

この記事では、mysql に関する関連知識を提供します。主に、mysql 最適化のための 21 の実践的なスキルをまとめています。これらの 21 の最適化スキルを見てみましょう。皆さんのお役に立てれば幸いです。

推奨学習: mysql ビデオ チュートリアル
1. クエリ キャッシュ用にクエリを最適化する今日、データベース操作がアプリケーション全体のパフォーマンスにますます重要になってきています。ボトルネックは、Web アプリケーションで特に顕著です。データベースのパフォーマンスに関しては、DBA だけが心配する必要があるのではなく、私たちプログラマも注意を払う必要があります。データベースのテーブル構造を設計し、データベースを操作するとき (特にテーブルを検索するときの SQL ステートメント)、データ操作のパフォーマンスに注意を払う必要があります。ここでは、SQL ステートメントの最適化についてはあまり説明しませんが、最も多くの Web アプリケーションを備えたデータベースである MySQL についてのみ説明します。次の最適化のヒントがお役に立てば幸いです
ほとんどの MySQL サーバーではクエリ キャッシュが有効になっています。これはパフォーマンスを向上させる最も効果的な方法の 1 つであり、MySQL データベース エンジンによって処理されます。同じクエリの多くが複数回実行されると、これらのクエリ結果はキャッシュに配置されるため、後続の同一のクエリではテーブルを操作する必要がなく、キャッシュされた結果に直接アクセスできます。ここでの主な問題は、プログラマにとってこの問題が見落とされやすいことです。一部のクエリ ステートメント
により、MySQL はキャッシュ を使用しなくなるためです。次の例を見てください:

上記 2 つの SQL ステートメントの違いは、MySQL のクエリ キャッシュである2. SELECT クエリを説明しますCURDATE()
です。ペア この機能は動作しません。したがって、NOW()やRAND()などの SQL 関数、または他の同様の関数では、クエリ キャッシュは有効になりません。これらの関数の戻り値は揮発性であるためです。したがって、必要なのは、MySQL 関数を変数に置き換えてキャッシュを有効にすることだけです。
EXPLAIN
キーワードを使用して、MySQL が SQL ステートメントをどのように処理するかを確認します## #。これは、クエリ ステートメントまたはテーブル構造のパフォーマンスのボトルネックを分析するのに役立ちます。 EXPLAIN
のクエリ結果には、インデックスの主キーがどのように使用されるか、データ テーブルがどのように検索および並べ替えられるかなどもわかります。SELECT
ステートメントの 1 つを選択し (複数のテーブル接続を持つ最も複雑なステートメントを選択することをお勧めします)、キーワードEXPLAINを先頭に追加します。これを行うには、phpmyadminを使用できます。すると、フォームが表示されます。次の例では、group_idインデックスを追加するのを忘れてテーブル結合を行っています:
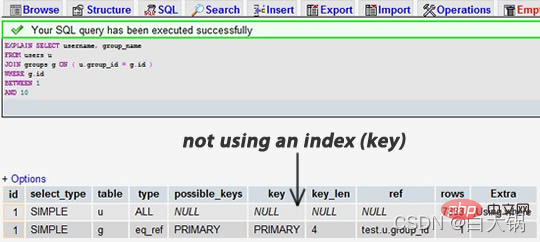 After インデックスを追加したとき:
After インデックスを追加したとき:
前者の結果は 7883 行が検索されたことを示していますが、後者の結果は 2 つのテーブルの 9 行と 16 行のみを検索したことがわかります。行列を確認すると、潜在的なパフォーマンスの問題を見つけることができます。 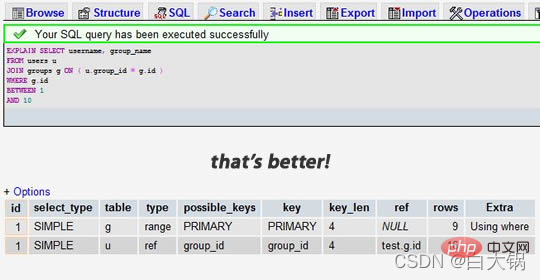
3. データが 1 行しかない場合は LIMIT 1 1 を使用します
fetchCursor が必要な場合や、返されたレコードの数を確認する必要がある場合があります。
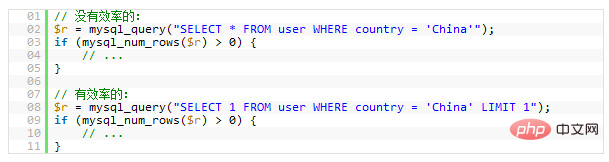
この場合、LIMIT 1
を追加すると、パフォーマンスが向上します。このようにして、MySQL データベース エンジンは、レコードに一致する次のデータの検索を続けるのではなく、データを見つけた後に検索を停止します。 次の例は、「中国」ユーザーが存在するかどうかを確認するためのものですが、明らかに、後者の方が前者よりも効率的です。 (最初のエントリは Select *
で、2 番目のエントリはSelect 1であることに注意してください)
 4 。検索フィールドのインデックスを作成する
4 。検索フィールドのインデックスを作成する
上の図から、検索文字列「
last_name LIKE 'a%'」の一方にはインデックスが作成され、もう一方にはインデックスが作成されておらず、パフォーマンスが 低下していることがわかります。 4 約 回 。
さらに、通常のインデックスを使用できない検索の種類についても知る必要があります。たとえば、大きな記事内で「WHERE post_content LIKE '%apple%'」などの単語を検索する必要がある場合、インデックスは意味をなさない可能性があります。 MySQL フルテキスト インデックスを使用するか、自分でインデックスを作成する必要がある場合があります (例: キーワードやタグの検索)
アプリケーションに多数の JOIN クエリがある場合は、両方のテーブルの結合フィールドにインデックスが作成されていることを確認する必要があります。このようにして、MySQL は内部で Join SQL ステートメントを最適化するメカニズムを開始します。
さらに、結合に使用されるこれらのフィールドは同じタイプである必要があります。例:DECIMALフィールドと INT フィールドをJoinした場合、MySQL はそのインデックスを使用できません。これらのSTRING型の場合も、同じ文字セットを持つ必要があります。 (2 つのテーブルの文字セットは異なる場合があります)

返されたものをスクランブルしないでください。データ行? データの一部をランダムに選択? 誰がこの使用法を発明したのかはよくわかりませんが、多くの初心者はこの方法を好んで使用します。しかし、これがどれほどひどいパフォーマンス上の問題を抱えているか、あなたは本当に理解していません。
返されたデータ行を本当にスクランブルしたい場合、これを実現する方法は N 通りあります。これを使用すると、データベースのパフォーマンスが急激に低下するだけです。ここでの問題は、MySQL はRAND()関数 (多くの CPU 時間を消費します) を実行する必要があり、これはレコードの各行の行を記録し、並べ替えるためです。彼ら。Limit 1を使用したとしても、役に立ちません (並べ替える必要があるため)
次の例では、レコードをランダムに選択します。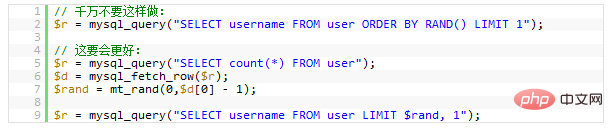
データベース内の各テーブルの ID を主キーとして設定する必要があります。最適なものはデータベースから読み取られるデータが増えるほど、クエリの速度が遅くなります。また、データベースサーバーとWEBサーバーが独立した2台のサーバーの場合、ネットワーク通信の負荷も大きくなります。したがって、必要なものはすべて摂取する習慣を身につける必要があります。
8. 各テーブルに常に ID を設定します。
INTENUM 型は非常に高速でコンパクトです。実際には、タイプで (
9. VARCHAR の代わりに ENUM を使用しますUNSIGNEDを使用することをお勧めします)、自動的に増加するAUTO_INCREMENTフラグを設定します。users テーブルに「email
」という主キーを持つフィールドがある場合でも、それを主キーにしないでください。VARCHAR型を主キーとして使用すると、パフォーマンスが低下します。さらに、プログラムではテーブル ID を使用してデータ構造を構築する必要があります。さらに、MySQL データ エンジンでは、主キーの使用が必要な操作がいくつかあります。この場合、主キーのパフォーマンスと設定が非常に重要になります (クラスター、パーティションなど)。
ここで、例外が 1 つだけあり、それは「関連テーブル」の「外部キー」です。つまり、このテーブルの主キーは、複数の個別のテーブルの主キーで構成されています。 。この状況を「外部キー」と呼びます。例: 学生 ID を含む「学生テーブル」とコース ID を含む「カリキュラム テーブル」があり、「スコア テーブル」は学生テーブルとコース スケジュールを関連付ける「関連付けテーブル」になります。表では、学生 ID とコース ID は「外部キー」と呼ばれ、これらが合わせて主キーを形成します。
TINYINTが保存されますが、文字列として表示されます。このようにして、このフィールドを使用して選択リストを作成するのが非常に完璧になります。
「性別」、「国」、「民族」、「ステータス」、または「部門」などのフィールドがあり、これらのフィールドの値が制限され固定されていることがわかっている場合は、次のようにする必要があります。VARCHAR
の代わりにENUMを使用してください。MySQL には、テーブル構造を再編成する方法を示す「提案」 (項目 10 を参照) もあります。VARCHAR
フィールドがある場合、この提案は、それをENUM型に変更するように指示します。PROCEDURE ANALYSE()を使用すると、関連する提案が得られます
PROCEDURE ANALYSE()を使用すると、MySQL がフィールドと実際のデータの分析に役立ちます。いくつかの有益な提案をしてください。いくつかの大きな決定を下すには基礎となるデータが必要であるため、これらの提案はテーブルに実際のデータがある場合にのみ役に立ちます。
たとえば、主キーとして INT フィールドを作成したが、データがあまりない場合、PROCEDURE ANALYSE()は、このフィールドの型をMEDIUMINT に変更することを提案します。。または、VARCHARフィールドを使用する場合、データが少ないため、
をENUMに変更するよう提案される場合があります。これらの提案はすべて、十分なデータがなく、意思決定が十分に正確ではないために可能になります。
phpmyadminで、テーブル
# を表示しているときに 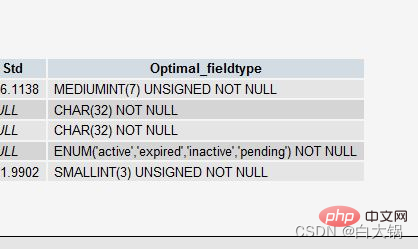 「テーブル構造の提案」
「テーブル構造の提案」
最終的に決定を下すのはあなたであることを必ず覚えておいてください
11. 特別な事情がない限り、できるだけ NOT NULL を使用してください。理由NOT NULL準備されたステートメントのままにする必要があります。これは少し物議を醸すかもしれませんが、読み続けてください。
まず、「Empty」と「NULL
」の間の違いがどれくらい大きいかを自問してください (INTの場合、それは0 と NULL です))? 両者に違いがないと思われる場合は、NULLを使用しないでください。 (ご存知ですか? Oracle では、NULLとEmpty の文字列は同じです!)## とは考えないでください。 #NULLスペースは必要ありません。余分なスペースが必要です。 比較を行うとプログラムがより複雑になります。もちろん、これは
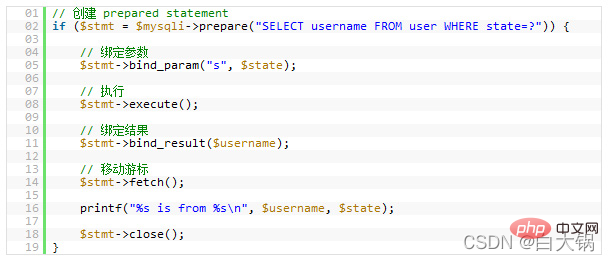
NULL を使用できないという意味ではありません。実際は非常に複雑であり、NULL 値を使用する必要がある状況が依然として存在します。12.準備されたステートメント
パフォーマンスの問題やセキュリティの問題を問わず、多くの利点が得られます。
13 などのデータベース抽象化レイヤーを使用できます。バッファなしクエリ準備されたステートメントバインドしたいくつかの変数を確認できます。これにより、「SQL インジェクション」攻撃からプログラムを保護できます。もちろん、変数を手動でチェックすることもできますが、手動によるチェックは問題が発生しやすく、プログラマが忘れることがよくあります。この問題は、framework
またはORMを使用すると改善されます。 パフォーマンスの点では、同じクエリが複数回使用されると、パフォーマンスが大幅に向上します。これらの Prepared Statementsに対していくつかのパラメータを定義できます。MySQL はそれらを 1 回だけ解析します。MySQL の最新バージョンは、プリペアド ステートメントを送信するときに
バイナリ形式を使用しますが、これによりネットワーク送信が非常に効率的になります
。もちろん、Prepared Statements はクエリ キャッシュをサポートしていないため、Prepared Statements の使用を避ける必要がある場合もあります。ただし、バージョン 5.1 以降でサポートされると言われています。 PHP でプリペアド ステートメントを使用するには、マニュアル: mysql 拡張機能を確認するか、PDO.
 通常、スクリプト内で SQL ステートメントを実行すると、プログラムは SQL ステートメントが返されるまでそこで停止し、その後プログラムは実行を続けます。バッファリングされていないクエリを使用して、この動作を変更できます。
通常、スクリプト内で SQL ステートメントを実行すると、プログラムは SQL ステートメントが返されるまでそこで停止し、その後プログラムは実行を続けます。バッファリングされていないクエリを使用して、この動作を変更できます。
fethchを実行せず、
mysql_query()のように結果をキャッシュせずに SQL ステートメントを MySQL に送信します。これにより、特に多数の結果を生成するクエリの場合に、かなりのメモリが節約され、すべての結果が返されるまで待つ必要はありません。データの最初の行を返すだけで作業を開始できます。クエリ結果が表示されます。ただし、これにはいくつかの制限があります。すべての行を読み取るか、次のクエリの前にmysql_free_result()を呼び出して結果をクリアする必要があるためです。また、mysql_num_rows() または mysql_data_seek()は機能しません。したがって、バッファなしクエリを使用するかどうかを慎重に検討する必要があります。
として保存するプログラマの多くは、整形 IP ではなく文字列形式で IP を保存するために
VARCHAR(15)フィールドを作成します。 。整数を使用して格納する場合、必要なバイト数は 4 バイトだけであり、固定長フィールドを使用できます。さらに、これにより、特に次のようなWHERE条件を使用する必要がある場合に、クエリの利点がもたらされます:IP between ip1 と ip2。
IP アドレスは 32 ビット符号なし整数型全体を使用するため、UNSIGNED INT, を使用する必要があります。
クエリでは、INET_ATON()を使用して文字列 IP を整数に変換し、INET_NTOA()を使用して整数を文字列 IP に変換できます。 。 PHP には、ip2long() および long2ip()という関数もあります。
「テーブル内のすべてのフィールドが「固定長」の場合、テーブル全体が考慮されます。 「
静的」または「固定長」。たとえば、テーブルにはVARCHAR、TEXTというタイプのフィールドはありません。これらのフィールドのいずれかを含めている限り、テーブルは「固定長の静的テーブル」ではなくなり、MySQL エンジンは別の方法でテーブルを処理します。
固定長のテーブルは、MySQL の検索が高速になるため、パフォーマンスが向上します。これらの固定長により、次のデータのオフセットの計算が容易になるため、読み取りが自然に高速になります。また、フィールドが固定長でない場合、次のフィールドを検索するたびに、プログラムは主キーを検索する必要があります。
また、固定長テーブルはキャッシュと再構築が容易です。ただし、唯一の副作用は、固定長フィールドがスペースを無駄にすることです。固定長フィールドは、使用するかどうかに関係なく、非常に多くのスペースを割り当てるためです。
垂直分割」テクノロジ (次の項目を参照) を使用すると、テーブルを 2 つに分割できます。1 つは固定長、もう 1 つは可変長です。の。
16. 垂直分割「垂直分割」は、データベース内のテーブルを列ごとに複数のテーブルに変換する方法で、テーブル番号の複雑さとフィールドを削減できます。 、最適化の目的を達成するために。 (以前、銀行のプロジェクトに取り組んでいたときに、100 を超えるフィールドがあるテーブルを見たことがありました。とても怖かったです。)
例 1: Users テーブルには、次のようなフィールドがあります。これに対して、このフィールドはオプションのフィールドであり、データベースで操作する場合の個人情報を除いて、このフィールドを頻繁に読み取ったり書き換えたりする必要はありません。それで、それを別のテーブルに入れてみませんか?これにより、テーブルのパフォーマンスが向上します。よく考えてください。ユーザー テーブルの場合、ユーザー ID、ユーザー名、パスワードしかありません。ユーザー ロール、などが頻繁に使われることになります。時計が小さいほど、常にパフォーマンスが向上します。例 2: ユーザーがログインするたびに更新される「last_login」というフィールドがあります。ただし、更新のたびにテーブルのクエリ キャッシュがクリアされます。したがって、クエリ キャッシュによってパフォーマンスが大幅に向上するため、このフィールドを別のテーブルに配置すると、ユーザー ID、ユーザー名、およびユーザー ロールの継続的な読み取りに影響を与えなくなります。
さらに、これらの分割されたフィールドで構成されるテーブルを頻繁に結合しないことに注意する必要があります。そうしないと、分割しない場合よりもパフォーマンスが低下します。極端な低下になります
17.大規模な DELETE または INSERT ステートメントを分割します
オンライン Web サイトで大規模なステートメントを実行する必要がある場合は、DELETEまたは
INSERTクエリを実行する場合は、Web サイト全体の応答停止を引き起こす操作を避けるために細心の注意を払う必要があります。これら 2 つの操作はテーブルをロックするため、テーブルがロックされると、他の操作は入力できなくなります。Apache には多くの子プロセスまたはスレッドがあります。したがって、非常に効率的に動作し、サーバーは子プロセス、スレッド、データベース リンクが多すぎることを望まないため、多くのサーバー リソース、特にメモリが消費されます。テーブルを一定期間 (30 秒など) ロックすると、トラフィック量が多いサイトでは、アクセス プロセス/スレッド、データベース リンク、開いているファイルの数が 30 秒間に蓄積され、 WEB サービスが
クラッシュ
するだけでなく、サーバー全体が即座にハングアップする可能性があります。したがって、大規模なプロセスがあり、確実に分割する場合は、LIMIT
条件を使用するのが良い方法です。以下に例を示します:
ほとんどのデータベース エンジンでは、ハード ディスク操作が最も重大なボトルネックになる可能性があります。したがって、データをコンパクトにすると、ハード ドライブへのアクセスが減るため、この状況では非常に役立ちます。
すべてのデータ型を確認するには、MySQL ドキュメントのストレージ要件を参照してください。
テーブルに数個の列しかない場合 (ディクショナリ テーブル、構成テーブルなど)、主キーとしてINTを使用する理由はありません。MEDIUMINT、SMALLINTを使用してください。または、TINYINT を小さくすると、より経済的になります。時間を記録する必要がない場合は、DATETIMEよりもDATEを使用する方がはるかに適切です。
もちろん、拡張のための十分な余地も残しておく必要があります。そうでないと、将来これを実行すると、醜く死ぬことになります。Slashdot(2009 年 11 月 6 日) の例を参照してください。単純なALTER TABLEステートメントには 1,600 万個のデータが含まれていたため、3 時間以上かかりました。
MySQL には MyISAM と InnoDB という 2 つのストレージ エンジンがあり、それぞれのエンジンには長所と短所があります。 Cool Shell の以前の記事「MySQL: InnoDB または MyISAM?」では、この問題について説明しました。
MyISAM は、多数のクエリを必要とするアプリケーションには適していますが、多数の書き込み操作にはあまり適していません。フィールドを更新するだけの場合でも、テーブル全体がロックされ、読み取り操作が完了するまで他のプロセス (読み取りプロセスであっても) が動作できなくなります。さらに、MyISAM は、SELECT COUNT(*)などの計算が非常に高速です。
InnoDB の傾向は非常に複雑なストレージ エンジンになるため、小規模なアプリケーションではMyISAMよりも遅くなる可能性があります。もう 1 つの理由は、「行ロック」をサポートしているため、書き込み操作が多い場合に優れていることです。さらに、トランザクションなどのより高度なアプリケーションもサポートします。
ORM (
オブジェクト リレーショナル マッパー) を使用すると、確実にパフォーマンスを向上させることができます。 ORM で実行できることはすべて手動で記述することもできます。ただし、これには高度な専門家が必要です。
ORM で最も重要なことは、「Lazy Loading」です。つまり、値を取得する必要がある場合にのみ実際に実行されます。ただし、このメカニズムの副作用にも注意する必要があります。これは、多数の小さなクエリを作成することによってパフォーマンスが低下する可能性があるためです。
ORM では、SQL ステートメントをトランザクションにパッケージ化することもできます。これは、SQL ステートメントを個別に実行するよりもはるかに高速です。
現在、私のお気に入りの PHP 用 ORM は、Doctrine
「パーマネント リンク」には注意してください。目的は、MySQL 接続の再作成の回数を減らすことです。リンクが作成されると、データベース操作が終了した後でも、リンクは永久に接続されたままになります。さらに、Apache がその子プロセスの再利用を開始したため、次の HTTP リクエストは Apache の子プロセスを再利用し、同じ MySQL 接続を再利用します。
理論的には、これは非常に良いことのように思えます。しかし、個人的な経験 (そしてほとんどの人の経験) から言えば、この機能はさらに多くの問題を引き起こします。なぜなら、リンク、メモリの問題、ファイル ハンドルなどの数が限られているからです。
さらに、Apache は非常に並列的な環境で実行され、非常に多くのプロセスを作成します。これが、この「パーマリンク」メカニズムがうまく機能しない理由です。 「永続リンク」の使用を決定する前に、システム全体のアーキテクチャを慎重に検討する必要があります
クエリを実行する場合、インデックス列を関数の式またはパラメータの一部にすることはできません。そうでない場合、インデックスは使用できません。
たとえば、次のクエリでは、actor_id 列のインデックスを使用できません。
#这是错误的SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
最適化方法: 式と関数の演算は、等号の右側に移動できます。次のように:
SELECT actor_id FROM sakila.actor WHERE actor_id = 5 - 1;
クエリの条件として複数の列を使用する必要がある場合、複数の単一列インデックスを使用するよりも複数列インデックスを使用する方がパフォーマンスが高くなります。 。
たとえば、次のステートメントでは、actor_id と film_id を複数列インデックスとして設定するのが最適です。 Yuanfudao から質問があります。詳細についてはリンクを参照してください。これは、より深く理解するのに役立ちます。
SELECT film_id, actor_ id FROM sakila.film_actorWHERE actor_id = 1 AND film_id = 1;
最も選択的なインデックス列を最初に配置します。
インデックス選択性とは、レコードの総数に対する一意のインデックス値の比率を指します。最大値は 1 で、この時点で各レコードはそれに対応する一意のインデックスを持ちます。選択性が高いほど、各レコードの識別性が高くなり、クエリ効率が高くなります。
たとえば、以下に示す結果では、customer_id は Staff_id よりも選択性が高いため、customer_id 列を複数列の前に置くのが最善です。索引。
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity, COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity, COUNT(*) FROM payment; #结果如下 staff_id_selectivity: 0.0001 customer_id_selectivity: 0.0373 COUNT(*): 16049
BLOB、TEXT、および VARCHAR 型の列の場合、先頭文字のみにインデックスを付けるために接頭辞インデックスを使用する必要があります。
プレフィックス長の選択は、インデックスの選択性に基づいて決定する必要があります。
索引包含所有需要查询的字段的值。具有以下优点:
1.索引通常远小于数据行的大小,只读取索引能大大减少数据访问量。
2.一些存储引擎(例如 MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不使用系统调用(通常比较费时)。
3.对于 InnoDB 引擎,若辅助索引能够覆盖查询,则无需访问主索引。
mysql在使用like进行模糊查询的时候把%放后面,避免开头模糊查询
因为mysql在使用like查询的时候只有使用后面的%时,才会使用到索引。
如:’%ptd_’ 和 ‘%ptd_%’ 都没有用到索引;而 ‘ptd_%’ 使用了索引。
#进行全表查询,没有用到索引 EXPLAIN SELECT * FROM `user` WHERE username LIKE '%ptd_%'; EXPLAIN SELECT * FROM `user` WHERE username LIKE '%ptd_'; #有用到索引 EXPLAIN SELECT * FROM `user` WHERE username LIKE 'ptd_%';
再比如:经常用到的查询数据库中姓张的所有人:
SELECT * FROM `user` WHERE username LIKE '张%';
比如:
SELECT * FROM t WHERE id IN (2,3)SELECT * FROM t1 WHERE username IN (SELECT username FROM t2)
优化方式:如果是连续数值,可以用between代替。如下:
SELECT * FROM t WHERE id BETWEEN 2 AND 3
如果是子查询,可以用exists代替。如下:
SELECT * FROM t1 WHERE EXISTS (SELECT * FROM t2 WHERE t1.username = t2.username)
如:
SELECT * FROM t WHERE id = 1 OR id = 3
优化方式:可以用union代替or。如下:
SELECT * FROM t WHERE id = 1UNIONSELECT * FROM t WHERE id = 3
SELECT * FROM t WHERE score IS NULL
优化方式:可以给字段添加默认值0,对0值进行判断。如下:
SELECT * FROM t WHERE score = 0
同第1个,单独的列;
SELECT * FROM t2 WHERE score/10 = 9SELECT * FROM t2 WHERE SUBSTR(username,1,2) = 'li'
优化方式:可以将表达式、函数操作移动到等号右侧。如下:
SELECT * FROM t2 WHERE score = 10*9SELECT * FROM t2 WHERE username LIKE 'li%'
SELECT * FROM t WHERE 1=1
优化方式:用代码拼装sql时进行判断,没where加where,有where加and。
索引的好处:建立索引后,查询时不会扫描全表,而会查询索引表锁定结果。索引的缺点:在数据库进行DML操作的时候,除了维护数据表之外,还需要维护索引表,运维成本增加。应用场景:数据量比较大,查询字段较多的情况。
索引规则:
1.选用选择性高的字段作为索引,一般unique的选择性最高;
2.复合索引:选择性越高的排在越前面。(左前缀原则);
3.如果查询条件中两个条件都是选择性高的,最好都建索引;
Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
比较重要的字段有:
select_type: 查询类型,有简单查询、联合查询、子查询等;key: 使用的索引;rows: 扫描的行数;
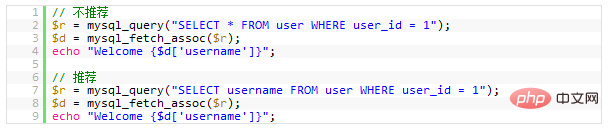
1.减少请求的数据量
只返回必要的列:最好不要使用
SELECT *语句。
只返回必要的行:使用LIMIT语句来限制返回的数据。
缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
2.减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
1.切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
2.分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
キャッシュをより効率的にする: 結合クエリの場合、テーブルの 1 つが変更されると、クエリ キャッシュ全体が使用できなくなります。分解後の複数のクエリの場合、1 つのテーブルが変更された場合でも、他のテーブルのクエリ キャッシュは引き続き使用できます。
複数の単一テーブル クエリに分解する: これらの単一テーブル クエリのキャッシュされた結果は、他のクエリで使用される可能性が高くなるため、冗長なレコード クエリが削減されます。
ロックの競合を減らす;
アプリケーション層で接続するとデータベースの分割が容易になり、高いパフォーマンスとスケーラビリティを実現しやすくなります。
クエリ自体の効率も向上する可能性があります。たとえば、次の例では、結合クエリの代わりに IN() を使用すると、MySQL が ID 順にクエリを実行できるようになり、ランダム結合よりも効率的になる可能性があります。
SELECT * FROM tab JOIN tag_post ON tag_post.tag_id=tag.id JOIN post ON tag_post.post_id=post.id WHERE tag.tag='mysql'; SELECT * FROM tag WHERE tag='mysql'; SELECT * FROM tag_post WHERE tag_id=1234; SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
通过对查询语句的分析,可以了解查询语句执行的情况,找出查询语句执行的瓶颈,从而优化查询语句。mysql中提供了EXPLAIN语句和
DESCRIBE语句,用来分析查询语句。EXPLAIN语句的基本语法如下:
EXPLAIN [EXTENDED] SELECT select_options;
使用EXTENED关键字,EXPLAIN语句将产生附加信息。select_options是select语句的查询选项,包括from where子句等等。
执行该语句,可以分析EXPLAIN后面的select语句的执行情况,并且能够分析出所查询的表的一些特征。
例如:EXPLAIN SELECT * FROM user;
查询结果进行解释说明:
a、id:select识别符,这是select的查询序列号。
b、select_type:标识select语句的类型。
它可以是以下几种取值:
b1、SIMPLE(simple)表示简单查询,其中不包括连接查询和子查询。
b2、PRIMARY(primary)表示主查询,或者是最外层的查询语句。
b3、UNION(union)表示连接查询的第2个或者后面的查询语句。
b4、DEPENDENT UNION(dependent union)连接查询中的第2个或者后面的select语句。取决于外面的查询。
b5、UNION RESULT(union result)连接查询的结果。
b6、SUBQUERY(subquery)子查询的第1个select语句。
b7、DEPENDENT SUBQUERY(dependent subquery)子查询的第1个select,取决于外面的查询。
b8、DERIVED(derived)导出表的SELECT(FROM子句的子查询)。
c、table:表示查询的表。
d、type:表示表的连接类型。
下面按照从最佳类型到最差类型的顺序给出各种连接类型。
d1、system,该表是仅有一行的系统表。这是const连接类型的一个特例。
d2、const,数据表最多只有一个匹配行,它将在查询开始时被读取,并在余下的查询优化中作为常量对待。const表查询速度很快,因为它们只读一次。const用于使用常数值比较primary key或者unique索引的所有部分的场合。
例如:EXPLAIN SELECT * FROM user WHERE id=1;
d3、eq_ref,对于每个来自前面的表的行组合,从该表中读取一行。当一个索引的所有部分都在查询中使用并且索引是UNIQUE或者PRIMARY KEY时候,即可使用这种类型。eq_ref可以用于使用“=”操作符比较带索引的列。比较值可以为常量或者一个在该表前面所读取的表的列的表达式。
例如:EXPLAIN SELECT * FROM user,db_company WHERE user.company_id = db_company.id;
d4、ref对于来自前面的表的任意行组合,将从该表中读取所有匹配的行。这种类型用于所以既不是UNION也不是primaey key的情况,或者查询中使用了索引列的左子集,即索引中左边的部分组合。ref可以用于使用=或者操作符的带索引的列。
d5、ref_or_null,该连接类型如果ref,但是如果添加了mysql可以专门搜索包含null值的行,在解决子查询中经常使用该连接类型的优化。
d6、index_merge,该连接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
d7、unique_subquery,该类型替换了下面形式的in子查询的ref。是一个索引查询函数,可以完全替代子查询,效率更高。
d8、index_subquery,该连接类型类似于unique_subquery,可以替换in子查询,但是只适合下列形式的子查询中非唯一索引。
d9、range,只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。key_len包含所使用索引的最长关键元素。当使用=,,>,>=,,between或者in操作符,用常量比较关键字列时,类型为range。
d10、index,该连接类型与all相同,除了只扫描索引树。着通常比all快,引文索引问价通常比数据文件小。
d11、all,对于前面的表的任意行组合,进行完整的表扫描。如果表是第一个没有标记const的表,这样不好,并且在其他情况下很差。通常可以增加更多的索引来避免使用all连接。
e.possible_keys: possible_keys 列は、mysql がテーブル内の行を検索するために使用できるインデックスを示します。列が null の場合、関連付けられたインデックスはありません。この場合、where句をチェックして、インデックス付けに適した特定の列が発生するかどうかを確認することで、クエリのパフォーマンスを向上させることができます。その場合は、適切なインデックスを作成してクエリのパフォーマンスを向上させることができます。
f,key: クエリで実際に使用されるインデックスを示します。インデックスが選択されていない場合、この列の値は null です。mysql にインデックスの使用または無視を強制したい場合は、 possible_key 列をクエリで使用します。インデックスを強制する、インデックスを使用する、またはインデックスを無視する。
g,key_len: mysql で選択されたインデックス フィールドの長さをバイト単位で計算して示します。キーが null の場合、長さは null です。 key_len 値は、mysql が実際に使用する複数列インデックス内のフィールドの数を決定することに注意してください。
h,ref: レコードのクエリに使用する列、定数、またはインデックスを示します。
i,rows: テーブル内でクエリを実行するときに mysql がチェックする必要がある行の数を表示します。
j,Extra: mysql がクエリを処理するときのこの列の詳細情報。
推奨学習: mysql ビデオ チュートリアル
以上がmysql最適化実践スキルの超詳しくまとめの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



