

読むとMySQLの永続化とロールバックが理解できる(画像と文章で詳しく解説)

この記事では、mysql の永続化とロールバックに関する関連知識を提供します。お役に立てば幸いです。

- 原子性: すべての操作は完了するか何も行われないかのどちらかであり、分割できません。
- 一貫性: データベースがある状態から別の状態に変化した結果は、最終的に一貫性があります。たとえば、A は 500 を B に転送します。A は最終的に 500 を失い、B は最終的に 500 を多く持つことになりますが、A B の価値は決して変わりません。
- 分離: トランザクションとトランザクションは互いに分離されており、相互に干渉しません。
- 永続性: トランザクションがコミットされると、データに対する変更は永続的になります。
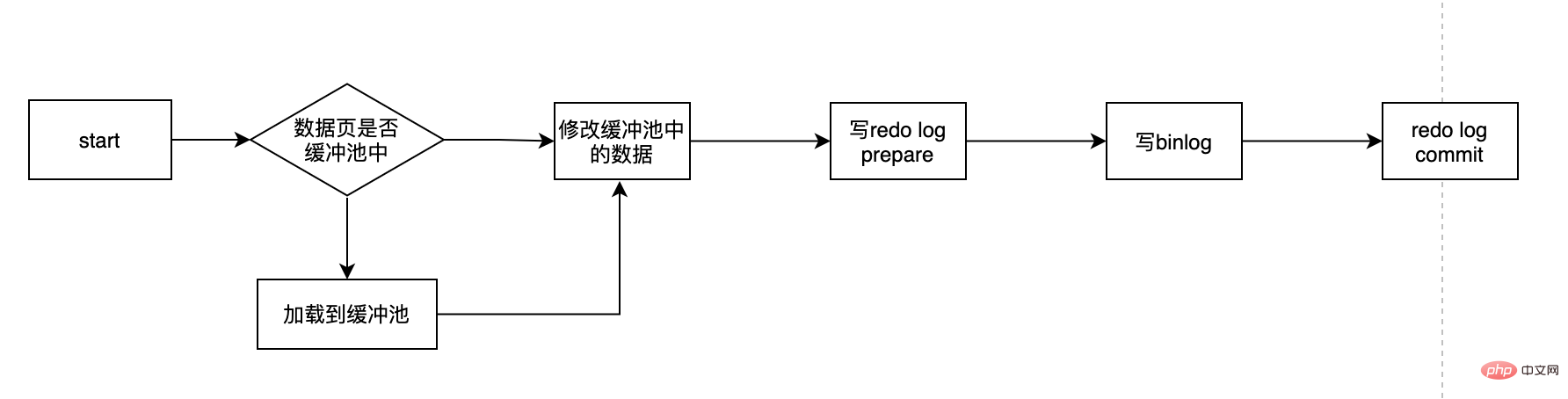
update user set age=11 where user_id=1;
- 最初に user_id データがどこにあるかを確認します。メモリ内のページが残っていますか? そうでない場合は、まずデータベースからページを読み取り、次にメモリにロードします。
- メモリ内の経過時間を 11 に変更します。
- REDO ログを書き込み、REDO ログを作成します。準備状態では
- 書き込みbinlog
- トランザクションをコミットし、REDOログはコミット状態になります
ディスク データを直接更新するのではなく、最初にメモリ データを更新する必要があるのはなぜですか?
データを更新するたびに、対応するディスク データを直接更新しないのはなぜでしょうか?まず第一に、ディスク IO は遅く、メモリは速いことがわかっています。この 2 つの速度は桁違いです。したがって、ディスク IO が遅い場合、インデックスが表示されます。インデックスを通じて、たとえ数百万のデータがあっても、データをディスクに保存することはできますが、データをすばやく見つけることがインデックスの役割です。ただし、インデックスも維持する必要があり、静的ではありません。新しいデータ A を挿入するとき、このデータは既存のデータ B の後に挿入されるため、A 用のスペースを空けるために B のデータを移動する必要があります。一定のオーバーヘッドが発生します。 さらに悪いことに、挿入するページがすでにいっぱいの場合は、新しいページを申請して、そこにデータを移動する必要があります。これはページ分割と呼ばれ、コストが高くなります。 SQL の変更がディスク上のデータを直接変更するものであり、上記の問題が発生した場合、このときの効率は非常に低くなり、ひどい場合にはタイムアウトが発生するため、上記の更新を行っています。プロセスは、最初に対応するデータ ページをメモリにロードし、次にメモリ内のデータを最初に更新する必要があります。 mysql の場合、すべての変更はまずバッファ プール内のデータを更新する必要があり、その後バッファ プール内のダーティ ページが特定の頻度でディスクにフラッシュされ (checkPoint メカニズム)、バッファを通じて最適化されます。プール CPU とディスクの間にギャップがあるため、全体的なパフォーマンスが急激に低下することはありません。
なぜ REDO ログが必要なのでしょうか?
バッファ プールは、CPU とディスク間のギャップをなくすのに役立ちます。チェックポイント メカニズムは、データの最終的な配置を保証します。ただし、チェックポイントは、変更があるたびにトリガーされるわけではありません。ただし、マスター スレッドは一定の間隔で処理されます。したがって、最悪のシナリオは、バッファー プールが書き込まれたばかりでデータベースがクラッシュし、このデータが失われ、回復できなくなることです。このケースでは、ACID の D が満たされていません。この場合の永続性の問題を解決するために、InnoDB エンジンのトランザクションは WAL テクノロジ (Write-Ahead Logging) を使用します。このテクノロジのアイデアは、最初にログを書き込み、その後、ディスクに書き込みます。ログが正常に書き込まれた場合にのみ、トランザクションは成功したと見なされます。ここでのログは REDO ログです。ダウンタイムが発生し、データがディスクにフラッシュされなかった場合、REDO ログを使用してデータを復元し、ACID の D を確保することができます。これが REDO ログの役割です。REDO ログはどのように実装されますか?
REDO ログの書き込みはディスクに直接書き込まれません。REDO ログには、REDO ログ バッファ (REDO ログ バッファ) と呼ばれるバッファもあります。InnoDB エンジンは最初に REDO を書き込みます。 log REDOログ・バッファを書き込み、特定の頻度で実際のREDOログにフラッシュします。通常、REDOログ・バッファは特に大きくする必要はありません。これは単なる一時的なコンテナです。マスター・スレッドがREDOログ・バッファをフラッシュします。したがって、REDO ログ バッファが 1 秒以内にトランザクションによって変更されたデータの量を保存できることを確認するだけで済みます。例として mysql5.7.23 を使用すると、デフォルトは 16M です。mysql> show variables like '%innodb_log_buffer_size%'; +------------------------+----------+ | Variable_name | Value | +------------------------+----------+ | innodb_log_buffer_size | 16777216 | +------------------------+----------+
- master线程每秒将buffer刷到到redo log中
- 每个事务提交的时候会将buffer刷到redo log中
- 当buffer剩余空间小于1/2时,会被刷到redo log中
需要注意的是redo log buffer刷到redo log的过程并不是真正的刷到磁盘中去了,只是刷入到os cache中去,这是现代操作系统为了提高文件写入的效率做的一个优化,真正的写入会交给系统自己来决定(比如os cache足够大了)。那么对于InnoDB来说就存在一个问题,如果交给系统来fsync,同样如果系统宕机,那么数据也丢失了(虽然整个系统宕机的概率还是比较小的)。针对这种情况,InnoDB给出innodb_flush_log_at_trx_commit策略,让用户自己决定使用哪个。
mysql> show variables like 'innodb_flush_log_at_trx_commit'; +--------------------------------+-------+ | Variable_name | Value | +--------------------------------+-------+ | innodb_flush_log_at_trx_commit | 1 | +--------------------------------+-------+
- 0:表示事务提交后,不进行fsync,而是由master每隔1s进行一次重做日志的fysnc
- 1:默认值,每次事务提交的时候同步进行fsync
- 2:写入os cache后,交给操作系统自己决定什么时候fsync
从3种刷入策略来说:
2肯定是效率最高的,但是只要操作系统发生宕机,那么就会丢失os cache中的数据,这种情况下无法满足ACID中的D
0的话,是一种折中的做法,它的IO效率理论是高于1的,低于2的,它的数据安全性理论是要低于1的,高于2的,这种策略也有丢失数据的风险,也无法保证D。
1是默认值,可以保证D,数据绝对不会丢失,但是效率最差的。个人建议使用默认值,虽然操作系统宕机的概率理论小于数据库宕机的概率,但是一般既然使用了事务,那么数据的安全应该是相对来说更重要些。
redo log是对页的物理修改,第x页的第x位置修改成xx,比如:
page(2,4),offset 64,value 2
在InnoDB引擎中,redo log都是以512字节为单位进行存储的,每个存储的单位我们称之为redo log block(重做日志块),若一个页中存储的日志量大于512字节,那么就需要逻辑上切割成多个block进行存储。
一个redo log block是由日志头、日志体、日志尾组成。日志头占用12字节,日志尾占用8字节,所以一个block真正能存储的数据就是512-12-8=492字节。
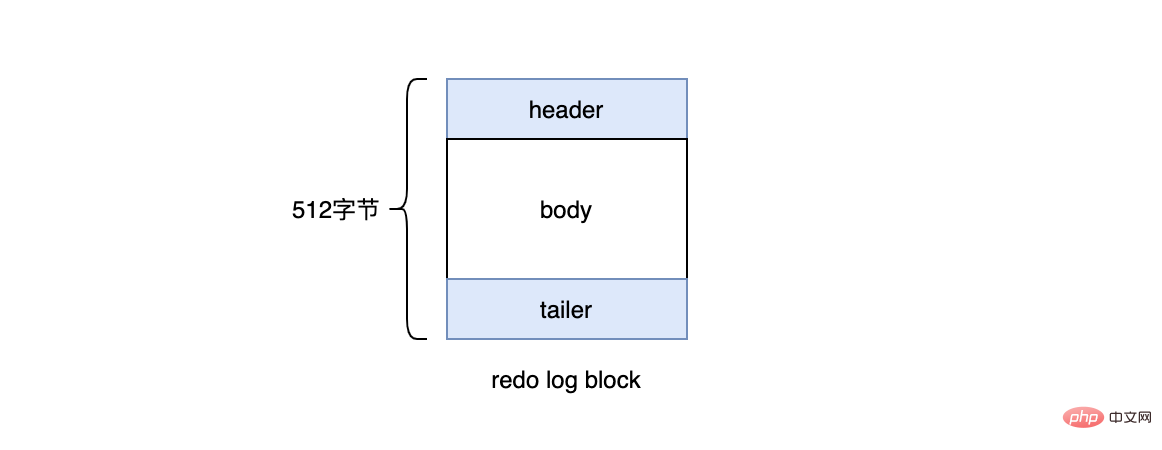
多个redo log block组成了我们的redo log。
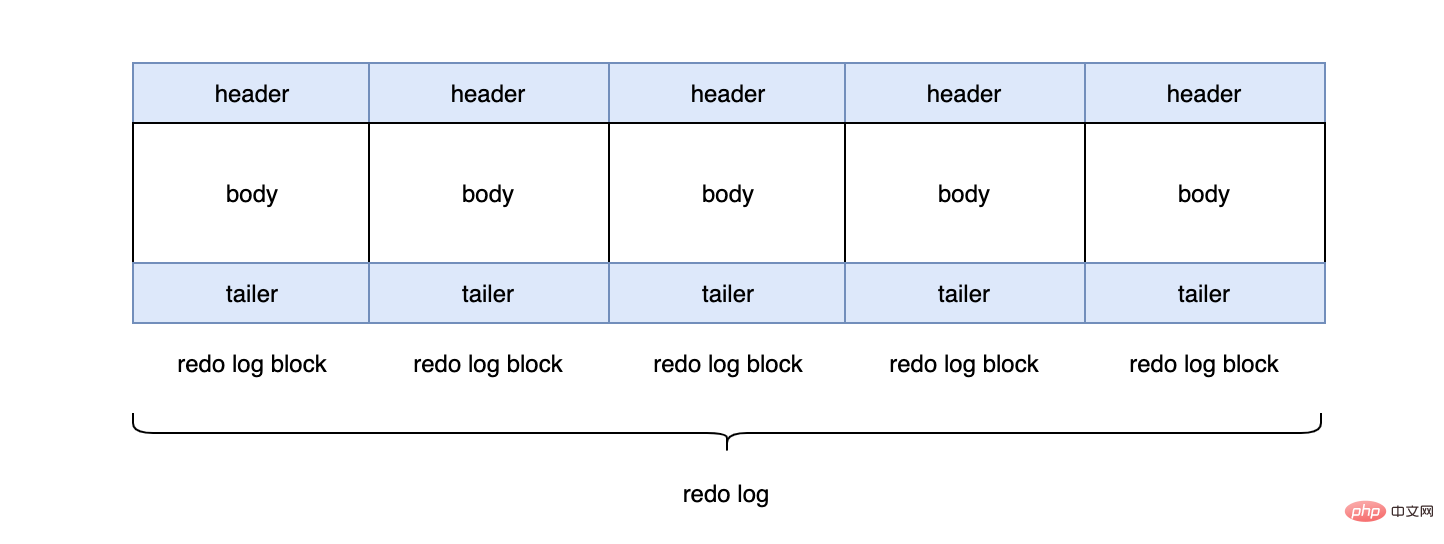
每个redo log默认大小为48M:
mysql> show variables like 'innodb_log_file_size'; +----------------------+----------+ | Variable_name | Value | +----------------------+----------+ | innodb_log_file_size | 50331648 | +----------------------+----------+
InnoDB默认2个redo log组成一个log组,真正工作的就是这个log组。
mysql> show variables like 'innodb_log_files_in_group'; +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | innodb_log_files_in_group | 2 | +---------------------------+-------+ #ib_logfile0 #ib_logfile1
当ib_logfile0写完之后,会写ib_logfile1,当ib_logfile1写完之后,会重新写ib_logfile0...,就这样一直不停的循环写。
为什么一个block设计成512字节?
这个和磁盘的扇区有关,机械磁盘默认的扇区就是512字节,如果你要写入的数据大于512字节,那么要写入的扇区肯定不止一个,这时就要涉及到盘片的转动,找到下一个扇区,假设现在需要写入两个扇区A和B,如果扇区A写入成功,而扇区B写入失败,那么就会出现非原子性的写入,而如果每次只写入和扇区的大小一样的512字节,那么每次的写入都是原子性的。
为什么要两段式提交?
从上文我们知道,事务的提交要先写redo log(prepare),再写binlog,最后再提交(commit)。这里为什么要有个prepare的动作?redo log直接commit状态不行吗?假设redo log直接提交,在写binlog的时候,发生了crash,这时binlog就没有对应的数据,那么所有依靠binlog来恢复数据的slave,就没有对应的数据,导致主从不一致。
所以需要通过两段式(2pc)提交来保证redo log和binlog的一致性是非常有必要的。具体的步骤是:处于prepare状态的redo log,会记录2PC的XID,binlog写入后也会记录2PC的XID,同时会在redo log上打上commit标识。
redo log和bin log是否可以只需要其中一个?
不可以。redo log本身大小是固定的,在写满之后,会重头开始写,会覆盖老数据,因为redo log无法保存所有数据,所以在主从模式下,想要通过redo log来同步数据给从库是行不通的。那么binlog是一定需要的,binlog是mysql的server层产生的,和存储引擎无关,binglog又叫归档日志,当一个binlog file写满之后,会写入到一个新的binlog file中。
所以我们是不是只需要binlog就行了?redo log可以不需要?当然也不行,redo log的作用是提供crash-safe的能力,首先对于一个数据的修改,是先修改缓冲池中的数据页的,这时修改的数据并没有真正的落盘,这主要是因为磁盘的离散读写能力效率低,真正落盘的工作交给master线程定期来处理,好处就是master可以一次性把多个修改一起写入磁盘。
那么此时就有一个问题,当事务commit之后,数据在缓冲区的脏页中,还没来的及刷入磁盘,此时数据库发生了崩溃,那么这条commit的数据即使在数据库恢复后,也无法还原,并不能满足ACID中的D,然后就有了redo log,从流程来看,一个事务的提交必须保证redo log的写入成功,只有redo log写入成功才算事务提交成功,redo log大部分情况是顺序写的磁盘,所以它的效率要高很多。当commit后发生crash的情况下,我们可以通过redo log来恢复数据,这也是为什么需要redo log的原因。
但是事务的提交也需要binlog的写入成功,那为什么不可以通过binlog来恢复未落盘的数据?这是因为binlog不知道哪些数据落盘了,所以不知道哪些数据需要恢复。对于redo log而言,在数据落盘后对应的redo log中的数据会被删除,那么在数据库重启后,只要把redo log中剩下的数据都恢复就行了。
crash后是如何恢复的?
通过两段式提交我们知道redo log和binlog在各个阶段会被打上prepare或者commit的标识,同时还会记录事务的XID,有了这些数据,在数据库重启的时候,会先去redo log里检查所有的事务,如果redo log的事务处于commit状态,那么说明在commit后发生了crash,此时直接把redo log的数据恢复就行了,如果redo log是prepare状态,那么说明commit之前发生了crash,此时binlog的状态决定了当前事务的状态,如果binlog中有对应的XID,说明binlog已经写入成功,只是没来的及提交,此时再次执行commit就行了,如果binlog中找不到对应的XID,说明binlog没写入成功就crash了,那么此时应该执行回滚。
undo log
redo log是事务持久性的保证,undo log是事务原子性的保证。在事务中更新数据的前置操作其实是要先写入一个undo log中的,所以它的流程大致如下:

什么情况下会生成undo log?
undo log的作用就是mvcc(多版本控制)和回滚,我们这里主要说回滚,当我们在事务里insert、update、delete某些数据的时候,就会产生对应的undo log,当我们执行回滚时,通过undo log就可以回到事务开始的样子。需要注意的是回滚并不是修改的物理页,而是逻辑的恢复到最初的样子,比如一个数据A,在事务里被你修改成B,但是此时有另一个事务已经把它修改成了C,如果回滚直接修改数据页把数据改成A,那么C就被覆盖了。
对于InnoDB引擎来说,每个行记录除了记录本身的数据之外,还有几个隐藏的列:
- DB_ROW_ID:如果没有为表显式的定义主键,并且表中也没有定义唯一索引,那么InnoDB会自动为表添加一个row_id的隐藏列作为主键。
- DB_TRX_ID:每个事务都会分配一个事务ID,当对某条记录发生变更时,就会将这个事务的事务ID写入trx_id中。
- DB_ROLL_PTR:回滚指针,本质上就是指向 undo log 的指针。

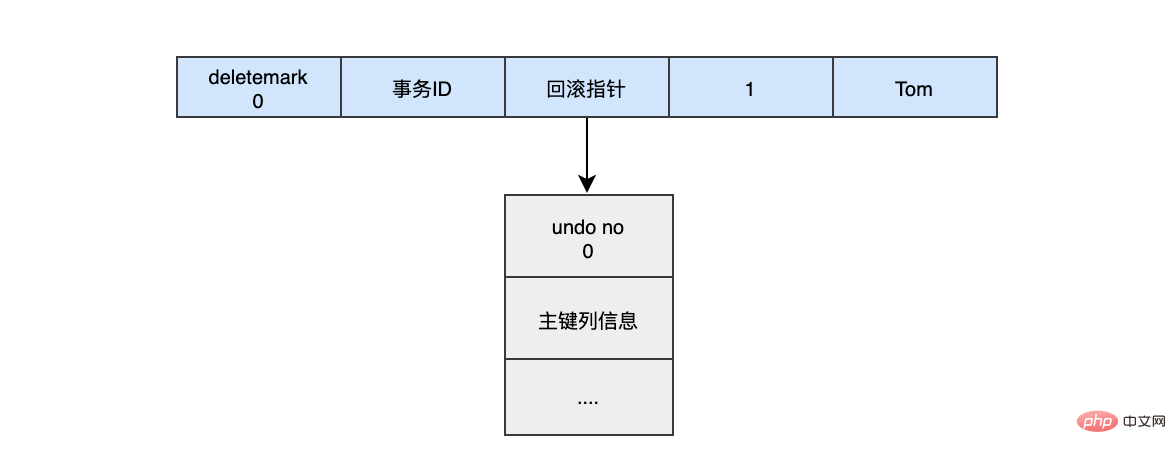
当我们执行INSERT时:
begin;
INSERT INTO user (name) VALUES ("tom")插入的数据都会生一条insert undo log,并且数据的回滚指针会指向它。undo log会记录undo log的序号、插入主键的列和值...,那么在进行rollback的时候,通过主键直接把对应的数据删除即可。
对于更新的操作会产生update undo log,并且会分更新主键的和不更新的主键的,假设现在执行:
UPDATE user SET name="Sun" WHERE id=1;
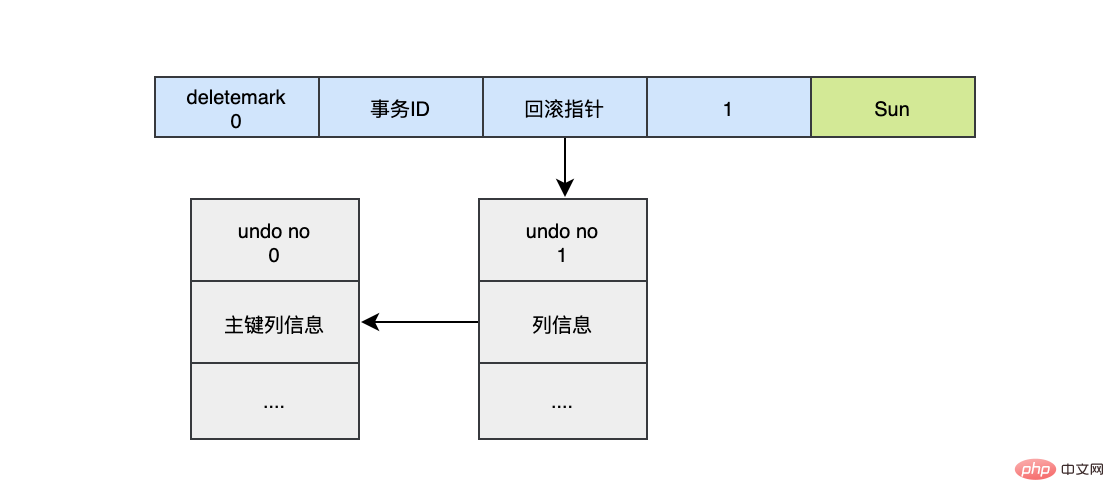
这时会把老的记录写入新的undo log,让回滚指针指向新的undo log,它的undo no是1,并且新的undo log会指向老的undo log(undo no=0)。
假设现在执行:
UPDATE user SET id=2 WHERE id=1;

对于更新主键的操作,会先把原来的数据deletemark标识打开,这时并没有真正的删除数据,真正的删除会交给清理线程去判断,然后在后面插入一条新的数据,新的数据也会产生undo log,并且undo log的序号会递增。
可以发现每次对数据的变更都会产生一个undo log,当一条记录被变更多次时,那么就会产生多条undo log,undo log记录的是变更前的日志,并且每个undo log的序号是递增的,那么当要回滚的时候,按照序号依次向前推,就可以找到我们的原始数据了。
undo log是如何回滚的?
以上面的例子来说,假设执行rollback,那么对应的流程应该是这样:
- 通过undo no=3的日志把id=2的数据删除
- 通过undo no=2的日志把id=1的数据的deletemark还原成0
- 通过undo no=1的日志把id=1的数据的name还原成Tom
- 通过undo no=0的日志把id=1的数据删除
undo log存在什么地方?
InnoDB对undo log的管理采用段的方式,也就是回滚段,每个回滚段记录了1024个undo log segment,InnoDB引擎默认支持128个回滚段
mysql> show variables like 'innodb_undo_logs'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | innodb_undo_logs | 128 | +------------------+-------+
那么能支持的最大并发事务就是128*1024。每个undo log segment就像维护一个有1024个元素的数组。
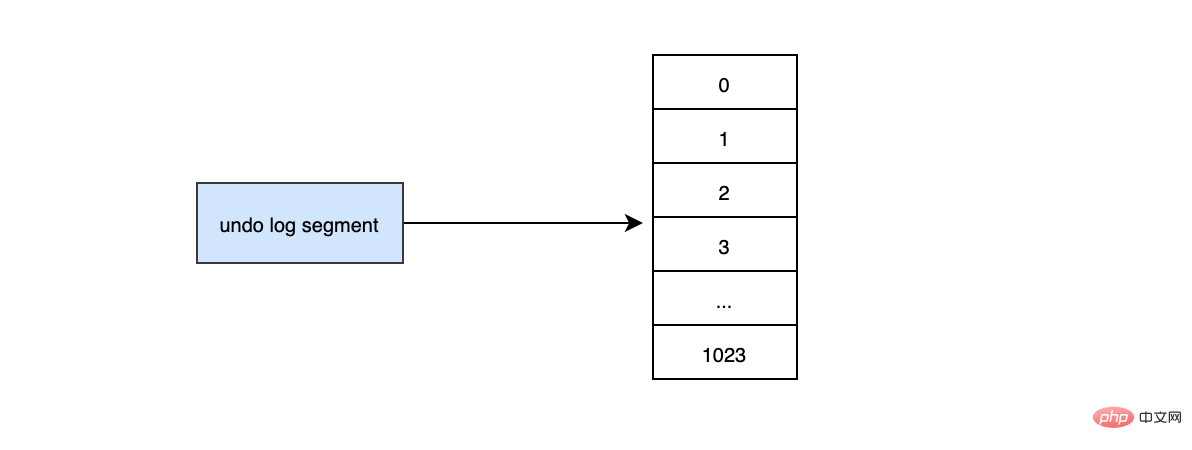
当我们开启个事务需要写undo log的时候,就得先去undo log segment中去找到一个空闲的位置,当有空位的时候,就会去申请undo页,最后会在这个申请到的undo页中进行undo log的写入。我们知道mysql默认一页的大小是16k。
mysql> show variables like '%innodb_page_size%'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | innodb_page_size | 16384 | +------------------+-------+
那么为一个事务就分配一个页,其实是非常浪费的(除非你的事物非常长),假设你的应用的TPS为1000,那么1s就需要1000个页,大概需要16M的存储,1分钟大概需要1G的存储...,如果照这样下去除非mysql清理的非常勤快,否则随着时间的推移,磁盘空间会增长的非常快,而且很多空间都是浪费的。
于是undo页就被设计的可以重用了,当事务提交时,并不会立刻删除undo页,因为重用,这个undo页它可能不干净了,所以这个undo页可能混杂着其他事务的undo log。undo log在commit后,会被放到一个链表中,然后判断undo页的使用空间是否小于3/4,如果小于3/4的话,则表示当前的undo页可以被重用,那么它就不会被回收,其他事务的undo log可以记录在当前undo页的后面。由于undo log是离散的,所以清理对应的磁盘空间时,效率不是那么高。
推荐学习:mysql视频教程
以上が読むとMySQLの永続化とロールバックが理解できる(画像と文章で詳しく解説)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

 MySQLユーザーとデータベースの関係
Apr 08, 2025 pm 07:15 PM
MySQLユーザーとデータベースの関係
Apr 08, 2025 pm 07:15 PM
MySQLデータベースでは、ユーザーとデータベースの関係は、アクセス許可と表によって定義されます。ユーザーには、データベースにアクセスするためのユーザー名とパスワードがあります。許可は助成金コマンドを通じて付与され、テーブルはCreate Tableコマンドによって作成されます。ユーザーとデータベースの関係を確立するには、データベースを作成し、ユーザーを作成してから許可を付与する必要があります。
 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICAT自体はデータベースパスワードを保存せず、暗号化されたパスワードのみを取得できます。解決策:1。パスワードマネージャーを確認します。 2。NAVICATの「パスワードを記憶する」機能を確認します。 3.データベースパスワードをリセットします。 4.データベース管理者に連絡してください。
 MySQLのクエリ最適化は、特に大規模なデータセットを扱う場合、データベースのパフォーマンスを改善するために不可欠です
Apr 08, 2025 pm 07:12 PM
MySQLのクエリ最適化は、特に大規模なデータセットを扱う場合、データベースのパフォーマンスを改善するために不可欠です
Apr 08, 2025 pm 07:12 PM
1.正しいインデックスを使用して、データの量を削減してデータ検索をスピードアップしました。テーブルの列を複数回検索する場合は、その列のインデックスを作成します。あなたまたはあなたのアプリが基準に従って複数の列からのデータが必要な場合、複合インデックス2を作成します2。選択した列のみを避けます。必要な列のすべてを選択すると、より多くのサーバーメモリを使用する場合にのみサーバーが遅くなり、たとえばテーブルにはcreated_atやupdated_atやupdated_atなどの列が含まれます。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MariadBのNAVICATでデータベースパスワードを表示する方法は?
Apr 08, 2025 pm 09:18 PM
MariadBのNAVICATでデータベースパスワードを表示する方法は?
Apr 08, 2025 pm 09:18 PM
Passwordが暗号化された形式で保存されているため、MariadbのNavicatはデータベースパスワードを直接表示できません。データベースのセキュリティを確保するには、パスワードをリセットするには3つの方法があります。NAVICATを介してパスワードをリセットし、複雑なパスワードを設定します。構成ファイルを表示します(推奨されていない、高リスク)。システムコマンドラインツールを使用します(推奨されません。コマンドラインツールに習熟する必要があります)。
 mysqlを表示する方法
Apr 08, 2025 pm 07:21 PM
mysqlを表示する方法
Apr 08, 2025 pm 07:21 PM
次のコマンドでmysqlデータベースを表示します。サーバーに接続します:mysql -u username -pパスワードrun showデータベース。すべての既存のデータベースを取得するコマンド[データベース]を選択します。データベース名を使用します。テーブルを表示:表を表示します。テーブル構造を表示:テーブル名を説明してください。データを表示:[テーブル名]から[ *]を選択します。
 MySQLでテーブルをコピーする方法
Apr 08, 2025 pm 07:24 PM
MySQLでテーブルをコピーする方法
Apr 08, 2025 pm 07:24 PM
MySQLでテーブルをコピーするには、新しいテーブルの作成、データの挿入、外部キーの設定、インデックスのコピー、トリガー、ストアドプロシージャ、および機能が必要です。特定の手順には、同じ構造を持つ新しいテーブルの作成が含まれます。元のテーブルからデータを新しいテーブルに挿入します。同じ外部キーの制約を設定します(元のテーブルに1つがある場合)。同じインデックスを作成します。同じトリガーを作成します(元のテーブルに1つがある場合)。同じストアドプロシージャまたは関数を作成します(元のテーブルが使用されている場合)。
