比方说我们想找主键值为6的记录,过程是这样的:
计算中间槽的位置:(0+4)/2=2,所以查看槽2对应记录的主键值为8,又因为8 > 6,所以设置high=2,low保持不变。 重新计算中间槽的位置:(0+2)/2=1,所以查看槽1对应的主键值为4,又因为4 ,所以设置<code>low=1,high保持不变。 因为high - low的值为1,所以确定主键值为6的记录在槽2对应的组中。此刻我们需要找到槽2中主键值最小的那条记录,然后沿着单向链表遍历槽2中的记录。但是我们前边又说过,每个槽对应的记录都是该组中主键值最大的记录,这里槽2对应的记录是主键值为8的记录,怎么定位一个组中最小的记录呢?别忘了各个槽都是挨着的,我们可以很轻易的拿到槽1对应的记录(主键值为4),该条记录的下一条记录就是槽2中主键值最小的记录,该记录的主键值为5。所以我们可以从这条主键值为5的记录出发,遍历槽2中的各条记录,直到找到主键值为6的那条记录即可。由于一个组中包含的记录条数只能是1~8条,所以遍历一个组中的记录的代价是很小的。
所以在一个数据页中查找指定主键值的记录的过程分为两步:
通过二分法确定该记录所在的槽,并找到该槽所在分组中主键值最小的那条记录。 通过记录的next_record属性遍历该槽所在的组中的各个记录。
Page Header(页面头部)
设计InnoDB的大叔们为了能得到一个数据页中存储的记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等,特意在页中定义了一个叫Page Header的部分,它是页结构的第二部分,这个部分占用固定的56个字节,专门存储各种状态信息,具体各个字节都是干嘛的看下表:
#名前 | 占有スペース | 説明 |
# PAGE_N_DIR_SLOTS
| bytesページ ディレクトリ内のスロットの数 |
|
PAGE_HEAP_TOP
#2Bytes |
未使用スペースの最小アドレス、つまりこのアドレスの後のアドレスは Free Space
|
| PAGE_N_HEAP
2bytes |
このページ内のレコード数 (最小および最大レコード、および削除対象としてマークされたレコードを含む) |
#PAGE_FREE |
2Bytes
| 最初のアドレスは、削除対象としてマークされたレコードのアドレスです。 (削除された各レコードは、next_record を通じて単一リンク リストも形成し、この単一リンク リスト内のレコードは再利用できます)
|
PAGE_GARBAGE |
2Bytes
| 削除されたレコードによって占められていたバイト数 |
PAGE_LAST_INSERT |
2Bytes
| 最後に挿入されたレコードの位置 | ##PAGE_DIRECTION |
2Bytes |
|
| 2Bytes一方向に連続して挿入されるレコードの数 |
|
|
2Bytes ページ内のレコード数 (最小および最大レコードおよび削除対象としてマークされたレコードを除く)
|
|
| # 8 bytes
現在のページの最大トランザクション ID を変更します。この値はセカンダリ インデックスでのみ定義されます |
PAGE_LEVEL |
#2 | bytes #B ツリー内の現在のページのレベル
| #PAGE_INDEX_ID | 8bytes |
現在のページがどのインデックスに属しているかを示すインデックス ID
| PAGE_BTR_SEG_LEAF
| bytes | #B ツリー リーフ セグメントのヘッダー情報は、B ツリーのルート ページでのみ定義されます
|
| bytes | B ツリー ルート ページ定義のみの B ツリー非リーフ セグメントのヘッダー情報 <p>前の記事を注意深く読んでいる場合は、<code>PAGE_N_DIR_SLOTS から PAGE_LAST_INSERT および PAGE_N_RECS の意味を理解しているはずです。よくわからない場合は、申し訳ありませんが、前の記事に戻ってもう一度読んでください。残りのステータス情報が理解できなくても心配する必要はありません。一度に一口ずつ食べて、少しずつ物事を学ぶ必要があります (これらの名詞に怯えないよう、落ち着いてください)。ここでは、まず PAGE_DIRECTION と PAGE_N_DIRECTION の意味について説明します。
-
#PAGE_DIRECTION
新しく挿入されたレコードの主キー値が前のレコードの主キー値より大きい場合、このレコードの挿入方向は右方向であると言い、その逆も同様です。最後のレコードの挿入方向を示すために使用されるステータスは PAGE_DIRECTION です。
-
PAGE_N_DIRECTION
新しいレコードを連続して数回挿入する方向が同じであると仮定すると、InnoDB は次のようになります。 Record に沿って新しいレコードを挿入 同じ方向に挿入されたレコードの数。この数はステータス PAGE_N_DIRECTION で表されます。もちろん、最後のレコードの挿入方向が変わると、このステータスの値はクリアされ、再度カウントされます。
言及しなかった属性については、今知る必要がないため言及しませんでした。心配しないでください。次の内容を学び終えた後、振り返ってみると、すべてが明確になっているはずです。
ファイル ヘッダー
上記の ページ ヘッダーは、データ ページに記録されるさまざまなステータス情報に特化しています。ページ内にレコードとスロットがあります。ここで説明している ファイル ヘッダー は、さまざまな種類のページに共通です。つまり、さまざまな種類のページの最初のコンポーネントとして ファイル ヘッダー があり、これにはいくつかの特定の共通情報が記述されています。このページの番号は何ですか、前のページと次のページは誰ですか? この部分は 38 バイトの固定数を占め、次の内容で構成されます:
##名前 | 占有スペース | 説明 |
FIL_PAGE_SPACE_OR_CHKSUM |
4bytes
| ページのチェックサム値 |
FIL_PAGE_OFFSET |
4バイト
| ページ番号 |
FIL_PAGE_PREV |
#4bytes
| 前のページのページ番号 |
FIL_PAGE_NEXT |
4bytes | 次のページのページ番号 |
FIL_PAGE_LSN |
8Bytes
| 対応するページが最後に変更されたときのログ シーケンスの位置 (英語名は Log Sequence Number) |
FIL_PAGE_TYPE |
2 bytes
| ページのタイプ |
##FIL_PAGE_FILE_FLUSH_LSN | 8Bytes |
|
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID | 4bytes |
|
この表を対比して、より重要な部分をいくつか見てみましょう:
-
FIL_PAGE_SPACE_OR_CHKSUM
これは、現在のページと (チェックサム)。チェックサムとは何ですか?つまり、非常に長いバイト文字列の場合、何らかのアルゴリズムを使用して、長いバイト文字列を表す短い値を計算します。この比較的短い値は、 チェックおよび と呼ばれます。このように、2 つの非常に長いバイト文字列を比較する前に、まずこれら 2 つの長いバイト文字列のチェックサムを比較します。チェックサムが異なる場合、2 つの長いバイト文字列は異なるはずであるため、直接の比較は省略されます。2 つの相対的な時間の消費量は、長いバイト文字列。
-
FIL_PAGE_OFFSET
各 ページ には、ID カード番号 InnoDB と同じように、個別のページ番号があります。 は、ページ番号を通じて ページ を一意に見つけることができます。
-
FIL_PAGE_TYPE
これは、前に述べたように、現在の ページ のタイプを表します、InnoDB ページは、目的に応じてさまざまなタイプに分割されます。上で紹介したのは、実際にはレコードを保存する データ ページです。実際には、次の表で詳しく説明するように、他にも多くのタイプのページがあります:
##タイプ名 | 16進数 | 説明 |
FIL_PAGE_TYPE_ALLOCATED | 0x0000 | 最新の割り当て、まだ使用されていません |
#FIL_PAGE_UNDO_LOG
|
元に戻すログ ページ |
|
##FIL_PAGE_INODE
0x0003 | セグメント情報ノード | |
FIL_PAGE_IBUF_FREE_LIST
0x0004 | バッファ空きリストの挿入 |
| #FIL_PAGE_IBUF_BITMAP
0x0005 |
|
##FIL_PAGE_TYPE_SYS |
0x0006システム ページ | | ##FIL_PAGE_TYPE_TRX_SYS |
0x0007
トランザクション システム データ |
| FIL_PAGE_TYPE_FSP_HDR | 0x0008
表スペースのヘッダー情報 |
##FIL_PAGE_TYPE_XDES |
| 0x0009
拡張説明ページ |
FIL_PAGE_TYPE_BLOB |
| 0x000A
オーバーフロー ページ
|
FIL_PAGE_INDEX |
| 0x45BF
インデックス ページ (データ ページと呼ばれます) |
|
レコードを保存するデータ ページのタイプは、実際には FIL_PAGE_INDEX で、いわゆる インデックス ページです。インデックスとは何かについては、次回説明を聞いてみましょう~
-
FIL_PAGE_PREV と FIL_PAGE_NEXT
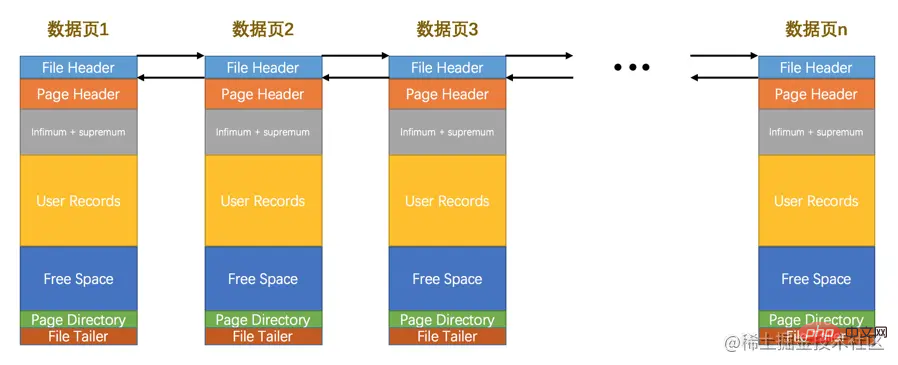
を強調しました前に、InnoDB はデータをページ単位で保存します。特定の種類のデータを保存すると、非常に大量のスペースが必要になる場合があります (たとえば、テーブルに数千のレコードが存在する場合があります)。 ##InnoDB 非常に多くのデータを一度に格納するため、非常に大きなストレージ スペースを割り当てることはできない場合があります。データが複数の不連続なページに分散して格納されている場合は、これらのページを関連付ける必要があります (FIL_PAGE_PREV##) # と FIL_PAGE_NEXT は、それぞれこのページの前のページと次のページのページ番号を表します。このようにして、多くのページは、物理的に接続される必要がなく、二重リンク リストを確立することによって直列に接続されます。すべてのタイプのページが前ページと次ページのプロパティを持っているわけではないことに注意してください。ただし、このエピソードで説明している データ ページ (つまり、タイプは FIL_PAGE_INDEX##) です。 # ページ) にはこれら 2 つの属性があるため、すべてのデータ ページは実際には次のような二重リンク リストになります:
About 当面はファイル ヘッダー の他の属性を使用してください。使用するときに説明します~ファイル トレーラー
InnoDB ストレージエンジンはデータをディスクに保存していますが、ディスク速度が遅すぎます。データは page 単位で処理するためにメモリにロードする必要があります。ページ内のデータが変更された場合、変更後の特定のページでは、データをディスクに同期するのに時間がかかります。でも、同期の途中で電源が切れてしまったらどうすればいいのでしょう?ページが完了したかどうか (つまり、同期中にページの半分しか同期されないという恥ずかしい状況がないかどうか) を検出するために、InnoDB を設計したおじさんたちは、次の場所に ファイル トレーラーを追加しました。各ページの終わり。 部分、この部分は 8 バイトで構成され、2 つの小さな部分に分割できます: 最初の 4 バイトは次のことを表しますページのチェックサム は ファイル ヘッダー に似ており、すべての種類のページに共通です。 概要
InnoDB は、さまざまな目的に応じてさまざまなタイプのページを設計しています。レコードの保存に使用されるページを データ ページ - と呼びます。
データ ページは、大まかに 7 つの部分に分けることができます。
-
ファイル ヘッダー
は、データの一般的な情報を表します。 page 、固定の 38 バイトを占めます。 -
は、データ ページ専用の情報を表し、固定の 56 バイトを占めます。 -
、2 つの仮想疑似レコード。ページ内の最小レコードと最大レコードを表し、固定 - 26
バイトを占有します。 : 挿入したレコードを実際に保存する部分で、サイズは固定されていません。 -
: ページの未使用の部分。サイズは不確かです。 -
: ページ内の一部のレコードの相対位置、つまりページ内の各スロットのアドレス オフセットのサイズは固定されていません。挿入されるレコードが増えるほど、スペースがあればあるほど、この部分の占有率が高くなります。 -
: ページが完了したかどうかを確認するために使用され、固定の 8 バイトを占めます。 各レコードのヘッダー情報には next_record- 属性があり、ページ内のすべてのレコードが
単一リンク リスト#に連結されます。 ##。 InnoDB は、ページ内のレコードをいくつかのグループに分割し、各グループの最後のレコードのアドレス オフセットが - スロットとして使用されます。
は ページ ディレクトリ に保存されるため、ページ内の主キーに基づいてレコードを非常に高速に検索できます。これは 2 つのステップに分かれています: # は二分法によって決定されます。 このレコードが配置されているスロット。
- レコードの next_record 属性を通じて、スロットが配置されているグループ内の各レコードを走査します。
各データ ページの ファイル ヘッダー 部分には前後のページの番号が含まれるため、すべてのデータ ページは を形成します。二重リンクリスト。 メモリからディスクに同期されたページの整合性を確保するために、ページ内のデータのチェックサムと、ページが最後に変更されたときの対応する ## が、 #LSN 値、ヘッダーと末尾のチェックサム、および LSN 値が正常に検証されない場合は、同期プロセスに問題があることを意味します。 推奨学習: mysql ビデオ チュートリアル
|
| 



 で多大な労力を費やしました。どこに労力を費やしましたか?指定された行形式に従って
で多大な労力を費やしました。どこに労力を費やしましたか?指定された行形式に従って  (現在は
(現在は 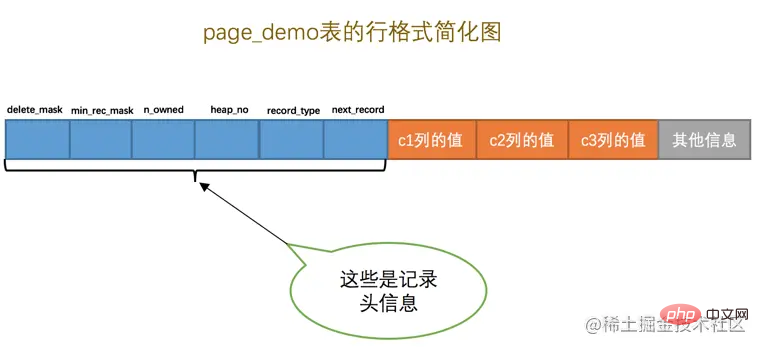




 値が
値が 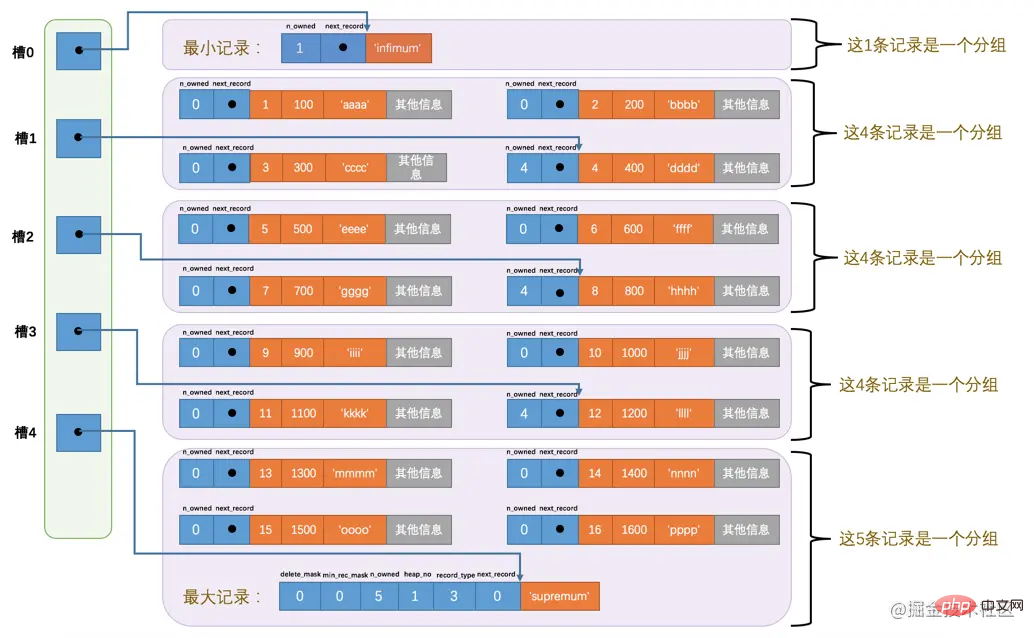














![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



