

Redis クラスター ソリューション (マスター/スレーブ モード、センチネル モード、Redis クラスター モード) についての深い理解

この記事では、Redis に関する関連知識を提供し、主にマスター/スレーブ モード、センチネル モード、Redis クラスター モードの関連問題について紹介します。

推奨学習: Redis チュートリアル
Redis クラスター ソリューションの概要 (マスター/スレーブ モード、センチネル モード、Redis クラスター モード) )
1. マスター/スレーブ モード
# データを 1 つの Redis に完全に保存するには、
データのバックアップと、大量のデータによって引き起こされるパフォーマンスの低下という 2 つの主な問題があります。
Redis のマスター/スレーブ モデルは、これら 2 つの問題に対するより良い解決策を提供します。マスター/スレーブ モードは、1 つの Redis インスタンスをホストとして使用し、残りのインスタンスをバックアップ マシンとして使用することを指します。
ホストとスレーブのデータは完全に一致しています。ホストはデータの書き込みや読み取りなどのさまざまな操作をサポートしますが、スレーブはホストとのデータの同期と読み取りのみをサポートします。つまり、クライアントはデータに書き込むことができます。ホストはスレーブへのデータ書き込み操作を自動的に同期します。
マスター/スレーブ モードは、データ バックアップの問題を非常にうまく解決します。マスター/スレーブ サービス データはほぼ一貫しているため、データを書き込むコマンドは実行のためにホストに送信でき、データを読み取るコマンドはホストに送信できます。異なるスレーブを使用してマシンを実行することで、読み取りと書き込みを分離するという目的を達成します。
マスター/スレーブ レプリケーションの仕組み:
スレーブ スレーブ ノード サービスが開始してマスターに接続すると、SYNC コマンドがアクティブに送信されます。同期コマンドを受信した後、マスター サービスのマスター ノードはバックグラウンド保存プロセスを開始し、データ セットを変更するために受信したすべてのコマンドを収集します。バックグラウンド プロセスが完了した後、マスターはデータベース ファイル全体をスレーブに転送して、完全な同期を完了します。同期です。スレーブ スレーブ ノード サービスは、データベース ファイルのデータを受信後、メモリに保存し、ロードします。その後、マスターノードは収集した全ての変更コマンドと新たな変更コマンドを順次スレーブに送信し、今度はスレーブがこれらのデータ変更コマンドを実行して最終的なデータ同期を実現します。
マスターとスレーブ間のリンクが切断された場合、スレーブは自動的にマスターに再接続でき、接続が成功すると、完全な同期が自動的に実行されます。 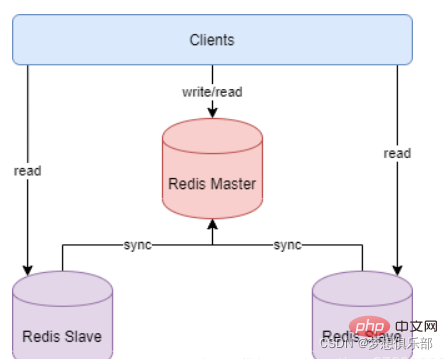
デプロイメント:
redis バージョン:6.0.9
1. Redis 構成ファイル
のコピーを 4 つコピーし、名前を付けますマスター .conf スレーブ 1.conf スレーブ 2.conf スレーブ 3.conf
2. 4 つの設定ファイルの簡単な設定
マスター ノードの設定ファイルは通常、特別な設定を必要としません。デフォルトのポートは 6379# です。 ## スレーブ 1 ノード ポート 6380 を設定し、replicaof 127.0.0.1 の別の行を構成します 6379
スレーブ 2 ノード ポートの設定 6381 と、replicaof 127.0.0.1 の別の行を構成します 6379
スレーブ 3 ノード ポートの設定 6382 は、replicaof 127.0 の別の行を構成します。 0.1 6379
redis-server smile1.conf
redis-server smile2.conf
redis-server smile3.conf
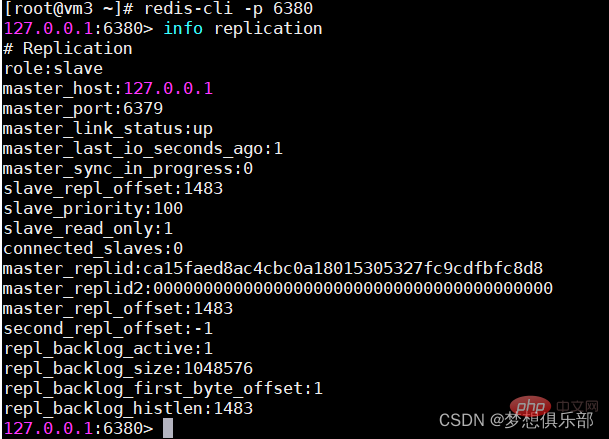
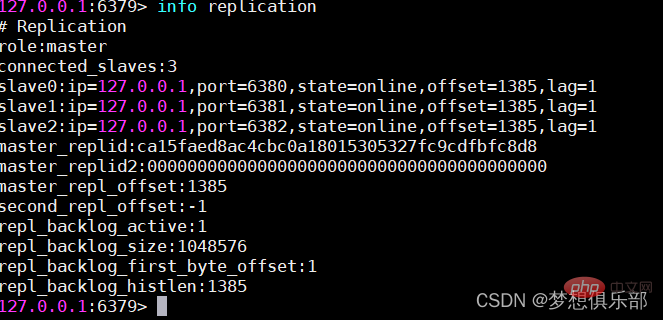
マスターはデータをスレーブに自動的に同期でき、読み取りと書き込みを分離してマスターの読み取り圧力を共有できます。
マスターとスレーブ間の同期はノンブロッキング方式で実行されます。
2. 欠点:
マスターがダウンしています。ダウンタイム前にデータが同期されていない場合、IP 切り替え後にデータの不整合が発生します。
復旧は困難です。オンライン拡張をサポートしており、Redis の容量は単一マシン構成によって制限されます
実は、redis のマスター スレーブ モードは非常にシンプルで、実際の運用環境ではほとんど使用されません。マスターの使用は推奨されません。実際の運用環境では、システムの高可用性を実現するためにスレーブ モードが推奨されますが、これが推奨されない理由は、その欠点によるものです。システムの要件は高いです。このモデルは非常に単純ですが、このモデルは他のモデルの基礎となるため、このモデルを理解することは他のモデルを学習するのに非常に役立ちます。
マスターとスレーブが正常に動作しているかどうかを監視します。
マスターが故障した場合、自動的にスレーブをマスターに変換できます (兄が死亡したため、引き継ぐ弟を選択します)
複数の監視員が同じ Redis を監視でき、監視員も自動的に監視されます
スレーブおよび他のセンチネル ノードを自動的に検出した後、センチネルは定期的に PING コマンドを送信することで、これらのデータベースとノードがサービスを停止しているかどうかを定期的に監視できます。
PING を実行しているデータベースまたはノードがタイムアウト (sentinel down-after-milliseconds master-name milliseconds で設定) され、応答しない場合、Sentinel はそれが主観的にオフラインであるとみなします (sdown、s は主観的 - 主観的にを意味します)。マスターがオフラインの場合、センチネルは他のセンチネルにコマンドを送信し、マスターも主観的にオフラインであると考えるかどうかを尋ねます。投票が特定の数 (つまり、構成ファイルのクォーラム) に達すると、 Sentinel は、マスターが客観的にオフライン (odown) であるとみなします。o は客観的に - 客観的に)、マスター/スレーブ システムの障害回復を開始する先頭のセンチネル ノードを選択します。マスターのオフライン ステータスに同意するのに十分なセンチネル プロセスがない場合、マスターの客観的なオフライン ステータスは削除されます。マスターが再度センチネル プロセスに送信された PING コマンドに対して有効な応答を返すと、マスターの主観的なオフライン ステータスは削除されます。
Sentinel は、マスターが客観的にオフラインになった後、選出されたリーダー センチネルによって障害回復操作が実行される必要があると考えています。
リーダーが選出された後、リーダーはシステム上で障害回復の実行を開始します。障害が発生したマスターから開始します。データベースから 1 つを選択して新しいマスターを選択します。
成功する必要があるスレーブを選択した後、先頭のセンチネルはデータベースにコマンドを送信してマスターにアップグレードし、次に他のマスターにコマンドを送信します。スレーブが新しいマスターを受け入れ、最後にデータを更新します。停止した古いマスターを新しいマスターのスレーブ データベースに更新して、サービスが復元された後もスレーブとして実行を継続できるようにします。 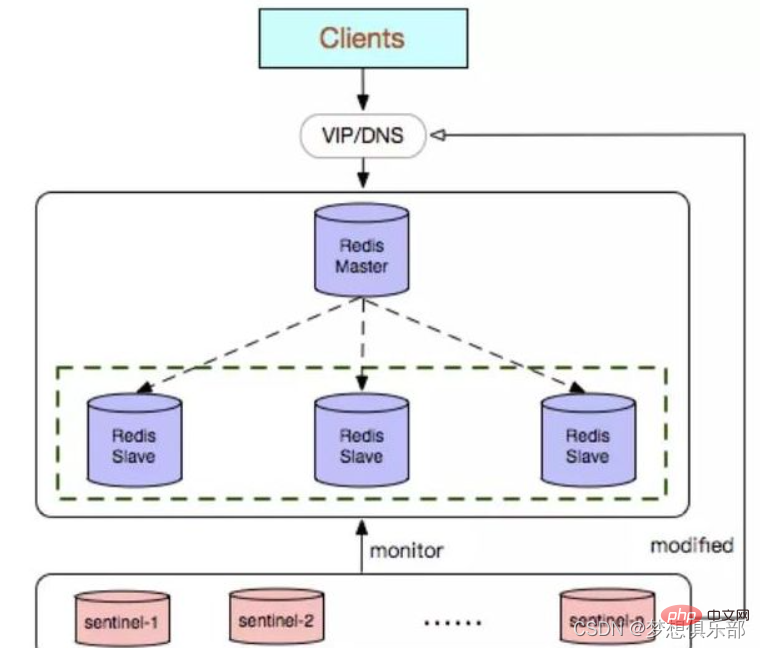
センチネル モードは、以前のマスター/スレーブ レプリケーション モードに基づいています。 Sentinel 設定ファイルは Sentinel.conf です。対応するディレクトリに次の設定を追加します。ポートと競合しないように注意してください:
port 26379 protected-mode no daemonize yes pidfile "/var/run/redis-sentinel-26379.pid" logfile "/data/redis/logs/sentinel_26379.log" dir "/data/redis/6379" sentinel monitor mymaster 127.0.0.1 6379 2 ##指定主机IP地址和端口,并且指定当有2台哨兵认为主机挂了,则对主机进行容灾切换 #sentinel auth-pass mymaster pwdtest@2019 ##当在Redis实例中开启了requirepass,这里就需要提供密码 sentinel down-after-milliseconds mymaster 3000 ##这里设置了主机多少秒无响应,则认为挂了 sentinel failover-timeout mymaster 180000 ##故障转移的超时时间,这里设置为三分钟
形式は次のとおりです:
センチネルのステータスの表示 :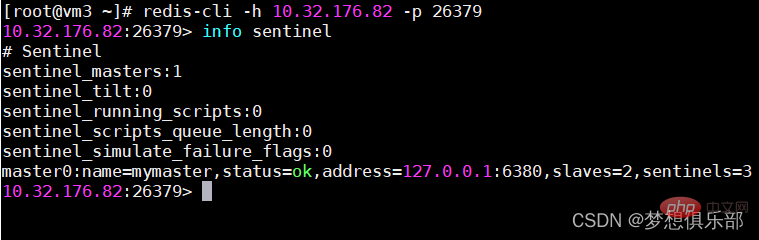
 ##クラスターはセンターレス構造を採用しており、
##クラスターはセンターレス構造を採用しており、
クラスター モードの具体的な動作メカニズム:
キーにアクセスすると、Redis はCRC16 アルゴリズムに基づいて結果を取得し、結果の剰余を 16384 まで計算して、各キーが 0 ~ 16383 の番号が付いたハッシュ スロットに対応するようにします。この値を使用して、対応するスロットに対応するノードを見つけます。その後、アクセス操作のために対応するノードに自動的にジャンプします。
高可用性を確保するために、クラスター モードではマスター/スレーブ レプリケーション モードも導入されています。1 つのマスター ノードは 1 つ以上のスレーブ ノードに対応します。マスター ノードがダウンすると、スレーブ ノードが有効になります。
他のマスター ノードがマスター ノード A に ping を実行するときに、マスター ノードの半分以上が A との通信がタイムアウトになると、マスター ノード A はダウンしていると見なされます。マスター ノード A とそのスレーブ ノードがダウンすると、クラスターはサービスを提供できなくなります。
Redis クラスターは、16384 スロットに対応するノードが正常に動作していることを確認する必要があります。ノードに障害が発生すると、そのノードが担当するスロットも無効になり、クラスター全体が動作しなくなります。
クラスターのアクセシビリティを向上させるために、公式に推奨されるソリューションは、ノードをマスター/スレーブ構造、つまりマスター ノードと n 個のスレーブ ノードに構成することです。このとき、マスター ノードに障害が発生した場合、Redis Cluster は選出アルゴリズムに基づいてマスター ノードに昇格するスレーブ ノードの 1 つを選択し、クラスター全体が外部へのサービスの提供を継続します。Redis Cluster 自体がフェイルオーバーを提供します。耐障害性。
クラスター モードのクラスター ノードの最小構成は 6 ノードです (クラスター選択メカニズムとマスター/スレーブ バックアップの実装によると、redis クラスターを形成するには、合計で少なくとも 3 つのマスターと 3 つのスレーブが必要です)。 Redis クラスターを形成するには少なくとも半分が必要であるため、ノードがダウンしていてマスター/スレーブ バックアップが必要かどうかを判断します) (マスター ノードが読み取りおよび書き込み操作を提供し、スレーブ ノードがバックアップ ノードとして機能する場合)。リクエストを提供し、フェイルオーバーのみに使用されます。
クラスタークラスターのデプロイメント
クラスター選択メカニズムとマスター/スレーブバックアップの実装によると、redis クラスターを形成するには、合計で少なくとも 3 つのマスターと 3 つのスレーブが必要です。テスト環境は 6 つから開始できます。 redis ノードは 1 台の物理マシン上にありますが、運用環境には少なくとも 2 ~ 3 台の物理マシンを準備する必要があります。 (ここでは 3 つの仮想マシンが使用されています)
クラスター モードは Sentinel モードに基づいています。動的拡張が必要なデータが大量にある場合、最初の 2 つは機能せず、データを断片化する必要があります。redis を配布します。特定のルールに従ってデータを複数のマシンに送信します。
该模式就支持动态扩容,可以在线增加或删除节点,而且客户端可以连接任何一个主节点进行读写,不过此时的从节点仅仅只是备份的作用。至于为何能做到动态扩容,主要是因为Redis集群没有使用一致性hash,而是使用的哈希槽。Redis集群会有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,而集群的每个节点负责一部分hash槽。
那么这样就很容易添加或者删除节点, 比如如果我想新添加个新节点, 我只需要从已有的节点中的部分槽到过来;如果我想移除某个节点,就只需要将该节点的槽移到其它节点上,然后将没有任何槽的A节点从集群中移除即可。由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
需要注意的是,该模式下不支持同时处理多个key(如MSET/MGET),因为redis需要把key均匀分布在各个节点上,并发量很高的情况下同时创建key-value会降低性能并导致不可预测的行为。
搭建集群
这里就直接搭建较为复杂的Cluster模式集群,也是企业级开发过程中使用最多的。
1.建redis各节点目录
最终目录结构如下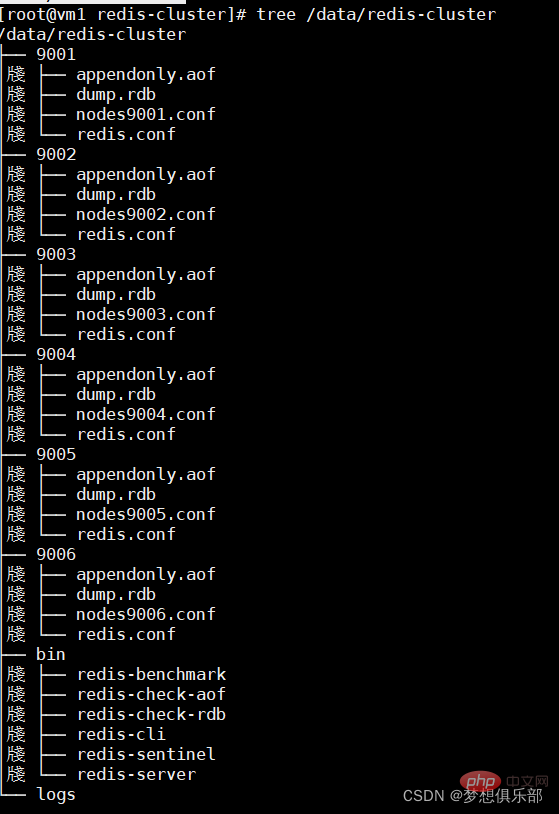
2.逐个修改redis配置
以 9001 的为例子,其余五个类似。
编辑 /data/redis-cluster/9001/redis.conf
redis.conf修改如下:
port 9001(每个节点的端口号) daemonize yes appendonly yes //开启aof bind 0.0.0.0(绑定当前机器 IP) dir "/data/redis-cluster/9001"(数据文件存放位置,,自己加到最后一行 快捷键 shift+g) pidfile /var/run/redis_9001.pid(pid 9001和port要对应) logfile "/data/redis-cluster/logs/9001.log" cluster-enabled yes(启动集群模式) cluster-config-file nodes9001.conf(9001和port要对应) cluster-node-timeout 15000
3.逐个启动redis节点
/data/redis-cluster/bin/redis-server /data/redis-cluster/9001/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9002/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9003/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9004/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9005/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9006/redis.conf
现在检查一下是否成功开启,如下图所示,都开启成功。
ps -el | grep redis
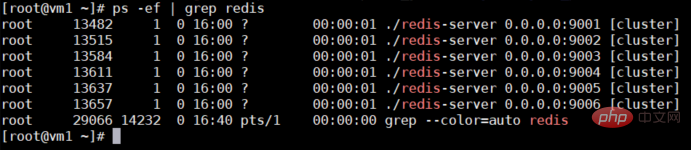
4.集群配置
此时的节点虽然都启动成功了,但他们还不在一个集群里面,不能互相发现,测试会报错:(error) CLUSTERDOWN Hash slot not served。
如下图所示

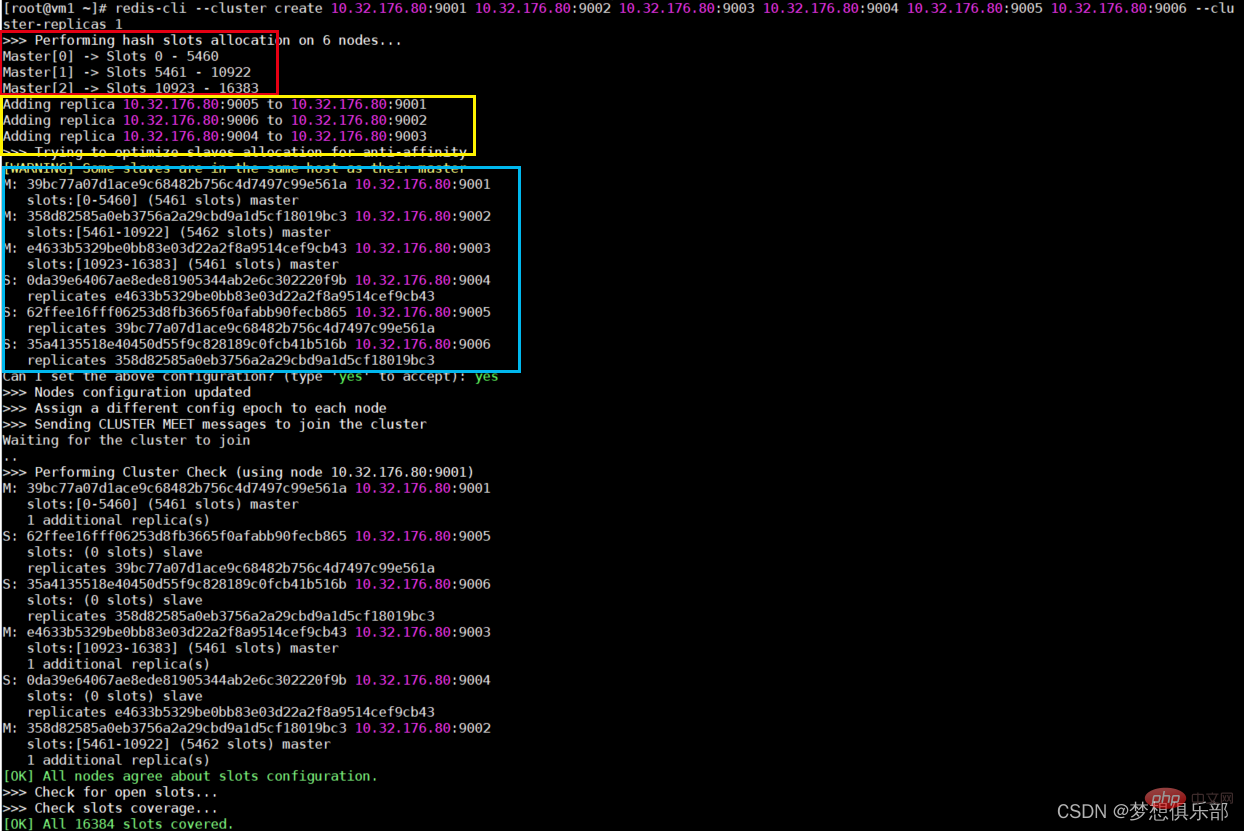
redis-cli --cluster create 10.32.176.80:9001 10.32.176.80:9002 10.32.176.80:9003 10.32.176.80:9004 10.32.176.80:9005 10.32.176.80:9006 --cluster-replicas 1
–cluster-replicas 1 这个指的是从机的数量,表示我们希望为集群中的每个主节点创建一个从节点。
红色选框是给三个主节点分配的共16384个槽点。
黄色选框是主从节点的分配情况。
蓝色选框是各个节点的详情。
5.测试
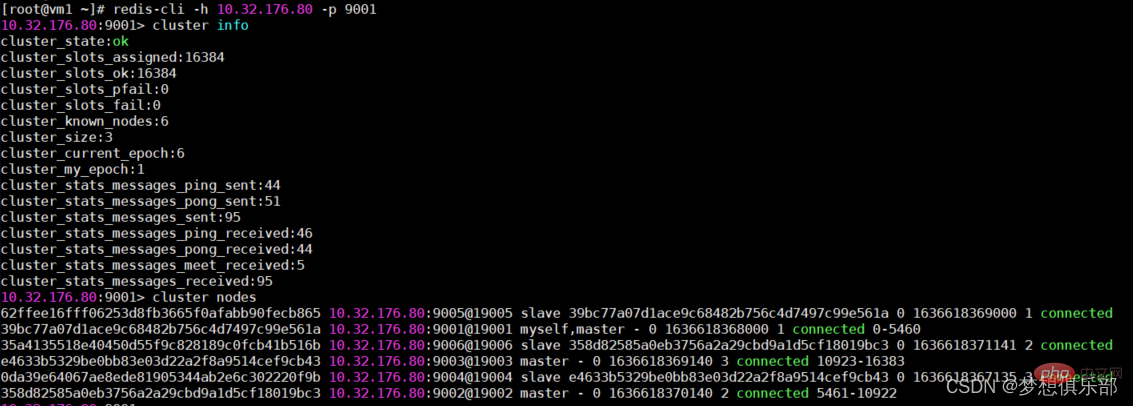
现在通过客户端命令连接上,通过集群命令看一下状态和节点信息等
/data/redis-cluster/bin/redis-cli -c -h 10.32.176.80 -p 9001 cluster info cluster nodes
效果图如下,集群搭建成功。
现在往9001这个主节点写入一条信息,我们可以在9002这个主节点取到信息,集群间各个节点可以通信。
6.故障转移
故障转移机制详解
集群中的节点会向其它节点发送PING消息(该PING消息会带着当前集群和节点的信息),如果在规定时间内,没有收到对应的PONG消息,就把此节点标记为疑似下线。当被分配了slot槽位的主节点中有超过一半的节点都认为此节点疑似下线(就是其它节点以更高的频次,更频繁的与该节点PING-PONG),那么该节点就真的下线。其它节点收到某节点已经下线的广播后,把自己内部的集群维护信息也修改为该节点已事实下线。
节点资格审查:然后对从节点进行资格审查,每个从节点检查最后与主节点的断线时间,如果该值超过配置文件的设置,那么取消该从节点的资格。准备选举时间:这里使用了延迟触发机制,主要是给那些延迟低的更高的优先级,延迟低的让它提前参与被选举,延迟高的让它靠后参与被选举。(延迟的高低是依据之前与主节点的最后断线时间确定的)
選挙投票: スレーブ ノードが選挙資格を取得すると、スロットを持つ他のマスター ノードに選挙リクエストを開始し、投票します。優先度の高いスレーブ ノードほど、マスター ノードになる可能性が高くなります。スレーブ ノードから取得した投票数が特定の値に達したとき (たとえば、クラスター内に N 個のマスター ノードがある場合、1 つのスレーブ ノードが N/2 1 票を取得している限り、そのスレーブ ノードが勝者とみなされます) 、マスター ノードとして置き換えられます。
マスター ノードを交換する: 選択されたスレーブ ノードは、slaveof no one を実行してステータスをスレーブからマスターに変更します。その後、clusterDelSlot 操作を実行して、障害が発生したマスター ノードの原因となっているスロットをキャンセルし、clusterAddSlot を実行して割り当てます。これらのスロットをそれ自体に送信し、独自の pong メッセージをクラスターにブロードキャストして、現在のスレーブ ノードがマスター ノードになったことをクラスター内のすべてのノードに通知します。
引き継ぎ関連操作: 新しいマスター ノードは、以前に障害が発生したマスター ノードのスロット情報を引き継ぎ、自身のスロットに関連するコマンド要求を受信して処理します。
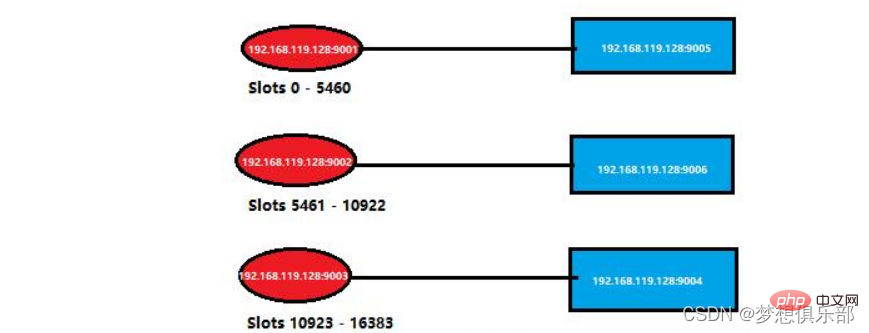
フェイルオーバーテスト
これは、前のクラスターの特定のノードの状況です。以下のように単純化しました。図でクラスター情報を振り返ることができます。 。
ここで 9001 ポートのプロセスを閉じます。これは、マスター ノードがハングアップすることをシミュレートするためです。
停止した Redis ノードにログインすると、サービスが拒否されます。正常に動作しているマスター ノードからログインし、再度クラスター内の情報を確認してください。
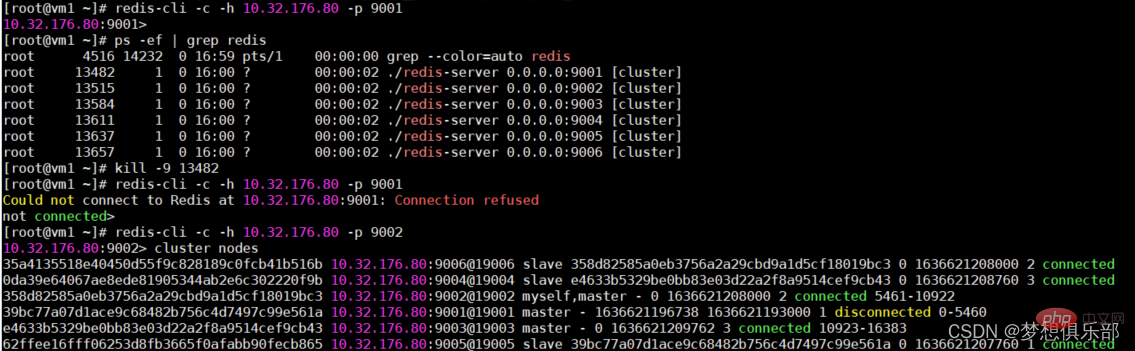
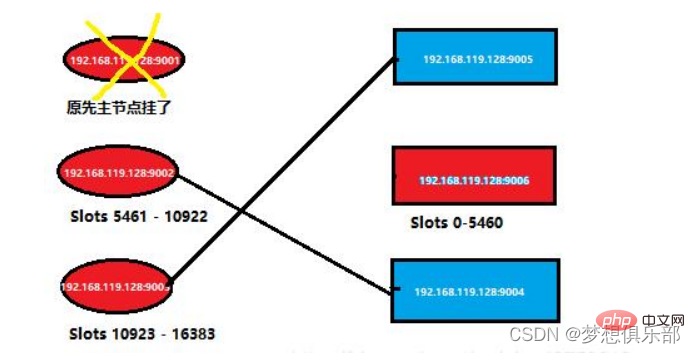
つまり、以前のクラスター情報は次のようになります


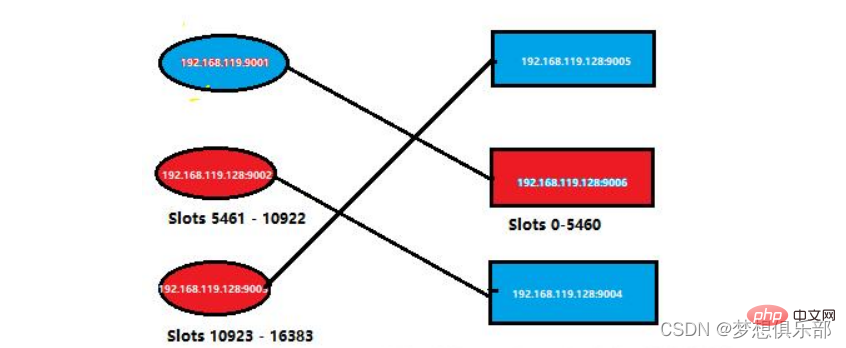 推奨される学習:
推奨される学習:
以上がRedis クラスター ソリューション (マスター/スレーブ モード、センチネル モード、Redis クラスター モード) についての深い理解の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redis用のメッセージミドルウェアの作成方法
Apr 10, 2025 pm 07:51 PM
Redis用のメッセージミドルウェアの作成方法
Apr 10, 2025 pm 07:51 PM
Redisは、メッセージミドルウェアとして、生産消費モデルをサポートし、メッセージを持続し、信頼できる配信を確保できます。メッセージミドルウェアとしてRedisを使用すると、低遅延、信頼性の高いスケーラブルなメッセージングが可能になります。
