
この記事では、Oracle に関する関連知識を提供します。主にデータベース アーキテクチャに関連する問題を紹介します。Oracle DB サーバーは、Oracle DB と 1 つ以上のデータベース インスタンスで構成されます。例は、メモリで構成されます。構造と背景プロセスについて説明しますので、皆様のお役に立てれば幸いです。

推奨チュートリアル: 「Oracle チュートリアル 」
Oracle DB サーバーは、Oracle DB と1 つまたは複数のデータベース インスタンス。インスタンスはメモリ構造とバックグラウンドプロセスで構成されます。インスタンスが起動されるたびに、システム グローバル領域 (SGA) と呼ばれる共有メモリ領域が割り当てられ、バックグラウンド プロセスが開始されます。
データベースには物理構造と論理構造が含まれます。物理構造と論理構造が分離されているため、データの物理ストレージを管理する場合、論理ストレージ構造へのアクセスは影響を受けません。 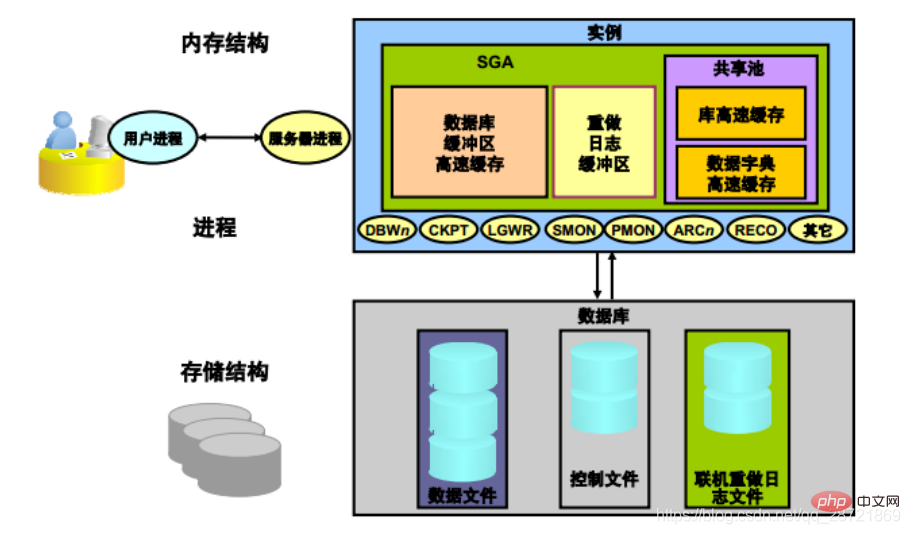
Oracle インスタンスは、メモリ構造とプロセスを使用してデータベースを管理し、データベースにアクセスします。すべてのメモリ構造は、データベース サーバーを構成するコンピュータのメイン メモリに存在します。プロセスは、これらのコンピューターのメモリ内で実行されるジョブです。プロセスは、一連のステップを実行するオペレーティング システムの「制御のスレッド」またはメカニズムとして定義されます。
Oracle インスタンスには、関連する 2 つの基本的なメモリ構造があります。
1. システム グローバル領域 (SGA)
は、SGA コンポーネント グループと呼ばれます。 Oracle DB インスタンスのデータと制御情報を含む共有メモリ構造。 SGA は、すべてのサーバーとバックグラウンド プロセスによって共有されます。 SGA に格納されるデータの例には、キャッシュされたデータ ブロックや共有 SQL 領域などがあります。
SGA は、インスタンスのデータと制御情報を含むメモリ領域です。 SGA には次のデータ構造が含まれます。
• データベース バッファ キャッシュ: データベースから取得したデータ ブロックをキャッシュするために使用されます。
• REDO ログ バッファ: 物理 REDO ログに書き込めるようになるまで、インスタンスのリカバリに使用される REDO 情報をキャッシュするために使用されます。ディスクに保存されるファイル
• 共有プール: ユーザー間で共有できるさまざまな構造をキャッシュするために使用されます
• 大規模プール: Oracle のバックアップおよびリカバリ操作などの特定の大規模プロセスに使用され、I/O サーバー プロセスはオプションで提供します。大きなメモリ割り当てが行われる領域。
• Java プール: Java 仮想マシン (JVM) 内のセッション固有のすべての Java コードとデータに使用されます
• ストリーム プール: 操作の取得と適用に必要な情報を格納するために Oracle Streams によって使用されます
2. プログラム グローバル領域 (PGA)
サーバー プロセスまたはバックグラウンド プロセスのデータと制御情報を含むメモリ領域。
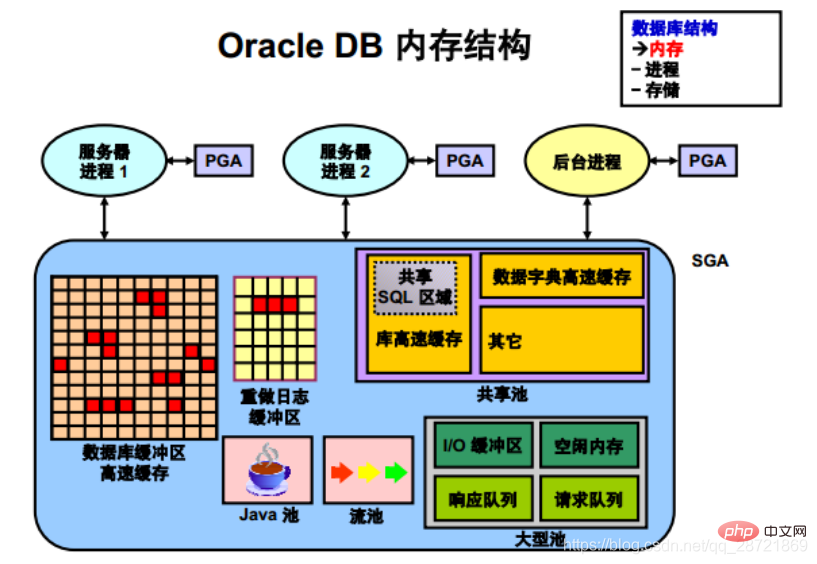
PGA は、サーバー プロセスまたはバックグラウンド プロセスの開始時に Oracle DB によって作成される非共有メモリです。サーバー・プロセスによるPGAへのアクセスは相互に排他的です。各サーバー プロセスとバックグラウンド プロセスには独自の PGA があります。
プログラム グローバル領域 (PGA) は、各サーバー プロセスのデータと制御情報を含むメモリ領域です。 Oracle サーバーはサービス クライアントのリクエストを処理します。各サーバー・プロセスには独自の専用のPGAがあり、サーバー・プロセスの起動時に作成されます。PGAへのアクセスはそのサーバー・プロセスに制限されており、そのサーバー・プロセスに代わってOracleコードによってのみ読み書きできます。
Oracle DB は、初期化パラメータを使用してメモリ構造を作成および管理します。メモリを管理する最も簡単な方法は、データベースにメモリを自動的に管理および最適化させることです。これを行うには (以下はほとんどのプラットフォームで機能します)、ターゲット メモリ サイズの初期化パラメータ (MEMORY_TARGET) と最大メモリ サイズの初期化パラメータ (MEMORY_MAX_TARGET) を設定するだけです。
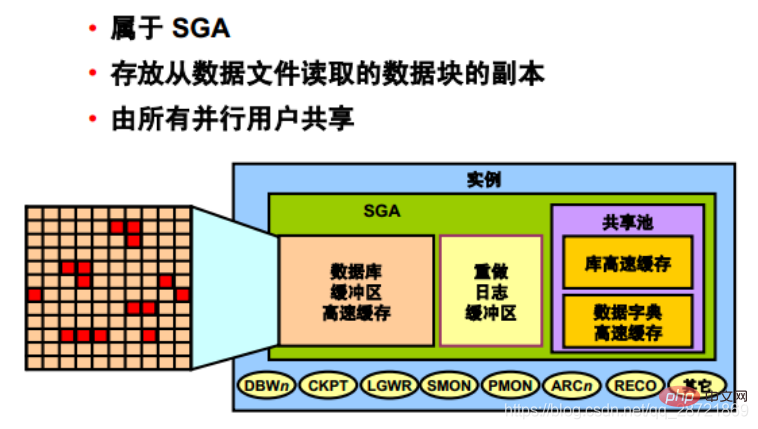
データベース バッファ キャッシュは SGA の一部であり、データ ファイルから読み取られたデータ ブロックのコピーを保存するために使用されます。インスタンスに並行して接続しているすべてのユーザーは、データベース バッファ キャッシュへのアクセスを共有します。
Oracle DB ユーザー・プロセスは、初めて特定のデータを必要とするときに、データベース・バッファ・キャッシュでデータを検索します。
プロセスがキャッシュ内でデータを見つけた場合 (キャッシュ ヒットと呼ばれます)、データはメモリから直接読み取られます。プロセスがキャッシュ内でデータを見つけられない場合 (キャッシュ ミスと呼ばれます)、データにアクセスするには、ディスク上のデータ ファイルのデータ ブロックをキャッシュ内のバッファにコピーする必要があります。キャッシュ ヒット時のデータ アクセスは、キャッシュ ミス時のデータ アクセスよりも高速です。
キャッシュ内のバッファは、最も最近使用されていない (LRU) リストとドック カウント メカニズムを組み合わせた複雑なアルゴリズムによって管理されます。
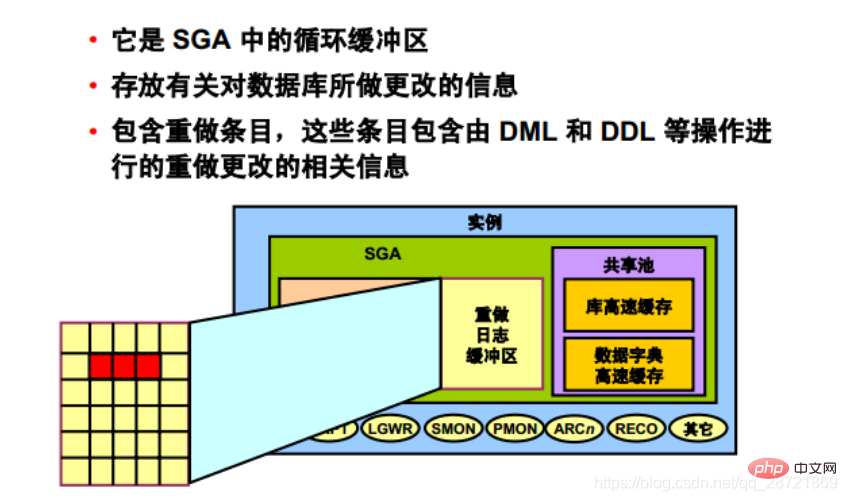
REDO ログ バッファは、データベースに加えられた変更に関する情報を格納する SGA の循環バッファです。この情報はREDOエントリに保存されます。 REDO エントリには、DML、DDL、または内部操作によってデータベースに加えられた変更を再構築 (またはやり直し) するために必要な情報が含まれています。必要に応じて、REDO エントリがデータベースの回復に使用されます。
サーバー・プロセスがバッファ・キャッシュを変更すると、REDOエントリが生成され、SGAのREDOログ・バッファに書き込まれます。 REDO エントリは、バッファ内の連続したシーケンシャル領域を占有します。 LGWR バックグラウンド プロセスは、ディスク上のアクティブな REDO ログ ファイル (またはファイル グループ) に REDO ログ バッファを書き込みます。
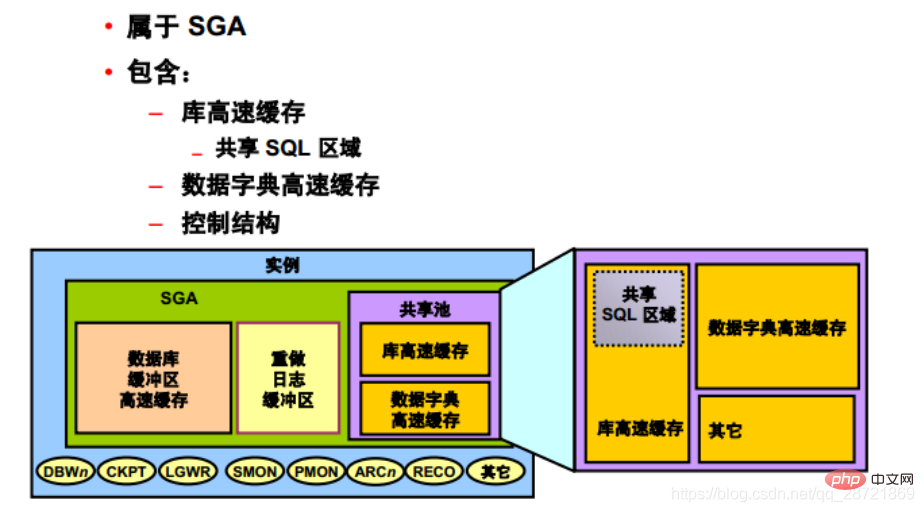
SGAの共有プール部分には、ライブラリ・キャッシュ、データ・ディクショナリ・キャッシュ、SQL問合せ結果キャッシュ、PL/SQL関数結果キャッシュ、並列処理実行メッセージ・バッファが含まれます。そして制御構造。
「データ ディクショナリ」は、データベース、その構造、およびそのユーザーに関する参照情報を含むデータベース テーブルとビューのコレクションです。 SQL 文の解析中、Oracle DB はデータ ディクショナリに頻繁にアクセスします。このアクセス操作は、Oracle DB の継続的な操作にとって重要です。
Oracle DB はデータ ディクショナリに非常に頻繁にアクセスするため、ディクショナリ データを格納するためにメモリ内の 2 つの特別な場所が指定されます。
領域は「データ ディクショナリ キャッシュ」と呼ばれ、バッファの形式ではなく行の形式でデータを格納するため、「行キャッシュ」とも呼ばれます (バッファは完全なデータ部分を格納するために使用されます)。辞書データに使用される別のメモリ領域は「ライブラリ キャッシュ」と呼ばれます。すべてのOracle DBユーザー・プロセスは、データ・ディクショナリ情報にアクセスするためにこれら2つのキャッシュを共有します。
Oracle DB は、共有 SQL 領域 (および PGA で予約されたプライベート SQL 領域) を使用して、実行する各 SQL 文を表します。 Oracle DBは、2人のユーザーが同じSQL文を実行することを認識し、それらのユーザーの共有SQL領域を再利用します。
「共有 SQL 領域」には、特定の SQL ステートメントの解析ツリーと実行プランが含まれます。 Oracle DBは、複数回実行されるSQL文に共有SQL領域を使用することでメモリーを節約します。多くのユーザーが同じアプリケーションを実行する場合、同じ SQL ステートメントが複数回実行されることがよくあります。
新しい SQL 文が解析されると、Oracle DB は共有プールからメモリを割り当て、その文を共有 SQL 領域に格納します。このメモリのサイズは、ステートメントの複雑さによって異なります。
Oracle DB は、個々の SQL 文を処理するのとほぼ同じ方法で、PL/SQL プログラム単位 (プロシージャ、関数、パッケージ、無名ブロック、データ トリガー) を処理します。 Oracle DBは、解析およびコンパイルされた形式でプログラム・ユニットを格納するための共有領域を割り当てます。 Oracle DBは、ローカル変数、グローバル変数、パッケージ変数(「パッケージのインスタンス化」とも呼ばれます)など、プログラムユニットが実行されているセッションに固有の値を格納したり、SQLの実行に使用されるバッファを格納したりするためのプライベート領域を割り当てます。 。複数のユーザーが同じプログラムユニットを実行する場合、すべてのユーザーは同じ共有領域を使用しますが、自分のセッションに固有の値を保持するために自分のプライベート SQL 領域の別のコピーを維持します。
PL/SQL プログラムユニット内に含まれる個々の SQL 文は、他の SQL 文と同様に処理されます。
PL/SQL プログラム単位内のこれらの SQL 文の生成元に関係なく、解析表現を保持するために共有領域と、文が実行されるセッションごとに専用領域を使用します。
SQL 問合せ結果キャッシュと PL/SQL 関数結果キャッシュは、Oracle Database 11g の新機能です。
これらは同じインフラストラクチャを共有し、同じ動的パフォーマンス (V$) ビューに表示され、同じ提供パッケージを使用して管理されます。
クエリとクエリのフラグメントの結果は、メモリ内の「SQL クエリ結果キャッシュ」にキャッシュできます。このようにして、データベースはキャッシュされた結果を使用して、これらのクエリおよびクエリ フラグメントの後で実行する応答を返すことができます。 SQL クエリ結果キャッシュからの結果の取得は、クエリを再実行するよりもはるかに高速であるため、頻繁に実行されるクエリの
結果をキャッシュすると、これらのクエリのパフォーマンスが大幅に向上します。
この関数は、計算への入力が PL/SQL 関数によって発行された 1 つまたは複数のパラメータ化された問合せである場合に、計算の結果を返すために使用されることがあります。場合によっては、これらのクエリは、(関数が呼び出される頻度と比較して) ほとんど変更されないデータにアクセスします。
PL/SQL ファンクションのソース・テキストに構文を含めて、ファンクションの結果を「PL/SQL ファンクション結果キャッシュ」にキャッシュし、表で DML が検出されたときにキャッシュをクリアするようにリクエストできます。テーブルリスト (正しいことを確認してくださいで始まります)。
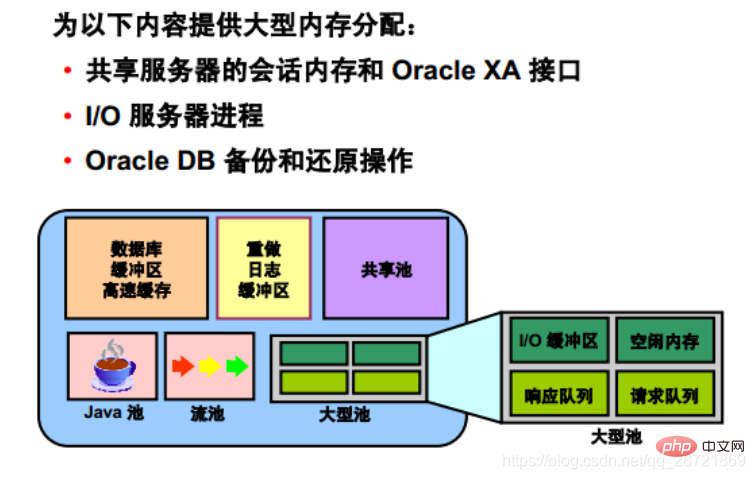
データベース管理者は、「ラージ プール」と呼ばれるオプションのメモリ領域を構成して、以下に大規模なメモリ割り当てを提供できます。
• 共有サーバー セッション メモリと Oracle XAまたはパラレル問合せバッファによってセッション・メモリーが割り当てられ、Oracle DBは主に共有プールを使用して共有SQLをキャッシュし、共有SQLキャッシュの縮小によって生じるパフォーマンスのオーバーヘッドを回避できます。
さらに、Oracle DB のバックアップおよび復元操作、I/O サーバー プロセス、および並列バッファに使用されるメモリは、数百 KB のバッファに割り当てられます。大規模なプールは、共有プールよりもこのような大規模なメモリ要求に適切に対応します。
大規模なプール用の LRU リストはありません。これは、共有プールから割り当てられた他のメモリと同じ LRU リストを使用する共有プール内の予約スペースとは異なります。
Java プールとストリーム プール
Java プール ガイドの統計は、Java のライブラリ キャッシュ メモリに関する情報を提供し、Java プール サイズの変更が解析速度にどのような影響を与えるかを予測します。 statistics_level が TYPICAL 以上に設定されている場合、Java プール ガイダンスが内部的に有効になります。これらの統計は、ガイドを閉じるとリセットされます。 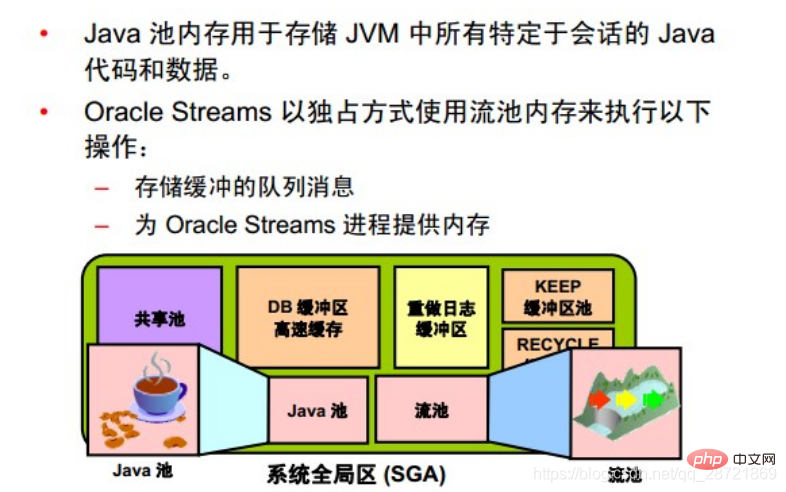 ストリーム・プールは、Oracle Streams によって排他的に使用されます。ストリーム・プールは、バッファされたキュー・メッセージを格納し、Oracle Streams取得プロセスおよびアプリケーション・プロセスにメモリーを提供します。
ストリーム・プールは、Oracle Streams によって排他的に使用されます。ストリーム・プールは、バッファされたキュー・メッセージを格納し、Oracle Streams取得プロセスおよびアプリケーション・プロセスにメモリーを提供します。
ストリーム プールが特別に構成されていない限り、そのサイズは 0 から始まります。 Oracle Streamsを使用する場合、プールのサイズは必要に応じて動的に増加します。
プログラム グローバル領域 (PGA)
各 PGA にはスタック スペースが含まれています。専用サーバー環境では、データベース インスタンスに接続するユーザーごとに個別のサーバー プロセスが存在します。このタイプの接続の場合、PGA にはユーザー グローバル エリア (UGA) と呼ばれるメモリの細分化が含まれています。 UGA には次の部分が含まれます。 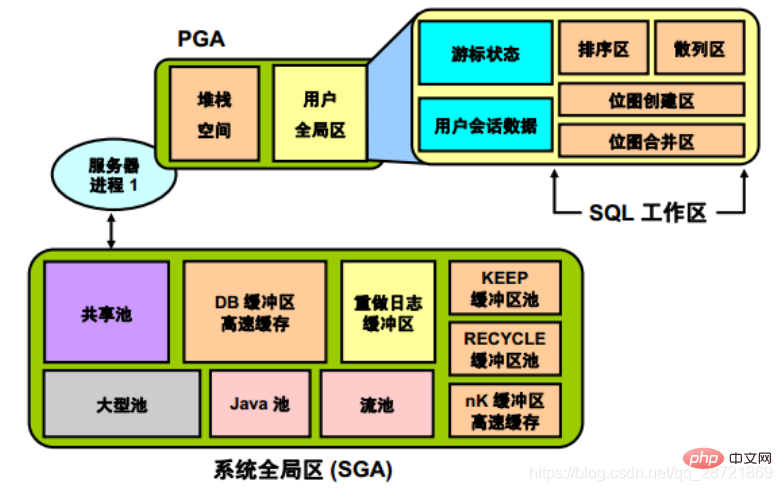 • カーソル領域。カーソルの実行時情報を保存するために使用されます。
• カーソル領域。カーソルの実行時情報を保存するために使用されます。
• ユーザー セッション データ ストレージ領域。セッションに関する制御情報を保存するために使用されます。
• SQL ワークスペース。SQL を処理するために使用されます。次のようなステートメント:
Oracle DB システムのプロセスは、主に 2 つのグループに分けられます。
1. アプリケーションまたは Oracle ツール コードを実行するユーザー プロセス
Oracle DB の構成、ユーザー プロセス構造は、選択したオペレーティング システムと OracleDB オプションによって異なります。接続ユーザーのコードは、専用サーバーまたは共有サーバーとして構成できます。
• 専用サーバー: ユーザーごとに、データベース アプリケーションを実行するユーザー プロセスは、Oracle DB サーバー コードを実行する専用サーバー プロセスによって提供されます。
• 共有サーバー: 接続ごとに専用のサーバー プロセスを用意する必要はありません。ディスパッチャーは、複数の受信ネットワーク セッション要求を共有サーバー プロセス プールに送信します。共有サーバー プロセスは、すべてのクライアント要求に対応します。
2. Oracle DB サーバーコードを実行する Oracle DB プロセス (サーバープロセスとバックグラウンドプロセスを含む)
2.1. サーバープロセス
Oracle DB は、インスタンスに接続されているユーザープロセスからのリクエストを処理するサーバープロセスを作成します。ユーザー・プロセスは、Oracle DBに接続するアプリケーションまたはツールを表します。これは、Oracle DB と同じコンピュータ上に存在することも、ネットワークを使用して Oracle DB にアクセスするリモート クライアント上に存在することもできます。ユーザー プロセスは最初にリスナー プロセスと通信し、リスナー プロセスは専用環境でサーバー プロセスを作成します。
各ユーザーのアプリケーションに代わって作成されたサーバー プロセスは、次の 1 つ以上を実行できます。
• アプリケーションを通じて発行された SQL ステートメントを解析して実行します。
• ディスクから データ ファイルから必要なデータ ブロックを読み取ります。 SGA 上のデータを SGA の共有データベース バッファに格納します (まだ SGA にない場合)
• アプリケーションが情報を処理できるように結果を返します
2.2. バックグラウンド プロセス
パフォーマンスを最大化し、複数のユーザーのニーズを満たすために、マルチプロセス Oracle DB システムは、「バックグラウンド プロセス」と呼ばれる追加の Oracle DB プロセスを使用します。 Oracle DB インスタンスには複数のバックグラウンド プロセスを含めることができます。
非 RAC、非 ASM 環境における一般的なバックグラウンド プロセスには次のものが含まれます。
• データベース書き込みプロセス (DBWn)
• ログ書き込みプロセス (LGWR)
• チェックポイント プロセス (CKPT)
•システム監視プロセス (SMON)
• プロセス監視プロセス (PMON)
• 復元プロセス (RECO)
• ジョブ キュー コーディネーター (CJQ0)
• ジョブ スレーブ プロセス (Jnnn)
• アーカイブプロセス (ARCn)
• キュー モニター プロセス (QMNn)
より高度な構成 (RAC など) では、他のバックグラウンド プロセスが存在する場合があります。バックグラウンド・プロセスの詳細については、V$BGPROCESS ビューを参照してください。
バックグラウンド プロセスには、インスタンスの起動時に自動的に作成されるものと、オンデマンドで作成されるものがあります。
他のプロセス構造は単一のデータベースに固有のものではありませんが、同じサーバー上の複数のデータベース間で共有できます。グリッド インフラストラクチャ プロセスとネットワーク プロセスは、このカテゴリに分類されます。
Linux および UNIX システム上の Oracle Grid Infrastructure プロセスには次のものが含まれます。
• ohasd: Oracle Clusterware プロセスの開始を担当する Oracle High Availability Service デーモン
• ocssd: クラスタ同期サービス デーモン
• diskmon: ディスク監視デーモン。HP Oracle Exadata Storage Server の入出力の監視を担当します。
• cssdagent: CSS デーモンの起動、停止、ステータスの確認を行います。 ocssd
• oraagent: Oracle 固有の要件と複雑さをサポートするためにクラスタウェアを拡張します。リソース
• orarootagent: root ユーザーが所有するリソース (ネットワークなど) の管理を支援する特殊な Oracle エージェント プロセス 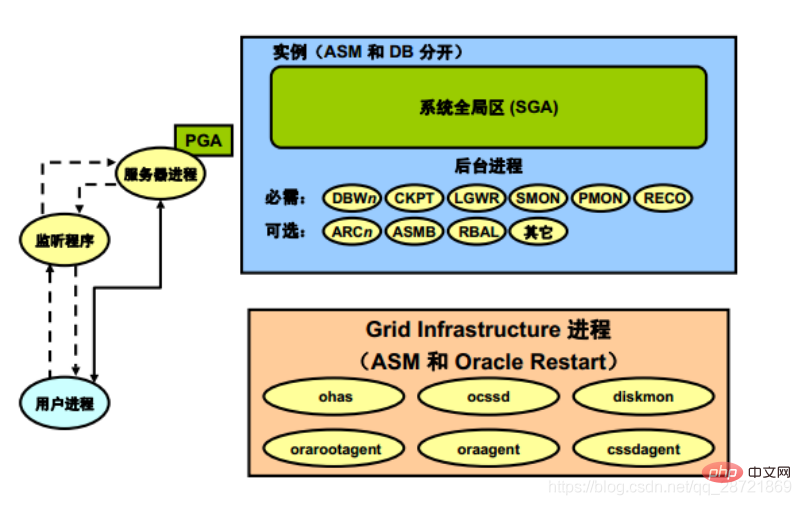
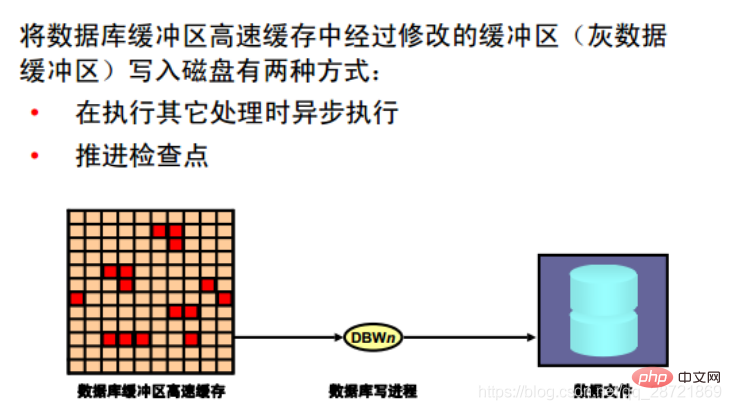
データベース書き込みプロセス (DBWn) は、バッファの内容をデータ ファイルに書き込むことができます。 DBWn プロセスは、データベース バッファ キャッシュ内の変更されたバッファ (グレー データ バッファ) をディスクに書き込む役割を果たします。ほとんどのシステムでは、1 つのデータベース書き込みプロセス (DBW0) で十分ですが、システムでデータを頻繁に変更する必要がある場合は、追加のプロセス (DBW1 ~ DBW9 および DBWa ~ DBWz) を構成して書き込みパフォーマンスを向上させることができます。これらの追加の DBWn プロセスは、ユニプロセッサ システムでは役に立ちません。
データベース バッファ キャッシュ内のバッファが変更されると、システムはそのバッファをグレー データ バッファとしてマークし、SCN 順序でチェックポイント キューの先頭に追加します。したがって、この順序は、これらの変更されたバッファの REDO エントリが REDO ログに書き込まれる順序と一致します。バッファ・キャッシュ内の空きバッファの数が何らかの内部しきい値を下回ると(サーバー・プロセスが空きバッファの取得が困難であると判断するレベルまで)、DBWnは使用頻度の低いバッファをデータ・ファイルに書き込み、順序付けはデータ・ファイルの最後から開始されます。 LRU リストを使用すると、プロセスが必要に応じてバッファを置き換えることができます。 DBWn はまた、チェックポイント キューの末尾から書き込み、進行中のチェックポイントを保護します。
SGA には、インスタンスが失敗したときにリカバリが開始される REDO ストリーム内の位置の RBA (REDO バイト アドレス) を保持するメモリ構造があります。この構造体はやり直しへのポインタとして機能し、CKPT プロセスによって 3 秒ごとに制御ファイルに書き込まれます。 DBWn はグレイ データ バッファに SCN 順序で書き込み、REDO は SCN 順序で実行されるため、DBWn が LRUW リストからグレイ データ バッファに書き込むたびに、インスタンスのリカバリを容易にするために SGA メモリ構造に保持されているポインタも前方に移動されます。必要な場合) ほぼ正しい位置から読み取りやり直しを開始し、不要な I/O を回避します。これは「増分チェックポイント」と呼ばれます。
注: DBWn が書き込み操作を実行する状況は他にもあります (たとえば、表スペースが読み取り専用に設定されている場合やオフラインになっている場合など)。このような場合、対応するデータ ファイルのみに属するグレー データ バッファがデータベースに書き込まれる順序は SCN の順序とは無関係であるため、増分チェックポイントは発生しません。
LRU アルゴリズムは、ディスク読み取りを最小限に抑えるために、より頻繁にアクセスされるブロックをバッファ キャッシュに保持します。テーブルで CACHE オプションを使用すると、メモリ内にブロックをより長く保持しやすくなります。
DB_WRITER_PROCESSES 初期化パラメータは、DBWn プロセスの数を指定します。 DBWn プロセスの最大数は 36 です。ユーザーが起動時にこのプロセス数を指定しない場合、Oracle DB は CPU とプロセッサ グループの数に基づいて DB_WRITER_PROCESSES を設定する方法を決定します。
DBWn プロセスは、次の条件でグレー データ バッファをディスクに書き込みます。
• サーバー プロセスがしきい値に達したバッファをスキャンした後、クリーンな再利用可能なバッファを見つけられない場合、DBWn は書き込み操作を実行するように通知されます。 DBWn は、他の処理を実行しながら、グレイ データ バッファを非同期でディスクに書き込みます。
• DBWn はチェックポイントを進めるためのバッファを書き込みます。チェックポイントは、インスタンスのリカバリを実行するために使用される REDO スレッド (ログ) 内の開始位置です。ログの位置は、バッファ キャッシュ内の最も古いグレー データ バッファによって決定されます。すべての場合において、DBWn は効率を向上させるためにバッチ (マルチブロック) 書き込み操作を実行します。マルチブロック書き込み操作で書き込まれるブロックの数は、オペレーティング システムによって異なります。
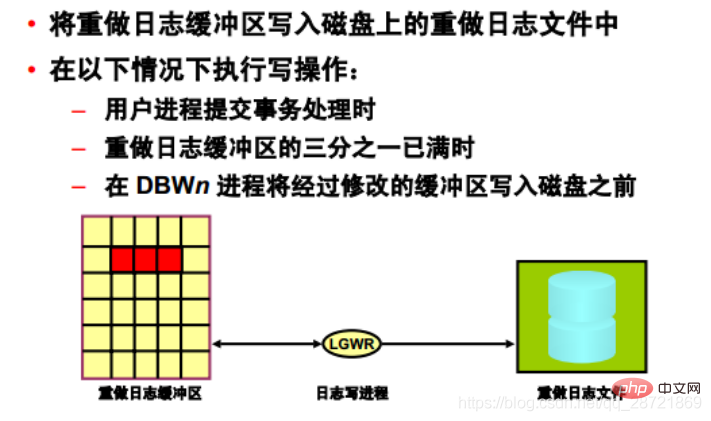
ログ書き込みプロセス (LGWR) は、ディスク上の REDO ログ バッファに REDO ログ バッファ エントリを書き込むことにより、REDO ログ バッファを管理します。ログファイルを作成します。 LGWR は、最後の書き込み以降にバッファにコピーされたすべての REDO エントリを書き込みます。
REDO ログ バッファは循環バッファです。 LGWR が REDO ログ・バッファ内の REDO エントリを REDO ログ・ファイルに書き込んだ後、サーバー・プロセスは、ディスクに書き込まれたエントリの上に新しいエントリを REDO ログ・バッファにコピーできます。 LGWR の書き込み速度は、通常、REDO ログへのアクセスが多い場合でも、バッファーに新しいエントリ用のスペースを常に確保できるほど高速です。 LGWR は、バッファの連続部分をディスクに書き込みます。
LGWR は、次の状況で書き込み操作を実行します。
• ユーザー プロセスがトランザクションをコミットしたとき
• REDO ログ バッファの 3 分の 1 がいっぱいになったとき
• DBWn プロセスが変更された Before を転送したときバッファはディスクに書き込まれます(必要な場合)
• 3秒ごと
DBWnが変更されたバッファをディスク District に書き込む前に、バッファ変更に関連付けられたすべてのREDOレコードをディスクに書き込む必要があります(最初にアグリーメントを書き込みます)。 DBWnは、一部のREDOレコードがまだ書き込まれていないことを検出すると、これらのREDOレコードをディスクに書き込むようにLGWR
に通知し、LGWRがREDOログ・バッファへの書き込みを完了するのを待ってからデータ・バッファに書き込みます。 LGWR は現在のログ グループに書き込みます。グループ内のファイルが破損するか使用できなくなると、LGWR はグループ内の他のファイルへの書き込みを継続し、LGWR トレース ファイルとシステム アラート ログにエラーを記録します。グループ内のすべてのファイルが破損している場合、またはグループがアーカイブされていないために使用できない場合、LGWR は動作を継続できません。
ユーザーが COMMIT ステートメントを発行すると、LGWR はコミット レコードを REDO ログ バッファに配置し、そのレコードをトランザクションの REDO ログとともに直ちにディスクに書き込みます。データ ブロックへの対応する変更は、より効率的に書き込めるようになるまで遅延されます。これは「高速コミットメカニズム」と呼ばれます。トランザクションコミットレコードを含むREDOエントリのアトミック書き込みは、トランザクションがコミットしたかどうかを決定する単一のイベントです。
Oracle DB は、データ バッファがまだディスクに書き込まれていなくても、コミットされたトランザクションに対して成功コードを返します。
より多くのバッファ領域が必要な場合、LGWR はトランザクションをコミットする前に REDO ログ エントリを書き込むことがあります。これらのエントリは、後でトランザクションがコミットされた場合にのみ永続的になります。ユーザーがトランザクションをコミットすると、そのトランザクションにはシステム変更番号(SCN)が割り当てられ、Oracle DBはこの番号をトランザクションのREDOエントリとともにREDOログに記録します。 SCN は REDO ログに記録されるため、Real Application Clusters と分散
データベース間でリカバリ操作を同期できます。
アクティビティが高い場合、LGWR はグループ コミットを使用して REDO ログ ファイルを書き込むことができます。たとえば、ユーザーがトランザクションを送信すると仮定します。 LGWR は、このトランザクションの REDO エントリをディスクに書き込む必要があります。これが発生すると、他のユーザーが COMMIT ステートメントを発行します。ただし、LGWR は、前の書き込み操作が完了するまで、REDO ログ ファイルに書き込んでこれらのトランザクションをコミットできません。最初のトランザクションのエントリが REDO ログ ファイルに書き込まれた後、保留中の (まだコミットされていない) トランザクションの REDO エントリのリスト全体を 1 回の操作でディスクに書き込むことができ、個々のトランザクション エントリを個別に処理するよりも高速です。 ○は必須です。その結果、Oracle DB はディスク I/O を最小限に抑え、LGWR のパフォーマンスを最大化できます。コミット要求のレートが一貫して高い場合、REDO ログ バッファからの各書き込み操作 (LGWR によって実行される) に複数のコミット レコードが含まれる可能性があります。
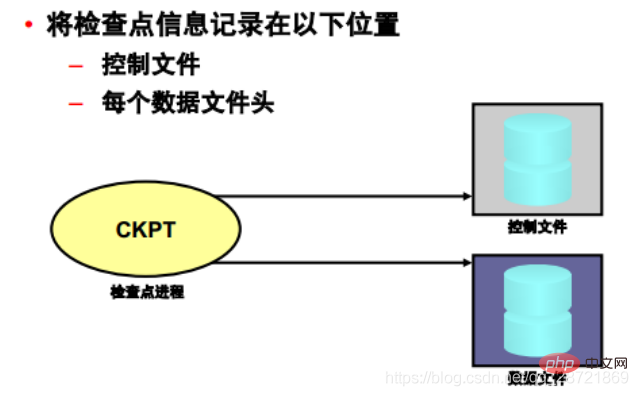
「チェックポイント」は、データベースの REDO スレッド内のシステム変更番号 (SCN) を定義するデータ構造です。チェックポイントは、制御ファイルと各データ ファイルのヘッダーに記録されます。これらは復旧作業の重要な要素です。
チェックポイントが発生すると、Oracle DB はすべてのデータ ファイルのヘッダーを更新して、チェックポイントの詳細を記録する必要があります。これは CKPT プロセスによって行われます。 CKPT プロセスはブロックをディスクに書き込みません。その作業は DBWn によって実行されます。ファイルヘッダーに記録された SCN により、その SCN より前のデータベース ブロックに対するすべての変更がディスクに書き込まれることが保証されます。
Oracle Enterprise Manager の SYSTEM_STATISTICS モニタには、完了したチェックポイント リクエストの数を示す統計 DBWR チェックポイントが表示されます。

システム モニター プロセス (SMON) は、インスタンスの起動時に (必要に応じて) リカバリを実行します。 SMON は、使用されなくなった一時セグメントをクリーンアップする責任もあります。ファイル読み取りまたはオフラインエラーにより、インスタンスのリカバリ中に終了したトランザクションがスキップされた場合、SMON は、表スペースまたはファイルがオンラインに戻ったときにそれらのトランザクションを再開します。
SMON は、プロセスが必要かどうかを定期的にチェックします。他のプロセスも、SMON の必要性を検出したときにそれを呼び出すことができます。
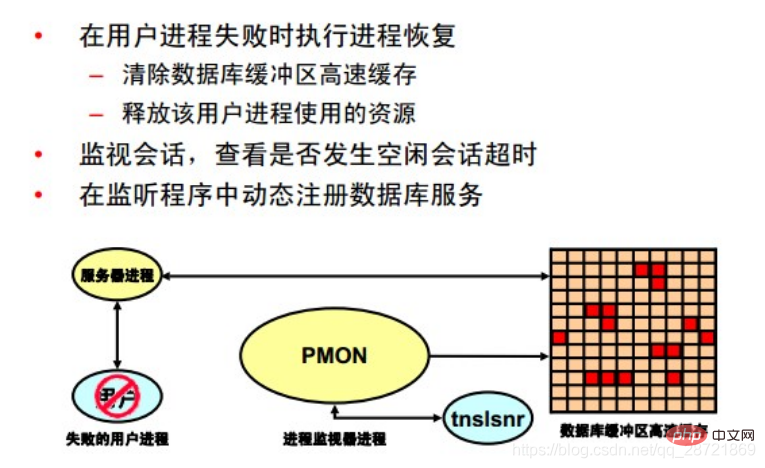
プロセス モニター プロセス (PMON) は、ユーザー プロセスに障害が発生したときにプロセスの回復を実行します。 PMON は、データベース バッファ キャッシュをクリアし、ユーザー プロセスが占有しているリソースを解放する役割を果たします。たとえば、PMON はアクティブなトランザクション テーブルの状態をリセットし、ロックを解放し、アクティブなプロセスのリストからプロセス ID を削除します。
PMON は、ディスパッチャーおよびサーバー・プロセスのステータスを定期的にチェックし、実行を停止したディスパッチャーおよびサーバー・プロセスを再起動します (OracleDB によって意図的に終了されない限り)。 PMON は、インスタンスおよびディスパッチャ プロセスに関する情報もネットワーク リスナーに登録します。
SMON と同様に、PMON は実行する必要があるかどうかを定期的にチェックします。必要であることが検出された場合は、他のプロセスによって呼び出すこともできます。
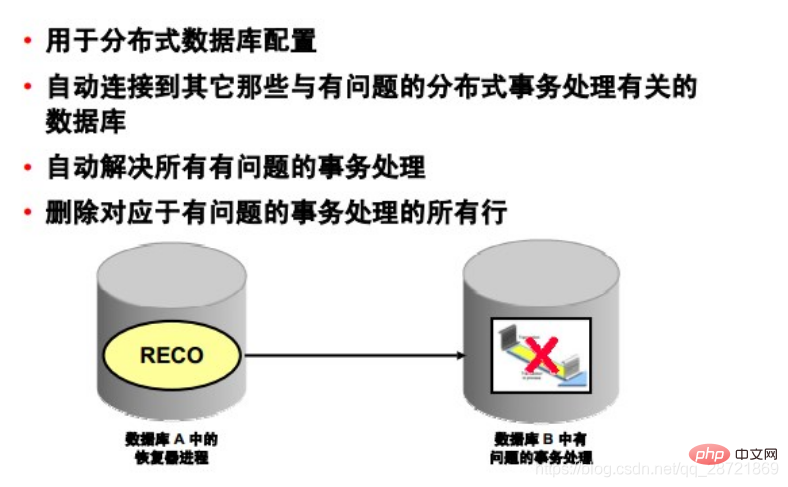
リストアラープロセス (RECO) は、分散トランザクション処理に関連する障害を自動的に解決するために分散データベース構成で使用されるバックグラウンド プロセスです。インスタンスの RECO プロセスは、問題の分散トランザクション処理に関与する他のデータベースに自動的に接続します。 RECO プロセスが関係するデータベース サーバー間の接続を再確立すると、問題のあるすべてのトランザクションが自動的に解決され、解決された問題のあるトランザクションに対応するすべてのトランザクションが各データベースの保留中のトランザクション テーブルから削除されます。
RECO プロセスがリモート サーバーに接続できない場合、RECO は一定の時間間隔の後に自動的に再接続を試みます。ただし、RECO は接続を再試行するまでの待機時間が (指数関数的に) 増加します。
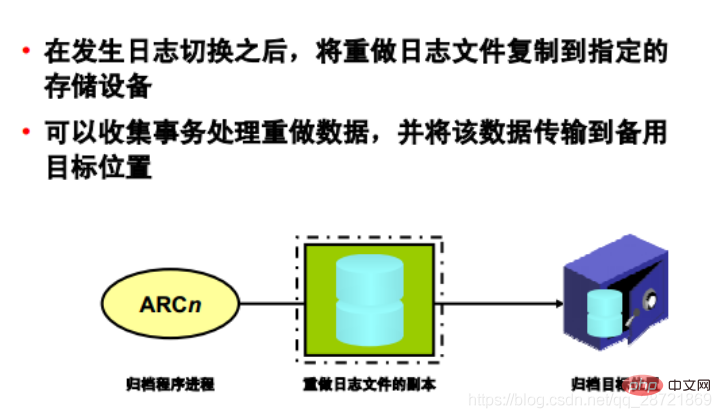
ログの切り替えが発生すると、アーカイブ プロセス (ARCn) は REDO ログ ファイルを指定されたストレージ デバイスにコピーします。 ARCn プロセスは、データベースが ARCHIVELOG モードで、自動アーカイブが有効になっている場合にのみ存在します。
重いアーカイブ ワークロードが予想される場合 (データのバッチ ロード中など)、LOG_ARCHIVE_MAX_PROCESSES 初期化パラメータを使用してアーカイブ プロセスの最大数を増やすことができます。 ALTER SYSTEM ステートメントは、このパラメータの値を動的に変更して、ARCn プロセスの数を増減できます。
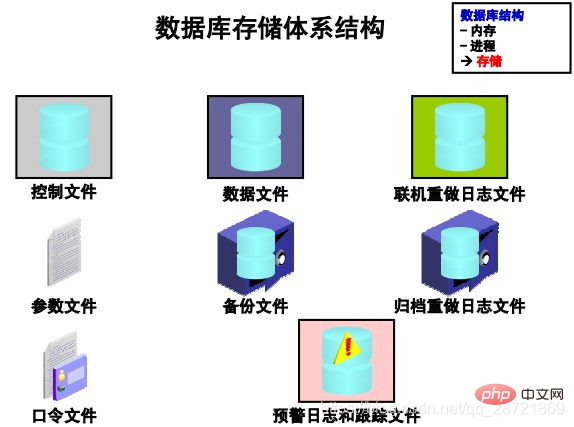
Oracle DB を構成するファイルは、次のカテゴリに分類できます。
• 制御ファイル: データに関連するデータが含まれます。データベース自体、つまり物理データベース構造情報。これらのファイルはデータベースにとって重要です。これらのファイルがないと、データ ファイルを開いてデータベース内のデータにアクセスできません。
• データ ファイル: データベースのユーザーまたはアプリケーション データ、メタデータおよびデータ ディクショナリが含まれます。
• オンライン REDO ログ ファイル: データベースのインスタンスのリカバリに使用されます。データベース サーバーがクラッシュしてもデータ ファイルが失われた場合、インスタンスはこれらのファイル内の情報を使用してデータベースを回復できます。
次の追加ファイルは、データベースを正常に実行するために重要です。
• パラメータ ファイル: インスタンスの開始時に構成を定義するために使用されます。
• パスワード ファイル: sysdba、sysoper、および sysasm がデータベースに接続できるようにします。リモートでインスタンスを作成し、管理タスクを実行します
• バックアップ ファイル: データベースのリカバリに使用されます。通常、バックアップ ファイルは、メディアの障害やユーザー エラーによって元のファイルが破損または削除された場合に復元されます。
• アーカイブ REDO ログ ファイル: インスタンス上で発生したデータ変更 (REDO) のリアルタイム履歴が含まれます。これらのファイルとデータベースのバックアップを使用すると、失われたデータ ファイルを回復できます。つまり、アーカイブ ログは、復元されたデータ ファイルを復元できます。
• トレース ファイル: 各サーバーおよびバックグラウンド プロセスは、関連するトレース ファイルに書き込むことができます。プロセスが内部エラーを検出すると、プロセスはエラーに関する情報を適切なトレース ファイルにダンプします。トレース・ファイルに書き込まれる情報の一部はデータベース管理者に提供され、その他の情報は Oracle サポート・サービスに提供されます。
• アラート ログ ファイル: これらのファイルには特別なトレース エントリが含まれています。データベースの警告ログは、メッセージ ログとエラー ログが時系列にリストされています。アラート・ログを定期的に確認することをお薦めします。
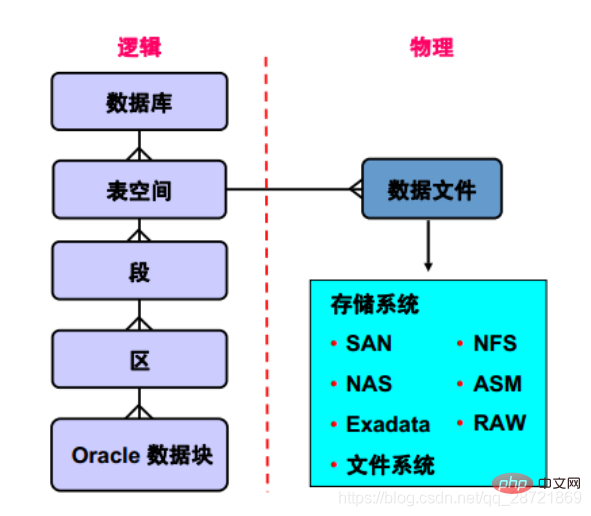
このスライドでは、データベース、テーブルスペース、およびデータファイルの関係について説明します。と説明した。各データベースは論理的に 2 つ以上の表スペースに分割されます。表スペース内のすべての論理構造のデータを物理的に保管するために、1 つ以上のデータ・ファイルが各表スペースに明示的に作成されます。 TEMPORARY テーブルスペースの場合、データ ファイルは作成されませんが、一時
ファイルが作成されます。表スペースのデータ・ファイルは、サポートされているストレージ・テクノロジーを使用して物理的に保管できます。
データベースは、「テーブル スペース」と呼ばれる複数の論理ストレージ ユニットに分割されており、関連する論理構造またはデータ ファイルをグループ化するために使用されます。たとえば、表スペースは通常、アプリケーションのすべてのセグメントを 1 つのグループにグループ化し、一部の管理操作を簡素化します。 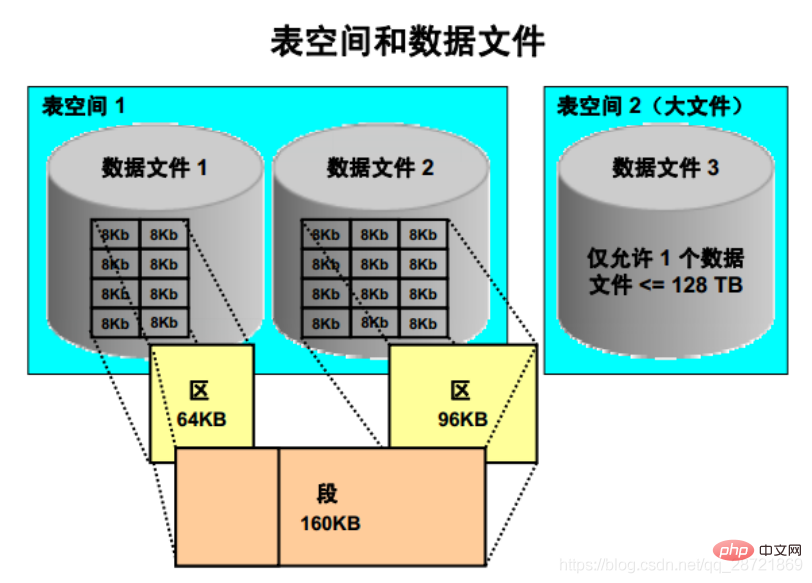
データベースは「テーブルスペース」に分割されます。テーブルスペースは、関連する論理構造をグループ化するために使用できる論理ストレージユニットです。各データベースは論理的に 2 つ以上の表スペース (SYSTEM 表スペースと SYSAUX 表スペース) に分割されます。表スペース内のすべての論理構造のデータを物理的に保管するために、1 つ以上のデータ・ファイルが各表スペースに明示的に作成されます。
サイズ 160 KB のセグメントは 2 つのデータ ファイルにまたがり、2 つのエクステントで構成されます。最初のエクステントは最初のデータ ファイルにあり、サイズは 64 KB です。2 番目のエクステントは 2 番目のデータ ファイルにあり、サイズは 96 KB です。どちらのエクステントも、複数の連続した 8Kb Oracle ブロックで構成されています。
注: 通常は非常に大きいファイルを 1 つだけ含む、大きなファイル表スペースを作成することができます。ファイルは、行 ID アーキテクチャで許可される最大サイズまで可能です。この最大サイズは、表スペースのブロック・サイズに 236 を乗算したものです。ブロック・サイズが 32 KB の場合、最大サイズは 128 TB です。従来の小さなファイル表領域 (デフォルト) には複数のデータ ファイルを含めることができますが、これらのファイルはそれほど大きくありません。
Oracle DB データは、最小レベルの粒度である「データ ブロック」に格納されます。データ ブロックは、ディスク上の物理スペースの特定のバイト数に対応します。各表スペースのデータ・ブロック・サイズは、表スペースの作成時に指定されます。データベースは、Oracle データ ブロックの単位でデータベースの空き領域を使用し、割り当てます。

論理データベーススペースの次のレベルは「ディストリクト」です。エクステントとは、特定の種類の情報を格納するために使用される、Oracle データの特定の数の連続ブロック (単一の割り当てから取得) です。エクステント内の Oracle データ ブロックは論理的には連続していますが、物理的にはディスク上の異なる場所に分散する可能性があります (RAID ストライピングとファイル システムの実装がこの動作を引き起こす可能性があります)。
論理データベースの記憶領域の上位を「セグメント」と呼びます。セグメントとは、特定の論理構造に割り当てられた領域の集合です。次に例を示します。
• データ セグメント: 外部テーブル、グローバル一時テーブル、およびパーティション テーブルを除き、各非クラスタ化非インデックス構成テーブルにはデータ セグメントがあり、各テーブルには 1 つまたは複数のセグメントがあります。テーブル内のすべてのデータは、対応するデータ セグメントのエクステントに格納されます。パーティション化されたテーブルの場合、各パーティションに 1 つのデータ セグメントがあります。各クラスターにはデータ セグメントもあります。クラスター内の各テーブルのデータは、クラスターのデータ セグメントに保存されます。
• インデックス セグメント: 各インデックスには、すべてのデータを保存するインデックス セグメントがあります。パーティション索引の場合、パーティションごとに 1 つの索引セグメントがあります。
• UNDO セグメント: システムはデータベース インスタンスごとに UNDO テーブルスペースを作成します。このテーブルスペースには、リストア情報を一時的に保存するために使用される多数のリストア セグメントが含まれています。復元セグメント内の情報は、データベースの回復中にユーザーのコミットされていないトランザクションをロールバックするための読み取り一貫性のあるデータベース情報を生成するために使用されます。
• 一時セグメント: SQL 文の実行を完了するために一時作業領域が必要な場合、一時セグメントは Oracle DB によって作成されます。ステートメントの実行が完了すると、一時セグメントのエクステントは将来の使用のためにインスタンスに返されます。ユーザーごとにデフォルトの一時表スペースを指定することも、データベースの範囲内で使用されるデフォルトの一時表スペースを指定することもできます。
注: 上記にリストされていない他のタイプのセグメントもあります。さらに、ビュー、パッケージ、トリガーなどの一部のスキーマ オブジェクトは、データベース オブジェクトであってもセグメントとみなされません。セグメントには個別のディスク領域が割り当てられます。他のオブジェクトは、システム メタデータ セグメントに行として保存されます。
Oracle DB サーバーはスペースを動的に割り当てます。セグメント内の既存のエクステントがいっぱいの場合は、エクステントが追加されます。エクステントは必要に応じて割り当てられるため、セグメント内のエクステントはディスク上で隣接している場合も隣接していない場合もあり、同じ表スペースに属する異なるデータ ファイルから取得されたものである場合もあります。
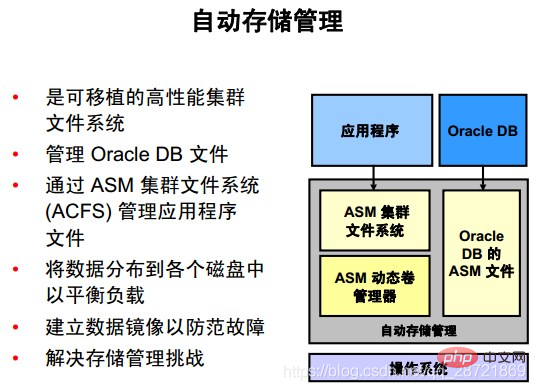
自動ストレージ管理 (ASM) は、Oracle DB ファイルのファイル システムとボリューム マネージャの垂直統合を提供します。 ASM は、単一の対称型マルチプロセッシング (SMP) コンピュータ、またはクラスタの複数のノードを管理して、Oracle Real Application Clusters (RAC) をサポートできます。
Oracle ASM Cluster File System (ACFS)は、マルチプラットフォームのスケーラブルなファイル・システムおよびストレージ管理テクノロジであり、ASMの機能を拡張して、実行可能ファイル、レポート、BFILE、ビデオ、オーディオ、テキスト、画像、その他の汎用アプリケーション ファイル データ。
ASM は、入出力 (I/O) 負荷を使用可能なすべてのリソースに分散し、I/O の手動最適化を排除し、パフォーマンスを最適化します。 ASM は、データベースをシャットダウンせずにデータベースのサイズを増やしてストレージ割り当てを調整できるようにすることで、DBA による動的なデータベース環境の管理を支援します。
ASM は、データの冗長コピーを維持してフォールト トレランスを提供することも、ベンダーが提供するストレージ メカニズム上に構築することもできます。データ管理は、ファイルごとに手動で操作するのではなく、データの種類ごとに必要な信頼性とパフォーマンスのメトリックを選択することによって実現されます。
ASM 機能は、手動のストレージ タスクを自動化することで DBA の時間を節約し、それによって管理者のより多くの、より大規模なデータベースをより効率的に管理する能力が向上します。 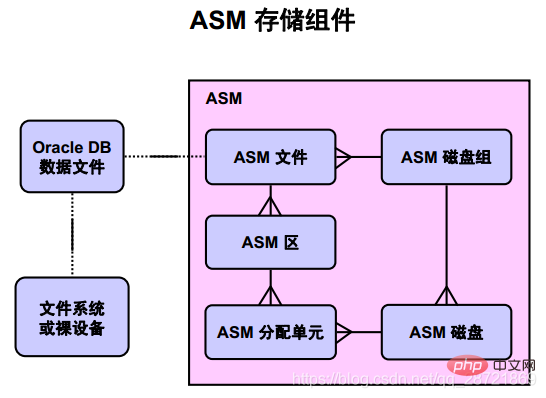
ASM は既存のデータベース機能を妨げません。既存のデータベースは通常どおり動作します。新しいファイルは ASM ファイルとして作成でき、既存のファイルはそのまま管理することも、ASM に移行することもできます。
上の図は、Oracle DB データ ファイルと ASM ストレージ コンポーネントの関係を示しています。カラスの足のマークは 1 対多の関係を表します。 Oracle DBデータファイルと、オペレーティングシステムのファイルシステムに格納されているファイルまたはASMファイルの間には1対1の関係があります。
Oracle ASM ディスク・グループは、論理ユニットとして管理される 1 つ以上の Oracle ASM ディスクの集合です。ディスク グループ内のデータ構造は自己完結型であり、メタデータのニーズに応じてスペースの一部を使用します。 Oracle ASMディスクは、Oracle ASMディスク・グループにプロビジョニングされたストレージ・デバイスです。これには、物理ディスク、パーティション、ストレージ・アレイ内の
論理ユニット番号(LUN)、論理ボリューム(LV)、または接続されたファイルを指定できます。ネットワークに接続します。各 ASM ディスクは、ASM アロケーション ユニット (AU) の数に分割されます。AU は、ASM が割り当てることができる連続したディスク領域の最小量です。 ASM ディスク グループを作成するときは、ディスク グループの互換性レベルに応じて、ASM アロケーション ユニット サイズを 1、2、4、8、16、32、または 64 MB に設定できます。 1 つ以上の ASM アロケーション ユニットが ASM 領域を形成します。 Oracle ASM領域は、Oracle ASMファイルのコンテンツを格納するために使用されるRAWストレージです。 Oracle ASM ファイルは、1 つ以上のファイル エクステントで構成されます。非常に大きな ASM ファイルをサポートするには、AU サイズの 1 倍、4 倍、16 倍に等しい可変サイズのエクステントを使用できます。
推奨チュートリアル: 「Oracle ビデオ チュートリアル 」
以上がOracle データベース アーキテクチャの詳細な図による説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



