

Linux スワップは、ディスク上の領域である Linux スワップ パーティションを指します。パーティション、ファイル、またはその 2 つの組み合わせにすることができます。スワップは Windows の仮想メモリに似ています。メモリが不足した場合、ハードディスク領域の一部をメモリに仮想化し、メモリ容量不足の問題を解決します。

#このチュートリアルの動作環境: linux5.9.8 システム、Dell G3 コンピューター。
linux swap
Linux スワップ パーティション (スワップ)、またはメモリ置換スペース (スワップ スペース) は、ディスク上の領域です。パーティション、ファイル、またはそれらの組み合わせです。
SWAP は、Windows システムにおける「仮想メモリ」のように機能します。物理メモリが不足した場合、ハードディスク容量の一部をSWAPパーティション(仮想的にメモリに変換)として使用し、メモリ容量不足の問題を解決します。
SWAP とはスワップの意味で、その名の通り、プロセスが OS にメモリを要求し、メモリが足りないと判断した場合、OS はメモリ上の一時的に使用されていないデータをスワップアウトし、SWAP パーティションに配置します。このプロセスは SWAP OUT と呼ばれます。プロセスがこのデータを必要とし、空き物理メモリがあることを OS が検出すると、SWAP パーティション内のデータを物理メモリにスワップして戻します。このプロセスは SWAP IN と呼ばれます。
もちろん、スワップ サイズには上限があり、スワップが使い果たされると、オペレーティング システムは OOM-Killer メカニズムをトリガーし、最も多くのメモリを消費するプロセスを強制終了してメモリを解放します。
データベース システムはなぜスワップを嫌うのでしょうか?
明らかに、スワップ メカニズムの本来の目的は、物理メモリが使い果たされたときに OOM プロセスを直接荒らす恥ずかしさを軽減することです。しかし、率直に言って、MySQL、Oracal、MongoDB、HBase など、ほとんどすべてのデータベースはスワップを好みません。これは主に次の 2 つの側面に関係します:
1. データベース システムは一般に応答遅延に敏感であり、メモリの代わりにスワップが使用される場合、データベース サービスのパフォーマンスは必然的に許容できないものになります。応答遅延に非常に敏感なシステムの場合、遅延が大きすぎることとサービスが利用できないことの間に違いはありません。サービスが利用できないことよりも深刻なのは、スワップ シナリオでプロセスが停止しないことです。つまり、システムが常に利用できないことになります。 ...もう一度考えてください。スワップを使用せずに直接 oom する方が良い選択なのでしょうか? この方法では、多くの高可用性システムはマスターとスレーブを直接切り替えるため、ユーザーは基本的にそれを意識しません。
2. さらに、HBase などの分散システムの場合、特定のノードがダウンすることは実際には心配しませんが、特定のノードが停止することは心配します。ノードがダウンした場合、一時的に利用できなくなるリクエストは多くても少数ですが、再試行することで回復できます。ただし、ノードがブロックされると、すべての分散リクエストがブロックされ、サーバー側のスレッド リソースが占有されるため、クラスター リクエスト全体がブロックされ、クラスターがダウンすることもあります。
これら 2 つの観点を考慮すると、すべてのデータベースがスワップを好まないのは当然です。
スワップの動作メカニズム
データベースはスワップに関心がないため、swapoff コマンドを使用してスワップを行う必要がありますか?ディスク キャッシュをオフにしますか?機能についてはどうですか?いや、よく考えてみてください、ディスク キャッシュをオフにするということは何を意味するのでしょうか?実際の運用環境では、これほど極端なシステムはありません。世界は決して 0 か 1 のどちらかではないことを知っておく必要があります。誰もが多かれ少なかれ中間を選択するでしょうが、0 に偏っている人もいれば、1 に偏っている人もいます。明らかに、スワップに関しては、データベースはその使用をできるだけ少なくすることを選択する必要があります。 HBase の公式文書に記載されているいくつかの要件は、実際にはこのポリシーを実装すること、つまりスワップの影響を可能な限り軽減することです。自分自身と敵を知ることによってのみ、すべての戦いに勝つことができます。スワップの影響を軽減するには、考えられる疑問を見逃さないように、Linux メモリのリサイクルの仕組みを理解する必要があります。
まず、スワップがどのようにトリガーされるかを見てみましょう。
簡単に言うと、Linux は 2 つのシナリオでメモリ リサイクルをトリガーします。1 つは、メモリ割り当て中に十分な空きメモリがないことが判明した場合にすぐにメモリ リサイクルをトリガーすることです。もう 1 つは、プロセス (swapd プロセス) はシステム メモリを定期的にチェックし、利用可能なメモリが特定のしきい値まで低下した後、メモリのリサイクルをアクティブにトリガーします。最初のシナリオについては特に言うことはありません。次の図に示すように、2 番目のシナリオに注目してみましょう。パラメータ: vm.min_free_kbytes に注目します。これは、システムによって予約されている空きメモリの最小ウォーターマーク [分] を表し、ウォーターマーク [低] とウォーターマーク [高] に影響します。これは単純に次のように考えることができます:
watermark[min] = min_free_kbytes watermark[low] = watermark[min] * 5 / 4 = min_free_kbytes * 5 / 4 watermark[high] = watermark[min] * 3 / 2 = min_free_kbytes * 3 / 2 watermark[high] - watermark[low] = watermark[low] - watermark[min] = min_free_kbytes / 4
LInux のこれらの水位はパラメータ min_free_kbytes から切り離せないことがわかります。システムにとって min_free_kbytes の重要性は自明のことであり、大きすぎたり小さすぎたりすることはできません。 
min_free_kbytes が小さすぎる場合、[min, low] の間の水位バッファーは非常に小さくなります。kswapd リサイクル プロセス中に、上位層がメモリをあまりにも速く適用すると (典型的なアプリケーション: データベース)、空きメモリが非常に小さくなる可能性があります。ウォーターマーク [分] を下回る可能性があります。このとき、カーネルは直接再生 (直接リサイクル) を実行し、アプリケーションのプロセス コンテキストで直接リサイクルし、再生された空きメモリを使用します。メモリ要求を満たすためにページを追加するため、実際にはアプリケーションがブロックされ、一定の応答遅延が発生します。もちろん、min_free_kbytes は大きすぎてはいけません。大きすぎると、アプリケーション プロセスのメモリが減少し、システム メモリ リソースが無駄に消費されます。また、kswapd プロセスの使用量も増加します。メモリのリサイクルに多くの時間を費やします。このプロセスをもう一度見てください。これは、Java ガベージ コレクション メカニズムの CMS アルゴリズムにおける古い世代のリサイクル トリガー メカニズムに似ていますか? パラメーター -XX:CMSInitiatingOccupancyFraction について考えてみてください。公式ドキュメントでは、min_free_kbytes を 1G 未満にすることはできません (大規模なメモリ システムでは 8G に設定)、つまり、直接リサイクルを簡単にトリガーしないようにする必要があります。
ここまで、Linux のメモリ再利用のトリガーメカニズムと、気になる最初のパラメータ vm.min_free_kbytes について、基本的に説明しました。次に、Linux メモリのリサイクルで何がリサイクルされるのかを簡単に見てみましょう。 Linux のメモリ リサイクル オブジェクトは主に 2 つのタイプに分類されます:
1. ファイル キャッシュ、これは理解しやすいですが、ファイル データを毎回ハードディスクから読み取らなくても済むように、システムはホットスポットを保存します。パフォーマンスを向上させるためにメモリ内のデータ。ファイルを読み取るだけの場合、メモリ リサイクルではメモリのこの部分を解放するだけで済み、次回ファイル データを読み取るときは、ハード ディスクから直接読み取ることができます (HBase ファイル キャッシュと同様)。ファイルが読み取られるだけでなく、キャッシュされたファイル データも変更される場合 (ダーティ データ)、メモリを再利用するには、データ ファイルのこの部分をハードディスクに書き込んでから解放する必要があります (MySQL ファイルと同様)キャッシュ)。
2. 匿名メモリ。一般的なヒープ データやスタック データなどのハードディスク ファイルなどのキャリアを持つファイル キャッシュとは異なり、メモリのこの部分には実際のキャリアがありません。メモリのこの部分は、リサイクル中に直接解放したり、ファイルのようなメディアに書き戻したりすることができないため、このタイプのメモリをハードディスクにスワップアウトし、必要に応じて再度ロードするスワップ メカニズムが開発されました。
どのファイル キャッシュまたは匿名メモリをリサイクルする必要があるかを決定するために Linux で使用される特定のアルゴリズムについては、ここでは関係ありません。興味がある場合は、ここを参照してください。しかし、考えなければならない疑問があります。リサイクルできるメモリには 2 つのタイプがあるため、両方のタイプのメモリがリサイクルできる場合、Linux はどのタイプのメモリをリサイクルするかをどのように決定するのでしょうか。それとも両方ともリサイクルされるのでしょうか?これにより、2 番目のパラメータである swappiness が表示されます。この値は、カーネルがスワップをどの程度積極的に使用するかを定義するために使用されます。値が大きいほど、カーネルはスワップを積極的に使用します。値が小さいほど、スワップの使用は少なくなります。陽性。値の範囲は 0 ~ 100 で、デフォルトは 60 です。この交換性はどのようにして実現されるのでしょうか?具体的な原理は非常に複雑ですが、簡単に言うと、swappiness は、メモリのリサイクル中により多くの匿名ページをリサイクルするか、より多くのファイル キャッシュをリサイクルするかを制御することでこの効果を実現します。 swappiness は 100 に等しく、匿名メモリとファイル キャッシュが同じ優先度でリサイクルされることを意味します。デフォルトの 60 は、ファイル キャッシュが最初にリサイクルされることを意味します。ファイル キャッシュが最初にリサイクルされる理由については、次のようにしてもよいでしょう。考えてみてください (ファイル キャッシュをリサイクルする通常の状況では、IO 操作は発生せず、システム パフォーマンスへの影響はほとんどありません)。データベースの場合、スワップは可能な限り回避する必要があるため、0 に設定する必要があります。ここで、0 に設定してもスワップが実行されないわけではないことに注意してください。
これまで、Linux メモリ リサイクルのトリガー メカニズム、Linux メモリ リサイクル オブジェクト、およびスワップについて説明し、パラメーター min_free_kbytes と swappiness について説明しました。次に、スワップに関連する別のパラメータ、zone_reclaim_mode を見てみましょう。ドキュメントには、このパラメータを 0 に設定すると、NUMA のゾーン再利用をオフにできると記載されています。何が起こっているのでしょうか? NUMA に関しては、データベースは再び満足できなくなり、多くの DBA が騙されました。ここで 3 つの小さな質問があります: NUMA とは何ですか? NUMAとスワップの関係は何ですか? zone_reclaim_mode の具体的な意味は何ですか?
NUMA (Non-Uniform Memory Access) は UMA に関連しています。どちらも CPU 設計アーキテクチャです。次の図 (インターネットからの画像) に示すように、初期の CPU は UMA 構造として設計されました。
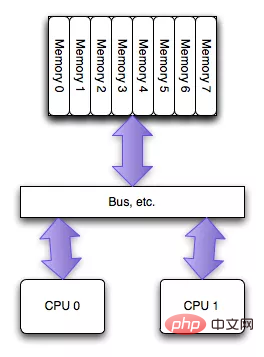
同じメモリを読み取るマルチコア CPU によって発生するチャネルのボトルネック問題を軽減するために、チップ エンジニアは、次の図に示すように NUMA 構造を設計しました (画像は次の図から)
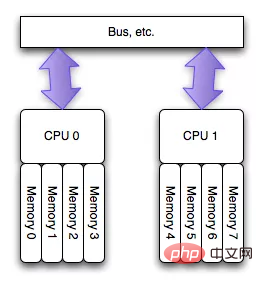
このアーキテクチャは、異なる CPU が排他的なメモリ領域を持つという UMA の問題をうまく解決できます。 CPU 間のサポートも必要です。 ソフトウェア レベルでの 2 つのサポート ポイント:
1. 内存分配需要在请求线程当前所处CPU的专属内存区域进行分配。如果分配到其他CPU专属内存区,势必隔离性会受到一定影响,并且跨越总线的内存访问性能必然会有一定程度降低。
2. 另外,一旦local内存(专属内存)不够用,优先淘汰local内存中的内存页,而不是去查看远程内存区是否会有空闲内存借用。
这样实现,隔离性确实好了,但问题也来了:NUMA这种特性可能会导致CPU内存使用不均衡,部分CPU专属内存不够使用,频繁需要回收,进而可能发生大量swap,系统响应延迟会严重抖动。而与此同时其他部分CPU专属内存可能都很空闲。这就会产生一种怪现象:使用free命令查看当前系统还有部分空闲物理内存,系统却不断发生swap,导致某些应用性能急剧下降。见叶金荣老师的MySQL案例分析:《找到MySQL服务器发生SWAP罪魁祸首》。
所以,对于小内存应用来讲,NUMA所带来的这种问题并不突出,相反,local内存所带来的性能提升相当可观。但是对于数据库这类内存大户来说,NUMA默认策略所带来的稳定性隐患是不可接受的。因此数据库们都强烈要求对NUMA的默认策略进行改进,有两个方面可以进行改进:
1. 将内存分配策略由默认的亲和模式改为interleave模式,即会将内存page打散分配到不同的CPU zone中。通过这种方式解决内存可能分布不均的问题,一定程度上缓解上述案例中的诡异问题。对于MongoDB来说,在启动的时候就会提示使用interleave内存分配策略:
WARNING: You are running on a NUMA machine. We suggest launching mongod like this to avoid performance problems: numactl –interleave=all mongod [other options]
2. 改进内存回收策略:此处终于请出今天的第三个主角参数zone_reclaim_mode,这个参数定义了NUMA架构下不同的内存回收策略,可以取值0/1/3/4,其中0表示在local内存不够用的情况下可以去其他的内存区域分配内存;1表示在local内存不够用的情况下本地先回收再分配;3表示本地回收尽可能先回收文件缓存对象;4表示本地回收优先使用swap回收匿名内存。可见,HBase推荐配置zone_reclaim_mode=0一定程度上降低了swap发生的概率。
不都是swap的事
至此,我们探讨了三个与swap相关的系统参数,并且围绕Linux系统内存分配、swap以及NUMA等知识点对这三个参数进行了深入解读。除此之外,对于数据库系统来说,还有两个非常重要的参数需要特别关注:
1. IO调度策略:这个话题网上有很多解释,在此并不打算详述,只给出结果。通常对于sata盘的OLTP数据库来说,deadline算法调度策略是最优的选择。
2. THP(transparent huge pages)特性关闭。THP特性笔者曾经疑惑过很久,主要疑惑点有两点,其一是THP和HugePage是不是一回事,其二是HBase为什么要求关闭THP。经过前前后后多次查阅相关文档,终于找到一些蛛丝马迹。这里分四个小点来解释THP特性:
(1)什么是HugePage?
网上对HugePage的解释有很多,大家可以检索阅读。简单来说,计算机内存是通过表映射(内存索引表)的方式进行内存寻址,目前系统内存以4KB为一个页,作为内存寻址的最小单元。随着内存不断增大,内存索引表的大小将会不断增大。一台256G内存的机器,如果使用4KB小页, 仅索引表大小就要4G左右。要知道这个索引表是必须装在内存的,而且是在CPU内存,太大就会发生大量miss,内存寻址性能就会下降。
HugePage就是为了解决这个问题,HugePage使用2MB大小的大页代替传统小页来管理内存,这样内存索引表大小就可以控制的很小,进而全部装在CPU内存,防止出现miss。
(2)什么是THP(Transparent Huge Pages)?
HugePage是一种大页理论,那具体怎么使用HugePage特性呢?目前系统提供了两种使用方式,其一称为Static Huge Pages,另一种就是Transparent Huge Pages。前者根据名称就可以知道是一种静态管理策略,需要用户自己根据系统内存大小手动配置大页个数,这样在系统启动的时候就会生成对应个数的大页,后续将不再改变。而Transparent Huge Pages是一种动态管理策略,它会在运行期动态分配大页给应用,并对这些大页进行管理,对用户来说完全透明,不需要进行任何配置。另外,目前THP只针对匿名内存区域。
(3)HBase(数据库)为什么要求关闭THP特性?
THP は、実行時に大きなページを割り当てて管理する動的な管理戦略であるため、ある程度の割り当て遅延が発生します。これは、応答遅延を追求するデータベース システムでは許容できません。さらに、THP には他にも多くの欠点があります。この記事「why-tokudb-hates-transparent-hugepages」を参照してください。
(4) THP のオフ/オンが HBase の読み取りと書き込みにどの程度の影響を与えるかパフォーマンス?
THP のオン/オフが HBase のパフォーマンスにどの程度の影響を与えるかを検証するために、テスト環境で簡単なテストを実行しました。テスト クラスターにはリージョン サーバーが 1 つだけあり、テストの負荷は読み取り/書き込みです。 1:1の比率。 THP には 2 つのオプションがあります。一部のシステムでは「常に」と「決して」、もう 1 つはシステムによっては madvise と呼ばれる追加オプションです。コマンド echo Never/always > /sys/kernel/mm/transparent_hugepage/enabled を使用して、THP をオフ/オンにできます。テスト結果を次の図に示します。

上の図に示すように、TPH シャットダウン シナリオ (決して) では、HBase が最高のパフォーマンスを示し、比較的安定。 THPをON(常時)にしたシーンでは、THPをOFFにしたシーンに比べて30%程度性能が低下し、カーブのジッターが大きくなります。 HBase で THP オンラインを忘れずにオフにすることがわかります。
関連する推奨事項: 「Linux ビデオ チュートリアル 」
以上がLinuxスワップとは何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



