

Python3 データ構造の知識ポイントの詳細な紹介

この記事は、python に関する関連知識を提供します。主に、数値、文字列、リスト、タプル、辞書などを含むデータ構造に関連する問題を紹介します。内容は、皆様のお役に立てれば幸いです。 。

推奨学習: Python ビデオ チュートリアル
Number
整数型 ( int ) - 多くの場合、整数または整数、つまり小数点のない正または負の整数と呼ばれます。 Python3 の整数にはサイズ制限がなく、Long 型として使用できます。ブール値は整数のサブタイプです。
浮動小数点型 (float) - 浮動小数点型は整数部と小数部で構成され、科学表記法 (2.5e2 = 2.5 x ) を使用して表現することもできます。 102 = 250)
複素数 ((complex)) - 複素数は実数部と虚数部で構成され、bj または complex(a, b). 複素数 b の実部 a と虚数部はすべて浮動小数点型です。
数値型変換
int(x) x を整数に変換します。
float(x) x を浮動小数点数に変換します。
complex(x) 実数部を x、虚数部を 0 として、x を複素数に変換します。
complex(x, y) 実数部を x、虚数部を y として、x と y を複素数に変換します。 x と y は数値式です。
数値操作
# + - * / %(取余) **(幂运算) # 整数除法中,除法 / 总是返回一个浮点数, # 如果只想得到整数的结果,丢弃可能的分数部分,可以使用运算符 // print(8 / 5) # 1.6 print(8 // 5) # 1 # 注意:// 得到的并不一定是整数类型的数,它与分母分子的数据类型有关系 print(8 // 5.0) # 1.0 # 使用 ** 操作来进行幂运算 print(5 ** 2) # 5的平方 25
String str
文字列のクエリ
index():部分文字列 substr が初めて出現する位置。検索対象の部分文字列が存在しない場合、ValueErrorrindex() 例外がスローされます。
rindex(): 最後の出現箇所を検索します。部分文字列 substr.position、検索された部分文字列が存在しない場合、ValueError() 例外がスローされます
find(): 部分文字列 substr が最初に出現する位置を検索します。検索された部分文字列 文字列が存在しない場合、-1
rfind(): 部分文字列 substr の最後の出現を検索します。検索された部分文字列が存在しない場合、-1 を返します。
s = 'hello, hello'
print(s.index('lo')) # 3
print(s.find('lo')) # 3
print(s.find('k')) # -1
print(s.rindex('lo')) # 10
print(s.rfind('lo')) # 10文字列の大文字と小文字の変換
upper(): 文字列内のすべての文字を大文字に変換します
# lower(): 文字列内のすべての文字を小文字に変換します - swapcase(): 文字列内のすべての大文字を小文字に変換し、すべてを小文字に変換します文字を大文字に変換します
- capitalize(): 最初の文字を大文字に変換し、残りの文字を小文字に変換します
- title():各単語の最初の文字を大文字に変換し、各単語の残りの文字を小文字に変換します
-
#
文字列の配置s = 'hello, Python' print(s.upper()) # HELLO, PYTHON print(s.lower()) # hello, python print(s.swapcase()) # HELLO, pYTHON print(s.capitalize()) # Hello, python print(s.title()) # Hello, Python
ログイン後にコピー
-
#ljust(): 左揃え、最初のパラメータは幅を指定し、2 番目のパラメータはフィラーを指定します。デフォルトはスペースです。設定された幅が実際の幅より小さい場合は、元の文字列が返されます
-
rjust(): 右揃え、最初のパラメータは幅を指定し、2 番目のパラメータはフィラーを指定します。デフォルトはスペースです。設定された幅が実際の幅より小さい場合は、元の文字列が返されます
zfill(): 右揃え、左側は 0 で埋められます。このメソッドは、文字列の幅を指定するために使用されるパラメータを 1 つだけ受け取ります。指定された幅が文字列の長さ以下である場合、文字列自体が返されます
-
s = 'hello,Python' '''居中对齐''' print(s.center(20, '*')) # ****hello,Python**** '''左对齐 ''' print(s.ljust(20, '*')) # hello,Python******** print(s.ljust(5, '*')) # hello,Python '''右对齐''' print(s.rjust(20, '*')) # ********hello,Python '''右对齐,使用0进行填充''' print(s.zfill(20)) # 00000000hello,Python print('-1005'.zfill(8)) # -0001005ログイン後にコピー文字列の分割、スライス
split(): 文字列の左側から分割します
rsplit(): 文字列の右側から分割します- デフォルトの分割文字はスペース、戻り値はリスト
- 引数 sep で分割文字列を指定 分割文字
- 引数 maxsplit は文字列を分割する際の最大分割数を指定します。分割の場合、残りの部分文字列は一部として個別に使用されます
s = 'hello word Python' print(s.split()) # ['hello', 'word', 'Python'] s1 = 'hello|word|Python' print(s1.split(sep='|')) # ['hello', 'word', 'Python'] print(s1.split('|', 1)) # ['hello', 'word|Python'] # 左侧开始 print(s1.rsplit('|', 1)) # ['hello|word', 'Python'] # 右侧开始ログイン後にコピー#スライス
s = 'hello,world' print(s[:5]) # hello 从索引0开始,到4结束 print(s[6:]) # world 从索引6开始,到最后一个元素 print(s[1:5:1]) # ello 从索引1开始,到4结束,步长为1 print(s[::2]) # hlowrd 从开始到结束,步长为2 print(s[::-1]) # dlrow,olleh 步长为负数,从最后一个元素(索引-1)开始,到第一个元素结束 print(s[-6::1]) # ,world 从索引-6开始,到最后一个结束
#isidentifier(): 指定された文字列が正当な識別子であるかどうかを判断します。
isspace(): 指定された文字列全体が空白文字 (キャリッジ リターン、ライン フィード、水平タブ文字) で構成されているかどうかを判断します。 isalpha(): 指定された文字列が完全に文字構成で構成されているかどうかを判断します。- isdecmal(): 指定された文字列が完全に 10 進数字で構成されているかどうかを判断します
- isnumeric() : 指定された文字列が完全に 10 進数で構成されているかどうかを判断します
- isalnum (): 指定された文字列が完全に文字と数字で構成されているかどうかを判断します
- その他の文字列操作
- 文字列置換
#replace()
s = 'hello,Python,Python,Python'
print(s.replace('Python', 'Java')) # 默认全部替换 hello,Java,Java,Java
print(s.replace('Python', 'Java', 2)) # 设置替换个数 hello,Java,Java,Python- join()
lst = ['hello', 'java', 'Python']
print(','.join(lst)) # hello,java,Python
print('|'.join(lst)) # hello|java|Pythonフォーマットされた文字列出力
% プレースホルダー: 出力の前に % を追加し、複数のパラメーターには括弧とカンマを使用します- %s string
-
- {} プレースホルダー: format() メソッドを呼び出します
- f-文字列: {} に変数を書き込みます
name = '张三' age = 20 print('我叫%s, 今年%d岁' % (name, age)) print('我叫{0}, 今年{1}岁,小名也叫{0}'.format(name, age)) print(f'我叫{name}, 今年{age}岁') # 我叫张三, 今年20岁 # 我叫张三, 今年20岁,小名也叫张三 # 我叫张三, 今年20岁ログイン後にコピー数値の幅と精度を設定します
# 设置数字的宽度和精度 '''%占位''' print('%10d' % 99) # 10表示宽度 print('%.3f' % 3.1415926) # .3f表示小数点后3位 print('%10.3f' % 3.1415926) # 同时设置宽度和精度 '''{}占位 需要使用:开始''' print('{:.3}'.format(3.1415926)) # .3表示3位有效数字 print('{:.3f}'.format(3.1415926)) # .3f表示小数点后3位 print('{:10.3f}'.format(3.1415926)) # .3f表示小数点后3位 # 99 #3.142 # 3.142 #3.14 #3.142 # 3.142ログイン後にコピー文字列エンコード s = '但愿人长久' # 编码 将字符串转换成byte(二进制)数据 print(s.encode(encoding='gbk')) #gbk,中文占用2个字节 print(s.encode(encoding='utf-8')) #utf-8,中文占用3个字节 # 解码 将byte(二进制)转换成字符串数据 # 编码与解码中,encoding方式需要一致 byte = s.encode(encoding='gbk') print(byte.decode(encoding='gbk')) # b'\xb5\xab\xd4\xb8\xc8\xcb\xb3\xa4\xbe\xc3' # b'\xe4\xbd\x86\xe6\x84\xbf\xe4\xba\xba\xe9\x95\xbf\xe4\xb9\x85' # 但愿人长久
ログイン後にコピーリスト list- 特性リストの数
順序付けされたシーケンス
一意のデータのインデックス マッピング
可以存储重复数据
任意数据类型混存
根据需要动态分配和回收内存
列表的创建
- []:使用中括号
- list():使用内置函数list()
- 列表生成式
语法格式:[i*i for i in range(i, 10)]
-
解释:i表示自定义变量,i*i表示列表元素的表达式,range(i, 10)表示可迭代对象
print([i * i for i in range(1, 10)])# [1, 4, 9, 16, 25, 36, 49, 64, 81]
ログイン後にコピー
列表元素的查询
- 判断指定元素在列表中是否存在
in / not in
- 列表元素的遍历
for item in list: print(item)
- 查询元素索引
list.index(item)
- 获取元素
list = [1, 4, 9, 16, 25, 36, 49, 64, 81]print(list[3]) # 16print(list[3:6]) # [16, 25, 36]
列表元素的增加
append():在列表的末尾添加一个元素
extend():在列表的末尾至少添加一个元素
insert0:在列表的指定位置添加一个元素
切片:在列表的指定位置添加至少一个元素
列表元素的删除
rerove():一次删除一个元素,
重复元素只删除第一个,
元素不存在抛出ValceError异常pop():删除一个指定索引位置上的元素,
指定索引不存在抛出IndexError异常,
不指定索引,删除列表中最后一个元素切片:一次至少删除一个元素
clear0:清空列表
del:删除列表
列表元素的排序
- sort(),列表中的所有元素默认按照从小到大的顺序进行排序,可以指定reverse= True,进行降序排序,是对原列表的操作。
list.sort()
- sorted(),可以指定reverse—True,进行降序排序,原列表不发生改变,产生新的列表。
sorted(list)
知识点总结
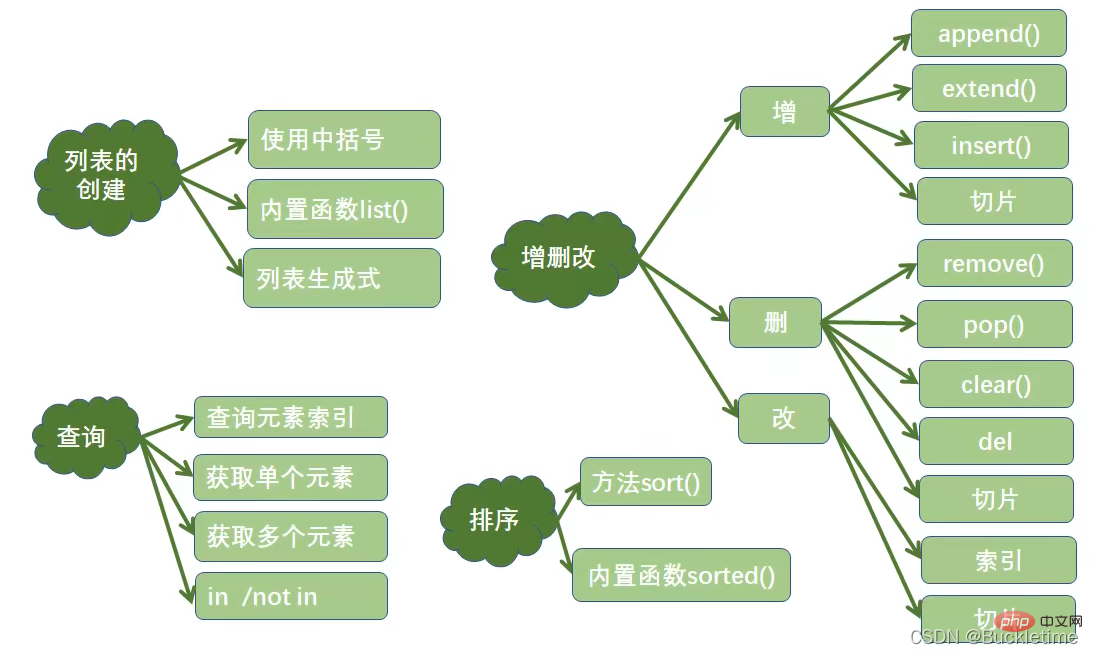
元组 tuple
元组的特点
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号
元组的创建
- 直接使用小括号(), 小括号可以省略
t = ('Python', 'hello', 90)- 使用内置函数tuple(), 若有多个元素必须加小括号
tuple(('Python', 'hello', 90))- 只包含一个元素的元组,需要使用小括号和逗号
t = (10,)
知识点总结
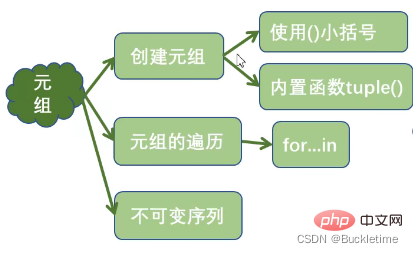
字典 dict
字典的特点
- 以键值对的方式存储,key唯一
- key必须是不可变对象
- 字典是可变序列
- 字典是无序序列 (注意:自Python3.7本后,dict 对象的插入顺序保留性质已被声明为 Python 语言规范的正式部分。即,Python3.7之后,字典是有序序列,顺序为字典的插入顺序)
字典的创建
- {}:使用花括号
- 使用内置函数dict()
- zip():字典生成式
items = ['fruits', 'Books', 'Others']
prices = [12, 36, 44]
d = {item.upper(): price for item, price in zip(items, prices)}
print(d) # {'FRUITS': 12, 'BOOKS': 36, 'OTHERS': 44}字典元素的获取
- []:[]取值
scores[‘张三’],若key不存在,抛出keyError异常 - get():get()方法取值,若key不存在,返回None,还可以设置默认返回值
字典元素的新增
user = {"id": 1, "name": "zhangsan"}
user["age"] = 25
print(user) # {'id': 1, 'name': 'zhangsan', 'age': 25}字典元素的修改
user = {"id": 1, "name": "zhangsan", "age": 25}
user["age"] = 18
print(user) # {'id': 1, 'name': 'zhangsan', 'age': 18}字典元素的删除
- del :删除指定的键值对或者删除字典
user = {"id": 1, "name": "zhangsan"}del user["id"]print(user) # {'name': 'zhangsan'}del user- claer():清空字典中的元素
user = {"id": 1, "name": "zhangsan"}user.clear()print(user) # {}获取字典视图
- keys():获取字典中所有key
- values():获取字典中所有value
- items():获取字典中所有key,value键值对
字典元素的遍历
- 遍历key,再通过key获取value
scores = {'张三': 100, '李四': 95, '王五': 88}for name in scores:
print(name, scores[name])- 通过items()方法,同时遍历key,value
scores = {'张三': 100, '李四': 95, '王五': 88}for name, score in scores.items():
print(name, score)知识点总结

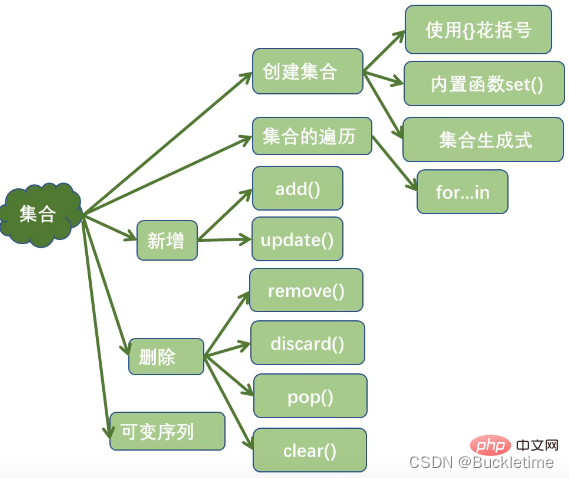
集合 set
集合的特点
- 集合是可变序列
- 集合是没有value的字典
- 集合中元素不重复
- 集合中元素是无序的
集合的创建
- {}
s = {'Python', 'hello', 90}- 内置函数set()
print(set("Python"))print(set(range(1,6)))print(set([3, 4, 7]))print(set((3, 2, 0)))print(set({"a", "b", "c"}))# 定义空集合:set()print(set())- 集合生成式
print({i * i for i in range(1, 10)})# {64, 1, 4, 36, 9, 16, 49, 81, 25}集合的操作
- 集合元素的判断操作
- in / not in
- 集合元素的新增操作
- add():一次添中一个元素
- update(:)添加多个元素
- 集合元素的删除操作
- remove():删除一个指定元素,如果指定的元素不存在抛出KeyError
- discard(:)删除一个指定元素,如果指定的元素不存在不抛异常
- pop():随机删除一个元素
- clear():清空集合
集合间的关系
两个集合是否相等:可以使用运算符 == 或 != 进行判断,只要元素相同就相等
一个集合是否是另一个集合的子集:issubset()
s1 = {10, 20, 30, 40, 50, 60}s2 = {10, 30, 40}s3 = {10, 70}print(s2.issubset(s1))
# Trueprint(s3.issubset(s1)) # False- 一个集合是否是另一个集合的超集:issuperset()
print(s1.issuperset(s2)) # Trueprint(s1.issuperset(s3)) # False
- 两个集合是否无交集:isdisjoint()
s1 = {10, 20, 30, 40, 50, 60}s2 = {10, 30, 40}s3 = {20, 70}print(s1.isdisjoint(s2))
# False 有交集print(s3.isdisjoint(s2)) # True 无交集集合的数学操作
- 交集: intersection() 与 &等价,两个集合的交集
s1 = {10, 20, 30, 40}s2 = {20, 30, 40, 50, 60}print(s1.intersection(s2)) # {40, 20, 30}print(s1 & s2) # {40, 20, 30}- 并集: union() 与 | 等价,两个集合的并集
print(s1.union(s2)) # {40, 10, 50, 20, 60, 30}print(s1 | s2) # {40, 10, 50, 20, 60, 30}- 差集: difference() 与 - 等价
print(s2.difference(s1)) # {50, 60}print(s2 - s1) # {50, 60}- 对称差集:symmetric_difference() 与 ^ 等价
print(s2.symmetric_difference(s1)) # {10, 50, 60}print(s2 ^ s1) # {10, 50, 60}知识点总结
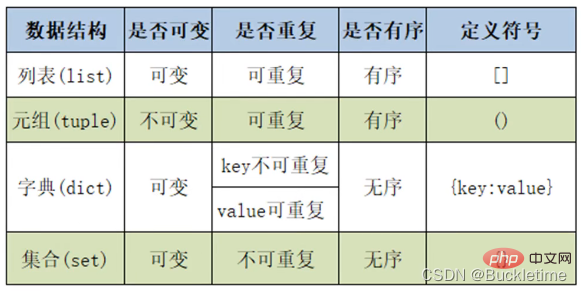
列表、元组、字典、集合总结
推荐学习:python教程
以上がPython3 データ構造の知識ポイントの詳細な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7466
7466
 15
1376
52
77
11
18
19
15
1376
52
77
11
18
19

 PSフェザーリングは、遷移の柔らかさをどのように制御しますか?
Apr 06, 2025 pm 07:33 PM
PSフェザーリングは、遷移の柔らかさをどのように制御しますか?
Apr 06, 2025 pm 07:33 PM
羽毛の鍵は、その漸進的な性質を理解することです。 PS自体は、勾配曲線を直接制御するオプションを提供しませんが、複数の羽毛、マッチングマスク、および細かい選択により、半径と勾配の柔らかさを柔軟に調整して、自然な遷移効果を実現できます。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
MySQLには、無料のコミュニティバージョンと有料エンタープライズバージョンがあります。コミュニティバージョンは無料で使用および変更できますが、サポートは制限されており、安定性要件が低く、技術的な能力が強いアプリケーションに適しています。 Enterprise Editionは、安定した信頼性の高い高性能データベースを必要とするアプリケーションに対する包括的な商業サポートを提供し、サポートの支払いを喜んでいます。バージョンを選択する際に考慮される要因には、アプリケーションの重要性、予算編成、技術スキルが含まれます。完璧なオプションはなく、最も適切なオプションのみであり、特定の状況に応じて慎重に選択する必要があります。
 PSフェザーリングをセットアップする方法は?
Apr 06, 2025 pm 07:36 PM
PSフェザーリングをセットアップする方法は?
Apr 06, 2025 pm 07:36 PM
PSフェザーリングは、イメージエッジブラー効果であり、エッジエリアのピクセルの加重平均によって達成されます。羽の半径を設定すると、ぼやけの程度を制御でき、値が大きいほどぼやけます。半径の柔軟な調整は、画像とニーズに応じて効果を最適化できます。たとえば、キャラクターの写真を処理する際に詳細を維持するためにより小さな半径を使用し、より大きな半径を使用してアートを処理するときにかすんだ感覚を作成します。ただし、半径が大きすぎるとエッジの詳細を簡単に失う可能性があり、効果が小さすぎると明らかになりません。羽毛効果は画像解像度の影響を受け、画像の理解と効果の把握に従って調整する必要があります。
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 MySQLインストール後に開始できないサービスのソリューション
Apr 08, 2025 am 11:18 AM
MySQLインストール後に開始できないサービスのソリューション
Apr 08, 2025 am 11:18 AM
MySQLは開始を拒否しましたか?パニックにならないでください、チェックしてみましょう!多くの友人は、MySQLのインストール後にサービスを開始できないことを発見し、彼らはとても不安でした!心配しないでください、この記事はあなたがそれを落ち着いて対処し、その背後にある首謀者を見つけるためにあなたを連れて行きます!それを読んだ後、あなたはこの問題を解決するだけでなく、MySQLサービスの理解と問題のトラブルシューティングのためのあなたのアイデアを改善し、より強力なデータベース管理者になることができます! MySQLサービスは開始に失敗し、単純な構成エラーから複雑なシステムの問題に至るまで、多くの理由があります。最も一般的な側面から始めましょう。基本知識:サービススタートアッププロセスMYSQLサービススタートアップの簡単な説明。簡単に言えば、オペレーティングシステムはMySQL関連のファイルをロードし、MySQLデーモンを起動します。これには構成が含まれます
 MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLのインストール障害の主な理由は次のとおりです。1。許可の問題、管理者として実行するか、SUDOコマンドを使用する必要があります。 2。依存関係が欠落しており、関連する開発パッケージをインストールする必要があります。 3.ポート競合では、ポート3306を占めるプログラムを閉じるか、構成ファイルを変更する必要があります。 4.インストールパッケージが破損しているため、整合性をダウンロードして検証する必要があります。 5.環境変数は誤って構成されており、環境変数はオペレーティングシステムに従って正しく構成する必要があります。これらの問題を解決し、各ステップを慎重に確認して、MySQLを正常にインストールします。
