

Python によるマルチスレッド クローラーと一般的な検索アルゴリズムの詳細な分析

この記事では、python に関する関連知識を提供します。主にマルチスレッド クローラー開発と一般的な検索アルゴリズムに関連する問題を紹介します。一緒に見てみましょう。皆さんのお役に立てれば幸いです。 。 ヘルプ。

マルチスレッド クローラー
マルチスレッドの利点
リクエストと正規表現をマスターしたら、いくつかの単純な URL を実際にクロールし始めることができます。 ただし、この時点のクローラは 1 つのプロセスと 1 つのスレッドしか持たないため、
したがって、シングルスレッド クローラー と呼ばれます。シングルスレッド クローラーは一度に 1 ページしかアクセスしないため、コンピューターのネットワーク帯域幅を十分に活用できません。ページは最大でも数百 KB にすぎないため、クローラーがページをクロールすると、追加のネットワーク速度と、リクエストの開始からソース コードの取得までの時間が無駄になります。 クローラが同時に 10 ページにアクセスできる場合、クローラ速度が 10 倍になることと同じです。この目標を達成するには、マルチスレッド テクノロジを使用する必要があります。
マルチプロセッシングの下にはダミー モジュールがあり、Python スレッドでさまざまなマルチプロセッシング方法を使用できるようになります。 ダミーの下に Pool クラスがあり、スレッド プールの実装に使用されます。
このスレッド プールには、map() メソッドがあり、これにより、スレッド プール内のすべてのスレッドが関数を「同時に」実行できるようになります。
for ループを学習した後
for i in range(10): print(i*i)
from multiprocessing.dummy import Pooldef cal_pow(num):
return num*num
pool=Pool(3)num=[x for x in range(10)]result=pool.map(cal_pow,num)print('{}'.format(result))は最初に二乗を計算する関数を定義し、次に 3 つのスレッドでスレッド プールを初期化します。これら 3 つのスレッドは、10 の数値の 2 乗を計算する役割を果たします。最初に手持ちの数値の計算を終えた人が次の数値を取得し、すべての数値が計算されるまで計算を続けます。
この例では、スレッド プールの map() メソッドは 2 つのパラメーターを受け取ります。最初のパラメーターは関数名で、2 番目のパラメーターはリストです。注: 最初のパラメータは関数の名前のみであり、括弧 を含めることはできません。 2 番目のパラメータは反復可能オブジェクトであり、この反復可能オブジェクトの各要素は関数 clac_power2() によってパラメータとして受け取られます。リストに加えて、タプル、セット、または辞書を、map() の 2 番目のパラメータとして使用できます。
マルチスレッド クローラー開発クローラーは、特に Web ページのソース コードをリクエストする場合に I/O 集約型の操作であるため、単一のスレッドを使用して開発すると大量の時間を無駄にすることになります。 Web ページが返されるまで待機するため、クローラにマルチスレッド技術を適用すると、クローラの動作効率が大幅に向上します。例として。洗濯機で服を洗うのに50分、やかんでお湯を沸かすのに15分、単語を覚えるのに1時間かかります。まず洗濯機が洗濯するのを待って、洗濯が終わったらお湯を沸かし、沸騰したら単語を暗唱すると、合計125分かかります。 しかし、別の言い方をすると、全体として見ると、3 つのことが同時に実行できます。突然、他に 2 人がいて、そのうちの 1 人が衣類を洗濯機に入れる担当だとします。洗濯機が終わるのを待っている、お湯を沸かして水が沸騰するのを待つのは別の人が担当しており、単語を覚えるだけで済みます。水が沸騰すると、水を沸騰させる役割を果たしたクローンが最初に消えます。洗濯機が衣類の洗濯を終えると、衣類の洗濯を担当していたクローンが消滅します。最後に、単語を自分で覚えます。 3つのことを同時に完了するのにかかる時間はわずか60分です。もちろん、上記の例が人生の実際の状況ではないことは誰でも間違いなくわかるでしょう。実際には、誰も分離されていません。現実の生活では、人は単語を覚えるとき、その単語を覚えることに集中します。お湯が沸騰すると、やかんが音を立てて思い出させます。服を洗うとき、洗濯機が「ディディ」という音を出します。 。したがって、リマインダーが来たら、対応するアクションを実行するだけでよく、毎分確認する必要はありません。上記の 2 つの違いは、実際にはマルチスレッド モデルとイベント ドリブンの非同期モデルの違いです。このセクションではマルチスレッド操作について説明します。非同期操作を使用するクローラー フレームワークについては後ほど説明します。ここで覚えておいてほしいのは、操作する必要があるアクションの数がそれほど多くない場合、2 つのメソッドのパフォーマンスに違いはありませんが、アクションの数が大幅に増加すると、マルチスレッドの効率向上が大きくなるということです。減少し、シングルスレッドよりもさらに悪化します。その時点では、非同期操作のみが問題の解決策となります。
次の 2 つのコードは、bd ホームページのクロールにおけるシングルスレッド クローラーとマルチスレッド クローラーのパフォーマンスの違いを比較するために使用されます。 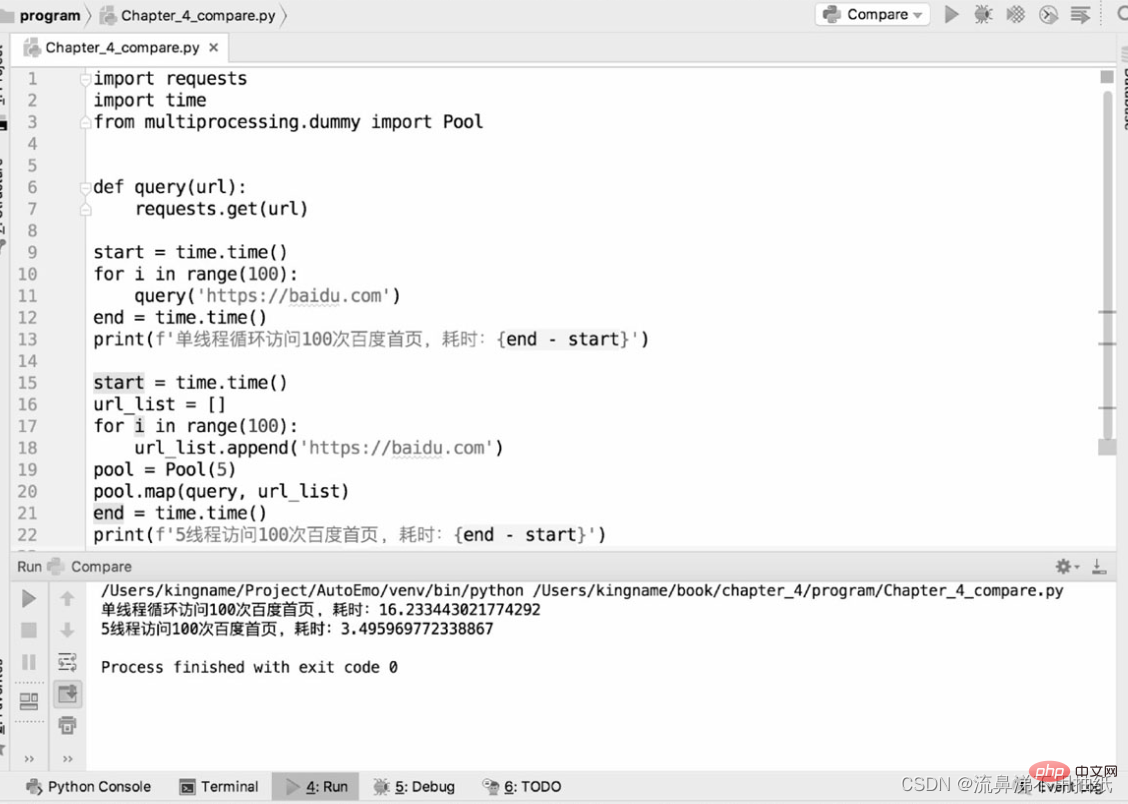
実行結果からわかるように、 1 つのスレッドには約 16.2 秒かかります。5 スレッドには約 3.5 秒かかります。これは、単一スレッドの時間の約 5 分の 1 です。 5 つのスレッドが「同時に実行」されることの効果を時間の観点から見ることもできます。ただし、スレッド プールが大きければ大きいほど良いというわけではありません。上記の結果から、5 つのスレッドの実行時間は、実際には 1 つのスレッドの実行時間の 5 分の 1 を少し超えることもわかります。追加のポイントは、実際にはスレッドの切り替えの時間です。これは、Python のマルチスレッドが依然としてマイクロ レベルでシリアルであることを側面から反映しています。したがって、スレッド プールの設定が大きすぎると、スレッドの切り替えによって発生するオーバーヘッドがマルチスレッドによるパフォーマンスの向上を相殺する可能性があります。スレッド プールのサイズは実際の状況に応じて決定する必要があり、正確なデータはありません。リーダーは、特定のアプリケーション シナリオでのテストと比較のためにさまざまなサイズを設定し、最適なデータを見つけることができます。
クローラーの一般的な検索アルゴリズム
深さ優先検索
オンライン教育 Web サイトのコース分類をクロールする必要があるコース情報。コースはホームページから始まり、言語ごとに Python、Node.js、Golang などのいくつかの主要なカテゴリに分かれています。クローラー、Django、Python での機械学習など、主要なカテゴリごとに多くのコースがあります。各コースは多くの授業時間に分かれています。
深さ優先探索の場合、巡回ルートは図のようになります(小さい順に通し番号)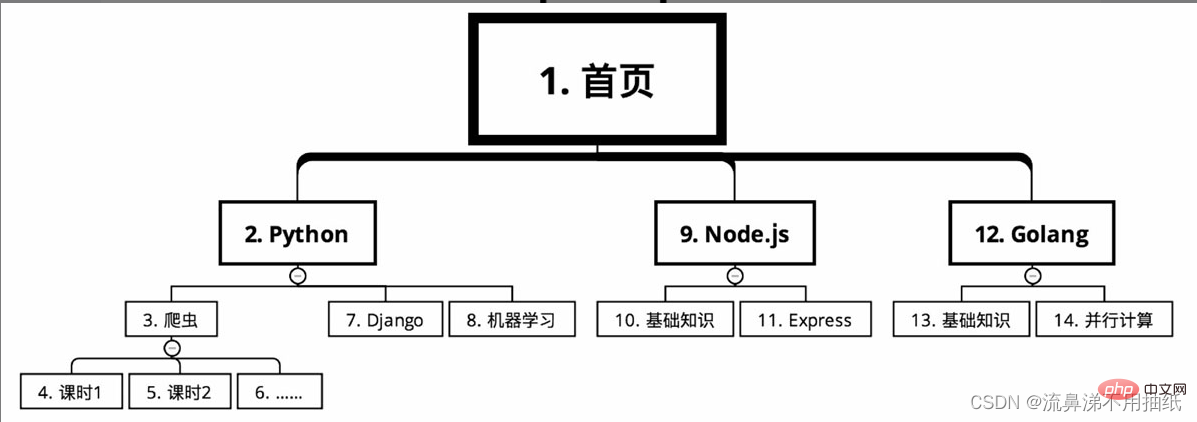
幅優先探索
シーケンス 以下の 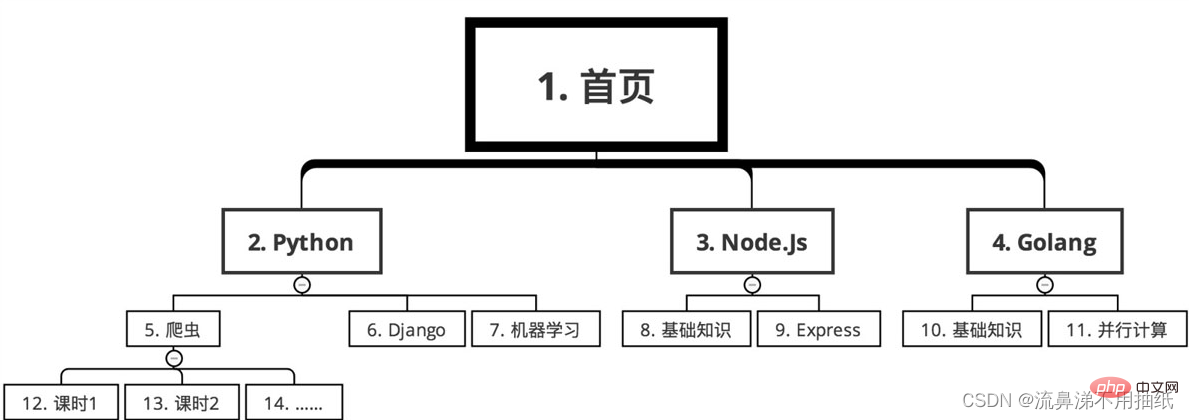
以上がPython によるマルチスレッド クローラーと一般的な検索アルゴリズムの詳細な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7322
7322
 9
1625
14
1350
46
1262
25
1209
29
9
1625
14
1350
46
1262
25
1209
29

 ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
多くのウェブサイト開発者は、ランプアーキテクチャの下でnode.jsまたはPythonサービスを統合する問題に直面しています:既存のランプ(Linux Apache MySQL PHP)アーキテクチャWebサイトのニーズ...
 LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示する際の許可の問題の解決策PythonターミナルでPythonバージョンを表示しようとするとき、Pythonを入力してください...
 Scapy Crawlerを使用するときにパイプラインの永続的なストレージファイルを書き込めない理由は何ですか?
Apr 01, 2025 pm 04:03 PM
Scapy Crawlerを使用するときにパイプラインの永続的なストレージファイルを書き込めない理由は何ですか?
Apr 01, 2025 pm 04:03 PM
Scapy Crawlerを使用する場合、パイプラインの永続的なストレージファイルを書くことができない理由は?ディスカッションデータクローラーにScapy Crawlerを使用することを学ぶとき、あなたはしばしば...
 Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python:Hourglassグラフィック図面と入力検証この記事では、Python NoviceがHourglass Graphic Drawingプログラムで遭遇する可変定義の問題を解決します。コード...
 PythonプロセスプールがTCPリクエストを同時に処理し、クライアントが立ち往生する理由は何ですか?
Apr 01, 2025 pm 04:09 PM
PythonプロセスプールがTCPリクエストを同時に処理し、クライアントが立ち往生する理由は何ですか?
Apr 01, 2025 pm 04:09 PM
Python Process Poolは、クライアントが立ち往生する原因となる同時TCP要求を処理します。ネットワークプログラミングにPythonを使用する場合、同時のTCP要求を効率的に処理することが重要です。 ...
 Python functools.partialオブジェクトによって内部的にカプセル化された元の関数を表示する方法は?
Apr 01, 2025 pm 04:15 PM
Python functools.partialオブジェクトによって内部的にカプセル化された元の関数を表示する方法は?
Apr 01, 2025 pm 04:15 PM
python functools.partialオブジェクトのpython functools.partialを使用してPythonを使用する視聴方法を深く探索します。
 Pythonクロスプラットフォームデスクトップアプリケーション開発:どのGUIライブラリが最適ですか?
Apr 01, 2025 pm 05:24 PM
Pythonクロスプラットフォームデスクトップアプリケーション開発:どのGUIライブラリが最適ですか?
Apr 01, 2025 pm 05:24 PM
Pythonクロスプラットフォームデスクトップアプリケーション開発ライブラリの選択多くのPython開発者は、WindowsシステムとLinuxシステムの両方で実行できるデスクトップアプリケーションを開発したいと考えています...
 GoogleとAWSはパブリックピピイメージソースを提供していますか?
Apr 01, 2025 pm 05:15 PM
GoogleとAWSはパブリックピピイメージソースを提供していますか?
Apr 01, 2025 pm 05:15 PM
多くの開発者はPypi(PythonPackageIndex)に依存しています...
