
[username/password] [@server] [as sysdba|sysper]
CREATE TABLESPACE tablespace_name DATAFILE 'XX.dbf' SIZE 10m
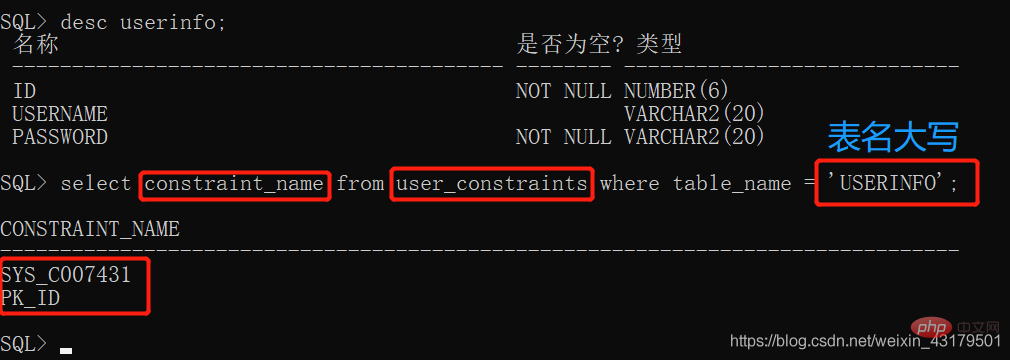
desc dba_data_files
select file_name from dba_data_files where tablespace_name = 'tablespace_name';
ALTER TABLE table_name DROP COLUMN column_name;
ALTER TABLE table_name RENAME COLUMN column_name TO new_column_name;
RENAME table_name TO new_table_name;
TRUNCATE TABLE table_name;

Oracleデータベースを使用するための基礎知識をまとめます。

この記事は、Oracle に関する関連知識を提供します。主に、インストール、アンインストール、テーブル スペース、データ型など、データベースの使用に関する関連問題を要約して紹介します。皆さん、助かります。

推奨チュートリアル: 「Oracle チュートリアル 」
アンインストール
アンインストールを実行します。自動アンインストール用の xml ファイル。実行中に Enter または yes を入力します。削除できないディレクトリは、アンインストールの完了後に手動で削除されます。 
はじめに
システム ユーザー
sys、system (権限 sys>system>scott)
sys にはシステム管理者権限が必要です
システムは直接ログインできます
sysman はエンタープライズ マネージャー、管理者レベルの操作に使用されます
scott Oracle 創設者名、デフォルトのパスワードは Tiger
# # ログイン
システム ユーザーを使用してログインします[username/password] [@server] [as sysdba|sysper]
ログイン後にコピー
[username/password] [@server] [as sysdba|sysper]
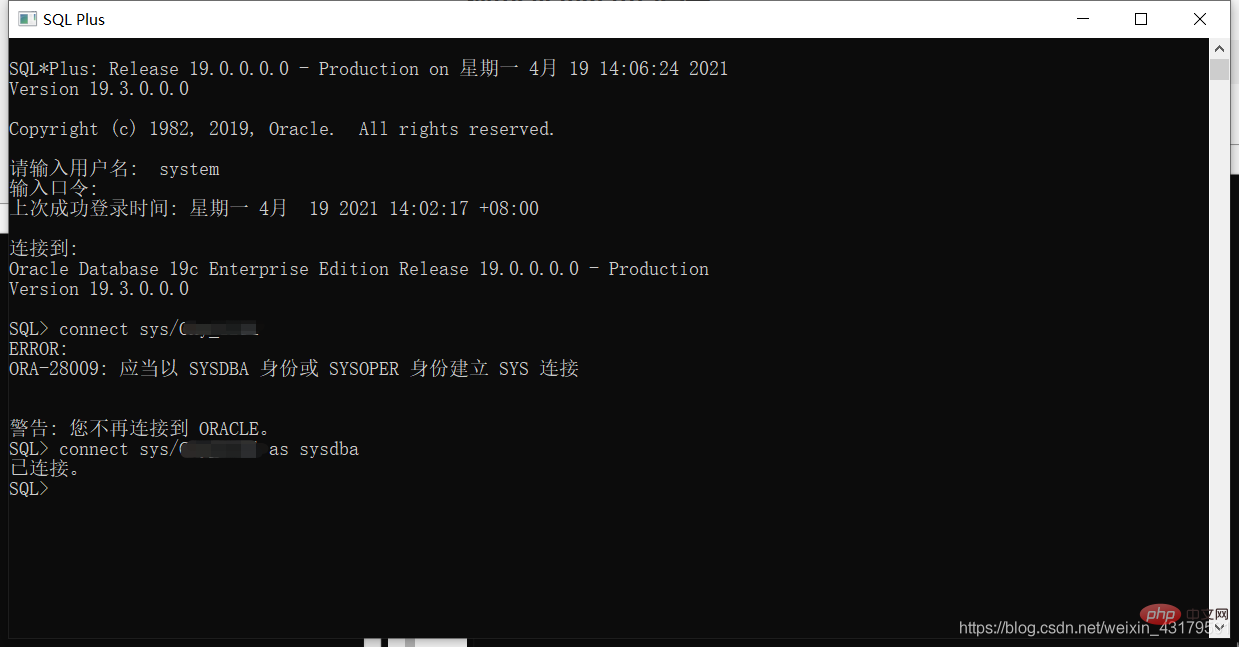
注: ローカル データベースにログインする場合、 @server は必要ありません
- #永続テーブル スペース: テーブル情報、ビュー、ストアド プロシージャ、および永続的に保存する必要があるその他のファイル
- 一時テーブルスペース: データベース操作の途中 実行プロセス中に、実行が完了し、
- UNDO テーブルスペースが解放され、データが保存されます。データが変更されロールバックできる前に
- #ユーザー テーブル スペースを表示します。
一般のユーザー データ ディクショナリ: user_tablespaces 、user_users
ユーザーのデフォルトまたは一時表スペースを設定します
ALTER USER username DEFAULT|TEMPOPRRY TABLESPACE tablespace_name
CREATE TABLESPACE tablespace_name DATAFILE 'XX.dbf' SIZE 10m
ログイン後にコピー
一時表スペースを作成しますCREATE TABLESPACE tablespace_name DATAFILE 'XX.dbf' SIZE 10m
CREATE TEMPORARY TABLESPACE tablespace_name TEMPFILE 'XX.dbf' SIZE 10m
ログイン後にコピー
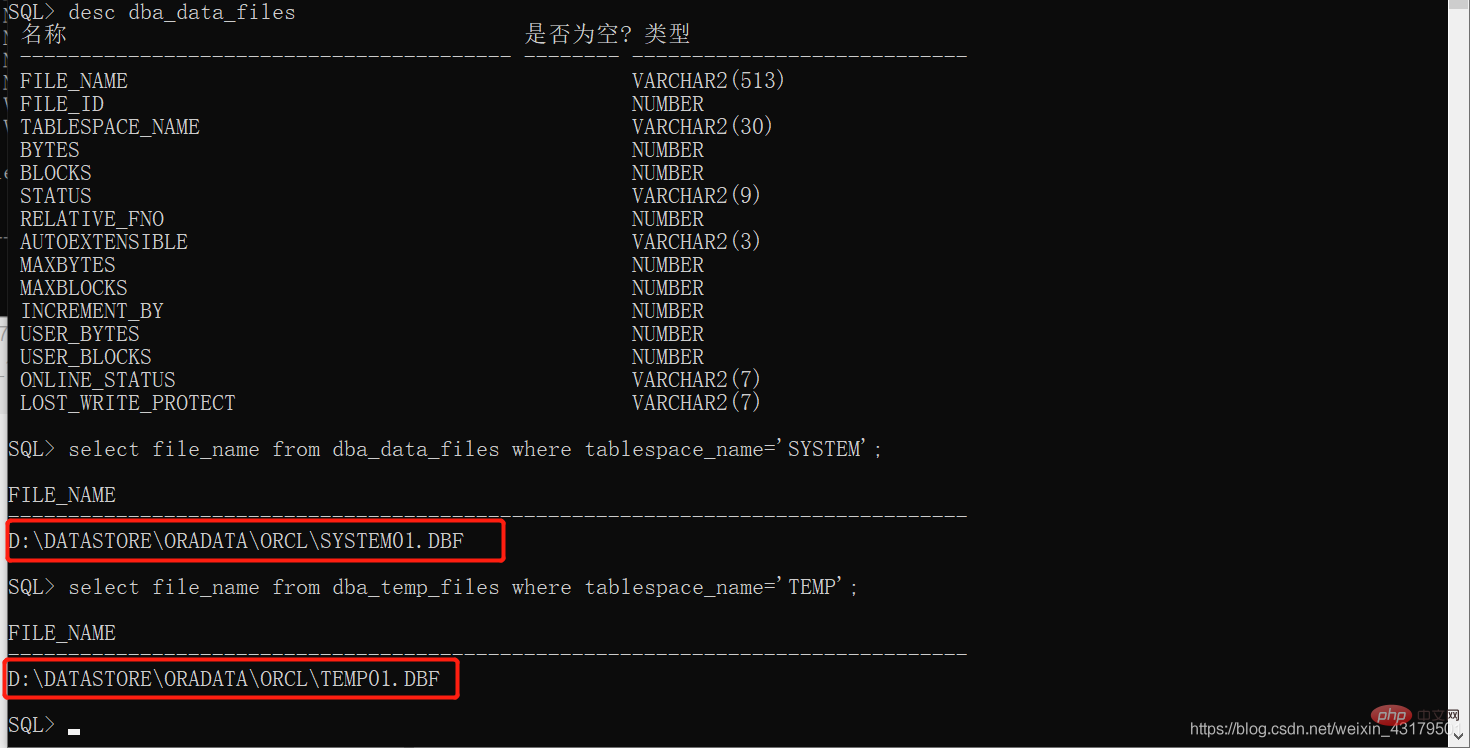
データ ファイル ディクショナリの表示CREATE TEMPORARY TABLESPACE tablespace_name TEMPFILE 'XX.dbf' SIZE 10m
desc dba_data_files
ログイン後にコピー
表スペース ファイルのストレージ パスの表示desc dba_data_files
select file_name from dba_data_files where tablespace_name = 'tablespace_name';
ログイン後にコピー
select file_name from dba_data_files where tablespace_name = 'tablespace_name';
ALTER TABLESPACE tablespace_name ONLINE|OFFLINE; 読み取り専用または読み取り/書き込みステータスを設定します:
ALTER TABLESPACE tablespace_name READ ONLY|READ WRITE; #テーブルスペース変更データファイル
データファイルの追加:
ALTER TABLESPACE tablespace_nama ADD DATAFILE 'xx.dbf' SIZE xx; データファイルの削除: ALTER TABLESPACE tablespace_nama DROP DATAFILE 'xx.dbf';
(テーブルスペースを削除しないと最初のデータファイルは削除できません)テーブルスペースの削除
DROP TABLESPACE tablespace_name [INCLUDING CONTENTS]
データ型
文字タイプCHAR(n): MAX-2000
NCHAR(n): MAX-1000、Unicode形式、より多くの中国語文字を格納 VARCHAR2(n): MAX-4000
NVARCHAR2(n): MAX-2000、unicode 形式
NUMBER(p, s): p-有効桁数、s-数値保持する小数点以下の桁数
FLOAT(n): 1 ~ 126 ビットのバイナリ データ (*0.30103 は 10 進データを取得します)DATE:秒までの精度
TIMESTAMP: ミリ秒までの精度
#その他の種類の大きなファイル
BLOB: 4G バイナリ CLOB: 4G 文字列
テーブルの管理
フィールドの追加
ALTER TABLE table_name add column_name data_type;
ALTER TABLE table_name MODIFY column_name data_type;
ログイン後にコピー
フィールドの削除ALTER TABLE table_name MODIFY column_name data_type;
ALTER TABLE table_name DROP COLUMN column_name;
ログイン後にコピー
フィールド名を変更ALTER TABLE table_name DROP COLUMN column_name;
ALTER TABLE table_name RENAME COLUMN column_name TO new_column_name;
ログイン後にコピー
テーブル名を変更ALTER TABLE table_name RENAME COLUMN column_name TO new_column_name;
RENAME table_name TO new_table_name;
ログイン後にコピー
テーブルを削除削除よりも高速で、何もせずにすべてのデータを削除します。テーブル構造を削除します。 RENAME table_name TO new_table_name;
TRUNCATE TABLE table_name;
ログイン後にコピー
テーブル構造の削除
TRUNCATE TABLE table_name;
DROP TABLE table_name;
在创建时复制表
CREATE TABLE new_table AS SELECT column1,...|* FROM old_table;
在添加时复制表
INSERT INTO new_table [(column1,...)] SELECT column1,...|* FROM old_table;
约束 :定义规则和确保完整性
非空约束:数据不能是NULL值,如用户名、密码等(设置非空约束之前表中不能有空数据)
主键约束:唯一标识,不能为空,加快查询速度,自动创建索引。一张表只能设计一个,可以由多个字段构成(联合或复合主键)。


启用|禁用当前约束
DISABLE | ENABLE CONSTARINT constraint_name;
删除当前约束
ALTER TABLE table_name DROP CONSTRAINT constraint_name;
DROP PRIMARY KEY [CASCADE] ; [CASCADE] :外键约束关系
外键约束:主表的字段必须是主键,主从表中响应的字段是同一个数据类型,从表外键字段值必须来自主表中相应字段值,或者为null值。
创建表时添加外键约束
CREATE TABLE table2 (column_name datatype REFERENCES table1(column_name));

CONSTRAINT constraint_name FOREIGN KEY(column_name) REFERENCES table_name(column_name) [ON DELETE CASCADE]

修改表时添加外键约束
ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY(column_name) REFERENCES table_name(column_name) [ON DELETE CASCSDE] ; [ON DELETE CASCSDE]:级联删除
唯一约束:字段值不能重复
唯一约束和主键约束的区别
主键必须是非空,唯一约束允许有一个空值。主键在每张表中只能有一个,唯一约束在每张表中可以有多个。

修改表时添加唯一约束
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(column_name);
检查约束:使表当中的值具有实际意义。

修改表时添加检查约束
ALTER TABLE table_name ADD CONSTRAINT constraint_name CHECK(column_name > 0);
查询
替换列的显示名称

设置数据格式
更改字符长度(字符类型)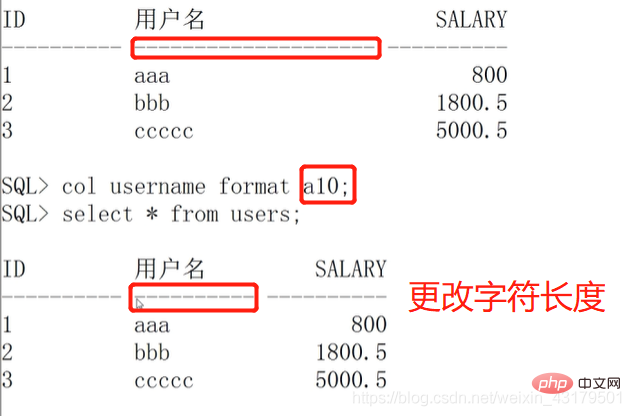
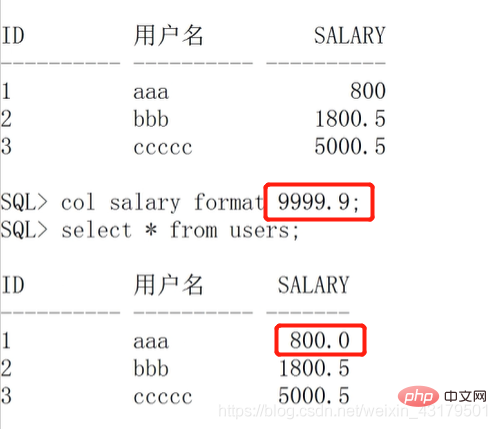
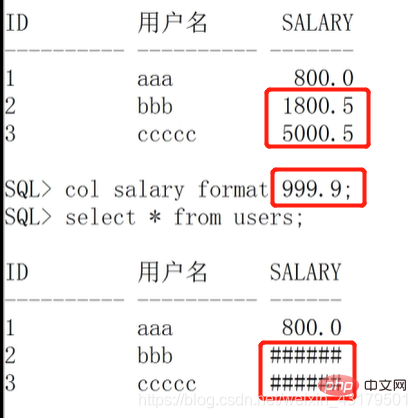
== 数值类型格式(“9”代表一个数字)==

== 清除设置的格式==
COLUMN column_name CLEAR;
函数
函数的作用
- 方便数据统计
- 处理查询结果
函数的分类Oracleデータベースを使用するための基礎知識をまとめます。数值函数
四舍五入: ROUND(n,[,m]) ; 省略m : m = 0 取整; m>0 : 保留小数点后m位;m 取整函数:CEIL(n) - 整数最大值
FLOOR(n) - 整数最小值
常用计算:ABS(n) - 绝对值
MOD(m,n) 取余数 m/n ,m和n有一个值为null,结果返回NULL
POWER(m,n) 返回m的n次幂,m和n有一个值为null,结果返回NULL
SORT(n) 平方根
三角函数:…
字符函数
大小写转换:UPPER(char)
LOWER(char)
INITCAP(char) : 首字母大写
获取子字符串:n可以省略,截取到最后;m
获取字符串长度:LENGTH(char)
字符串连接:CONCAT(char1,char2) 与 || 操作符作用一样
去除字串:TRIM(c2 FROM c1) 从c1当中去除c2字符串
LTRIM(c1 [, c2]) 从头部开始去除一个c2 ,c2 为空去除左边空格
LTRIM(c1 [, c2]) 从尾部开始去除一个c2,c2 为空去除右边空格
TRIM(c1) 去除空格
替换函数:REPLACE(char,s_string [,r_string]) r_string为空默认替换为空串
日期函数
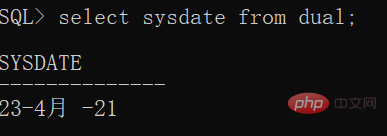
系统时间: SYDATE 默认格式 DD-MON-YY
ADD_MONTHS(date,i)
NEXT_DAY(date,char)
LAST_DAY(date)
MONTHS_BETWEEN(date1.date2) 两个日期之间间隔的月份,计算间隔多少天直接日期相减
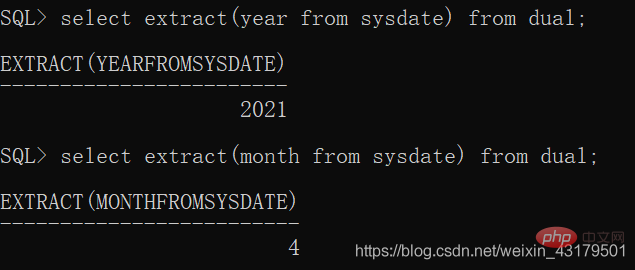
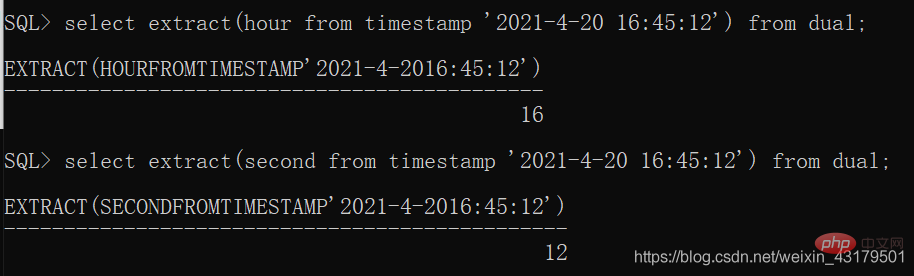
EXTRACT(date FROM datetime)
转换函数
日期>>字符:TO_CHAR(date[,format[,params]]) date:将要转换的日期 ; format:转换的格式; params: 日期的语言,通常不写;
字符>>日期:TO_DATE(date[,format[,params]]) --------只能输出默认日期格式
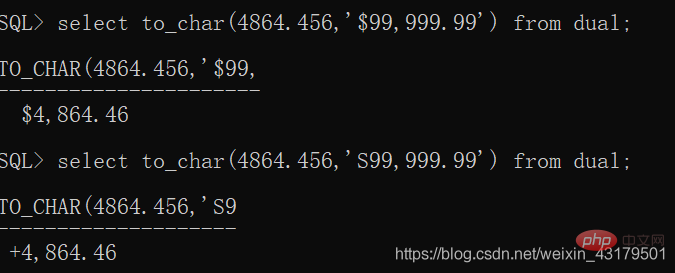
数字>>字符:TO_CHAR(number[,format])
9: 显示数字并忽略前面的0
0:显示数字,位数不足,用0补齐
. 或D 显示小数点
, 或G 显示千位符
$:美元符号
S:加正负号(前后都可以)
字符>>数字:TO_NUMBER(char[,format])


decode函数(都不满足返回null)
decode(column_name, value1,result1,... , defaultValue)

你问我答:
联合索引比单索引的效率高么?
如果联合索引中的多个字段都在where谓词中出现了,则联合索引效率比单列索引高。因为通过多个条件可以从索引中过滤得到更少的记录条数,也就减少了需要回表扫描的次数,甚至可以直接在联合索引中得到所查的所有结果,则不再需要回表。
但是由于多列的联合索引肯定要比单列索引大,也就是说同样的索引需要存储的物理块要多于单列索引,所以,如果查询中只出现了联合索引中的某一列,则其效率不如单列索引。
前导列的作用?
前导列的概念是这样的,如果建立了f1,f2上的联合索引,则在查询时必须要用到f1,也就是所谓的前导列,该索引才会有效,因为索引是按照前导列排序的,如果where条件谓词中没有前导列,则需要执行索引扫描才能得到想要的结果,这种情况下其效率往往较差。
如果不需要前导列的话,reverse 这个反转又起到什么作用呢?
鉴于前面描述的前导列的概念,我们考虑如下表存储table(f1,f2);
aa 1
ab 2
ac 3
ad 4
ae 5
如果我们对表table建立f1上的普通索引,由于按照f1进行排序,所以针对where f1=ad则需要遍历所有的a开始的索引,而如果对f1建立reverse索引,则由于da只有一个,则可以更快的得到需要的结果。
推荐教程:《Oracle视频教程》
以上がOracleデータベースを使用するための基礎知識をまとめます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7681
7681
 15
1639
14
1393
52
1286
25
1229
29
15
1639
14
1393
52
1286
25
1229
29

 オラクルを開けない場合はどうすればよいですか
Apr 11, 2025 pm 10:06 PM
オラクルを開けない場合はどうすればよいですか
Apr 11, 2025 pm 10:06 PM
Oracleのソリューションを開くことはできません。1。データベースサービスを開始します。 2。リスナーを開始します。 3.ポートの競合を確認します。 4.環境変数を正しく設定します。 5.ファイアウォールまたはウイルス対策ソフトウェアが接続をブロックしないことを確認してください。 6.サーバーが閉じているかどうかを確認します。 7. RMANを使用して破損したファイルを回復します。 8。TNSサービス名が正しいかどうかを確認します。 9.ネットワーク接続を確認します。 10。Oracleソフトウェアを再インストールします。
 Oracleからすべてのデータを削除する方法
Apr 11, 2025 pm 08:36 PM
Oracleからすべてのデータを削除する方法
Apr 11, 2025 pm 08:36 PM
Oracleのすべてのデータを削除するには、次の手順が必要です。1。接続を確立します。 2。外部のキーの制約を無効にします。 3.テーブルデータを削除します。 4.トランザクションを送信します。 5.外部キーの制約を有効にします(オプション)。データの損失を防ぐために、実行前にデータベースを必ずバックアップしてください。
 Oracle Cursorを閉じる問題を解決する方法
Apr 11, 2025 pm 10:18 PM
Oracle Cursorを閉じる問題を解決する方法
Apr 11, 2025 pm 10:18 PM
Oracle Cursorの閉鎖問題を解決する方法には、次のものが含まれます。 Scopeが終了した後に自動的に閉じるように、for update句のカーソルを宣言します。使用句のカーソルを宣言して、関連するPL/SQL変数が閉じられたときに自動的に閉じるようにします。例外処理を使用して、例外の状況でカーソルが閉じていることを確認します。接続プールを使用して、カーソルを自動的に閉じます。自動送信を無効にし、カーソルの閉鎖を遅延させます。
 Oracle Loopでカーソルを作成する方法
Apr 12, 2025 am 06:18 AM
Oracle Loopでカーソルを作成する方法
Apr 12, 2025 am 06:18 AM
Oracleでは、forループループは動的にカーソルを作成できます。手順は次のとおりです。1。カーソルタイプを定義します。 2。ループを作成します。 3.カーソルを動的に作成します。 4。カーソルを実行します。 5。カーソルを閉じます。例:カーソルをサイクルごとに作成して、上位10人の従業員の名前と給与を表示できます。
 Oracleデータベースをページングする方法
Apr 11, 2025 pm 08:42 PM
Oracleデータベースをページングする方法
Apr 11, 2025 pm 08:42 PM
Oracle Database Pagingは、Rownum Pseudo-ColumnsまたはFetchステートメントを使用して実装しています。RownumPseudo-Columnsは、行番号ごとに結果をフィルタリングするために使用され、複雑なクエリに適しています。 Fetchステートメントは、指定された最初の行を取得するために使用され、単純なクエリに適しています。
 Oracleデータベースを停止する方法
Apr 12, 2025 am 06:12 AM
Oracleデータベースを停止する方法
Apr 12, 2025 am 06:12 AM
Oracleデータベースを停止するには、次の手順を実行します。1。データベースに接続します。 2。すぐにシャットダウンします。 3.シャットダウンは完全に中止します。
 Oracle Dynamic SQLを作成する方法
Apr 12, 2025 am 06:06 AM
Oracle Dynamic SQLを作成する方法
Apr 12, 2025 am 06:06 AM
SQLステートメントは、Oracleの動的SQLを使用して、ランタイム入力に基づいて作成および実行できます。手順には、次のものが含まれます。動的に生成されたSQLステートメントを保存するための空の文字列変数を準備します。 executeを即座に使用するか、ステートメントを準備して、動的なSQLステートメントをコンパイルおよび実行します。バインド変数を使用して、ユーザー入力またはその他の動的値を動的SQLに渡します。実行するか、実行するか、動的SQLステートメントを実行します。
 HDFSでCentosを構成するために必要な手順
Apr 14, 2025 pm 06:42 PM
HDFSでCentosを構成するために必要な手順
Apr 14, 2025 pm 06:42 PM
CENTOSシステムにHadoop分散ファイルシステム(HDFS)を構築するには、複数のステップが必要です。この記事では、簡単な構成ガイドを提供します。 1.初期段階でJDKをインストールする準備:すべてのノードにJavadevelopmentKit(JDK)をインストールすると、バージョンはHadoopと互換性がある必要があります。インストールパッケージは、Oracleの公式Webサイトからダウンロードできます。環境変数構成: /etc /プロファイルファイルを編集し、JavaおよびHadoop環境変数を設定して、システムがJDKとHadoopのインストールパスを見つけることができるようにします。 2。セキュリティ構成:SSHパスワードなしログインSSHキーを生成する:各ノードでSSH-KeyGenコマンドを使用する
