

Vue3 の計算プロパティはどのように実装されますか?実装原則について話しましょう

Vue3 の計算プロパティはどのように実装されますか?次の記事では、Vue3.0 における計算プロパティの実装原理を簡単に分析します。

計算プロパティは、Vue.js 開発において非常に実用的な API であり、ユーザーは計算メソッドを定義し、依存関係に基づいて応答することができます。データは新しい値を計算して返します。依存関係が変更された場合、計算されたプロパティを自動的に再計算して新しい値を取得できるため、非常に便利に使用できます。
Vue.js 2.x では、計算されたプロパティのアプリケーションについてはすでによくご存じだと思いますが、コンポーネント オブジェクトで計算されたプロパティを定義できます。 Vue.js 3.0 では、Vue.js 2.x の使用法をコンポーネント内でも使用できますが、計算されたプロパティ API を単独で使用することもできます。
計算プロパティは本質的に依存関係の計算であるため、関数を直接使用しないのはなぜでしょうか? Vue.js 3.0 では、プロパティを計算するための API はどのように実装されていますか?この記事では、計算されたプロパティの実装原理を分析します。 (学習ビデオ共有: vuejs チュートリアル)
計算プロパティ API: computed
Vue.js 3.0 は、計算関数は計算属性 API として機能します。まずはその使い方を見てみましょう。
簡単な例を見てみましょう:
const count = ref(1) const plusOne = computed(() => count.value + 1) console.log(plusOne.value) // 2 plusOne.value++ // error count.value++ console.log(plusOne.value) // 3
コードからわかるように、最初に ref API を使用してレスポンシブ オブジェクト数を作成し、次に計算 API を使用して別のレスポンシブ オブジェクトを作成しました。 count.value を変更すると、plusOne.value は自動的に変更されます。
ここで plusOne.value を直接変更すると、エラーが報告されることに注意してください。これは、computed に渡すものが関数の場合、これはゲッター関数であり、その値を取得することしかできないためです。直接変更するのではありません。
ゲッター関数では、応答オブジェクトに基づいて新しい値を再計算します。そのため、計算プロパティと呼ばれます。この応答オブジェクトは計算プロパティの依存関係です。
もちろん、computed の戻り値を直接変更できるようにしたい場合もあります。その場合は、computed にオブジェクトを渡すことができます。
const count = ref(1)
const plusOne = computed({
get: () => count.value + 1,
set: val => {
count.value = val - 1
}
})
plusOne.value = 1
console.log(count.value) // 0この例では、上記と組み合わせています。コードを見ると、ゲッター関数とセッター関数を持つオブジェクトを計算関数に渡しました。ゲッター関数は以前と同様に count.value 1 を返します。セッター関数については、値を変更するときに注意してください。ここで plusOne.value を指定すると、setter 関数がトリガーされます。実際、setter 関数は、渡されたパラメータに従って計算された属性の依存関係の値 count.value を実際に変更します。計算された属性を取得するときにgetterを再実行するので、このようにして取得された値が変更されました。
さて、計算 API を使用する 2 つの方法がわかったので、それがどのように実装されるかを見てみましょう:
function computed(getterOrOptions) {
// getter 函数
let getter
// setter 函数
let setter
// 标准化参数
if (isFunction(getterOrOptions)) {
// 表面传入的是 getter 函数,不能修改计算属性的值
getter = getterOrOptions
setter = (process.env.NODE_ENV !== 'production')
? () => {
console.warn('Write operation failed: computed value is readonly')
}
: NOOP
}
else {
getter = getterOrOptions.get
setter = getterOrOptions.set
}
// 数据是否脏的
let dirty = true
// 计算结果
let value
let computed
// 创建副作用函数
const runner = effect(getter, {
// 延时执行
lazy: true,
// 标记这是一个 computed effect 用于在 trigger 阶段的优先级排序
computed: true,
// 调度执行的实现
scheduler: () => {
if (!dirty) {
dirty = true
// 派发通知,通知运行访问该计算属性的 activeEffect
trigger(computed, "set" /* SET */, 'value')
}
}
})
// 创建 computed 对象
computed = {
__v_isRef: true,
// 暴露 effect 对象以便计算属性可以停止计算
effect: runner,
get value() {
// 计算属性的 getter
if (dirty) {
// 只有数据为脏的时候才会重新计算
value = runner()
dirty = false
}
// 依赖收集,收集运行访问该计算属性的 activeEffect
track(computed, "get" /* GET */, 'value')
return value
},
set value(newValue) {
// 计算属性的 setter
setter(newValue)
}
}
return computed
}コードからわかるように、計算関数のプロセスでは主に 3 つの処理が行われます。内容: パラメータの標準化、副作用関数の作成、計算オブジェクトの作成。 これらの手順を詳しく分析してみましょう。
1 つ目は 標準化パラメータです。計算関数はゲッター関数とゲッター関数とセッター関数を持つオブジェクトの 2 種類のパラメーターを受け取り、パラメーターの型を判断して、関数内で定義されているゲッター関数とセッター関数を初期化します。
次のステップは、副作用関数ランナーを作成することです。 Computed は内部的に、ゲッター関数のカプセル化層であるエフェクトを通じて副作用関数を作成します。さらに、ここでの 2 番目のパラメーター (エフェクト関数の構成オブジェクト) に注意する必要があります。このうち、lazy は true (エフェクト関数によって返されたランナーがすぐには実行されないことを意味します)、computed は true (計算されたエフェクトであることを意味します) であり、トリガー ステージの優先順位の並べ替えに使用されます。後で分析します。スケジューラとは、そのスケジュールが実行されることを意味します。メソッドについても、後で分析します。
最後に、計算オブジェクトが作成されて返されます。このオブジェクトにはゲッター関数とセッター関数もあります。計算オブジェクトにアクセスするとゲッターが起動され、ダーティかどうかが判定され、ダーティであればランナーが実行され、依存関係の収集が行われます。 setter がトリガーされます。つまり、計算関数内で定義された setter 関数が実行されます。
計算されたプロパティの操作メカニズム
計算された関数のロジックは少し複雑になりますが、それは問題ではありません。計算プロパティの例を適用するメソッドと組み合わせて、計算プロパティ全体の動作メカニズムを理解できます。分析の前に、computed 内の 2 つの重要な変数を覚えておく必要があります。最初のダーティは、計算された属性の値が「ダーティ」であるかどうかを示し、再計算が必要かどうかを判断するために使用されます。2 番目の値は、計算された属性の各計算を示します. 最終結果。
次に、この例を見てみましょう:
<template>
<div>
{{ plusOne }}
</div>
<button @click="plus">plus</button>
</template>
<script>
import { ref, computed } from 'vue'
export default {
setup() {
const count = ref(0)
const plusOne = computed(() => {
return count.value + 1
})
function plus() {
count.value++
}
return {
plusOne,
plus
}
}
}
</script>可以看到,在这个例子中我们利用 computed API 创建了计算属性对象 plusOne,它传入的是一个 getter 函数,为了和后面计算属性对象的 getter 函数区分,我们把它称作 computed getter。另外,组件模板中引用了 plusOne 变量和 plus 函数。
组件渲染阶段会访问 plusOne,也就触发了 plusOne 对象的 getter 函数:
get value() {
// 计算属性的 getter
if (dirty) {
// 只有数据为脏的时候才会重新计算
value = runner()
dirty = false
}
// 依赖收集,收集运行访问该计算属性的 activeEffect
track(computed, "get" /* GET */, 'value')
return value
}由于默认 dirty 是 true,所以这个时候会执行 runner 函数,并进一步执行 computed getter,也就是 count.value + 1,因为访问了 count 的值,并且由于 count 也是一个响应式对象,所以就会触发 count 对象的依赖收集过程。
请注意,由于是在 runner 执行的时候访问 count,所以这个时候的 activeEffect 是 runner 函数。runner 函数执行完毕,会把 dirty 设置为 false,并进一步执行 track(computed,"get",'value') 函数做依赖收集,这个时候 runner 已经执行完了,所以 activeEffect 是组件副作用渲染函数。
所以你要特别注意这是两个依赖收集过程:对于 plusOne 来说,它收集的依赖是组件副作用渲染函数;对于 count 来说,它收集的依赖是 plusOne 内部的 runner 函数。
然后当我们点击按钮的时候,会执行 plus 函数,函数内部通过 count.value++ 修改 count 的值,并派发通知。请注意,这里不是直接调用 runner 函数,而是把 runner 作为参数去执行 scheduler 函数。我们来回顾一下 trigger 函数内部对于 effect 函数的执行方式:
const run = (effect) => {
// 调度执行
if (effect.options.scheduler) {
effect.options.scheduler(effect)
}
else {
// 直接运行
effect()
}
}computed API 内部创建副作用函数时,已经配置了 scheduler 函数,如下:
scheduler: () => {
if (!dirty) {
dirty = true
// 派发通知,通知运行访问该计算属性的 activeEffect
trigger(computed, "set" /* SET */, 'value')
}
}它并没有对计算属性求新值,而仅仅是把 dirty 设置为 true,再执行 trigger(computed, "set" , 'value'),去通知执行 plusOne 依赖的组件渲染副作用函数,即触发组件的重新渲染。
在组件重新渲染的时候,会再次访问 plusOne,我们发现这个时候 dirty 为 true,然后会再次执行 computed getter,此时才会执行 count.value + 1 求得新值。这就是虽然组件没有直接访问 count,但是当我们修改 count 的值的时候,组件仍然会重新渲染的原因。
通过下图可以直观的展现上述过程:

通过以上分析,我们可以看出 computed 计算属性有两个特点:
延时计算,只有当我们访问计算属性的时候,它才会真正运行 computed getter 函数计算;
缓存,它的内部会缓存上次的计算结果 value,而且只有 dirty 为 true 时才会重新计算。如果访问计算属性时 dirty 为 false,那么直接返回这个 value。
现在,我们就可以回答开头提的问题了。和单纯使用普通函数相比,计算属性的优势是:只要依赖不变化,就可以使用缓存的 value 而不用每次在渲染组件的时候都执行函数去计算,这是典型的空间换时间的优化思想。
嵌套计算属性
计算属性也支持嵌套,我们可以针对上述例子做个小修改,即不在渲染函数中访问 plusOne,而在另一个计算属性中访问:
const count = ref(0)
const plusOne = computed(() => {
return count.value + 1
})
const plusTwo = computed(() => {
return plusOne.value + 1
})
console.log(plusTwo.value)从代码中可以看到,当我们访问 plusTwo 的时候,过程和前面都差不多,同样也是两个依赖收集的过程。对于 plusOne 来说,它收集的依赖是 plusTwo 内部的 runner 函数;对于 count 来说,它收集的依赖是 plusOne 内部的 runner 函数。
接着当我们修改 count 的值时,它会派发通知,先运行 plusOne 内部的 scheduler 函数,把 plusOne 内部的 dirty 变为 true,然后执行 trigger 函数再次派发通知,接着运行 plusTwo 内部的 scheduler 函数,把 plusTwo 内部的 dirty 设置为 true。
然后当我们再次访问 plusTwo 的值时,发现 dirty 为 true,就会执行 plusTwo 的 computed getter 函数去执行 plusOne.value + 1,进而执行 plusOne 的 computed gette 即 count.value + 1 + 1,求得最终新值 2。
得益于 computed 这种巧妙的设计,无论嵌套多少层计算属性都可以正常工作。
计算属性的执行顺序
我们曾提到计算属性内部创建副作用函数的时候会配置 computed 为 true,标识这是一个 computed effect,用于在 trigger 阶段的优先级排序。我们来回顾一下 trigger 函数执行 effects 的过程:
const add = (effectsToAdd) => {
if (effectsToAdd) {
effectsToAdd.forEach(effect => {
if (effect !== activeEffect || !shouldTrack) {
if (effect.options.computed) {
computedRunners.add(effect)
}
else {
effects.add(effect)
}
}
})
}
}
const run = (effect) => {
if (effect.options.scheduler) {
effect.options.scheduler(effect)
}
else {
effect()
}
}
computedRunners.forEach(run)
effects.forEach(run)在添加待运行的 effects 的时候,我们会判断每一个 effect 是不是一个 computed effect,如果是的话会添加到 computedRunners 中,在后面运行的时候会优先执行 computedRunners,然后再执行普通的 effects。
那么为什么要这么设计呢?其实是考虑到了一些特殊场景,我们通过一个示例来说明:
import { ref, computed } from 'vue'
import { effect } from '@vue/reactivity'
const count = ref(0)
const plusOne = computed(() => {
return count.value + 1
})
effect(() => {
console.log(plusOne.value + count.value)
})
function plus() {
count.value++
}
plus()这个示例运行后的结果输出:
1 3 3
在执行 effect 函数时运行 console.log(plusOne.value + count.value),所以第一次输出 1,此时 count.value 是 0,plusOne.value 是 1。
后面连续输出两次 3 是因为, plusOne 和 count 的依赖都是这个 effect 函数,所以当我们执行 plus 函数修改 count 的值时,会触发并执行这个 effect 函数,因为 plusOne 的 runner 也是 count 的依赖,count 值修改也会执行 plusOne 的 runner,也就会再次执行 plusOne 的依赖即 effect 函数,因此会输出两次。
那么为什么两次都输出 3 呢?这就跟先执行 computed runner 有关。首先,由于 plusOne 的 runner 和 effect 都是 count 的依赖,当我们修改 count 值的时候, plusOne 的 runner 和 effect 都会执行,那么此时执行顺序就很重要了。
这里先执行 plusOne 的 runner,把 plusOne 的 dirty 设置为 true,然后通知它的依赖 effect 执行 plusOne.value + count.value。这个时候,由于 dirty 为 true,就会再次执行 plusOne 的 getter 计算新值,拿到了新值 2, 再加上 1 就得到 3。执行完 plusOne 的 runner 以及依赖更新之后,再去执行 count 的普通effect 依赖,从而去执行 plusOne.value + count.value,这个时候 plusOne dirty 为 false, 直接返回上次的计算结果 2,然后再加 1 就又得到 3。
如果我们把 computed runner 和 effect 的执行顺序换一下会怎样呢?我来告诉你,会输出如下结果:
1 2 3
第一次输出 1 很好理解,因为流程是一样的。第二次为什么会输出 2 呢?我们来分析一下,当我们执行 plus 函数修改 count 的值时,会触发 plusOne 的 runner 和 effect 的执行,这一次我们先让 effect 执行 plusOne.value + count.value,那么就会访问 plusOne.value,但由于 plusOne 的 runner 还没执行,所以此时 dirty 为 false,得到的值还是上一次的计算结果 1,然后再加 1 得到 2。
接着再执行 plusOne 的 runner,把 plusOne 的 dirty 设置为 true,然后通知它的依赖 effect 执行 plusOne.value + count.value,这个时候由于 dirty 为 true,就会再次执行 plusOne 的 getter 计算新值,拿到了 2,然后再加上 1 就得到 3。
知道原因后,我们再回过头看例子。因为 effect 函数依赖了 plusOne 和 count,所以 plusOne 先计算会更合理,这就是为什么我们需要让 computed runner 的执行优先于普通的 effect 函数。
总结
本文分析了计算属性的工作机制、计算属性嵌套代码的执行顺序,以及计算属性的两个特点——延时计算和缓存。
本文转载自:https://juejin.cn/post/7085524315063451684
作者:风度前端
(学习视频分享:web前端开发)
以上がVue3 の計算プロパティはどのように実装されますか?実装原則について話しましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7755
7755
 15
1643
14
1399
52
1293
25
1234
29
15
1643
14
1399
52
1293
25
1234
29

 vue3 プロジェクトで tinymce を使用する方法
May 19, 2023 pm 08:40 PM
vue3 プロジェクトで tinymce を使用する方法
May 19, 2023 pm 08:40 PM
tinymce はフル機能のリッチ テキスト エディター プラグインですが、tinymce を vue に導入するのは他の Vue リッチ テキスト プラグインほどスムーズではありません。tinymce 自体は Vue には適しておらず、@tinymce/tinymce-vue を導入する必要があります。外国のリッチテキストプラグインであり、中国語版を通過していないため、公式 Web サイトから翻訳パッケージをダウンロードする必要があります (ファイアウォールをバイパスする必要がある場合があります)。 1. 関連する依存関係をインストールします npminstalltinymce-Snpminstall@tinymce/tinymce-vue-S2. 中国語パッケージをダウンロードします 3. スキンと中国語パッケージを導入します. プロジェクトのパブリック フォルダーに新しい tinymce フォルダーを作成し、
 vue3+vite: src に画像を動的にインポートするために require を使用するときのエラーを解決する方法
May 21, 2023 pm 03:16 PM
vue3+vite: src に画像を動的にインポートするために require を使用するときのエラーを解決する方法
May 21, 2023 pm 03:16 PM
vue3+vite:src は、イメージとエラー レポートと解決策を動的にインポートするために require を使用します。vue3+vite は複数のイメージを動的にインポートします。vue3。TypeScript 開発を使用している場合、イメージを導入するために require のエラー メッセージが表示されます。requireisnotdefined は使用できません。 vue2 のような imgUrl:require(' .../assets/test.png') は、typescript が require をサポートしていないため、インポートされます。そのため、import が使用されます。解決方法は次のとおりです: awaitimport を使用します
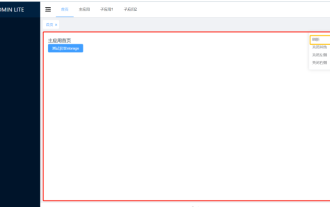 Vue3 でページの部分的なコンテンツを更新する方法
May 26, 2023 pm 05:31 PM
Vue3 でページの部分的なコンテンツを更新する方法
May 26, 2023 pm 05:31 PM
ページの部分的な更新を実現するには、ローカル コンポーネント (dom) の再レンダリングを実装するだけで済みます。 Vue でこの効果を実現する最も簡単な方法は、v-if ディレクティブを使用することです。 Vue2 では、v-if 命令を使用してローカル dom を再レンダリングすることに加えて、新しい空のコンポーネントを作成することもできます。ローカル ページを更新する必要がある場合は、この空のコンポーネント ページにジャンプしてから、再びジャンプします。 beforeRouteEnter ガードを空白のコンポーネントに配置します。元のページ。以下の図に示すように、Vue3.X の更新ボタンをクリックして赤枠内の DOM を再読み込みし、対応する読み込みステータスを表示する方法を示します。 Vue3.X の scriptsetup 構文のコンポーネントのガードには o しかないので、
 Vue3 がマークダウンを解析し、コードのハイライトを実装する方法
May 20, 2023 pm 04:16 PM
Vue3 がマークダウンを解析し、コードのハイライトを実装する方法
May 20, 2023 pm 04:16 PM
Vue はブログ フロントエンドを実装しており、マークダウン解析を実装する必要があり、コードがある場合はコードのハイライトを実装する必要があります。 Vue には、markdown-it、vue-markdown-loader、marked、vue-markdown など、マークダウン解析ライブラリが多数あります。これらのライブラリはすべて非常に似ています。ここではMarkedが使用され、コード強調表示ライブラリとしてhighlight.jsが使用されます。 1. 依存ライブラリをインストールする vue プロジェクトの下でコマンド ウィンドウを開き、次のコマンド npminstallmarked-save//marked を入力して、マークダウンを htmlnpmins に変換します。
 vue3+ts+axios+pinia を使用して無意味なリフレッシュを実現する方法
May 25, 2023 pm 03:37 PM
vue3+ts+axios+pinia を使用して無意味なリフレッシュを実現する方法
May 25, 2023 pm 03:37 PM
vue3+ts+axios+pinia で無意味なリフレッシュを実現 1. まず、プロジェクト内の aiXos と pinianpmipinia をダウンロードします--savenpminstallaxios--save2. axios リクエストをカプセル化-----ダウンロード js-cookienpmiJS-cookie-s// aixosimporttype{AxiosRequestConfig , AxiosResponse}from"axios";importaxiosfrom'axios';import{ElMess
 Vue3 の再利用可能なコンポーネントの使用方法
May 20, 2023 pm 07:25 PM
Vue3 の再利用可能なコンポーネントの使用方法
May 20, 2023 pm 07:25 PM
はじめに vue であれ、react であれ、複数の繰り返しコードに遭遇した場合、ファイルを冗長なコードの束で埋めるのではなく、これらのコードを再利用する方法を考えます。実際、vue と React はどちらもコンポーネントを抽出することで再利用を実現できますが、小さなコードの断片に遭遇し、別のファイルを抽出したくない場合は、それに比べて、React は同じファイル内で対応するウィジェットを宣言して使用できます。または、次のような renderfunction を通じて実装します。 constDemo:FC=({msg})=>{returndemomsgis{msg}}constApp:FC=()=>{return(
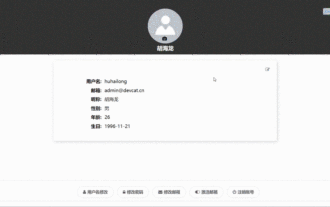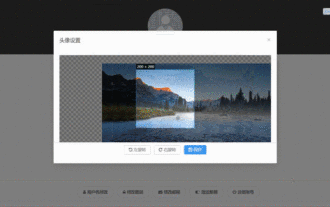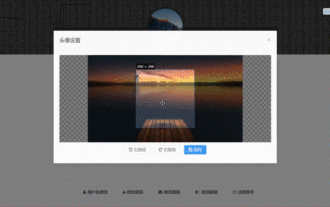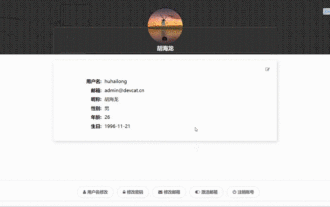 Vue3 でアバターを選択してトリミングする方法
May 29, 2023 am 10:22 AM
Vue3 でアバターを選択してトリミングする方法
May 29, 2023 am 10:22 AM
最終的な効果は、VueCropper コンポーネントのyarnaddvue-cropper@next をインストールすることです。上記のインストール値は Vue3 用です。Vue2 の場合、または他の方法を参照したい場合は、公式 npm アドレス: 公式チュートリアルにアクセスしてください。また、コンポーネント内で参照して使用するのも非常に簡単です。必要なのは、対応するコンポーネントとそのスタイル ファイルを導入することだけです。ここではグローバルに参照しませんが、import{userInfoByRequest}from'../js/api を導入するだけです。 ' コンポーネント ファイルにインポートします。import{VueCropper}from'vue-cropper&
 DefineCustomElement を使用して Vue3 でコンポーネントを定義する方法
May 28, 2023 am 11:29 AM
DefineCustomElement を使用して Vue3 でコンポーネントを定義する方法
May 28, 2023 am 11:29 AM
Vue を使用してカスタム要素を構築する WebComponents は、開発者が再利用可能なカスタム要素 (カスタム要素) を作成できるようにする一連の Web ネイティブ API の総称です。カスタム要素の主な利点は、フレームワークがなくても、任意のフレームワークで使用できることです。これらは、異なるフロントエンド テクノロジ スタックを使用している可能性のあるエンド ユーザーをターゲットにする場合、または最終アプリケーションを使用するコンポーネントの実装の詳細から切り離したい場合に最適です。 Vue と WebComponents は補完的なテクノロジであり、Vue はカスタム要素の使用と作成に対する優れたサポートを提供します。カスタム要素を既存の Vue アプリケーションに統合したり、Vue を使用してビルドしたりできます。
