

この記事では、mysql に関する関連知識を提供します。主に Explain に関連する問題を紹介します。Mysql の Explain は、Mysql のパフォーマンス最適化分析ツールと呼ぶことができます。対応する問題を分析するために使用できます。 SQL ステートメントの実行について、皆さんのお役に立てれば幸いです。

推奨学習: mysql ビデオ チュートリアル
データベース パフォーマンスの最適化は、すべてのバックエンド プログラマーが持つ必要のある基本スキルの 1 つです。 , Mysql で説明するものは、Mysql のパフォーマンス最適化分析アーティファクトと呼ぶことができます。これを使用して、対応する SQL ステートメントの実行計画が Mysql の下部でどのように実行されるかを分析できます。SQL の実行効率を評価するのに役立ち、 Mysql のパフォーマンスを決定する最適化の方向性は非常に重要です。ただし、多くの学生は、Explain に基づいて既存の SQL の詳細な実行分析を実行する方法についてまだ混乱しているため、この記事では、Explain 分析を通じてデータベースのパフォーマンスの問題を特定する方法について詳しく説明します。
各 SQL は、クライアントによって MySQL サーバーに送信されると、主にいくつかの特別な処理を含む MySQL オプティマイザー コンポーネントによって分析されます。実行シーケンスは次のとおりです。最適な実行効率を確保するために変更され、対応する実行計画が最終的に生成されます。いわゆる実行計画とは、実際にはストレージ エンジン レベルでのデータの取得方法を指し、データをインデックスまたはフル テーブル スキャンで取得するか、データ取得後にテーブルを返す必要があるかどうかなどを指します。 MySQL でデータを取得するプロセスです。
次に、この説明が何であるか、そしてなぜそれがパフォーマンスの最適化に役立つのかを詳しく見てみましょう。次のステートメントを実行すると:
explain SELECT * FROM user_info where NAME='mufeng'
Explain ステートメントを実行すると、次の実行結果が得られます。データベース テーブルに似たこの 12 個のフィールドは、実際には、Mysql によって実行される実行プランの詳細な説明です。これら 12 のフィールドの意味を詳しく見てみましょう. それらの意味を理解することによってのみ、Mysql がデータ クエリを実行する方法を理解することができます。

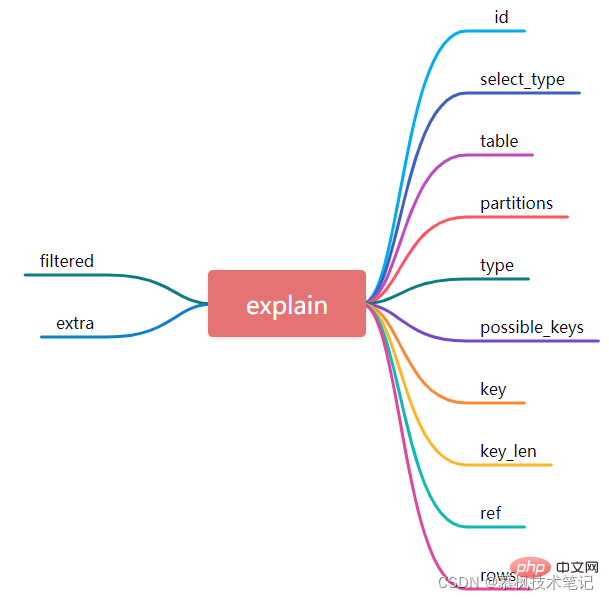
1. id
実際には、各選択クエリは ID に対応します。 . SQLの実行順序を表し、idの値が大きいほど、対応するSQL文の実行優先度が高くなります。一部の複雑なクエリ SQL ステートメントにはサブクエリが含まれることが多く、ID のシリアル番号が増加します。ネストされたクエリがある場合、最も内側のクエリが最大の ID に対応していることがわかり、最初に実行されます。

上の図に示すように、SQL クエリ ステートメントでは、最初の実行プランの ID は 1、2 番目の実行プランの ID は 2、そしてID 1 の実行 プランに対応するテーブルは order で、ID 2 の実行プランに対応するテーブルは user_info です。SQL ステートメントと組み合わせると、user_info からのサブクエリ select id が最初に実行され、次にデータが実行されることがわかります。テーブルの順序に関するクエリが実行されます。
2. select_type
select_type は、実行プランに対応するクエリの種類を示します。一般的なクエリの種類には、主に通常のクエリ、結合クエリ、サブクエリが含まれます。 SIMPLE (クエリ ステートメントは単純なクエリであり、サブクエリは含まれません)、PRIMARY (クエリ ステートメントにサブクエリが含まれる場合、最も外側のクエリ タイプに対応します)、UNION (union の後に表示される select ステートメントに対応するクエリ タイプがマークされます)このタイプ)、SUBQUERY (サブクエリはこのタイプとしてマークされます)、DEPENDENT SUBQUERY (外部クエリに依存します)

3、table
#table はテーブル名を表し、どのテーブルをクエリするかを示します。もちろん、これは実際のテーブルの名前である必要はなく、テーブルの別名または一時テーブルの場合もあります。4、partitions
partitions はパーティションの概念を表します。これは、クエリを実行するときに、対応するテーブルがデッド パーティション テーブルになるかどうかを意味します。 , するとここに特定のパーティション情報が表示されます。5. type
type は、習得する必要がある非常に中心的な属性です。データベーステーブルにアクセスする現在の方法を示します。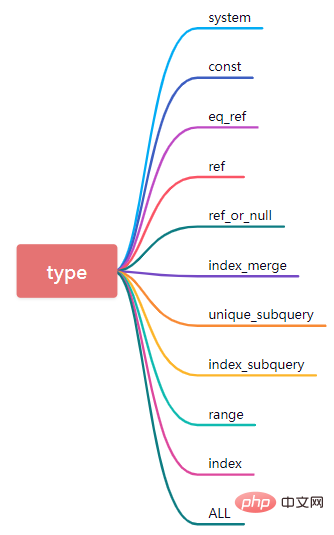
テーブルには 1 行しかなく (システム テーブルに相当)、データ量は少なく、クエリ速度は非常に高速です。システムは const 型の特殊なケースです。
(2) const
type が const の場合は、データ クエリ中に主キーまたは一意のインデックスがヒットしたことを意味し、このタイプのデータ クエリは非常に高速です。

(3) eq_ref
データ クエリのプロセスで、SQL ステートメントがクラスター化インデックスまたは非 null に基づくことができるかどうかテーブル接続の値の一意のインデックスはデータスキャンを記憶し、タイプに対応する値が eq_ref として表示されます。
(4)ref
データをクエリするとき、インデックス ヒットが一意のインデックスではなくセカンダリ インデックスである場合、テスト クエリの速度は非常に速くなりますが、タイプは ref です。また、複数フィールドの結合インデックスの場合、左端のマッチング原則に従い、結合インデックスの左端から始まる連続する複数列のフィールドの等価比較も ref 型となります。

(5) ref_or_null
この接続タイプは ref と似ていますが、MySQL が NULL 値を含む行をさらに検索する点が異なります。
(7)unique_subquery
where 条件内の一連のサブクエリ条件です。
(8)index_subquery
unique_subquery とは異なり、非一意のインデックスなので、重複した値を返すことができます。
(9)range
インデックスを使用して行データを取得し、指定された範囲内の行データのみを取得します。つまり、インデックス付きフィールドの指定された範囲でデータが取得されます。 where ステートメントで bettween...and、<、>、<=、in およびその他の条件付きクエリ タイプを使用する場合、タイプは range です。

(10)index
Index と ALL は実際にはテーブル全体を読み取ります。違いは、index はインデックス ツリーを走査して読み取るのに対し、ALL はテーブル全体を読み取ることです。ハードディスクを読み込みます。
(11)all
データ マッチングのためにテーブル全体を走査します。この時点でのデータ クエリのパフォーマンスは最悪です。
6. possible_keys
は、Mysql オプティマイザーによってどのインデックスが選択できるか、つまりどのようなインデックス候補があるかを示します。
#7, key# possible_keys で実際に選択されたインデックス
#8, key_lenはインデックスの長さを示します。これは実際のフィールド属性と null かどうかに関連します。
9, ref
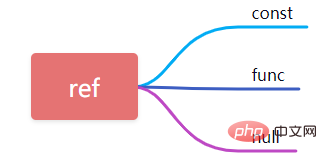 #定数と同等のクエリにフィールドを使用する場合、クエリ条件で使用される場合、ここでの ref は const です。式や関数がない場合、ref は func として表示され、その他は null として表示されます。
#定数と同等のクエリにフィールドを使用する場合、クエリ条件で使用される場合、ここでの ref は const です。式や関数がない場合、ref は func として表示され、その他は null として表示されます。
rows 列には、クエリの実行時に MySQL がチェックする必要があると考える行数が表示されます。行数が少ないほど効率が高くなります。
11. filteredfiltered これは、条件を満たすテーブル内のレコード数のパーセンテージ値です。簡単に言うと、このフィールドは、ストレージ エンジンから返されたデータをフィルター処理した後に条件を満たす残りのレコードの割合を表します。
12、追加追加情報は他の列には表示されませんが、この列には表示されます。
(1) インデックスの使用
データ クエリを実行するとき、データベースはカバー インデックスを使用します。つまり、クエリ対象の列がインデックスによってカバーされ、クエリ速度が非常に速くなります。カバリングインデックスを使用します。 select * を使用する代わりに、selectphone_number を使用します。これにより、カバーインデックスが使用されます。
 (2) where
(2) where
の使用 クエリ時に使用可能なインデックスが見つからず、必要なデータは where 条件フィルタリングを通じて取得されますが、 where ステートメントを含むすべてのクエリで [Using where] が表示されるわけではないことに注意してください。
 (3) 一時テーブルを使用するということは、クエリ結果を一時テーブルに保存する必要があることを意味します。一時テーブルは通常、クエリを並べ替えたりグループ化するときに使用されます。
(3) 一時テーブルを使用するということは、クエリ結果を一時テーブルに保存する必要があることを意味します。一時テーブルは通常、クエリを並べ替えたりグループ化するときに使用されます。
(4) filesort の使用
このタイプは、指定された並べ替え操作をインデックスを使用して完了できないことを示します。つまり、ORDER BY フィールドには実際にはインデックスがないため、このタイプのSQLを最適化する必要がある。
上文中我们阐述了explain在分析SQL语句时,可以通过12个属性来分析SQL的大致执行过程,并以此来判断SQL存在的性能问题。那么接下来我们通过一个实际的例子,来具体看下如何结合explain来实现SQL的性能分析。
其实所谓的Mysql性能问题,大部分都指的是平台出现了慢查询问题。慢查询实际上是可以通过配置进行记录的,把执行时间超过某个设定的阈值的sql都记录下来,当出现问题的时候可以通过记录的慢查询日志进行问题的定位。但是有的时候,出现大量慢查询会导致数据库连接给占满,导致整个平台的出现异常。
实际上我们在产品评价表product_evaluation中是建立了索引的,正常来说应该是可以使用到对应的索引字段进行查询的。但是实际上查询耗时有几十秒的时间,远远超过我们的预期。那我们猜测是不是由于某种原因导致Mysql优化器没有选择对应的索引进行数据检索,最后造成慢查询的发生。到底执行计划是怎样的,还是得借助于explain来看下。

如上文所说,虽然explain有12个字段属性帮助我们进行执行计划的分析,但是实际上常用的核心字段也就几个。我们可以看的出来在possible_key中实际上包含了我们设置的索引的,但是实际上Mysql却选择了PRIMARY作为其实际使用的。那么问题来了,为什么明明设置了索引,但是实际并没有用上,呗Mysql吃了吗?另外为什么之前的业务中没有出现这个问题,而现在出现了?我们需要进行进一步的分析。
我们所建立的idx_evaluation_type实际上是一个二级索引(叶子节点是主键id),对于数千万一张的大表来说,实际上这个二级索引也是非常大的,而且这个字段本身的值就三个,变化不大。因此Mysql的优化器在分析这个SQL的时候发现,如果按照SQL中的索引来获取数据后再根据where条件进行筛选,筛选后的数据还需要回表到聚簇索引中获取实际的数据。
假如通过二级索引筛选出来的数据有几万条,而后还需要进行排序,这些操作都是基于临时磁盘我恩建进行的,Mysql判断这种方式的性能可能会很差,因此优化器放弃了原有的数据查询方式,直接通过主键id对应的聚簇索引来进行数据的获取,因为id本身就是有序的。
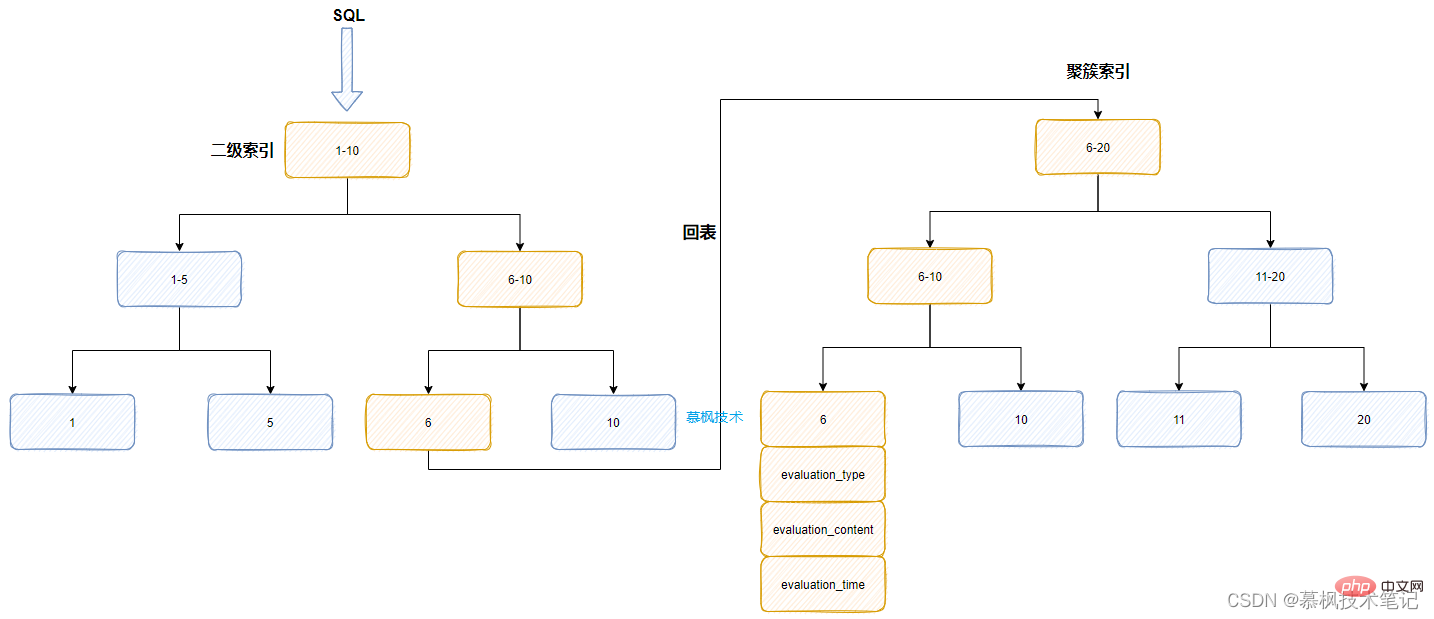
那么知道了查询慢的原因,我们应该怎么进行优化呢?实际上可以在SQL语句中增加force idnex,强制Mysql使用我们设置的二级索引。
SELECT * FROM product_evaluation force index(idx_product_id)WHERE product_id =1 and evaluation_type='GOOD' ORDER BY id desc LIMIT 200
通过上文对于explain使用的介绍,大家在遇到慢SQL问题的时候,可以先通过explain来进行初步的分析,主要明确SQL在Mysql中实际的执行过程是怎样的,如果查询字段没有索引则增加索引,如果有索引就要分析为什么没有用到索引。只要明确具体的执行过程,我们才能确定具体的查询优化方案。
推荐学习:mysql视频教程
以上がMySQLを完全マスターして解説の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



