

この記事では、python に関する関連知識を提供します。主に、XML の基本の概要、Python による XML ファイルの解析、XML ファイルの作成、XML ファイルの更新など、Python による XML ファイルの操作方法に関する関連問題を紹介します。 , など、以下で見ていきましょうので、皆さんの参考になれば幸いです。

特徴:
機能:
<?xml version="1.0” encoding=' "UTF-8" standalone=" no”?>


 ## 2. Python は XML ファイルを解析します
## 2. Python は XML ファイルを解析します
ファイルを作成します: <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class="brush:php;toolbar:false"><collection>
<class>
<code>2022001</code>
<number>10</number>
<teacher>小白</teacher>
</class>
<class>
<code>2022002</code>
<number>20</number>
<teacher>小红</teacher>
</class>
<class>
<code>2022003</code>
<number>30</number>
<teacher>小黑</teacher>
</class></collection></pre><div class="contentsignin">ログイン後にコピー</div></div>1.ElementTree メソッド
要素オブジェクト メソッド:
#説明 1)接下来,我们加载这个文档,并进行解析: 2) 然后,我们获取根元素(root element): 3)根元素(root)是一个Element对象。我们看看根元素都有哪些属性: 4)根元素也具备遍历其直接子元素的接口: 5)通过索引值来访问特定的子元素: 6) 查找需要的元素 从上面的示例中,可以明显发现我们能够通过简单的递归方法(对每一个元素,递归式访问其所有子元素)获取树中的所有元素。但是,由于这是十分常见的工作,ET提供了一些简便的实现方法。 Element对象有一个iter方法,可以对某个元素对象之下所有的子元素进行深度优先遍历(DFS)。ElementTree对象同样也有这个方法。下面是查找XML文档中所有元素的最简单方法: 7)对树进行任意遍历——遍历所有元素,iter方法可以接受tag名称,然后遍历所有具备所提供tag的元素: 8)支持通过XPath查找元素 9)查找所有具备某个name属性的className元素: 10)完整解析代码 输出结果: DOM (Document Object Model)将XML文档作为一棵树状结构进行分析,获取节点的内容以及相关属性,或是新增、删除和修改节点的内容。XML解析器在加载XML文件以后,DQM模式将XML文件的元素视为一个树状结构的节点,一次性读入内存。 解析代码: 输出结果: 语法格式: 参数说明: 案例代码: 生成 向xml中插入新的子元素 案例代码: 输出结果:添加了新节点 记录工作中常用的一个小技巧 cmd控制台安装第三方模块: 新建一个 转换代码实现: 输出结果(生成json文件): 新建 转换代码实现: 输出结果(生成xml文件): 推荐学习:python视频教程
メソッド名#クラスメソッド
説明
##Element.iter(tag=None)
要素のすべての子孫を走査するか、走査して検索するタグを指定できます。
Element.iterfind(path, namespaces=None)
タグまたはパスに基づいてすべての子孫を検索します。
Element.itertext() #Element.findall(path)
すべての子孫を走査し、テキスト値を返します。
Element.findtext(path,default=None, namespaces=None)タグまたはパスが一致する現在の要素の下の直接ノードを検索します
Element.find(path)最初に一致した子要素を検索し、そのテキスト値を返します。一致するオブジェクトはタグまたはパスです。
Element.text現在の要素の下で、タグまたはパスが一致する最初の直接ノードを検索します。
Element.get(key,default=None)現在の要素のテキスト値を取得します。
Element.keys()要素の指定されたキーに対応する属性値を取得します。そのような属性がない場合は、デフォルト値を返します。
要素の属性名のリストを返します##要素 .items()
Return (name, value) list
##Element.getchildren()
#Element.getiterator(tag=None)
:
##Element.tag
ノード名 (タグ) (文字列)
Element.attrib 属性 (dict)
Element.text Text(text)(str)
Element.tail 追加テキスト (末尾) (str)
Element[:] 子ノード リスト (リスト)
>>> import xml.etree.ElementTree as ET>>> tree = ET.ElementTree(file='1.xml')
>>> tree.getroot()<element></element>
>>> root = tree.getroot()>>> root.tag, root.attrib('collection', {'shelf': 'New Arrivals'})>>> for child_of_root in root:... print(child_of_root.tag, child_of_root.attrib)...class {'className': '1班'}class {'className': '2班'}class {'className': '3班'}>>> root[0].tag, root[0].text('class', '\n\t ')>>> for elem in tree.iter():... print(elem.tag, elem.attrib)...collection {'shelf': 'New Arrivals'}class {'className': '1班'}code {}number {}teacher {}class {'className': '2班'}code {}number {}teacher {}class {'className': '3班'}code {}number {}teacher {}>>> for elem in tree.iter(tag='teacher'):... print(elem.tag, elem.text)...teacher 小白
teacher 小红
teacher 小黑
>>> for elem in tree.iterfind('class/teacher'):... print(elem.tag, elem.text)...teacher 小白
teacher 小红
teacher 小黑>>> for elem in tree.iterfind('class[@className="1班"]'):... print(elem.tag, elem.attrib)...class {'className': '1班'}import xml.etree.ElementTree as ET
tree = ET.ElementTree(file='1.xml')print(type(tree))root = tree.getroot() # root是根元素print(type(root))print(root.tag)for index, child in enumerate(root):
print("第%s个%s元素,属性:%s" % (index, child.tag, child.attrib))
for i, child_child in enumerate(child):
print("标签:%s,内容:%s" % (child_child.tag, child_child.text))<class><class>collection
第0个class元素,属性:{'className': '1班'}标签:code,内容:2022001标签:number,内容:10标签:teacher,内容:小白
第1个class元素,属性:{'className': '2班'}标签:code,内容:2022002标签:number,内容:20标签:teacher,内容:小红
第2个class元素,属性:{'className': '3班'}标签:code,内容:2022003标签:number,内容:30标签:teacher,内容:小黑</class></class>2、DOM 方式
from xml.dom.minidom import parse# 读取文件dom = parse('1.xml')# 获取文档元素对象elem = dom.documentElement# 获取 classclass_list_obj = elem.getElementsByTagName('class')print(class_list_obj)print(type(class_list_obj))for class_element in class_list_obj:
# 获取标签中内容
code = class_element.getElementsByTagName('code')[0].childNodes[0].nodeValue
number = class_element.getElementsByTagName('number')[0].childNodes[0].nodeValue
teacher = class_element.getElementsByTagName('teacher')[0].childNodes[0].nodeValue print('code:', code, ', number:', number, ', teacher:', teacher)[<dom>, <dom>, <dom>]<class>code: 2022001 , number: 10 , teacher: 小白
code: 2022002 , number: 20 , teacher: 小红
code: 2022003 , number: 30 , teacher: 小黑</class></dom></dom></dom>
三、Python写入XML文件
doc.writexml():生成xml文档,将创建的存在于内存中的xml文档写入本地硬盘中,这时才能看到新建的xml文档writexml(file,indent=’’,addindent=’’,newl=’’,endocing=None)
file:要保存为的文件对象名indent:根节点的缩进方式allindent:子节点的缩进方式newl:针对新行,指明换行方式encoding:保存文件的编码方式import xml.dom.minidom
# 1、在内存中创建一个空的文档doc = xml.dom.minidom.Document()
# 2、创建根元素root = doc.createElement('collection ')# print('添加的xml标签为:',root.tagName)
# 3、设置根元素的属性root.setAttribute('type', 'New Arrivals')
# 4、将根节点添加到文档对象中doc.appendChild(root)
# 5、创建子元素book = doc.createElement('book')
# 6、添加注释book.appendChild(doc.createComment('这是一条注释'))
# 7、设置子元素的属性book.setAttribute('语言', 'java')
# 8、子元素中嵌套子元素,并添加文本节点name = doc.createElement('name')name.appendChild(doc.createTextNode('java基础'))price = doc.createElement('价格')price.appendChild(doc.createTextNode('99元'))number = doc.createElement('number')number.appendChild(doc.createTextNode('剩余100本'))# 9、将子元素添加到boot节点中book.appendChild(name)book.appendChild(price)book.appendChild(number)# 10、将book节点添加到root根元素中root.appendChild(book)# 创建子元素book = doc.createElement('book')# 设置子元素的属性book.setAttribute('语言', 'python')# 子元素中嵌套子元素,并添加文本节点name = doc.createElement('name')name.appendChild(doc.createTextNode('python基础'))price = doc.createElement('价格')price.appendChild(doc.createTextNode('50元'))number = doc.createElement('number')number.appendChild(doc.createTextNode('剩余20本'))# 将子元素添加到boot节点中book.appendChild(name)book.appendChild(price)book.appendChild(number)# 将book节点添加到root根元素中root.appendChild(book)print(root.toxml())fp = open('./书籍.xml', 'w', encoding='utf-8') # 需要指定utf-8的文件编码格式,不然notepad中显示十六进制doc.writexml(fp, indent='', addindent='\t', newl='\n', encoding='utf-8')fp.close()书籍.xml文件: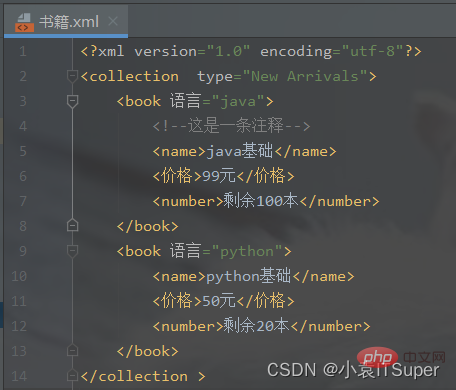
四、Python更新XML文件
import xml.dom.minidomfrom xml.dom.minidom import parse# 对book.xml新增一个子元素english,并删除math元素xml_file = './书籍.xml'# 拿到根节点domTree = parse(xml_file)rootNode = domTree.documentElement# rootNode.removeChild(rootNode.getElementsByTagName('book')[0])# print(rootNode.toxml())# 在内存中创建一个空的文档doc = xml.dom.minidom.Document()book = doc.createElement('book')book.setAttribute('语言', 'c++')# 子元素中嵌套子元素,并添加文本节点name = doc.createElement('name')name.appendChild(doc.createTextNode('c++基础'))price = doc.createElement('价格')price.appendChild(doc.createTextNode('200元'))number = doc.createElement('number')number.appendChild(doc.createTextNode('剩余300本'))# 将子元素添加到boot节点中book.appendChild(name)book.appendChild(price)book.appendChild(number)math_book = rootNode.getElementsByTagName('book')[0]# insertBefore方法 父节点.insertBefore(新节点,父节点中的子节点)rootNode.insertBefore(book, math_book)# appendChild将新产生的子元素在最后插入rootNode.appendChild(book)print(rootNode.toxml())with open(xml_file, 'w', encoding='utf-8') as fh:
domTree.writexml(fh, indent='', addindent='\t', newl='', encoding='utf-8')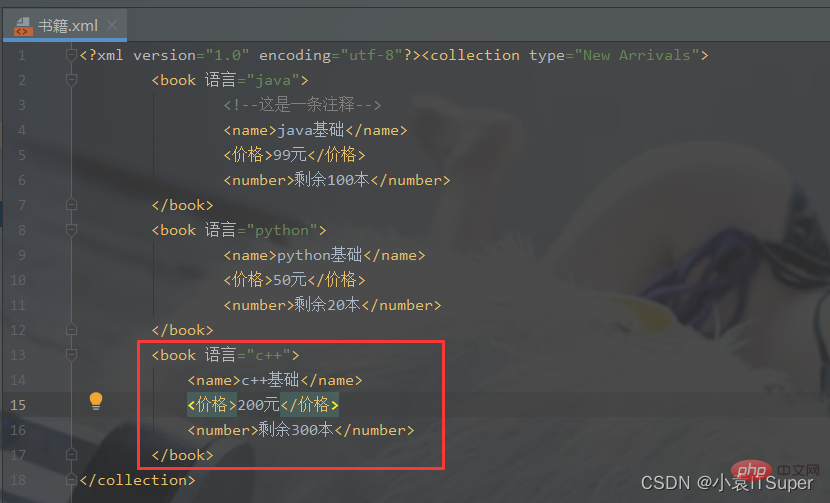
五、XML文件和JSON文件互转
pip install xmltodict
1、XML文件转为JSON文件
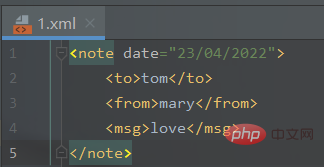
1.xml文件:<note>
<to>tom</to>
<from>mary</from>
<msg>love</msg></note>
import jsonimport xmltodictdef xml_to_json(xml_str):
"""parse是的xml解析器,参数需要
:param xml_str: xml字符串
:return: json字符串
"""
xml_parse = xmltodict.parse(xml_str)
# json库dumps()是将dict转化成json格式,loads()是将json转化成dict格式。
# dumps()方法的ident=1,格式化json
json_str = json.dumps(xml_parse, indent=1)
return json_str
XML_PATH = './1.xml' # xml文件的路径with open(XML_PATH, 'r') as f:
xmlfile = f.read()
with open(XML_PATH[:-3] + 'json', 'w') as newfile:
newfile.write(xml_to_json(xmlfile))
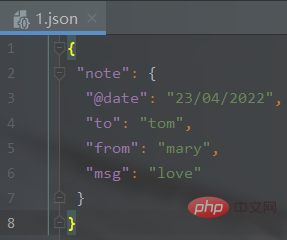
2、JSON文件转换为XML文件
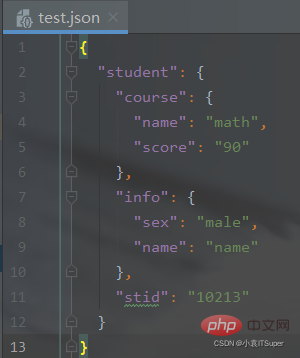
test.json文件:{
"student": {
"course": {
"name": "math",
"score": "90"
},
"info": {
"sex": "male",
"name": "name"
},
"stid": "10213"
}}
import xmltodictimport jsondef json_to_xml(python_dict):
"""xmltodict库的unparse()json转xml
:param python_dict: python的字典对象
:return: xml字符串
"""
xml_str = xmltodict.unparse(python_dict)
return xml_str
JSON_PATH = './test.json' # json文件的路径with open(JSON_PATH, 'r') as f:
jsonfile = f.read()
python_dict = json.loads(jsonfile) # 将json字符串转换为python字典对象
with open(JSON_PATH[:-4] + 'xml', 'w') as newfile:
newfile.write(json_to_xml(python_dict))
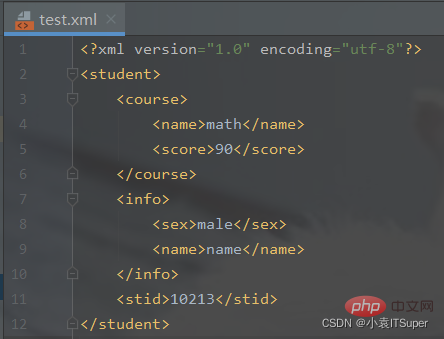
以上がPython が XML ファイルをどのように操作するかを分析してみましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



