

この記事では、mysql に関する関連知識を提供します。主にアーキテクチャ原則に関する関連内容を紹介します。MySQL Server のアーキテクチャは、上から順にネットワーク接続層とサービス層に大別できます。 、ストレージ エンジン層、システム ファイル層について、一緒に見ていきましょう。皆さんのお役に立てれば幸いです。

推奨学習: mysql ビデオ チュートリアル
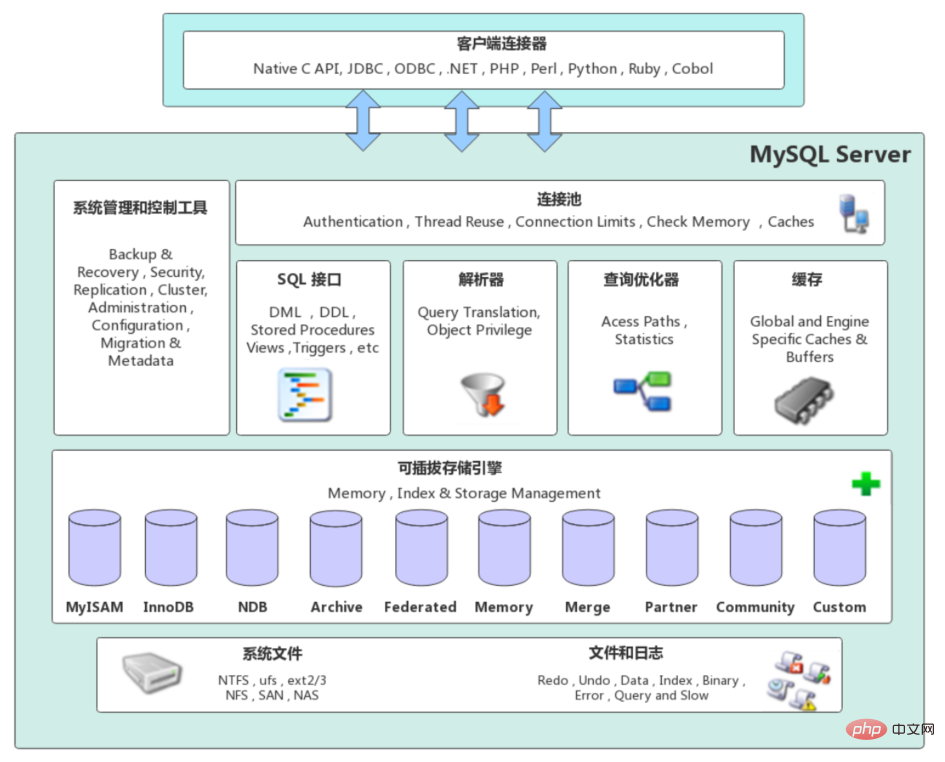
MySQL Server のアーキテクチャは、上からネットワーク接続層、サービス層、ストレージ エンジン層、システム ファイル層に大別できます。
性別 = 1 のユーザーから uid、名前を選択;選択-->>投影-->>結合戦略場所に基づいて最初に選択ステートメントの選択は、すべてのデータをクエリしてからフィルタリングすることを意味するわけではありません;
- select クエリは、uid と名前に基づいて属性プロジェクションを実行しますが、すべてのフィールドは削除しません;
- 前の選択とプロジェクションをに接続します最後にクエリを生成します。 結果;
ストレージ エンジンは、MySQL アーキテクチャの 3 番目の層に位置しており、 MySQL担当 ファイルを扱うサブシステムであり、MySQLが提供するファイルアクセス層の抽象インタフェースをベースにカスタマイズされたファイルアクセス機構であり、この機構をストレージエンジンと呼びます。
show Engines コマンドを使用して、現在のデータベースでサポートされているエンジン情報を表示します。 
バージョン 5.5 より前は、MyISAM ストレージ エンジンがデフォルトで使用され、5.5 からは InnoDB ストレージ エンジンが使用されました。
MySQL バージョン 5.5 以降、InnoDB がデフォルトでエンジンとして使用され、トランザクション処理に優れ、自動クラッシュ回復機能が備わっています。以下は公式の InnoDB エンジン アーキテクチャ図であり、主にメモリ構造とディスク構造の 2 つの部分に分かれています。
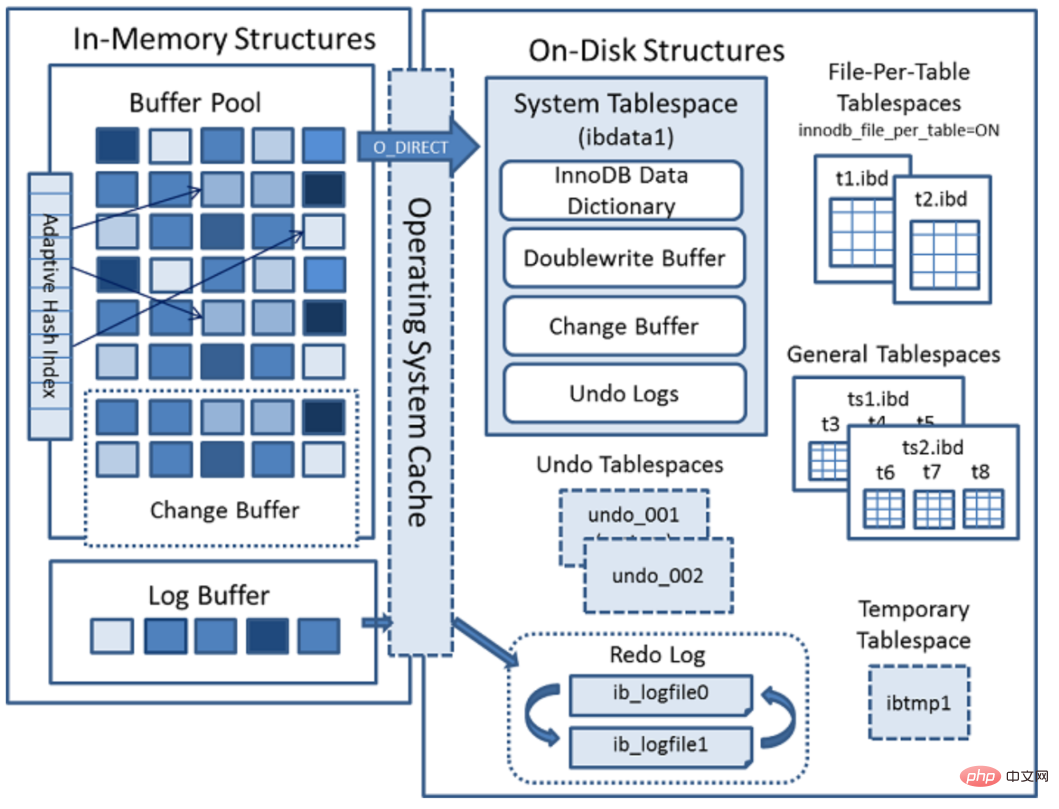
メモリ構造には、主にバッファ プール、変更バッファ、アダプティブ ハッシュ インデックス、ログの 4 つの主要コンポーネントが含まれています。バッファ。
テーブルスペース: テーブル構造とデータを保存するために使用されます。表スペースは、システム表スペース、独立表スペース、一般表スペース、一時表スペース、UNDO表スペースおよびその他のタイプに分類されます。
InnoDB データ ディクショナリ、二重書き込みバッファ、変更バッファ、および元に戻すログを含むストレージ領域。システム表スペースには、デフォルトでシステム表スペース内の任意のユーザーによって作成された表データと索引データも含まれます。システム表領域は複数の表で共有されるため、共有表領域です。このスペースのデータ ファイルはパラメータ innodb_data_file_path によって制御され、デフォルト値は ibdata1:12M:autoextend (ファイル名は ibdata1、12MB、自動的に拡張されます) です。
CREATE TABLESPACE ts1 ADD DATAFILE ts1.ibd Engine=InnoDB; //创建表空 间ts1 CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1; //将表添加到ts1 表空间
はデフォルトで有効になっており、独立テーブルスペースは単一テーブルのテーブルスペースである場合、テーブルはシステムテーブルスペースではなく独自のデータファイルに作成されます。 innodb_file_per_table オプションが有効になっている場合、テーブルはテーブルスペースに作成されます。それ以外の場合、innodb はシステム テーブルスペースに作成されます。各テーブル ファイルのテーブルスペースは .ibd データ ファイルによって表され、デフォルトでデータベース ディレクトリに作成されます。表スペース表ファイルは、動的 (動的) および圧縮 (圧縮) 行フォーマットをサポートします。
一般表領域は、create tablespace 構文を使用して作成された共有表領域です。一般的なテーブル スペースは、mysql データ ディレクトリの外部の他のテーブル スペースに作成でき、複数のテーブルを収容でき、すべての行フォーマットをサポートします。
Undo テーブルスペースは 1 つ以上の Undo ログ ファイルで構成されます。 MySQL 5.7 より前では、Undo はシステム テーブルスペースの共有領域を占有していましたが、5.7 以降、Undo はシステム テーブルスペースから分離されました。
セッション一時表領域とグローバル一時表領域の 2 つのタイプに分かれています。
Undo ログ
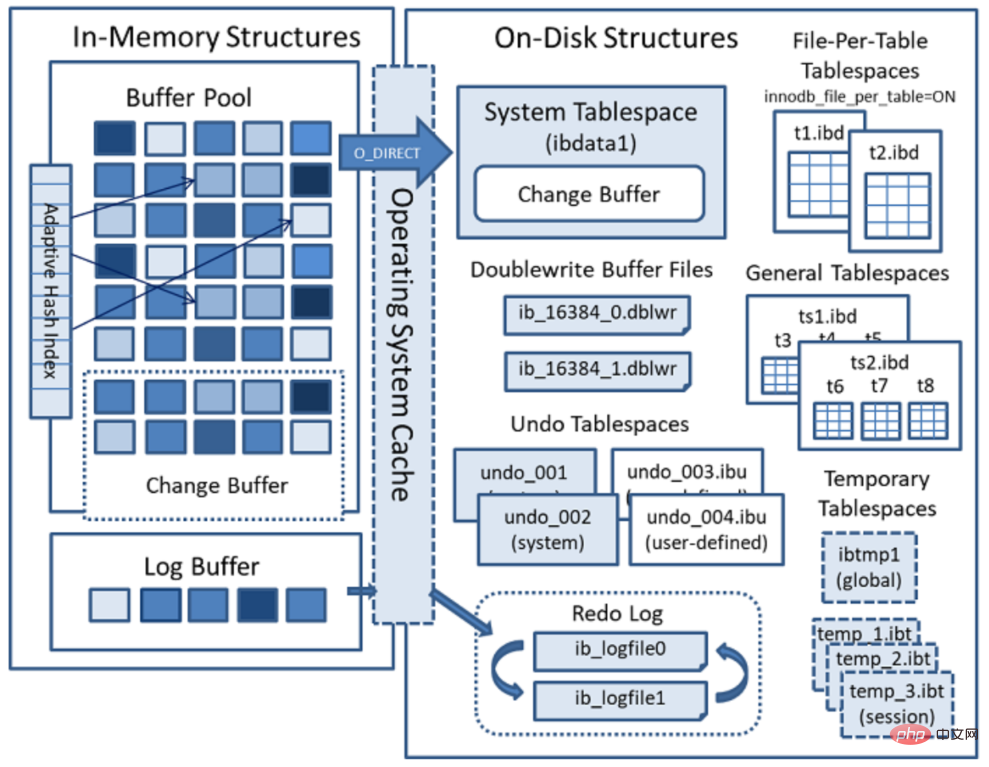
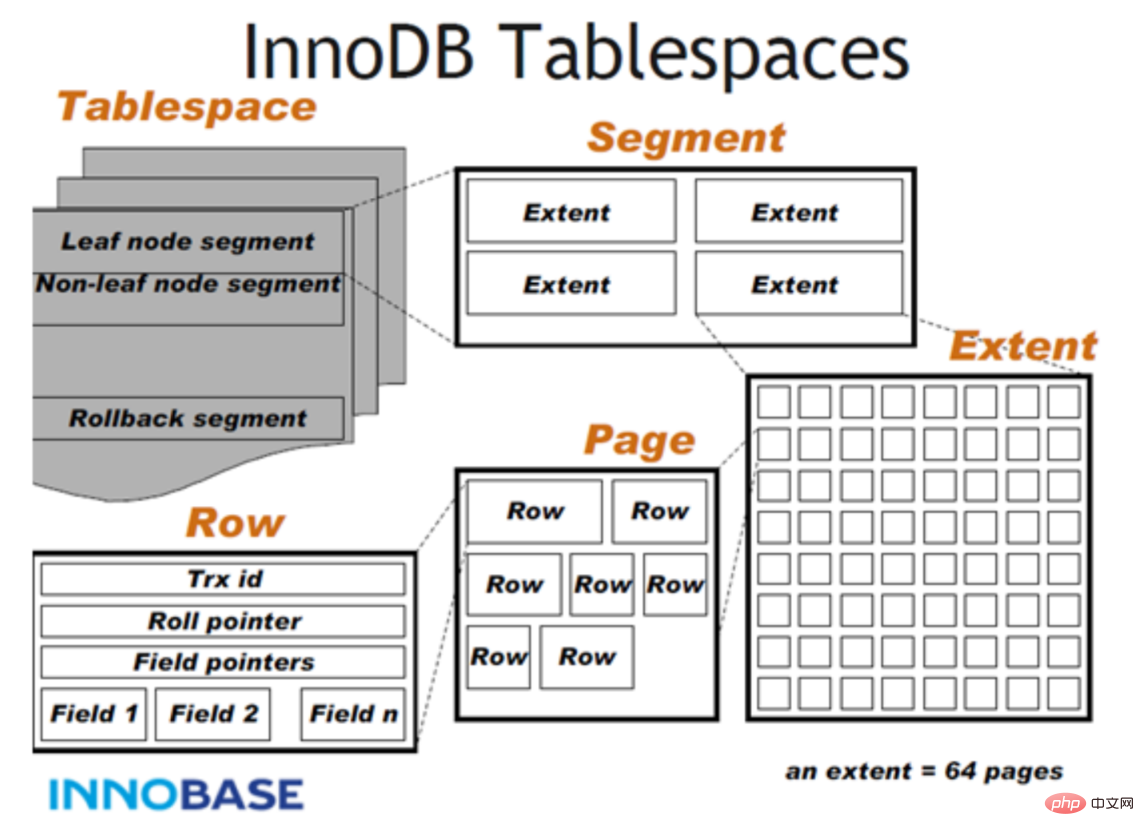
InnoDB データファイルのストレージ構造
Page是文件最基本的单位,无论何种类型的page,都是由page header,page trailer和page body组成。如下图所示
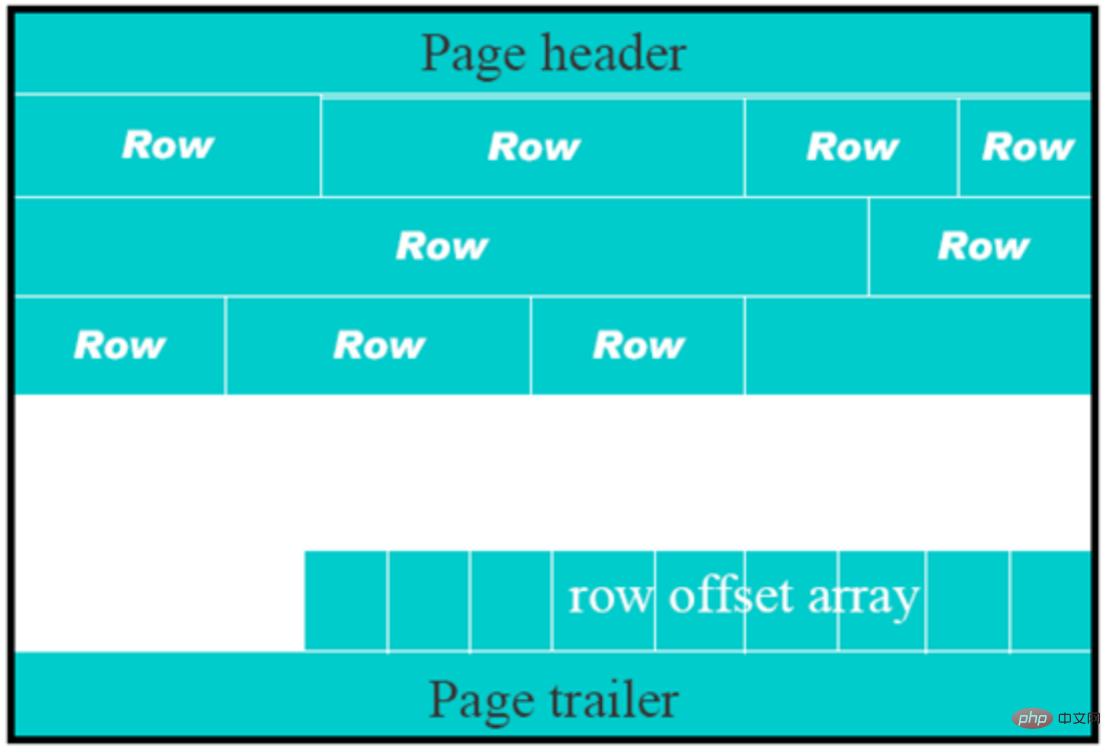
InnoDB文件存储格式
通过 SHOW TABLE STATUS 命令 查看
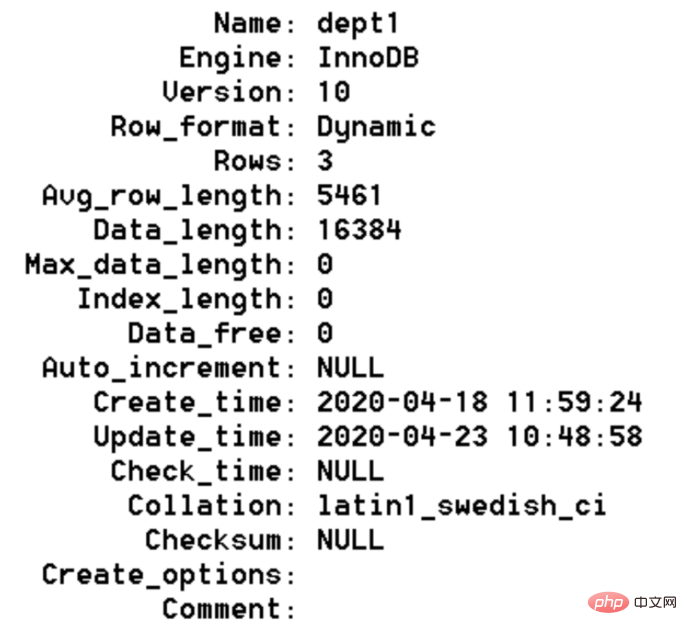
一般情况下,如果row_format为REDUNDANT、COMPACT,文件格式为Antelope;如果row_format为DYNAMIC和COMPRESSED,文件格式为Barracuda。
通过 information_schema 查看指定表的文件格式
select * from information_schema.innodb_sys_tables;
File文件格式(File-Format)
Row行格式(Row_format)
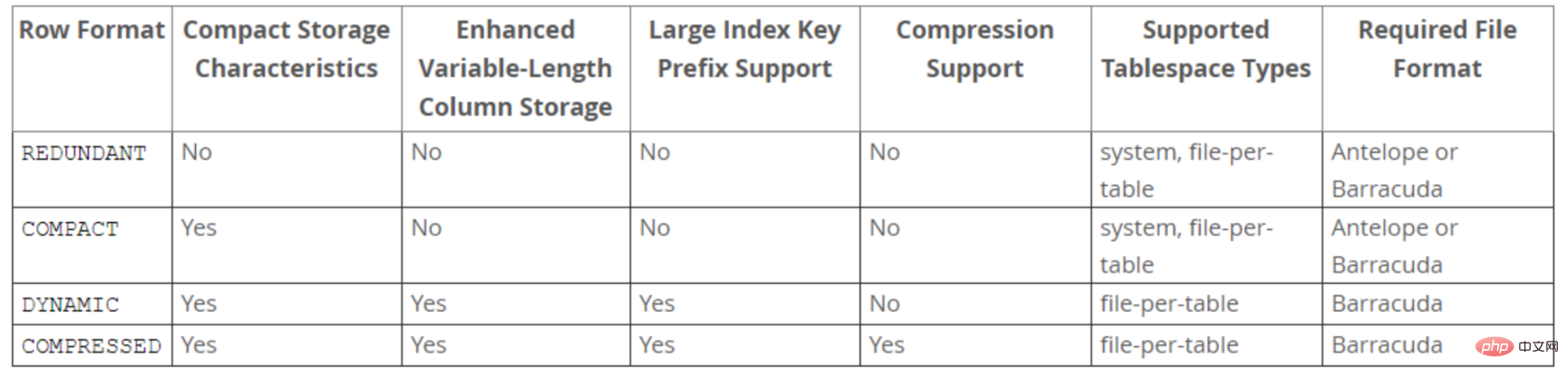
表的行格式决定了它的行是如何物理存储的,这反过来又会影响查询和DML操作的性能。如果在单个page页中容纳更多行,查询和索引查找可以更快地工作,缓冲池中所需的内存更少,写入更新时所需的I/O更少。
InnoDB存储引擎支持四种行格式:REDUNDANT、COMPACT、DYNAMIC和COMPRESSED。
DYNAMIC和COMPRESSED新格式引入的功能有:数据压缩、增强型长列数据的页外存储和大索引前缀。
每个表的数据分成若干页来存储,每个页中采用B树结构存储;
如果某些字段信息过长,无法存储在B树节点中,这时候会被单独分配空间,此时被称为溢出页,该字段被称为页外列。
在创建表和索引时,文件格式都被用于每个InnoDB表数据文件(其名称与*.ibd匹配)。修改文件格式的方法是重新创建表及其索引,最简单方法是对要修改的每个表使用以下命令:
ALTER TABLE 表名 ROW_FORMAT=格式类型;
Undo:意为撤销或取消,以撤销操作为目的,返回指定某个状态的操作。
Undo Log:数据库事务开始之前,会将要修改的记录存放到 Undo 日志里,当事务回滚时或者数据库崩溃时,可以利用 Undo 日志,撤销未提交事务对数据库产生的影响。
Undo Log产生和销毁:Undo Log在事务开始前产生;事务在提交时,并不会立刻删除undo log,innodb会将该事务对应的undo log放入到删除列表中,后面会通过后台线程purge thread进行回收处理。Undo Log属于逻辑日志,记录一个变化过程。例如执行一个delete,undolog会记录一个insert;执行一个update,undolog会记录一个相反的update。
Undo Log存储:undo log采用段的方式管理和记录。在innodb数据文件中包含一种rollback segment回滚段,内部包含1024个undo log segment。可以通过下面一组参数来控制Undo log存储。
#相关参数命令 show variables like '%innodb_undo%';
实现多版本并发控制(MVCC)
Undo Log 在 MySQL InnoDB 存储引擎中用来实现多版本并发控制。事务未提交之前,Undo Log保存了未提交之前的版本数据,Undo Log 中的数据可作为数据旧版本快照供其他并发事务进行快照读。
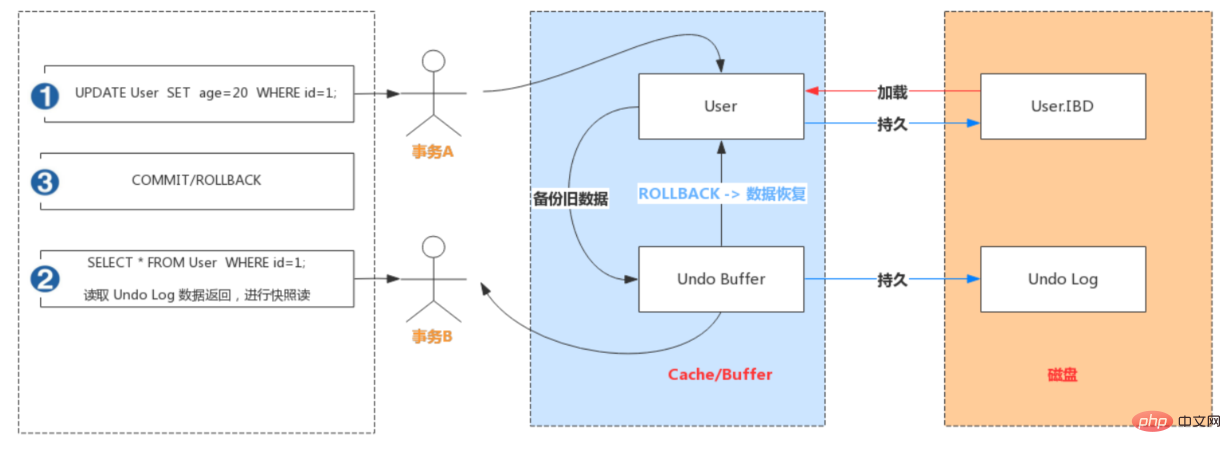
事务B手动开启事务,执行查询操作,会读取 Undo 日志数据返回,进行快照读;
Redo Log 和 Binlog
Redo Log 介绍
Redo Log工作原理
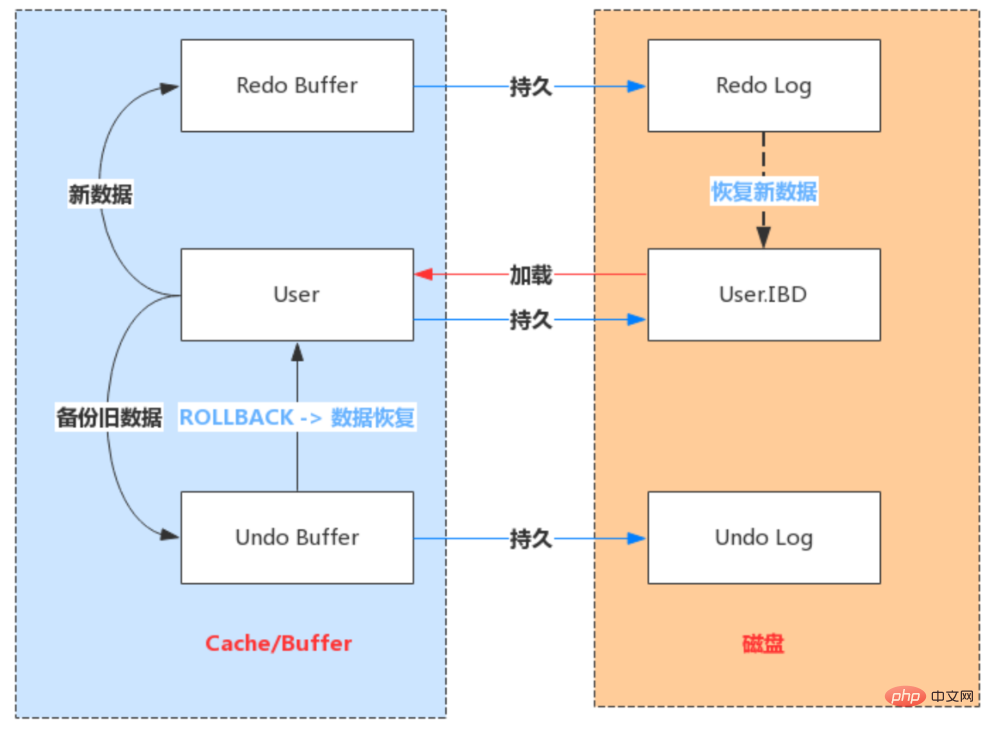
Redo Log写入机制
Redo Log 文件内容是以顺序循环的方式写入文件,写满时则回溯到第一个文件,进行覆盖写。
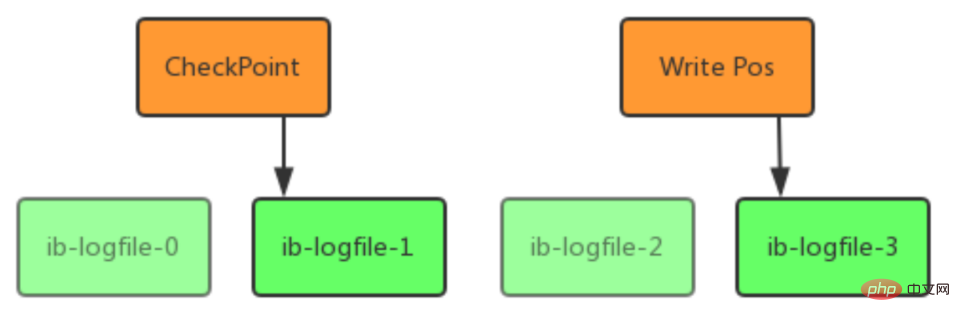
Redo Log相关配置参数
每个InnoDB存储引擎至少有1个重做日志文件组(group),每个文件组至少有2个重做日志文件,默认为ib_logfile0和ib_logfile1。可以通过下面一组参数控制Redo Log存储:
show variables like '%innodb_log%';
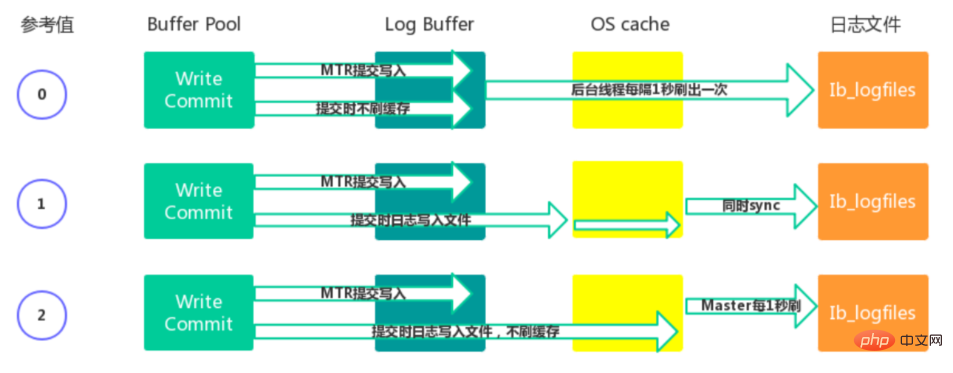
Redo Buffer 持久化到 Redo Log 的策略,可通过 Innodb_flush_log_at_trx_commit 设置:
Binlog 记录模式
Binlog 文件结构
Binlog文件中Log event结构如下图所示:

Binlog写入机制
Binlog文件操作
Binlog文件操作
Binlog状态查看
show variables like 'log_bin';
开启Binlog功能
set global log_bin = mysqllogbin; ERROR 1238 (HY000): Variable 'log_bin' is a read only variable
需要修改my.cnf或my.ini配置文件,在[mysqld]下面增加log_bin=mysql_bin_log,重启MySQL服务。
#log-bin=ON #log-bin-basename=mysqlbinlog binlog-format=ROW log-bin=mysqlbinlog
使用show binlog events命令
show binary logs; //等价于show master logs; show master status; show binlog events; show binlog events in 'mysqlbinlog.000001';
使用 mysqlbinlog 命令
mysqlbinlog "文件名" mysqlbinlog "文件名" > "test.sql"
使用 binlog 恢复数据
//按指定时间恢复 mysqlbinlog --start-datetime="2020-04-25 18:00:00" --stop- datetime="2020-04-26 00:00:00" mysqlbinlog.000002 | mysql -uroot -p1234 //按事件位置号恢复 mysqlbinlog --start-position=154 --stop-position=957 mysqlbinlog.000002 | mysql -uroot -p1234
mysqldump:定期全部备份数据库数据。mysqlbinlog可以做增量备份和恢复操作。
删除Binlog文件
purge binary logs to 'mysqlbinlog.000001'; //删除指定文件 purge binary logs before '2020-04-28 00:00:00'; //删除指定时间之前的文件 reset master; //清除所有文件
可以通过设置expire_logs_days参数来启动自动清理功能。默认值为0表示没启用。设置为1表示超出1天binlog文件会自动删除掉。
Redo Log和 Binlog区别
推荐学习:mysql视频教程
以上がmysql アーキテクチャ原則の詳細な図による説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



