

この記事は、java に関する関連知識を提供します。主に Java の同時実行に関連する問題を紹介し、いくつかの問題を要約します。どれくらいになるかを見てみましょう。お役に立てば幸いです。みんなに。 。

推奨学習: 「java チュートリアル 」
オペレーティング システムの観点から見ると、スレッドは CPU 割り当ての最小単位です。
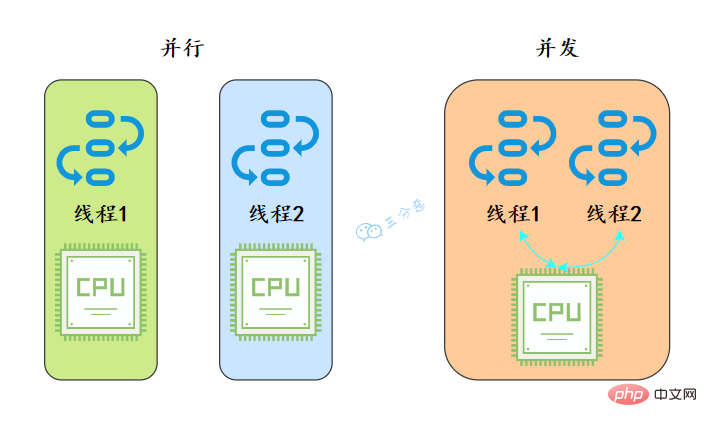
# 私たちが食堂に食べ物を取りに行くときと同じように、並行性とは、私たちが複数の窓口に並び、数人のおばさんが同時に食べ物を手に入れることを意味します。 ; 同時進行とは、私たちが 1 つのウィンドウに群がることを意味します, おばさんはこれにスプーン一杯与え、そして急いであれにスプーン一杯与えました。

スレッドについて話すには、まずプロセスについて話さなければなりません。
オペレーティング システムは、リソースを割り当てるときにプロセスにリソースを割り当てますが、CPU リソースは特別であり、実行のために実際に CPU を占有するのはスレッドであるため、スレッドに割り当てられます。スレッドは CPU 割り当ての基本単位であると述べました。
たとえば、Java では、main 関数を開始すると、実際には JVM プロセスが開始されます。main 関数が配置されているスレッドは、このプロセス内のスレッドであり、メイン スレッドとも呼ばれます。
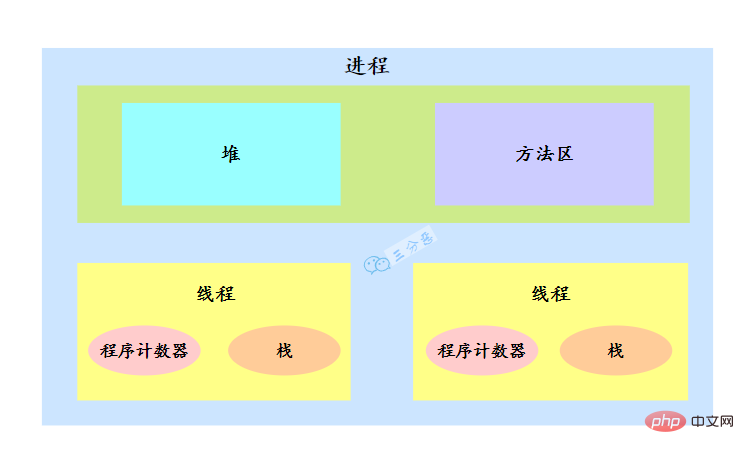
プロセス内に複数のスレッドが存在します。複数のスレッドはプロセスのヒープおよびメソッド領域のリソースを共有しますが、各スレッドには独自のプログラム カウンタとスタックがあります。
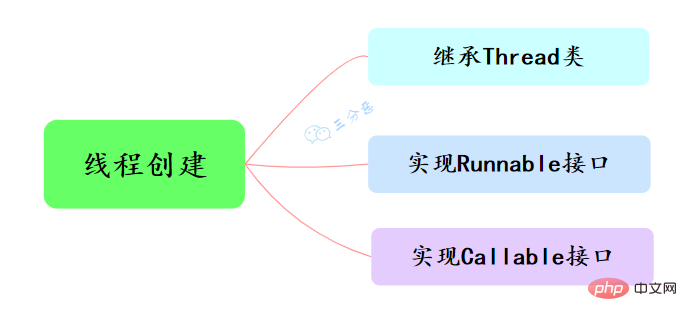
Java でスレッドを作成するには、主に 3 つの方法があります。つまり、Thread クラスの継承、Runnable インターフェイスの実装、および Callable インターフェイスの実装です。
public class ThreadTest {
/**
* 继承Thread类
*/
public static class MyThread extends Thread {
@Override
public void run() {
System.out.println("This is child thread");
}
}
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}}public class RunnableTask implements Runnable {
public void run() {
System.out.println("Runnable!");
}
public static void main(String[] args) {
RunnableTask task = new RunnableTask();
new Thread(task).start();
}}上の 2 つは戻り値がありませんが、スレッドの実行結果を取得する必要がある場合はどうすればよいでしょうか。
public class CallerTask implements Callable<string> {
public String call() throws Exception {
return "Hello,i am running!";
}
public static void main(String[] args) {
//创建异步任务
FutureTask<string> task=new FutureTask<string>(new CallerTask());
//启动线程
new Thread(task).start();
try {
//等待执行完成,并获取返回结果
String result=task.get();
System.out.println(result);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}}</string></string></string>JVM が start メソッドを実行すると、まずスレッドが作成され、作成された新しいスレッドによってスレッドの run メソッドが実行され、マルチスレッド効果が実現します。
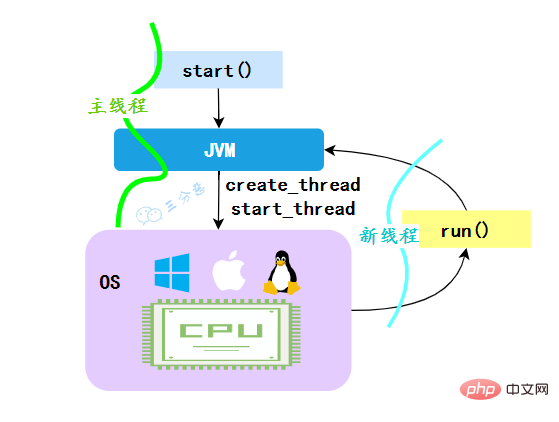
#**なぜ run() メソッドを直接呼び出せないのでしょうか? **Thread の run() メソッドが直接呼び出された場合、run メソッドは依然としてメインスレッドで実行され、これは順次実行と同等であり、マルチスレッド効果が達成されないことも明らかです。
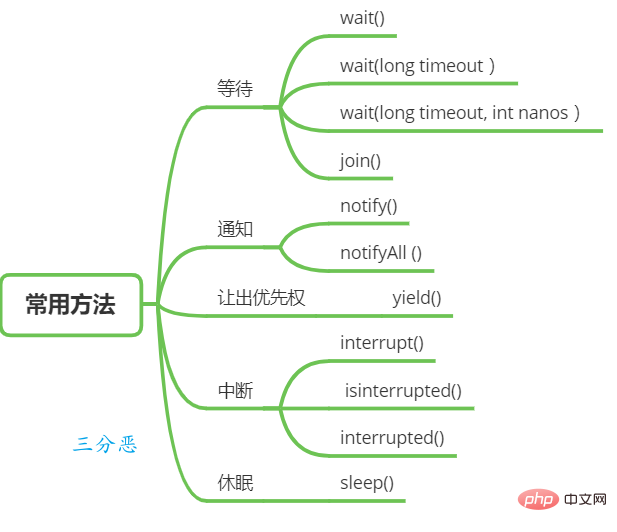
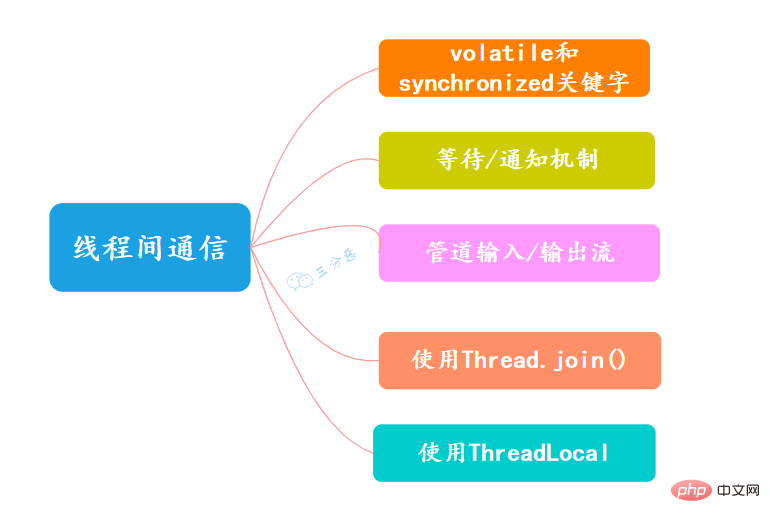
#スレッドの待機と通知
オブジェクト クラスには、スレッドの待機と通知に使用できる関数がいくつかあります。Thread クラスは、待機するためのメソッドも提供します。
join(): スレッド A が thread.join() ステートメントを実行する場合、その意味は現在のスレッド A は、
が thread.join() から戻る前に、スレッド thread が終了するのを待ちます。
Thread sleep
Give priority
スレッド中断
Java のスレッド中断はスレッド間の協調モードであり、スレッドの中断フラグを設定してもスレッドを直接終了することはできません。中断されたスレッドは、中断ステータスに応じて独自に処理します。
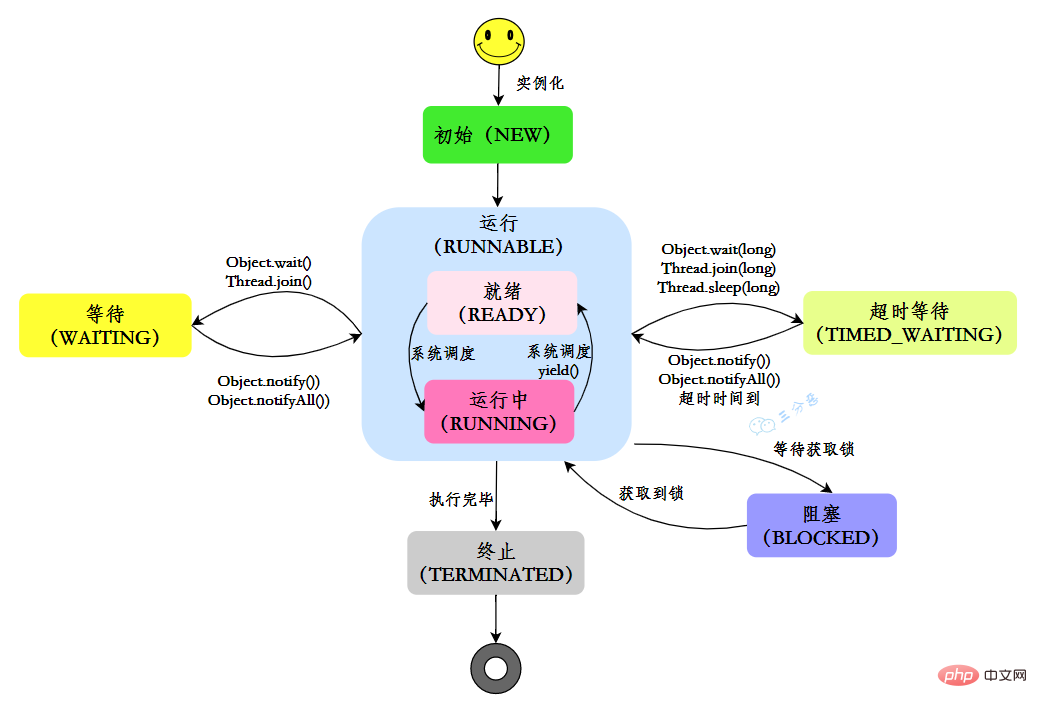
Java では、スレッドには 6 つの状態があります:
| State | Description |
|---|---|
| ##NEW | 初期状態: スレッドは作成されましたが、start() メソッドはまだ呼び出されていません |
| RUNNABLE | 実行状態 : Java スレッドは通常、オペレーティング システムでの準備完了と実行の 2 つの状態を「実行中」と呼びます。 |
| BLOCKED | ブロッキング状態:スレッドはロックでブロックされています |
| WAITING | 待機状態: スレッドが待機状態に入ったことを示します。この状態に入ることは、現在のスレッドが他のスレッドを待機する必要があることを意味します。特定のアクション (通知または中断) を行うためのスレッド |
| TIME_WAITING | タイムアウト待機ステータス: このステータスは WAITIND とは異なり、指定された時間に自動的に戻ることができます。 |
| TERMINATED | 終了ステータス: 現在のスレッドが実行を完了したことを示します |
独自のライフサイクルでは、スレッドは固定された状態にありませんが、コードが実行されるとさまざまな状態の間で切り替わります。Java スレッドの状態は、図に示すように変化します:
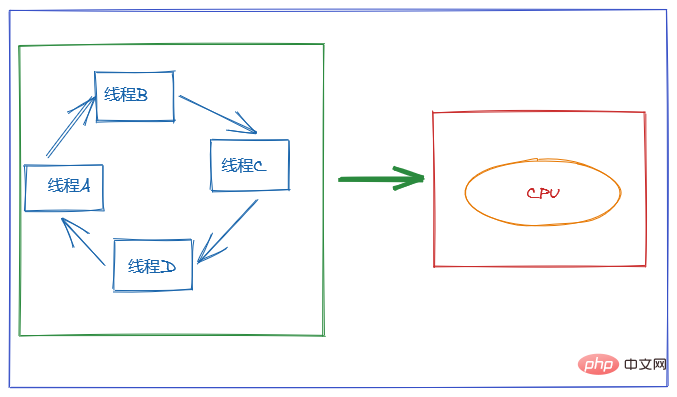
マルチスレッドを使用する目的は CPU を最大限に活用することですが、同時実行性は実際には 1 つの CPU で複数のスレッドを処理することであることがわかっています。
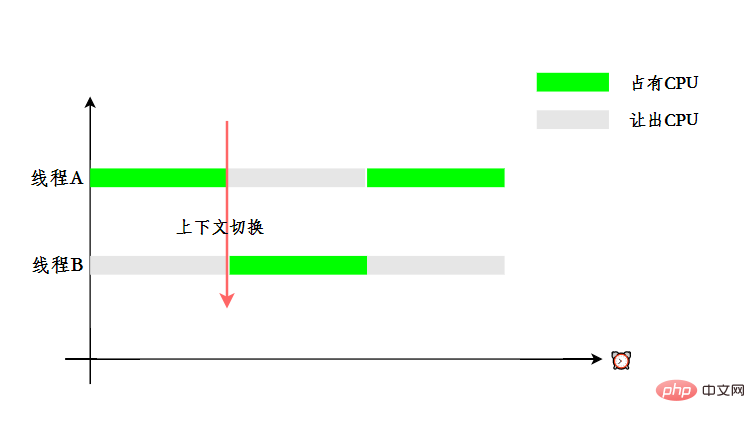
ユーザーに複数のスレッドが同時に実行されていると感じさせるために、タイム スライスのローテーションを使用して CPU リソースが割り当てられます。つまり、各スレッドにタイム スライスが割り当てられます。 . CPU は、タイム スライス内でタスクを実行するために占有されます。スレッドがタイム スライスを使い切ると、スレッドは準備完了状態になり、他のスレッドが CPU を占有できるようになります。これがコンテキスト スイッチです。
マルチスレッドに関しては、代替印刷、銀行振込、生産モデルと消費モデルなどの筆記試験問題も出題される可能性が高くなります。後日、Laosan が公開する予定です。一般的な質問を別の号で確認し、マルチスレッドの筆記試験問題を確認します。ThreadLocalThreadLocal には、実際には多くのアプリケーション シナリオはありませんが、マルチスレッド、データ構造、JVM が含まれており、何千回も攻撃を受けてきたベテランのインタビューです。 . 質問することができます。より多くのポイントを持っている場合は、ポイントを獲得する必要があります。 10.ThreadLocal とは何ですか? ThreadLocal。スレッド ローカル変数です。 ThreadLocal 変数を作成すると、この変数にアクセスする各スレッドは、この変数のローカル コピーを持つことになります。複数のスレッドがこの変数を操作する場合、実際には独自のローカル メモリ内で変数を操作するため、スレッドの分離が実現されます。スレッドを回避する関数安全性の問題。
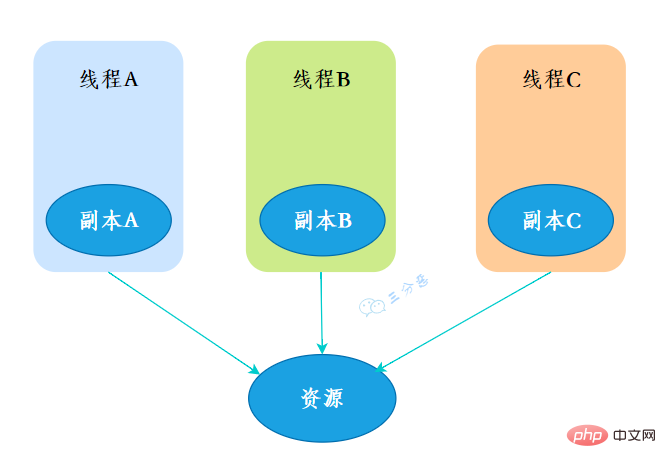
创建了一个ThreadLoca变量localVariable,任何一个线程都能并发访问localVariable。
//创建一个ThreadLocal变量public static ThreadLocal<string> localVariable = new ThreadLocal();</string>
线程可以在任何地方使用localVariable,写入变量。
localVariable.set("鄙人三某”);线程在任何地方读取的都是它写入的变量。
localVariable.get();
有用到过的,用来做用户信息上下文的存储。
我们的系统应用是一个典型的MVC架构,登录后的用户每次访问接口,都会在请求头中携带一个token,在控制层可以根据这个token,解析出用户的基本信息。那么问题来了,假如在服务层和持久层都要用到用户信息,比如rpc调用、更新用户获取等等,那应该怎么办呢?
一种办法是显式定义用户相关的参数,比如账号、用户名……这样一来,我们可能需要大面积地修改代码,多少有点瓜皮,那该怎么办呢?
这时候我们就可以用到ThreadLocal,在控制层拦截请求把用户信息存入ThreadLocal,这样我们在任何一个地方,都可以取出ThreadLocal中存的用户数据。
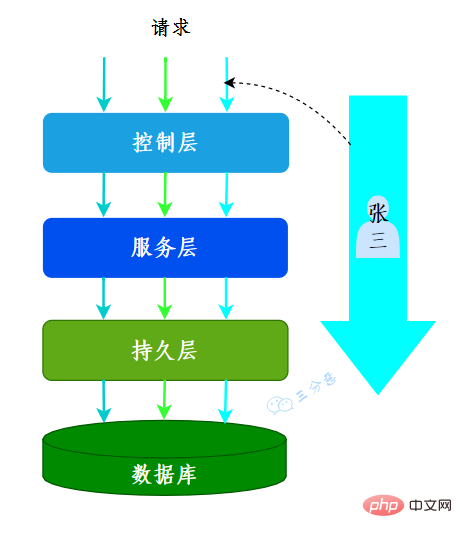
很多其它场景的cookie、session等等数据隔离也都可以通过ThreadLocal去实现。
我们常用的数据库连接池也用到了ThreadLocal:
我们看一下ThreadLocal的set(T)方法,发现先获取到当前线程,再获取ThreadLocalMap,然后把元素存到这个map中。
public void set(T value) {
//获取当前线程
Thread t = Thread.currentThread();
//获取ThreadLocalMap
ThreadLocalMap map = getMap(t);
//讲当前元素存入map
if (map != null)
map.set(this, value);
else
createMap(t, value);
}ThreadLocal实现的秘密都在这个ThreadLocalMap了,可以Thread类中定义了一个类型为ThreadLocal.ThreadLocalMap的成员变量threadLocals。
public class Thread implements Runnable {
//ThreadLocal.ThreadLocalMap是Thread的属性
ThreadLocal.ThreadLocalMap threadLocals = null;}ThreadLocalMap既然被称为Map,那么毫无疑问它是
static class Entry extends WeakReference<threadlocal>> {
/** The value associated with this ThreadLocal. */
Object value;
//节点类
Entry(ThreadLocal> k, Object v) {
//key赋值
super(k);
//value赋值
value = v;
}
}</threadlocal>这里的节点,key可以简单低视作ThreadLocal,value为代码中放入的值,当然实际上key并不是ThreadLocal本身,而是它的一个弱引用,可以看到Entry的key继承了 WeakReference(弱引用),再来看一下key怎么赋值的:
public WeakReference(T referent) {
super(referent);
}key的赋值,使用的是WeakReference的赋值。
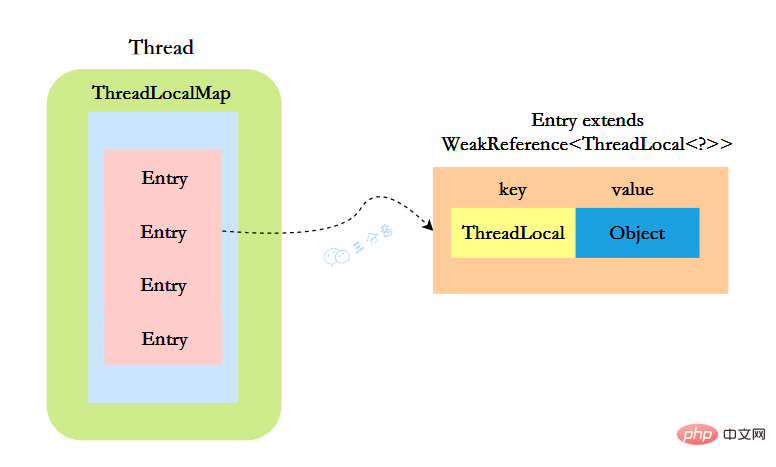
所以,怎么回答ThreadLocal原理?要答出这几个点:
我们先来分析一下使用ThreadLocal时的内存,我们都知道,在JVM中,栈内存线程私有,存储了对象的引用,堆内存线程共享,存储了对象实例。
所以呢,栈中存储了ThreadLocal、Thread的引用,堆中存储了它们的具体实例。
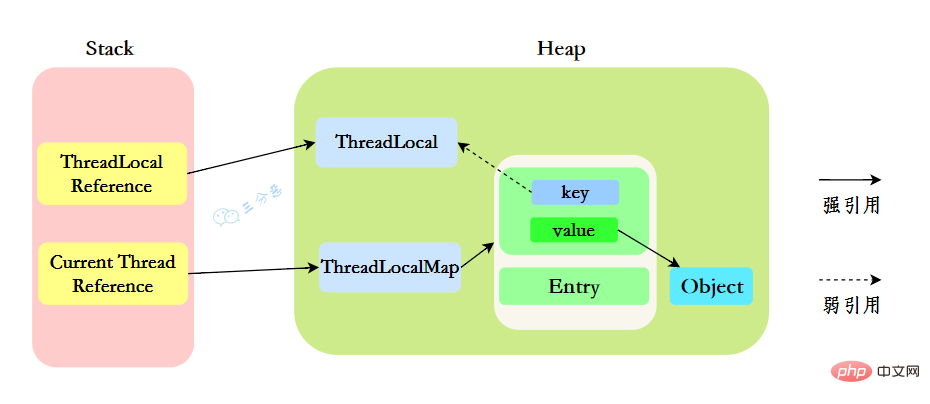
ThreadLocalMap中使用的 key 为 ThreadLocal 的弱引用。
“弱引用:只要垃圾回收机制一运行,不管JVM的内存空间是否充足,都会回收该对象占用的内存。”
那么现在问题就来了,弱引用很容易被回收,如果ThreadLocal(ThreadLocalMap的Key)被垃圾回收器回收了,但是ThreadLocalMap生命周期和Thread是一样的,它这时候如果不被回收,就会出现这种情况:ThreadLocalMap的key没了,value还在,这就会造成了内存泄漏问题。
那怎么解决内存泄漏问题呢?
很简单,使用完ThreadLocal后,及时调用remove()方法释放内存空间。
ThreadLocallocalVariable = new ThreadLocal();try { localVariable.set("鄙人三某”); ……} finally { localVariable.remove();}
那为什么key还要设计成弱引用?
key设计成弱引用同样是为了防止内存泄漏。
假如key被设计成强引用,如果ThreadLocal Reference被销毁,此时它指向ThreadLoca的强引用就没有了,但是此时key还强引用指向ThreadLoca,就会导致ThreadLocal不能被回收,这时候就发生了内存泄漏的问题。
ThreadLocalMap虽然被叫做Map,其实它是没有实现Map接口的,但是结构还是和HashMap比较类似的,主要关注的是两个要素:元素数组和散列方法。
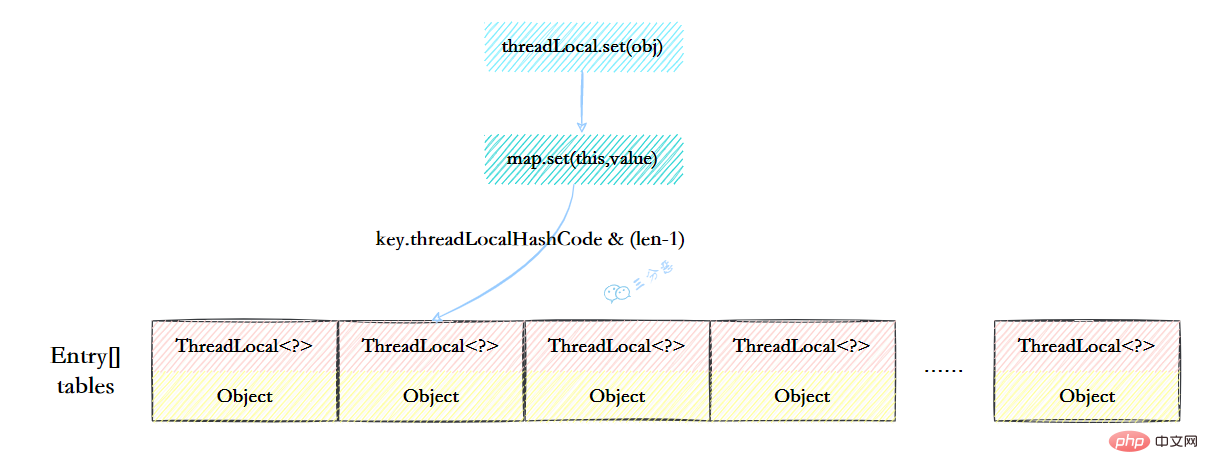
元素数组
一个table数组,存储Entry类型的元素,Entry是ThreaLocal弱引用作为key,Object作为value的结构。
private Entry[] table;
散列方法
散列方法就是怎么把对应的key映射到table数组的相应下标,ThreadLocalMap用的是哈希取余法,取出key的threadLocalHashCode,然后和table数组长度减一&运算(相当于取余)。
int i = key.threadLocalHashCode & (table.length - 1);
这里的threadLocalHashCode计算有点东西,每创建一个ThreadLocal对象,它就会新增0x61c88647,这个值很特殊,它是斐波那契数 也叫 黄金分割数。hash增量为 这个数字,带来的好处就是 hash 分布非常均匀。
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}我们可能都知道HashMap使用了链表来解决冲突,也就是所谓的链地址法。
ThreadLocalMap没有使用链表,自然也不是用链地址法来解决冲突了,它用的是另外一种方式——开放定址法。开放定址法是什么意思呢?简单来说,就是这个坑被人占了,那就接着去找空着的坑。
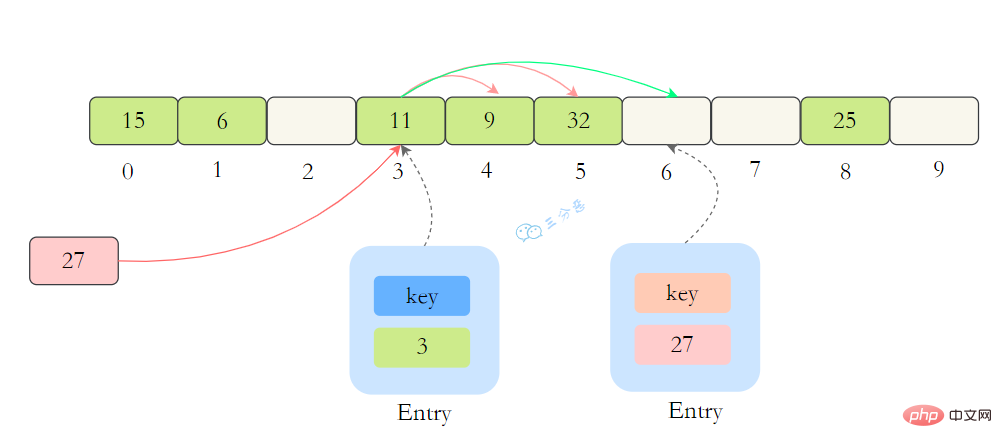
如上图所示,如果我们插入一个value=27的数据,通过 hash计算后应该落入第 4 个槽位中,而槽位 4 已经有了 Entry数据,而且Entry数据的key和当前不相等。此时就会线性向后查找,一直找到 Entry为 null的槽位才会停止查找,把元素放到空的槽中。
在get的时候,也会根据ThreadLocal对象的hash值,定位到table中的位置,然后判断该槽位Entry对象中的key是否和get的key一致,如果不一致,就判断下一个位置。
在ThreadLocalMap.set()方法的最后,如果执行完启发式清理工作后,未清理到任何数据,且当前散列数组中Entry的数量已经达到了列表的扩容阈值(len*2/3),就开始执行rehash()逻辑:
if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash();
再着看rehash()具体实现:这里会先去清理过期的Entry,然后还要根据条件判断size >= threshold - threshold / 4 也就是size >= threshold* 3/4来决定是否需要扩容。
private void rehash() {
//清理过期Entry
expungeStaleEntries();
//扩容
if (size >= threshold - threshold / 4)
resize();}//清理过期Entryprivate void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j <p>接着看看具体的<code>resize()</code>方法,扩容后的<code>newTab</code>的大小为老数组的两倍,然后遍历老的table数组,散列方法重新计算位置,开放地址解决冲突,然后放到新的<code>newTab</code>,遍历完成之后,<code>oldTab</code>中所有的<code>entry</code>数据都已经放入到<code>newTab</code>中了,然后table引用指向<code>newTab</code></p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/6137d48077cbb320beee2007e8763d69-16.png" class="lazy" alt="Java 同時実行に関するナレッジ ポイントを要約する"></p><p>具体代码:</p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/85310a4f8d2bb86283cd76fb2542424d-17.png" class="lazy" alt="ThreadLocalMap resize"></p><h2>17.父子线程怎么共享数据?</h2><p>父线程能用ThreadLocal来给子线程传值吗?毫无疑问,不能。那该怎么办?</p><p>这时候可以用到另外一个类——<code>InheritableThreadLocal</code>。</p><p>使用起来很简单,在主线程的InheritableThreadLocal实例设置值,在子线程中就可以拿到了。</p><pre class="brush:php;toolbar:false">public class InheritableThreadLocalTest {
public static void main(String[] args) {
final ThreadLocal threadLocal = new InheritableThreadLocal();
// 主线程
threadLocal.set("不擅技术");
//子线程
Thread t = new Thread() {
@Override
public void run() {
super.run();
System.out.println("鄙人三某 ," + threadLocal.get());
}
};
t.start();
}}那原理是什么呢?
原理很简单,在Thread类里还有另外一个变量:
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
在Thread.init的时候,如果父线程的inheritableThreadLocals不为空,就把它赋给当前线程(子线程)的inheritableThreadLocals。
if (inheritThreadLocals && parent.inheritableThreadLocals != null) this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals)
Java 同時実行に関するナレッジ ポイントを要約する(Java Memory Model,JMM),是一种抽象的模型,被定义出来屏蔽各种硬件和操作系统的内存访问差异。
JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。
Java 同時実行に関するナレッジ ポイントを要約する的抽象图:
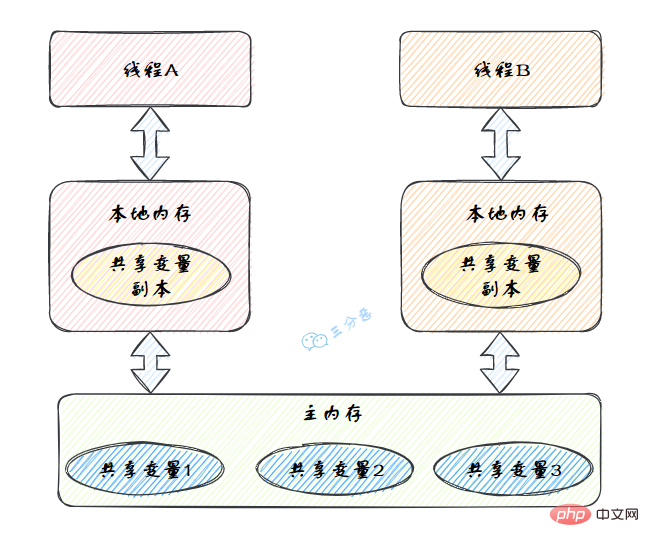
本地内存是JMM的 一个抽象概念,并不真实存在。它其实涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。
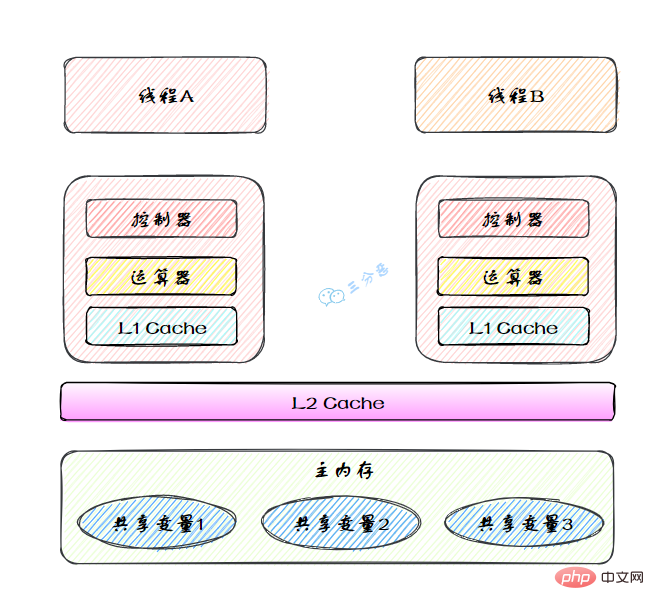
图里面的是一个双核 CPU 系统架构 ,每个核有自己的控制器和运算器,其中控制器包含一组寄存器和操作控制器,运算器执行算术逻辅运算。每个核都有自己的一级缓存,在有些架构里面还有一个所有 CPU 共享的二级缓存。 那么 Java 内存模型里面的工作内存,就对应这里的 Ll 缓存或者 L2 缓存或者 CPU 寄存器。
原子性、有序性、可见性是并发编程中非常重要的基础概念,JMM的很多技术都是围绕着这三大特性展开。
分析下面几行代码的原子性?
int i = 2;int j = i;i++;i = i + 1;
原子性、可见性、有序性都应该怎么保证呢?
synchronized。volatile关键字来保证可见性的,除此之外,final和synchronized也能保证可见性。synchronized或者volatile都可以保证多线程之间操作的有序性。在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型。
从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序,如图:

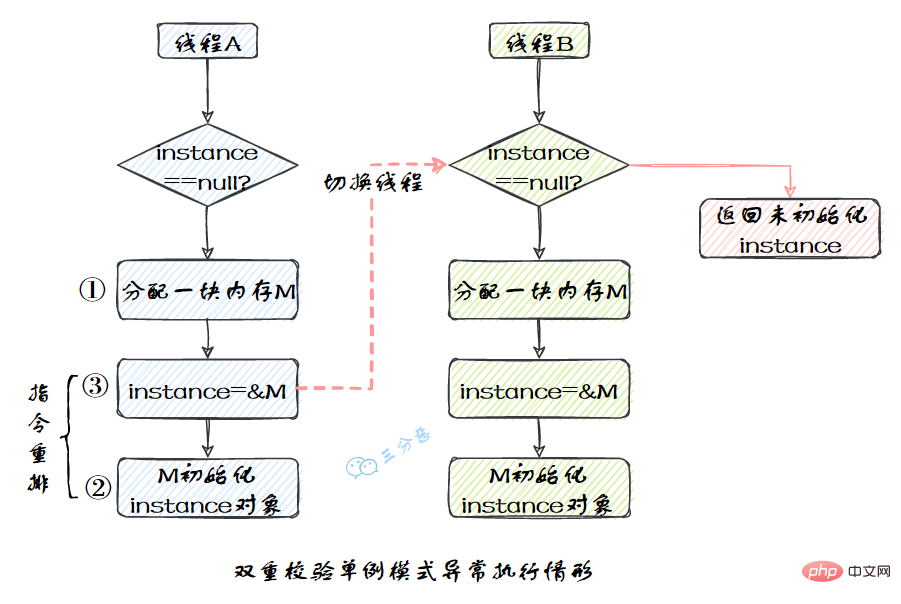
我们比较熟悉的双重校验单例模式就是一个经典的指令重排的例子,Singleton instance=new Singleton();对应的JVM指令分为三步:分配内存空间–>初始化对象—>对象指向分配的内存空间,但是经过了编译器的指令重排序,第二步和第三步就可能会重排序。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
指令重排也是有一些限制的,有两个规则happens-before和as-if-serial来约束。
happens-before的定义:
happens-before和我们息息相关的有六大规则:
as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提高并行度),单线程程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。为了具体说明,请看下面计算圆面积的代码示例。
double pi = 3.14; // Adouble r = 1.0; // B double area = pi * r * r; // C
上面3个操作的数据依赖关系:
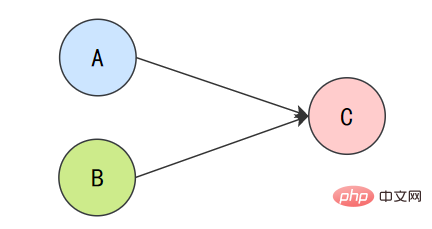
A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。
所以最终,程序可能会有两种执行顺序:
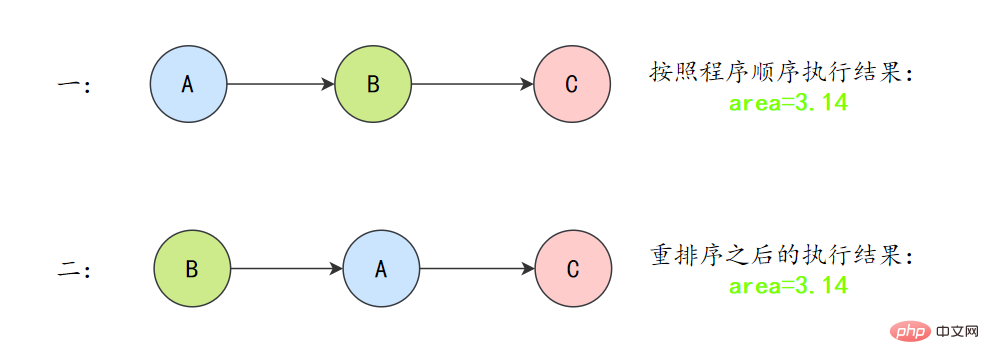
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器、runtime和处理器共同编织了这么一个“楚门的世界”:单线程程序是按程序的“顺序”来执行的。as- if-serial语义使单线程情况下,我们不需要担心重排序的问题,可见性的问题。
volatile有两个作用,保证可见性和有序性。
volatile怎么保证可见性的呢?
相比synchronized的加锁方式来解决共享变量的内存可见性问题,volatile就是更轻量的选择,它没有上下文切换的额外开销成本。
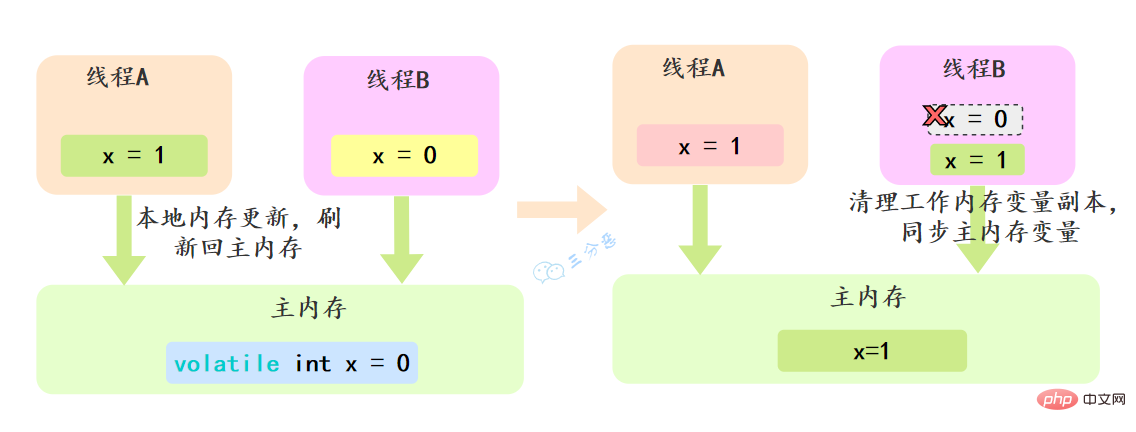
volatile可以确保对某个变量的更新对其他线程马上可见,一个变量被声明为volatile 时,线程在写入变量时不会把值缓存在寄存器或者其他地方,而是会把值刷新回主内存 当其它线程读取该共享变量 ,会从主内存重新获取最新值,而不是使用当前线程的本地内存中的值。
例如,我们声明一个 volatile 变量 volatile int x = 0,线程A修改x=1,修改完之后就会把新的值刷新回主内存,线程B读取x的时候,就会清空本地内存变量,然后再从主内存获取最新值。
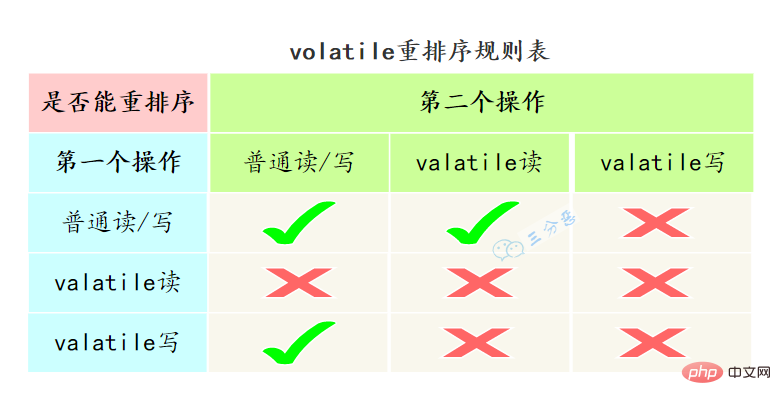
volatile怎么保证有序性的呢?
重排序可以分为编译器重排序和处理器重排序,valatile保证有序性,就是通过分别限制这两种类型的重排序。
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
StoreStore屏障StoreLoad屏障LoadLoad屏障LoadStore屏障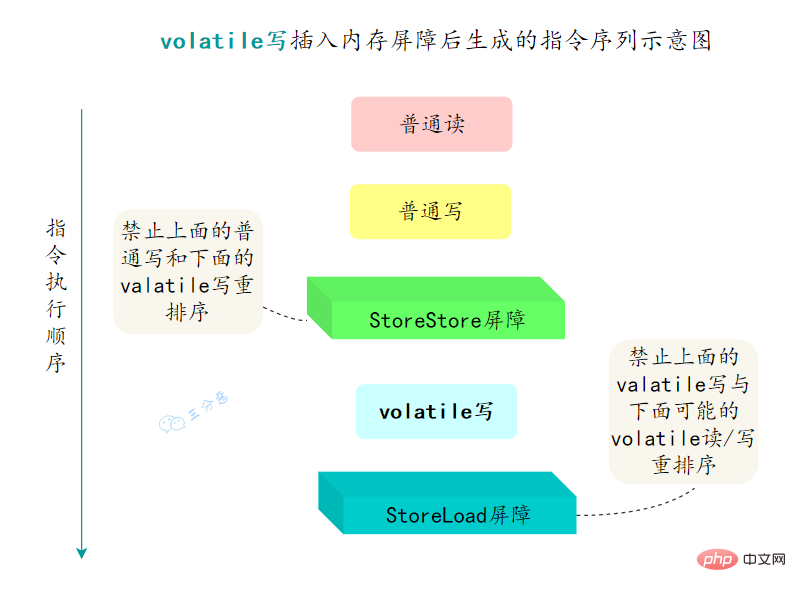
synchronized经常用的,用来保证代码的原子性。
synchronized主要有三种用法:
synchronized void method() {
//业务代码}修饰静态方法:也就是给当前类加锁,会作⽤于类的所有对象实例 ,进⼊同步代码前要获得当前 class 的锁。因为静态成员不属于任何⼀个实例对象,是类成员( static 表明这是该类的⼀个静态资源,不管 new 了多少个对象,只有⼀份)。
如果⼀个线程 A 调⽤⼀个实例对象的⾮静态 synchronized ⽅法,⽽线程 B 需要调⽤这个实例对象所属类的静态 synchronized ⽅法,是允许的,不会发⽣互斥现象,因为访问静态 synchronized ⽅法占⽤的锁是当前类的锁,⽽访问⾮静态 synchronized ⽅法占⽤的锁是当前实例对象锁。
synchronized void staic method() {
//业务代码}synchronized(this) {
//业务代码}synchronized是怎么加锁的呢?
我们使用synchronized的时候,发现不用自己去lock和unlock,是因为JVM帮我们把这个事情做了。
synchronized修饰代码块时,JVM采用monitorenter、monitorexit两个指令来实现同步,monitorenter 指令指向同步代码块的开始位置, monitorexit 指令则指向同步代码块的结束位置。
反编译一段synchronized修饰代码块代码,javap -c -s -v -l SynchronizedDemo.class,可以看到相应的字节码指令。
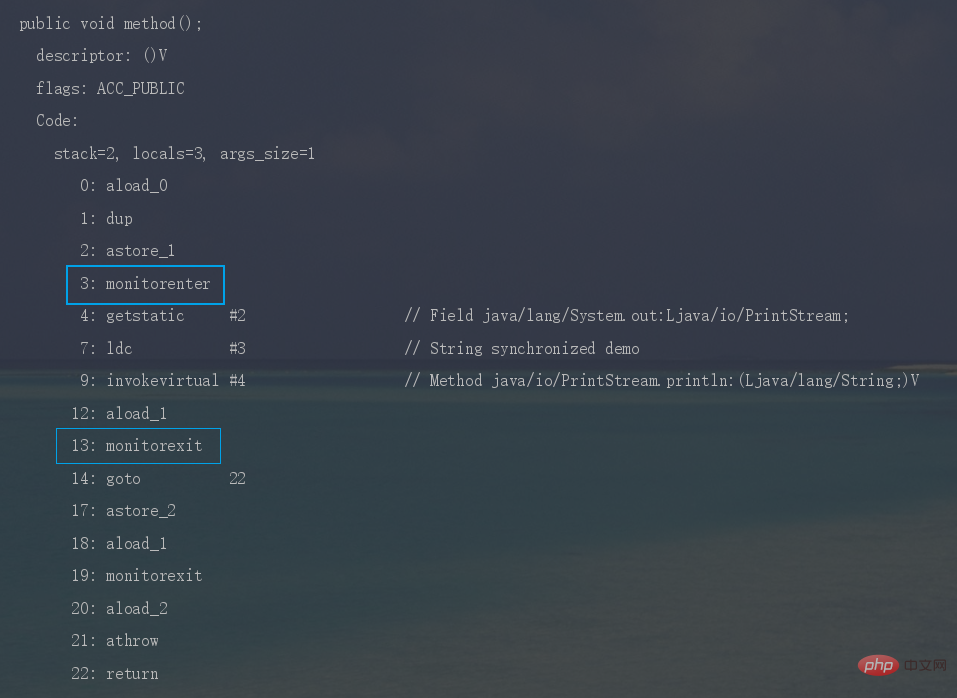
Java 同時実行に関するナレッジ ポイントを要約する时,JVM采用ACC_SYNCHRONIZED标记符来实现同步,这个标识指明了该方法是一个同步方法。
同样可以写段代码反编译看一下。
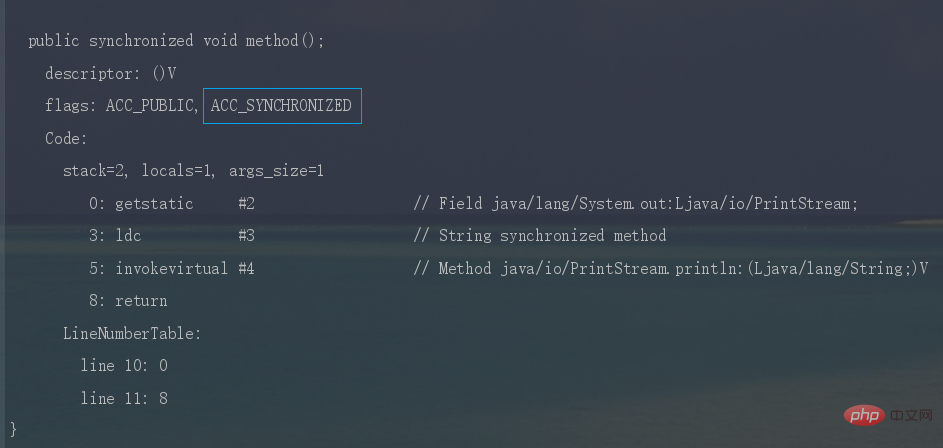
synchronized锁住的是什么呢?
monitorenter、monitorexit或者ACC_SYNCHRONIZED都是基于Monitor实现的。
实例对象结构里有对象头,对象头里面有一块结构叫Mark Word,Mark Word指针指向了monitor。
所谓的Monitor其实是一种同步工具,也可以说是一种同步机制。在Java虚拟机(HotSpot)中,Monitor是由ObjectMonitor实现的,可以叫做内部锁,或者Monitor锁。
ObjectMonitor的工作原理:
ObjectMonitor() {
_header = NULL;
_count = 0; // 记录线程获取锁的次数
_waiters = 0,
_recursions = 0; //锁的重入次数
_object = NULL;
_owner = NULL; // 指向持有ObjectMonitor对象的线程
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}可以类比一个去医院就诊的例子[18]:
首先,患者在门诊大厅前台或自助挂号机进行挂号;
随后,挂号结束后患者找到对应的诊室就诊:
就诊结束后,走出就诊室,候诊室的下一位候诊患者进入就诊室。
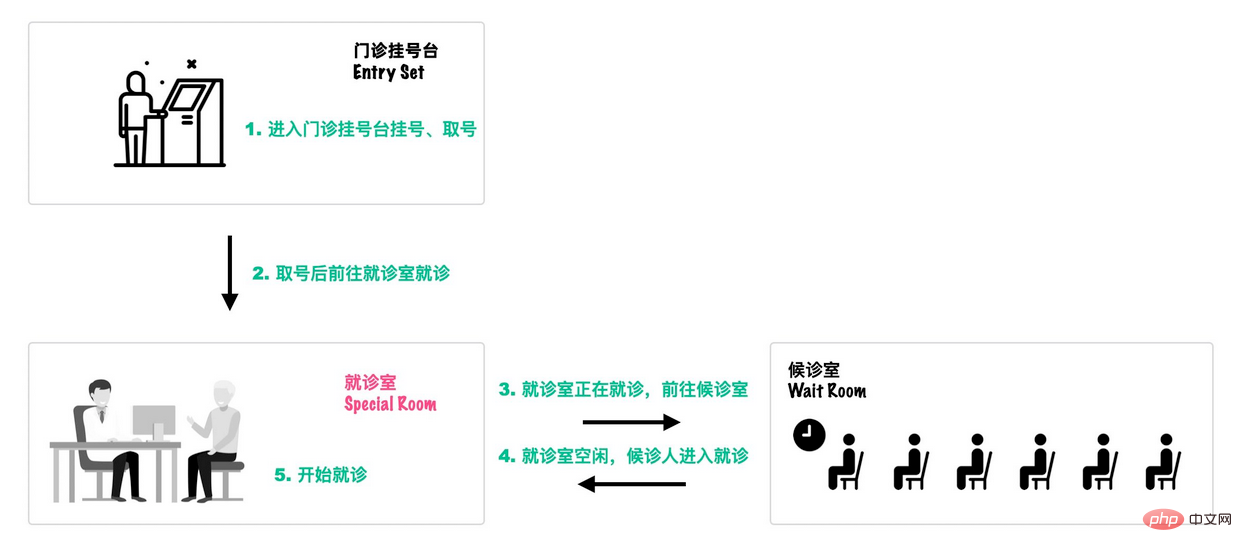
这个过程就和Monitor机制比较相似:
# から新しいスレッドが呼び出されます。 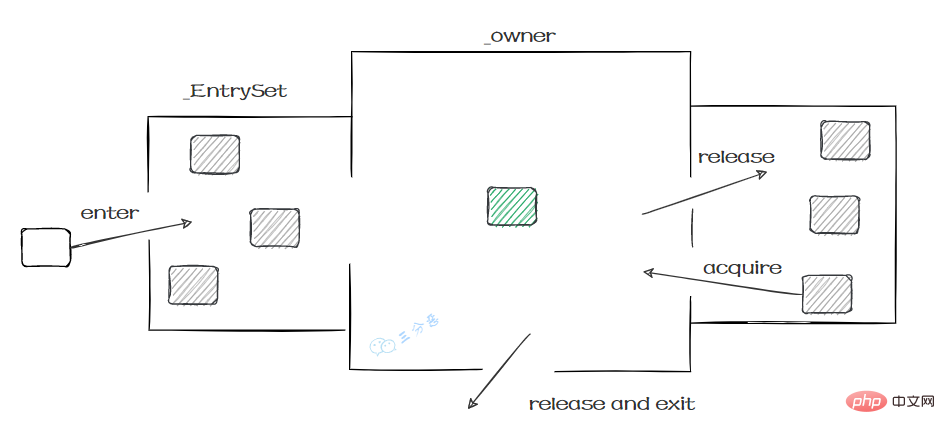
スレッドがロックされる前に、ワーキングメモリ内のシェア変数の値がクリアされるため、シェア変数を使用する場合は、メインスレッドから最新の値を再読み込みする必要があります。メモリ。
同期されたコード ブロックは排他的であり、一度に 1 つのスレッドのみが所有できるため、同期により、コードが 1 つのスレッドによって同時に実行されることが保証されます。
as-if-serial セマンティクスが存在するため、シングルスレッド プログラムでは最終結果が適切であることを保証できますが、命令が再配置されないという保証はありません。
したがって、synchronized によって保証される順序は実行結果の順序であり、命令の並べ替えを防ぐ順序ではありません。
同期はどのようにして再入可能を実現しますか?synchronized はリエントラント ロックです。つまり、スレッドは保持しているオブジェクト ロックのクリティカル リソースを 2 回要求できます。この状況はリエントラント ロックと呼ばれます。
synchronized オブジェクトをロックするときにカウンターがあります。スレッドがロックを取得した回数が記録されます。対応するコード ブロックが実行された後、カウンターがクリアされるまでカウンターは -1 になります。ロックが解除されます。
理由は、リエントラントであるためです。これは、同期ロック オブジェクトにはカウンターがあり、スレッドがロックを取得した後は 1 ずつカウントされ、スレッドが実行を完了すると、ロックが解除されてロックが解放されるまで -1 ずつカウントされるためです。
27. ロックのアップグレード?同期最適化について理解していますか?
Java オブジェクトのヘッダーには、
Mark Word マーク フィールドという構造があり、ロック状態の変化に応じてこの構造も変化します。 64 ビット仮想マシン Mark Word は 64 ビットです。ステータスの変化を見てみましょう:
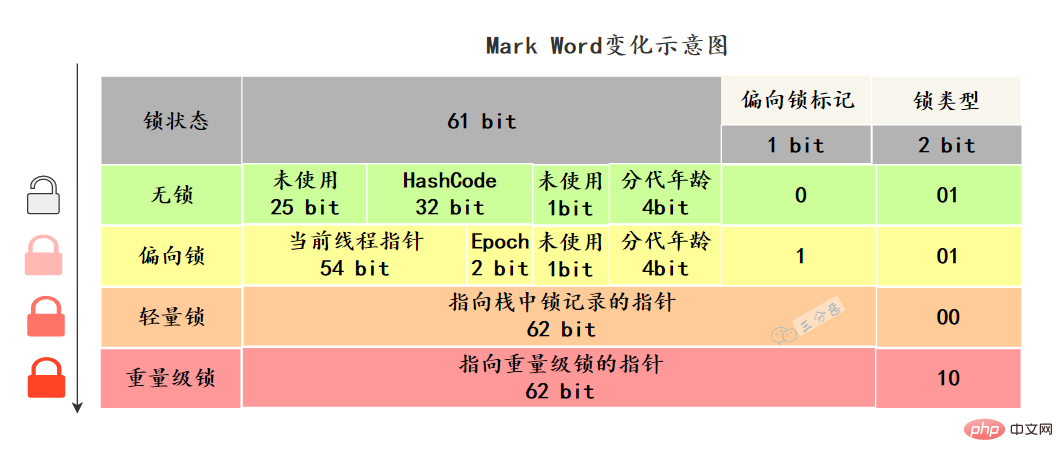 Mark Word はオブジェクトの実行データを保存します
Mark Word はオブジェクトの実行データを保存します
など、それ自体。
同期ではどのような最適化が行われましたか?JDK1.6 より前では、synchronized の実装は ObjectMonitor の開始と終了を直接呼び出していました。この種のロックはHeavyweight lock
と呼ばれていました。 JDK6 以降、HotSpot 仮想マシン開発チームは、同期のパフォーマンスを向上させるために、適応スピン、ロックの削除、ロックの粗密化、軽量ロック、バイアスされたロックなどの最適化戦略を追加するなど、Java でロックを最適化しました。
ロックのアップグレード方向: ロックなし –> バイアス ロック –> 軽量ロック –> 重量ロック。この方向は基本的に元に戻すことはできません。
 アップグレード プロセスを見てみましょう:
アップグレード プロセスを見てみましょう:
バイアス ロック:
バイアス ロックの取得: バイアスされたロックの取り消し: 軽量ロックの取得: AbstractQueuedSynchronizer 抽象同期キュー (AQS と呼ばれる) は、Java 同時実行パッケージの基盤です。同時実行パッケージ内のロックは、AQS に基づいて実装されます。 AQS 中的队列是 CLH 变体的虚拟双向队列,通过将每条请求共享资源的线程封装成一个节点来实现锁的分配: AQS 中的 CLH 变体等待队列拥有以下特性: ps:AQS源码里面有很多细节可问,建议有时间好好看看AQS源码。 ReentrantLock 是可重入的独占锁,只能有一个线程可以获取该锁,其它获取该锁的线程会被阻塞而被放入该锁的阻塞队列里面。 看看ReentrantLock的加锁操作: 公平锁 FairSync 非公平锁 NonfairSync 默认创建的对象lock()的时候: 同时也可以在创建锁构造函数中传入具体参数创建公平锁 FairSync FairSync、NonfairSync 代表公平锁和非公平锁,两者都是 ReentrantLock 静态内部类,只不过实现不同锁语义。 非公平锁和公平锁的两处不同: # 相対的に言えば、不公平なロックはスループットが比較的大きいため、パフォーマンスが向上します。もちろん、不公平なロックにより、ロックを取得する時間がより不確実になり、ブロッキング キュー内のスレッドが長時間にわたって枯渇する可能性があります。 CAS は CompareAndSwap と呼ばれ、比較と交換を行います。主にプロセッサ命令を使用して操作のアトミック性を確保します。 CAS 命令には、共有変数のメモリ アドレス A、期待値 B、共有変数の新しい値 C の 3 つのパラメータが含まれています。 メモリのアドレス A の値が B に等しい場合にのみ、メモリのアドレス A の値を新しい値 C に更新できます。 CAS 命令自体は CPU 命令としてアトミック性を保証できます。 CAS の 3 つの古典的な問題: 同時環境では、初期条件が A であると仮定すると、データを変更し、A であることが判明した場合、変更が実行されます。しかし、あなたが見ているのは A ですが、A が B に変化し、B が再び A に戻った可能性があります。この時点で、A はもう一方の A ではなくなります。データの変更が成功した場合でも、問題が発生する可能性があります。 ABA 問題を解決するにはどうすればよいですか? 変数が変更されるたびに、変数のバージョン番号に 1 が追加されます。このように、A-> だけです。 ;B->A の場合、A の値は変わっていないのに、バージョン番号が変わっているので、もう一度バージョン番号を判定すると、この時点で A が変わっていることがわかります。オプティミスティック ロックのバージョン番号を参照するこのアプローチにより、データに実際的なテストを行うことができます。 Java は AtomicStampReference クラスを提供します。その CompareAndSet メソッドは、まず現在のオブジェクト参照値が予期される参照と等しいかどうか、および現在のスタンプ (Stamp) フラグが予期されるフラグと等しいかどうかをチェックします。すべてが等しい場合, アトミックに 参照値とスタンプ値が指定された更新値に更新されます。 Spin CAS がループ内で実行されても成功しない場合、CPU に非常に大きな実行オーバーヘッドが生じます。 ループ パフォーマンスのオーバーヘッド問題を解決するにはどうすればよいですか? Java では、スピン CAS を使用する多くの場所でスピン数に制限があり、一定の数を超えるとスピンが停止します。 CAS は、変数に対する操作のアトミック性を保証します。複数の変数が操作される場合、CAS は現在、操作のアトミック性を直接保証できません。の。 1 つの変数しか保証できないアトミック操作の問題を解決するにはどうすればよいでしょうか? プログラムが変数を更新する際、複数のスレッドが同時に変数を更新すると、例えば変数i=1、スレッドAがi 1を更新し、スレッドBも更新すると予期せぬ値が得られる可能性があります。 i を 1 に更新します。 2 つ後 スレッド操作の後、i は 3 に等しくない場合がありますが、2 に等しくなります。スレッド A と B は変数 i を更新するときに両方とも 1 を取得するため、これはスレッド安全でない更新操作です。一般に、この問題を解決するには synchronized を使用します。Synchronized を使用すると、複数のスレッドが変数 i を同時に更新することがなくなります。 実際には、これに加えて、さらに軽量なオプションがあります。Java は、JDK 1.5 から java.util.concurrent.atomic パッケージを提供しています。このパッケージのアトミック操作クラスは、簡単な使用法とパフォーマンスを提供します。 - 変数を更新するための効率的でスレッドセーフな方法。 変数の種類が多いため、Atomic パッケージでは、アトミック更新基本型、アトミック更新配列、アトミック更新参照、アトミック更新リファレンスの 4 種類のアトミック更新メソッドに属する合計 13 個のクラスが提供されています。プロパティ (フィールド) のアトミック更新。 #Atomic パッケージ内のクラスは、基本的に Unsafe を使用して実装されたラッパー クラスです。 使用原子的方式更新基本类型,Atomic包提供了以下3个类: AtomicBoolean:原子更新布尔类型。 AtomicInteger:原子更新整型。 AtomicLong:原子更新长整型。 通过原子的方式更新数组里的某个元素,Atomic包提供了以下4个类: AtomicIntegerArray:原子更新整型数组里的元素。 AtomicLongArray:原子更新长整型数组里的元素。 AtomicReferenceArray:原子更新引用类型数组里的元素。 AtomicIntegerArray类主要是提供原子的方式更新数组里的整型 原子更新基本类型的AtomicInteger,只能更新一个变量,如果要原子更新多个变量,就需要使用这个原子更新引用类型提供的类。Atomic包提供了以下3个类: AtomicReference:原子更新引用类型。 AtomicReferenceFieldUpdater:原子更新引用类型里的字段。 AtomicMarkableReference:原子更新带有标记位的引用类型。可以原子更新一个布尔类型的标记位和引用类型。构造方法是AtomicMarkableReference(V initialRef,boolean initialMark)。 如果需原子地更新某个类里的某个字段时,就需要使用原子更新字段类,Atomic包提供了以下3个类进行原子字段更新: 一句话概括:使用CAS实现。 以AtomicInteger的添加方法为例: 通过 compareAndSwapInt 是一个native方法,基于CAS来操作int类型变量。其它的Java 同時実行に関するナレッジ ポイントを要約する基本都是大同小异。 死锁是指两个或两个以上的线程在执行过程中,因争夺资源而造成的互相等待的现象,在无外力作用的情况下,这些线程会一直相互等待而无法继续运行下去。 那么为什么会产生死锁呢? 死锁的产生必须具备以下四个条件: 该如何避免死锁呢?答案是至少破坏死锁发生的一个条件。 其中,互斥这个条件我们没有办法破坏,因为用锁为的就是互斥。不过其他三个条件都是有办法破坏掉的,到底如何做呢? 对于“请求并持有”这个条件,可以一次性请求所有的资源。 对于“不可剥夺”这个条件,占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源,这样不可抢占这个条件就破坏掉了。 对于“环路等待”这个条件,可以靠按序申请资源来预防。所谓按序申请,是指资源是有线性顺序的,申请的时候可以先申请资源序号小的,再申请资源序号大的,这样线性化后就不存在环路了。 可以使用jdk自带的命令行工具排查: 基本就可以看到死锁的信息。 还可以利用图形化工具,比如JConsole。出现线程死锁以后,点击JConsole线程面板的 CountDownLatch,倒计数器,有两个常见的应用场景[18]: 场景1:协调子线程结束动作:等待所有子线程运行结束 CountDownLatch允许一个或多个线程等待其他线程完成操作。 例如,我们很多人喜欢玩的王者荣耀,开黑的时候,得等所有人都上线之后,才能开打。 CountDownLatch模仿这个场景(参考[18]): 创建大乔、兰陵王、安其拉、哪吒和铠等五个玩家,主线程必须在他们都完成确认后,才可以继续运行。 在这段代码中, 场景2. 协调子线程开始动作:统一各线程动作开始的时机 王者游戏中也有类似的场景,游戏开始时,各玩家的初始状态必须一致。不能有的玩家都出完装了,有的才降生。 所以大家得一块出生,在 在这个场景中,仍然用五个线程代表大乔、兰陵王、安其拉、哪吒和铠等五个玩家。需要注意的是,各玩家虽然都调用了 CountDownLatch的核心方法也不多: CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一 组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。 它和CountDownLatch类似,都可以协调多线程的结束动作,在它们结束后都可以执行特定动作,但是为什么要有CyclicBarrier,自然是它有和CountDownLatch不同的地方。 不知道你听没听过一个新人UP主小约翰可汗,小约翰生平有两大恨——“Java 同時実行に関するナレッジ ポイントを要約する”我们来还原一下事情的经过:小约翰在亲政后认识了新垣结衣,于是决定第一次选妃,向结衣表白,等待回应。然而新垣结衣回应嫁给了星野源,小约翰伤心欲绝,发誓生平不娶,突然发现了铃木爱理,于是小约翰决定第二次选妃,求爱理搭理,等待回应。 我们拿代码模拟这一场景,发现CountDownLatch无能为力了,因为CountDownLatch的使用是一次性的,无法重复利用,而这里等待了两次。此时,我们用CyclicBarrier就可以实现,因为它可以重复利用。 Java 同時実行に関するナレッジ ポイントを要約する: CyclicBarrier最最核心的方法,仍然是await(): 上面的例子抽象一下,本质上它的流程就是这样就是这样: 两者最核心的区别[18]: それらの違いは表にまとめられています: Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。 听起来似乎很抽象,现在汽车多了,开车出门在外的一个老大难问题就是停车 。停车场的车位是有限的,只能允许若干车辆停泊,如果停车场还有空位,那么显示牌显示的就是绿灯和剩余的车位,车辆就可以驶入;如果停车场没位了,那么显示牌显示的就是绿灯和数字0,车辆就得等待。如果满了的停车场有车离开,那么显示牌就又变绿,显示空车位数量,等待的车辆就能进停车场。 我们把这个例子类比一下,车辆就是线程,进入停车场就是线程在执行,离开停车场就是线程执行完毕,看见红灯就表示线程被阻塞,不能执行,Semaphore的本质就是协调多个线程对共享资源的获取。 我们再来看一个Semaphore的用途:它可以用于做流量控制,特别是公用资源有限的应用场景,比如数据库连接。 假如有一个需求,要读取几万个文件的数据,因为都是IO密集型任务,我们可以启动几十个线程并发地读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这时我们必须控制只有10个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,就可以使用Semaphore来做流量控制,如下: 假如两个线程有一个没有执行exchange()方法,则会一直等待,如果担心有特殊情况发生,避免一直等待,可以使用 线程池: 简单理解,它就是一个Java 同時実行に関するナレッジ ポイントを要約する。 之前我们有一个和第三方对接的需求,需要向第三方推送数据,引入了多线程来提升数据推送的效率,其中用到了线程池来管理线程。 Java 同時実行に関するナレッジ ポイントを要約する如下: 完整可运行代码地址:https://gitee.com/fighter3/thread-demo.git 线程池的参数如下: corePoolSize:线程核心参数选择了CPU数×2 maximumPoolSize:最大线程数选择了和核心线程数相同 keepAliveTime:非核心闲置线程存活时间直接置为0 unit:非核心线程保持存活的时间选择了 TimeUnit.SECONDS 秒 workQueue:线程池等待队列,使用 LinkedBlockingQueue阻塞队列 同时还用了synchronized 来加锁,保证数据不会被重复推送: ps:这个例子只是简单地进行了数据推送,实际上还可以结合其他的业务,像什么数据清洗啊、数据统计啊,都可以套用。 用一个通俗的比喻: 有一个营业厅,总共有六个窗口,现在开放了三个窗口,现在有三个窗口坐着三个营业员小姐姐在营业。 老三去办业务,可能会遇到什么情况呢? 我们银行系统已经瘫痪 谁叫你来办的你找谁去 看你比较急,去队里加个塞 今天没办法,不行你看改一天 上面的这个流程几乎就跟 JDK 线程池的大致流程类似, 所以我们线程池的工作流程也比较好理解了: 当一个线程完成任务时,它会从队列中取下一个任务来执行。 当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。 线程池有七大参数,需要重点关注 此值是用来初始化线程池中核心线程数,当线程池中线程池数corePoolSize时,系统默认是添加一个任务才创建一个线程池。当线程数 = corePoolSize时,新任务会追加到workQueue中。 非核心线程 =(maximumPoolSize - corePoolSize ) ,非核心线程闲置下来不干活最多存活时间。 线程池中非核心线程保持存活的时间的单位 线程池等待队列,维护着等待执行的 创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。 类比前面的例子,无法办理业务时的处理方式,帮助记忆: 想实现自己的拒绝策略,实现RejectedExecutionHandler接口即可。 常用的阻塞队列主要有以下几种: 可以通过调用线程池的 shutdown() 将线程池状态置为shutdown,并不会立即停止: shutdownNow() 将线程池状态置为stop。一般会立即停止,事实上不一定: shutdown 和shutdownnow简单来说区别如下: 线程在Java中属于稀缺资源,线程池不是越大越好也不是越小越好。任务分为计算密集型、IO密集型、混合型。 一般的经验,不同类型线程池的参数配置: 当然,实际应用中没有固定的公式,需要结合测试和监控来进行调整。 面试常问,主要有四种,都是通过工具类Excutors创建出来的,需要注意,阿里巴巴《Java开发手册》里禁止使用这种方式来创建线程池。 newJava 同時実行に関するナレッジ ポイントを要約する (固定数目线程的线程池) newCachedThreadPool (可缓存线程的线程池) newSingleThreadExecutor (单线程的线程池) newScheduledThreadPool (定时及周期执行的线程池) 前三种线程池的构造直接调用ThreadPoolExecutor的构造方法。 线程池特点 工作流程: 适用场景 适用于串行执行任务的场景,一个任务一个任务地执行。 线程池特点: 工作流程: 使用场景 Java 同時実行に関するナレッジ ポイントを要約する 适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。 线程池特点: 当提交任务的速度大于处理任务的速度时,每次提交一个任务,就必然会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。 工作流程: 适用场景 用于并发执行大量短期的小任务。 线程池特点 工作机制 使用场景 周期性执行任务的场景,需要限制线程数量的场景 使用无界队列的线程池会导致什么问题吗? 例如newJava 同時実行に関するナレッジ ポイントを要約する使用了无界的阻塞队列LinkedBlockingQueue,如果线程获取一个任务后,任务的执行时间比较长,会导致队列的任务越积越多,导致机器内存使用不停飙升,最终导致OOM。 在使用线程池处理任务的时候,任务代码可能抛出RuntimeException,抛出异常后,线程池可能捕获它,也可能创建一个新的线程来代替异常的线程,我们可能无法感知任务出现了异常,因此我们需要考虑线程池异常情况。 常见的异常处理方式: 线程池有这几个状态:RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED。 SHUTDOWN STOP TIDYING TERMINATED 线程池提供了几个 setter方法来设置线程池的参数。 这里主要有两个思路: #マイクロサービス アーキテクチャでは、Nacos、Apollo などの構成センターを使用することも、独自の構成センターを開発することもできます。ビジネス サービスは、スレッド プール構成を読み取り、対応するスレッド プール インスタンスを取得して、スレッド プール パラメータを変更します。 構成センターの使用が制限されている場合は、ThreadPoolExecutor を自分で拡張し、メソッドを書き換え、スレッド プール パラメーターの変更を監視し、スレッド プールを動的に変更することもできます。パラメーター。 スレッド プールの構成には決まった計算式はありません。通常、スレッド プールは事前にある程度評価されます。一般的な評価スキームは次のとおりです。 その後は注意深く観察し、随時調整してください。 この質問は Alibaba のインタビューで頻繁に登場します キュー内で処理されてブロックされているタスクのトランザクション管理、またはブロックされたキュー内のタスクの永続化を行うことができます。また、停電やシステムクラッシュが発生して操作を続行できない場合、トレースバック ログ 正常に実行された 言い換えると、ブロッキング キューは永続化され、タスクのトランザクション制御が処理され、停電後にタスクのロールバックが処理され、ログを通じて操作が復元され、ブロッキング キュー内のデータはキューはサーバーの再起動後に再ロードされます。 一部の同時コンテナについては、 Work Stealing Algorithm 分割統治
作業盗用アルゴリズム その後、問題が発生します。一部のスレッドは激しく動作し、一部のスレッドはゆっくりと動作します。作業を終了したスレッドをアイドル状態のままにすることはできません。作業を終了していないスレッドの作業を許可する必要があります。他のスレッドのキューからタスクを盗んで実行する、いわゆる ワークスチール
Fork/Join フレームワーク アプリケーションの例を見て、1 ~ n の間の合計を計算します: 1 2 3 … n ForkJoinTask与一般Task的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果比较大,就必须分割成两个子任务,每个子任务在调用fork方法时,又会进compute方法,看看当前子任务是否需要继续分割成子任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。 推荐学习:《java教程》
軽量ロック:
ロック操作を実行するとき、JVM は重量ロックが取得されたかどうかを判断します。そうでない場合、現在のスレッド スタック フレームにロックのロック レコードとしてスペースが描画され、ロック オブジェクトは MarkWord がロック レコードにコピーされます
一般的に簡略化されたアップグレード プロセス:
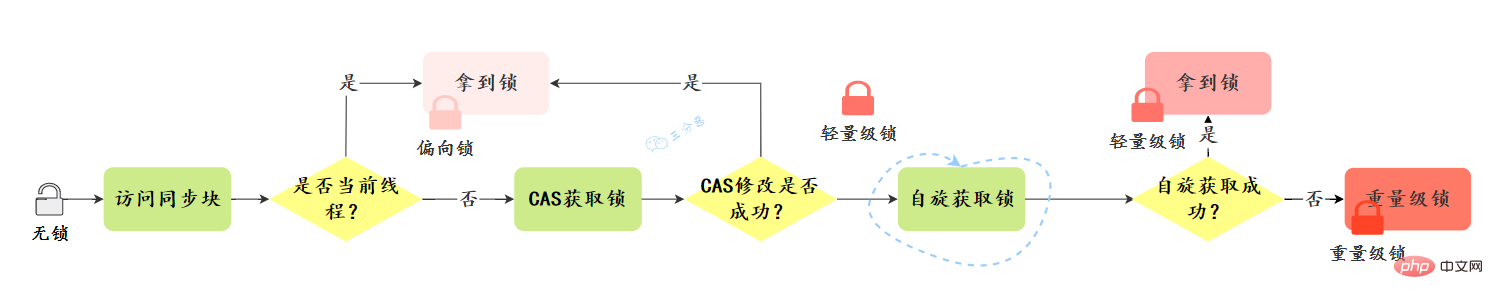
![synchronized 锁升级过程-来源参考[14]](https://img.php.cn/upload/article/000/000/067/2ef068e2d2216314dc9ad545dda17019-36.png)
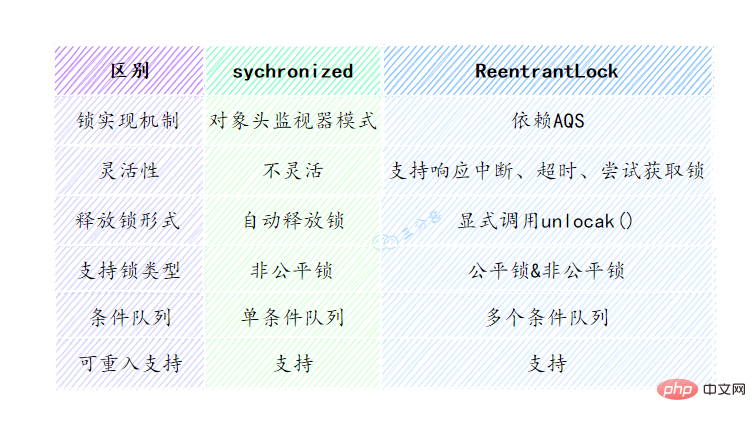
次の表に、2 つのロックの違いを示します:
ReentrantLock は、ロックを待機しているスレッドに割り込むことができるメカニズムを提供します。このメカニズムは、lock.lockInterruptibly() によって実装されます。
29. AQS についてどのくらい知っていますか? ?
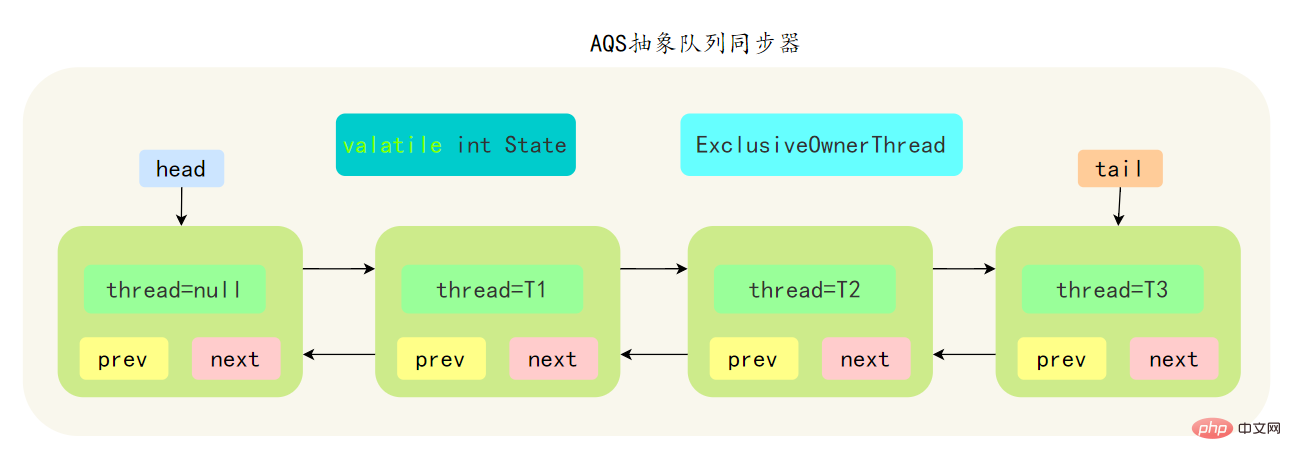 先简单了解一下CLH:Craig、Landin and Hagersten 队列,是 单向链表实现的队列。申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现 前驱节点释放了锁就结束自旋
先简单了解一下CLH:Craig、Landin and Hagersten 队列,是 单向链表实现的队列。申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现 前驱节点释放了锁就结束自旋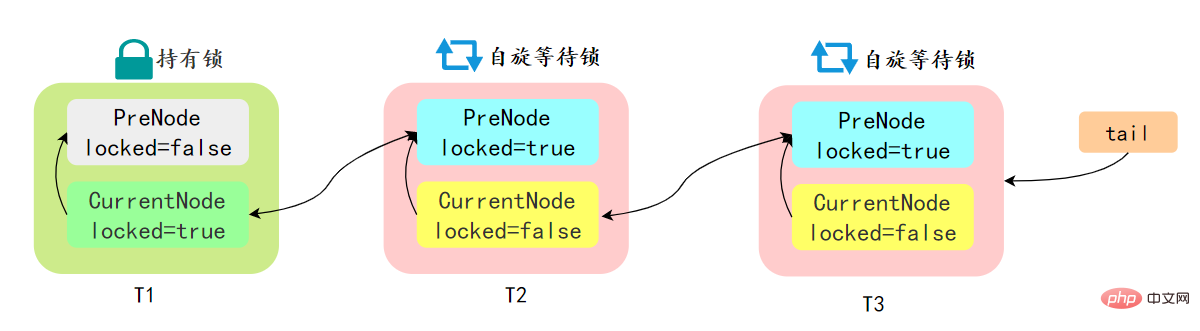
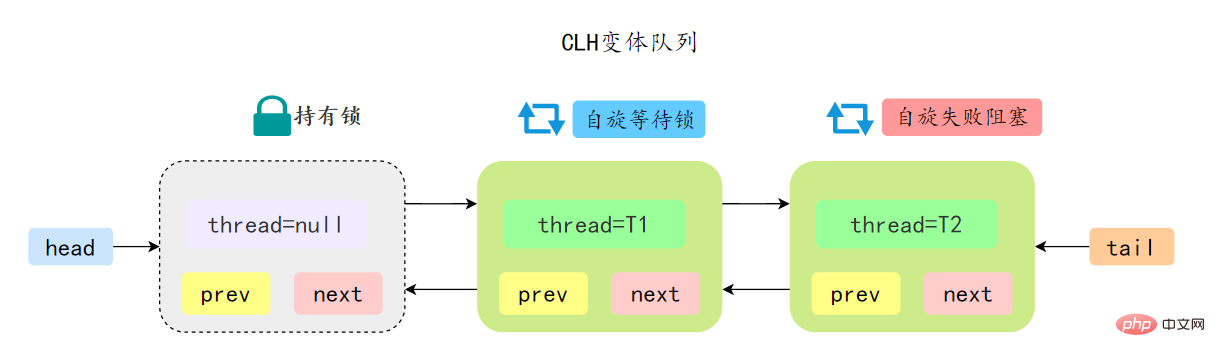
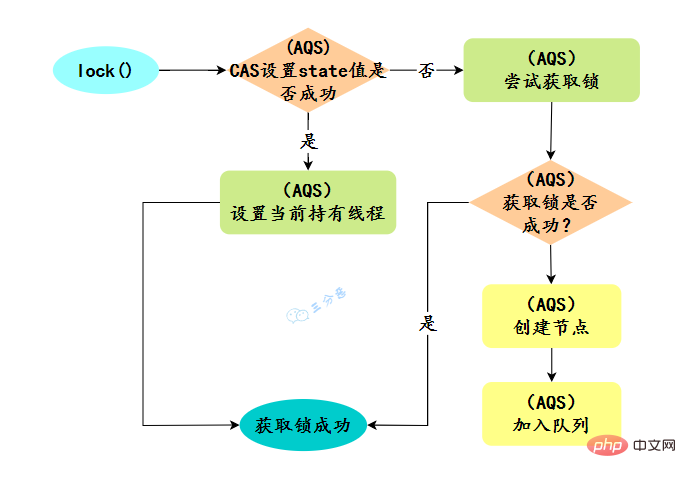
30.ReentrantLock实现原理?
// 创建非公平锁
ReentrantLock lock = new ReentrantLock();
// 获取锁操作
lock.lock();
try {
// 执行代码逻辑
} catch (Exception ex) {
// ...
} finally {
// 解锁操作
lock.unlock();
}new ReentrantLock()构造函数默认创建的是非公平锁 NonfairSync。
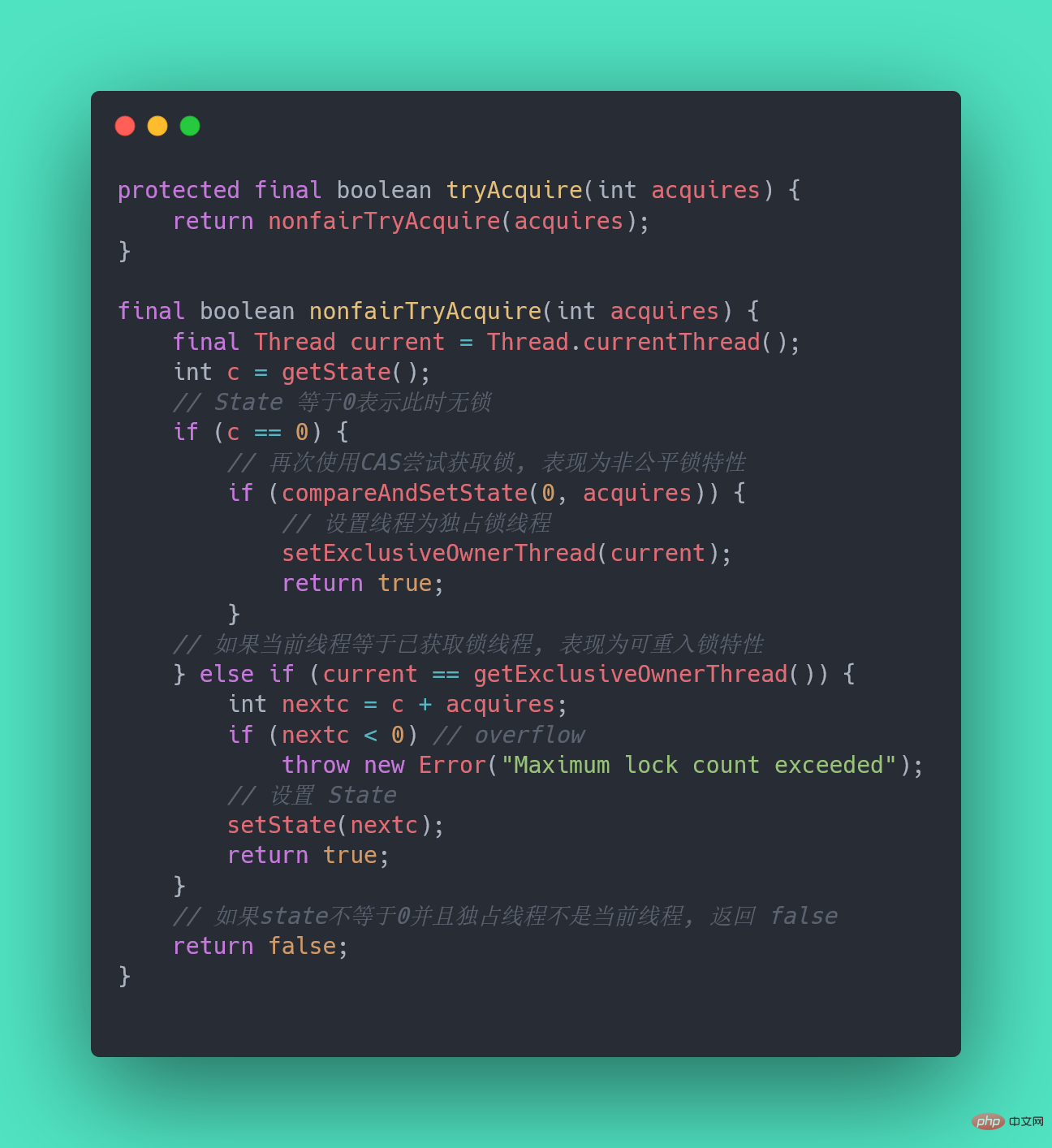
31.ReentrantLock怎么实现公平锁的?
new ReentrantLock()构造函数默认创建的是非公平锁 NonfairSyncpublic ReentrantLock() {
sync = new NonfairSync();}ReentrantLock lock = new ReentrantLock(true);--- ReentrantLock// true 代表公平锁,false 代表非公平锁public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();}
32.CASについてはどうですか? CASは何を知っているのでしょうか?
33.CAS の何が問題なのでしょうか?の解き方?
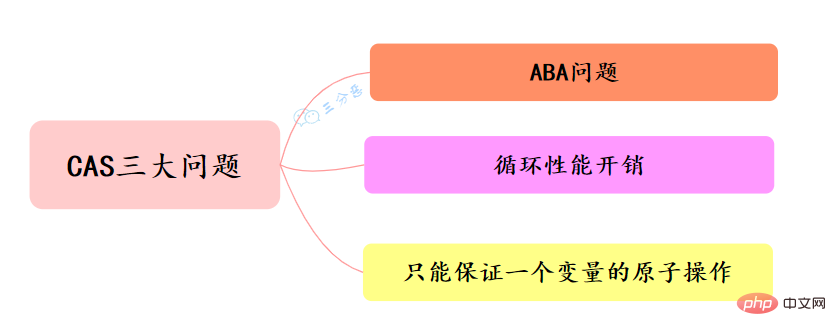
ABA 問題
ループ パフォーマンス オーバーヘッド
1 つの変数のアトミック操作のみを保証できます
34.Java でアトミック性を確保する方法は何ですか?マルチスレッド下で i の結果が正しいことを確認するにはどうすればよいですか?
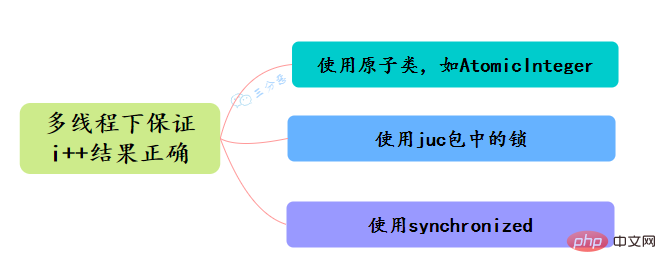
35. アトミック操作クラスについてどれくらい知っていますか?
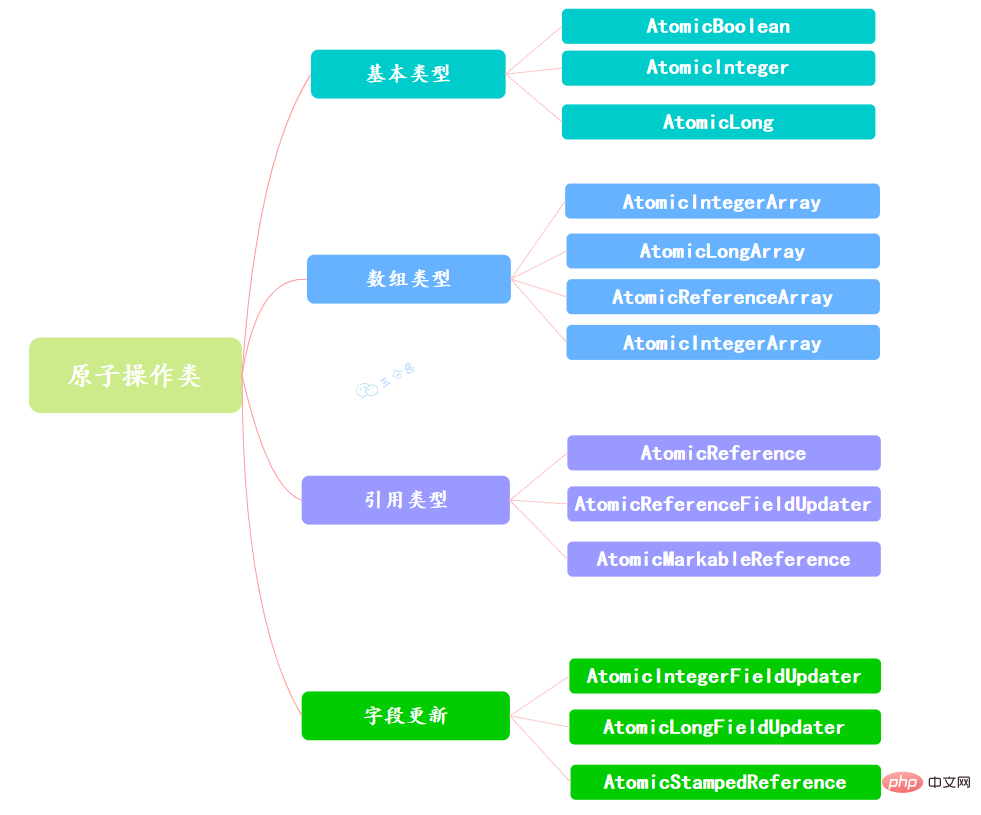
36.AtomicInteger 的原理?
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}Unsafe类的实例来进行添加操作,来看看具体的CAS操作: public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}37.线程死锁了解吗?该如何避免?
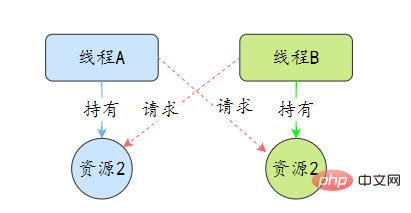
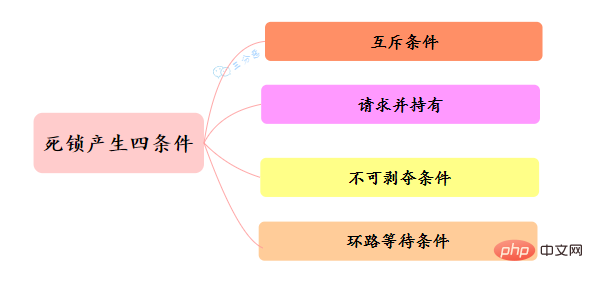
38.那死锁问题怎么排查呢?
检测到死锁按钮,将会看到线程的死锁信息。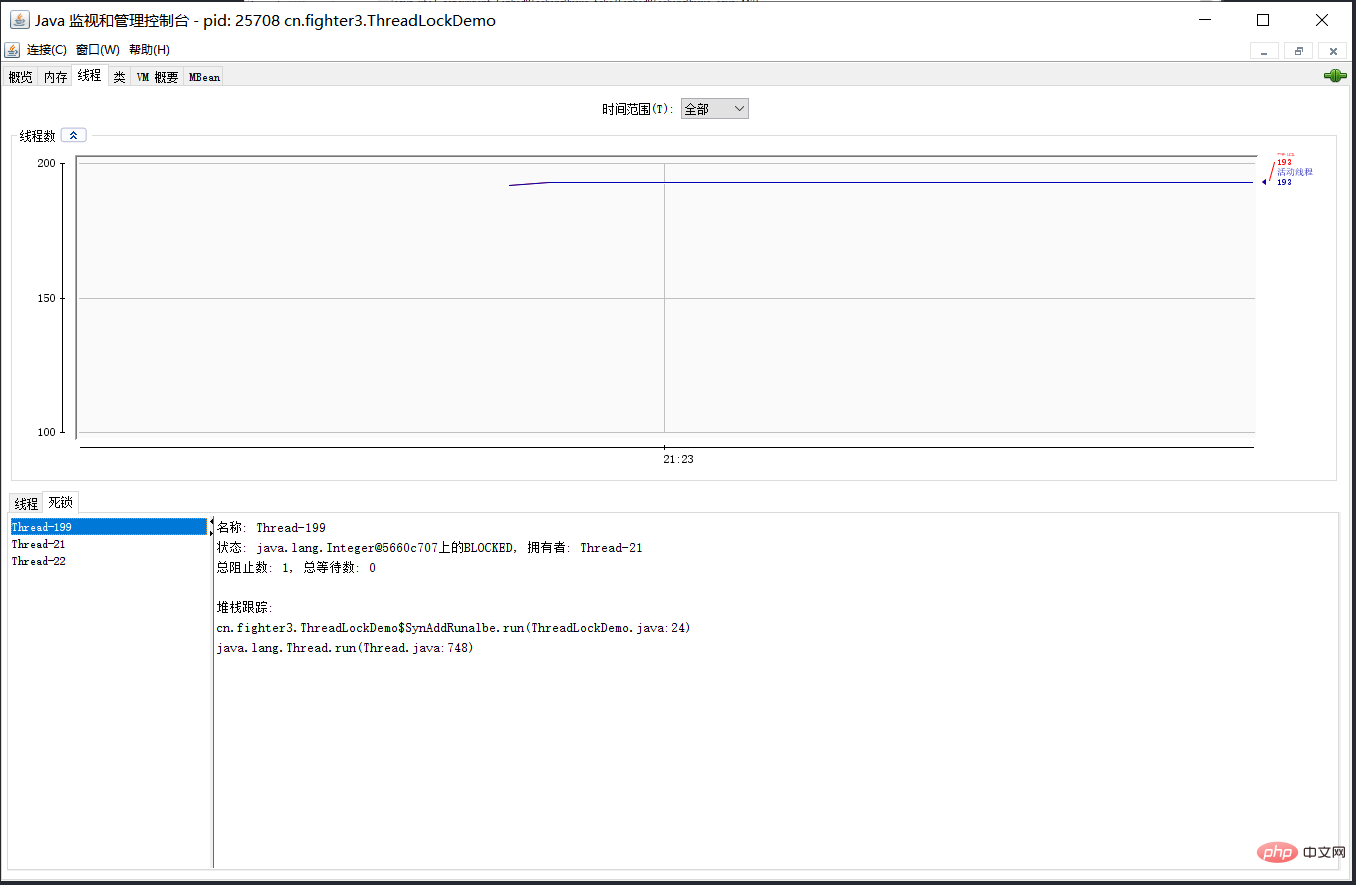
39.CountDownLatch(倒计数器)了解吗?
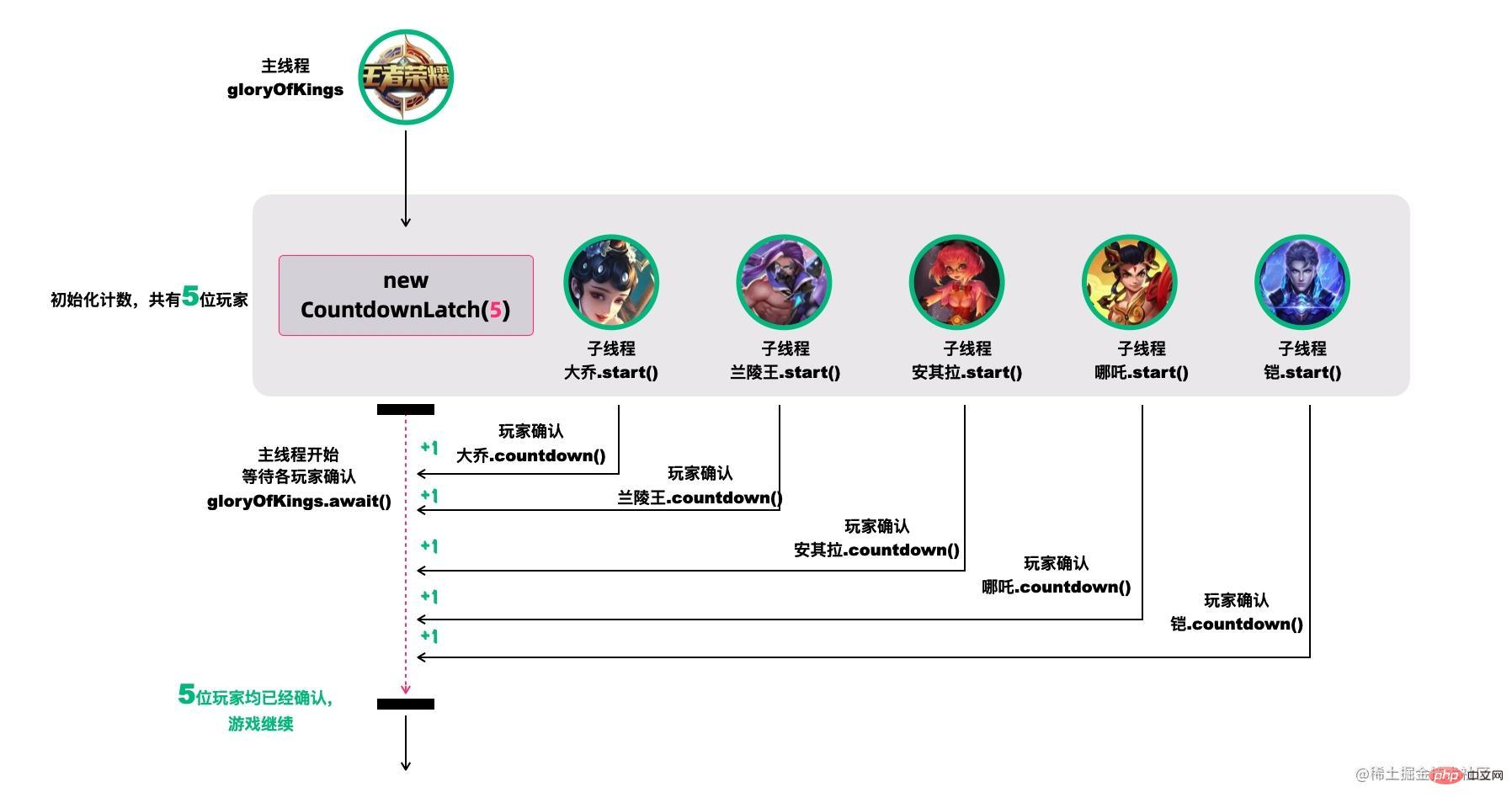
new CountDownLatch(5)用户创建初始的latch数量,各玩家通过countDownLatch.countDown()完成状态确认,主线程通过countDownLatch.await()等待。 public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(5);
Thread 大乔 = new Thread(countDownLatch::countDown);
Thread 兰陵王 = new Thread(countDownLatch::countDown);
Thread 安其拉 = new Thread(countDownLatch::countDown);
Thread 哪吒 = new Thread(countDownLatch::countDown);
Thread 铠 = new Thread(() -> {
try {
// 稍等,上个卫生间,马上到...
Thread.sleep(1500);
countDownLatch.countDown();
} catch (InterruptedException ignored) {}
});
大乔.start();
兰陵王.start();
安其拉.start();
哪吒.start();
铠.start();
countDownLatch.await();
System.out.println("所有玩家已经就位!");
}
start()线程,但是它们在运行时都在等待countDownLatch的信号,在信号未收到前,它们不会往下执行。 public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(1);
Thread 大乔 = new Thread(() -> waitToFight(countDownLatch));
Thread 兰陵王 = new Thread(() -> waitToFight(countDownLatch));
Thread 安其拉 = new Thread(() -> waitToFight(countDownLatch));
Thread 哪吒 = new Thread(() -> waitToFight(countDownLatch));
Thread 铠 = new Thread(() -> waitToFight(countDownLatch));
大乔.start();
兰陵王.start();
安其拉.start();
哪吒.start();
铠.start();
Thread.sleep(1000);
countDownLatch.countDown();
System.out.println("敌方还有5秒达到战场,全军出击!");
}
private static void waitToFight(CountDownLatch countDownLatch) {
try {
countDownLatch.await(); // 在此等待信号再继续
System.out.println("收到,发起进攻!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
await():等待latch降为0;boolean await(long timeout, TimeUnit unit):等待latch降为0,但是可以设置超时时间。比如有玩家超时未确认,那就重新匹配,总不能为了某个玩家等到天荒地老。countDown():latch数量减1;getCount():获取当前的latch数量。40.CyclicBarrier(同步屏障)了解吗?

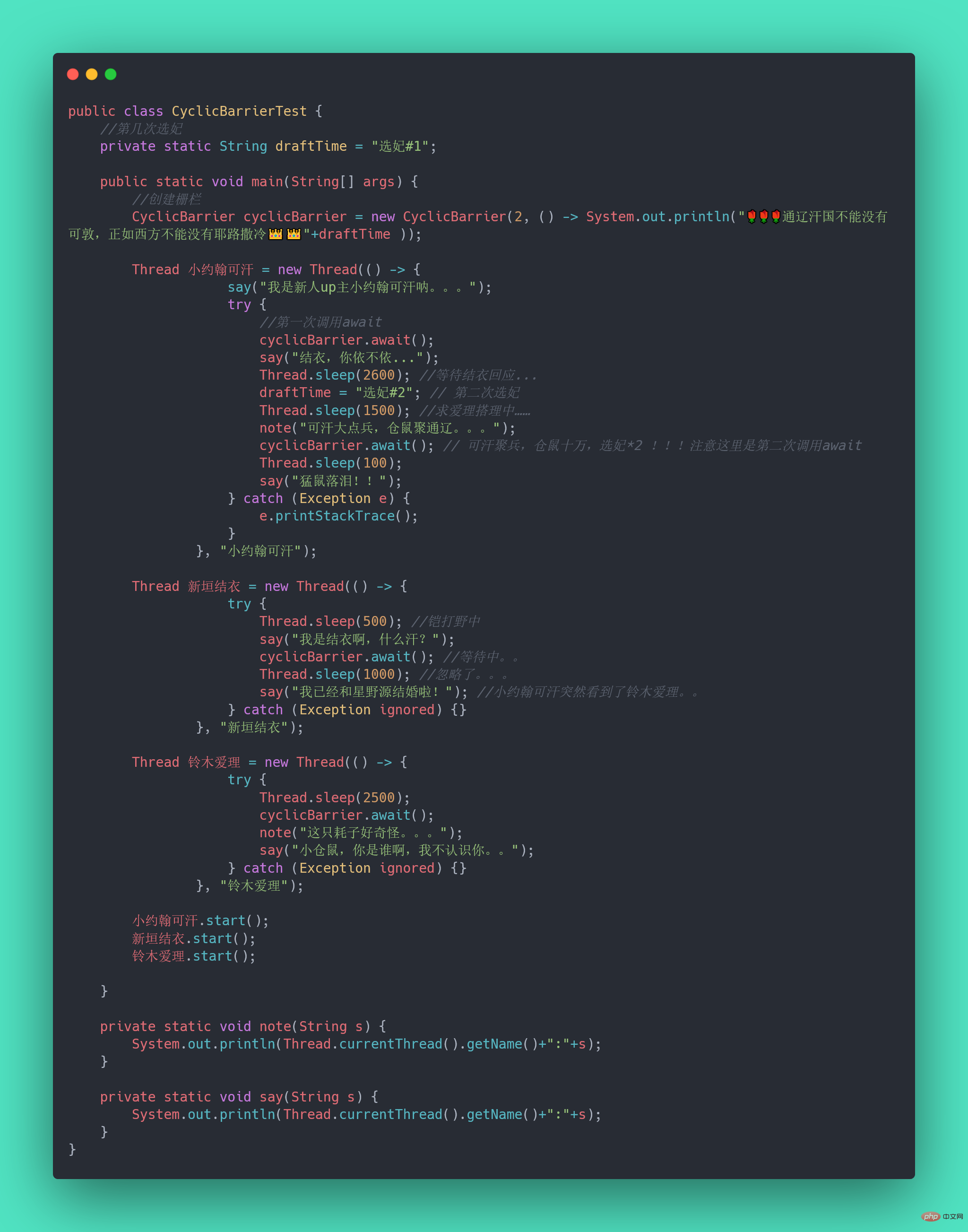

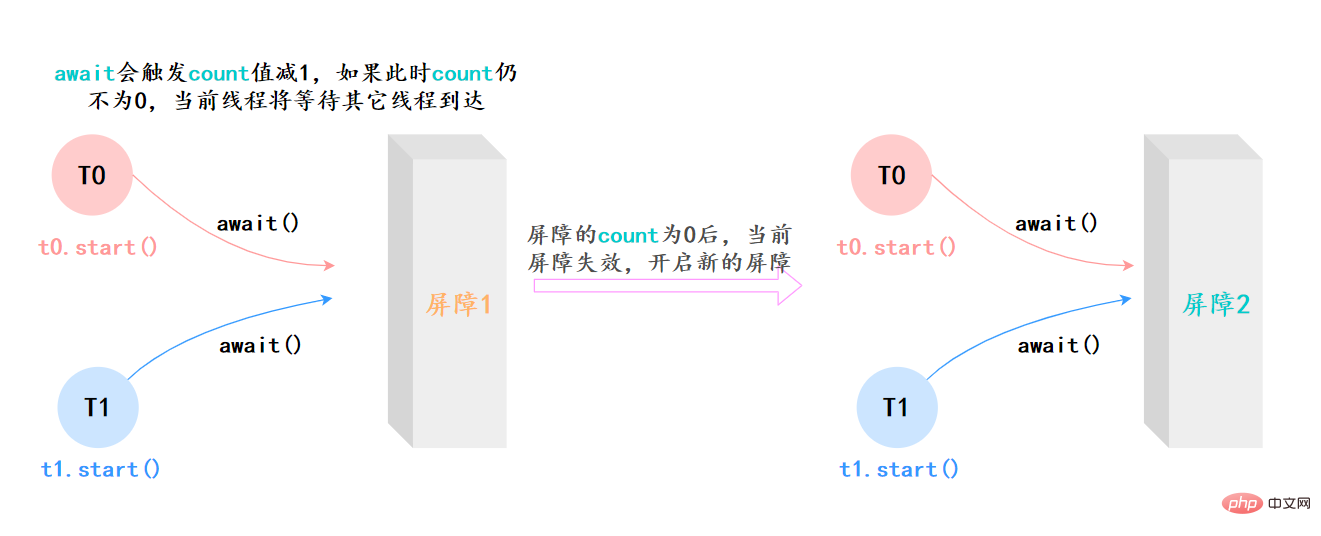
41.CyclicBarrier和CountDownLatch有什么区别?
CyclicBarrier
CountDownLatch
CyclicBarrier は再利用可能であり、その中のスレッドはすべてのスレッドがタスクを完了するまで待機します。その際、バリアは解除され、特定のアクションを選択的に実行できるようになります。
CountDownLatch は 1 回限りで、カウンタが 0 になるまで異なるスレッドが同じカウンタ上で動作します。
CyclicBarrier はスレッドの数を対象とします
CountDownLatch はタスクの数を重視します
CyclicBarrier を使用する場合は、構築でコラボレーションに参加するスレッドの数を指定する必要があり、これらのスレッドは await() メソッドを呼び出す必要があります。
CountDownLatch を使用するときは、タスクの数を指定する必要があります。どのスレッドがこれらのタスクを完了するかは関係ありません。
CyclicBarrier は、すべてのスレッドが解放された後に再利用できます
CountDownLatch カウンタが 0 になると使用できなくなります。
##CyclicBarrier では、スレッドが割り込みやタイムアウトなどに遭遇すると、スレッドは待機状態になります。問題が発生します
CountDownLatch では、1 つのスレッドで問題が発生しても、他のスレッドは影響を受けません
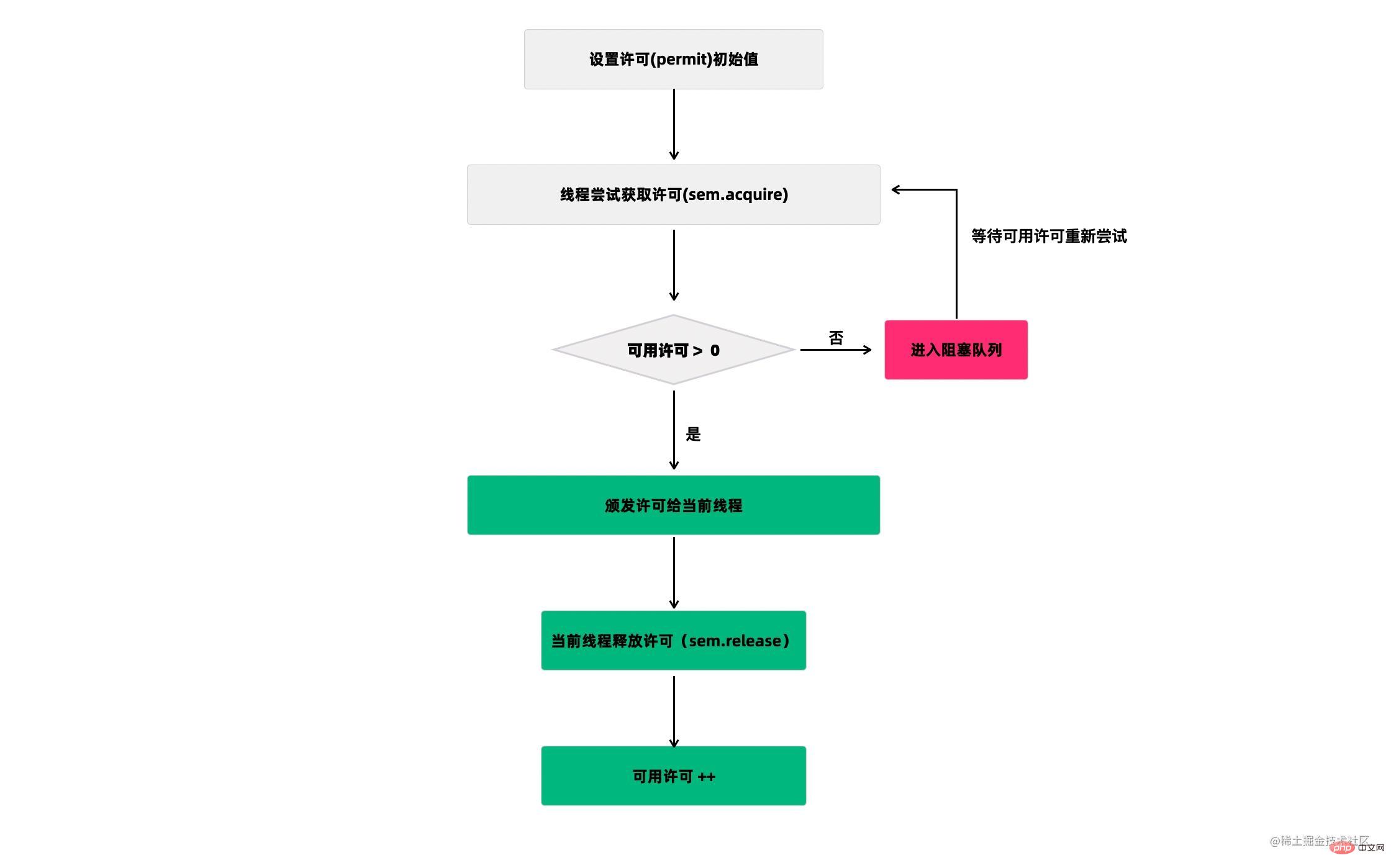
42.Semaphore(信号量)了解吗?

public class SemaphoreTest {
private static final int THREAD_COUNT = 30;
private static ExecutorService threadPool = Executors.newJava 同時実行に関するナレッジ ポイントを要約する(THREAD_COUNT);
private static Semaphore s = new Semaphore(10);
public static void main(String[] args) {
for (int i = 0; i <p>在代码中,虽然有30个线程在执行,但是只允许10个并发执行。Semaphore的构造方法<code>Semaphore(int permits</code>)接受一个整型的数字,表示可用的许可证数量。<code>Semaphore(10)</code>表示允许10个线程获取许可证,也就是最大并发数是10。Semaphore的用法也很简单,首先线程使用 Semaphore的acquire()方法获取一个许可证,使用完之后调用release()方法归还许可证。还可以用tryAcquire()方法尝试获取许可证。</p><h2>43.Exchanger 了解吗?</h2><p>Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger用于进行线程间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。</p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/a99f1f171b5f8c414e2981e6a7d5189a-57.png" class="lazy" alt="Java 同時実行に関するナレッジ ポイントを要約する"></p><p>这两个线程通过 exchange方法交换数据,如果第一个线程先执行exchange()方法,它会一直等待第二个线程也执行exchange方法,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。</p><p>Exchanger可以用于遗传算法,遗传算法里需要选出两个人作为交配对象,这时候会交换两人的数据,并使用交叉规则得出2个交配结果。Exchanger也可以用于校对工作,比如我们需要将纸制银行流水通过人工的方式录入成电子银行流水,为了避免错误,采用AB岗两人进行录入,录入到Excel之后,系统需要加载这两个Excel,并对两个Excel数据进行校对,看看是否录入一致。</p><pre class="brush:php;toolbar:false">public class ExchangerTest {
private static final Exchanger<string> exgr = new Exchanger<string>();
private static ExecutorService threadPool = Executors.newJava 同時実行に関するナレッジ ポイントを要約する(2);
public static void main(String[] args) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
String A = "银行流水A"; // A录入银行流水数据
exgr.exchange(A);
} catch (InterruptedException e) {
}
}
});
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
String B = "银行流水B"; // B录入银行流水数据
String A = exgr.exchange("B");
System.out.println("A和B数据是否一致:" + A.equals(B) + ",A录入的是:"
+ A + ",B录入是:" + B);
} catch (InterruptedException e) {
}
}
});
threadPool.shutdown();
}}</string></string>exchange(V x, long timeOut, TimeUnit unit)设置最大等待时长44.什么是线程池?
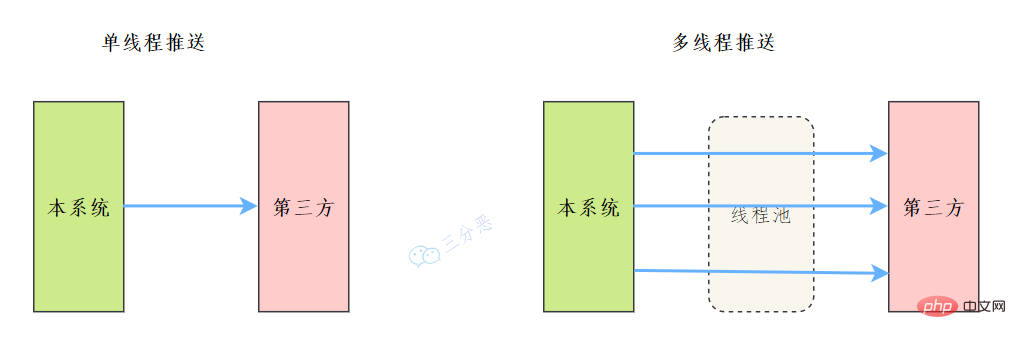
45.能说说工作中线程池的应用吗?
synchronized (PushProcessServiceImpl.class) {}46.能简单说一下线程池的工作流程吗?

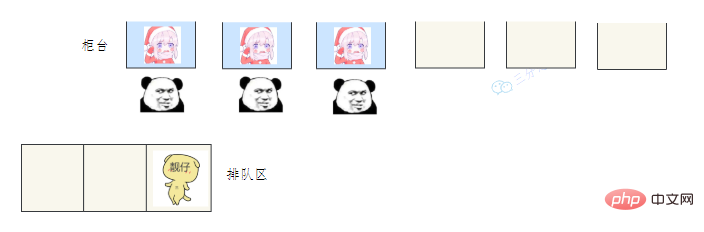
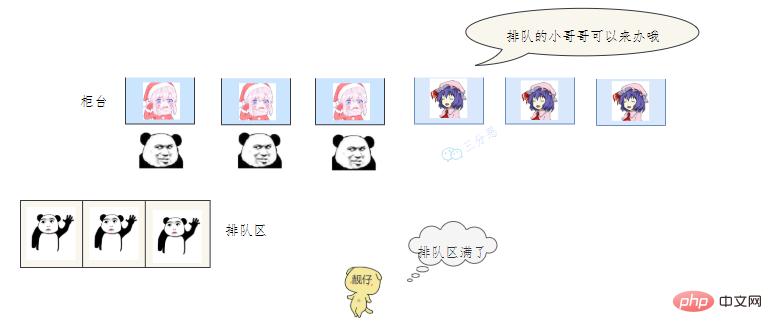
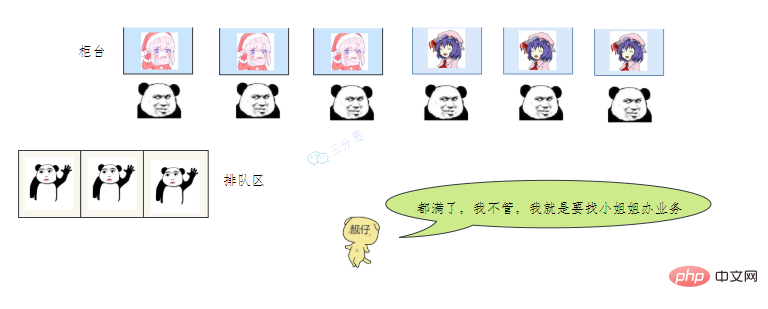
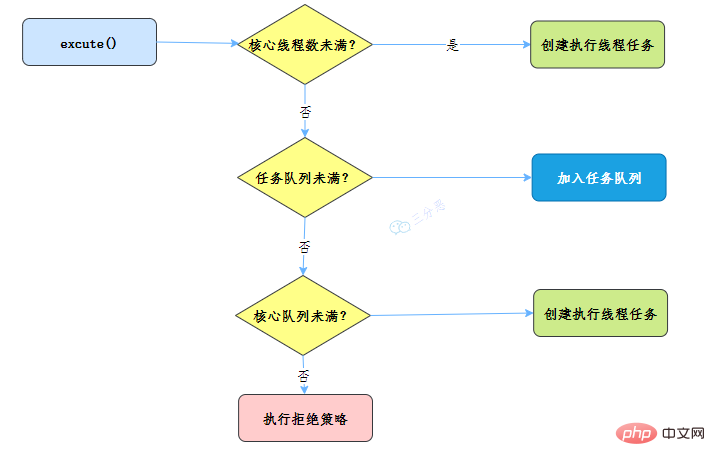
47.线程池主要参数有哪些?
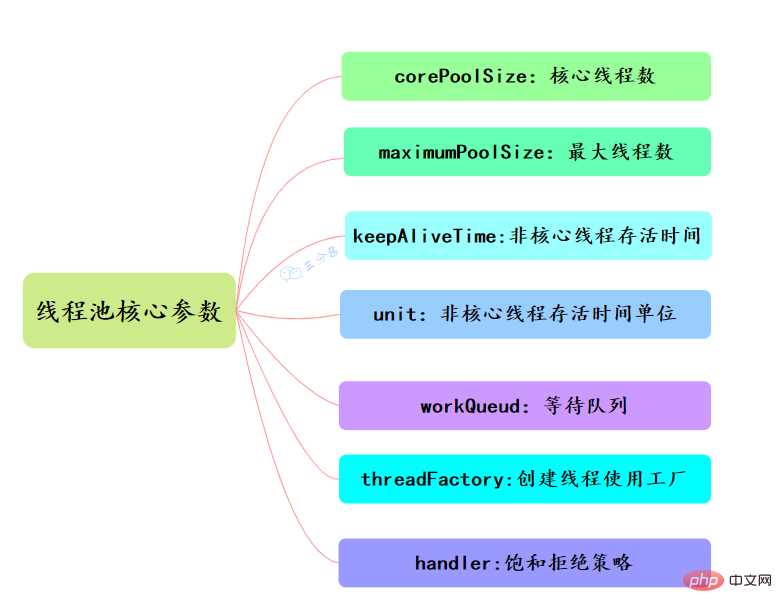
corePoolSize、maximumPoolSize、workQueue、handler这四个。maximumPoolSize表示允许的最大线程数 = (非核心线程数+核心线程数),当BlockingQueue也满了,但线程池中总线程数 maximumPoolSize时候就会再次创建新的线程。
Runnable对象。当运行当线程数= corePoolSize时,新的任务会被添加到workQueue中,如果workQueue也满了则尝试用非核心线程执行任务,等待队列应该尽量用有界的。corePoolSize、workQueue、maximumPoolSize都不可用的时候执行的饱和策略。48.线程池的拒绝策略有哪些?
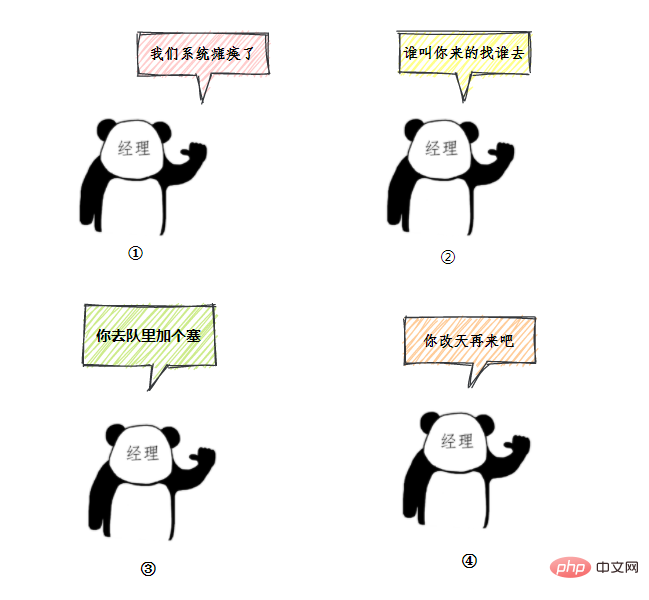
49.线程池有哪几种工作队列?
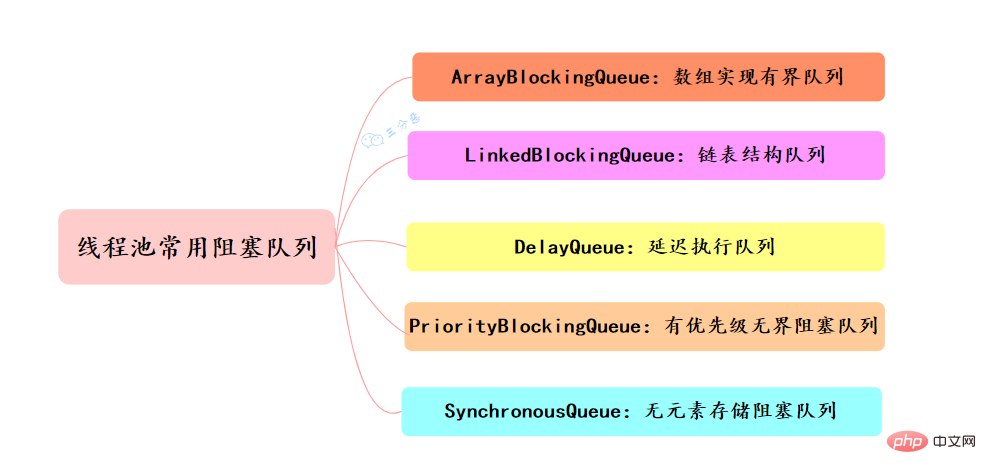
50.线程池提交execute和submit有什么区别?
threadsPool.execute(new Runnable() {
@Override public void run() {
// TODO Auto-generated method stub }
});Future<object> future = executor.submit(harReturnValuetask); try { Object s = future.get(); } catch (InterruptedException e) {
// 处理中断异常 } catch (ExecutionException e) {
// 处理无法执行任务异常 } finally {
// 关闭线程池 executor.shutdown();}</object>51.线程池怎么关闭知道吗?
shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。
52.线程池的线程数应该怎么配置?

Runtime.getRuntime().availableProcessors();
53.有哪几种常见的线程池?
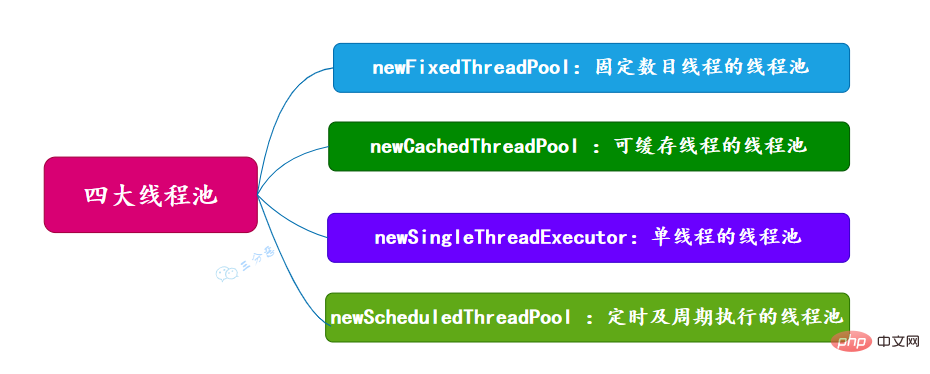
54.能说一下四种常见线程池的原理吗?
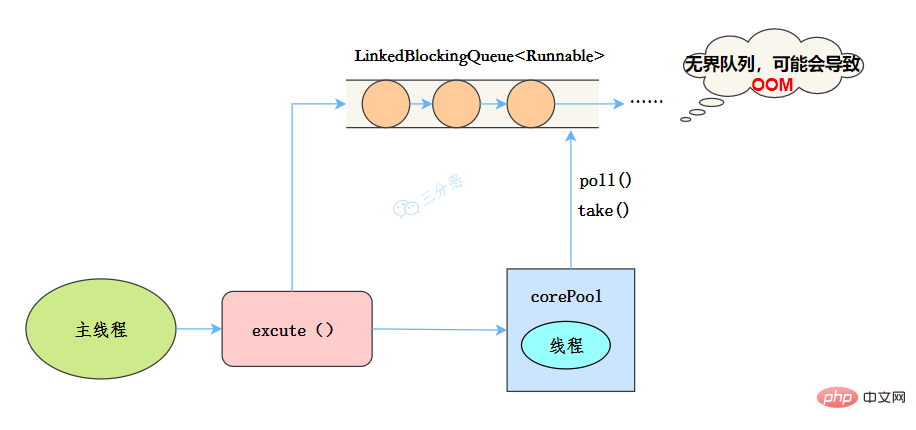
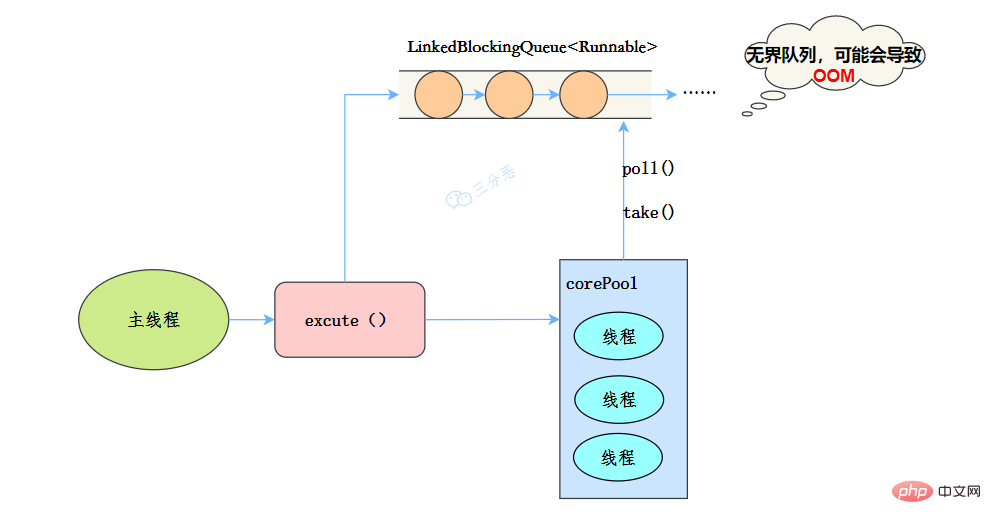
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<runnable>(),
threadFactory));
}</runnable>
newJava 同時実行に関するナレッジ ポイントを要約する
public static ExecutorService newJava 同時実行に関するナレッジ ポイントを要約する(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<runnable>(),
threadFactory);
}</runnable>
newCachedThreadPool
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<runnable>(),
threadFactory);
}</runnable>
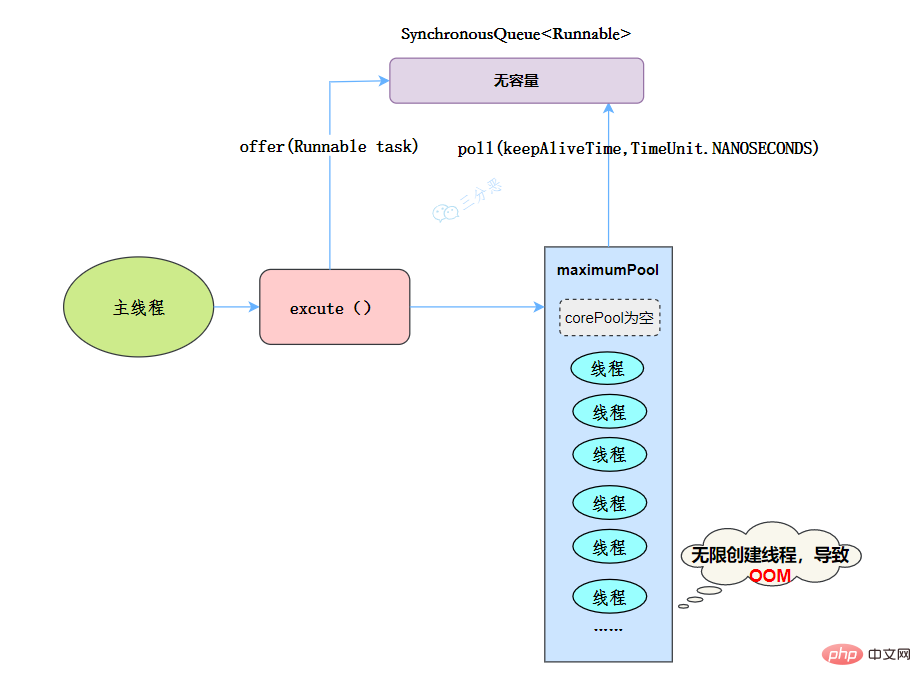
newScheduledThreadPool
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
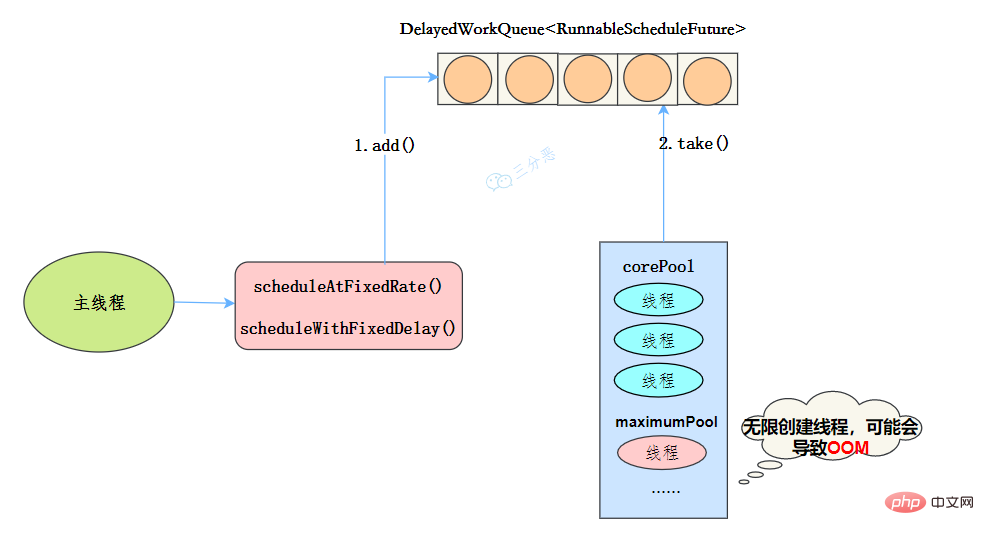
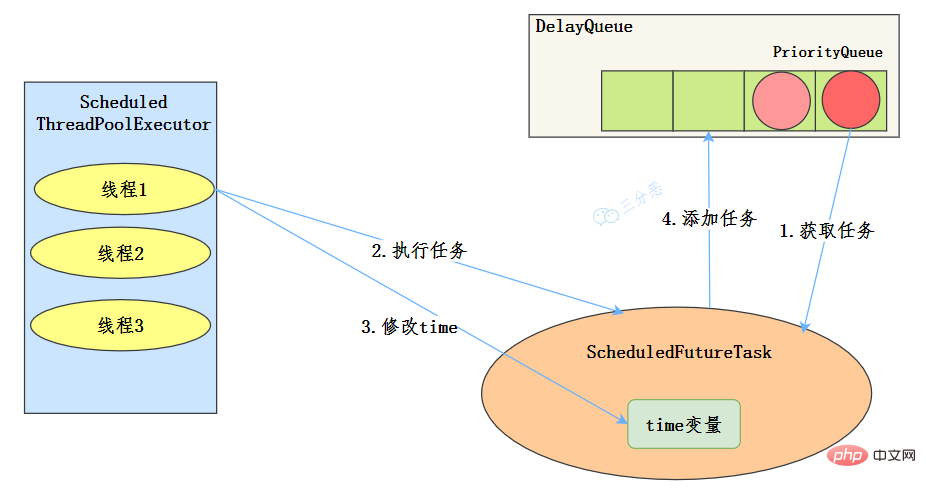
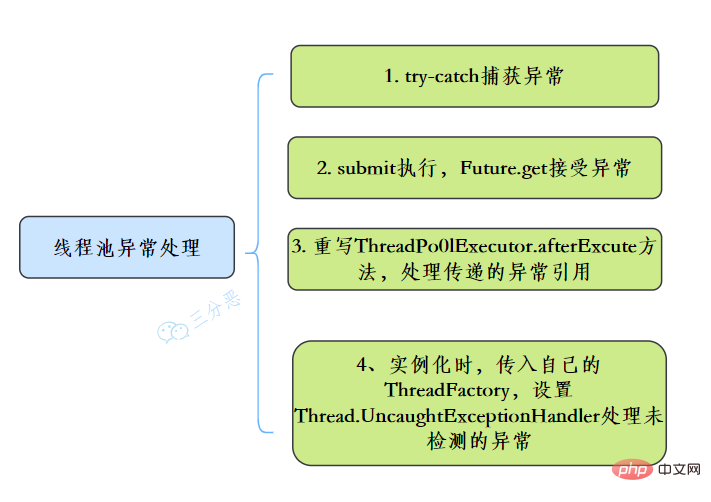
55.线程池异常怎么处理知道吗?
56.能说一下线程池有几种状态吗?
//线程池状态
private static final int RUNNING = -1 <p>线程池各个状态切换图:</p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/47690a2c7799a7bd0d10ed5490da3a7b-77.png" class="lazy" alt="Java 同時実行に関するナレッジ ポイントを要約する"></p><p><strong>RUNNING</strong></p>
57.线程池如何实现参数的动态修改?
![JDK Java 同時実行に関するナレッジ ポイントを要約する设置接口来源参考[7]](https://img.php.cn/upload/article/000/000/067/6094178ce7a357b1c3eb573fc35e4d09-78.png)
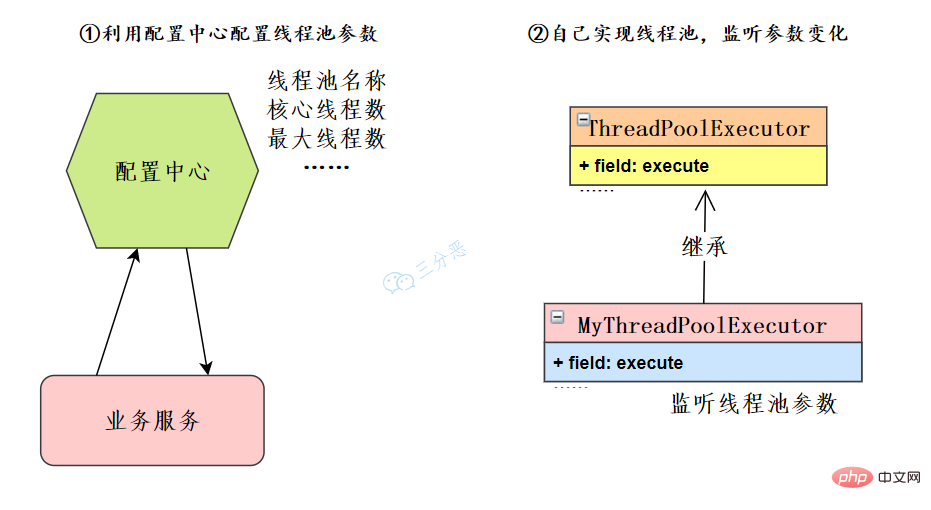
スレッド プールのチューニングについてご存知ですか?
![线程池评估方案 来源参考[7]](https://img.php.cn/upload/article/000/000/067/b8171ba02ccd61fc1cad003f65eae9c1-80.png) プロセス中に監視およびアラーム メカニズムを組み合わせてスレッド プールの問題を分析するか、ポイントを最適化し、スレッド プールの動的パラメーター構成メカニズムと組み合わせて構成を調整します。
プロセス中に監視およびアラーム メカニズムを組み合わせてスレッド プールの問題を分析するか、ポイントを最適化し、スレッド プールの動的パラメーター構成メカニズムと組み合わせて構成を調整します。 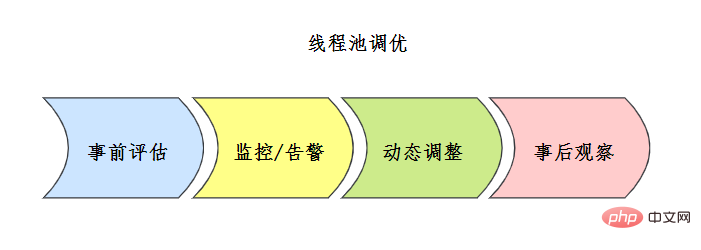 58. スレッド プールを設計して実装できますか?
58. スレッド プールを設計して実装できますか? スレッド プールの実装原理を確認できます。以前誰かがスレッド プールについてこのように話していたなら、私はとっくに理解しているはずです。もちろん、私たちはそれを自分たちで実装します。スレッドプールのコアプロセスを把握するだけで十分です - 参考文献 [6]:
私たち自身の実装は、このコアを完成させることですプロセス: 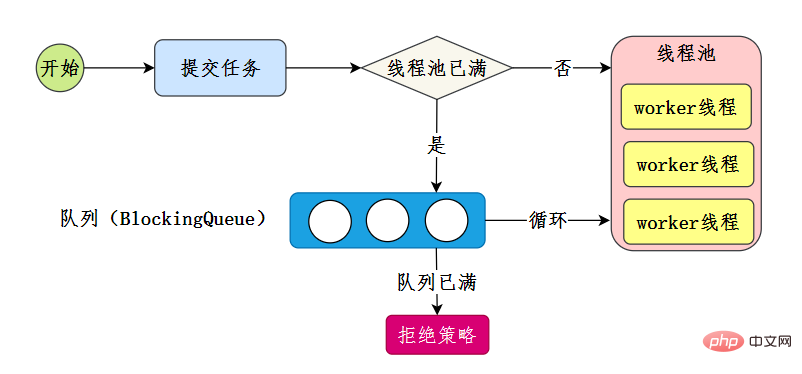
このようにして、メインスレッドプールが実現され、プロセスクラスが完成します。 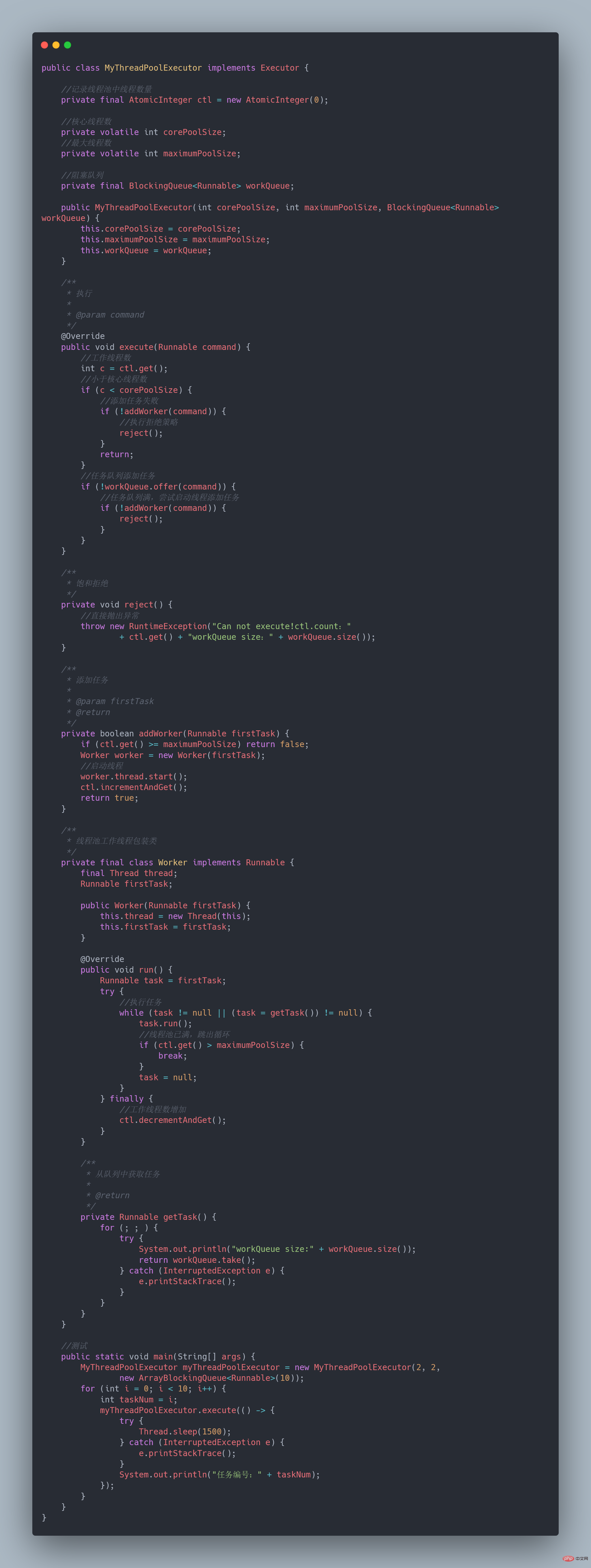 59. 単一マシンのスレッド プールの実行がパワーオフされている場合はどうすればよいですか?
59. 単一マシンのスレッド プールの実行がパワーオフされている場合はどうすればよいですか? 操作を元に戻すメソッド。次に、ブロッキング キュー全体を再実行します。
同時コンテナとフレームワーク と
ConcurrentHashMap## を含む「Counter Attack: Java Collection of Thirty question」をチェックしてください。 #これら 2 つのスレッドセーフなコンテナ クラスに関する質問と回答。 。 60.Fork/Join フレームワークを理解していますか? Fork/Joinフレームワークは、Java7で提供されているタスクを並列実行するためのフレームワークで、大きなタスクをいくつかの小さなタスクに分割し、最後にそれぞれの小さなタスクの結果をまとめて結果を得るフレームワークです。大きな仕事。 Divide and Conquer
と 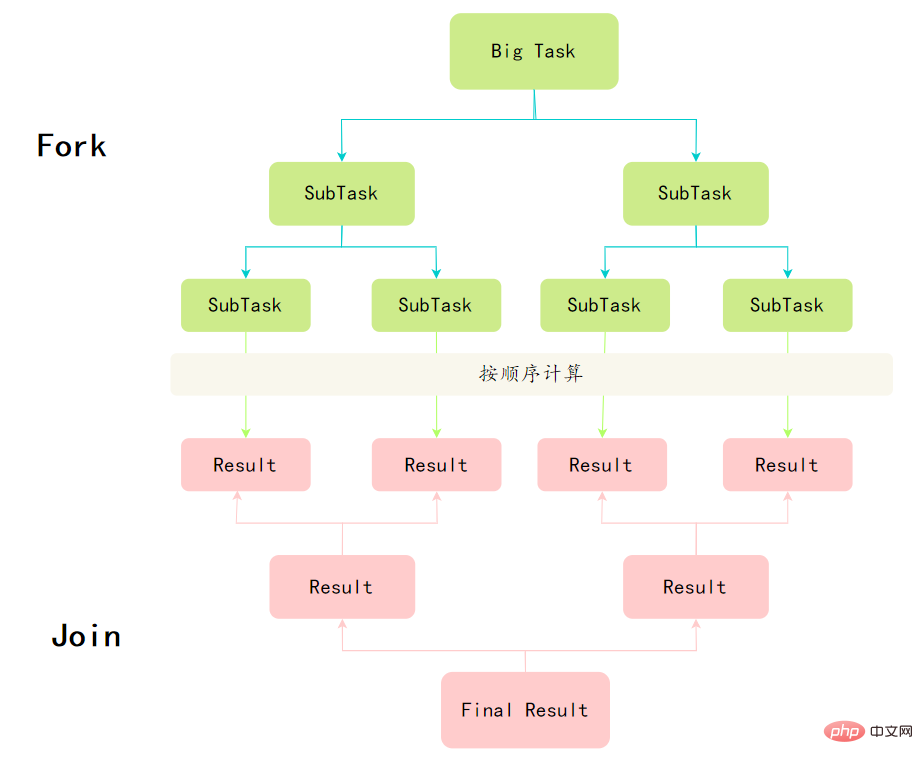
public class CountTask extends RecursiveTask<integer> {
private static final int THRESHOLD = 16; // 阈值
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
// 如果任务足够小就计算任务
boolean canCompute = (end - start) result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException e) {
} catch (ExecutionException e) {
}
}
}</integer>
以上がJava 同時実行に関するナレッジ ポイントを要約するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



