

Redis によるマスター/スレーブ レプリケーション、センチネル、クラスターの詳細な分析

この記事では、Redis に関する関連知識を提供します。この記事では、主にマスター/スレーブ レプリケーション、センチネル、クラスターの 3 つのモード、分散ロック、システムの最適化などに関連する問題を紹介します。皆さんのお役に立てば幸いです。

推奨学習: Redis チュートリアル
1. マスター/スレーブ レプリケーション
1. マスターの使用-slave synchronization
永続化機能により、redis はサーバーが再起動されてもデータが失われないことを保証します。永続化によってメモリ内のデータがハードディスクに保存され、再起動によってデータがロードされるためです。ただし、データはサーバー上に保存されているため、サーバーにハードディスク障害などの問題が発生した場合、データの損失も発生します。単一障害点を回避するために、データベースの複数のコピーを複製し、それらを異なるサーバーに展開するのが一般的です。これにより、1 つのサーバーに障害が発生した場合でも、他のサーバーが引き続きサービスを提供できます。この目的を達成するために、redis はレプリケーション replication 関数を提供します。この関数は、1 つのデータベースのデータが更新されたときに、更新されたデータを他のデータベースに自動的に同期できます。
レプリケーションの概念では、データベースは 2 つのカテゴリに分類され、1 つはマスター データベース master であり、もう 1 つはスレーブ データベース slave です。マスター データベースは読み取りおよび書き込み操作を実行できます。書き込み操作によりデータが変更されると、データはスレーブ データベースに自動的に同期されます。スレーブ データベースは通常読み取り専用で、マスター データベースから同期されたデータを受け取ります。マスター データベースには複数のスレーブ データベースを含めることができますが、スレーブ データベースにはマスター データベースを 1 つだけ含めることができます。
2. マスタ/スレーブ同期原理
2.1 原理の詳細説明
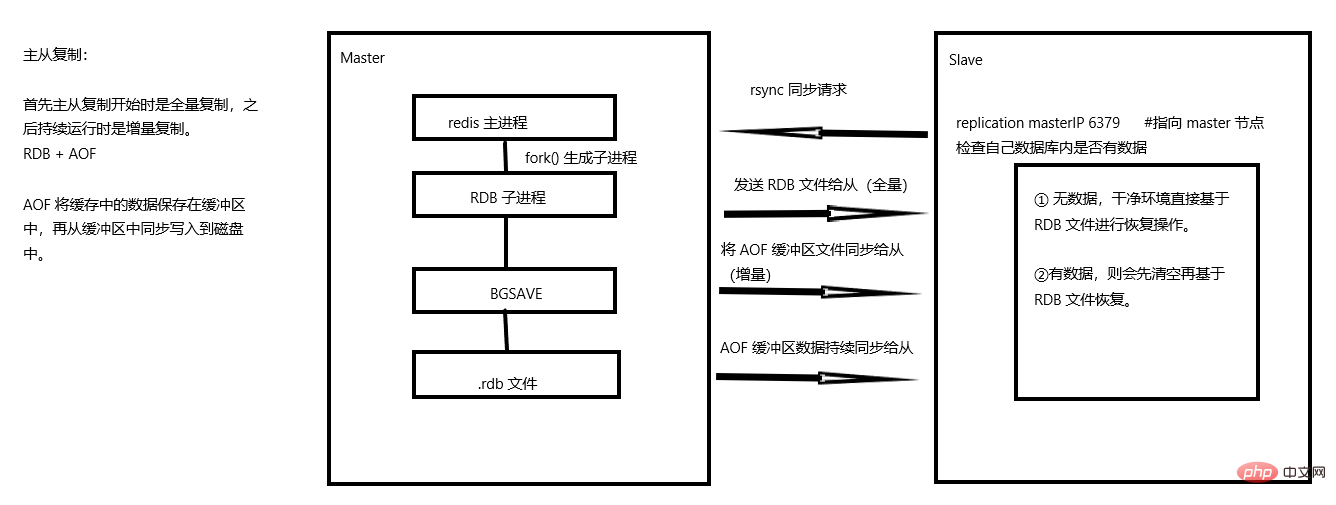
- # #スレーブ マシン プロセスが開始されると、
sync_command
コマンドをマスター マシンに送信して同期接続を要求します。 - 最初の接続であっても再接続であっても、マスター マシンはバックグラウンド プロセスを開始してデータ スナップショット (RDB) をデータ ファイル (.rdb ファイル) に保存し、マスター マシンはまた、データを変更するすべてのコマンドが記録され、データ ファイルにキャッシュされます。
- バックグラウンド プロセスがキャッシュ操作を完了した後、マスター マシンはデータ ファイルをスレーブ マシンに送信します。スレーブ マシンはデータ ファイルをハードディスクに保存し、ロードします。をメモリに保存すると、マスター マシンはデータを変更するためのすべての操作をスレーブ マシンに送信します。スレーブに障害が発生してダウンタイムが発生した場合、正常に戻った後に自動的に再接続されます。
- マスター マシンがスレーブ マシンから接続を受信した後、完全なデータ ファイルをスレーブ マシンに送信します。マスターが複数のスレーブ マシンから同時に同期要求を受信した場合、マスター マシン プロセスがバックグラウンドで開始されてデータ ファイルが保存され、その後すべてのスレーブ マシンに送信されて、すべてのスレーブ マシンが正常であることを確認します。
2.2 理論的な簡略化

slave -> master 发送 sync command 申请同步 master 主进程 -> 调用 fork() 函数 派生 RDB 子进程进行持久化 -> 生成 RDB 文件 将 RDB 文件推送给 slaves(完成全量同步)#增量同步:使用到了 AOF 持久化(机制:将缓存数据保存到缓冲中),所以主从节点均需要开启 AOF增量同步是通过 AOF 功能将缓存中的数据 append(追加)到缓冲中来进行 master 缓冲 -> slave 缓冲的同步 在持续性的运行过程中,也是增量持续同步的过程
2.3 最終合理化バージョンslave -> master 发送 syncmaster 使用 RDB 生成 .rdb 文件(全量同步)发送给 slaves
master 使用 AOF 将缓冲区数据同步给 slaves 缓冲区数据(增量)
ログイン後にコピー
slave -> master 发送 syncmaster 使用 RDB 生成 .rdb 文件(全量同步)发送给 slaves master 使用 AOF 将缓冲区数据同步给 slaves 缓冲区数据(增量)
2. センチネル モード1. セントリーの役割
センチネルの出現は、マスター/スレーブのレプリケーションが失敗したときに人間の介入が必要になるという問題を主に解決します
集群监控:负责监控 redismaster 和 slave 进程是否正常工作 消息通知:如果某个 redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上 配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址
sentinel インスタンスで構成されるシステムは Redis ノードを監視し、マスター ノードに障害が発生した場合、スレーブ ノードの 1 つをマスター ノードにアップグレードしてフェイルオーバーし、システムの可用性を確保します。
2.1 原則の詳細説明
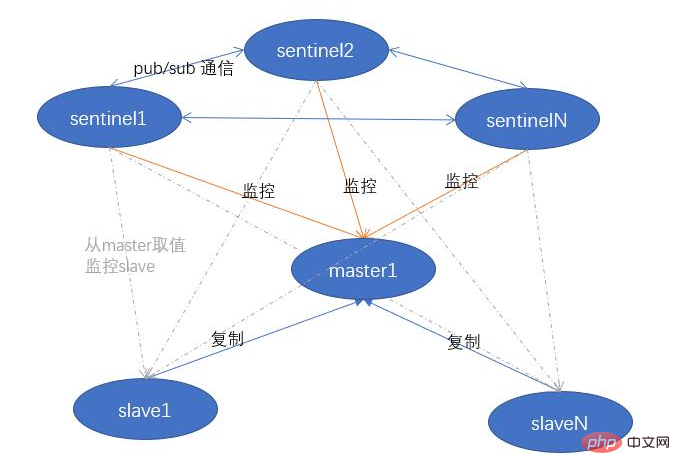
- 最初に中でもマスターノードの情報は Sentinel
sentinel
の設定ファイルに設定されます。 - センチネル ノードは、設定されたマスター ノードとの 2 つの接続を確立します: コマンド接続とサブスクリプション接続です。
PS: Redis のパブリッシュとサブスクライブ (pub/sub) は一種の接続です。メッセージの通信モード: 送信者 (パブ) がメッセージを送信し、サブスクライバー (サブ) がメッセージを受信します。 - Sentinel は、コマンド接続を通じて 10 秒ごとに INFO コマンドを送信します。INFO コマンドを通じて、マスター ノードは独自の run_id と独自のスレーブ ノード情報を返します。
- Sentinel は、これらのスレーブ ノードに対して 2 つの接続コマンド接続とサブスクリプション接続も確立します。
- センチネルはコマンド接続を通じて INFO コマンドをスレーブ ノードに送信し、情報の一部を取得します:
run id(redis 服务器 id) role(职能) 从服务器的复制偏移量 offset 其他
- Pass コマンド接続は、サーバーの
sentinel:hello
チャネルに、独自の IP、ポート、実行 ID、構成 (以降の投票で使用されます) などを含むメッセージを送信します。 通过订阅连接对服务器的
sentinel:hello频道做了监听,所有向该频道发送的哨兵的消息都能被接受到。解析监听到的消息,进行分析提取,就可以知道还有那些别的哨兵服务节点也在监听这些主从节点了,更新结构体将这些哨兵节点记录下来。
向观察到的其他的哨兵节点建立命令连接(此时没有订阅连接)。
2.2 原理精简
3 个哨兵 3 个 redis
- 三个哨兵之间建立命令连接,周期检测 “队友” 状态
- 哨兵会向 master 节点(己在配置文件中指定)发送两条连接,分别是命令连接和订阅连接(为了周期性获取 master 节点的数据)
- 哨兵向 master 周期性发送 info 命令,master(活着的情况下)会返回
redis-cli info replication master节点的信息 + 从节点位置 - 哨兵通过 master 返回的信息,再向 slaves 节点发送 info 命令,slaves 返回数据,从而哨兵集群就可以获取到 redis 所有集群信息
- 哨兵会向服务器发送命令连接,建立自己的 hello 频道,哨兵会向这个 hello 频道建立订阅,用于哨兵之间的消息共享
2.3 思路
- 3 个哨兵互相监听,使用 ping 互相检测存活
- 3 个哨兵分别向数据节点 master 发送命令连接和订阅连接(info 命令)获取数据节点信息(包含主从节点)3 个哨兵再向其他从节点发送 info ,用于获取从节点详细信息
- 3 个哨兵之间通过 hello 频道进行消息共享
3. 哨兵模式下的故障迁移
① 主观下线
哨兵节点会每秒一次的频率向建立了命令连接的实例发送 PING 命令,如果在down-after-milliseconds毫秒内没有做出有效响应包括PONG/LOADING/MASTERDOWN以外的响应,哨兵就会将该实例在本结构体中的状态标记为SRI_S_DOWN主观下线。② 客观下线
当一个哨兵节点发现主节点处于主观下线状态是,会向其他的哨兵节点发出询问,该节点是不是已经主观下线了。如果超过配置参数quorum个节点认为是主观下线时,该哨兵节点就会将自己维护的结构体中该主节点标记为SRIO DOWN客观下线询问命令SENTINEL is-master-down-by-addr。③ master 选举
在认为主节点客观下线的情况下,哨兵节点节点间会发起一次选举,命令为SENTINEL is-master-down-by-addr,只是 runid 这次会将自己的 runid 带进去,希望接受者将自己设置为主节点。如果超过半数以上的节点返回将该节点标记为 leader 的情况下,会有该 leader 对故障进行迁移。④ 故障转移
####在从节点中挑选出新的主节点通讯正常 优先级排序 优先级相同时选择 offset 最大的###将该节点设置成新的主节点SLAVEOF no one,并确保在后续的INGO命令时 该节点返回状态为master ###将其他的从节点设置成从新的主节点复制,SLAVEOF命令###将旧的主节点变成新的主节点的从节点PS:优缺点#优点:高可用,哨兵模式是基于主从模式的,所有主从模式的优点,哨兵模式都具有有;主从可以自动切换,系统更健壮,可用性更高#缺点:redis 比较难支持在线扩容,在群集容量达到上限时在线扩容会变得很复杂
三、集群
1. redis 集群的含义
主节点负责读写请求和集群信息的维护,从节点只进行主节点数据和状态信息的复制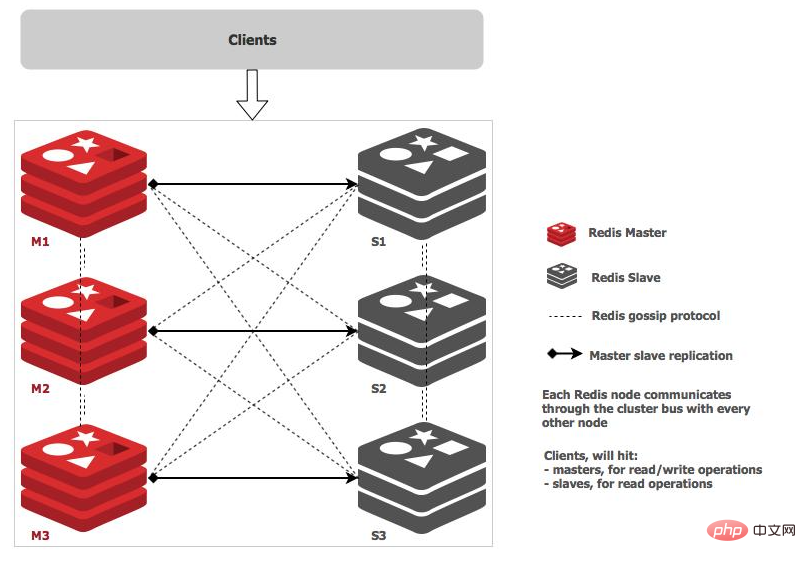
redis 的哨兵模式基本已经可以实现高可用、读写分离,但是在这种模式每台 redis 服务器都存储相同的数据,很浪费内存资源,所以在 redis3.0 上加入了 Cluster 群集模式,实现了 redis 的分布式存储,也就是说每台 redis 节点存储着不同的内容。根据官方推荐,集群部署至少要 3 台以上的 master 节点,最好使用 3 主 3 从六个节点的模式。
Cluster 群集由多个 redis 服务器组成的分布式网络服务群集,群集之中有多个 master 主节点,每一个主节点都可读可写,节点之间会相互通信,两两相连,redis 群集无中心节点。
2. redis 集群的特点
- 在 redis-Cluster 群集中,可以给每个一个主节点添加从节点,主节点和从节点直接尊循主从模型的特性,当用户需要处理更多读请求的时候,添加从节点可以扩展系统的读性能
- redis-cluster 的故障转移:redis 群集的主机节点内置了类似
redis sentinel的节点故障检测和自动故障转移功能,当群集中的某个主节点下线时,群集中的其他在线主节点会注意到这一点,并且对已经下线的主节点进行故障转移 - 集群进行故障转移的方法和
redis sentinel进行故障转移的方法基本一样,不同的是,在集群里面,故障转移是由集群中其他在线的主节点负责进行的,所以群集不必另外使用redis sentinel
四、分布式锁
https://www.zhihu.com/question/300767410/answer/1749442787
如果在一个分布式系统中,我们从数据库中读取一个数据,然后修改保存,这种情况很容易遇到并发问题。因为读取和更新保存不是一个原子操作,在并发时就会导致数据的不正确。这种场景其实并不少见,比如电商秒杀活动,库存数量的更新就会遇到。如果是单机应用,直接使用本地锁就可以避免。如果是分布式应用,本地锁派不上用场,这时就需要引入分布式锁来解决。由此可见分布式锁的目的其实很简单,就是为了保证多台服务器在执行某一段代码时保证只有一台服务器执行。
简单来说:
现在的业务应用通常都是微服务架构,这也意味着一个应用会部署多个进程,那么多个进程如果需要修改数据库中的同一行记录时,为了避免操作乱序导致数据错误,此时就需要引入分布式锁解决问题。
为了保证分布式锁的可用性,至少要确保锁的实现要同时满足以下几点:
- 互斥性。在任何时刻,保证只有一个客户端持有锁。
- 不能出现死锁。如果在一个客户端持有锁的期间,这个客户端崩溃了,也要保证后续的其他客户端可以上锁。
- 保证上锁和解锁都是同一个客户端。
一般来说,实现分布式锁的方式有以下几种:
- 使用 MySQL,基于唯一索引。
- 使用 ZooKeeper,基于临时有序节点。
- 使用 Redis,基于 setnx 命令。

对 redis 来说注意三点,对 key 的加锁,如果请求未完成对快要过期的 key 的续期,请求完成后 key 的解锁。防止并发环境下被读取的一个 key 可能被多个请求修改,造成无效操作,资源浪费的情况。
五、redis 总结
redis 可以做为 mysql 的前置缓存数据库,redis 与 mysql 对接的方式需要配置线程池,需要定义后端 mysql 的位置( IP + port +sock 文件的位置)
redis 基础功能:用于内存/缓存的快速存储(读取)
实现的方式:
默认将数据存储在内存/缓存中 具有丰富的数据类型:string list hash set && order set 等 重要数据持久化的功能,持久化的方式:AOF RDB
单线程模式 -> 速度快的原因之一:Epoll + I/O 复用(cluster 中的 slots 哈希槽可以充当数据读、取的索引)
- redis 中的算法:
LRU:淘汰策略1) 缓存中的数据进行随机淘汰2) 缓存中被设置了过期时间的数据进行随机淘汰3) 缓存中被设置了过期时间的数据,进行惰性删除(仅当访问到的数据过期了,才会删除)4) 当数据持续存储过程中内存将满,会在设置了过期时间的数据中进行近期淘汰 令牌桶 + 漏桶算法:限流 Raft:选举机制,用于选举新的主节点
- redis 缓存高热数据的机制
高热数据:命中次数高的数据 指定提高缓存内数据的命中数,最直接的可以刷脚本,访问这些数据
六、系统优化
1. 单例服务器,服务器本身优化
硬件资源选择(系统五大资源)
- 磁盘 固态盘 SCSI(硬件磁盘阵列)
- 服务器内存条选择(本地服务器和云服务器)
- CPU 核数选择
- 网络网卡(本地服务器和云服务器),需要考虑负载压力下的网络流量 QPS
- 服务器选型(麒麟、晓龙、浪潮英信、华为、华三、戴尔(类型:刀片、塔式、机柜))
以上需要计算费用成本,还需要考虑到该服务器上的服务在运行时消耗的性能比例(需要预留给系统一部分资源)
服务本身环境的选择
操作系统选择
Linux 发行版:centos ubuntu redhat server debian alphon mac SUSE(PS:虚拟化 KVM XEN FUFE)基于操作系统,依赖环境。选择最小化安装还是指定操作系统版本的安装 + 指定内核版本。软件是否有依赖(例如:tomcat 需要 JDK,编译需要 gcc gcc-c++ pcre …)
软件资源优化
五大负载+内核优化(TCP协议相关、队列相关、路由转发、重定向、端口、文件打开数、系统的软硬限制等)
2. シングルトン サーバー アプリケーション サービス自体を最適化する
redis を例に挙げます
スタートアップからの最初の復元読み取りの判断ファイルから、AOF 機能を AOF (RDB のデフォルト) に基づいてオンにする必要があります。
- RDB での保存 M N トリガー サイクルの選択と決定は、ディスク リソースの使用に影響します。
- AOF でディスクに同期的に書き込むための適切な syncwrite 戦略を選択します
毎秒
使用中は、メモリ使用量 (OOM) を考慮する必要があります。
- メモリ削除戦略: 遅延削除 + 定期的な削除、禁止された削除 + 定期的な削除。状況に基づいて、適切なエビクション戦略 (構成ファイルで定義) を選択します。
永続化の方向
データの整合性を確保しながら、永続化機能はディスク上にストレージの圧力を継続的に生成します (この圧力は、AOF および RDB ファイルによって生成されたデータから発生します。AOF および RDB ファイルによって生成されます)。 RDB ログ ファイル)。
- データ/ログ ファイルの定期的なアーカイブ
- ログ ファイルの分割 (ログ センターに保存)
- 共有ストレージ
NFS GFS fastDFS
redis メイン プロセス
- 2 つの Redis メイン プロセスを使用して、バックアップの冗長性を実現し、高い同時実行性への耐性を向上させることができます
推奨学習: Redis 学習チュートリアル
以上がRedis によるマスター/スレーブ レプリケーション、センチネル、クラスターの詳細な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7451
7451
 15
1374
52
77
11
14
9
15
1374
52
77
11
14
9

 すべてのデータをRedisでクリーニングする方法
Apr 10, 2025 pm 05:06 PM
すべてのデータをRedisでクリーニングする方法
Apr 10, 2025 pm 05:06 PM
すべてのRedisデータをクリーニングする方法:Redis 2.8以降:Flushallコマンドはすべてのキー価値ペアを削除します。 Redis 2.6以前:delコマンドを使用してキーを1つずつ削除するか、Redisクライアントを使用してメソッドを削除します。代替:Redisサービスを再起動し(注意して使用)、またはRedisクライアント(flushall()やflushdb()など)を使用します。
 Redisのさまざまなインスタンスがどのように通信するか
Apr 10, 2025 pm 05:15 PM
Redisのさまざまなインスタンスがどのように通信するか
Apr 10, 2025 pm 05:15 PM
Redisインスタンスの間に通信にはいくつかのメカニズムがあります。Pub/Sub:Publish/Sub Mode、効率的で低遅延のメッセージングを可能にします。クラスターモード:分散展開方法。高可用性とフォールトトレランスを提供します。クロスインスタンスコマンド:一時的な運用または管理目的に適したコマンドを別のインスタンスに直接送信できるようにします。
 現在のRedisバージョンを表示する方法
Apr 10, 2025 pm 05:09 PM
現在のRedisバージョンを表示する方法
Apr 10, 2025 pm 05:09 PM
このガイドには、現在のRedisバージョンを決定する2つの方法があります。情報コマンドを使用してバージョン番号を取得します。 -versionオプションを使用して、バージョン番号を直接表示します。バージョン番号は、メインバージョン番号、セカンダリバージョン番号、および改訂番号で構成されており、それぞれメジャーバージョンの更新、機能拡張、マイナーバグ修正を表します。
 Redisクラスターを再起動する方法
Apr 10, 2025 pm 05:18 PM
Redisクラスターを再起動する方法
Apr 10, 2025 pm 05:18 PM
Redisクラスターの再起動の手順は、次のとおりです。データとログを閉じてクリアします。シードノードを起動します。新しいクラスターを作成します。残りのノードを追加します。クラスターステータスを確認します。
 Redisコマンドを再起動する方法
Apr 10, 2025 pm 05:21 PM
Redisコマンドを再起動する方法
Apr 10, 2025 pm 05:21 PM
Redisは、スムーズな再起動とハード再起動の2つの方法で再起動できます。サービスを中断せずにスムーズに再起動し、クライアントが操作を継続できるようにします。ハード再起動はすぐにプロセスを終了し、クライアントがデータを切断してデータを失います。深刻なエラーを修正するか、データをクリーンアップする必要がある場合にのみ、ほとんどの場合、スムーズな再起動を使用することをお勧めします。
 Redisでマルチスレッドを実装する方法
Apr 10, 2025 pm 05:12 PM
Redisでマルチスレッドを実装する方法
Apr 10, 2025 pm 05:12 PM
Redisは、リアクターモード、スレッドプール、内部マルチスレッドメカニズムを巧みに組み合わせてマルチスレッドを実装し、それによりマルチコアCPUを効果的に利用し、スループットの改善、リソースの利用の最適化、低レイテンシの維持、スケーラビリティの向上、さまざまな負荷ニーズを満たします。
 Redisトランザクションの処理方法
Apr 10, 2025 pm 05:24 PM
Redisトランザクションの処理方法
Apr 10, 2025 pm 05:24 PM
Redisトランザクションは、原子性、一貫性、分離、および持続性(酸)特性を確保し、次のように動作します。トランザクションを開始:マルチコマンドを使用します。レコードコマンド:任意の数のredisコマンドを実行します。コミットまたはロールバックトランザクション:execコマンドを使用してトランザクションをコミットするか、廃棄コマンドを使用してトランザクションをロールバックします。コミット:エラーがない場合、execコマンドはトランザクションをコミットし、すべてのコマンドがデータベースに原子的に適用されます。ロールバック:エラーが発生した場合、Disdardコマンドがトランザクションをロールバックし、すべてのコマンドが破棄され、データベースのステータスは変更されません。
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
