

PythonのSeabornについて詳しく解説(データ可視化)

この記事では、データ視覚化処理のための散布図、折れ線グラフ、棒グラフなど、Seaborn に関連する問題を主に紹介する python に関する関連知識を紹介します。 以下の内容を見てみましょう。 , 皆様のお役に立てれば幸いです。

1. seaborn をインストールします
インストール:
##pip install seaborn##インポート:
#seaborn を sns としてインポートします
2. データを準備します
正式に開始する前に、まず次のコードを使用してセットを準備します便宜上のデータの使用法をデモンストレーションします。
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snspd.set_option('display.unicode.east_asian_width', True)df1 = pd.DataFrame( {'数据序号': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12], '厂商编号': ['001', '001', '001', '002', '002', '002', '003', '003', '003', '004', '004', '004'], '产品类型': ['AAA', 'BBB', 'CCC', 'AAA', 'BBB', 'CCC', 'AAA', 'BBB', 'CCC', 'AAA', 'BBB', 'CCC'], 'A属性值': [40, 70, 60, 75, 90, 82, 73, 99, 125, 105, 137, 120], 'B属性值': [24, 36, 52, 32, 49, 68, 77, 90, 74, 88, 98, 99], 'C属性值': [30, 36, 55, 46, 68, 77, 72, 89, 99, 90, 115, 101] })print(df1)次のようにデータ セットを生成します:
1 つの位置境界線
3.1 背景スタイルを設定します。スタイルの設定には sns.set_style() メソッドが使用され、ここでの組み込みスタイルは背景色を使用して名前を表しますが、実際の内容は背景色に限定されません。
# sns.set_style()
選択できる背景スタイルは次のとおりです。
#白グリッド白グリッド濃い灰色の背景
白白背景
- ticks 白い背景とその周りの目盛り
- ## sns.set()
- sns.set_style( "darkgrid") sns.set_style("whitegrid") sns.set_style("dark") sns.set_style("white")
- ## sns.set_style("ticks")
ここで、 sns.set() は、カスタム スタイルを使用することを意味します。パラメーターが渡されない場合、デフォルトはグレーです。グリッドの背景スタイル。 set() または set_style() がない場合、背景は白になります。
考えられるバグ: 「ティック」スタイルは、relplot() メソッドを使用して描画された画像には無効です。
3.3 その他
seaborn ライブラリは matplotlib ライブラリに基づいてカプセル化されており、そのカプセル化されたスタイルにより描画作業がより便利になります。 matplotlib ライブラリで一般的に使用されるステートメントは、seaborn ライブラリを使用する場合でも有効です。
フォントなどのその他のスタイル関連プロパティの設定については、これらのコードを有効にするには sns.set_style() の後に記述する必要があることに注意してください。たとえば、フォントを太字に設定するコード (中国語の文字化けを避けるため):
##plt.rcParams['font.sans-serif' ] = [' SimHei']
スタイルが背後に設定されている場合、設定されたフォントが設定されたスタイルをオーバーライドするため、警告が生成されます。他の属性についても同様です。
3.2 境界線制御
sns.despine() メソッド
# 移除顶部和右部边框,只保留左边框和下边框sns.despine()# 使两个坐标轴相隔一段距离(以10长度为例)sns.despine(offet=10,trim=True)# 移除左边框sns.despine(left=True)# 移除指定边框 (以只保留底部边框为例)sns.despine(fig=None, ax=None, top=True, right=True, left=True, bottom=False, offset=None, trim=False)
4 . 散布図を描画する
seaborn ライブラリを使用して散布図を描画します。replot() メソッドまたはscatter() メソッドを使用できます。
replot メソッドのパラメーターの種類はデフォルトで「散布図」に設定されており、散布図を描画することを意味します。
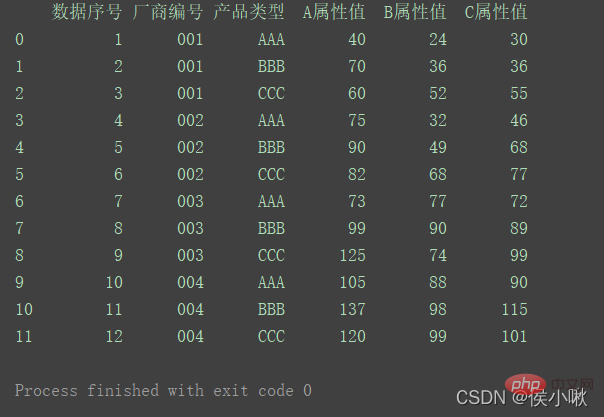
色相パラメータは、この次元では色で区別されることを示します① A 属性値とデータシーケンス番号、赤色の散布点、灰色のグリッドの散布図を描画します、左を維持し、下の境界線を維持しますsns.set_style('darkgrid')
plt.rcParams['font.sans-serif'] = ['SimHei' ]
sns.relplot(x='データシリアル番号', y='属性値', data=df1, color='red')
plt.show()
② A 属性値とデータ シーケンス番号の散布図を描画します。散布点は、異なる製品タイプに応じて異なる色で表示されます。 sns.set_style('whitegrid') ③ 3 つのフィールド A 属性、B 属性、C 属性の値を異なるスタイルで同じグラフ上にプロットします (散布図を描きます)。 -軸データは [0,2,4 ,6,8…] ## sns.set_style('ticks') plt.rcParams['font.sans-serif'] = ['STKAITI'] ① 要件: A 属性値とデータのシリアル番号の折れ線グラフを描画し、 sns.relplot (x='データシリアル番号', y='属性値', hue='商品タイプ', data=df1, kind='線') plt.title("折れ線グラフを描く", fontsize= 18) df2 = df1.copy() plt.title(“折れ線グラフを描く”, fontsize=18) plt.xlabel('num', fontsize=18) ## 水平複数サブグラフcol ##sns.set_style('darkgrid') plt.rcParams['font.sans-serif'] = [ ' STKAITI'] sns.set_style('darkgrid') sns.relplot (data=df1, x="A 属性値", y="B 属性値", kind="line", row="メーカー番号") plt.subplots_adjust(左=0.15, 右= 0.9, 下=0.1, top=0.95) #sns.set_style('darkgrid') plt.rcParams['font.sans-serif'] = ['STKAITI'] sns.lineplot(x='データシリアル番号', y= '属性値', data=df1, color='purple' ) plt.ylabel('属性値', fontsize=16) plt.subplots_adjust(left=0.15, right=0.9,bottom=0.1, top=0.9) dfs = [df2['A 属性値'], df2[ 'B 属性値'], df2[' C 属性値']] plt.subplots_adjust(left=0.15, right=0.9,bottom=0.1, top=0.9) plt.show() sns.set_style('darkgrid') sns.displot(data =df1[['C 属性値']], bins=6, Rug=True, kde =True) plt.title("ヒストグラム", fontsize=18) plt.xlabel('C 属性値', fontsize=18) � � � � � � � � barplot() メソッドは、 bar chart sns.set_style('darkgrid') ^ ^ ^ ^ ˜ 。 各行のサブピクチャの数を制御するには、col_wrap を使用します; サイズを使用して、サブピクチャの高さを制御します; 合計密度マップを描画すると、サンプル データの分布特性をより直感的に明確に確認できるようになります。カーネル密度プロットの描画に使用されるメソッドは kdeplot() メソッドです。 plt.title("カーネル密度プロット", fontsize=18) plt.xlabel('Value', fontsize=18) sns.jointplot(x=df1["A 属性値"] , y=df1["B 属性値"], kind="kde", space=0) 色相も指定できます。 ) 生成後、箱ひげ図の描画を開始します: #plt.rcParams['font.sans-serif'] = [' STKAITI'] sns.boxplot(x='商品タイプ', y='XXX 属性値', data=df2) � sns.boxplot(y='商品タイプ', x='XXX属性値', data=df2) plt.show( ) ##plt.rcParams['font.sans-serif'] = ['STKAITI'] plt.show() ##11. バイオリンプロットを描く Violinplot() plt.show() 双世丘の当選番号データを例として取り上げます。ヒート マップを描画します。ここでのデータはランダムです。数値生成。 import seaborn as sns s3 = np.random.randint(0, 200, 33) s4 = np.random.randint(0, 200 , 33) s5 = np.random.randint(0, 200, 33) data = pd.DataFrame( {'一': s1,
白いグリッド、左と下の境界線:
plt.rcParams['font.sans-serif'] = ['SimHei']
sns.relplot(x= ' データシリアル番号', y='属性値', hue='商品タイプ', data=df1)
plt.show()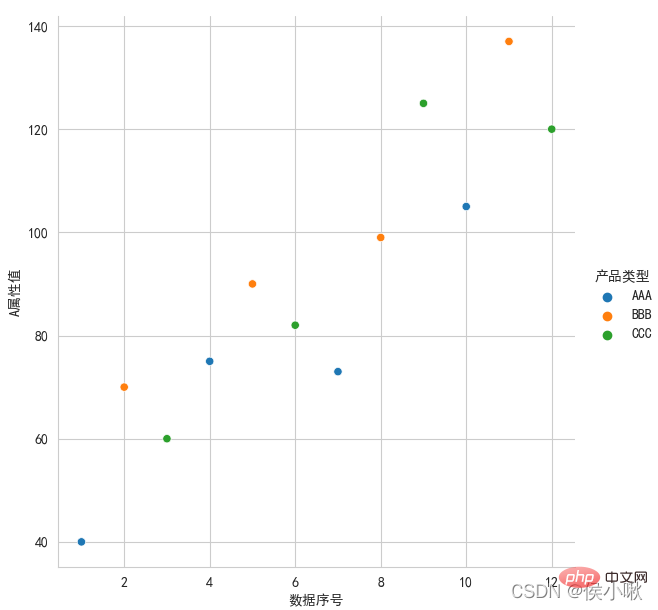
目盛スタイル (4 方向すべての枠線が必要)、フォントはイタリック体を使用します
plicity replot() メソッドまたは lineplot() メソッドを使用します。
df2 = df1.copy()
df2.index = list(range( 0, len(df2)*2, 2 ))
dfs = [df2['A 属性値'], df2['B 属性値'], df2['C 属性値']]
sns。 scatterplot(data=dfs)
plt .show()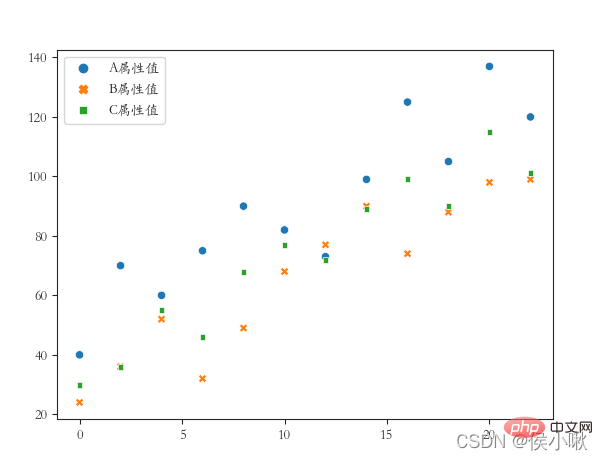
sns.replot() はデフォルトで散布図を描画します。折れ線グラフを描画するには、kind パラメータを「」に変更するだけです。ライン" 。 および 座標系とキャンバスの端の間の距離 (フォントが完全に表示されないため、距離が設定されます):
##sns.set (rc={'font.sans-serif ': "STKAITI"})
sns.relplot(x='データシリアル番号', y='属性値', data=df1, color='purple', kind='line')
plt. title("折れ線グラフを描く", fontsize=18)
plt.xlabel('num', fontsize=18) plt.ylabel('A 属性値', fontsize=16) plt.subplots_adjust (left=0.15, right=0.9,bottom=0.1, top=0.9)
② 要件: さまざまな製品タイプの属性ポリライン (1 つの図に 3 本の線)、白グリッド スタイル、斜体フォントを描画します。 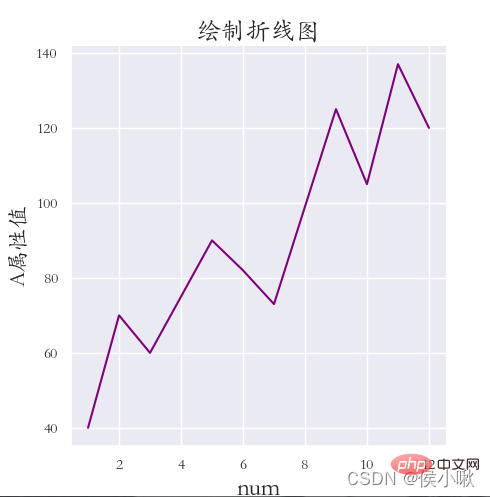
plt.rcParams['font.sans-serif'] = ['STKAITI']
plt.xlabel('num', fontsize=18) plt.ylabel('A 属性値', fontsize=16) plt.show()
plt.rcParams['font.sans-serif'] = ['STKAITI']
^ ^ ^ ^ ^ ^ 3 つのフィールド A、B、および C の値は次のように描画されます。同じグラフ上で異なるスタイルを使用 (折れ線グラフの描画) x 軸のデータは [0,2,4,6,8…]
です。 ◆ darkkgrid スタイル (4 方向すべての枠線を含める必要があります) を使用します。フォントには斜体を使用し、X 軸のラベル、Y 軸のラベル、タイトルを追加します。エッジの距離は適切です。 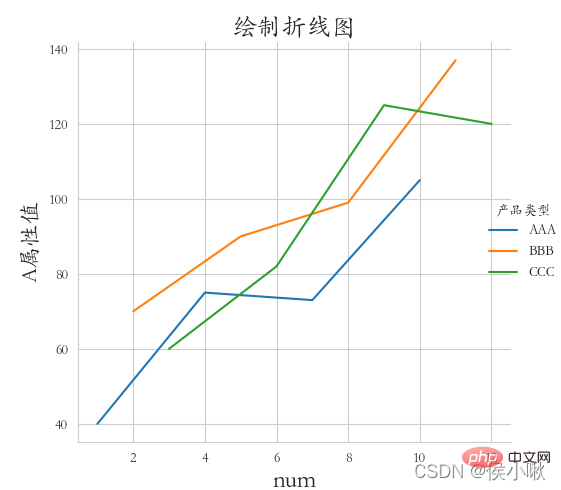 df2.index = list(range(0, len(df2)*2, 2))
df2.index = list(range(0, len(df2)*2, 2))
sns.relplot(data=dfs, kind=“line”)
plt.ylabel('A 属性値', fontsize=16) plt.subplots_adjust(left=0.15, right=0.9,bottom=0.1, top = 0.9)
plt.show() ∣ ∣ ∣ ∣ 位置
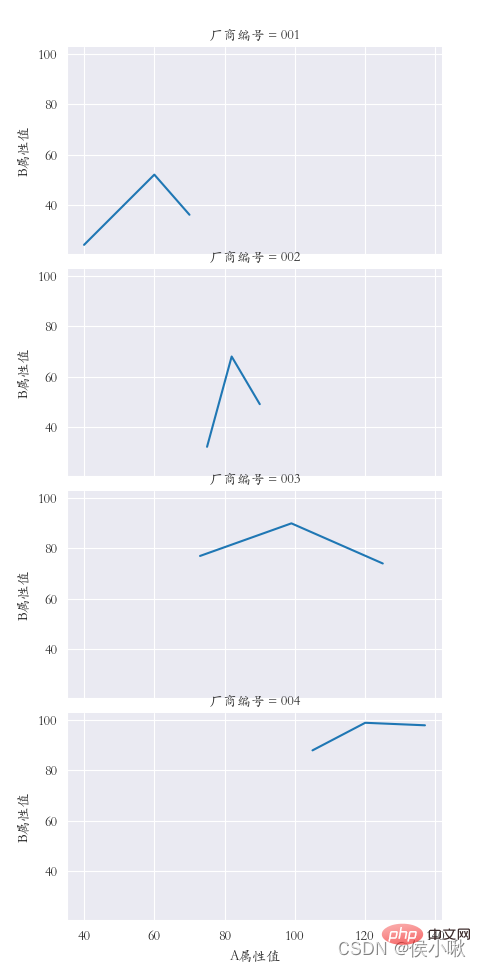
sns.relplot(data=df1, x="A 属性値", y="B 属性値", kind="line",col="メーカー番号")
plt.subplots_adjust ( left=0.05、right=0.95、bottom=0.1、top=0.9)
plt.show()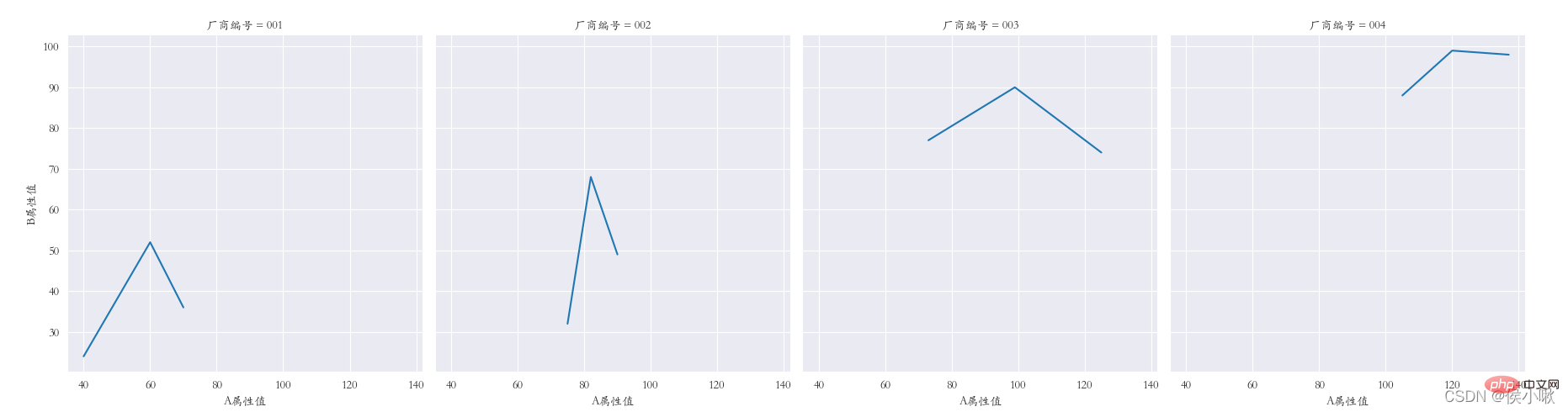
plt.rcParams['font.sans-serif'] = ['STKAITI']
#5.2 ラインプロットを使用します( )メソッド
plt.show()
## � � � � � � � � � 
plt.xlabel('num', fontsize=18)
df2.index = list(range(0, len(df2)*2, 2))
plt.show()
## 1 つのポジ
##sns.set_style('darkgrid') plt.rcParams['font.sans-serif'] = ['STKAITI'] 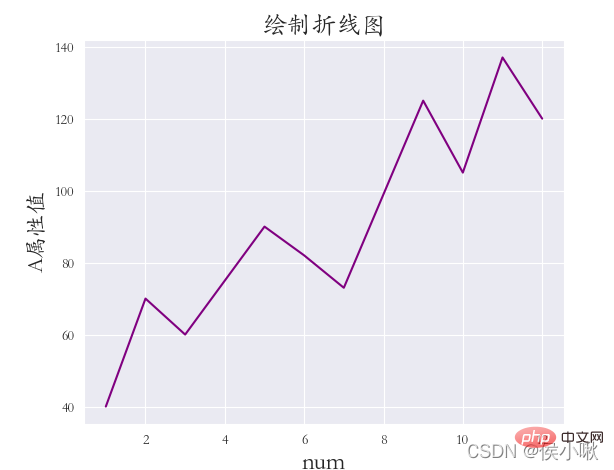 sns.lineplot(data=dfs)
sns.lineplot(data=dfs)
plt. xlabel('num', fontsize=18) plt.ylabel('A 属性値', fontsize=16)
� � � � � �
6. ヒストグラムの描画 displot()
ヒストグラムの描画には sns.displot() メソッドが使用されます。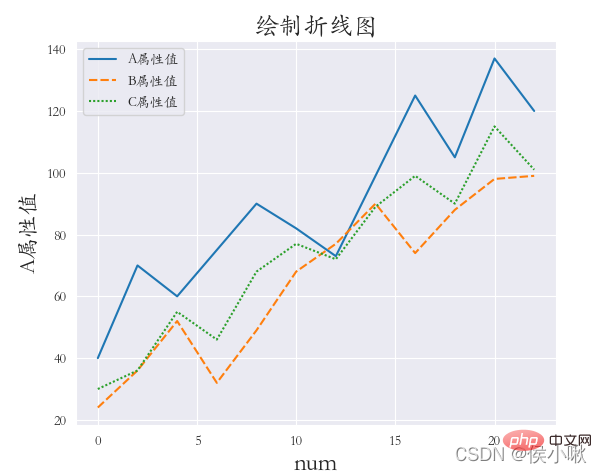 bins=6 は、描画が 6 つの間隔に分割されることを示します
bins=6 は、描画が 6 つの間隔に分割されることを示します
kde=True は、カーネル密度曲線が表示されることを示します
plt.xlabel('C 属性値', fontsize=18)
plt.ylabel('数量', fontsize=16) plt.subplots_adjust(left=0.15, right=0.9,bottom=0.1, top=0.9)
plt.title("ヒストグラム", fontsize =18)
^ ^ ^ ^ ˜
#sns.set_style('darkgrid')
plt.rcParams['font.sans-serif'] = ['STKAITI']
np.random.seed (13 ) Y = np.random.randn(300)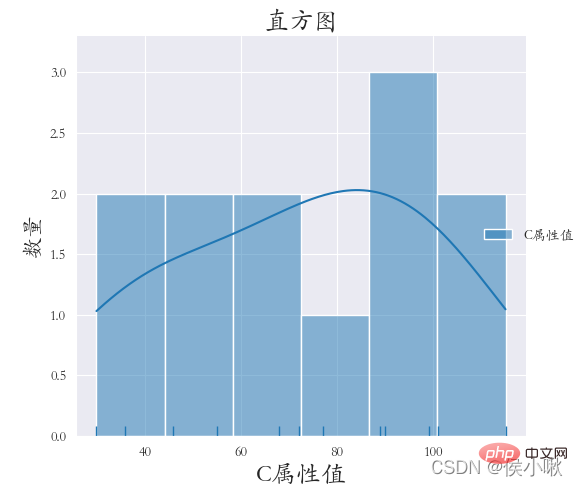 plt.ylabel('数量', fontsize=16)
plt.ylabel('数量', fontsize=16)
plt.show()
商品タイプフィールドのデータをX軸データ、A属性値データをY軸データとして使用します。さまざまな製造者番号フィールドに従って分類します。
詳細は次のとおりです:
plt.rcParams['font.sans-serif'] = ['STKAITI']
sns.barplot(x="製品タイプ", y='属性値', hue="メーカー番号", data=df1)
plt.title("棒グラフ", fontsize=18)
plt.xlabel('商品タイプ', fontsize =18)
plt.ylabel('数量', fontsize=16)
plt.subplots_adjust(left=0.15, right=0.9,bottom=0.15, top=0.9)
plt.show() 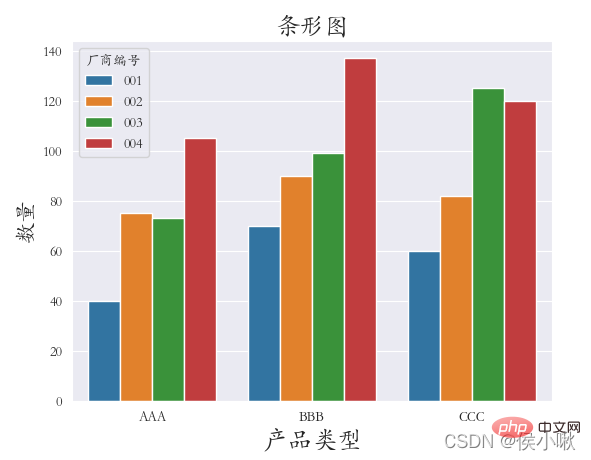 主なパラメータは x、y、データです。それぞれ x 軸データ、y 軸データ、データセットデータを表します。
主なパラメータは x、y、データです。それぞれ x 軸データ、y 軸データ、データセットデータを表します。
さらに、上で述べたように、 hue でカテゴリカル変数を指定することもできます; 水平方向の複数のサブグラフを描画するには、col で列カテゴリ変数を指定します;
row で行カテゴリ変数を指定し、垂直方向に描画します複数のサブピクチャ;
マーカーを使用して、点の形状を制御します。
X 属性値と Y 属性値に対して線形回帰を実行してみましょう コードは次のとおりです。 ## plt.rcParams['font.sans-serif'] = ['STKAITI']
sns.lmplot(x="A 属性値", y='B 属性値', data=df1)
plt.title( "線形回帰モデル", fontsize=18)
plt.xlabel('A 属性値', fontsize=18)
plt.ylabel('B 属性値', fontsize=16)
plt.subplots_adjust (left=0.15、right=0.9、bottom=0.15、top=0.9)
plt.show() ^ ^ ^ ^ ^ ^
9. カーネル密度マップの描画 kdeplot()
9.1 一般的なカーネル密度マップ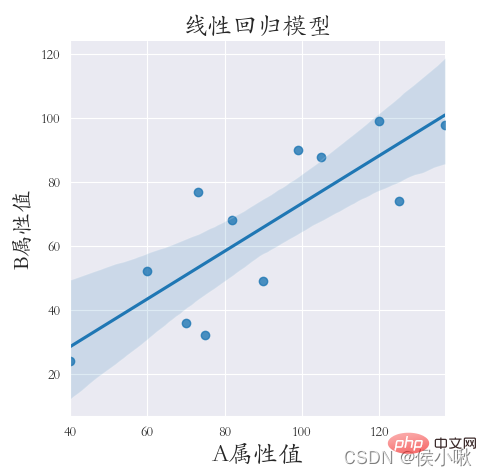
shade を True に設定すると周囲の影が表示され、それ以外の場合は線のみが表示されます。
sns.set_style('darkgrid') plt.rcParams['font.sans-serif'] = ['STKAITI'] sns.kdeplot (df1["A 属性値"], shade=True, data=df1, color='r')
sns.kdeplot(df1["B 属性値"], shade=True, data=df1, color= 'g')
plt.subplots_adjust(left=0.15, right=0.9 、bottom=0.15、top=0.9)
plt.show() ^ ^ ^ ^ ^
plt.rcParams['font.sans-serif'] = ['STKAITI']
9.2 限界カーネル密度map
sns.jointplot() メソッドは、限界カーネル密度マップを描画するときに使用されます。パラメータの種類は「kde」である必要があります。この方法を使用すると、デフォルトでダーク スタイルが使用されます。他のスタイルを手動で追加することはお勧めできません。追加すると、画像が正しく表示されなくなる可能性があります。 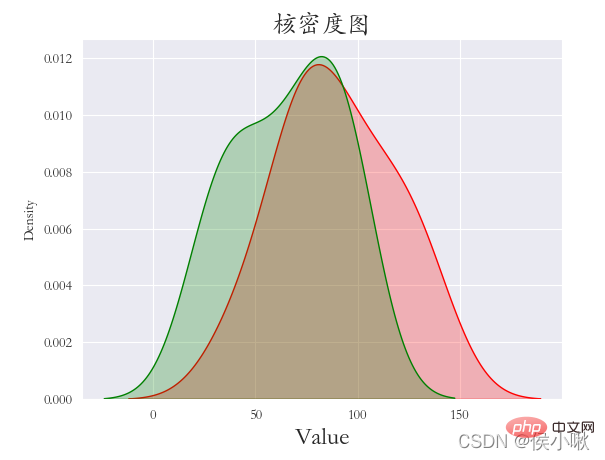 plt.show()
plt.show()
∣ ∣ ∣ ∣ ∣ 10. 箱ひげ図の描画 boxplot()
さらに、分類フィールドを示す
boxplot() メソッドは、箱ひげ図を描画するために使用されます。 基本パラメータは x、y、データです。 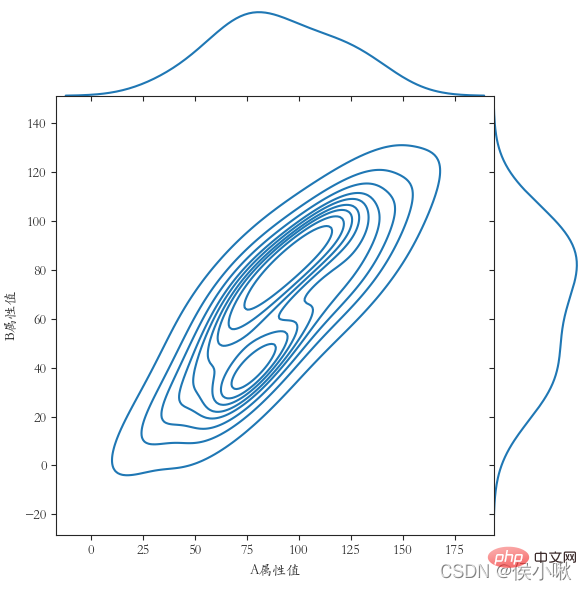 width はキャビネットの幅を調整できます。
width はキャビネットの幅を調整できます。
前のデータが表示できるほど大きくないことを考慮して、ここで別のデータ セットが生成されます:
np.random.seed (13)
Y = np.random.randint(20, 150, 360)
df2 = pd.DataFrame(
{'メーカー番号': ['001', ' 001', '001' , '002', '002', '002', '003', '003', '003', '004', '004', '004'] * 30,
'製品タイプ': [' AAA'、'BBB'、'CCC'、'AAA'、'BBB'、'CCC'、'AAA'、'BBB'、'CCC'、'AAA'、'BBB'、' CCC'] * 30, 'XXX 属性値': Y
# � � � � �
plt.show()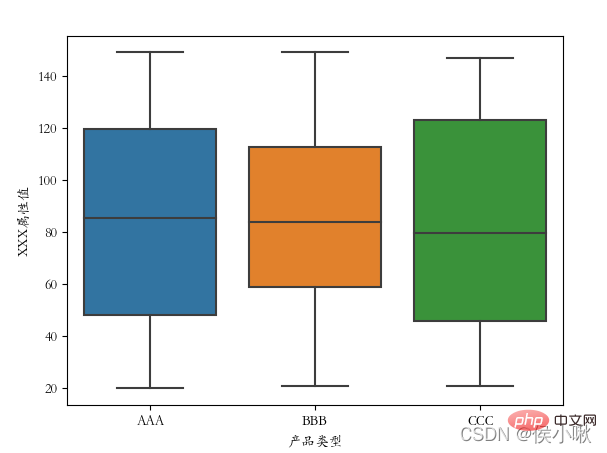
x 軸と y 軸のデータを交換した後: plt .rcParams[' font.sans-serif'] = ['STKAITI']
箱ひげ図の方向も変わっていることがわかります
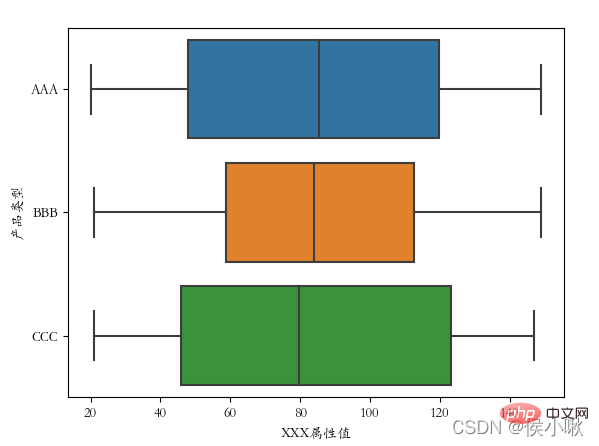
メーカー番号を分類フィールドとして使用します: sns.boxplot (x='商品タイプ', y='XXX 属性値', data=df2, hue="メーカー番号")
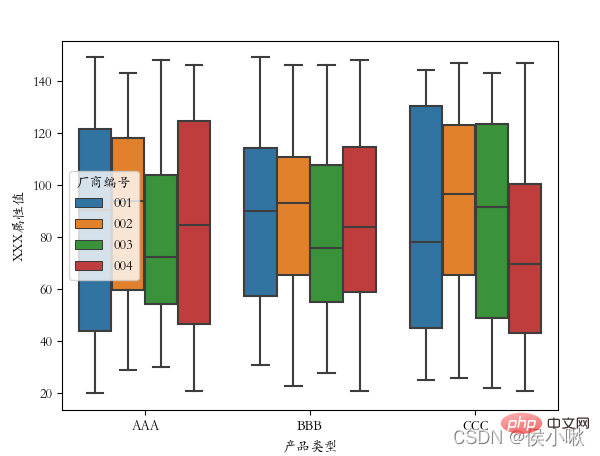
バイオリンプロットは、箱ひげ図とカーネル密度の機能を組み合わせたものです。データの分布形状を表示するプロット。 Violinplot() メソッドを使用して、バイオリン プロットを描画します。
plt.rcParams['font.sans-serif'] = ['STKAITI'] sns.violinplot(x='XXX 属性値', y='商品タイプ', data=df2)
ˆ ˆ ˆ ˆ 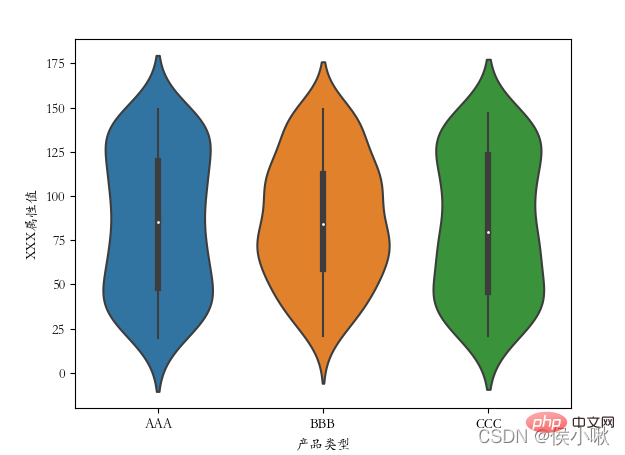
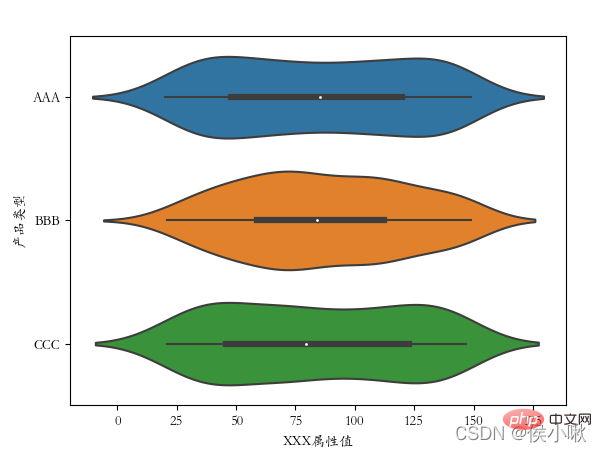
sns.violinplot(x='商品タイプ', y='XXX属性値', data=df2, hue="メーカー番号") plt.show()
 12. ヒート マップ heatmap()
12. ヒート マップ heatmap()
import matplotlib.pyplot as plt
plt .figure(figsize=(6,6)) plt.rcParams['font.sans-serif'] = ['STKAITI'] s1 = np.random.randint(0, 200, 33)
s2 = np.random.randint(0, 200, 33) s7 = np.random.randint(0, 200, 33)
'二': s2,
'三': s3,
'四':s4,
'五':s5,
'六':s6,
'七':s7
}
)
plt.title('ダブルカラーボールヒートマップ')
sns.heatmap(data, annot=True, fmt='d', lw=0.5)
plt.xlabel('当選番号桁')
plt.ylabel('ダブルカラーボールNumber')
x = ['1 位', '2 位', '3 位', '4 位', '5 位', '6 位', '7 位']
plt.xticks (range(0, 7, 1), x, ha='left')
plt.show()
推奨される学習:
Python ビデオ チュートリアル
以上がPythonのSeabornについて詳しく解説(データ可視化)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7449
7449
 15
1374
52
77
11
14
7
15
1374
52
77
11
14
7

 PSが荷重を見せ続ける理由は何ですか?
Apr 06, 2025 pm 06:39 PM
PSが荷重を見せ続ける理由は何ですか?
Apr 06, 2025 pm 06:39 PM
PSの「読み込み」の問題は、リソースアクセスまたは処理の問題によって引き起こされます。ハードディスクの読み取り速度は遅いか悪いです。CrystaldiskInfoを使用して、ハードディスクの健康を確認し、問題のあるハードディスクを置き換えます。不十分なメモリ:高解像度の画像と複雑な層処理に対するPSのニーズを満たすためのメモリをアップグレードします。グラフィックカードドライバーは時代遅れまたは破損しています:ドライバーを更新して、PSとグラフィックスカードの間の通信を最適化します。ファイルパスが長すぎるか、ファイル名に特殊文字があります。短いパスを使用して特殊文字を避けます。 PS独自の問題:PSインストーラーを再インストールまたは修理します。
 PSの負荷速度をスピードアップする方法は?
Apr 06, 2025 pm 06:27 PM
PSの負荷速度をスピードアップする方法は?
Apr 06, 2025 pm 06:27 PM
Slow Photoshopの起動の問題を解決するには、次のような多面的なアプローチが必要です。ハードウェアのアップグレード(メモリ、ソリッドステートドライブ、CPU)。時代遅れまたは互換性のないプラグインのアンインストール。システムのゴミと過剰な背景プログラムを定期的にクリーンアップします。無関係なプログラムを慎重に閉鎖する。起動中に多数のファイルを開くことを避けます。
 PSが開始されたときにロードの問題を解決する方法は?
Apr 06, 2025 pm 06:36 PM
PSが開始されたときにロードの問題を解決する方法は?
Apr 06, 2025 pm 06:36 PM
ブートがさまざまな理由によって引き起こされる可能性がある場合、「読み込み」に巻き込まれたPS:腐敗したプラグインまたは競合するプラグインを無効にします。破損した構成ファイルの削除または名前変更。不十分なプログラムを閉じたり、メモリをアップグレードしたりして、メモリが不十分であることを避けます。ソリッドステートドライブにアップグレードして、ハードドライブの読み取りをスピードアップします。 PSを再インストールして、破損したシステムファイルまたはインストールパッケージの問題を修復します。エラーログ分析の起動プロセス中にエラー情報を表示します。
 HTML次ページ関数
Apr 06, 2025 am 11:45 AM
HTML次ページ関数
Apr 06, 2025 am 11:45 AM
<p>次のページ関数は、HTMLを介して作成できます。手順には、コンテナ要素の作成、コンテンツの分割、ナビゲーションリンクの追加、他のページの隠し、スクリプトの追加が含まれます。この機能により、ユーザーはセグメント化されたコンテンツを閲覧でき、一度に1つのページのみを表示し、大量のデータやコンテンツを表示するのに適しています。 </p>
 遅いPSの読み込みはコンピューター構成に関連していますか?
Apr 06, 2025 pm 06:24 PM
遅いPSの読み込みはコンピューター構成に関連していますか?
Apr 06, 2025 pm 06:24 PM
PSの負荷が遅い理由は、ハードウェア(CPU、メモリ、ハードディスク、グラフィックスカード)とソフトウェア(システム、バックグラウンドプログラム)の影響を組み合わせたものです。ソリューションには、ハードウェアのアップグレード(特にソリッドステートドライブの交換)、ソフトウェアの最適化(システムガベージのクリーンアップ、ドライバーの更新、PS設定のチェック)、およびPSファイルの処理が含まれます。定期的なコンピューターのメンテナンスは、PSのランニング速度を改善するのにも役立ちます。
 PSがファイルを開いたときにロードの問題を解決する方法は?
Apr 06, 2025 pm 06:33 PM
PSがファイルを開いたときにロードの問題を解決する方法は?
Apr 06, 2025 pm 06:33 PM
「ロード」は、PSでファイルを開くときに発生します。理由には、ファイルが大きすぎるか破損しているか、メモリが不十分で、ハードディスクの速度が遅い、グラフィックカードドライバーの問題、PSバージョンまたはプラグインの競合が含まれます。ソリューションは、ファイルのサイズと整合性を確認し、メモリの増加、ハードディスクのアップグレード、グラフィックカードドライバーの更新、不審なプラグインをアンインストールまたは無効にし、PSを再インストールします。この問題は、PSパフォーマンス設定を徐々にチェックして使用し、優れたファイル管理習慣を開発することにより、効果的に解決できます。
 PSが常にロードされていることを常に示しているときに、ロードの問題を解決する方法は?
Apr 06, 2025 pm 06:30 PM
PSが常にロードされていることを常に示しているときに、ロードの問題を解決する方法は?
Apr 06, 2025 pm 06:30 PM
PSカードは「ロード」ですか?ソリューションには、コンピューターの構成(メモリ、ハードディスク、プロセッサ)の確認、ハードディスクの断片化のクリーニング、グラフィックカードドライバーの更新、PS設定の調整、PSの再インストール、優れたプログラミング習慣の開発が含まれます。
 H5ページの制作と従来のWebページの違いは何ですか
Apr 06, 2025 am 07:03 AM
H5ページの制作と従来のWebページの違いは何ですか
Apr 06, 2025 am 07:03 AM
従来のWebページでのH5ページの重要な違いは、モバイルの優先順位と柔軟性であり、モバイルデバイスにより適しており、開発効率が高まり、クロスプラットフォームの互換性が向上しています。具体的には、H5ページでは、セマンティックタグ、マルチメディアサポート、オフラインストレージ、地理的位置などの新機能を紹介し、モバイルエクスペリエンスを向上させます。
