

メモリがいっぱいになったときに Redis を最適化する方法の詳細な分析

この記事では、Redis に関する関連知識を提供し、メモリがいっぱいになったときに Redis を最適化する方法に関する関連問題を主に紹介し、削除メカニズム、LRU アルゴリズム、削除の処理についても説明します。 , 皆様のお役に立てれば幸いです。

推奨学習: Redis 学習チュートリアル
Redis メモリがいっぱいの場合はどうすればよいですか?メモリを最適化するにはどうすればよいですか?
MySQL には 2,000 万のデータがあり、redis には 200,000 のデータのみが保存されます。redis のデータがホット データであることを確認する方法
Redis メモリ データ セットのサイズが増加した場合一定のサイズに達すると、データ削除戦略が実装されます。
Redis は主にどのような物理リソースを消費しますか? ######メモリ。
Redis のメモリが不足するとどうなりますか?
設定された上限に達すると、Redis 書き込みコマンドはエラー メッセージを返します (ただし、読み取りコマンドは正常に戻ることができます)。または、メモリ削除メカニズムを構成して、Redis が上限メモリに達したときに設定することもできます。制限を超えると、古いコンテンツはフラッシュされます。
キャッシュされたデータの削除メカニズムについて話す
Redis キャッシュの削除戦略とは何ですか?データを削除しない唯一の戦略は、noeviction です。
- 消去法には 7 つの戦略があり、消去候補データセットの範囲に応じてさらに 2 つのカテゴリに分類できます。消去法には、volatile-random、volatile-ttl、volatile-lru、volatile-lfu の 4 種類があります。
allkeys-lru、allkeys-random、allkeys-lfu を含むすべてのデータ範囲で削除します。
- #ポリシー
| ##volatile-ttl | フィルタリングの際、有効期限が設定されているキーと値のペアは有効期限が早い順に削除されます。 |
|---|---|
| 有効期限が設定されたキーと値のペアをランダムに削除します。 | |
| LRU アルゴリズムを使用して、有効期限を指定してキーと値のペアをフィルター処理します | |
| LFU アルゴリズムを使用して有効期限が設定されたキーと値のペアを選択する | |
| ##戦略 |
| allkeys-random | すべてのキーと値のペアからデータをランダムに選択して削除します。 |
|---|---|
| valkeys-lfu | |
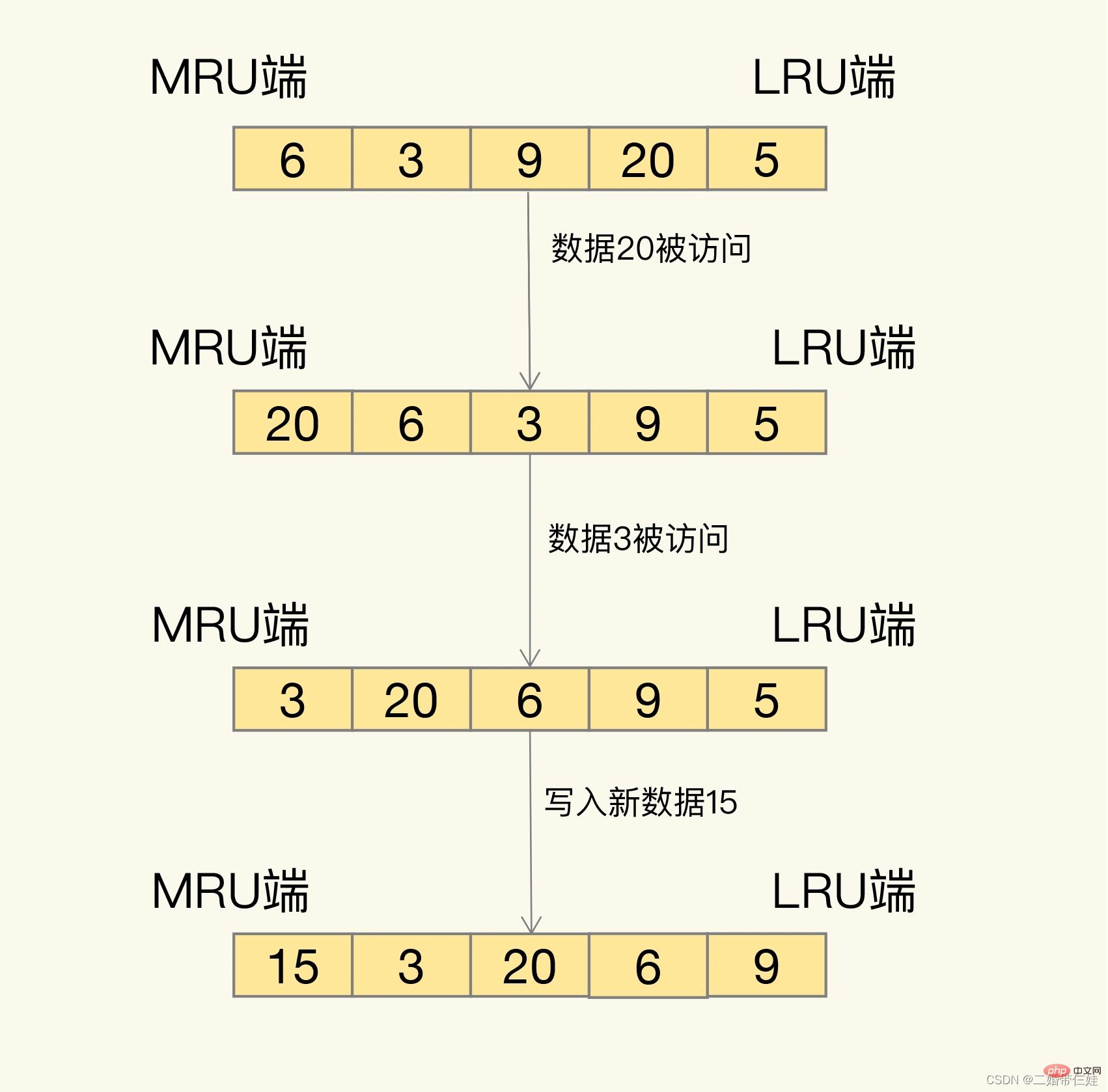
#LRU アルゴリズムについて話しますは、最も最近使用されていない原則に従ってデータをフィルタリングすることです。最も頻繁に使用されていないデータは除外されますが、最近頻繁に使用されたデータはキャッシュに残ります。 正確にはどのように審査されますか? LRU はすべてのデータをリンク リストに編成します。リンク リストの先頭と末尾はそれぞれ MRU の端と LRU の端を表し、最も最近使用されたデータと最も最近使用されなかったデータを表します。 問題: LRUアルゴリズムを実際に実装する場合、リンクされたリストを使用してすべてのキャッシュされたデータを管理する必要があり、追加のスペースオーバーヘッドが発生します。さらに、データにアクセスすると、データをリンク リストの MRU に移動する必要があり、大量のデータにアクセスするとリンク リストの移動操作が多数発生し、非常に時間がかかり、Redis キャッシュのパフォーマンスが低下します。 。 解決策: 使用上の推奨事項:
削除されたデータにどう対処するか?削除されたデータが選択されたら、そのデータがクリーン データの場合は直接削除しますが、ダーティ データの場合はデータベースに書き戻す必要があります。 では、データがクリーンかダーティかを判断するにはどうすればよいでしょうか?
削除されたデータがダーティ データであっても、Redis はそれらをデータベースに書き戻しません。したがって、Redis キャッシュを使用する場合、データが変更された場合は、データが変更されたときにデータベースに書き戻す必要があります。そうしないと、ダーティ データが削除されるときに Redis によって削除され、データベースには最新のデータがなくなります。 Redis はどのようにメモリを最適化しますか?1. キーの数を制御する: Redis を使用して大量のデータを保存する場合、通常は多数のキーがあり、キーが多すぎると大量のメモリも消費します。 Redis は本質的にデータ構造サーバーであり、ハッシュ、リスト、セット、zset、その他の構造などのさまざまなデータ構造を提供します。 Redis を使用する際に誤解しないように、get/set などの API を多用し、Redis を Memcached として使用します。同じデータ内容を保存する場合、Redis データ構造を使用して外部キーの数を減らすと、メモリを大幅に節約できます。
3. コーディングの最適化。 Redis は、string、list、hash、set、zet などの外部型を提供しますが、Redis にはさまざまな型のエンコーディングの概念が内部的にあり、いわゆるエンコーディングは、実装に使用される特定の基礎となるデータ構造を指します。エンコーディングの違いは、メモリ使用量とデータの読み取りおよび書き込み効率に直接影響します。
:コレクション型データを使用します :異なるエンコーディングを使用すると、メモリ使用量に明らかな違いがあります :開発のヒント: scan object idletime コマンドを使用すると、長期間アクセスされていないキーをバッチでクエリし、長期間アクセスされていないキーを見つけて、それらをクリーンアップしてメモリを削減できます。使用法。 :オブジェクトが整数で範囲が [0-9999] の場合、Redis は共有オブジェクトを使用してメモリを節約できます。 :開発のヒント: 同時書き込みが多いシナリオでは、条件が許せば文字列の長さを 39 バイト以内に制御することをお勧めします。 redisObject を作成するためのメモリ割り当ての数を減らし、パフォーマンスを向上させます。 #2. キーと値のオブジェクトを減らす
#3. 共有オブジェクト プール
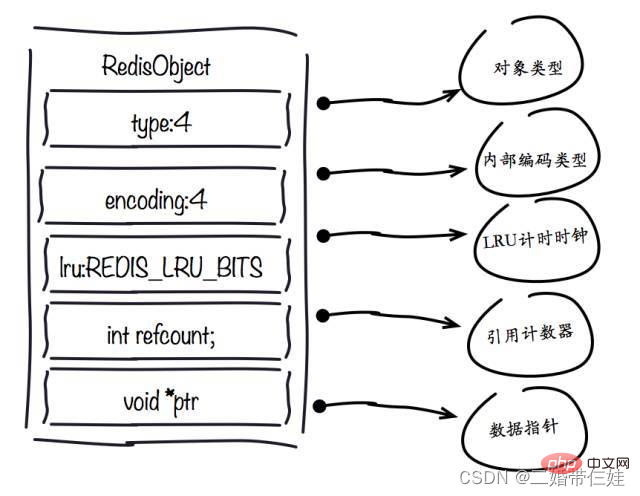
LRU アルゴリズムは、オブジェクト プールを排除するために、オブジェクトの最終アクセス時刻を取得する必要があります。最も長くアクセスされていないデータ。オブジェクトの最終アクセス時刻は、redisObject オブジェクトの lru フィールドに保存されます。オブジェクトの共有とは、複数の参照が同じ redisObject を共有することを意味しますが、このとき lru フィールドも共有されるため、各オブジェクトの最終アクセス時刻を取得することができなくなります。 maxmemory が設定されていない場合、Redis はメモリが使い果たされるまでメモリのリサイクルをトリガーしないため、共有オブジェクト プールは正常に動作できます。 要約すると、共有オブジェクト プールは maxmemory LRU 戦略と競合するため、使用する場合は注意する必要があります。 まず第一に、整数オブジェクト プールは再利用の可能性が最も高くなります。第二に、オブジェクト共有の重要な操作は同等性を判断することです。Redis に整数オブジェクト プールしかない理由は、整数オブジェクト プールの時間計算量が高いためです。整数比較アルゴリズムは O(1) です。オブジェクト プールの無駄を防ぐために、10,000 個の整数のみを保持します。文字列の等しいかどうかを判断する場合、時間計算量は O(n) になり、特に長い文字列の場合、より多くのパフォーマンスが消費されます (浮動小数点数は文字列を使用して Redis の内部に格納されます)。ハッシュ、リストなどのより複雑なデータ構造の場合、同等性の判定には O(n2) が必要です。シングルスレッド Redis の場合、このようなオーバーヘッドは明らかに不当であるため、Redis は整数の共有オブジェクト プールのみを保持します。 4. 文字列の最適化
: 特徴:
: 文字列再構築: ハッシュ タイプに基づく 2 次エンコード方式。 Redis のメモリが不足した場合、最初に考慮すべきことは、水平方向の拡張のためにマシンを追加しないことです。まずメモリの最適化を試みる必要があります。ボトルネックに遭遇した場合は、水平方向の拡張を検討してください。クラスタリング ソリューションの場合でも、クラスタリング後のリソースと管理コストの不必要な浪費を避けるために、垂直レベルの最適化が同様に重要です。 推奨される学習: Redis チュートリアル |
以上がメモリがいっぱいになったときに Redis を最適化する方法の詳細な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7549
7549
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
