

MySQL インデックスについて説明します

この記事では、mysql に関する関連知識を提供します。主に、インデックスとは何か、インデックスの基礎となる実装など、高度な mysql の章のいくつかの問題を紹介します。一緒にそれについて話しましょう。見てください、それが皆さんのお役に立てば幸いです。

推奨学習: mysql ビデオ チュートリアル
MySQL は、よく知られているようでなじみのない用語ですが、できるだけ早く私たちが Javaweb を学習していたとき、MySQL データベースを使用していました。その段階では、MySQL はデータを保存するのにちょうど良いものであるように思えました。保存するときはデータをすべて詰め込み、クエリを実行するときはテーブル全体を盲目的にクエリします。 (少しの情報なしで)最適化)。
私たちは常に自分自身と他人を欺き、他の側面を通じて最適化できると考えています。MySQL Advanced に直面することに消極的で、代わりに、より高度だと思われるものを学びます。 「高度な」こと、MySQL のプレッシャーを共有するために Redis を学ぶ、MyCat とその他のミドルウェアを学ぶ、マスター/スレーブ レプリケーション 、読み取り/書き込み分離 、サブデータベースを実装するおよびサブテーブルなど。 (メロのことを言っているのです、そうです)
面接の準備をしていたとき、面接の質問で MySQL についてすべてを知っているわけではないことがわかりました~
私が学んだ最先端のミドルウェアについては、ほとんどGet!に依頼しました。 !使い方しか分からない 履歴書を書くときに、xxx ミドルウェアについて「理解している」と弱くしか書けません...
もちろん、MySQL Advanced Chapter を学ぶことはできません。インタビューのためですが、実際のプロジェクトではこの部分の最適化が非常に重要です。サーバーダウンを経験した後は、黙って行うしかありません...
今から始めましょう、上陸するにはまだ遅すぎます現時点では ! ! !ゴールド 3 とシルバー 4 を利用して、MySQL 上級章の知識ポイントを補足し、次の側面から MySQL 上級章の旅を開始することをお勧めします。
サイドバー ディレクトリから 役立つ部分を取得します。その中で、 絵文字表現プレフィックス
絵文字表現プレフィックス
インデックスの定義
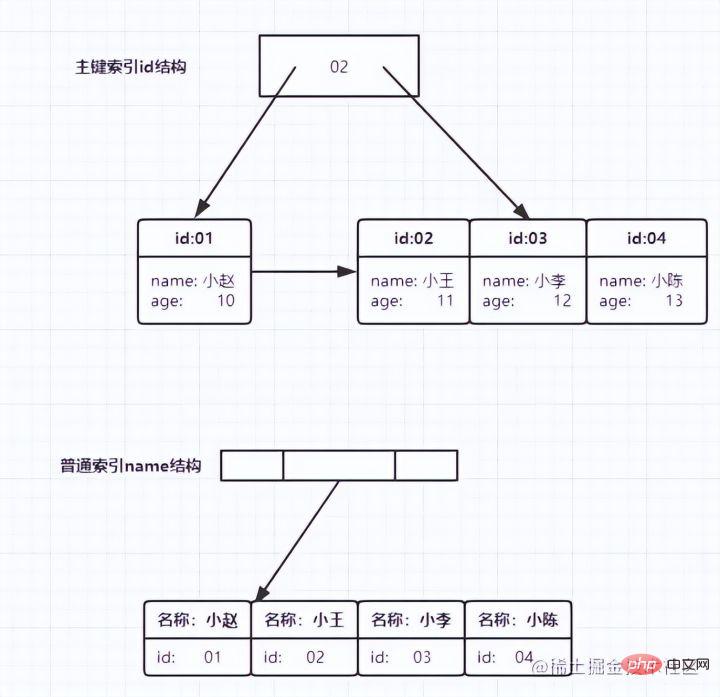
MySQL のインデックスの公式定義は次のとおりです。 インデックス (インデックス) は、MySQL がデータを効率的に取得するのに役立つ (順序付けられた) データ構造です。インデックスは、クエリ効率を向上させるメカニズムとしてデータベース テーブルのフィールドに追加されます。データベース システムは、データに加えて、特定の検索アルゴリズムを満たすデータ構造も維持します。これらのデータ構造は、何らかの方法でデータを参照 (ポイント) するため、これらのデータ構造に高度な検索アルゴリズムを実装できます。このデータ構造は、索引。 。以下の図に示すように:実際、簡単に言うと、インデックスはソートされたデータ構造です。
左側データ テーブルには合計 2 列と 7 つのレコードがあり、一番左はデータ レコードの物理アドレスです (論理的に隣接するレコードがディスク上で物理的に隣接しているとは限らないことに注意してください)。 Col2 の検索を高速化するために、右に示すようにバイナリ検索ツリーを維持できます。各ノードには、インデックス キー値
と、対応するデータ レコードの物理アドレスへのポインタが含まれています。 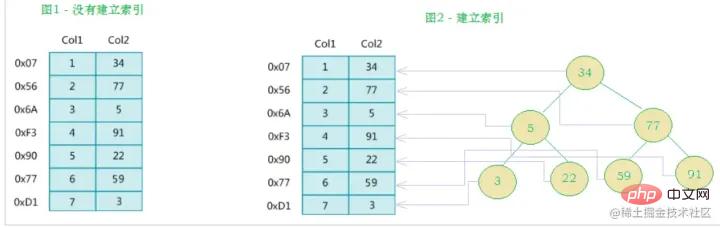 なので、二分検索を使用して、対応するデータをすばやく取得できます。
なので、二分検索を使用して、対応するデータをすばやく取得できます。
インデックスの利点検索
とソート
の速度を高速化し、データベースのIOコストとCPU消費量を削減します。- 一意のインデックスを作成すると、データベース テーブル内のデータの各行の一意性が保証されます。 インデックスの欠点
- インデックスは実際には テーブル
- をポイントする
- には、必要な場合があります。
- に変更されますが、実際には、MySQL に保存するために バイナリ検索ツリー を使用しません。なぜですか?
二分探索ツリーでは、ここのノードは 1 つのデータのみを保存でき、ノードは MySQL のディスク ブロックに対応するため、毎回 1 つのディスク ブロックを読み取ることを知っておく必要があります。データは 1 つしか取得できず、効率が非常に悪いので、B-tree 構造を使用して格納することを考えます。
インデックス構造
インデックスは、サーバー層ではなく、MySQL のストレージ エンジン層に実装されます。したがって、各ストレージ エンジンのインデックスは必ずしも完全に同じであるとは限らず、すべてのエンジンがすべてのインデックス タイプをサポートしているわけではありません。
- BTREE インデックス: 最も一般的なインデックス タイプで、ほとんどのインデックスが B ツリー インデックスをサポートします。
- HASH Index: メモリ エンジンでのみサポートされており、使用シナリオは簡単です。
- R ツリー インデックス (空間インデックス): 空間インデックスは、MyISAM エンジンの特別なインデックス タイプです。主に地理空間データ タイプに使用されます。通常はあまり使用されず、使用されません。特別にご紹介させていただきます。
- フルテキスト (フルテキスト インデックス): フルテキスト インデックスは MyISAM の特別なインデックス タイプでもあり、主にフルテキスト インデックスに使用されます。InnoDB はフルテキスト インデックスの開始をサポートしています。 Mysql5.6バージョンから。
MyISAM、InnoDB、および Memory ストレージ エンジンはさまざまなインデックス タイプをサポートします
インデックス |
#INNODB エンジン | #MYISAM エンジン##メモリ エンジン | ##BTREE インデックス | ||||||||||
| サポート | サポート | ## サポート#HASH インデックス | サポートされていません|||||||||||
|
#サポートされている |
R ツリー インデックス | サポートされていません | |||||||||||
| サポートされていない | ##全文 | バージョン 5.6 以降はサポートされます | ##サポートされます | ||||||||||
|
通常、インデックスと呼ばれるものは、特に指定がない限り、B ツリー (多方向検索ツリー、必ずしもバイナリではない) 構造で編成されたインデックスを指します。このうち、クラスター化インデックス、複合インデックス、プレフィックス インデックス、およびユニーク インデックスはすべてデフォルトで B ツリー インデックスを使用し、総称してインデックスと呼ばれます。 BTREEマルチパスバランス検索ツリー、m 次 (m フォーク) BTREE は次の条件を満たします。
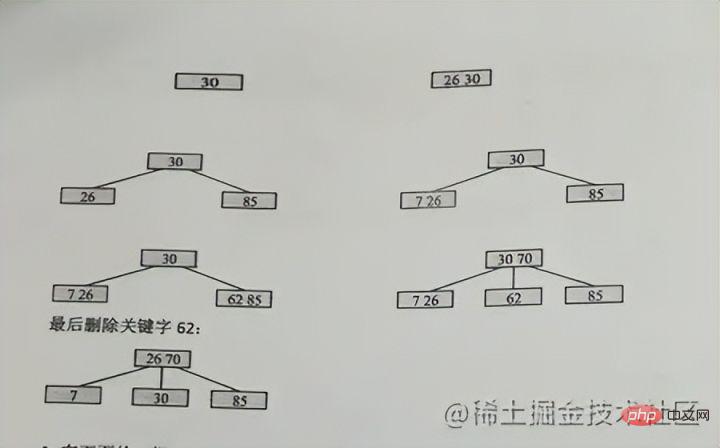
キーワード case を挿入
、つまり: 画像に 70 を挿入すると、たまたま 70 が真ん中の位置にあり、その後 62 が維持され、85 が新しいノードに分割されます。上昇したら、再度分割する必要があります。上方向に分割し続けるだけで同じです。
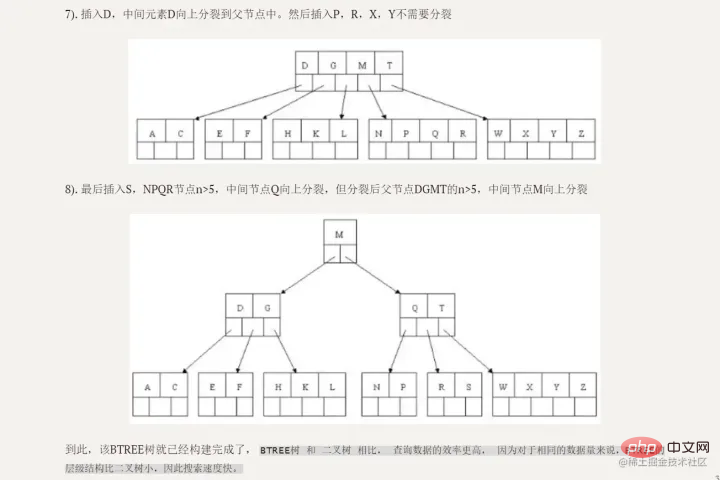
比較優位性二分探索ツリーと比較して、高さ/深さが低く、自然なクエリ効率が高くなります。 B TREE B ツリーには、内部ノード (インデックス ノードとも呼ばれます) と リーフ ノードという 2 種類のノードがあります。内部ノードは非リーフ ノードであり、内部ノードにはデータは格納されずインデックスのみが格納され、データはリーフ ノードに格納されます。
二分探索ツリーから B ツリー への移行では、1 つのノードに複数のデータを保存できるという大きな変更があります。これは、1 つのディスク ブロックに複数のデータを保存できるのと同等です。データにアクセスできるため、IO 時間が大幅に短縮されます。 !
初期化の概要 水色のものはディスクブロックと呼ばれ、各ディスクブロックに何個のディスクブロックが含まれているかがわかります。項目 (濃い青で表示) とポインター (黄色で表示)
データ項目 29 を検索する場合、最初にディスク ブロック 1 がディスクからメモリにロードされ、この時点で IO が発生します。 。メモリ内で二分探索を使用して、29 が 17 ~ 35 の間にあることを確認し、ディスク ブロック 1 の P2 ポインタをロックします。メモリ時間は (ディスクの IO と比較して) 非常に短いため、無視できます。ディスクを使用します。ディスク ブロック 1 からディスク ブロック 3 の P2 ポインタのアドレスがディスクからメモリにロードされます。2 番目の IO が発生します。29 は 26 と 30 の間にあります。ディスク ブロック 3 の P2 ポインタはロックされています。ディスク ブロック 8 がロードされます。ポインタを介してメモリにアクセス 3 回目の IO が発生 同時にメモリが通過 二分検索が 29 に達してクエリが終了し、合計 3 回の IO が発生します。 インデックスの分類 InnoDB では、主キーの順序に従ってテーブルをインデックス形式で格納しており、このように格納されたテーブルをインデックス構成テーブルと呼びます。前述したように、InnoDB は B ツリー インデックス モデルを使用するため、データは B ツリーに保存されます。 各インデックスは InnoDB の B ツリーに対応します。 mysql> create table T( id int primary key, k int not null, name varchar(16), index (k))engine=InnoDB; 复制代码 ログイン後にコピー テーブル内のR1~R5の(ID,k)値は(100,1)、(200,2)、 (300,3)、(500,5)、および (600,6)、2 つのツリーの図の例は次のとおりです。図からはわかりにくいですが、リーフ ノードの内容に応じて、インデックス タイプが主キー インデックスと非主キー インデックスに分けられます。 主キー インデックス
データ行全体が格納されます。 InnoDB では、主キー インデックスはクラスター化インデックス の値です。 InnoDB では、補助インデックスはSecondary Index (セカンダリ インデックス) とも呼ばれます。 以下に示すように: 主キー インデックスは
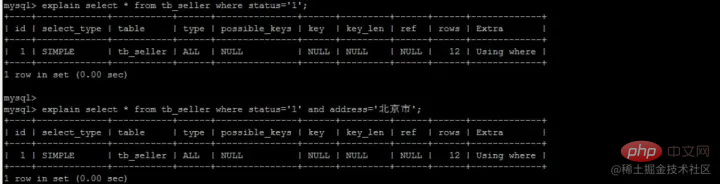
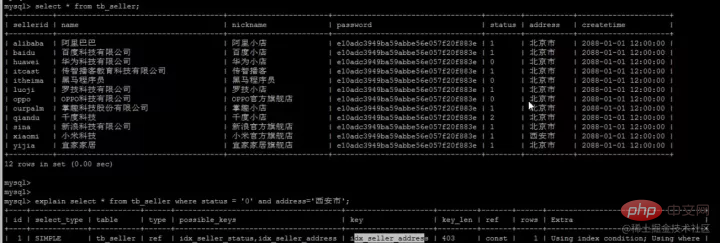
ステートメントが主キーのクエリ方法である select * from T where ID=500 の場合、ID の B ツリーを検索するだけで済みます。 ステートメントが select * from T where k=5 の場合、これは通常のインデックス クエリ方法ですが、最初に k インデックス ツリー
拡張機能--インデックス プッシュダウンいわゆるプッシュダウン名前が示すように、実際には テーブルを返す操作を延期します。非常に無駄が多いため、MySQL ではテーブルを簡単に返すことはできません。それはどういう意味ですか?次の例を考えてみましょう。 複合インデックス (名前、ステータス、アドレス) を確立しました。これも、次の図のように、このフィールドに従って保存されます。 複合インデックス ツリー (インデックス列とアドレスのみを保存します)主キーはテーブルを返すために使用されます)
|

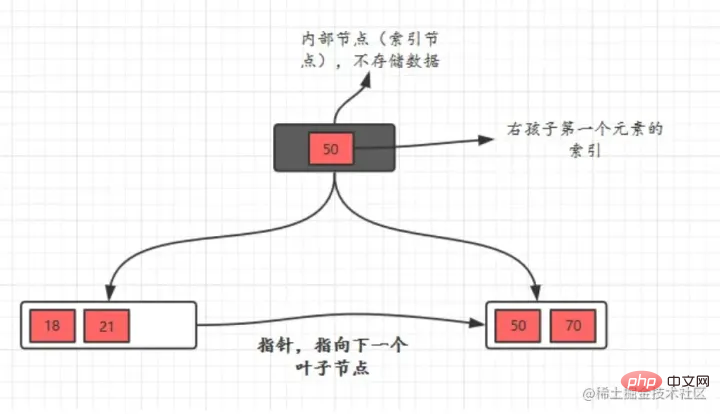 リーフ ノードをトラバースするだけで、ツリー全体をトラバースできます。
リーフ ノードをトラバースするだけで、ツリー全体をトラバースできます。 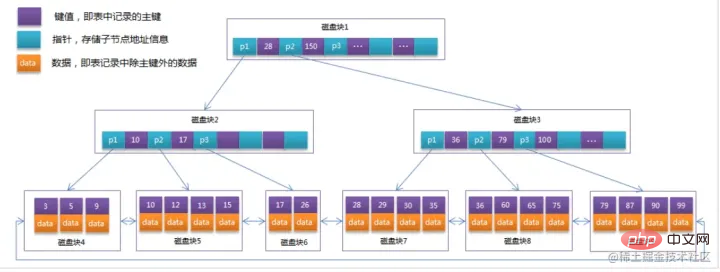 BTreeインデックス:
BTreeインデックス: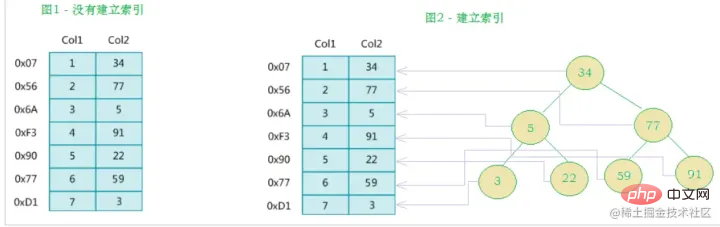 たとえば、ディスク ブロック 1 には、ポインター P1、P2、および P3 を含むデータ項目 17 と 35 が含まれています。
たとえば、ディスク ブロック 1 には、ポインター P1、P2、および P3 を含むデータ項目 17 と 35 が含まれています。 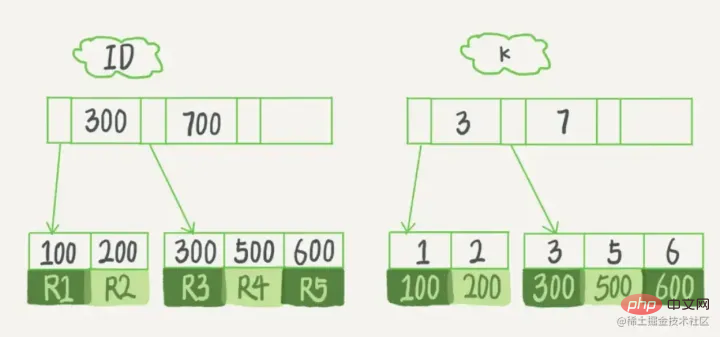


以上がMySQL インデックスについて説明しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7460
7460
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17

 MySQLユーザーとデータベースの関係
Apr 08, 2025 pm 07:15 PM
MySQLユーザーとデータベースの関係
Apr 08, 2025 pm 07:15 PM
MySQLデータベースでは、ユーザーとデータベースの関係は、アクセス許可と表によって定義されます。ユーザーには、データベースにアクセスするためのユーザー名とパスワードがあります。許可は助成金コマンドを通じて付与され、テーブルはCreate Tableコマンドによって作成されます。ユーザーとデータベースの関係を確立するには、データベースを作成し、ユーザーを作成してから許可を付与する必要があります。
 mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
mysqlは支払う必要がありますか
Apr 08, 2025 pm 05:36 PM
MySQLには、無料のコミュニティバージョンと有料エンタープライズバージョンがあります。コミュニティバージョンは無料で使用および変更できますが、サポートは制限されており、安定性要件が低く、技術的な能力が強いアプリケーションに適しています。 Enterprise Editionは、安定した信頼性の高い高性能データベースを必要とするアプリケーションに対する包括的な商業サポートを提供し、サポートの支払いを喜んでいます。バージョンを選択する際に考慮される要因には、アプリケーションの重要性、予算編成、技術スキルが含まれます。完璧なオプションはなく、最も適切なオプションのみであり、特定の状況に応じて慎重に選択する必要があります。
 RDS MySQL Redshift Zero ETLとの統合
Apr 08, 2025 pm 07:06 PM
RDS MySQL Redshift Zero ETLとの統合
Apr 08, 2025 pm 07:06 PM
データ統合の簡素化:AmazonrdsmysqlとRedshiftのゼロETL統合効率的なデータ統合は、データ駆動型組織の中心にあります。従来のETL(抽出、変換、負荷)プロセスは、特にデータベース(AmazonrdsmysQlなど)をデータウェアハウス(Redshiftなど)と統合する場合、複雑で時間がかかります。ただし、AWSは、この状況を完全に変えたゼロETL統合ソリューションを提供し、RDSMYSQLからRedshiftへのデータ移行のための簡略化されたほぼリアルタイムソリューションを提供します。この記事では、RDSMysQl Zero ETLのRedshiftとの統合に飛び込み、それがどのように機能するか、それがデータエンジニアと開発者にもたらす利点を説明します。
 MySQLのユーザー名とパスワードを入力する方法
Apr 08, 2025 pm 07:09 PM
MySQLのユーザー名とパスワードを入力する方法
Apr 08, 2025 pm 07:09 PM
MySQLのユーザー名とパスワードを入力するには:1。ユーザー名とパスワードを決定します。 2。データベースに接続します。 3.ユーザー名とパスワードを使用して、クエリとコマンドを実行します。
 MySQLのクエリ最適化は、特に大規模なデータセットを扱う場合、データベースのパフォーマンスを改善するために不可欠です
Apr 08, 2025 pm 07:12 PM
MySQLのクエリ最適化は、特に大規模なデータセットを扱う場合、データベースのパフォーマンスを改善するために不可欠です
Apr 08, 2025 pm 07:12 PM
1.正しいインデックスを使用して、データの量を削減してデータ検索をスピードアップしました。テーブルの列を複数回検索する場合は、その列のインデックスを作成します。あなたまたはあなたのアプリが基準に従って複数の列からのデータが必要な場合、複合インデックス2を作成します2。選択した列のみを避けます。必要な列のすべてを選択すると、より多くのサーバーメモリを使用する場合にのみサーバーが遅くなり、たとえばテーブルにはcreated_atやupdated_atやupdated_atなどの列が含まれます。
 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
