| #void addFirst(Object o) |
リストの先頭に要素を追加します |
#void addLast(Object o) | #要素を末尾に追加しますリストの |
# Object getFirst() | リストの最初の要素を返します |
Object getLast() | リストの最後の要素を返します |
Object RemoveFirst() | リストの最初の要素を削除して返します |
##Object RemoveLast()
| リストの最後の要素を削除して返します |
|
2、LinkedList介绍
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。这样看来,LinkedList简直就是个全能冠军。当你需要使用栈或者队列时,可以考虑使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue_的类(它是个接口名字)。关于栈或队列,现在的首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)有着更好的性能。
LinkedList的实现方式决定了所有跟下标相关的操作都是线性时间,而在首段或者末尾删除元素只需要常数时间。为追求效率LinkedList没有实现同步(synchronized),如果需要多个线程并发访问,可以先采用Collections.synchronizedList()方法对其进行包装
3、源码分析
3.1 继承结构与层次
public class LinkedList<e>
extends AbstractSequentialList<e>
implements List<e>, Deque<e>, Cloneable, java.io.Serializable</e></e></e></e>
ログイン後にコピー

这里可以发现LinkedList多了一层AbstractSequentialList的抽象类,这是为了减少实现顺序存取(例如LinkedList)这种类的工作。如果自己想实现顺序存取这种特性的类(就是链表形式),那么就继承 这个AbstractSequentialList抽象类,如果想像数组那样的随机存取的类,那么就去实现AbstracList抽象类。
-
List接口
列表add、set等一些对列表进行操作的方法
-
Deque接口
有队列的各种特性
-
Cloneable接口
能够复制,使用那个copy方法
-
Serializable接口
能够序列化。
-
没有RandomAccess
推荐使用iterator,在其中就有一个foreach,增强的for循环,其中原理也就是iterator,我们在使用的时候,使用foreach或者iterator
3.2 属性与构造方法
transient关键字修饰,这也意味着在序列化时该域是不会序列化的
//实际元素个数transient int size = 0;
//头结点transient Node<e> first;
//尾结点transient Node<e> last;</e></e>
ログイン後にコピー
public LinkedList() {}public LinkedList(Collection extends E> c) {
this();
//将集合c中的各个元素构建成LinkedList链表
addAll(c);}ログイン後にコピー
3.3 内部类Node
//根据前面介绍双向链表就知道这个代表什么了,linkedList的奥秘就在这里private static class Node<e> {
// 数据域(当前节点的值)
E item;
//后继
Node<e> next;
//前驱
Node<e> prev;
// 构造函数,赋值前驱后继
Node(Node<e> prev, E element, Node<e> next) {
this.item = element;
this.next = next;
this.prev = prev;
}}</e></e></e></e></e>ログイン後にコピー
3.4 核心方法add()和addAll()
public boolean add(E e) {
linkLast(e);
return true;}void linkLast(E e) {
//临时节点l(L的小写)保存last,也就是l指向了最后一个节点
final Node<e> l = last;
//将e封装为节点,并且e.prev指向了最后一个节点
final Node<e> newNode = new Node(l, e, null);
//newNode成为了最后一个节点,所以last指向了它
last = newNode;
if (l == null)
//判断是不是一开始链表中就什么都没有,如果没有,则new Node就成为了第一个结点,first和last都指向它
first = newNode;
else
//正常的在最后一个节点后追加,那么原先的最后一个节点的next就要指向现在真正的 最后一个节点,原先的最后一个节点就变成了倒数第二个节点
l.next = newNode;
//添加一个节点,size自增
size++;
modCount++;}</e></e>ログイン後にコピー
addAll()有两个重载函数,addAll(Collection extends E>)型和addAll(int,Collection extends E>)型,我们平时习惯调用的addAll(Collection<?extends E>)型会转化为addAll(int,Collection extends<e>)</e>型
public boolean addAll(Collection extends E> c) {
return addAll(size, c);}public boolean addAll(int index, Collection extends E> c) {
//检查index这个是否为合理
checkPositionIndex(index);
//将集合c转换为Object数组
Object[] a = c.toArray();
//数组a的长度numNew,也就是由多少个元素
int numNew = a.length;
if (numNew == 0)
//如果空的就什么也不做
return false;
Node<e> pred, succ;
//构造方法中传过来的就是index==size
//情况一:构造方法创建的一个空的链表,那么size=0,last、和first都为null。linkedList中是空的。
//什么节点都没有。succ=null、pred=last=null
//情况二:链表中有节点,size就不是为0,first和last都分别指向第一个节点,和最后一个节点,
//在最后一个节点之后追加元素,就得记录一下最后一个节点是什么,所以把last保存到pred临时节点中。
//情况三index!=size,说明不是前面两种情况,而是在链表中间插入元素,那么就得知道index上的节点是谁,
//保存到succ临时节点中,然后将succ的前一个节点保存到pred中,这样保存了这两个节点,就能够准确的插入节点了
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<e> newNode = new Node(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
/*如果succ==null,说明是情况一或者情况二,
情况一、构造方法,也就是刚创建的一个空链表,pred已经是newNode了,
last=newNode,所以linkedList的first、last都指向第一个节点。
情况二、在最后节后之后追加节点,那么原先的last就应该指向现在的最后一个节点了,
就是newNode。*/
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;}//根据引下标找到该结点并返回Node<e> node(int index) {
//判断插入的位置在链表前半段或者是后半段
if (index > 1)) {
Node<e> x = first;
//从头结点开始正向遍历
for (int i = 0; i x = last;
//从尾结点开始反向遍历
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}}</e></e></e></e>ログイン後にコピー
3.5 remove()
/*如果我们要移除的值在链表中存在多个一样的值,那么我们
会移除index最小的那个,也就是最先找到的那个值,如果不存在这个值,那么什么也不做
*/public boolean remove(Object o) {
if (o == null) {
for (Node<e> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<e> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;}不能传一个null值E unlink(Node<e> x) {
// assert x != null;
final E element = x.item;
final Node<e> next = x.next;
final Node<e> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
//x的前后指向都为null了,也把item为null,让gc回收它
x.item = null;
size--;
modCount++;
return element;}</e></e></e></e></e>ログイン後にコピー
3.6 其他方法
**get(index)、indexOf(Object o)**等查看源码即可
3.7 LinkedList的迭代器
在LinkedList中除了有一个Node的内部类外,应该还能看到另外两个内部类,那就是ListItr,还有一个是DescendingIterator内部类
/*这个类,还是调用的ListItr,作用是封装一下Itr中几个方法,让使用者以正常的思维去写代码,
例如,在从后往前遍历的时候,也是跟从前往后遍历一样,使用next等操作,而不用使用特殊的previous。
*/private class DescendingIterator implements Iterator<e> {
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}}</e>ログイン後にコピー
4、总结
- linkedList本质上是一个双向链表,通过一个Node内部类实现的这种链表结构。linkedList能存储null值
- 跟ArrayList相比较,就真正的知道了,LinkedList在删除和增加等操作上性能好,而ArrayList在查询的性能上好,从源码中看,它不存在容量不足的情况
- linkedList不光能够向前迭代,还能像后迭代,并且在迭代的过程中,可以修改值、添加值、还能移除值
- linkedList不光能当链表,还能当队列使用,这个就是因为实现了Deque接口
四、List总结
1、ArrayList和LinkedList区别
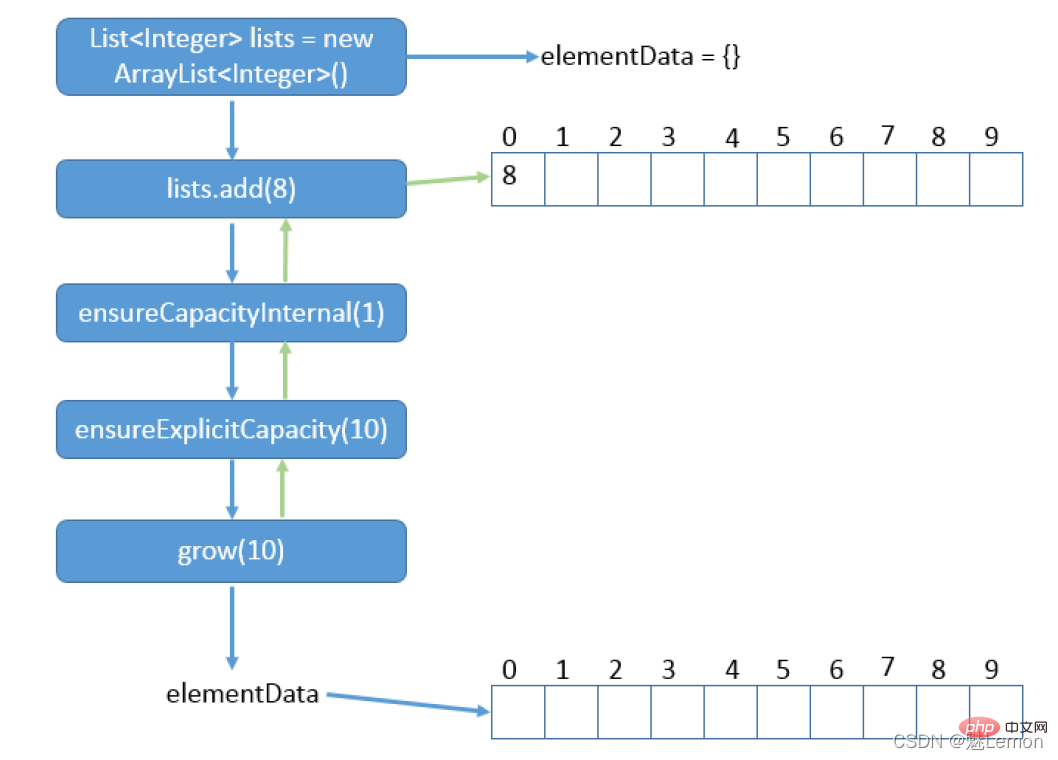
- ArrayList底层是用数组实现的顺序表,是随机存取类型,可自动扩增,并且在初始化时,数组的长度是0,只有在增加元素时,长度才会增加。默认是10,不能无限扩增,有上限,在查询操作的时候性能更好
- LinkedList底层是用链表来实现的,是一个双向链表,注意这里不是双向循环链表,顺序存取类型。在源码中,似乎没有元素个数的限制。应该能无限增加下去,直到内存满了在进行删除,增加操作时性能更好。
两个都是线程不安全的,在iterator时,会发生fail-fast:快速失效。
2. ArrayList と Vector の違い
- ArrayList はスレッド セーフではありません。イテレータを使用するとフェイルファストが発生します
- Vector は Synchronized キーを使用するためスレッド セーフです
#3. フェイルファストとフェイルセーフの違いと状況説明
すべてのコレクションはメソッドの前に追加されます。 java.util は失敗します。 -fast、java.util.concurrent で起こることはフェイルセーフです
- fail-fast 高速な失敗などarrayList と同様 イテレータを使用してトラバースする場合、別のスレッドが追加、削除など、arrayList のストレージ配列に変更を加え、構造上の変更が発生したため、イテレータはすぐに
java.util を報告します。 .ConcurrentModificationExceptionException (同時変更例外)、これは高速失敗です
- fail-safe 安全な失敗、
java.util.concurrent の下のクラス, すべて これはスレッドセーフなクラスです。反復プロセス中にスレッドが構造を変更しても、例外は報告されませんが、通常どおりに通過されます。これは安全な失敗です。
- なぜ java.util なのか。コンカレント パッケージのコレクションに構造的な変更があった場合、例外は報告されないのでしょうか? 並行コレクション クラスに要素を追加するときは、
Arrays.copyOf() を使用してコピーをコピーし、そのコピーに要素を追加します。他のスレッドがコレクションの構造を変更した場合、つまり、また、元のコレクションに影響を与えるのではなく、コピーに対する変更も行われます。イテレータは通常どおりトラバースします。トラバースが完了すると、元の参照はコピーを指すように変更されます。つまり、このパッケージの下のクラスが追加または削除すると、コピーが表示されます。したがって、フェイルファストを防ぐことができます。このメカニズムは誤動作しないため、この現象をフェイルセーフと呼びます。
- vector はスレッドセーフでもあります。なぜフェイルファストなのか? フェイルセーフは、追加と削除に対して異なる基礎メカニズムを実装しているためです。前述したように、コピーが存在しますが、arrayList、linekdList、verctor などの最下層は実際の参照に基づいています。操作、それが例外が発生する理由です。
4。今 Vector を使用することが推奨されない理由
Vector でスレッド セーフを実現する方法は、ロックを追加することです。これらのロックは必要ありません。実際の開発では、通常、一連の操作をロックすることでスレッド セーフを実現します。つまり、同期する必要があるリソースをまとめてロックして、スレッド セーフを確保します。- 複数のスレッドがロックされたメソッドを同時に実行する場合、このメソッドには Vector が存在します。Vector
- は独自の実装でロックされているため、ロックして再度ロックすることと同等であり、追加のオーバーヘッドが発生します。
Vector にはフェイルファストの問題もあります。つまり、トラバーサルのセキュリティを保証できません。トラバーサル中に追加のロックが必要になり、追加のオーバーヘッドが発生します。arrayList を直接使用してロックすることをお勧めします。-
概要: Vector は、スレッド セーフである必要がない場合にもロックし、追加のオーバーヘッドが発生するため、jdk1.5 以降は廃止されました。スレッド セーフなコレクションを使用するには、対応するクラスを次の場所から取得します。 java.util.concurrent パッケージ。
5. HashMap 分析1. HashMap の概要1.1 Java8
がキーと値を通じてエントリ オブジェクトにカプセル化される前の HashMap . 次に、キーの値に基づいてエントリのハッシュ値が計算されます。エントリのハッシュ値と配列の長さを使用して、エントリが配列内のどこに配置されるかを計算します。エントリが保存されるたびに、エントリは最初の位置に配置されます。
HashMap は Map インターフェイスを実装します。これにより、key を持つ要素を null にすることができ、value を ## に挿入することもできます。 #null; の要素は、このクラスが同期を実装していないことを除けば、残りは Hashtable とほぼ同じです。 TreeMap とは異なり、このコンテナは要素の順序を保証せず、コンテナは変更される可能性があります。 -必要に応じて要素をハッシュします。要素の順序も再シャッフルされるため、異なる時点で同じ HashMap を反復する順序は異なる場合があります。競合の処理方法に応じて、ハッシュ テーブルを実装するには 2 つの方法があります。1 つはオープン アドレッシング方式 (オープン アドレッシング)、もう 1 つは競合リンク リスト方式 (リンク リストによる分離チェーン) です。 Java7 HashMap は競合リンク リスト方式を使用します。
1.2 Java8后的HashMap
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度为 O(n)。为了降低这部分的开销,在 Java8 中,当链表中的元素达到了 8 个时,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
Java7 中使用 Entry 来代表每个 HashMap 中的数据节点,Java8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode
2、Java8 HashMap源码分析
2.1 继承结构与层次
public class HashMap<k> extends AbstractMap<k>
implements Map<k>, Cloneable, Serializable</k></k></k>
ログイン後にコピー
2.2 属性
//序列号private static final long serialVersionUID = 362498820763181265L;
//默认的初始容量static final int DEFAULT_INITIAL_CAPACITY = 1 [] table;
//存放具体元素的集transient Set<map.entry>> entrySet;
//存放元素的个数,注意这个不等于数组的长度transient int size;
//每次扩容和更改map结构的计数器transient int modCount;
//临界值,当实际大小(容量*填充因子)超过临界值时,会进行扩容int threshold;
//填充因子,计算HashMap的实时装载因子的方法为:size/capacityfinal float loadFactor;</map.entry>
ログイン後にコピー
2.3 构造方法
public HashMap(int initialCapacity, float loadFactor) {
// 初始容量不能小于0,否则报错
if (initialCapacity MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//填充因子不能小于或等于0,不能为非数字
if (loadFactor >> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n = MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}/**
* 自定义初始容量,加载因子为默认
*/public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);}/**
* 使用默认的加载因子等字段
*/public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}public HashMap(Map extends K, ? extends V> m) {
//初始化填充因子
this.loadFactor = DEFAULT_LOAD_FACTOR;
//将m中的所有元素添加至HashMap中
putMapEntries(m, false);}//将m的所有元素存入该实例final void putMapEntries(Map extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
//判断table是否已经初始化
if (table == null) { // pre-size
//未初始化,s为m的实际元素个数
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
//将m中的所有元素添加至HashMap中
for (Map.Entry extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}}ログイン後にコピー
2.4 核心方法
put()方法
先计算key的hash值,然后根据hash值搜索在table数组中的索引位置,如果table数组在该位置处有元素,则查找是否存在相同的key,若存在则覆盖原来key的value,否则将该元素保存在链表尾部,注意JDK1.7中采用的是头插法,即每次都将冲突的键值对放置在链表头,这样最初的那个键值对最终就会成为链尾,而JDK1.8中使用的是尾插法。此外,若table在该处没有元素,则直接保存。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<k>[] tab; Node<k> p; int n, i;
//第一次put元素时,table数组为空,先调用resize生成一个指定容量的数组
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//hash值和n-1的与运算结果为桶的位置,如果该位置空就直接放置一个Node
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//如果计算出的bucket不空,即发生哈希冲突,就要进一步判断
else {
Node<k> e; K k;
//判断当前Node的key与要put的key是否相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//判断当前Node是否是红黑树的节点
else if (p instanceof TreeNode)
e = ((TreeNode<k>)p).putTreeVal(this, tab, hash, key, value);
//以上都不是,说明要new一个Node,加入到链表中
else {
for (int binCount = 0; ; ++binCount) {
//在链表尾部插入新节点,注意jdk1.8是在链表尾部插入新节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果当前链表中的元素大于树化的阈值,进行链表转树的操作
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//在链表中继续判断是否已经存在完全相同的key
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//走到这里,说明本次put是更新一个已存在的键值对的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//在hashMap中,afterNodeAccess方法体为空,交给子类去实现
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//如果当前size超过临界值,就扩容。注意是先插入节点再扩容
if (++size > threshold)
resize();
//在hashMap中,afterNodeInsertion方法体为空,交给子类去实现
afterNodeInsertion(evict);
return null;}</k></k></k></k>ログイン後にコピー
resize() 数组扩容
用于初始化数组或数组扩容,每次扩容后,容量为原来的 2 倍,并进行数据迁移
final Node<k>[] resize() {
Node<k>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { // 对应数组扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 将数组大小扩大一倍
else if ((newCap = oldCap = DEFAULT_INITIAL_CAPACITY)
// 将阈值扩大一倍
newThr = oldThr 0) // 对应使用 new HashMap(int initialCapacity) 初始化后,第一次 put 的时候
newCap = oldThr;
else {// 对应使用 new HashMap() 初始化后,第一次 put 的时候
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap [] newTab = (Node<k>[])new Node[newCap];
table = newTab; // 如果是初始化数组,到这里就结束了,返回 newTab 即可
if (oldTab != null) {
// 开始遍历原数组,进行数据迁移。
for (int j = 0; j e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果该数组位置上只有单个元素,那就简单了,简单迁移这个元素就可以了
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 如果是红黑树,具体我们就不展开了
else if (e instanceof TreeNode)
((TreeNode<k>)e).split(this, newTab, j, oldCap);
else {
// 这块是处理链表的情况,
// 需要将此链表拆成两个链表,放到新的数组中,并且保留原来的先后顺序
// loHead、loTail 对应一条链表,hiHead、hiTail 对应另一条链表,代码还是比较简单的
Node<k> loHead = null, loTail = null;
Node<k> hiHead = null, hiTail = null;
Node<k> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 第一条链表
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 第二条链表的新的位置是 j + oldCap,这个很好理解
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;}</k></k></k></k></k></k></k>ログイン後にコピー
get()过程
public V get(Object key) {
Node<k> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;}final Node<k> getNode(int hash, Object key) {
Node<k>[] tab; Node<k> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 判断第一个节点是不是就是需要的
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
// 判断是否是红黑树
if (first instanceof TreeNode)
return ((TreeNode<k>)first).getTreeNode(hash, key);
// 链表遍历
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;}</k></k></k></k></k>ログイン後にコピー
2.5 其他方法
HashSet是对HashMap的简单包装,其他还有迭代器等
3、总结
关于数组扩容,从putVal源代码中我们可以知道,当插入一个元素的时候size就加1,若size大于threshold的时候,就会进行扩容。假设我们的capacity大小为32,loadFator为0.75,则threshold为24 = 32 * 0.75,此时,插入了25个元素,并且插入的这25个元素都在同一个桶中,桶中的数据结构为红黑树,则还有31个桶是空的,也会进行扩容处理,其实此时,还有31个桶是空的,好像似乎不需要进行扩容处理,但是是需要扩容处理的,因为此时我们的capacity大小可能不适当。我们前面知道,扩容处理会遍历所有的元素,时间复杂度很高;前面我们还知道,经过一次扩容处理后,元素会更加均匀的分布在各个桶中,会提升访问效率。所以说尽量避免进行扩容处理,也就意味着,遍历元素所带来的坏处大于元素在桶中均匀分布所带来的好处。
- HashMap在JDK1.8以前是一个链表散列这样一个数据结构,而在JDK1.8以后是一个数组加链表加红黑树的数据结构
- 通过源码的学习,HashMap是一个能快速通过key获取到value值得一个集合,原因是内部使用的是hash查找值得方法
另外LinkedHashMap是HashMap的直接子类,二者唯一的区别是LinkedHashMap在HashMap的基础上,采用双向链表(doubly-linked list)的形式将所有**entry**连接起来,这样是为保证元素的迭代顺序跟插入顺序相同
六、Collections工具类
1、概述
此类完全由在 collection 上进行操作或返回 collection 的静态方法组成。它包含在 collection 上操作的多态算法,即“包装器”,包装器返回由指定 collection 支持的新 collection,以及少数其他内容。如果为此类的方法所提供的 collection 或类对象为 null,则这些方法都将抛出NullPointerException
2、排序常用方法
//反转列表中元素的顺序
static void reverse(List> list)
//对List集合元素进行随机排序
static void shuffle(List> list)
//根据元素的自然顺序 对指定列表按升序进行排序
static void sort(List<t> list)
//根据指定比较器产生的顺序对指定列表进行排序
static <t> void sort(List<t> list, Comparator super T> c)
//在指定List的指定位置i,j处交换元素
static void swap(List> list, int i, int j)
//当distance为正数时,将List集合的后distance个元素“整体”移到前面;当distance为负数时,将list集合的前distance个元素“整体”移到后边。该方法不会改变集合的长度
static void rotate(List> list, int distance)</t></t></t>
ログイン後にコピー
3、查找、替换操作
//使用二分搜索法搜索指定列表,以获得指定对象在List集合中的索引
//注意:此前必须保证List集合中的元素已经处于有序状态
static <t> int binarySearch(List extends Comparable super T>>list, T key)
//根据元素的自然顺序,返回给定collection 的最大元素
static Object max(Collection coll)
//根据指定比较器产生的顺序,返回给定 collection 的最大元素
static Object max(Collection coll,Comparator comp):
//根据元素的自然顺序,返回给定collection 的最小元素
static Object min(Collection coll):
//根据指定比较器产生的顺序,返回给定 collection 的最小元素
static Object min(Collection coll,Comparator comp):
//使用指定元素替换指定列表中的所有元素
static <t> void fill(List super T> list,T obj)
//返回指定co1lection中等于指定对象的出现次数
static int frequency(collection>c,object o)
//返回指定源列表中第一次出现指定目标列表的起始位置;如果没有出现这样的列表,则返回-1
static int indexofsubList(List>source, List>target)
//返回指定源列表中最后一次出现指定目标列表的起始位置;如果没有出现这样的列表,则返回-1
static int lastIndexofsubList(List>source,List>target)
//使用一个新值替换List对象的所有旧值o1dval
static <t> boolean replaceA1l(list<t> list,T oldval,T newval)</t></t></t></t>
ログイン後にコピー
4、同步控制
Collectons提供了多个synchronizedXxx()方法,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。正如前面介绍的HashSet,TreeSet,arrayList,LinkedList,HashMap,TreeMap都是线程不安全的。Collections提供了多个静态方法可以把他们包装成线程同步的集合。
//返回指定 Collection 支持的同步(线程安全的)collection
static <T> Collection<T> synchronizedCollection(Collection<T> c)
//返回指定列表支持的同步(线程安全的)列表
static <T> List<T> synchronizedList(List<T> list)
//返回由指定映射支持的同步(线程安全的)映射
static <K,V> Map<K,V> synchronizedMap(Map<K,V> m)
//返回指定 set 支持的同步(线程安全的)set
static <T> Set<T> synchronizedSet(Set<T> s)
ログイン後にコピー
5、Collection设置不可变集合
//返回一个空的、不可变的集合对象,此处的集合既可以是List,也可以是Set,还可以是Map。
emptyXxx()
//返回一个只包含指定对象(只有一个或一个元素)的不可变的集合对象,此处的集合可以是:List,Set,Map。
singletonXxx():
//返回指定集合对象的不可变视图,此处的集合可以是:List,Set,Map
unmodifiableXxx()
ログイン後にコピー
推荐学习:《java教程》




























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



