

この記事では、python に関する関連知識を提供します。主に、NumPy の予備的な使用、Matplotlib パッケージの使用、データ統計のビジュアル表示など、データ処理と視覚化に関する関連問題を紹介します。皆さんのお役に立てば幸いです。

推奨学習: python チュートリアル
テーブルはデータの一般的な表現です表形式ですが、機械にとっては理解できない、つまり認識できないデータなので、テーブルの形式を調整する必要があります。
一般的に使用される機械学習表現はデータ行列です。 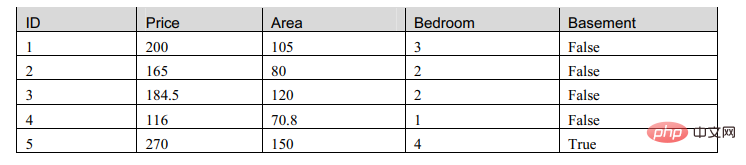
この表を観察したところ、マトリックスには 2 つのタイプの属性があることがわかりました。1 つは数値タイプで、もう 1 つはブールタイプです。そこで、このテーブルを記述するモデルを構築します。
# 数据的矩阵化import numpy as np data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False], [4,116,70.8,1,False],[5,270,150,4,True]])row = 0for line in data: row += 1print( row )print(data.size)print(data)
ここのコードの最初の行は、NumPy を導入し、その名前を np に変更することを意味します。 2 行目では、NumPy の mat() メソッドを使用してデータ行列を作成します。row は行数を計算するために導入された変数です。
ここでのサイズは 5*5 のテーブルを意味します。データを直接印刷することでデータを確認できます: 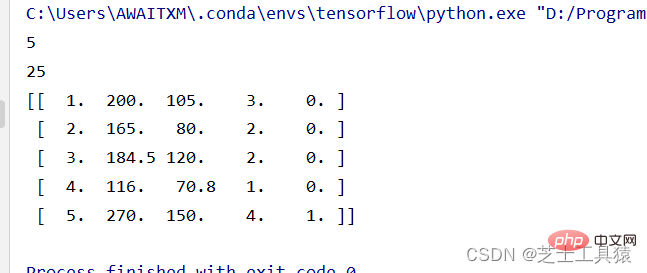
引き続き上の表を見てみましょう。2 番目の列は住宅価格の違いです。違いを直感的に見るのは簡単ではありません (数字しかないため)。なので、それを図で示したいと思います (Research The数値的な差異や異常を検出する方法は、データの分布を描画することです ):
import numpy as npimport scipy.stats as statsimport pylab data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False], [4,116,70.8,1,False],[5,270,150,4,True]])coll = []for row in data: coll.append(row[0,1])stats.probplot(coll,plot=pylab)pylab.show()
このコードの結果、グラフが生成されます: 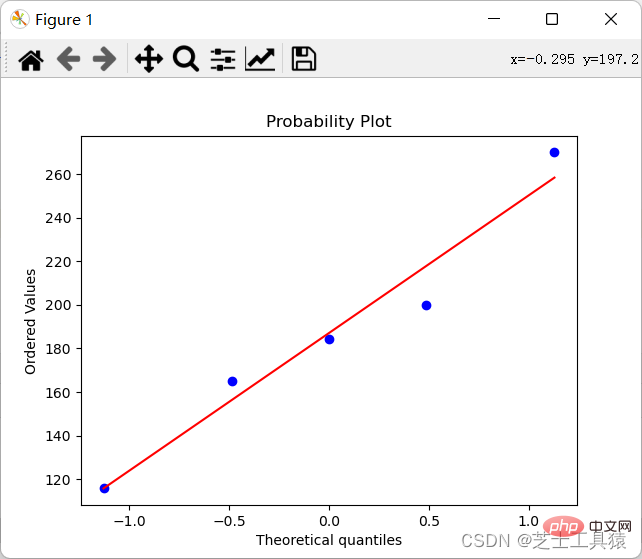
見てください、違いがあります。
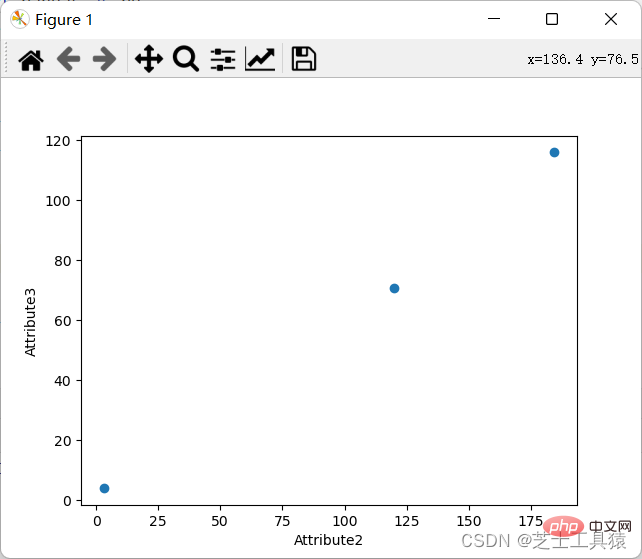
座標グラフの要件は、さまざまな行と列を通じてデータの特定の値を表示することです。
もちろん、座標図を表示することもできます: 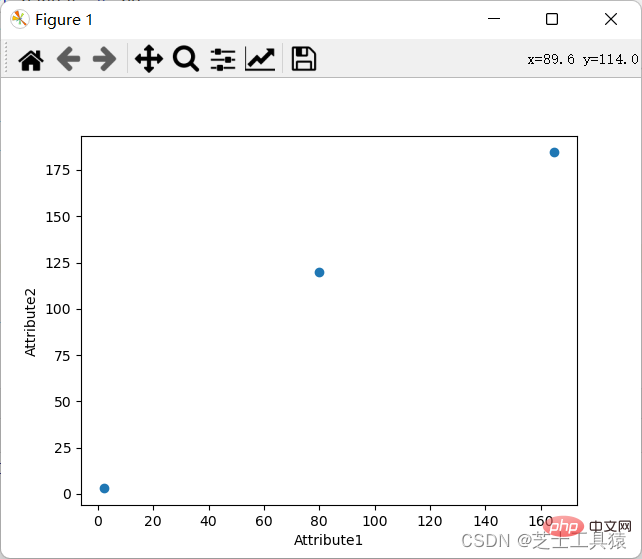
類似度計算方法は多数ありますが、最もよく使用される 2 つの計算方法、つまりユークリッド類似度計算とコサイン類似度計算を選択します。
ユークリッド距離は、3 次元空間内の 2 点間の真の距離を表すために使用されます。この公式は誰もが知っていますが、その名前を聞くことはめったにありません: 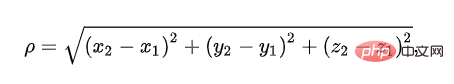
それでは、実際の応用例を見てみましょう:
この表は、3 人のユーザーによるアイテムの評価を示しています: 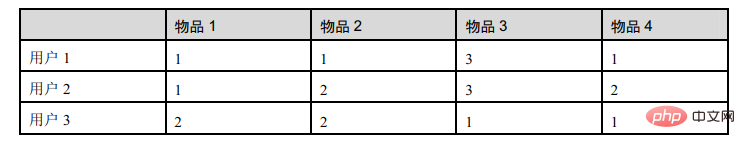
d12 はユーザー 1 とユーザー 2 の類似性を表し、次のようになります。 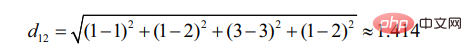
同様に、d13: 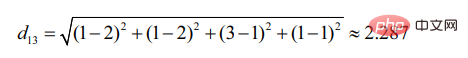
ユーザー 2 は次のとおりであることがわかります。ユーザー 1 に似ています (距離が小さいほど、類似性は高くなります)。
コサイン角の計算の開始点は、夾角の差です。 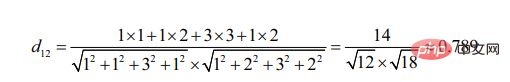
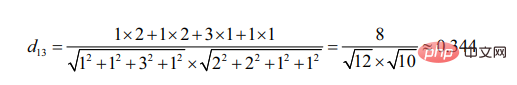
ユーザー 3 と比較すると、ユーザー 2 はユーザー 1 に似ていることがわかります (2 つのターゲットが似ているほど、形成される角度が小さくなります)
四分位数は統計です中央値スコア データを小さいものから大きいものまで並べて 4 等分し、その 3 つの分割点のデータが四分位になります。
第 1 四分位 (Q1)、下位四分位 とも呼ばれます;
第 2 四分位 (Q1)、中央値 とも呼ばれます;
第 3 四分位 (Q1)、下位四分位 ;
第 3 四分位と第 1 四分位の間のギャップは次のとおりです。 4 ポイント ギャップ (IQR) とも呼ばれます。
若n为项数,则:
Q1的位置 = (n+1)*0.25
Q2的位置 = (n+1)*0.50
Q3的位置 = (n+1)*0.75
四分位示例:
关于这个rain.csv,有需要的可以私我要文件,我使用的是亳州市2010-2019年的月份降水情况。
from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()print(summary)array = dataFile.iloc[:,:].values
boxplot(array)plot.xlabel("year")plot.ylabel("rain")show()以下是plot运行结果: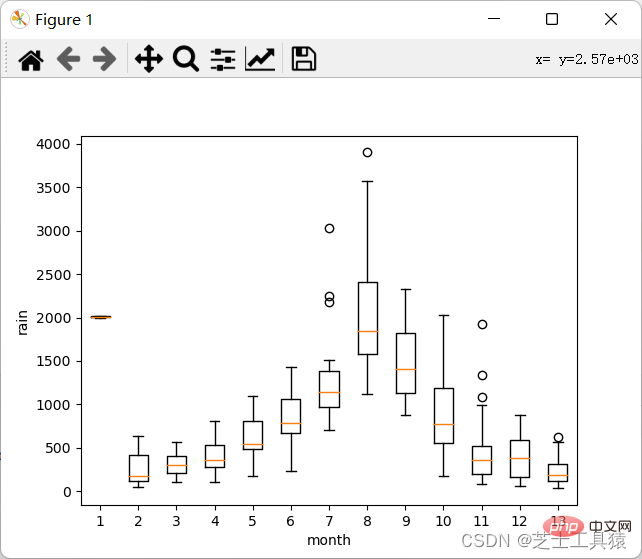
这个是pandas的运行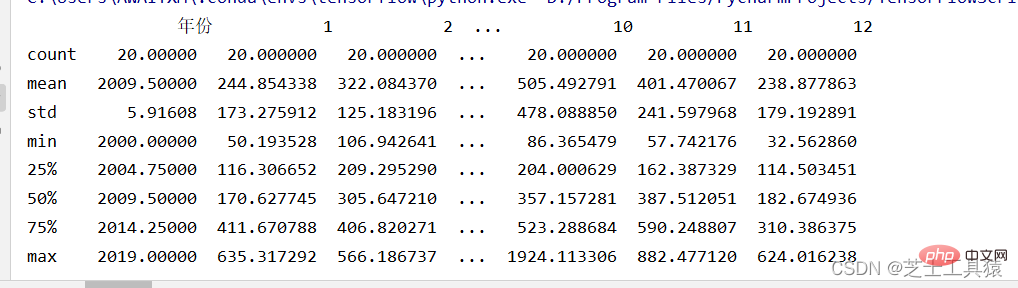
这里就可以很清晰的看出来数据的波动范围。
可以看出,不同月份的降水量有很大差距,8月最多,1-4月和10-12月最少。
那么每月的降水增减程度如何比较?
from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()minRings = -1maxRings = 99nrows = 11for i in range(nrows):
dataRow = dataFile.iloc[i,1:13]
labelColor = ( (dataFile.iloc[i,12] - minRings ) / (maxRings - minRings) )
dataRow.plot(color = plot.cm.RdYlBu(labelColor),alpha = 0.5)plot.xlabel("Attribute")plot.ylabel(("Score"))show()结果如图: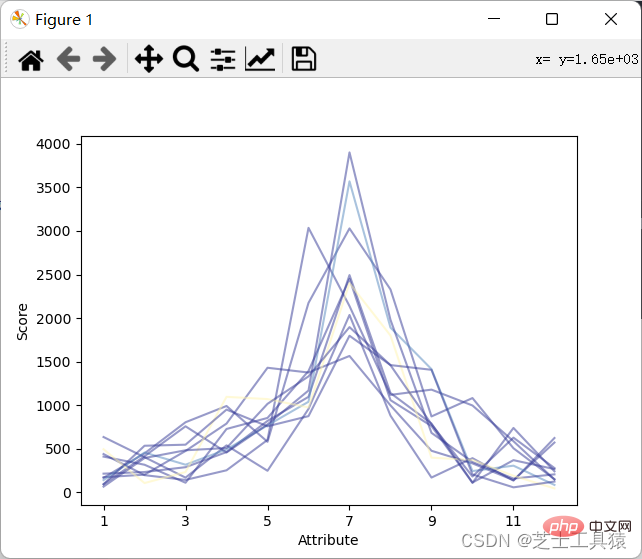
可以看出来降水月份并不规律的上涨或下跌。
那么每月降水是否相关?
from pylab import *import pandas as pdimport matplotlib.pyplot as plot
filepath = ("C:\\Users\\AWAITXM\\Desktop\\rain.csv")# "C:\Users\AWAITXM\Desktop\rain.csv"dataFile = pd.read_csv(filepath)summary = dataFile.describe()corMat = pd.DataFrame(dataFile.iloc[1:20,1:20].corr())plot.pcolor(corMat)plot.show()结果如图: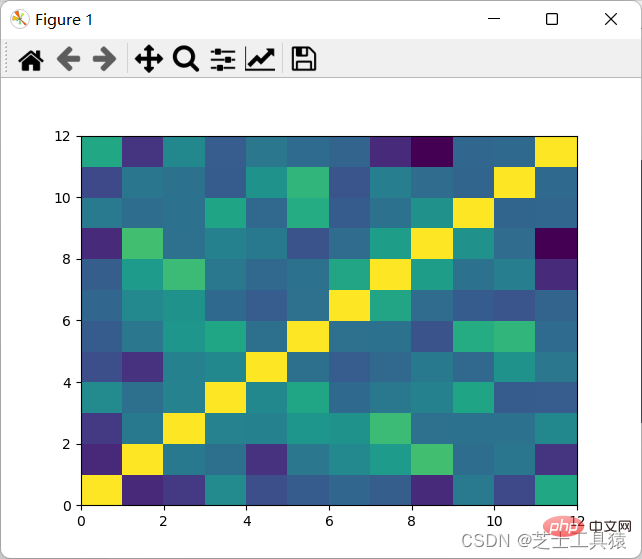
可以看出,颜色分布十分均匀,表示没有多大的相关性,因此可以认为每月的降水是独立行为。
今天就记录到这里了,我们下次再见!希望本文章对你也有所帮助。
推荐学习:python学习教程
以上がPython のデータ処理と視覚化についての深い理解の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



