

MySQL 学習のための DDL、DML、DQL の基本の概要

この記事では、mysql に関する関連知識を提供します。主に、操作データ テーブル、操作データベース、単純なクエリ データなど、DDL、DML、および DQL に関する関連コンテンツを紹介します。以下の内容が皆様のお役に立てれば幸いです。

データを保存する倉庫。それは私たちのコンピュータにソフトウェアまたはファイルシステムとして組み込まれています。次に、これらの特殊ファイルにデータを保存し、ファイル内のデータを操作するには固定言語 (データベースは、特定の形式に従ってデータをファイルに保存し、SQL 言語/ステートメント) を使用する必要があります。
データを保管する倉庫。データは整理された方法で保管されます。
#データベースの利点- 英語名:
- DataBase
、DB## と呼ばれます
大量のデータを簡単に増やすことができます。 SQL ステートメント一般的なリレーショナル データベース管理システム、
一般的なデータベースDelete、Change、Check操作を行う場合、データベースは大量の情報を管理するための効率的なソリューションです。
アプリケーションを開発するとき、最終的にはすべてのデータを保存する必要があります。プロフェッショナルなソフトウェアへ。このようなデータを保存するための専門的なソフトウェアをデータベースと呼びます。私たちがデータベースを学ぶとき、データベース ソフトウェアの開発方法を学ぶのではなく、データベースの使い方とデータベース内のデータ レコードの操作を学びます。データベース ソフトウェアはサードパーティ企業によって開発されています。
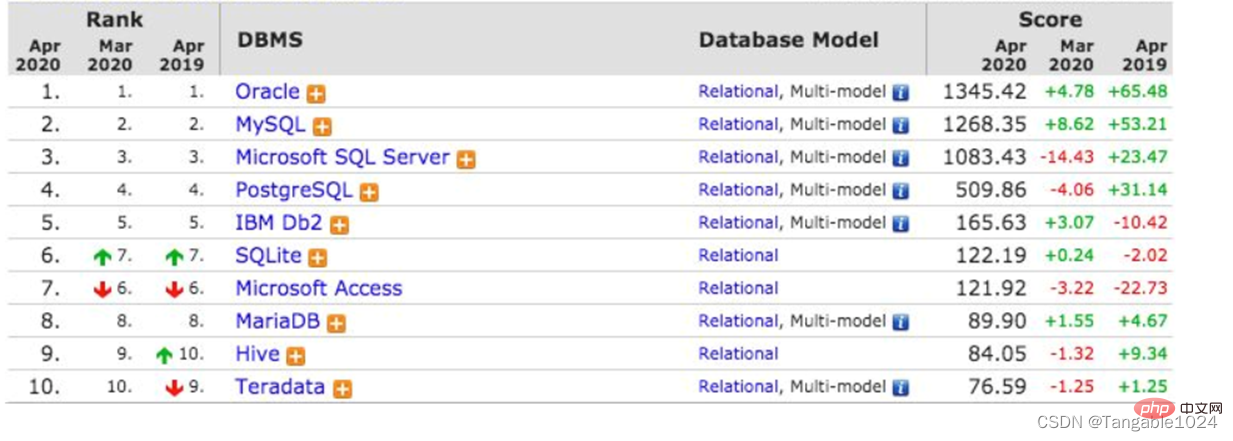
- : Oracle Corporation の大規模なリレーショナル データベースです。可搬性に優れ、使いやすく、機能も充実しており、大・中・小・マイコンの様々な環境に適しています。それは効率的で、安全で信頼性があります。ただし、手数料がかかります。
- MYSQL : 初期には MySQL AB というスウェーデンの会社によって開発されましたが、その後 Sun Company に買収され、その後 Oracle に買収されました。 MySQL は、サイズが小さく、速度が速く、総所有コストが低いこと、特にオープン ソースの特徴により、一般に中小規模の Web サイト開発用の Web サイト データベースとして選択されます。 MySQL6.x版も課金開始となります。
- DB2 : IBM のデータベース製品 (有料)。銀行システムでよく使用されます。
- SQLServer : Microsoft が提供する中規模のデータベース。 C#、.net、その他の言語がよく使用されます。
- SyBase : Sybase から。歴史の舞台から消え去った。非常に専門的なデータ モデリング ツール PowerDesigner を提供します。
- 一般的に使用されるデータベース: Java 開発アプリケーションで主に使用されるデータベース: MySQL (5.6)、Oracle、DB2。 (理由: オープンソース、無料、そして Web 開発に対応するのに十分な強力さ)
リレーショナル データベース
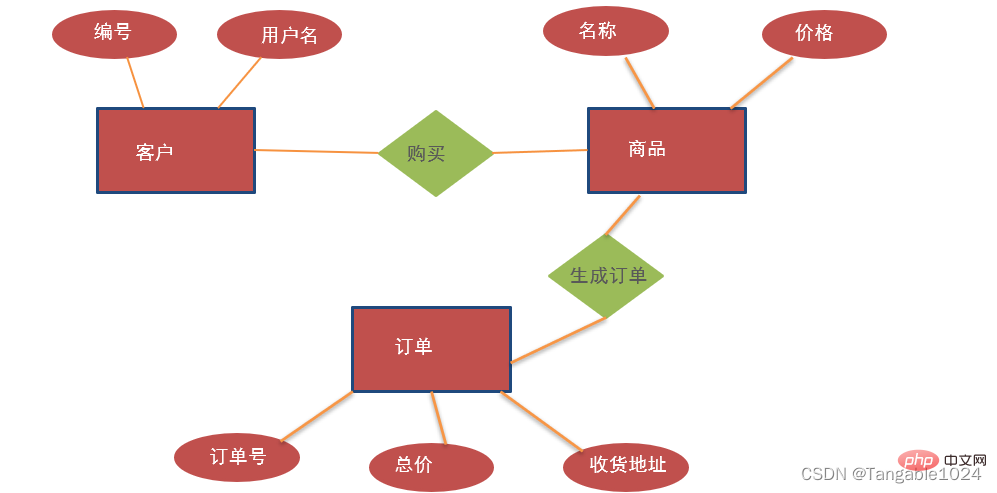
ソフトウェアを開発する場合、ソフトウェア関係のデータ間に特定の違いがなければなりません。存在します。たとえば、製品と顧客の関係では、1 人の顧客が複数の製品を購入することも、1 つの製品を複数の顧客が購入することもできます。 これらのデータをデータベースに保存し、データ間の関係を維持する必要がありますが、この場合は上記のデータベースをそのまま利用できます。上記のデータベースはすべてリレーショナル データベースです。リレーショナル データ: データベースを設計するときは、E-R エンティティ関係図を使用して記述する必要があります。
E-R は 2 つの単語の最初の文字で、E は
Entityエンティティを表し、R はRelationship
関係を表します。1. データ テーブル内のデータ間には、製品と顧客の関係など、特定の関係が必要です。顧客は複数の製品を購入することができ、1 つの製品を複数の顧客が購入することもできます。2. データベースを設計するとき、ER エンティティ関係図を使用してテーブル間の関係を説明できます。E はエンティティを表し、R は関係を表します。
- 3. エンティティ: は次のように理解できます。 us Java プログラム内のオブジェクト。たとえば、製品、顧客などはすべてエンティティ オブジェクトです。 E-R図では長方形(長方形)で表されます。
- 4. 属性: エンティティ オブジェクトには、製品名、価格などの属性が含まれます。エンティティ内の属性については、このエンティティのデータと呼ばれます。これは、E-R 図では楕円で表されます。
- 5. 関係: エンティティとエンティティ間の関係: E-R 図ではひし形で表されます。
- #要件: E-R 図を使用して顧客、製品、注文間の関係を説明します
MySQL データベース
 SQL の概要
SQL の概要
構造化クエリ言語構造化クエリ言語。 SQL ステートメントはプラットフォームに依存せず、すべてのデータベースに共通です。 SQL ステートメントの使用方法を学習すると、どのデータベースでも SQL ステートメントを使用できますが、その内容はすべて固有です。 SQL ステートメントは強力で、習得が簡単で、使いやすいです。
SQL の機能
SQL ステートメントは非手続き型言語であり、各 SQL ステートメントが実行された後に特定の結果が表示されます。複数のステートメント間には影響はありません
SQL 関数
SQL ステートメントは主にデータベース、データ テーブル、データ テーブルの操作に使用されます。データ レコード
SQL の一般的な構文
- SQL ステートメントは、単一行または複数行で記述でき、次で終わります。セミコロン。
- スペースとインデントを使用すると、ステートメントを読みやすくすることができます。
- MySQL データベースの SQL ステートメントでは大文字と小文字が区別されず、キーワード開発は通常大文字で行われます。
- 3 種類のコメント
- 単一行コメント:--コメントの内容
- 複数行のコメント:/* コメントの内容*/
-# コメントの内容: (mysql 固有の 1 行コメント)
SQL 分類
SQL はリレーショナル データベースにアクセスするために使用される言語で、リレーショナル データベースの定義、操作、制御、クエリの 4 つの機能があります。したがって、SQL を 4 つの関数に基づいて分類します。
DDL (データ定義言語) データ定義言語
は、データベース、テーブル、列などのデータベース オブジェクトを定義するために使用されます。キーワード: create、drop、alter、truncate (データレコードのクリア)、show など。DML (Data Manipulation Language) データ操作言語 ★★★
データベーステーブルで更新されます。 , レコードの追加と削除。更新(update)、挿入(insert)、削除(delete)などのクエリにはクエリは含まれません
DQL (Data Query Language) データクエリ言語
データテーブルレコードクエリ。キーワード選択。DCL (データ コントロール言語
) データ コントロール言語 (理解) は、データベース ユーザーまたはロールの権限を設定または変更するために使用されるステートメントです。付与 (アクセス許可の設定)、取り消し (アクセス許可の取り消し)、トランザクションの開始など。これは比較的まれに使用されます。

 ##MySQL データベース接続
##MySQL データベース接続
#MySQL は、ログインにアカウント名とパスワードが必要なデータベースです。ログイン後に使用できます。デフォルトの root アカウントが提供されます。インストール時に設定したパスワードを使用してログインできます。
データベース サービスを開始します
: 開いている dos ウィンドウにnet start MySQL コマンドを入力します
閉じるデータベース サービス 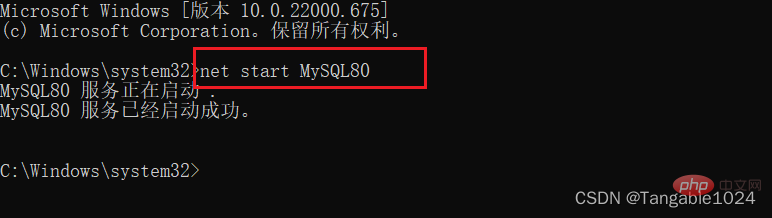 : 開いている dos ウィンドウに
: 開いている dos ウィンドウに
net stop MySQL コマンドを入力します。
MySQL に接続します。  : ログイン形式 1:
: ログイン形式 1:
mysql -u ユーザー名 -p パスワード
mysql -uroot -p123456
mysql[-h 接続ホストの IP アドレス -P ポート番号 3306] -u ユーザー名 -p パスワード
mysql -h 127.0.0.1 -P 3306 -u root -p 123456
ローカル マシンに接続している場合: -h -P ホスト IP とポートを省略できます。このようにして、mysql データベースにログインできます。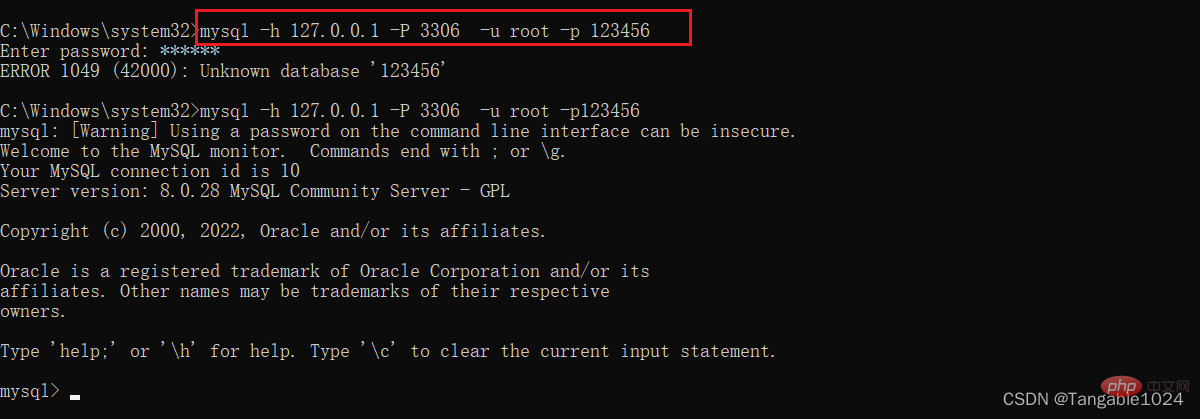
Exit
exitCommand
Displayデータベース :
:
データベースの表示;##SQL_DDL_データベースの操作 DDL_データベースの作成と表示
DDL_データベースの作成と表示
1. データベースを直接作成します create database 数据库名;
create database if not exists 数据库名;
3.データベースを作成し、文字セット (エンコーディング テーブル) を指定します
create database 数据库名 character set 字符集;
#データベースの表示:
1. すべてのデータベースの表示show databases;
show create database 数据库名;
3. 現在使用されているデータベースの表示
select database();
use 数据库名;
DDL_データベースの変更と削除
データベースの変更:1データベース文字セットの変更-- alter 表示修改alter database 数据库名 default character set 新字符集;
Java中的常用编码对应mysql数据库中的编码
| Java | MySQL |
|---|---|
| UTF-8 | utf8 |
| GBK | gbk |
| GB2312 | gb2312 |
| ISO-8859-1 | latin1 |
删除数据库:
1.直接删除
-- drop 删除数据库drop database 数据库名;
2.删除数据库时判断是否存在(如果存在,则删除)
drop database if exists 数据库名;
SQL_DDL_操作数据表
DDL_数据库约束
约束的概念:
约束是作用于表中列上的规则,用于限制加入表的数据
约束的存在保证了数据库中数据的正确性、有效性和完整性
约束的分类:
| 约束名称 | 关键字 | 描述 |
|---|---|---|
| 非空约束 | NOT NULL |
保证列中所有数据不能有null空值 |
| 唯一约束 | UNIQUE |
保证列中所有数据各不相同 |
| 主键约束 | PRIMARY KEY |
主键是一行数据的唯一标识,要求非空且唯一 |
| 检查约束 | CHECK |
保证列中的值满足某一条件 |
| 默认约束 | DEFAULT |
保存数据时,未指定值则采用默认值 |
| 外键约束 | FOREIGN KEY |
外键用来让两个表的数据之间建立链接,保证数据的一致性和完整性 |
MySQL5.7不支持检查约束,但写入语句不会报错,MySQL8.0版本支持检查约束
非空约束
非空约束用于保证列中所有数据不能有NULL值
1.建表时添加约束
-- 创建表时添加非空约束create table 表名( 列名 数据类型 not null, ...);
2.建完表之后添加约束
-- 建完表之后添加约束alter table 表名 modify 字段名 数据类型 not null;
3.删除约束
alter table 表名 modify 字段名 数据类型;
唯一约束
唯一约束用于保证列中所有数据各不相同
1.创建表时添加唯一约束
-- 方式1create table 表名( 字段名 数据类型 UNIQUE, ...);-- 方式2create table 表名( 字段名 数据类型, ... [CONSTRAINT] [约束名称] UNIQUE(列名));
2.建完表之后添加唯一约束
-- 建完表后添加唯一约束alter table 表名 modify 字段名 数据类型 UNIQUE;
3.删除唯一约束
alter table 表名 drop index 字段名;
主键约束
- 主键是一行数据的唯一标识,要求非空且唯一
- 一张表只能有一个主键
1.创建表时添加主键约束
create table 表名( 字段名 数据类型 PRIMARY KEY [AUTO_INCREMENT], -- [AUTO_INCREMENT] 当不指定值时自动增长 ...);create table 表名( 列名 数据类型, [CONSTRAINT] [约束名称] PRIMARY KEY(列名))
2.建完表之后添加主键约束
alter table 表名 add PRIMARY KEY(字段名);
3.删除主键约束
alter table 表名 drop PRIMARY KEY;
默认约束
保存数据时,未指定值则采用默认值
1.创建表时添加默认约束
create table 表名( 字段名 数据类型 default 默认值, ...);
2.建完表后添加默认约束
alter table 表名 alter 列名 set DEFAULT 默认值;
3.删除约束
alter table 表名 alter 列名 drop DEFAULT;
DDL_创建和查看和表
前提 :创建数据库db1并使用这个数据库
-- 创建数据库create database db1;-- 使用数据库use db1;
创建表:
create table 表名( 字段名1 字段类型 约束条件, 字段名2 字段类型 约束条件, ... 字段名n 字段类型 约束条件);-- 注意:最后一个字段不加逗号
创建一个表结构和其他表结构相同的表
create table 表名 like 其他表名;
MySQL中常用的数据类型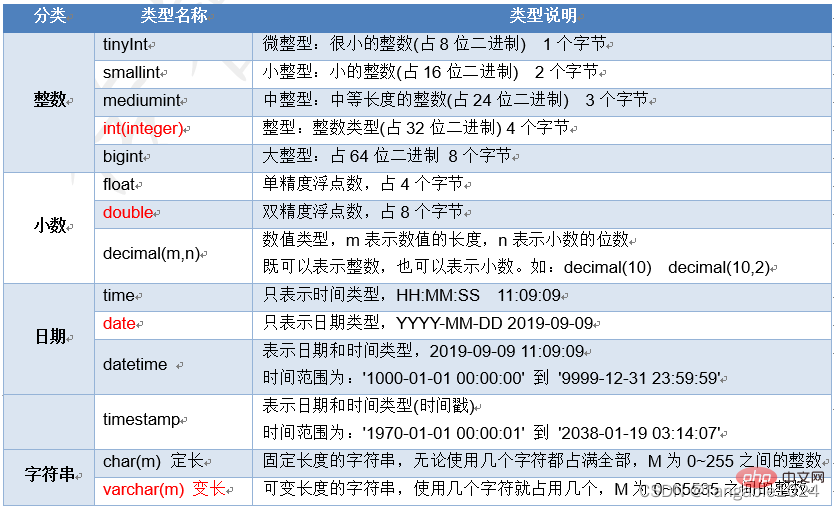
案列需求:
设计一张学生表,要求如下:
- 学号,要求唯一主键,自增
- 姓名,不能为空,且唯一
- 性别,只有男和女,默认值为null
- 班级,字符串类型
- 入学时间,取值为年、月、日
- 数学成绩,double类型,默认为60分
- 英语成绩,double类型,没有默认值
create table students(
id int primary key auto_increment,
name varchar(10) not null unique,
sex enum('男','女') default null,
class varchar(10),
starttime date,
math int default 60,
english int);
查看表:
1.查看某个数据库中所有的表
show tables;
2.查看表结构
desc 表名;
3.查看创建表的SQL语句
show create table 表名;-- 根据该语句查看上面案列的建表sql语句show create table students;

DDL_删除表和修改表的结构
删除表:
1.直接删除
drop table 表名;
2.删除表时判断表是否存在(如果存在,则删除)
drop table if exists 表名;
修改表:
1.修改表名
alter table 旧表名 rename to 新表名;
2.向表中添加一个字段(一列)
alter table 表名 add 字段名 数据类型;
3.修改表中字段数据类型
alter table 表名 modify 字段名 新的数据类型;
4.修改表中字段名(列名)和数据类型
alter table 表名 change 字段名 新的字段名 新的数据类型;
5.删除表中字段(列)
alter table 表名 drop 字段名;
SQL_DML_操作数据库
DML_插入表数据
1.插入全部字段
-- 全部字段写出来insert into 表名(字段1,字段2,...) values(值1,值2,...); -- 插入全部不写字段名insert into 表名 values(值1,值2,...); -- 给案例中的表插入数据insert into students(id,name,sex,class,starttime,math,english) values(1,'张三','男','高三1班','2022-03-02',80,69); insert into students values(2,'李四','女','高三2班','2022-03-01',70,80);

2.插入部分数据
-- 插入姓名,班级,入学时间,英语成绩-- id默认增长,性别默认null,数学默认60
insert into students(name,class,starttime,english) values('王五','高三3班','2022-03-02',78);
说明:插入部分数据的时候,要求列名一定书写出来。
3.批量插入数据
insert into 表名 values(字段值1, 字段值2...),(字段值1, 字段值2...),(字段值1, 字段值2...);
没有添加数据的字段会使用NULL
注意:
值与列一一对应。有多少个列,就需要写多少个值。如果某一个列没有值,可以使用null,表示插入空。
值的数据类型,与列被定义的数据类型要相匹配,并且值的长度,不能够超过定义的列的长度。
字符串:插入字符类型的数据,建议写英文单引号括起来。在mysql中,使用单引号表示字符串
date 时间类型的数据也得使用英文单引号括起来: 如
yyyy-MM-dd
DML_更新表数据
1.不带条件修改数据
update 表名 set 字段名=新的值,字段名=新的值,...; -- 注意:不带条件的修改是将数据表中的整列都做修改 -- 修改students表中math的值为90update students set math=90;

2.带条件修改数据
update 表名 set 字段名=新的值,字段名=新的值,... where 条件; -- 修改students表中王五的性别为男,数学成绩设置为70update students set sex='男',math=70 where name='王五';

3.关键字说明
UPDATE: 表示修改记录 SET: 要改哪个字段WHERE: 设置条件
4.注意
- 不带条件的更新数据库记录:UPDATE 表名 SET 字段名=新的值;是将整个表中修改的列修改
- 带条件:UPDATE 表名 SET 字段名=新的值 WHERE 条件
DML_删除表记录
1.不带条件删除
DELETE -- 删除记录DELETE FROM 表名;表还在,可以操作,只是删除数据。
2.带条件删除
DELETE FROM 表名 WHERE 条件;-- 删除学生表中的王五的信息DELETE FROM students WHERE name='王五';

3.truncate删除表记录(属于DDL)
truncate table 表名;
4.truncate和delete区别
- delete是将表中的数据一条一条删除
- truncate是将整个表摧毁,重新创建一个新的表,新的表结构和原来表结构一模一样
SQL_DQL_ 简单查询数据
准备一张学生表,在这张表上进行查询操作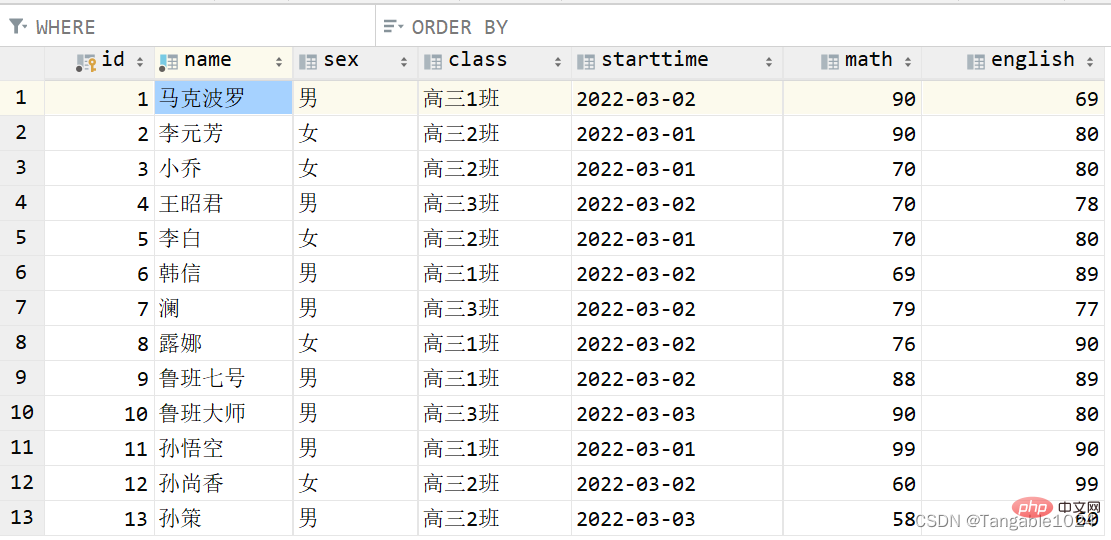
DQL_基础查询
1.查询所有数据
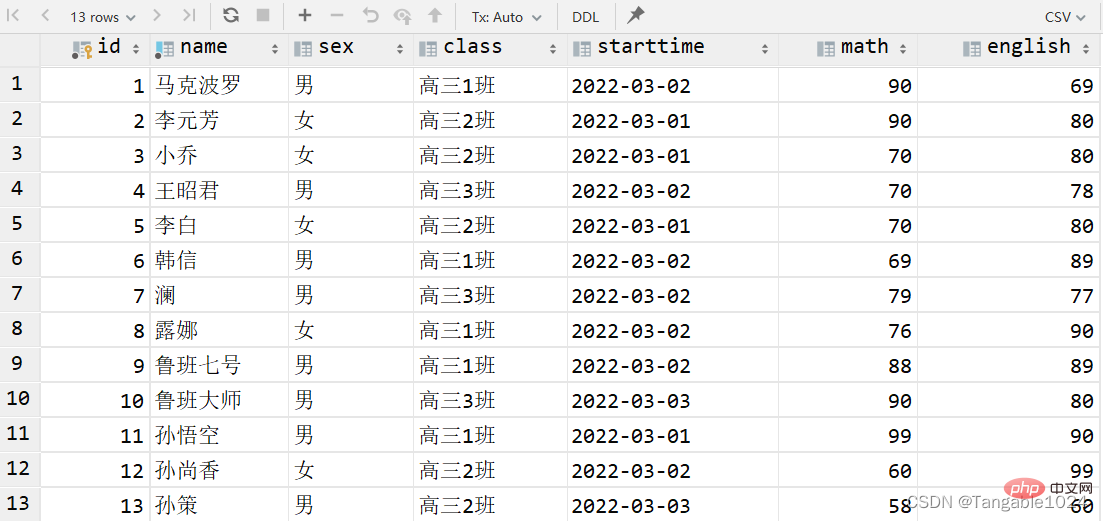
select * from 表名; -- 查询学生表中所有的数据select * from students;
2.查询指定列的数据
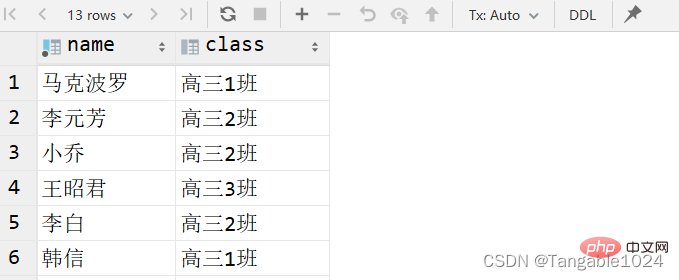
select 字段名1,字段名2,... from 表名; -- 查询姓名和班级这两个字段select name,class from students;
3.查询到的字段设置别名
select 字段名1 as 别名1,字段名2 as 别名2 from 表名; -- 查询students表中的字段并设置别名select id as 学号,name as 姓名,sex as 性别,class as 班级 , starttime as 入学时间 from students;
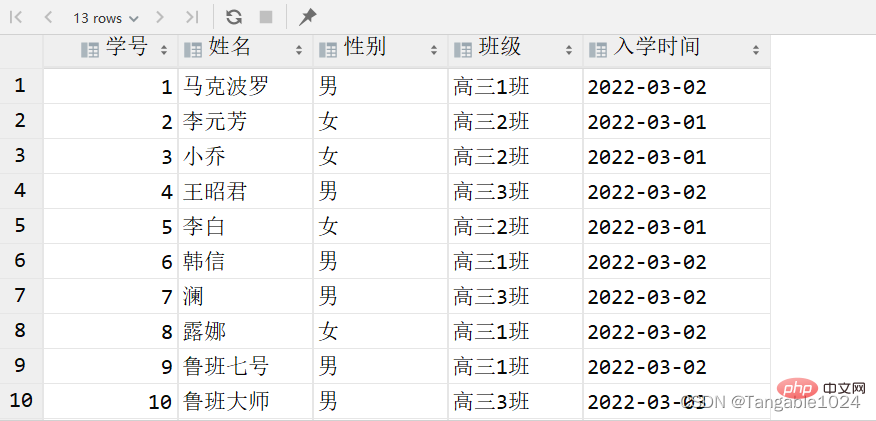
4.查询到的数据去重
-- DISTINCT 去重复-- 查询班级字段结果不出现重复的select DISTINCT class from students;
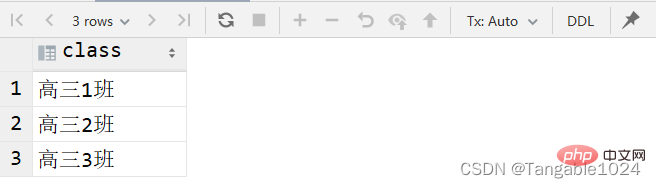
DQL_条件查询
1.条件查询语法
select 字段名1,字段名2,... where 条件列表;
2.条件运算符
| 符号 | 功能 |
|---|---|
| > | 大于 |
| 小于 | |
| >= | 大于等于 |
| 小于等于 | |
| = | 等于 |
| 或!= | 不等于 |
| BETWEEN…AND… | 在某个范围内(都包括) |
| IN(…) | 多选一 |
| LIKE | 模糊查询,_单个任意字符,%多个任意字符 |
| IS NULL | 为空 |
| IS NOT NULL | 不为空 |
| AND 或 && | 与,并且 |
| OR 或 || | 或,或者 |
| NOT 或 ! | 非,不是 |
3.查询数学成绩大于80并且性别为男的学生
-- 两个条件同时满足select * from students where math > 80 and sex='男';
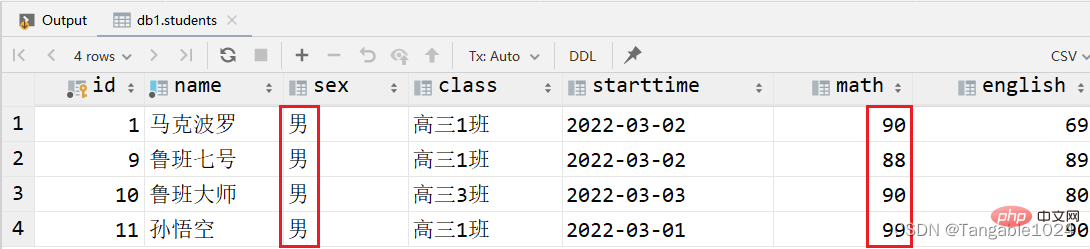
4.查询英语成绩在60-80之间的学生
-- BETWEEN 值1 AND 值2 -- 表示从值1到值2范围,包头又包尾 select * from students where english between 60 and 80; select * from students where english>=60 && english<p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/01283e47128a89592860b85cda10b160-24.png" class="lazy" alt="MySQL 学習のための DDL、DML、DQL の基本の概要"><br><strong>5.查询学号为1或者2或者3的学生</strong></p><pre class="brush:php;toolbar:false">-- in里面的每个数据都会作为一次条件,只要满足条件的就会显示select * from students where id in (1,2,3);

DQL_模糊查询
LIKE:表示模糊查询
select * from 表名 where 字段名 like '通配字符';
MySQL通配符有两个:
-
%:表示0个或多个字符(任意字符) -
_:表示一个字符
1.查找名字中以孙开头的学生
-- '孙%'表示孙后面有任意个字符select * from students where name like '孙%';

2.查找名字中以孙开头的两个字的学习
-- '孙_'表示孙后面只能有一个字符select * from students where name like '孙_';

DQL_查询排序
通过ORDER BY子句,可以将查询出的结果进行排序(排序只是显示方式,不会影响数据库中数据的顺序)
-- ASC:升序排序(默认)-- DESC:降序排序select 字段 from 表名 order by 排序字段 [ASC|DESC];
1.单列排序
-- 查询学生的数学成绩按照升序排序select * from students order by math ASC;
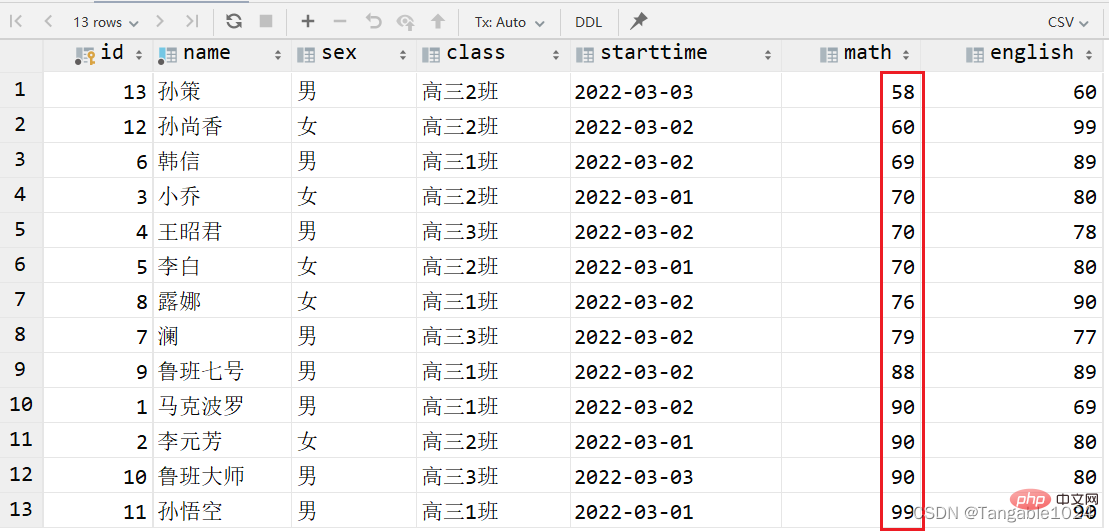
2.组合排序
-- 查询数学成绩升序的基础上,英语成绩降序-- 组合排序就是先按第一个字段进行排序,如果第一个字段相同,才按第二个字段进行排序,依次类推。 select * from students order by math ASC,english DESC;
DQL_ 聚合函数
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值;另外聚合函数会忽略空值,对于null不作为统计。
1.五个聚合函数
| 函数名 | 功能 |
|---|---|
| count(列名) | 统计数量(一般选用不为null的列) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
2.聚合函数语法
select 聚合函数名(列名) from 表名;
注意:null 值不参与所有聚合函数运算
3.查询学生总数
select count(id) from students;-- 通常使用select count(*) from students;

4.查询最高分和最低分
-- 查询数学最高分和英语最低分select max(math),min(english) from students;

5.求和求平均值
-- 求该表数学总分和平均值select sum(math),avg(math) from students;

6.ifnull()函数
-- ifnull(列名,默认值)函数表示判断该列是否为空值,如果为null,返回默认值,如果不为空,返回实际值ifnull(math,60); -- 如果数学成绩为null时,返回60,如果不为null,就返回实际值
DQL_分组查询
分组: 按照某一列或者某几列。把相同的数据,进行合并输出。
1.注意
- 按照某一列进行分组,目的为了统计使用。
- 聚合函数:分组之后进行计算
- 通常
select后面的内容是被分组的列,以及聚合函数 - 在
sql语句中的where后面不允许添加聚合函数 - 可以使用
having条件,表示分组之后的条件,在having后面可以书写聚合函数
2.查询各个班级的数学成绩总和
-- 查询每个班的数学成绩总和select class,sum(math) from students group by class;

3.having用法
having必须和group by 一起使用,having和where的用法一模一样,where怎么使用having就怎么使用,where不能使用的,having也可以使用,比如说where后面不可以使用聚合函数,但是在having后面是可以使用聚合函数的。
-- 查询每个班数学总成绩大于300分的班级并显示总成绩 select class,sum(math) from students group by class having sum(math)>300;

4.where和having的区别
having 通常与group by 分组结合使用。 where 和分组无关。
having 可以书写聚合函数 (聚合函数出现的位置: having 之后),例如having中的 聚合函数(count,sum,avg,max,min),是不可以出现where条件中。
where 是在分组之前进行过滤的,having 是在分组之后进行过滤的。
DQL_分页查询
1.应用和概念
比如我们登录京东,淘宝,返回的商品信息可能有几万条,不是一次全部显示出来。是一页显示固定的条数。假设我们一每页显示5条记录的方式来分页。
-- 起始索引:从0开始,索引是0表示数据表第一行数据select 字段列表 from 表名 limit 起始索引,查询条目数;
计算公式:起始索引=(当前页码-1)* 每页显示的条数
注意:
- 分页查询
limit是MySQL数据库的方言- Oracle分页查询使用
rownumber- SQLServer分页查询使用
top
2.分页查询
<span style="font-family: " microsoft yahei sans gb helvetica neue tahoma arial sans-serif>-- 查询学生表中数据,每四条数据为一页<br>select * from students limit 0,4;<br>select * from students limit 4,4;<br>select * from students limit 8,4;<br>select * from students limit 12,4;<br>...<br>-- 注意:最后一行不够查询条目数,有多少就显示多少</span><br>
3.返回前几条或者中间某几行数据
-- 2表示分页查询的索引,对应数据表是第3行数据,4表示每页显示4条数据 -- 查询从第三行数据开始查询之后的四条数据 select * from students limit 2,4;

4.SQL执行顺序
SELECT 字段名(5) FROM 表名(1) WHERE 条件(2) GROUP BY 分组列名(3) HAVING 条件(4) ORDER BY 排序列名(6) LIMIT 跳过行数, 返回行数(7); 执行顺序:1234567
顺序:1234567
推荐学习:mysql视频教程
以上がMySQL 学習のための DDL、DML、DQL の基本の概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7508
7508
 15
1378
52
78
11
19
58
15
1378
52
78
11
19
58

 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 SQLが行を削除した後にデータを回復する方法
Apr 09, 2025 pm 12:21 PM
SQLが行を削除した後にデータを回復する方法
Apr 09, 2025 pm 12:21 PM
データベースから直接削除された行を直接回復することは、バックアップまたはトランザクションロールバックメカニズムがない限り、通常不可能です。キーポイント:トランザクションロールバック:トランザクションがデータの回復にコミットする前にロールバックを実行します。バックアップ:データベースの定期的なバックアップを使用して、データをすばやく復元できます。データベーススナップショット:データベースの読み取り専用コピーを作成し、データが誤って削除された後にデータを復元できます。削除ステートメントを使用して注意してください:誤って削除されないように条件を慎重に確認してください。 WHERE句を使用します:削除するデータを明示的に指定します。テスト環境を使用:削除操作を実行する前にテストします。
 NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する手順:データベースに接続します。 SQLエディターウィンドウを作成します。 SQLクエリまたはスクリプトを書きます。 [実行]ボタンをクリックして、クエリまたはスクリプトを実行します。結果を表示します(クエリが実行された場合)。
