
この記事では、Redis に関する関連知識を提供し、主に単純な動的文字列、リンク リスト、辞書、ジャンプ テーブル、整数などの 6 つの基礎となるデータ構造に関連する問題を紹介します。コレクションと圧縮リスト、それがみんなに役立つことを願っています。

推奨学習: Redis チュートリアル
Redis ですがRedis は C 言語で書かれていますが、Redis は C 言語の伝統的な文字列表現 (ヌル文字 '\0' で終わる文字配列) を直接使用しません。次に、単純な動的文字列 (単純な動的文字列、SDS) と呼ばれる独自のメソッドを構築しました。 ) 抽象型であり、Redis のデフォルトの文字列表現として SDS を使用します。
Redis では、C 文字列は、ログの印刷など、文字列値を変更する必要がない場所でのみ文字列リテラルとして使用されます。
SDS の定義:
struct sdshdr{
//记录buf数组中已使用字节的数量
//等于 SDS 所保存字符串的长度
int len;
//记录 buf 数组中未使用字节的数量
int free;
//字节数组,用于保存字符串
char buf[];}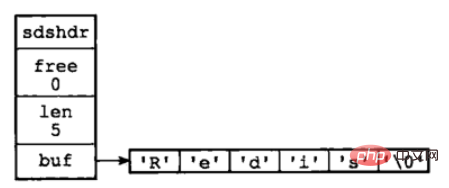
① free 属性の値は 0 で、この SDS が未使用の領域を割り当てないことを示します。
② len 属性の値は 5 です。これは、この SDS に 5 バイトの長さの文字列が格納されることを意味します。
③ buf 属性は char 型の配列で、配列の最初の 5 バイトには 'R'、'e'、
'd'、'i'、's' の 5 文字が格納されます。 、最後の 1 バイトにはヌル文字「\0」が格納されます。
(SDS は、C 文字列は null 文字で終了するという規則に従っています。null 文字を保持する 1 バイトのスペースは、SDS の len 属性にはカウントされず、追加の 1 バイトのスペースが割り当てられます。 NULL 文字を文字列の末尾に移動するなどの操作は、SDS 関数によって自動的に完了します。すべての NULL 文字は、SDS のユーザーにとって完全に透過的です。NULL 文字終了の規則に従う利点は、次のとおりです。 SDS は文字列関数ライブラリ内の C 関数を直接再利用できます。)
SDS と C ワード浮動文字列の違い:
(1)文字列長を取得するための一定の複雑さ
C 文字列には独自の長さ情報が記録されないため、C 文字列の長さを取得するには、プログラムは文字列全体を走査し、文字列の終わりを表す NULL 文字が見つかるまで、見つかった各文字をカウントする必要があります。この操作の複雑さは O(N) です。
C 文字列とは異なり、SDS は SDS 自体の長さを len 属性に記録するため、SDS の長さを取得する複雑さはわずか O(1) です。
(2)バッファ オーバーフローの防止
C 言語では strcat 関数を使用して 2 つの文字列を結合することが知られていますが、十分な長さのメモリ領域が割り当てられないと、バッファオーバーフロー。 SDS データ型の場合、文字を変更する際は、記録された len 属性に基づいてメモリ空間が要件を満たしているかどうかを確認し、満たしていない場合は該当する空間を拡張してから変更操作を実行します。バッファがありません。オーバーフローします。
(3)文字列変更のためのメモリ再割り当ての数を減らす
C 言語では文字列の長さが記録されないため、文字列を変更したい場合は、次のようにする必要があります。メモリを再割り当てします (最初に解放してから適用します)。再割り当てがない場合、文字列の長さが増加するとメモリ バッファ オーバーフローが発生し、文字列の長さが減少するとメモリ リークが発生します。
SDS の場合、len 属性と free 属性の存在により、SDS は文字列を変更するためのスペースの事前割り当てと遅延スペースの解放という 2 つの戦略を実装します。スペースの事前割り当て Allocation
: 文字列のスペースを拡張すると、実際に必要なメモリよりも多くのメモリが拡張されるため、継続的な文字列の拡大操作に必要なメモリの再割り当ての回数が削減されます。2. 遅延スペース解放
: 文字列を短縮する場合、プログラムは短縮後に余分なバイトをリサイクルするためにすぐにメモリの再割り当てを使用せず、代わりに free 属性を使用してこれらの単語を解放します。セクションの数は、後で使用するために記録されます。 (もちろん、SDS は対応する API も提供しており、必要に応じてこれらの未使用のスペースを手動で解放することもできます)。(4)バイナリ セキュリティ
C 文字列は文字列の末尾の識別子として null 文字を使用するため、また一部のバイナリ ファイル (画像など) では、コンテンツには NULL 文字列が含まれる可能性があるため、C 文字列に正しくアクセスできません。また、すべての SDS API は buf 内の要素をバイナリ方式で処理し、SDS は空の文字列を使用して終了かどうかを判断しませんが、次のように表される長さを使用します。 len 属性。文字列が終了するかどうかを判断します。 (5)
一部の C 文字列関数との互換性
SDS の API はバイナリ セーフですが、C 文字列は null 文字で終わるという規則にも準拠しています。 SDS によって保存されたデータの一部は常に null 文字に設定され、buf 配列にスペースを割り当てるときに null 文字を収容するためにさらに 1 バイトが常に割り当てられます。これは、テキスト データを保存する SDS がデータの一部を再利用できるようにするためです。 ライブラリによって定義された関数。 (6)总结 作为一种常用数据结构,链表内置在很多高级的编程语言里面,因为Redis使用的 C 语言并没有内置这种数据结构,所以 Redis 构建了自己的链表结构。 每个链表节点使用一个 adlist.h/listNode 结构来表示: 多个 listNode 可以通过 prev 和 next 指针组成双端链表, 如图 3-1 所示。 list 结构为链表提供了表头指针 head 、表尾指针 tail , 以及链表长度计数器 len , 而 dup 、 free 和 match 成员则是用于实现多态链表所需的类型特定函数: 图 3-2 是由一个 list 结构和三个 listNode 结构组成的链表: 字典又称为符号表或者关联数组、或映射(map),是一种用于保存键值对的抽象数据结构。字典中的每一个键 key 都是唯一的,通过 key 可以对值来进行查找或修改。C 语言中没有内置这种数据结构的实现,所以字典依然是 Redis 自己构建的。 Redis 的字典使用哈希表作为底层实现, 一个哈希表里面可以有多个哈希表节点, 而每个哈希表节点就保存了字典中的一个键值对。 Redis 字典所使用的哈希表由 dict.h/dictht 结构定义: 图 4-1 展示了一个大小为 4 的空哈希表 (没有包含任何键值对)。 哈希表节点使用 dictEntry 结构表示, 每个 dictEntry 结构都保存着一个键值对: key 用来保存键,val 属性用来保存值,值可以是一个指针,也可以是uint64_t 整数,也可以是 int64_t 整数。 注意这里还有一个指向下一个哈希表节点的指针,我们知道哈希表最大的问题是存在哈希冲突,如何解决哈希冲突,有开放地址法和链地址法。这里采用的便是链地址法,通过 next 这个指针可以将多个哈希值相同的键值对连接在一起,用来解决哈希冲突。 (因为 dictEntry 节点组成的链表没有指向链表表尾的指针, 所以为了速度考虑, 程序总是将新节点添加到链表的表头位置(复杂度为 O(1)), 排在其他已有节点的前面。) Redis 中的字典由 dict.h/dict 结构表示: type 属性和 privdata 属性是针对不同类型的键值对, 为创建多态字典而设置的: ● type 属性是一个指向 dictType 结构的指针, 每个 dictType 结构保存了一簇用于操作特定类型键值对的函数, Redis 会为用途不同的字典设置不同的类型特定函数。 ht 属性是一个包含两个项的数组, 数组中的每个项都是一个 dictht 哈希表, 一般情况下, 字典只使用 ht[0] 哈希表, ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用。 除了 ht[1] 之外, 另一个和 rehash 有关的属性就是 rehashidx : 它记录了 rehash 目前的进度, 如果目前没有在进行 rehash , 那么它的值为 -1 。 图 4-3 展示了一个普通状态下(没有进行 rehash)的字典: ②解决哈希冲突:这个问题上面我们介绍了,方法是链地址法。通过字典里面的 *next 指针指向下一个具有相同索引值的哈希表节点。 ③扩容和收缩(rehash):当哈希表保存的键值对太多或者太少时,就要通过 rerehash(重新散列)来对哈希表进行相应的扩展或者收缩。具体步骤: 1、为字典的 ht[1] 哈希表分配空间, 这个哈希表的空间大小取决于要执行的操作, 以及 ht[0] 当前包含的键值对数量 (也即是 ht[0].used 属性的值) ④触发扩容与收缩的条件: 2、服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于5。 ps:负载因子 = 哈希表已保存节点数量 / 哈希表大小。 3、另一方面, 当哈希表的负载因子小于 0.1 时, 程序自动开始对哈希表执行收缩操作。 ⑤渐近式 rehash 跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。 具有如下性质: 2、每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点; 3、最底层的链表包含了所有的元素; 4、如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集); 5、链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点; 和链表、字典等数据结构被广泛地应用在 Redis 内部不同, Redis 只在两个地方用到了跳跃表, 一个是实现有序集合键, 另一个是在集群节点中用作内部数据结构, 除此之外, 跳跃表在 Redis 里面没有其他用途。 该结构包含以下属性: ②后退(backward)指针:节点中用 BW 字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。 ③分值(score):各个节点中的 1.0 、 2.0 和 3.0 是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。 ④成员对象(obj):各个节点中的 o1 、 o2 和 o3 是节点所保存的成员对象。 注意表头节点和其他节点的构造是一样的: 表头节点也有后退指针、分值和成员对象, 不过表头节点的这些属性都不会被用到, 所以图中省略了这些部分, 只显示了表头节点的各个层。 ① header :指向跳跃表的表头节点。 整数集合(intset)是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用集合作为集合键的底层实现。 整数集合(intset)是Redis用于保存整数值的集合抽象数据类型,它可以保存类型为int16_t、int32_t 或者int64_t 的整数值,并且保证集合中不会出现重复元素。 每个 intset.h/intset 结构表示一个整数集合: 整数集合的每个元素都是 contents 数组的一个数据项,它们按照从小到大的顺序排列,并且不包含任何重复项。 length 属性记录了 contents 数组的大小。 需要注意的是虽然 contents 数组声明为 int8_t 类型,但是实际上contents 数组并不保存任何 int8_t 类型的值,其真正类型有 encoding 来决定。 ② 降级 压缩列表(ziplist)是列表键和哈希键的底层实现之一。 因为哈希键里面包含的所有键和值都是小整数值或者短字符串。 压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。 圧縮リストには任意の数のノード (エントリ) を含めることができ、各ノードにはバイト配列または整数値を格納できます。 ② エンコーディング: ノードのエンコーディングは、ノードのコンテンツのコンテンツ タイプと長さを保存します。エンコーディング タイプには 2 つあり、1 つはバイト配列で、もう 1 つは整数です。エンコーディング領域の長さは次のとおりです。 1 バイト、2 バイト、または 5 バイトの長さ。 チェーン更新は複雑ですが、実際にパフォーマンスの問題が発生する可能性は非常に低いことに注意してください。 推奨される学習: Redis学習チュートリアル
2、链表
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;} listNode;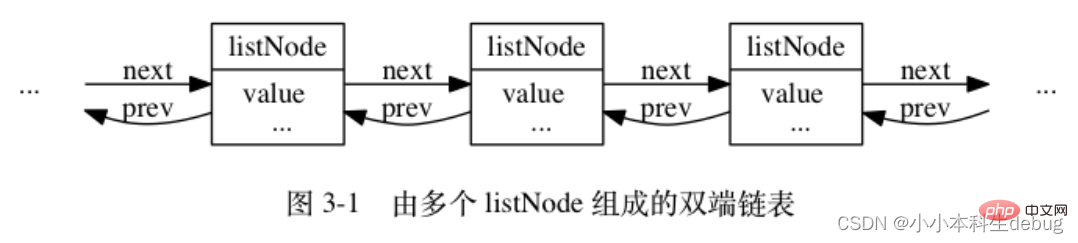
虽然仅仅使用多个 listNode 结构就可以组成链表, 但使用 adlist.h/list 来持有链表的话, 操作起来会更方便:typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);} list;
① dup 函数用于复制链表节点所保存的值;
② free 函数用于释放链表节点所保存的值;
③ match 函数则用于对比链表节点所保存的值和另一个输入值是否相等。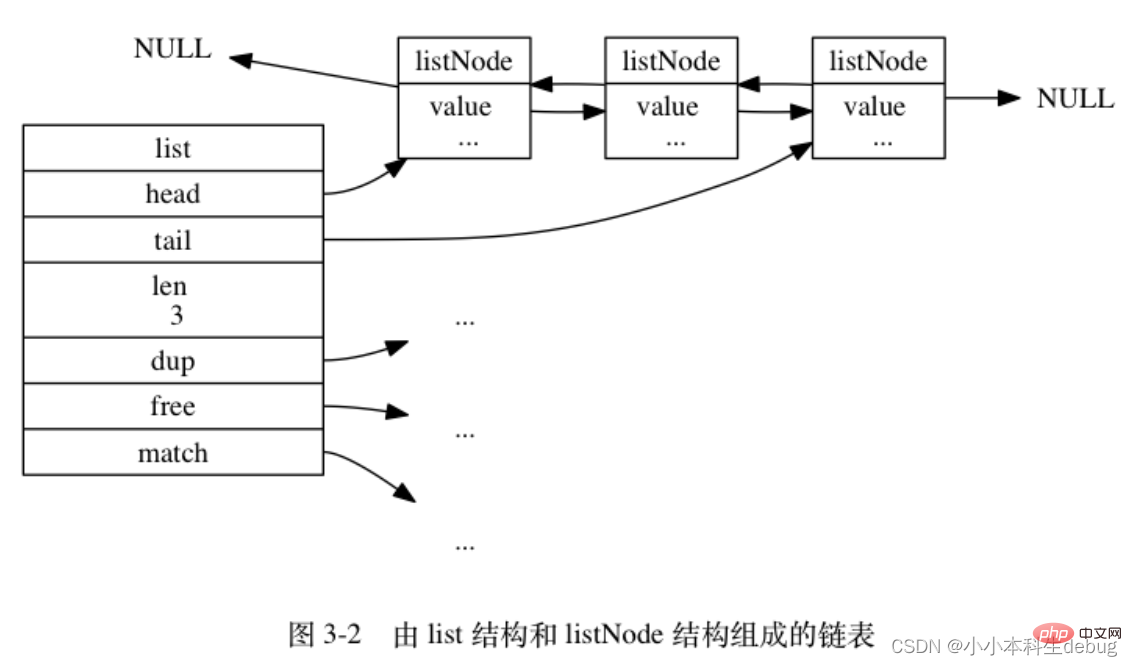
Redis 的链表实现的特性可以总结如下:
①双端: 链表节点带有 prev 和 next 指针, 获取某个节点的前置节点和后置节点的复杂度都是 O(1) 。
②无环: 表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL , 对链表的访问以 NULL 为终点。
③带表头指针和表尾指针: 通过 list 结构的 head 指针和 tail 指针, 程序获取链表的表头节点和表尾节点的复杂度为 O(1) 。
④带链表长度计数器: 程序使用 list 结构的 len 属性来对 list 持有的链表节点进行计数, 程序获取链表中节点数量的复杂度为 O(1) 。
⑤多态: 链表节点使用 void* 指针来保存节点值, 并且可以通过 list 结构的 dup 、 free 、 match 三个属性为节点值设置类型特定函数, 所以链表可以用于保存各种不同类型的值。3、字典
哈希表
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;} dictht;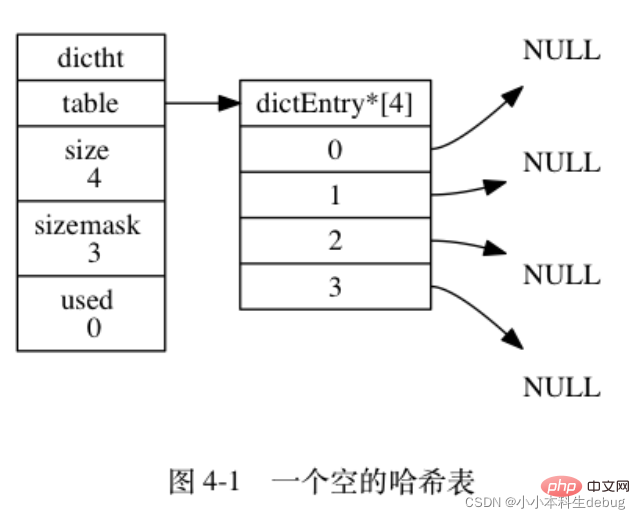
哈希表节点
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;} dictEntry;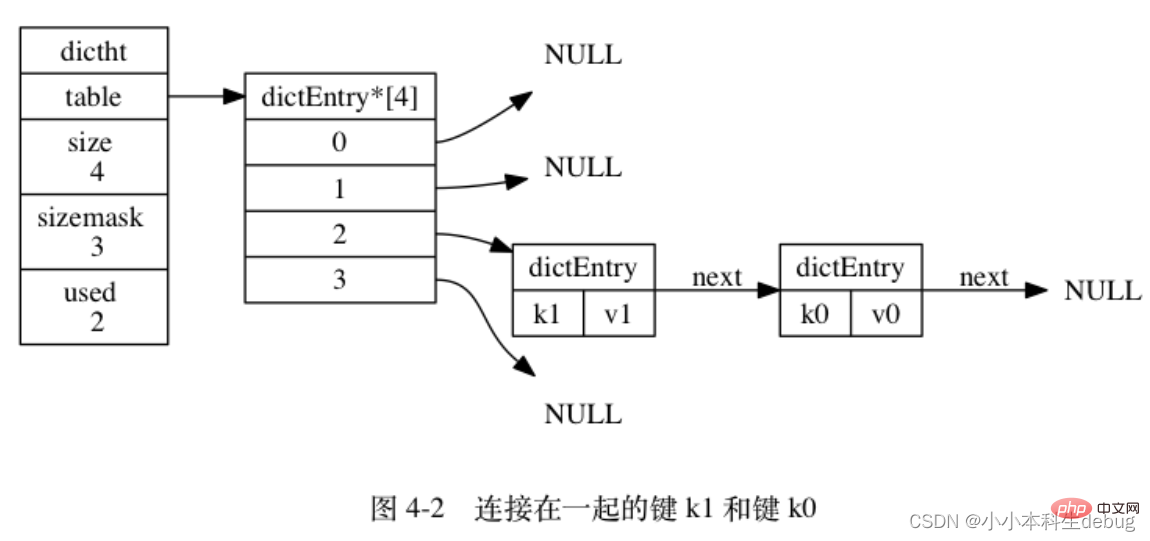
字典
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx;
/* rehashing not in progress if rehashidx == -1 */} dict;
● 而 privdata 属性则保存了需要传给那些类型特定函数的可选参数。typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);} dictType;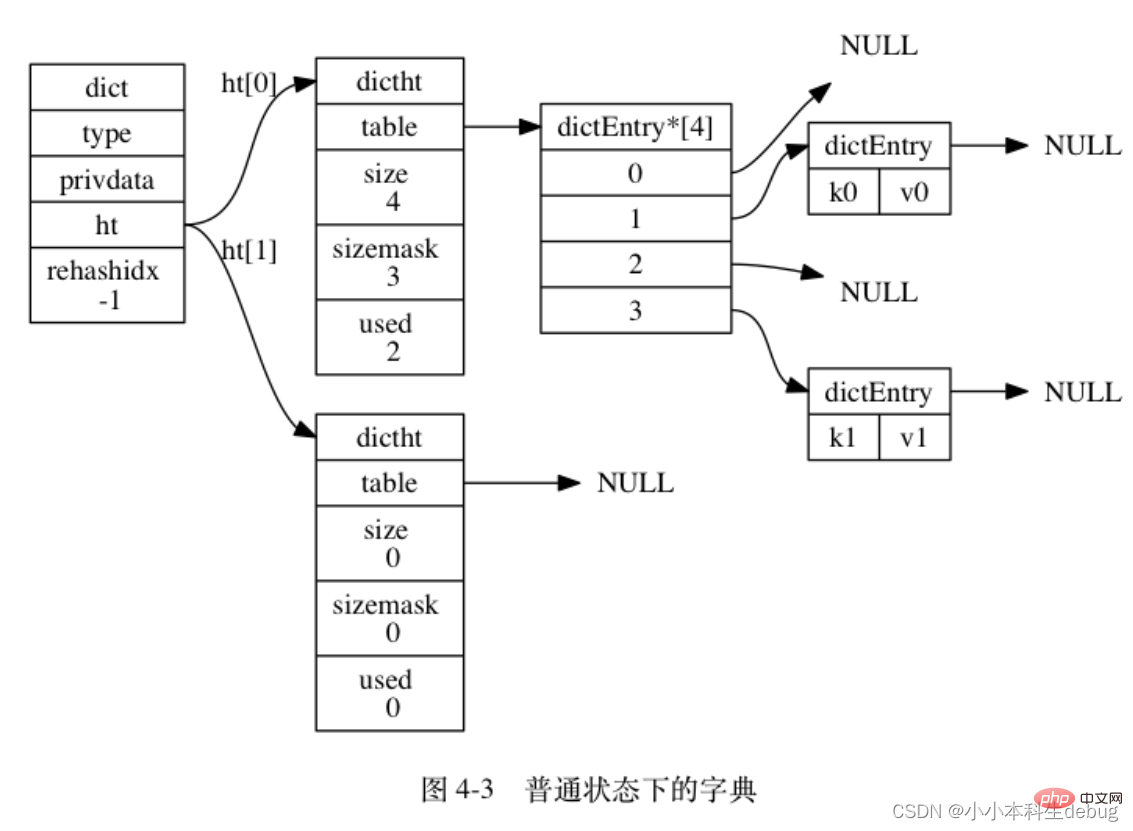
① 哈希算法:Redis计算哈希值和索引值方法如下:# 使用字典设置的哈希函数,计算键 key 的哈希值
hash = dict->type->hashFunction(key);# 使用哈希表的 sizemask 属性和哈希值,计算出索引值
# 根据情况不同, ht[x] 可以是 ht[0] 或者 ht[1]index = hash & dict->ht[x].sizemask;
● 如果执行的是扩展操作, 那么 ht[1] 的大小为第一个大于等于 ht[0].used * 2n; (也就是每次扩展都是根据原哈希表已使用的空间扩大一倍创建另一个哈希表)
● 如果执行的是收缩操作, 每次收缩是根据已使用空间缩小一倍创建一个新的哈希表。
2、将保存在 ht[0] 中的所有键值对 rehash 到 ht[1] 上面: rehash 指的是重新计算键的哈希值和索引值, 然后将键值对放置到 ht[1] 哈希表的指定位置上。
3、当 ht[0] 包含的所有键值对都迁移到了 ht[1] 之后 (ht[0] 变为空表), 释放 ht[0] , 将 ht[1] 设置为 ht[0] , 并在 ht[1] 新创建一个空白哈希表, 为下一次 rehash 做准备。
1、服务器目前没有执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于1。
什么叫渐进式 rehash?也就是说扩容和收缩操作不是一次性、集中式完成的,而是分多次、渐进式完成的。如果保存在Redis中的键值对只有几个几十个,那么 rehash 操作可以瞬间完成,但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行 rehash,势必会造成Redis一段时间内不能进行别的操作。所以Redis采用渐进式 rehash,这样在进行渐进式rehash期间,字典的删除查找更新等操作可能会在两个哈希表上进行,第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行增加操作,一定是在新的哈希表上进行的。4、跳跃表
1、由很多层结构组成;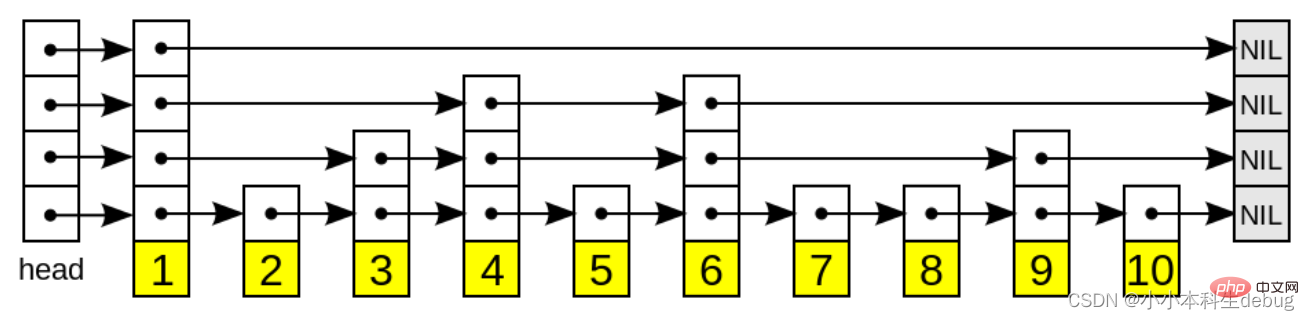
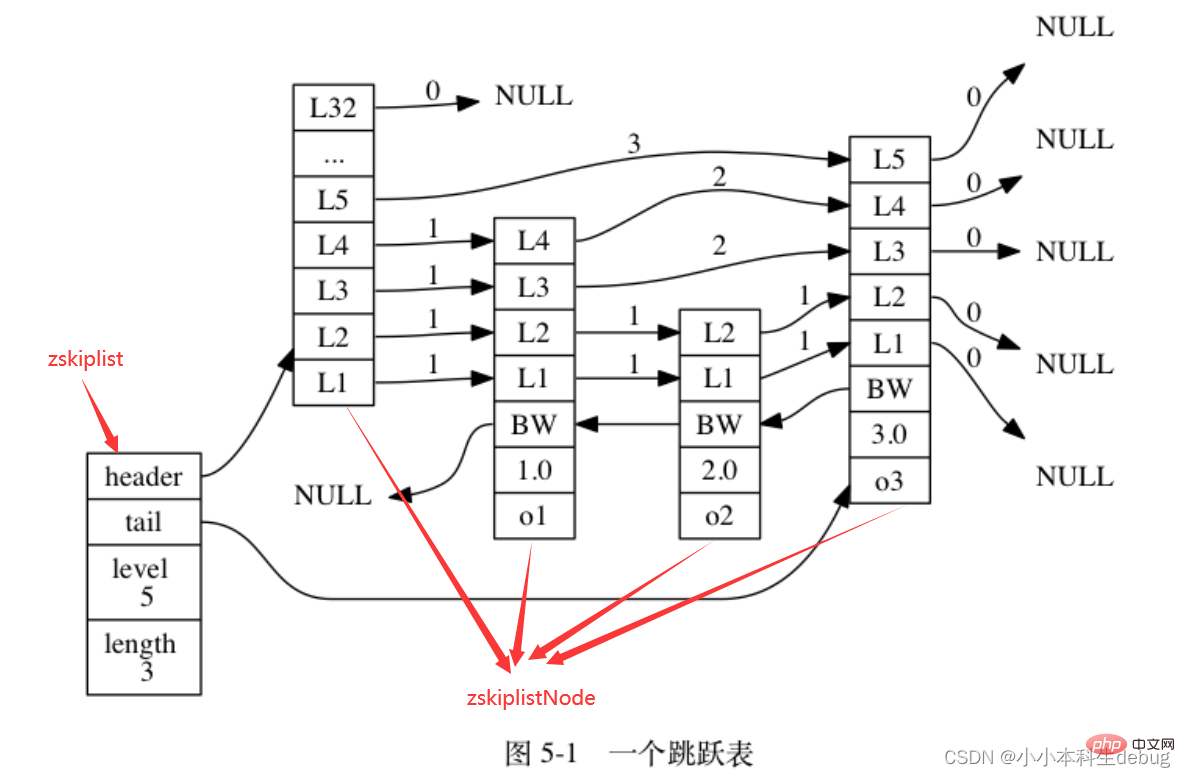
跳跃表节点(zskiplistNode)
①层(level):节点中用 L1 、 L2 、 L3 等字样标记节点的各个层, L1 代表第一层, L2 代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则记录了前进指针所指向节点和当前节点的距离。在上面的图片中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。
每次创建一个新跳跃表节点的时候, 程序都根据幂次定律 (power law,越大的数出现的概率越小) 随机生成一个介于 1 和 32 之间的值作为 level 数组的大小, 这个大小就是层的“高度”。(所以说表头节点的高度就是32)跳跃表(zskiplist)
② tail :指向跳跃表的表尾节点。
③ level :记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)。
④ length :记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)。5、整数集合
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];} intset;
① 升级(encoding int16_t -> int32_t -> int64_t)
当我们新增的元素类型比原集合元素类型的长度要大时,需要对整数集合进行升级,才能将新元素放入整数集合中。具体步骤:
1、根据新元素类型,扩展整数集合底层数组的大小,并为新元素分配空间。
2、将底层数组现有的所有元素都转成与新元素相同类型的元素,并将转换后的元素放到正确的位置,放置过程中,维持整个元素顺序都是有序的。
3、将新元素添加到整数集合中(保证有序)。
升级能极大地节省内存。
整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态。6、压缩列表
当一个列表键只包含少量列表项, 并且每个列表项要么就是小整数值, 要么就是长度比较短的字符串, 那么 Redis 就会使用压缩列表来做列表键的底层实现。
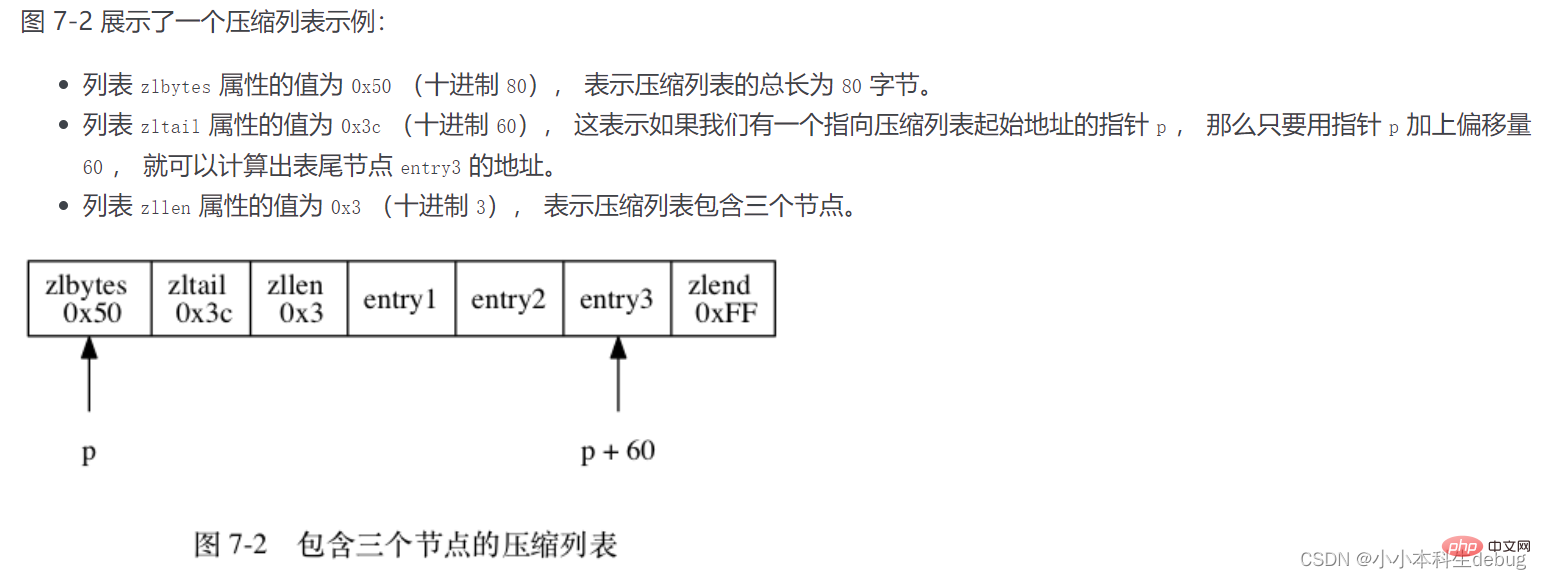
各圧縮リスト ノードは、previous_entry_length、エンコーディング、およびコンテンツの 3 つの部分で構成されます。 
①Previous_entry_ength: 圧縮の前のバイトを記録します。リストの長さ。 previous_entry_ength の長さは 1 バイトまたは 5 バイトです。前のノードの長さが 254 未満の場合、ノードは前のノードの長さを表すために 1 バイトだけを必要とします。前のノードの長さが 254 以上の場合、属性の最初のバイトは 254 で、次の 4 バイトは現在のノードの前のノードの長さを表します。この原理を使用すると、前のノードの開始位置は、現在のノードの位置から前のノードの長さを減算することによって取得され、圧縮されたリストを末尾から先頭までたどることができます。これにより、メモリの無駄が効果的に削減されます。 
③コンテンツ: コンテンツ領域はノードのコンテンツを保存するために使用され、ノードのコンテンツのタイプと長さはエンコードによって決まります。 
チェーン更新の問題
チェーン更新では、最悪の場合、圧縮リスト上で N 個の空間再割り当て操作が必要になります。各空間再割り当ての最悪の場合の複雑さは次のようになります。 O(N) であるため、チェーン更新の最悪の複雑さは O(N^2) です。
以上がRedis の 6 つの基礎となるデータ構造を要約して整理するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



