

Oracle の高度な学習を完全にマスターして実行計画を表示する

この記事では、Oracle に関する関連知識を提供し、主に実行計画の表示に関連する問題について紹介します。

推奨チュートリアル: 「Oracle ビデオ チュートリアル 」
今日は、Oracle の実行計画の見方とその表示方法について説明します。実行計画。
1. 実行計画の表示方法
1.1. autotrace の設定
autotrace コマンドは次のとおりです
| #シリアル番号 |
コマンド |
#説明 |
1 |
SET AUTOTRACE OFF |
これはデフォルト値ですこれは、Autotrace がオフになっていることを意味します |
2 |
SET AUTOTRACE ON EXPLAIN |
実行計画のみを表示 |
| ##3 | SET AUTOTRACE ON STATISTICS | |
| SET AUTOTRACE ON |
## の実行のみの統計を表示します # には 2 と 3 の項目が含まれています |
##5 |
| ##SET AUTOTRACE TRACEONLY | ON と似ていますが、ステートメントの実行結果は表示されません |
1.2. サードパーティ ツールを使用するPL/SQL Develop の Explain ウィンドウなど
SQLを実行する前にEXPLAIN PLAN FORを入れると実行計画が確認できるとのことですが、まだよく分かりませんので、例えば について説明しました。 SQL> SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE')); ログイン後にコピー または: SQL> select * from table(dbms_xplan.display); ログイン後にコピー 2. SGA キャッシュをクリアします SQL が実行されると、SQL 実行プラン、ディスクから読み取られたデータベース、およびその他の情報が消去されるためです。 SGA では、一部のキャッシュは一定期間保存されるため、ステートメントの最初の実行の効果を確認するには、これらのキャッシュをクリアする必要があります。ALTER SYSTEM FLUSH SHARED_POOL; ALTER SYSTEM FLUSH BUFFER_CACHE; ALTER SYSTEM FLUSH GLOBAL CONTEXT; ログイン後にコピー 3. 実行計画の分析 3.1. テスト テーブルの作成2 つの新しいテーブル cust_info と cst_tran を作成します (テスト専用で、実用的な意味はありません)CREATE TABLE CUST_INFO (CST_NO NUMBER, CST_NAME VARCHAR2(50), AGE SMALLINT); CREATE TABLE CST_TRAN ( CST_NO NUMBER, TRAN_DATE VARCHAR2(8), TRAN_AMT NUMBER(19,3) ); ログイン後にコピー データを挿入します。CUST_INFO テーブル 10,000、CST_TRAN テーブル 100 万。 INSERT INTO CUST_INFO
SELECT 100000+LEVEL,
'test'||LEVEL,
ROUND(DBMS_RANDOM.VALUE(1,100))
FROM DUAL
CONNECT BY LEVEL<=10000;
INSERT INTO CST_TRAN
WITH AA AS
(SELECT LEVEL FROM DUAL CONNECT BY LEVEL<=100)
SELECT T.CST_NO,
TO_CHAR(SYSDATE - DBMS_RANDOM.VALUE(1,1000),'yyyymmdd'),
ROUND(DBMS_RANDOM.VALUE(1,999999999),3)
FROM CUST_INFO T
INNER JOIN AA
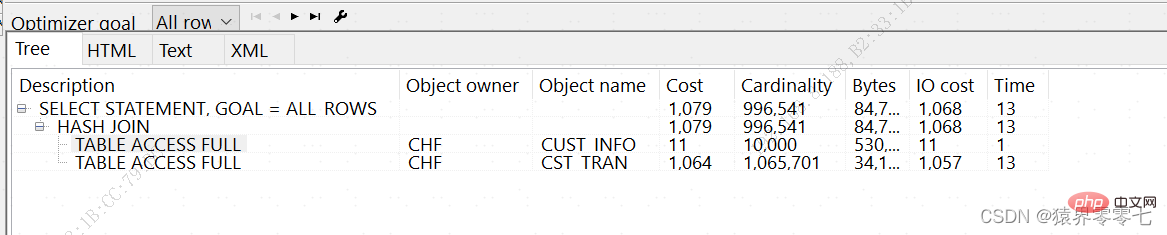
ON 1=1;ログイン後にコピー 3.2. 実行計画の表示 これら 2 つのテーブルに関連付けられた実行計画の表示SQL> SELECT T.CST_NO, T.CST_NAME, G.TRAN_DATE, G.TRAN_AMT FROM CUST_INFO T INNER JOIN CST_TRAN G ON G.CST_NO = T.CST_NO;
1000000 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 2290587575
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 996K| 68M| 1079 (2)| 00:00:13 |
|* 1 | HASH JOIN | | 996K| 68M| 1079 (2)| 00:00:13 |
| 2 | TABLE ACCESS FULL | CUST_INFO | 10000 | 390K| 11 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | CST_TRAN | 1065K| 32M| 1064 (1)| 00:00:13 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("G"."CST_NO"="T"."CST_NO")
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
561 recursive calls
0 db block gets
70483 consistent gets
4389 physical reads
0 redo size
45078003 bytes sent via SQL*Net to client
733845 bytes received via SQL*Net from client
66668 SQL*Net roundtrips to/from client
10 sorts (memory)
0 sorts (disk)
1000000 rows processedログイン後にコピー 3.2.1. 実行計画 最初に見てみましょうパート 1-------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 996K| 68M| 1079 (2)| 00:00:13 | |* 1 | HASH JOIN | | 996K| 68M| 1079 (2)| 00:00:13 | | 2 | TABLE ACCESS FULL | CUST_INFO | 10000 | 390K| 11 (0)| 00:00:01 | | 3 | TABLE ACCESS FULL | CST_TRAN | 1065K| 32M| 1064 (1)| 00:00:13 | -------------------------------------------------------------------------------- ログイン後にコピー ## ID: シリアル番号 (順序ではありません)実行の。実行順序はインデントに基づいて判断されます。 操作: 現在の操作の内容。
1. 操作各ステップの操作を記録し、程度に応じて実行順序を判断します。インデント。 OLAP データベースには多くの HASH JOIN 接続があり、特に返されるデータ セットが大きい場合、基本的に HASH JOIN になります。 2. Rows rows の値は、CBO が行ソースから返すと予想されるレコードの数を示します。この行ソースは、テーブル、インデックス、またはサブクエリの場合があります。 Oracle 9i の実行プランでは、カーディナリティは Card と省略されます。 10gでは、カードの値が行に置き換えられます。 rows 値は、CBOが正しい実行計画を作成するために重要です。 CBO によって取得された行の値が十分に正確でない場合 (通常、分析が不足しているか、分析データが古いため)、実行計画のコスト計算に誤差が生じ、CBO が誤って実行計画を策定することになります。 SQL に複数テーブル関連のクエリやサブクエリがある場合、関連する各テーブルやサブクエリの rows 値がメインクエリに大きな影響を与え、CBO は関連するそれぞれのテーブルやサブクエリに依存するとさえ言えます。または、サブクエリ行の値によって最終的な実行計画が計算されます。 複数テーブルのクエリの場合、CBO は、関連付けられた各テーブルから返された行数 (行数) を使用して、テーブルの関連付けに使用するアクセス方法 (ネストされたループ結合やハッシュ結合など) を決定します。 3. コスト(CPU)と時間は実行計画の重要な参考値です 3.2.2. 述語の説明:述語情報(で識別されます)操作 ID):------------------------------------------ ----- ---1 - アクセス("G"."CST_NO"="T"."CST_NO")
- このステートメントに使用される動的サンプリング (レベル=2) アクセス: この述語条件の値がデータ (テーブルまたはインデックス) のアクセス パスに影響を与えることを示します。 に注意してください。述語の条件とアクセス パスが適切であるかどうかを考慮する必要があります。使用されているのが正しいです。 参数说明: 这个指标的计算方式和一个参数息息相关,arraysize。 arraysize是什么呢? 请查阅大牛博文:Oracle arraysize 和 fetch size 参数 与 性能优化 说明 arraysize定义了一次返回到客户端的行数,取值范围【1-5000】,默认15。 使用命令在数据库中查看arraysize的值。 show arraysize 还可以修改这个值 set arraysize 5000; 明白了arraysize这个参数就可以计算SQL*Net roundtrips to/from client的值了。上例中,返回客户端结果集的行数是1000000,默认arraysize值是15,1000000/15向上取整等于66667。 为啥要向上取整? 举个栗子,如果有10个苹果,一个只能拿3个,几次可以拿完,3次可以拿9个,还剩1个,所以还需要再拿一次,共4次。 统计分析中的值是66668,为什么我们计算的值是66667? 就要看这个指标本身了,再粘贴一次:SQL*Net roundtrips to/from client 重点看from,意思是我们还要接受一次客户端发来的SQL语句,因此是:66667+1,本问题纯属个人臆断,无真凭实据,受限于本人的知识水平,如有误,请指出。 将arraysize的值修改为5000后,再观察SQL*Net roundtrips to/from client的变化,结果为201。 前面提到 arraysize的取值范围是【1-5000】,我们可以试一下改为不在这个区间的值,比如改为0,结果报错了 译为中文就是:一致性读, 好抽象的一个指标,啥叫一致性读,心中无数羊驼驼在大海中狂奔。 官网对consistent gets 的解释: consistent gets:Number of times a consistent read wasrequested for a block. 通常我们执行SQL查询时涉及的每一block都是Consistent Read, 只是有些CR(Consistent Read)需要使用undo 来进行构造, 大部分CR(Consistent Read)并不涉及到undo block的读. 还有就是每次读这个block都是一次CR(可能每个block上有多个数据row), 也就是如果某个block被读了10次, 系统会记录10个Consistent Read. 如果想深入学习,请参考大佬博文:Oracle 有关 Consistent gets 的测试 -- cnDBA.cn_中国DBA社区 接来下测试下, consistent gets是从哪来的,需要使用有sysdba权限的用户,因为oradebug工具需要sysdba权限。 oradebug工具介绍:oracle实用工具:oradebug 使用10046对同一条数据跟踪两次,注意观察 consistent gets的不同 为了不影响测试结果,首先清空缓存 第一次执行 第二次执行 通过对比两次执行,发现consistent gets、physical reads、sorts (memory)都有变化,这是因为SGA中已经缓存了部分数据块。 再对比下我们刚才生产的两个跟踪日志,为方便查看,先将其格式转换以下 打开 /u01/chf1.trc,下面贴出部分重要信息 打开 /u01/chf2.trc,下面贴出部分重要信息 比较发现,第一次执行解析SQL语句,生产执行计划时,consistent gets发生67次,执行SQL语句时发生70301。第一次执行解析SQL语句,生产执行计划时,因已经有缓存,所以consistent gets发生0次,执行SQL语句时发生70301。 推荐教程:《Oracle视频教程》 |
以上がOracle の高度な学習を完全にマスターして実行計画を表示するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7692
7692
 15
1639
14
1393
52
1287
25
1229
29
15
1639
14
1393
52
1287
25
1229
29

 オラクルを開けない場合はどうすればよいですか
Apr 11, 2025 pm 10:06 PM
オラクルを開けない場合はどうすればよいですか
Apr 11, 2025 pm 10:06 PM
Oracleのソリューションを開くことはできません。1。データベースサービスを開始します。 2。リスナーを開始します。 3.ポートの競合を確認します。 4.環境変数を正しく設定します。 5.ファイアウォールまたはウイルス対策ソフトウェアが接続をブロックしないことを確認してください。 6.サーバーが閉じているかどうかを確認します。 7. RMANを使用して破損したファイルを回復します。 8。TNSサービス名が正しいかどうかを確認します。 9.ネットワーク接続を確認します。 10。Oracleソフトウェアを再インストールします。
 Oracle Cursorを閉じる問題を解決する方法
Apr 11, 2025 pm 10:18 PM
Oracle Cursorを閉じる問題を解決する方法
Apr 11, 2025 pm 10:18 PM
Oracle Cursorの閉鎖問題を解決する方法には、次のものが含まれます。 Scopeが終了した後に自動的に閉じるように、for update句のカーソルを宣言します。使用句のカーソルを宣言して、関連するPL/SQL変数が閉じられたときに自動的に閉じるようにします。例外処理を使用して、例外の状況でカーソルが閉じていることを確認します。接続プールを使用して、カーソルを自動的に閉じます。自動送信を無効にし、カーソルの閉鎖を遅延させます。
 Oracleからすべてのデータを削除する方法
Apr 11, 2025 pm 08:36 PM
Oracleからすべてのデータを削除する方法
Apr 11, 2025 pm 08:36 PM
Oracleのすべてのデータを削除するには、次の手順が必要です。1。接続を確立します。 2。外部のキーの制約を無効にします。 3.テーブルデータを削除します。 4.トランザクションを送信します。 5.外部キーの制約を有効にします(オプション)。データの損失を防ぐために、実行前にデータベースを必ずバックアップしてください。
 Oracleデータベースをページングする方法
Apr 11, 2025 pm 08:42 PM
Oracleデータベースをページングする方法
Apr 11, 2025 pm 08:42 PM
Oracle Database Pagingは、Rownum Pseudo-ColumnsまたはFetchステートメントを使用して実装しています。RownumPseudo-Columnsは、行番号ごとに結果をフィルタリングするために使用され、複雑なクエリに適しています。 Fetchステートメントは、指定された最初の行を取得するために使用され、単純なクエリに適しています。
 Oracle Loopでカーソルを作成する方法
Apr 12, 2025 am 06:18 AM
Oracle Loopでカーソルを作成する方法
Apr 12, 2025 am 06:18 AM
Oracleでは、forループループは動的にカーソルを作成できます。手順は次のとおりです。1。カーソルタイプを定義します。 2。ループを作成します。 3.カーソルを動的に作成します。 4。カーソルを実行します。 5。カーソルを閉じます。例:カーソルをサイクルごとに作成して、上位10人の従業員の名前と給与を表示できます。
 Oracleデータベースを停止する方法
Apr 12, 2025 am 06:12 AM
Oracleデータベースを停止する方法
Apr 12, 2025 am 06:12 AM
Oracleデータベースを停止するには、次の手順を実行します。1。データベースに接続します。 2。すぐにシャットダウンします。 3.シャットダウンは完全に中止します。
 Oracle Dynamic SQLを作成する方法
Apr 12, 2025 am 06:06 AM
Oracle Dynamic SQLを作成する方法
Apr 12, 2025 am 06:06 AM
SQLステートメントは、Oracleの動的SQLを使用して、ランタイム入力に基づいて作成および実行できます。手順には、次のものが含まれます。動的に生成されたSQLステートメントを保存するための空の文字列変数を準備します。 executeを即座に使用するか、ステートメントを準備して、動的なSQLステートメントをコンパイルおよび実行します。バインド変数を使用して、ユーザー入力またはその他の動的値を動的SQLに渡します。実行するか、実行するか、動的SQLステートメントを実行します。
 HDFSでCentosを構成するために必要な手順
Apr 14, 2025 pm 06:42 PM
HDFSでCentosを構成するために必要な手順
Apr 14, 2025 pm 06:42 PM
CENTOSシステムにHadoop分散ファイルシステム(HDFS)を構築するには、複数のステップが必要です。この記事では、簡単な構成ガイドを提供します。 1.初期段階でJDKをインストールする準備:すべてのノードにJavadevelopmentKit(JDK)をインストールすると、バージョンはHadoopと互換性がある必要があります。インストールパッケージは、Oracleの公式Webサイトからダウンロードできます。環境変数構成: /etc /プロファイルファイルを編集し、JavaおよびHadoop環境変数を設定して、システムがJDKとHadoopのインストールパスを見つけることができるようにします。 2。セキュリティ構成:SSHパスワードなしログインSSHキーを生成する:各ノードでSSH-KeyGenコマンドを使用する
