

MySQL データベースに関するよくある面接の質問を要約して整理する

この記事では、mysql に関する関連知識を紹介しており、主にデータベースメーカーの面接質問の概要を紹介していますので、一緒に見ていきましょう。

第一正規形 (1NF): テーブルの列をさらに分割できないことを意味します。データベース内のテーブルの各列は分割できない基本データ項目です。複数の値をテーブルに含めることはできません。同じ列;
- 第 2 正規形 (2NF): 1NF に基づいており、2 つの部分も含まれています: まず、テーブルには主キーが必要です。第 2 に、テーブル内の非主キー列は完全に依存している必要があります。パート;
- 第 3 正規形 (3NF): 2NF に基づいて、主キーに対する非主キー列の推移的な依存関係が排除されます。 -主キー列は主キーに直接依存する必要があります。
- BC 標準形式 (BCNF): 3NF に基づいて、コード部分の main 属性の推移的な依存性を排除します。
2. の実行プロセスSQL ステートメント:
2.1. クライアント データベース ドライバーとデータベース接続プール:
(1) クライアントがデータベースと通信する前に、クライアントとの接続を確立します。 MySQL は、データベース ドライバーを介して、確立が完了した後、SQL ステートメントを送信します。 (2) 頻繁な接続の作成と切断によるシステム パフォーマンスの低下を軽減するために、一定数の接続スレッドが使用されます。データベース接続プールを通じて維持され、接続が必要な場合は接続プールから直接取得し、使用後は接続プールに戻します。一般的なデータベース接続プールには、Druid、C3P0、DBCP2.2. MySQL アーキテクチャのサーバー層の実行プロセス:
(1) コネクタ: 主に顧客との通信 クライアントは接続を確立し、権限を取得し、接続を維持および管理します(2) クエリ キャッシュ: 最初にキャッシュ内でクエリを実行し、見つかった場合は直接返します。クエリがキャッシュ内で見つからない場合は、 、データベース内のクエリ。MySQL キャッシュはデフォルトでオフになっており、キャッシュの使用は推奨されず、MySQL8.0 バージョンではクエリ キャッシュ機能全体が削除されました。これは主に、その使用シナリオの制限によって発生します。まず、キャッシュ内のデータ ストレージ形式について説明します。キー (SQL ステートメント) - 値 (データ値) です。 (キー) のみが存在します 少しの違いが直接データベース クエリにつながります;
- テーブル内のデータは静的ではないため、そのほとんどは頻繁に変更され、データベース内のデータが変更されると、関連付けられます抽象構文ツリーを取得し、プリプロセッサを使用して抽象構文ツリーに対して意味検証を実行し、抽象構文ツリー内のテーブルが存在するかどうかを判断します。存在する場合は、選択されたテーブルが存在するかどうかを判断します。テーブルなどに射影列フィールドが存在します。
- (4) オプティマイザー: 主に SQL の字句解析と構文解析後に得られた構文ツリーを使用し、データ ディクショナリの内容と統計情報を介して、一連の操作を経て最終的に実行を取得します。使用するインデックスの選択を含む計画
インデックス クエリを使用するかどうかを分析する場合、
動的データ サンプリング統計分析によって決定されます。統計的に分析される限り、
分析エラーが発生する可能性があります。そのため、インデックスを作成せずに SQL を実行する場合は、この要素も考慮する必要があります。(5) Executor: 一連の実行計画に従って呼び出されます。ストレージ エンジンが提供する API インターフェイスは、操作データの呼び出しと SQL の実行に使用されます。
2.3. Innodb ストレージ エンジンの実行プロセス:
- (1) まず、MySQL エグゼキュータはストレージ エンジンの API を呼び出し、実行計画に従ってデータをクエリします。
- (2) ストレージ エンジンは、まずストレージ エンジンからデータをクエリします。そうでない場合はディスクにクエリが実行され、クエリが実行された場合はバッファ プールに格納されます
- (3) データがバッファ プールにロードされている間、このデータの元のレコードがバッファ プールにロードされます。データはUNDOログファイルに保存されます
- (4) innodbはバッファプールで更新操作を実行します
## (5) 更新されたデータはREDOログバッファ##に記録されます- # (6) 送信されたトランザクションが送信されます。同時に次の 3 つの処理が行われます。
- (7)(1 つ目) REDO ログ バッファ内のデータを REDO ログにフラッシュします。 file
- (8)(2つ目) 事) この操作記録をbinログファイルに書き込みます
- (9)(3つ目) binログファイルの名前と、 bin 内の更新されたコンテンツの場所を redo ログに記録し、同時に redo ログの最後にコミット マーク
- を追加します (10) バックグラウンド スレッドを使用して、更新されたデータをフラッシュします特定の機会にバッファ プール内のデータを MySQL データベースに転送し、メモリとデータベースを結合します データは統合されたままになります
#3. 一般的に使用されるストレージ エンジン? InnoDB と MyISAM の違いは何ですか?
ストレージ エンジンは、基盤となる物理データに対して実際の操作を実行し、サーバー サービス層のデータを操作するためのさまざまな API を提供するコンポーネントです。一般的に使用されるストレージ エンジンには、InnoDB、MyISAM、Memory などがあります。ここでは主に InnoDB と MyISAM の違いを紹介します。 (1) トランザクション: MyISAM はトランザクションをサポートしませんが、InnoDB はトランザクションをサポートします (2) ロック レベル: MyISAM はテーブル レベルのロックのみをサポートします, InnoDB は行レベルのロックとテーブル レベルのロックを行います。デフォルトでは行レベルのロックが使用されますが、行ロックはインデックスを介してデータがクエリされる場合にのみ使用され、それ以外の場合はテーブル ロックが使用されます。行レベルのロックは、ロックの取得と解放の各操作でテーブル ロックよりも多くのリソースを消費します。行ロックを使用するとデッドロックが発生する可能性がありますが、テーブル レベルのロックではデッドロックは発生しません (3) 主キーと外部キー: MyISAM では、インデックスと主キーのないテーブルの存在が許可されます。外部キーをサポートします。 InnoDB の主キーは空にすることはできず、主キーの自動拡張をサポートしています。主キーまたは空でない一意のインデックスが設定されていない場合は、6 バイトの主キーが自動的に生成され、外部キー整合性制約をサポートします。 (4) インデックス構造: MyISAM と InnoDB は両方とも B ツリー インデックスを使用しており、MyISAM の主キー インデックスと補助インデックスのデータ フィールドは行データ レコードが保存されるアドレスです。ただし、InnoDB の主キー インデックスのデータ フィールドは行データ レコードのアドレスではなく、行のすべてのデータ内容を保存しますが、補助インデックスのデータ フィールドは主インデックスの値を保存します。InnoDB の補助インデックスは主キー インデックスの値を保存するため、補助インデックスを使用するにはインデックスを 2 回取得する必要があります。まず、補助インデックスを取得して主キーを取得し、次に主キーを使用します。プライマリ インデックス内のレコードを取得します。これが、長すぎるフィールドを主キーとして使用することをお勧めしない理由です。補助インデックスには主キー列が含まれているため、主キーが長すぎるフィールドを使用すると、他の補助インデックスが大きくなる原因となるため、主キーはできるだけ小さく、小さいほど小さくします。(5) フルテキスト インデックス: MyISAM はフルテキスト インデックスをサポートします。InnoDB はバージョン 5.6 より前のフルテキスト インデックスをサポートしません。バージョン 5.6 以降のバージョンではフルテキスト インデックスのサポートが開始されます。 (6) テーブル 具体的な行数:
- ① MyISAM: テーブルの総行数を保存します select count() from table を使用すると、値は次のようになりますフルテーブルスキャンを必要とせずに直接取り出されます。
- ② InnoDB: テーブル内の総行数が保存されないため、select count() from table を使用するとテーブル全体を走査する必要があり、多大なコストがかかります。
- ① MyISAM は、テーブル定義を保存する .frm ファイル、データを保存する .MYD ファイル、の 3 つのファイルをディスク上に保存します。 MYI ファイルストレージインデックス。
- ② InnoDB: データとインデックスをテーブル スペースに保存します。すべてのテーブルは同じデータ ファイルに保存されます。InnoDB テーブルのサイズは、オペレーティング システム ファイルのサイズによってのみ制限されます。通常は 2GB です。 。
- ① MyISAM: 圧縮可能で、記憶容量が小さくなります。静的テーブル (デフォルトですが、データの末尾にスペースがあってはなりません。スペースは削除されることに注意してください)、動的テーブル、圧縮テーブルの 3 つの異なるストレージ形式をサポートします。
- ② InnoDB: より多くのメモリとストレージを必要とし、データとインデックスをキャッシュするためにメイン メモリ内に独自の専用バッファ プールを確立します。
- ① ロールバックおよびクラッシュ回復機能を備えた ACID トランザクション機能を提供し、行ロック レベルの同時実行制御が必要な場合、InnoDB は良い選択;
- ② データ テーブルが主にレコードのクエリに使用され、読み取り操作が書き込み操作よりはるかに多く、データベース トランザクションのサポートを必要としない場合、MyISAM エンジンはより高度な処理を提供できます。
注: MyISAM ストレージ エンジンは、mysql8.0 バージョンで廃止されました
4. ACID とその実装原理取引?
データベース トランザクションは同時実行制御の基本単位であり、操作の論理セットを指します。操作のすべてが実行されるか、まったく実行されません。4.1. トランザクション ACID:
- (1) 原子性: トランザクションは分割できない作業単位です。トランザクション内のすべての操作は成功または失敗します。トランザクションが失敗した場合は、ロールバックする必要があります。
- (2) 分離: トランザクションによって操作されるデータが、送信される前に他のトランザクションから見える程度。
- (3) 永続性: トランザクションがコミットされると、データベース内のデータに対する変更は永続的になります。
- (4) 一貫性: トランザクションによってデータの整合性とビジネスの一貫性が破壊されることはありません。たとえば、送金する場合、トランザクションが成功しても失敗しても、両当事者間の合計金額は変わりません。
4.2. ACID 実装原則:
4.2.1. アトミック性: アトミック性は MySQL のロールバック ログ undo ログを通じて行われます来 実装: トランザクションがデータベースを変更すると、InnoDB は対応する Undo ログを生成します。トランザクションの実行が失敗するかロールバックが呼び出され、トランザクションがロールバックされると、Undo ログ内の情報を使用してデータを転送できます。改造前の状態に戻りました。
4.2.2. 分離:
(1) トランザクション分離レベル:
同時環境でそれを確保するにはデータベースには、読み取りデータの整合性と一貫性を保証するために 4 つのトランザクション分離レベルが用意されています。分離レベルが高いほど、データの整合性と整合性はより良く保証されますが、高い同時実行パフォーマンスへの影響が大きくなり、実行速度が低下します。効率。 。 (4 つの分離レベルは上から下に増加します)
#Read uncommitted: トランザクションが実行中に他のトランザクションのコミットされていないデータを読み取ることを許可します;
- Read commit: トランザクションを許可します実行中に他のトランザクションによって送信されたデータを読み取るため;
- 反復読み取り (デフォルト レベル): 同じトランザクション内でいつでもクエリ結果に一貫性があります;
- 読み取りシリアル化: すべてのトランザクションが実行されます読み取りごとにテーブルレベルの共有ロックを取得する必要があり、読み取りと書き込みは相互にブロックされます。
(2) トランザクションの同時実行性の問題:
トランザクションの分離が考慮されていない場合、トランザクションの同時実行環境で問題が発生する可能性があります。トランザクション分離レベルが異なると、同時環境での同時実行性の問題も異なります。更新の喪失: 2 つ以上のトランザクションが同じデータを操作し、選択された値に基づいて行を更新する場合。これは、各トランザクションが他のトランザクションの存在を認識していないためです。 、更新が失われる問題が発生します。最後の更新が他のトランザクションによって行われた更新を上書きします。
- ダーティ リード: トランザクション A がデータにアクセスし、データを変更したことを意味します (トランザクションはコミットされていません)。このとき、トランザクション B もこのデータを使用します。その後、トランザクション A はロールバックをキャンセルし、データを元の値に戻すと、B が読み取ったデータはデータベース内のデータと不一致、つまり、B が読み取ったデータはダーティ データになります。
- 非反復読み取り: トランザクション内で同じデータが複数回読み取られますが、この期間中に別のトランザクションがデータを変更してコミットしたため、前後に読み取られたデータは不一致になります。
- ファントム読み取り: トランザクションでは、同じデータ (通常は範囲クエリ) が 2 回読み取られますが、別のトランザクションがデータを追加または削除するため、2 回の結果は矛盾します。
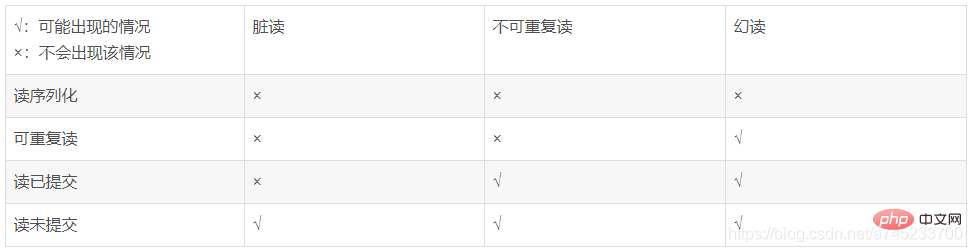
(3) トランザクション実装の原則分離のレベル:
Innodb トランザクションの分離レベルは、MVVC とロック機構によって実装されます: ① MVCC (Multi-Version Concurrency Control、マルチバージョン同時実行制御) は、特定のMySQL の InnoDB ストレージ エンジンがトランザクション分離レベルを実装する方法は、コミットされた読み取りと反復可能な読み取りという 2 つの分離レベルを実装することです。読み取り非コミット分離レベルは、MVCC を使用せずに常に最新のデータ行を読み取ります。読み取りシリアル化分離レベルでは、すべての読み取り行をロックする必要がありますが、これは MVCC を使用するだけでは実現できません。 MVCC は、レコードの各行の背後に 2 つの非表示列を保存することによって実装されます。1 つは行のトランザクション ID を保存し、もう 1 つは行のロールバック セグメント ポインターを保存します。新しいトランザクションが開始されるたびに、新しいトランザクション ID が自動的に増加します。トランザクションが開始されると、現在のトランザクションの影響を受ける行のトランザクション ID フィールドにトランザクション ID が配置され、ロールバック セグメントのポインタには行レコード上のすべてのバージョン データが含まれます。これは、リンクされた形式で編成されます。 UNDO ログのロールバック ログ内のリスト。つまり、値は実際には UNDO ログ内の行の履歴リンク リストを指していると言われています。 データベースに同時にアクセスする場合、書き込み操作が読み取り操作をブロックすることを回避するために、トランザクション内のデータに対して MVCC マルチバージョン管理が実行されます。また、スナップショット読み取りのファントム読み取りの問題は、バージョンを比較することで解決できますが、現在の MVCC はファントム読み取りを解決できず、一時的なキー ロックを通じて解決する必要があります。 ② ロック メカニズム: MySQL ロック メカニズムの基本的な動作原理は次のとおりです: トランザクションはデータベースを変更する前に、対応するロックを取得する必要があります。ロックを取得できるのは、ロックを取得したトランザクションだけです。データを変更する; このトランザクション内 操作中、データのこの部分はロックされています。他のトランザクションがデータを変更する必要がある場合、現在のトランザクションがコミットまたはロールバックしてロックを解放するまで待つ必要があります。#排他的ロックはダーティ読み取りを解決します
# #4.2.3. 永続性:- 共有ロックは反復不可能な読み取りを解決します
- プロキー ロックはファントム読み取りを解決します
永続性は
を達成するために REDO ログに依存しており、 は SQL 実行時に実行された SQL ステートメントを REDO ログ ファイルに保存しますが、効率を向上させるために、 REDO ログにデータを書き込む前に、まずメモリ内の REDO ログ バッファ キャッシュにデータが書き込まれます。書き込みプロセスは次のとおりです: データベースにデータを書き込むとき、実行プロセスはまず REDO ログ バッファに書き込みます。REDO ログ バッファ内の変更されたデータは、ディスク上の REDO ログ ファイルに定期的に更新されます。このプロセスはこれはディスクフラッシュと呼ばれます (つまり、REDO ログバッファがディスク上の REDO ログファイルにログを書き込みます)。
0: 意味ディスクをフラッシュしません;4.2.4. 一貫性:
- 1: トランザクションが送信されるたびに、バッファ プール内のデータがディスクにフラッシュされます;
- 2: トランザクションが送信されると、バッファ プール内のデータはディスクにフラッシュされますバッファ プールはディスク ファイルに書き込まれます。ディスク ファイルに直接入力する代わりに、対応する OS キャッシュ キャッシュに移動します。 OS キャッシュ内のデータがディスク ファイルに書き込まれるまでに 1 秒かかる場合があります。
一貫性とは、トランザクションがデータの整合性とビジネスの一貫性を破壊できないことを意味します:
データの整合性: エンティティの整合性、列の整合性 (フィールドのタイプ、サイズ、長さが要件を満たす必要があるなど)、外部キー制約など。
#5. データベースのロック メカニズムとは何ですか?- ビジネスの一貫性: たとえば、銀行振込では、取引が成功しても失敗しても、両当事者間の合計金額は変わりません。
データベース内の複数のトランザクションが同時に同じデータにアクセスする場合、同時操作が制御されていないと、誤ったデータが読み取られて格納され、データベースの一貫性が破壊される可能性があります。 MySQL ロック メカニズムの基本的な動作原理は、トランザクションがデータベースを変更する前に、対応するロックを取得する必要があるということです。ロックを取得したトランザクションのみがデータを変更できます。トランザクション操作中、この部分は、他のトランザクションの場合 データを変更する必要がある場合は、現在のトランザクションがコミットまたはロールバックされた後にロックを解放する必要があります。
さまざまな分類方法に従って、ロックのタイプは次のタイプに分類できます:
ロックの粒度に従って: テーブル レベルロック、行レベルのロック、ページレベルのロック;ロックの種類ごとに分割: 共有 (ロック S ロック)、排他的ロック (X ロック);
5.1、テーブルレベルのロック、行レベルのロック、ページレベルのロック:- ロックの使用方法ごとに分割: 楽観的ロック、悲観的ロック;
テーブル レベルのロック: 最大粒度ロック レベルでは、ロック競合の可能性が最も高く、同時実行性は最も低くなりますが、オーバーヘッドは小さく、ロックは高速で、デッドロックは発生しません。
InnoDB ストレージ エンジンは、行レベルのロックとテーブル レベルのロックをサポートしています。デフォルトでは、行レベルのロックが使用されますが、行レベルのロックは、データがインデックスを通じてクエリされる場合にのみ使用されます。それ以外の場合は、テーブル レベルのロックが使用されます。行レベルロック: すべてのレベルの最小粒度、ロック競合の可能性 最小で最高の同時実行性ですが、高いオーバーヘッド、遅いロック、デッドロックが発生します;
- ページ レベルのロック: ロックの粒度は制限されていますテーブルレベルのロックと行レベルのロックの間のロックであり、ロックは妥協によるものであり、同時実行性は平均的です。オーバーヘッドとロック時間もテーブル ロックと行ロックの間で制限され、デッドロックが発生します。
- ストレージ エンジンが異なればサポートされるロック メカニズムも異なります:
MyISAM および MEMORY ストレージ エンジンはテーブル レベルのロックを使用します;
5.2. InnoDB 行ロック:- BDB ストレージ エンジンはページ ロックを使用しますが、テーブル レベルのロックもサポートします;
InnoDB 行ロックには 2 つのタイプがあります:
共有ロック (S ロック、読み取りロック): 複数のトランザクションで共有可能同じデータ行に対する S ロック、ただし読み取りのみ可能で変更はできません。
- 排他ロック (X ロック、書き込みロック): トランザクションが排他ロックを取得した後、トランザクション中にロック範囲を変更できます。ロック期間が経過すると、他のトランザクションはデータ行のこの部分のロック (共有ロック、排他ロック) を取得できなくなり、排他ロックを取得したトランザクションのみがデータを更新できます。
- 更新、削除、挿入操作の場合、InnoDB は関連するデータ行に排他ロックを自動的に追加しますが、通常の SELECT ステートメントの場合、InnoDB はロックを追加しません。
5.3. InnoDB テーブル ロックとインテンション ロック:
InnoDB エンジンでは行ロックとテーブル ロックを共存させることができるため、複数粒度のロック メカニズムを実現できます。 , ただし、テーブルロックと行ロックはロック範囲が異なりますが、互いに競合します。テーブル ロックを追加する場合は、まずテーブル内のすべてのレコードを調べて、排他ロックがあるかどうかを確認する必要があります。このトラバーサル チェック方法は明らかに非効率的な方法であり、MySQL ではテーブル ロックと行ロックの間の競合を検出するためにインテンション ロックが導入されています。
意図ロックもテーブル レベルのロックであり、読み取り意図ロック (IS ロック) と書き込み意図ロック (IX ロック) に分けられます。 トランザクションがレコードに行ロックを追加する場合、まず対応するインテンション ロックをテーブルに追加します。トランザクションが後でテーブルをロックする必要がある場合、最初に目的のロックが存在するかどうかを判断するだけで済みます。ロックが存在する場合は、すぐにテーブルに戻ることができます。テーブル ロックは有効にできません。有効にしない場合は、効率を向上させるために待機する必要があります。
5.4. InnoDB 行ロックと一時キー ロックの実装:
InnoDB 行ロックは、インデックスのインデックス エントリをロックすることによって実装されます。 行ロックは、インデックスを通じてデータを取得する場合にのみ使用できます。それ以外の場合は、テーブル ロックが使用されます。
InnoDB では、ファントム リード現象を解決するために、ネクスト キー ロック (ネクスト キー) が導入されています。インデックスによれば、左が開き、右が閉じた区間に分かれています。範囲クエリを実行するときに、インデックスがヒットしてデータを取得できる場合、レコードが配置されている間隔とその次の間隔がロックされます。実際、Next-Key = Record Locks ギャップ ロック
- ギャップ ロック: データを取得するために正確なクエリではなく範囲クエリを使用する場合、共有ロックまたは排他的ロックをリクエストすると、InnoDB は範囲条件を満たす既存のデータ レコードのインデックス エントリ。キー値が条件範囲内にあるが存在しないレコードはギャップ (GAP) と呼ばれます。
- レコード ロック: 一意のインデックスとレコードの存在の正確なクエリを使用する場合は、レコード ロックを使用します
#5.5. ロック メカニズムを使用して同時実行性の問題を解決します:
InnoDB ストレージ エンジンのロック メカニズムと MyISAM ストレージ エンジンのロック メカニズムの詳細については、次の記事を参照してください: MySQL データベース: ロック メカニズム_Zhang Weipeng のブログ - CSDN ブログ_データベースのロック メカニズム#X ロックはダーティ リードを解決します
- S ロックは反復不可能なリードを解決します
- プロキー ロックはファントム リードを解決します
6. MySQL インデックスの実装原則:
インデックスは本質的に、必要な行数を減らすことでクエリのパフォーマンスを高速化するデータ構造です。クエリ によって走査されます。書籍の目次と同様に、データベースがテーブル全体のスキャンを実行するのを防ぎ、コンテンツをより速く見つけられるようにします。 (テーブルには最大 16 個のインデックスを作成できます)
6.1. インデックスのメリットとデメリット:
(1) インデックスのメリット:クエリによって取得する必要がある行の数を減らし、クエリを高速化し、テーブル全体のスキャンを回避するこれが、インデックスを作成する主な理由でもあります。
(2) インデックスのデメリット:- インデックスのデータ構造が B ツリーの場合、グループ化と並べ替えを使用すると、クエリでのグループ化と並べ替えの時間を大幅に短縮できます。
- 一意のインデックスを作成すると、データベース テーブル内のデータの各行の一意性が保証されます。
テーブル内のデータを追加、削除、変更するとインデックスも更新する必要があり、メンテナンス時間がかかります。データ量に応じて増加します。
- インデックスは物理的なスペースを占有する必要があります。クラスター化インデックスを作成する場合、必要なスペースはさらに大きくなります。
6.2. インデックスの使用シナリオ:
(1) インデックスを作成する列:WHERE句に頻繁に出現する列にインデックスを作成し、条件の判定を高速化します。
(2) インデックスを作成しない列はどれですか?- 範囲によってアクセスされる列、または group by または order by で使用される列は、インデックスが並べ替えられているため、インデックスを使用して並べ替えクエリ時間を短縮できます。
- は、接続の列でよく使用されます。これらの列は主に外部キーであり、接続を高速化できます。
- は、列の一意性を強制するための主キー列として使用されます。データの配置構造;
区別性の低い列。これらの列には、クエリ結果内の性別などの値が非常に少ないため、結果セット内のデータ行がテーブル内のデータ行の大部分を占めます。つまり、データ行の大部分を表で検索しました。インデックスを増やしても、検索が大幅に高速化されるわけではありません。
- クエリにほとんど含まれない列にはインデックスを作成しないでください。これらの列はめったに使用されないため、インデックスを追加すると、実際にはシステムのメンテナンス速度が低下し、必要なスペースが増加します。
- インデックスを追加すると、検索パフォーマンスの向上よりも変更コストの増加がはるかに大きくなる場合は、インデックスを作成しないでください。インデックスを追加すると、検索パフォーマンスは向上しますが、変更パフォーマンスは低下します。インデックスを減らすと、変更パフォーマンスは向上しますが、検索パフォーマンスは低下します。
- テキスト、イメージ、およびビット データ型として定義された列にはインデックスを作成しないでください。これらの列のデータ量は非常に大きいか、値が非常に少ないかのいずれかです。
6.3. インデックス分類:
(1) 通常インデックス、一意インデックス、主キーインデックス、全文インデックス、複合インデックス。
- 通常のインデックス: 制限のない最も基本的なインデックス
- 一意のインデックス: ただし、インデックス列の値は一意である必要があり、NULL 値が許可されます。複数の NULL 値にする必要があります。複合インデックスの場合、列値の組み合わせは一意である必要があります。
- 主キー インデックス: null 値を許可しない特別な一意のインデックス。
- フルテキスト インデックス: フルテキスト インデックスは MyISAM テーブルにのみ使用でき、CHAR、VARCHAR、または TEXT タイプのみをサポートします。ファジー マッチング操作などの効率の悪い操作を置き換えるために使用され、以下と組み合わせることができます。全文インデックス作成による複数フィールドの同時複数フィールドの完全なあいまいマッチング。
- 複合インデックス: 主に mysql の効率を向上させるため、複合インデックスを作成する場合、制限条件として最もよく使用される列を降順で左端に配置する必要があります。
(2) クラスター化インデックスと非クラスター化インデックス:
データの物理的な格納順序とインデックス値の順序に従って分類すると、インデックスは次のようになります。クラスター化インデックスと非クラスター化インデックスには 2 つのタイプがあります:
- クラスター化インデックス: テーブル内のデータ ストレージの物理的な順序は次のとおりです。インデックス値の順序。基本的なテーブルには最大でも 1 つのクラスターしか含めることができません。インデックス、クラスター化インデックス列のデータを更新すると、多くの場合、テーブル内のレコードの物理的な順序が変更され、コストがかかります。したがって、頻繁に更新される列にクラスター化インデックスを確立するのは適切ではありません。
- 非クラスター化インデックス: テーブル データの物理的な順序がインデックス値の順序と一致しないインデックス構成では、基本テーブルに複数のインデックスを含めることができます。クラスター化インデックス。
6.4. インデックス データ構造:
一般的なインデックス データ構造には、B ツリー、ハッシュ インデックスが含まれます。
(1) ハッシュ インデックス: MySQL の Memory ストレージ エンジンのみが、Memory テーブルのデフォルトのインデックス タイプであるハッシュ インデックスをサポートします。ハッシュ インデックスはデータをハッシュ値の形式で編成するため、クエリ効率が非常に高く、一度に検索できます。
ハッシュ インデックスの欠点:
- ハッシュ インデックスは等しい値クエリのみを満たすことができますが、範囲クエリや並べ替えには対応できません。データがハッシュ アルゴリズムを通過すると、そのサイズ関係が変化する可能性があるためです。
- 複合インデックスを作成する場合、複合インデックスの一部の列のみをクエリに使用することはできません。ハッシュインデックスは複数の列データを結合してハッシュ値を計算するため、列データごとにハッシュ値を計算しても意味がありません。
- ハッシュの衝突が発生した場合、ハッシュ インデックスはテーブル データのスキャンを避けることができません。ハッシュ値を比較するだけでは十分ではないため、実際の値を比較して要件を満たしているかどうかを判断する必要があります。
(2) B ツリー インデックス: B ツリーは、mysql で最も頻繁に使用されるインデックス データ構造で、Innodb および Myisam ストレージ エンジン モードのインデックス タイプです。 B Tree インデックスは、検索中にルート ノードからリーフ ノードまで複数の IO 操作が必要で、クエリ速度はハッシュ インデックスほどではありませんが、ソートなどの操作に適しています。
B ツリー インデックスの利点:
- ページ内のノードにはコンテンツが保存されず、IO ごとにより多くの行を読み取ることができるため、ディスク I/O 読み取り時間が大幅に削減されます
- 順次アクセス ポインタを持つ B ツリー: B ツリーのインデックス データはすべてリーフ ノードに格納され、順次アクセス ポインタが追加されます。各リーフ ノードは隣接するリーフ ノードへのポインタを持つため、間隔を改善するためにこれが行われます。クエリ効率。
6.5. B ツリーをインデックスとして使用する理由:
インデックス自体も非常に大きいため、すべてを格納することは不可能です。 インデックスは、多くの場合、インデックス ファイルの形式でディスクに保存されます。この場合、インデックス検索処理時にディスク I/O 消費が発生します ディスク I/O アクセスの消費量は、メモリアクセスに比べて数桁大きいため、メリットを評価するのが最善です。インデックスとしてのデータ構造 重要な指標は、検索プロセス中のディスク I/O 操作の数の漸近的な複雑さです。言い換えると、インデックスのデータ構造は、検索プロセス中のディスク I/O アクセスの数を最小限に抑える必要があります。
(1) 局所性原理とプログラムの先読み:
ディスク自体は、機械的な動作の消費と相まって、メインメモリよりもアクセスがはるかに遅いため、効率を向上させるには、ディスク I/O を最小限に抑える必要があります。この目標を達成するために、ディスクは厳密にオンデマンドで読み取るのではなく、毎回事前に読み取ります。たとえ 1 バイトしか必要でない場合でも、ディスクはこの位置から開始して、一定の長さのデータを順番に後方に読み取ります。メモリ。この理論的根拠は、コンピュータ サイエンスにおける有名な局所性原理です。つまり、データの一部が使用されると、通常は近くのデータがすぐに使用されます。通常、プログラム実行中に必要なデータは集中しています。
ディスクのシーケンシャル読み取りは非常に効率的であるため (シーク時間なし、スピン時間が非常に短い)、局所性のあるプログラムに先読みを使用して I/O 効率を向上させることができます。 先読みの長さは通常、ページの整数倍です。プログラムが読み込むデータがメインメモリにない場合、ページフォールト例外が発生し、システムはディスクに読み取り信号を送り、ディスクはデータの開始位置を見つけます。 1 つまたは複数のページを逆方向に読み取り、メモリにロードしてから異常終了し、プログラムは実行を続けます。
(2) B Tree インデックスのパフォーマンス分析:前述したように、ディスク I/O 時間は通常、インデックス構造の品質を評価するために使用されます。 B ツリー分析から始めましょう。B ツリーの取得には、一度に最大 h 個のノードにアクセスする必要があります。同時に、データベースはディスク先読みの原理を巧みに使用して、ノードのサイズを 1 に設定します。ページ、つまり、新しいノードが作成されるたびに、直接アプリケーションが作成されます。ページ スペース。これにより、ノードがページに物理的に格納され、コンピュータのストレージ割り当てがページに合わせて配置されるため、各ノードをI/O が 1 つだけで完全にロードされます。 B ツリーでの取得には最大 h-1 個の I/O (ルート ノードはメモリ内に常駐) が必要で、時間計算量は O(h)=O(logdN) です。一般的な実際のアプリケーションでは、出次数 d は非常に大きな数 (通常は 100 を超える) であるため、h は非常に小さくなります。要約すると、B ツリーをインデックス構造として使用することは非常に効率的です。
赤黒ツリー構造に関しては、時間計算量も O(h) ですが、h は明らかにはるかに深く、論理的に近いノードは物理的に遠い可能性があるため、これを利用することはできません。局所性があるため、IO 効率は B ツリーよりも明らかに劣ります。
また、インデックスデータ構造としてはB Treeの方が適していますが、その理由は内部ノードの出次数dに関係しています。上記の分析から、d が大きいほどインデックスのパフォーマンスが向上し、出次数 d の上限はノード内のキーとデータのサイズに依存することがわかります。 B ツリー内のノードの場合、より大きな出次数を持つことができ、ディスク IO の数は少なくなります。
(3) B-treeインデックスとB-treeインデックスの比較?
B ツリーと B ツリーの構造によれば、次の理由により、ファイル システムやデータベース システムでは B ツリーの方が B ツリーよりも優れていることがわかります。
- (1) B ツリーはデータベース スキャンに役立ちます。B ツリーはディスク IO パフォーマンスを向上させますが、要素トラバーサルの非効率性の問題は解決しません。一方、B ツリーはリーフ ノードをトラバースするだけですべての問題を解決できます。キーワード情報をスキャンするため、B ツリーは範囲クエリや並べ替えなどの操作のパフォーマンスが高くなります。
- (2) B ツリーのディスク IO コストが低い: B ツリーの内部ノードのデータ フィールドにはデータが格納されないため、内部ノードは B ツリーの内部ノードよりも小さくなります。同じ内部ノードのすべてのキーワードが同じディスク ブロックに格納されている場合、ディスク ブロックはより多くのキーワードを保持できます。検索する必要があるキーワードが一度にメモリに読み込まれるほど、I/O の読み取りおよび書き込みの数が相対的に減少します。
- (3) B ツリーのクエリ効率はより安定しています。B ツリーの内部ノードはリーフ ノード内のキーワードのインデックスにすぎず、データを格納しないためです。したがって、キーワード検索では、ルート ノードからリーフ ノードまでのパスをたどる必要があります。すべてのキーワード クエリのパス長は同じであるため、各データのクエリ効率は同等になります。
(4) MySQL の InnoDB および MyISAM ストレージ エンジンでの B Tree インデックスの実装?
MyISAM と InnoDB はどちらも B ツリー インデックスを使用します。MyISAM の主キー インデックスと補助インデックスのデータ フィールドは行のアドレスを保存しますが、InnoDB の主キー インデックスは行のアドレスではなく、行を保存します。すべてのデータ (補助インデックスのデータ フィールドには主インデックスの値が保存されます)。
インデックスの長さ制限:
- Innodb の結合インデックスの場合、各列の長さが 767 バイトを超える場合、767 バイトを超える列はプレフィックス インデックスになります。 Innodb の単一列インデックス、列の長さが 767 を超える場合は、プレフィックス インデックスを取得します (最初の 255 文字を取得します)
- MyISAM の結合インデックスの場合、作成されるインデックスの合計長は 1000 バイトを超えることはできません。それ以外の場合はエラーが発生します。報告され、作成は失敗します。MyISAM の単一列インデックスの場合、最大長は 1000 を超えることはできません。それ以外の場合はアラームが発行されますが、作成は成功し、最終的な作成はプレフィックス インデックスになります (最初の 333 文字が取得されます)。 )
7. SQL 最適化、インデックス最適化、テーブル構造最適化:
(1) MySQL の SQL 最適化とインデックス最適化: https: //blog.csdn.net/a745233700 /article/details/84455241
(2) MySQL テーブル構造の最適化: https://blog.csdn.net/a745233700/article/details/84405087
8. データベース パラメーターの最適化:
MySQL は IO 集中型のアプリケーションであり、その主な役割はデータの管理とストレージです。また、メモリからデータベースを読み取る時間はマイクロ秒レベルであるのに対し、通常のハードディスクから IO を読み取る時間はミリ秒レベルであり、両者の差は 3 桁であることがわかっています。したがって、データベースを最適化するには、最初に IO を最適化する必要があり、ディスク IO を可能な限りメモリ IO に変換します。したがって、MySQL データベースのパラメータを最適化するときは、主にディスク IO を削減するパラメータを最適化します。たとえば、query_cache_size を使用してクエリ キャッシュのサイズを調整し、innodb_buffer_pool_size を使用してバッファのサイズを調整します。
9. Explain の実行計画:
実行計画は、抽象構文ツリーと、SQL 文を渡した後の SQL 文で得られる関連テーブルの統計情報から作成されるクエリです。プラン、このプランはクエリ オプティマイザーによって自動的に分析され、生成されます。動的データサンプリングと統計分析の結果であるため、分析エラー、つまり実行計画が最適ではない可能性があります。 Explain キーワードを使用して、MySQL が SQL クエリ ステートメントを実行する方法を確認し、select ステートメントのパフォーマンスのボトルネックを分析し、クエリを改善します。 Explain 結果は次のとおりです:
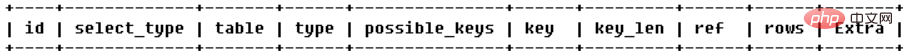 # # 重要なのは、id、type、key、key_len、rows、extra:
# # 重要なのは、id、type、key、key_len、rows、extra:
(1) id: id 列は、SQL の実行順序の識別子として理解できます。いくつかの選択。
異なる ID 値: ID 値が大きいほど優先度が高く、最初に実行されます。(2) select_type: クエリのタイプ。主に通常のクエリ、結合クエリ、サブクエリなどの複雑なクエリを区別するために使用されます。
- 同じ ID 値: 上から下に順番に実行されます。
- id 列は null です。これは、これが結果セットであり、クエリに使用する必要がないことを示します。
(3) table: 表現 行がどのテーブルにアクセスしているのかを説明します
(4) type: アクセス タイプ、つまり、テーブル内の行を検索する方法を MySQL が決定します。最良から最悪の順: system > const > eq_ref > ref > fulltext > ref_or_null > Index_merge > unique_subquery > Index_subquery > range > Index > ALL、例外 all、その他のタイプ すべてのタイプが使用可能Index_merge を除いて、他のタイプは 1 つのインデックスのみを使用できます。一般に、type は ref レベルである必要があり、範囲検索は range レベルに達する必要があります。
system: テーブル (システム テーブルに等しい) 内に一致するデータは 1 つだけあり、これは const 型(6) key: テーブルへのアクセスを最適化するために実際に使用されるインデックス (7) key_len: 実際に使用されるクエリを最適化するためのインデックスの長さ、つまりインデックスで使用されるバイト数。この値を使用して、インデックスのどのフィールドが複数列インデックスで実際に使用されているかを計算できます。 (8)ref: どのフィールドまたは定数がキーとともに使用されているかを表示します。(9)rows: テーブルの統計とインデックスの選択に基づいて、クエリが実行するデータ量を大まかに見積もります。ここでは、正確な値ではなく、行数を読み取る必要があります。 (10)extra: その他の追加情報 インデックスの使用: カバリング インデックスの使用
- const の特殊なケースとみなすことができます。これはインデックスを通じて 1 回検出され、主キー インデックスまたは一意のインデックスの使用を示します。
- eq_ref: 主キーまたは一意のインデックスのフィールドが接続に使用され、一致するデータの 1 行のみが返されます
- ref: 通常のインデックス スキャンでは、複数の一致するデータのクエリ条件行が返される場合があります。
- fulltext: フルテキスト インデックスの取得、フルテキスト インデックスの優先度は非常に高く、フルテキスト インデックスと通常のインデックスが同時に存在する場合、mysql はフルテキスト インデックスを優先します。コストに関係なくテキストインデックスを作成します。
- ref_or_null: ref メソッドと似ていますが、null 値の比較が追加される点が異なります。
- index_merge: クエリで 3 つ以上のインデックス、インデックス マージの最適化方法が使用され、最後に交差または和集合が使用されることを示します。共通の and and or 条件では異なるインデックスが使用されます。
- unique_subquery: サブクエリが値を繰り返さずに一意の値を返す形式内サブクエリに使用されます;
- index_subquery: 補助インデックスまたは定数リストを使用した形式内サブクエリ、サブクエリに使用されます重複した値を返す可能性があり、インデックスを使用してサブクエリの重複を排除できます。
- range: インデックス範囲スキャン。>、<、between、in、like などの演算子を使用するクエリでよく使用されます。
- index: インデックス全体のテーブル スキャン、インデックス ツリーを最初から最後までスキャンします;
- all: テーブル全体を走査して一致する行を見つけます (Index と ALL は両方ともテーブル全体を読み取りますが、インデックスはインデックスから読み取られ、ALL はハードディスクから読み取られます)
#NULL: MySQL は最適化プロセス中にステートメントを分解し、実行中にテーブルやインデックスにアクセスする必要さえありません- (5) possible_keys: クエリで使用できるインデックス
インデックス条件の使用: クエリされた列にはインデックスが付けられていません。 、フィルター条件はインデックスを使用します
- usingtemporary: 中間結果を保存するために一時テーブルを使用します。グループ化操作や並べ替え操作でよく使用されます。通常はグループ化列にインデックスがないためですが、次の理由も考えられます。同時に group by と order by がありますが、group by と order by の列は異なります。一般的に言えば、クエリを最適化する必要があることを意味します。クエリ結果を並べ替えるには、インデックスを使用する方法と、ファイルソート (クイック ソートに基づいた外部並べ替えであり、パフォーマンスは低い) があります。データ量が大きい場合、これは CPU を大量に使用するプロセスになります。パフォーマンス
- 実行計画の詳細の説明に興味がある読者は、この記事を参照してください: https://blog.csdn.net/a745233700/記事/詳細/84335453
10. MySQL マスター/スレーブ レプリケーション:
10.1. MySQL マスター/スレーブ レプリケーションの原理:
スレーブはマスターから binlog バイナリ ログ ファイルを取得し、ログ ファイルを対応する SQL ステートメントに解析して、スレーブ サーバー上でマスター サーバーの操作を再実行します。データは確保されています。マスター/スレーブのレプリケーション プロセスは非同期であるため、スレーブとマスターの間でデータに遅延が発生する可能性があり、データの最終的な整合性のみが保証されます。マスターとスレーブ間のレプリケーション プロセス全体は、主に 3 つのスレッドによって完了します。
にあるスレーブ サーバーに送信します。
- (1) スレーブ SQL スレッド スレッド: リレー ログを読み取り、更新を実行するために作成されます。スレーブ側にあるログに含まれます
- (2) スレーブ I/O スレッド: マスター サーバーの Binlog Dump スレッドによって送信されたコンテンツを読み取り、それをスレーブ サーバーのリレー ログに保存します。スレーブ側:
- (3) ビンログ ダンプ スレッド スレッド (IO スレッドとも呼ばれます): bin-log バイナリ ログの内容をマスター側
注: マスター サーバーに 2 つのスレーブ サーバーが装備されている場合、マスター サーバーには 2 つの Binlog ダンプ スレッドがあり、各スレーブ サーバーには 2 つのスレッドがあります。
10.2. マスター/スレーブ レプリケーション プロセス:
- # (1) マスター サーバーが SQL ステートメントを実行すると、SQL ステートメントは binlog バイナリ ファイルに記録されます。
- (2) スレーブ側の IO スレッドはマスター側に接続し、指定された bin ログ ログ ファイルの指定された pos ノード位置 (またはファイルの先頭から) からコピーされる次のログ コンテンツを要求します。ログ)。
- (3) スレーブ側から IO スレッドリクエストを受信したマスター側は、レプリケーション処理を担当する IO スレッドに通知し、リクエスト情報に従って、指定された pos ノード位置以降の指定された binlog ログを読み取ります。ログ情報はスレーブ側の IO スレッドに返されます。返される情報には、binlog ログに含まれる情報に加えて、マスター側で返される情報の binlog ファイル名と、binlog ログ内の POS ノードの位置も含まれます。
- (4) マスター側 IO によって返された情報を受信した後、スレーブ側の IO スレッドは、受信した binlog ログの内容をスレーブ側のリレー ログ ファイルの末尾に順番に書き込みます。マスター側の binlog ファイル名と pos ノードの場所はマスター情報ファイル (このファイルはスレーブ側に保存されます) に記録されるため、マスターは次回の同期中にどの位置からデータ同期を開始するかを指示できます。 synchronization;
- (5) スレーブ マスター側の SQL スレッドは、リレー ログ ファイルの新しい内容を検出すると、すぐにリレー ログ ファイルの内容を解析し、実際に実行された SQL 文に復元します。マスター側でこれらの SQL ステートメントを実行し、マスターとスレーブの間でデータの一貫性を実現します;
10.3. マスター/スレーブ レプリケーションの利点:
- (1) 読み取りと書き込みの分離により、スレーブ サーバーを動的に追加し、マスター サーバーで書き込みと更新を実行し、スレーブ サーバーで読み取り機能を実行することにより、データベースのパフォーマンスが向上します。
- (2) データのセキュリティの向上 データがスレーブ サーバーにコピーされているため、スレーブ サーバーはレプリケーション プロセスを終了でき、対応するデータを破壊することなくスレーブ サーバーにバックアップできます。マスターサーバー。
- (3) マスターサーバーでリアルタイムデータを生成し、スレーブサーバーでデータを分析することで、マスターサーバーのパフォーマンスを向上させます。
10.4. MySQL でサポートされるレプリケーション タイプとその長所と短所:
binlog ログ ファイルには 2 つの形式があり、1 つはステートメントベース (ステートメントベースのレプリケーション)、もう 1 つは行ベース(行ベースのレプリケーション)です。デフォルトの形式はステートメントベースです。形式を変更したい場合は、サービスの開始時に -binlog-format オプションを使用します。具体的なコマンドは次のとおりです:
mysqld_safe –user=msyql – binlog-format=format&
(1) ステートメントベースのレプリケーション: SQL ステートメントがマスター サーバーで実行され、同じステートメントがスレーブ サーバーで実行されます。効率は比較的高いです。正確なコピーが不可能であることが判明すると、行ベースのコピーが自動的に選択されます。
利点:
- ① SQL ステートメントが記録されるため、必要なストレージ容量が少なくなります。 binlog ログにはデータベース操作を説明するイベントが含まれますが、これらのイベントには、挿入、更新、作成、削除などのデータベースを変更する操作のみが含まれます。逆に、select や desc などの同様の操作は記録されません。
- ② binlog ログ ファイルには、データベースを変更するすべてのステートメントが記録されるため、このファイルはデータベースを監査するための基礎として使用できます。
欠点:
- ① 安全ではありません。データを変更するすべてのステートメントが記録されるわけではありません。非決定的な動作はログに記録されません。たとえば、delete または update ステートメントの場合、limit が使用されているが order by がない場合、これは非決定的ステートメントであるため、記録されません。
- ② インデックス条件のない update、insert...select ステートメントの場合、より多くのデータをロックする必要があり、データベースのパフォーマンスが低下します。
(2) 行ベースのコピー: スレーブ サーバーでコマンドを実行する代わりに、変更された内容をコピーします。mysql5.0 以降でサポートされます。
利点:
- ① すべての変更がコピーされ、これが最も安全なコピー方法です。
- ② 更新の場合は、挿入...ステートメントがロックする行が少なくなるまで待機するを選択します。
欠点:
- ① binlog ログ ファイルを通じてどのステートメントが実行されたかを確認することはできず、スレーブ サーバーで何が受信されたかを知る方法もありません。どのデータが変更されたかを確認することしかできません。
- ② データを記録するため、binlog ログ ファイルが占有する記憶領域はステートメント ベースよりも大きくなります。
- ③ 大量のデータを扱う操作には時間がかかります。
(3) 混合型レプリケーション: デフォルトではステートメントベースのレプリケーションが採用されますが、ステートメントベースのレプリケーションが正確ではないことが判明した場合は、行ベースのレプリケーションが採用されます。
マスター/スレーブ レプリケーションの詳細については、次の記事を参照してください: https://blog.csdn.net/a745233700/article/details/85256818
11。書き込み分離:
11.1. 実装原理:
読み取りと書き込みの分離により、データベースの書き込み操作がデータベースの効率に影響を与えるという問題が解決されます。書き込みよりも読み取りの方がはるかに重要なシナリオに適しています。読み取りと書き込みの分離を実現するための基礎は、マスター/スレーブ レプリケーションです。マスター データベースは、マスター/スレーブ レプリケーションを使用して、自身のデータ変更をスレーブ データベース クラスターに同期します。その後、マスター データベースは、書き込み操作の処理を担当します (もちろん、読み取り操作も実行します)、スレーブ データベースは読み取り操作の処理を担当しますが、書き込み操作は実行できません。また、負荷の状況に応じて、複数のスレーブ データベースを展開して、読み取り操作の速度を向上させ、メイン データベースへの負荷を軽減し、システム全体のパフォーマンスを向上させることができます。
11.2 読み取りと書き込みの分離によってパフォーマンスが向上する理由:
- (1) 物理サーバーと負荷分散を追加します。
(2) マスターとスレーブは自身の書き込みと読み取りのみを担当するため、X ロックと S ロックの競合が大幅に軽減されます;- (3) スレーブ ライブラリは MyISAM で構成できます。システム オーバーヘッド;
- (4) マスター/スレーブ レプリケーションのもう 1 つの主な機能は、冗長性を高め、可用性を向上させることです。1 つのデータベース サーバーがダウンした場合でも、迅速に復元できます。別のスレーブ データベースを調整して可能な限り対応します。
11.3. Mysql 読み書き分割実装:
- (1) プログラム コードに基づく内部実装:コードでは、ルーティング分類は選択と挿入に基づいて実行されます。利点は、プログラムがコードに実装され、追加のハードウェア費用が必要ないため、パフォーマンスが向上することですが、欠点は、開発者が実装する必要があり、運用保守担当者が開始する手段がないことです。
- (2) 中間プロキシ層に基づく実装: プロキシは通常、アプリケーション サーバーとデータベース サーバーの間にあり、アプリケーション サーバーからリクエストを受信した後、プロキシ データベース サーバーはそれをバックエンドに転送します。エージェント層は以下の代表例が挙げられます。
#12. サブデータベースとテーブル: 垂直サブテーブル、垂直サブデータベース、水平サブテーブル、水平サブデータベース
読み取り/書き込みの分離は、データベースの読み取りおよび書き込み操作の負荷を解決しますが、データベースのストレージの負荷を分散しません。サブデータベースとサブテーブルを使用すると、データベースのストレージのボトルネックを解決し、データベースのクエリ効率を向上させることができます。データベース。
12.1. 垂直分割:
(1) テーブルの垂直分割: テーブルをフィールドごとに複数のテーブルに分割し、各テーブルにフィールドの一部を格納します。それフィールド。一般に、よく使用されるフィールドは 1 つのテーブルに配置され、あまり使用されないフィールドは別のテーブルに配置されます。
利点:
(1) IO 競合を回避し、テーブルがロックされる可能性を減らします。大きなフィールドは効率が低いため、まず、大きなフィールドはより多くのスペースを占有し、単一ページに格納される行数が減少するため、IO 操作が増加します。次に、データ量が多く、読み取り時間が長くなります。 。
(2) 人気のあるデータのクエリ効率を向上させることができます。
(2) 垂直データベース分割: さまざまなビジネス モジュールに応じてテーブルをさまざまなデータベースに分割します。これは、ビジネスとビジネス ロジック間の結合が非常に低い場合に適しています。明確なシステムです。
利点:
- ビジネス内の結合を減らし、異なるビジネスの階層管理を容易にする
- IO およびデータベース接続の数を増やし、問題を解決できる単一マシンの問題 ハードウェアストレージリソースのボトルネック問題
# (3) 垂直分割 (サブデータベース、サブテーブル) のデメリット:
#12.2、水平分割:
- 主キーが冗長化され、冗長なカラムを管理する必要がある
##トランザクションの処理が複雑になる- ##単一テーブルのデータ量が多すぎるという問題が依然としてある
(1) テーブルの水平分割: 同一データベース内で、同一テーブルのデータを一定の規則に従って複数のテーブルに分割します。
利点:
- 単一テーブル内の過剰なデータ量の問題を解決します
- IO競合を回避し、テーブルロックの可能性を低減します
(2) データベースの水平分割: 同じテーブルのデータを一定の規則に従って異なるデータベースに分割し、異なるデータベースを異なるサーバーに配置することができます。
# (3) 水平分割の欠点 (サブテーブル、サブデータベース):利点:
- 単一データベース内の大量のデータによるボトルネック問題を解決します。
- IO 競合、ロック競合、およびデータベースに関する問題を削減します。特定のデータベースは他のデータベースに影響を与えず、システムの安定性と可用性が向上します
シャーディングされたトランザクションの一貫性を解決するのは困難です
- クロスノード JOIN のパフォーマンスが低く、ロジックが複雑になります
- データの拡張が難しく、保守も困難です
12.3. サブデータベースおよびサブテーブルに存在する問題の解決策:
(1) トランザクションの問題:① 解決策 1: 分散トランザクションを使用する :利点: データベースによって管理され、シンプルかつ効果的です。
② オプション 2: プログラムとデータベースが共同して実装を制御する原理は、複数のデータベースにわたる分散トランザクションを、単一のデータベース上にのみ存在する複数の小さなトランザクションに分解し、アプリケーションに渡すことです。個々の小さなトランザクションを全体的に制御するプログラム。- 欠点: 特にシャードの数が増えると、パフォーマンス コストが高くなります。
利点: パフォーマンス上の利点;
- 欠点: アプリケーションではトランザクションの柔軟な制御が必要です。 Spring のトランザクション管理を使用する場合、変更を行う際に特定の困難に直面することになります。
(2) クロスノード結合の問題:
この問題を解決する一般的な方法は、2 回クエリを実行することです。最初のクエリ結果は、関連データの ID を見つけることに重点を置き、これらの ID に基づいて 2 番目のリクエストを開始して、関連データを取得します。(3) クロスノード数、順序付け、グループ化、ページング、および集計関数の問題:
このような問題では、データ収集全体に基づいて計算する必要があるためです。ほとんどのエージェントはマージ作業を自動的に処理しません。解決策はクロスノード結合の問題を解決するのと似ています。結果は各ノードで取得され、アプリケーション側でマージされます。結合とは異なり、各ノードのクエリを並列実行できるため、単一の大きなテーブルよりもはるかに高速です。ただし、結果セットが大きい場合、アプリケーション メモリの消費が問題になります。12.4. データベースをテーブルに分割した後、ID キーをどのように扱うか? # データベースをテーブルに分割した場合、各テーブルの ID は 1 から始めることができないため、グローバル ID が必要になります。グローバル ID を設定するには、主に以下の方法があります。
##(1) UUID:
利点: ローカルで生成された ID、リモート呼び出しは不要、グローバルに一意で繰り返されません。
欠点: 多くのスペースを占有するため、インデックスとしては適していません。
- (2) データベース自動インクリメント ID: データベースをテーブルに分割した後、データベース自動インクリメント ID を使用します 主キーを生成するための専用ライブラリが必要です サービスがリクエストを受信するたびに、最初にこれを要求します。意味のないデータをデータベースに挿入し、データベースによって自動的にインクリメントされる ID を取得し、この ID を使用して別のデータベースとテーブルにデータを書き込みます。
利点: シンプルで実装が簡単です。
欠点: 同時実行性が高いとボトルネックが発生します。
- (3) Redis は ID:
を生成します。 利点: データベースに依存せず、パフォーマンスが向上します。
欠点: 新しいコンポーネントの導入によりシステムの複雑さが増加します
- (4) Twitter のスノーフレーク アルゴリズム: これは 64 ビット長の ID であり、そのうちの 1 ビットは使用されず、41 ビットがミリ秒として使用され、10 ビットが作業マシン ID として使用され、12 ビットがシリアル番号として使用されます。
1bit: バイナリの最初のビットが 1 の場合、それは負の数ですが、ID を負にすることはできないため、最初のビットはデフォルトで 0 になります。タイムスタンプ、単位はミリ秒です。
10bit: 稼働中のマシン ID を記録します。そのうち 5 ビットはコンピュータ室 ID を表し、5 ビットはマシン ID を表します。
13、パーティション:- 12 ビット: 同じミリ秒内に生成された異なる ID を記録するために使用されます。
- (5) Meituan の Leaf 分散 ID 生成システム、Meituan-Dianping の分散 ID 生成システム:
パーティショニングとは、テーブル データを特定のルールに従って異なる領域に格納すること、つまり、テーブル データ ファイルを複数の小さなブロックに分割することです。データをクエリする場合、データがどの領域に格納されているかがわかっていれば問題ありません。を実行し、対応する領域で直接クエリを実行します。すべてのテーブル データをクエリする必要がないため、クエリのパフォーマンスが向上します。同時に、テーブル データが特に大きく 1 つのディスクに収まらない場合は、ストレージのボトルネック問題を解決するためにデータを別のディスクに割り当てることもできます。複数のディスクを使用すると、ディスクの IO 効率が向上し、データベースのパフォーマンス。 パーティション テーブルを使用する場合は、パーティション フィールドを主キーまたは一意のインデックスに配置する必要があり、各テーブルのパーティションの最大数は 1024 であることに注意する必要があります。一般的なパーティション タイプは、レンジ パーティション、リスト パーティションです。 、ハッシュ パーティション、キー パーティション、
- (1) 範囲分割: 連続間隔範囲に従って分割します。
- (2) リスト分割: 指定されたセット内の値に従って分割を選択します。
- (3) ハッシュ分割: テーブルに挿入する行の列値を使用して計算されるユーザー定義式の戻り値に基づいて分割します。この関数には、負でない整数値を生成する MySQL の有効な式を含めることができます。
- (4) キー パーティショニング: HASH パーティショニングと似ていますが、キー パーティショニングが 1 つ以上の列の計算のみをサポートし、キー パーティショニングのハッシュ関数が MySQL サーバーによって提供される点が異なります。
(1) テーブルパーティショニングの利点:
① スケーラビリティ:
- パーティショニングはオンになります。異なるディスクを使用すると、単一ディスクの容量ボトルネックの問題を解決でき、より多くのデータを保存できるほか、単一ディスクの IO ボトルネック問題も解決できます。
② データベースのパフォーマンスの向上:
- データベースの取得中に走査する必要があるデータの量を削減します。クエリを実行する場合、クエリを実行する必要があるのは、データベースに対応するパーティションのみです。データ。
- Innodb の単一インデックスの相互排他的アクセス制限を回避します
- sum() や count() などの集計関数については、各パーティションで並列処理を実行でき、最終的にのみ実行できます。得られた結果
③ データの運用・保守管理が便利:
- 保存の意味を失ったデータについては、対応するパーティションを削除することで、迅速な削除を実現できます。たとえば、特定の時点で履歴データを削除するには、truncate を直接実行するか、パーティション全体を直接削除する方が、削除するより効率的です。
- シナリオによっては、単一のパーティション テーブルのバックアップの方が効率的です。効率的に復元できます。
#14. 通常、主キーとして自動インクリメント ID または UUID を使用しますか?
(1) 自動インクリメント ID:
UUID を使用する利点:自動インクリメント ID を使用する利点:
- フィールド長が大幅に小さくなりますUUIDよりも。
- データベースには自動的に番号が付けられ、順番に保存されるため、検索に便利です。
- 主キーの重複を心配する必要はありません。
self- を使用するデメリットID の増加:
## (2) UUID: ユニバーサル固有の識別コード UUID は、現在時刻、カウンタ、ハードウェア ID およびその他のデータに基づいて計算および生成されます。
- これは自己増加するため、特定のビジネス シナリオでは、他の人がビジネスの量を確認するのが簡単です。
#データの移行やテーブルのマージが発生すると、非常に面倒になります- 同時実行性が高いシナリオでは、自己増加するロックの競合によってデータベースのスループットが低下します
UUID はランダムに生成されるため、ランダム IO が発生し、挿入速度に影響を及ぼし、ハードディスクの使用率が低下します。
- は、データベースのスループットを向上させるためにアプリケーション層で生成できます。
- 業務量の漏洩を心配する必要はありません。
- UUID を使用するデメリット:
通常の状況では、
- UUID は多くのスペースを占有し、より多くのインデックスが作成されるほど影響は大きくなります。
- UUID 間のサイズの比較は、自己増加する ID よりもはるかに遅く、クエリの速度に影響します。
15. ビュー:
ビューは 1 つ以上のテーブル (またはビュー) から派生したテーブルであり、その内容は次のように定義されます。クエリ。ビューは仮想テーブルです。データベースにはビューの定義のみが保存され、ビューに対応するデータは保存されません。ビューのデータを操作するとき、システムは、ビューの定義に従って、対応する基本テーブルを操作します。景色。
ビューは基本テーブルの上に構築されたテーブルであると言え、その構造と内容は基本テーブルから派生し、基本テーブルの存在に基づいて存在します。ビューは 1 つの基本テーブルまたは複数の基本テーブルに対応できます。ビューは、基本的なテーブルと論理的な意味で確立された新しい関係を抽象化したものです。
(1) ビューの利点:操作を簡素化し、頻繁に使用されるデータをビューとして定義します16. ストアド プロシージャ プロシージャ:悪いパフォーマンスを向上させるために、データベースはビューのクエリを基本テーブルのクエリに変換する必要があります。ビューが複雑な複数テーブル クエリによって定義されている場合、ビューの単純なクエリであってもデータベースによって処理される必要があります。複雑な組み合わせなので時間がかかります。
- セキュリティ、ユーザーはデータのクエリと変更のみ可能
- #論理的な独立性、実際のテーブルの構造の影響を保護する
- (2) ビューの欠点:
SQL ステートメントは最初にコンパイルしてから実行する必要があり、
ストアド プロシージャは特定の操作を完了するためのプロシージャのセット 関数 SQL ステートメントのセットはコンパイルされてデータベースに保存され、ユーザーはストアド プロシージャの名前を指定し、パラメータを指定することによってそれを呼び出します。
データベースを操作するための複雑なロジックもプログラムを使用して実装できるのに、なぜストアド プロシージャが必要なのでしょうか?主な理由は、プログラムを使用して API を呼び出す効率が比較的遅いためです。アプリケーションは、実行のためにエンジンを介して MYSQL エンジンに SQL ステートメントを渡す必要があります。MySQL に直接処理を任せたほうがよいでしょう。それは最も熟練しており、完了することができます。
ストアド プロシージャの利点:
- (1) 標準コンポーネント プログラミング: ストアド プロシージャを作成した後、書き直すことなくプログラム内で複数回呼び出すことができます。プロシージャ ストアド プロシージャの SQL ステートメント。また、DBA は、アプリケーションのソース コードに影響を与えることなく、いつでもストアド プロシージャを変更できます。
- (2) 実行速度の高速化: 操作に大量の Transaction-SQL コードが含まれる場合、または複数回実行される場合、ストアド プロシージャはバッチ処理よりもはるかに高速に実行されます。ストアド プロシージャはプリコンパイルされているため、ストアド プロシージャが初めてクエリされると、オプティマイザがストアド プロシージャを分析して最適化し、最終的にシステム テーブルに保存される実行プランを提供します。バッチ Transaction-SQL ステートメントは、実行するたびにコンパイルして最適化する必要があり、速度は比較的遅くなります。
- (3) SQL 言語の機能と柔軟性の強化: ストアド プロシージャは制御文で記述でき、柔軟性が高く、複雑な判断や複雑な操作を完了できます。
- (4) ネットワーク トラフィックの削減: 同じデータベース オブジェクトに対する操作 (クエリ、変更など) の場合、この操作に含まれる Transaction-SQL ステートメントがストアド プロシージャに編成されている場合、操作の実行時にクライアント コンピュータ上でストアド プロシージャが呼び出されるとき、呼び出しステートメントのみがネットワーク経由で送信されるため、ネットワーク トラフィックが大幅に削減され、ネットワーク負荷が軽減されます。
- (5) セキュリティ機構として活用する: 特定のストアドプロセスの実行権限を制限することで、該当するデータへのアクセス権限を制限し、不正なユーザーによるデータへのアクセスを回避できます。データのセキュリティを確保します。
17. トリガー:
トリガーはテーブルに関連するデータベース オブジェクトです。トリガーがテーブルに表示されると、トリガーが見つかります。イベントが指定され、定義された条件が満たされると、トリガーで定義された一連のステートメントが実行されます。 トリガーの特性をデータベース側に適用して、データの整合性を確保できます。トリガーは特別なストアド プロシージャです。違いは、ストアド プロシージャは call を使用して呼び出す必要があるのに対し、トリガーは呼び出しや手動呼び出しを必要としないことです。特定のテーブルでデータを挿入、削除、または変更するときに実行をトリガーします。データベース自体の標準機能よりも高度かつ複雑なデータ制御機能を備えています。
18. カーソル:
カーソルは水泳の識別子であり、ポインターとして機能します。データベースにクエリを実行し、結果セット内のすべてのレコードを返します。ただし、一度に抽出できるレコードは 1 つだけです。つまり、対応する操作を実行するために一度に指定および取得できるデータ行は 1 行だけです。 カーソルを使用しないときは、誰かが一度にすべてを与えているのと同じですが、カーソルを使用した後は、誰かがそれを 1 つずつあなたに与えているのと同じです。このとき、これを見てください。それが良いか悪いかは、自分で決めるのです。
推奨学習: mysql ビデオ チュートリアル
以上がMySQL データベースに関するよくある面接の質問を要約して整理するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7536
7536
 15
1379
52
82
11
21
86
15
1379
52
82
11
21
86

 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
