

mysqlの読み書き分離の実装方法は何ですか?

mysql では、「mysql-proxy」を使用して読み取りと書き込みの分離を実現できます。「mysql-proxy」は、読み取りと書き込みの分離を実現するために mysql によって公式に提供されるソフトウェアであり、ミドルウェアとも呼ばれます。メイン データベースへの書き込み操作は処理され、データベースからのクエリ操作は処理され、データベースの一貫性はマスター/スレーブ レプリケーションによって実現されます。

このチュートリアルの動作環境: Windows10 システム、mysql8.0.22 バージョン、Dell G3 コンピューター。
mysql の読み書き分離の実装方法は何ですか?
Mysql で読み書き分離を実現できるプラグインには、mysql-proxy / Mycat / Ameba などがあります。システムに付属するプラグインです。この実験では主に読み取りと書き込みの分離を実現するために使用します。
mysql-proxy は、「読み取りと書き込みの分離 (Read/Write Splitting)」を実現するソフトウェアです (公式に提供されています) MySQL (ミドルウェアとも呼ばれます) の基本原理は、メイン データベースに書き込み操作 (挿入、更新、削除) を処理させ、スレーブ データベースにクエリ操作 (選択) を処理させることです。データベースの一貫性は、マスター/スレーブ レプリケーションによって実現されます。
MySQL プロキシは、主に内部 Lua スクリプトに依存して読み取りステートメントと書き込みステートメントの区別を実現できます (読み取りステートメントと書き込みステートメントの判断を実現できます)
マスターサーバー(ライトサーバー)のみでデータの書き込みが完了した場合、この時点ではスレーブサーバーでは書き込みが行われず、データは存在しません。 、マスター/スレーブ サーバーを実装するには別のテクノロジーを使用する必要があります。データの整合性、このテクノロジーはマスター/スレーブ レプリケーション テクノロジーと呼ばれるため、マスター/スレーブ レプリケーションは読み取りと書き込みの分離の基礎です
読み取り-書き込み分離 (MySQL-Proxy) とは、マスターに書き込み操作を処理させ、スレーブに読み取り操作を処理させることを意味します。これは、比較的大規模な読み取り操作を行うシナリオに非常に適しており、マスターへの負担を軽減できます。
使用mysql-proxy は、mysql の読み取りと書き込みの分離を実現します。mysql-proxy は、実際には、バックエンドの mysql マスター/スレーブ サーバーのプロキシとして機能します。クライアントのリクエストを直接受け入れ、SQL ステートメントを分析し、読み取り操作であるかどうかを判断します。
データベースの書き込み操作は読み取り操作よりも時間がかかるため、データベースの読み取りと書き込みを分離することで、この問題を解決できます。データベースへの書き込みの問題は、クエリの効率に影響します。
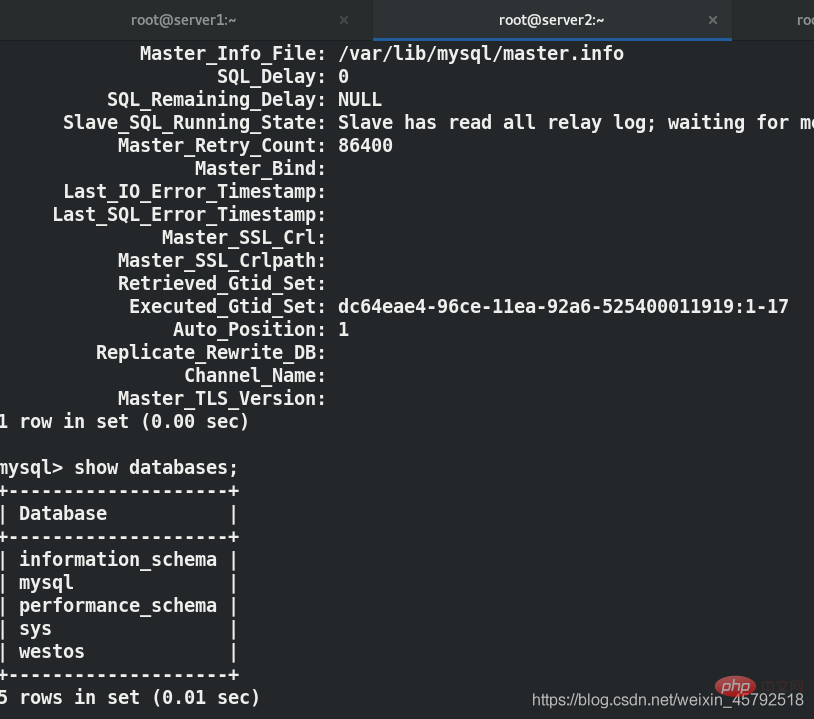
最初に、サーバー 1 とサーバー 2 で gtid マスター/スレーブ レプリケーションを構成します。
gtid マスター/スレーブ レプリケーションに関する以前のブログは完了しました。説明、ここでは詳細には触れず、最終的な効果のみを示します。
サーバー 1 に Westos データベースが確立され、対応するサーバー 2 が同期されることがわかります。
 server3 プロキシの設定 (mysql-proxy)
server3 プロキシの設定 (mysql-proxy)
server3 に mysql-proxy プロキシ サーバーを構築します (クライアントがサーバー 1 で書き込み、サーバー 2 でデータを読み取ることを実現するため)
(1) mysql を入手します。 - 物理マシンのプロキシインストールパッケージからserver3
(2)server3で設定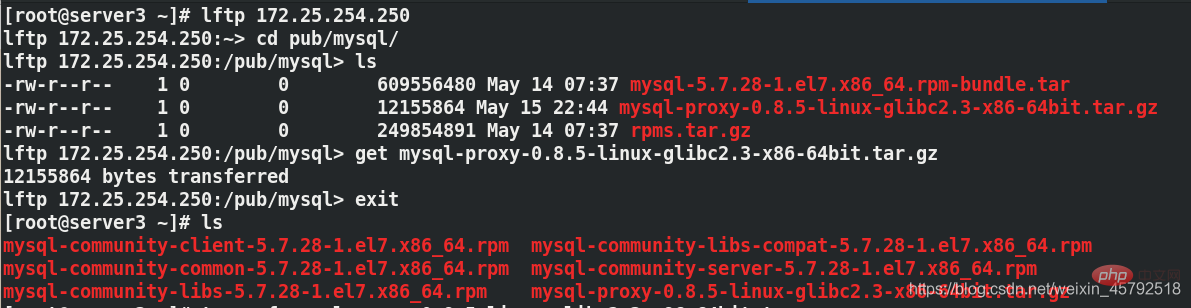
[root@server3 ~]# systemctl status mysqld ##查看mysqld服务状态 [root@server3 ~]# systemctl stop mysqld ##关闭mysqld服务,因为代理服务器要用3306端口 [root@server3 ~]# tar zxf mysql-proxy-0.8.5-linux-glibc2-x86-64bit.tar.gz -C /usr/local/ ##解压到/usr/local/目录下
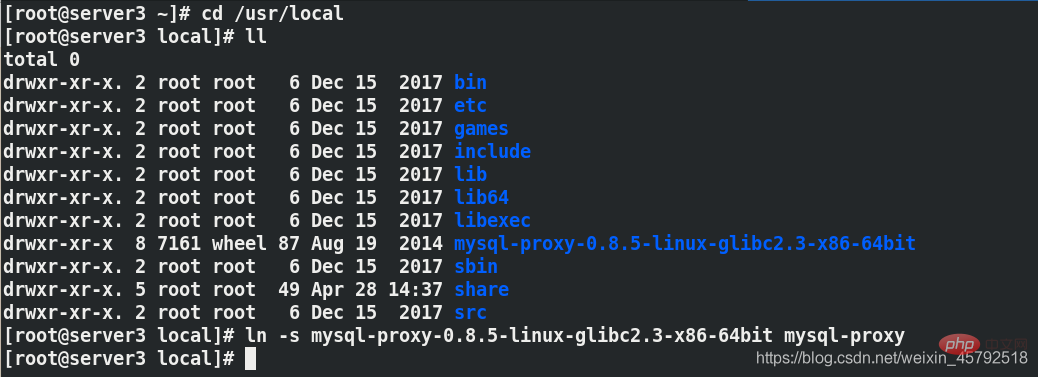
管理用のソフト接続を作成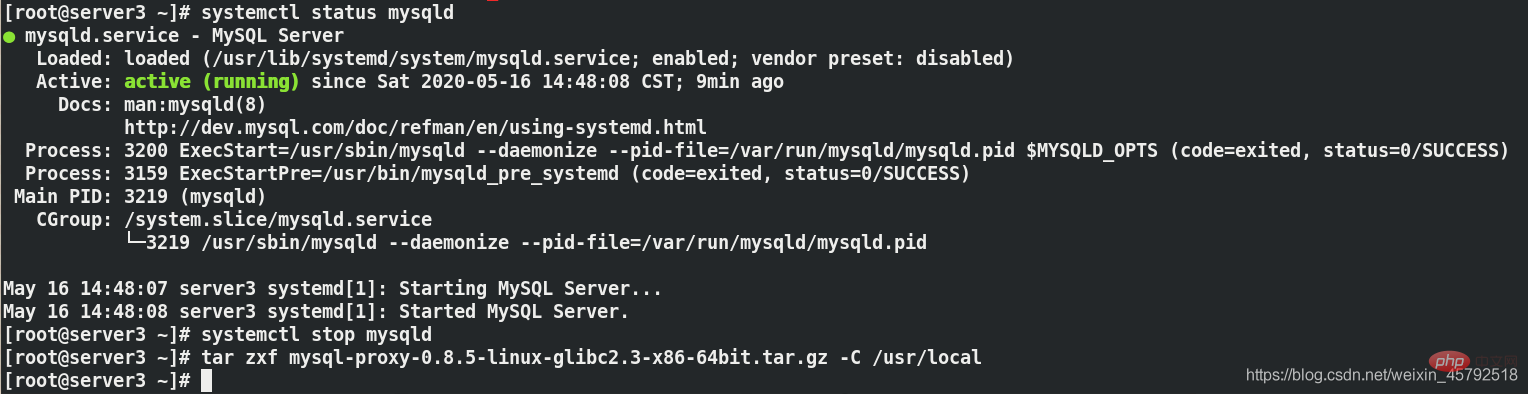
ln -s mysql-proxy-0.8.5-linux-glibc2-x86-64bit mysql-proxy
 mysql-proxy ディレクトリには設定ファイルがないため、自分で設定ファイル用のディレクトリを作成し、設定ファイルを作成する必要があります
mysql-proxy ディレクトリには設定ファイルがないため、自分で設定ファイル用のディレクトリを作成し、設定ファイルを作成する必要があります
# # 次の 2 つのコマンドを使用して、設定ファイルに記述されたパラメータを確認します。
[root@server3 bin]# ./mysql-proxy --help [root@server3 bin]# ./mysql-proxy --help-proxy
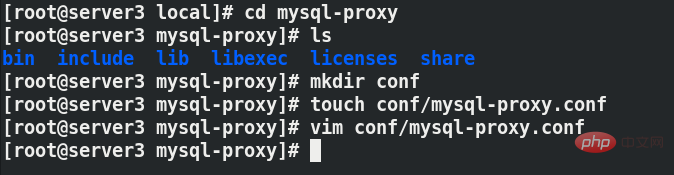
[mysql-proxy] ##指定语句块 proxy-address=0.0.0.0:3306 ##指定proxy访问的主机和端口,3306是一个对外的通用端口 proxy-read-only-backend-addresses=172.25.254.2:3306 ##读主机的ip和端口 proxy-backend-addresses=172.25.254.1:3306 ##执行写主机的ip和端口 proxy-lua-script=/usr/local/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua ##指定读写分离操作使用的lua文件路径 pid-file=/usr/local/mysql-proxy/log/mysql-proxy.pid ##pid存放路径 log-file=/usr/local/mysql-proxy/log/mysql-proxy.log ##日志存放路径 plugins=proxy ##指定使用的插件 log-level=debug ##日志的等级 keepalive=true ##开启守护进程 daemon=true ##使用后台方式运行
保存後、設定ファイルの権限を 660 に変更し、ログ ディレクトリを作成する必要があります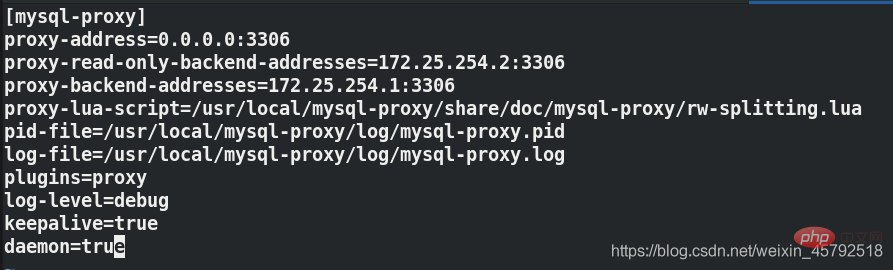
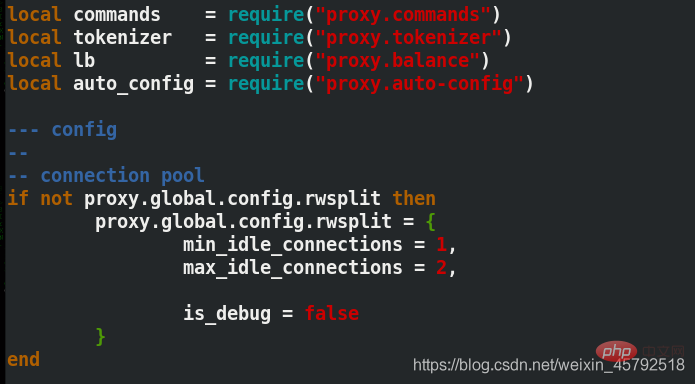
#データベースで読み取りと書き込みの分離が発生した場合の接続の最大数と最小数を変更する
##
[root@server3 mysql-proxy]# find . -name *.lua ./share/doc/mysql-proxy/rw-splitting.lua [root@server3 mysql-proxy]# cd share/doc/mysql-proxy [root@server3 mysql-proxy]# ls [root@server3 mysql-proxy]# vim rw-splitting.lua ##将lua脚本里原本启动机制的最小4个最大8个连接,改为1和2 min_idle_connections = 1, 最小连接数 max_idle_connections = 2, 最大连接数
(3) mysql -proxy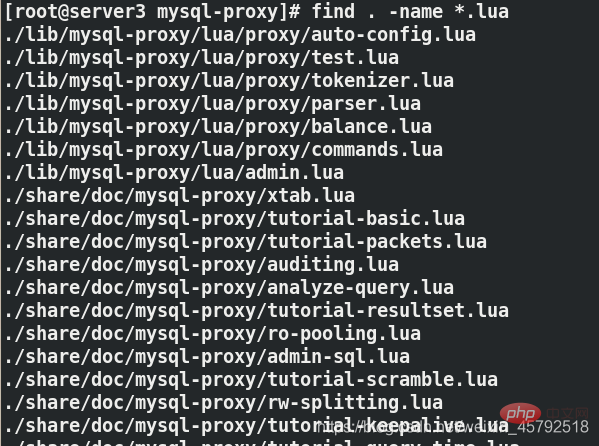
/usr/local/mysql-proxy/bin/mysql-proxy --defaults-file=/usr/local/mysql-proxy/conf/mysql-proxy.conf ##启动 cat /usr/local/mysql-proxy/log/mysql-proxy.log ##查看日志

 を開始し、読み取りと書き込みの分離をテストします
を開始し、読み取りと書き込みの分離をテストします(1) 新規作成サーバー1のユーザーと承認
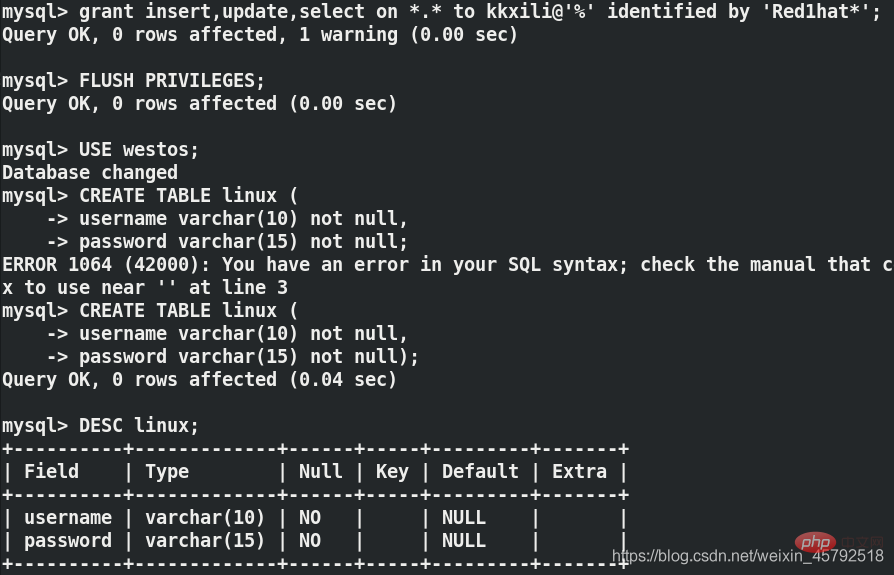
mysql> grant insert,update,select on *.* to kkxili@'%' identified by 'Red1hat*'; mysql> FLUSH PRIVILEGES; ##刷新授权表 mysql> USE westos; Database changed mysql> CREATE TABLE linux ( -> username varchar(10) not null, -> password varchar(15) not null); mysql>DESC linux;
(2)server3安装lsof

(3)在用户端虚拟机server4上第一次连接数据库代理server3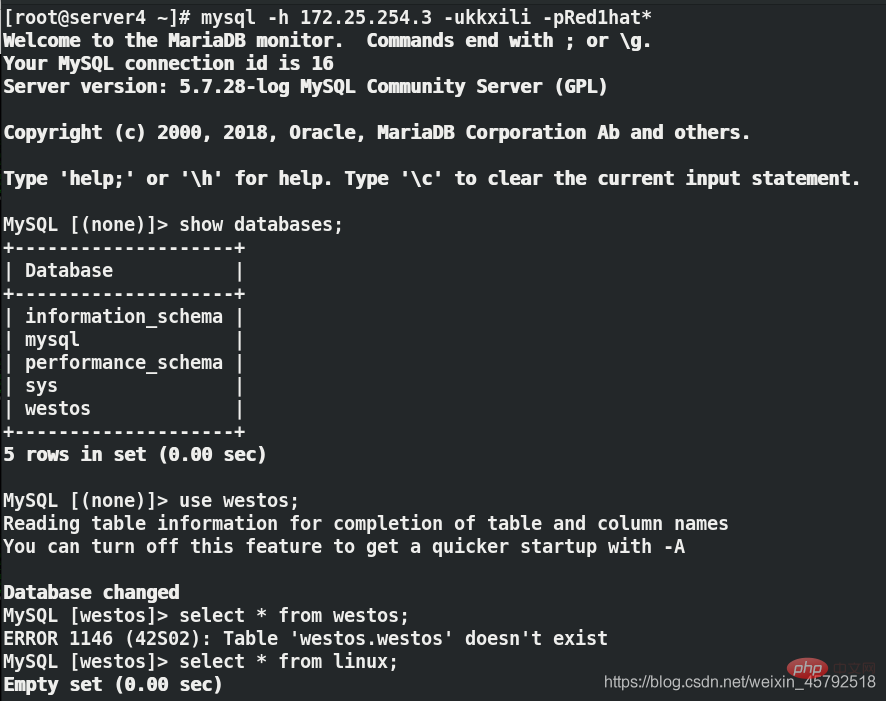
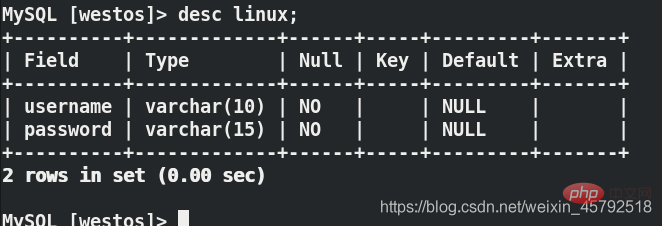
在server3上面:lsof -i:3306

(4)在用户端虚拟机server4上第二次连接数据库代理server3
在server3上面:lsof -i:3306

(5)在用户端虚拟机server4上第三次连接数据库代理server3
在server3上面:lsof -i:3306
开始读写分离
 上面是读写分离的读访问测试
上面是读写分离的读访问测试
写测试
在用户端插入数据
use westos;
insert into linux values('user1','123');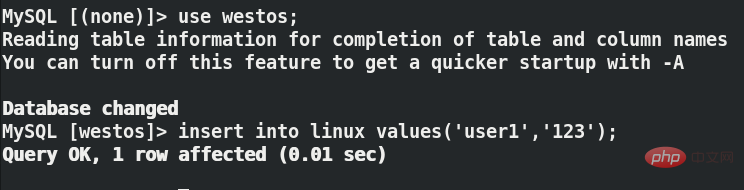
server1和server2都可以看到插入的数据
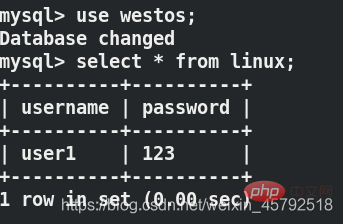
在server2中关闭主从复制
用户端再次写入数据,看不到刚刚写的数据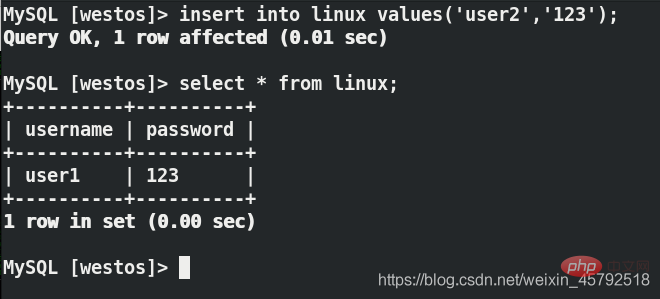
写在server1上,可以查看到数据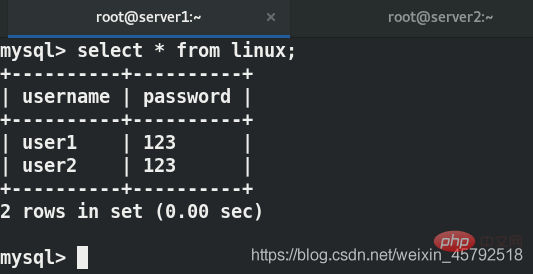
在server2上实现了读写分离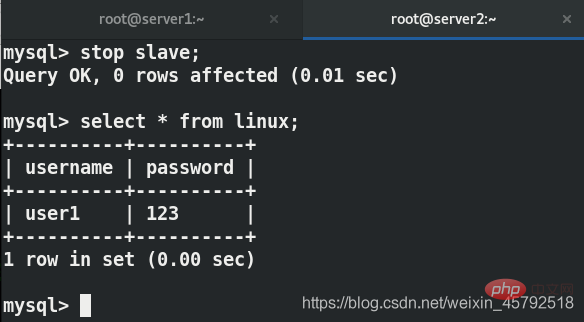
server2重新开启主从复制可以看到数据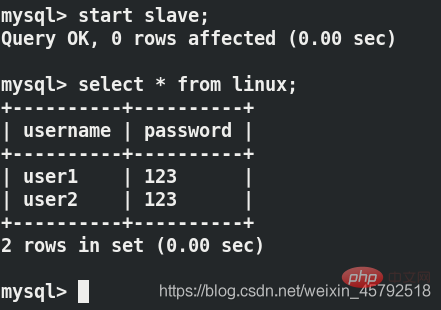
客户端读的是server2,server2只能读,不能写,因此看不到刚才写进去的东西,server1可以看到
实现了客户端(虚拟机)对server1的写,对server2的读
当访问数据库的用户数量很多时,数据库的代理就把后端的数据库实现读写分离
server1是写的数据库、server2是读的数据库
当server1和server2满足gtid的主从复制时,用户往数据库写入的数据其实是写入了server1,并没有写入server2,server2上面的数据是复制过去的,因此server1、server2、客户机上面都能查到刚刚写进去的数据,其实客户机查的是server2(读)
当关闭server1和server2的异步复制时,客户机往数据库写入的数据只写进了server1,没有写进去server2,server2也没有复制一份
因此server1可以查看到,server2和客户机上面都查不到刚刚写进去的数据,此时的客户机读的是server2
推荐学习:mysql视频教程
以上がmysqlの読み書き分離の実装方法は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7529
7529
 15
1378
52
82
11
21
76
15
1378
52
82
11
21
76

 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 SQLが行を削除した後にデータを回復する方法
Apr 09, 2025 pm 12:21 PM
SQLが行を削除した後にデータを回復する方法
Apr 09, 2025 pm 12:21 PM
データベースから直接削除された行を直接回復することは、バックアップまたはトランザクションロールバックメカニズムがない限り、通常不可能です。キーポイント:トランザクションロールバック:トランザクションがデータの回復にコミットする前にロールバックを実行します。バックアップ:データベースの定期的なバックアップを使用して、データをすばやく復元できます。データベーススナップショット:データベースの読み取り専用コピーを作成し、データが誤って削除された後にデータを復元できます。削除ステートメントを使用して注意してください:誤って削除されないように条件を慎重に確認してください。 WHERE句を使用します:削除するデータを明示的に指定します。テスト環境を使用:削除操作を実行する前にテストします。
