

この記事では、javascript に関する関連知識を紹介します。主に文字列に関する関連知識を紹介します。主に、よく使用される基本的なメソッドと、特殊文字や絵文字の内部表現方法を紹介します。以下の内容が皆様のお役に立てば幸いです。

[関連する推奨事項: JavaScript ビデオ チュートリアル 、Web フロントエンド ]
どんなプログラミングでも言語 では、文字列は重要なデータ型です。詳細を学ぶためにフォローしてくださいJavaScript 文字列の知識!
文字列は文字で構成される文字列です。C、Java を学習したことがある場合は、文字自体もさまざまな文字列で構成されることを知っているはずです。独立してタイプになります。ただし、JavaScript には単一の文字タイプはなく、長さ 1 の文字列のみがあります。
JavaScript の文字列は、固定の UTF-16 エンコーディングを使用しています。プログラムを作成するときにどのようなエンコーディングを使用しても、影響を受けません。
文字列を記述するには、一重引用符、二重引用符、バックティックの 3 つの方法があります。
let single = 'abcdefg';//单引号let double = "asdfghj";//双引号let backti = `zxcvbnm`;//反引号
一重引用符と二重引用符は同じステータスを持ち、区別しません。
文字列の書式設定
バッククォートを使用すると、文字列の加算演算を使用する代わりに、${...}文字列をエレガントに書式設定できます。
let str = `I'm ${Math.round(18.5)} years old.`;console.log(str);コードの実行結果:

複数行の文字列
バックティックを使用すると、文字列を複数行にまたがることもできます。 、複数行の文字列を記述するときに非常に便利です。
let ques = `Is the author handsome? A. Very handsome; B. So handsome; C. Super handsome;`;console.log(ques);
コード実行結果:
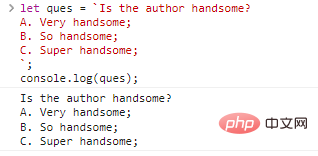
何も無いように見えませんか?ただし、これは一重引用符と二重引用符を使用して実現することはできません。同じ結果を得たい場合は、次のように記述できます:
let ques = 'Is the author handsome?\nA. Very handsome;\nB. So handsome;\nC. Super handsome;';console.log(ques);
上記のコードには、特殊文字 \n が含まれています。プログラミングプロセスで使用される最も一般的な特殊文字。
文字\nは、「改行文字」とも呼ばれ、複数行の文字列を出力するための一重引用符と二重引用符をサポートしています。エンジンが文字列を出力するときに、\n に遭遇すると、別の行に出力を続けるため、複数行の文字列が実現されます。
\n は 2 文字のように見えますが、占有する文字位置は 1 つだけです。これは、\ が文字列内の エスケープ文字であるためです。 #、エスケープ文字で修飾された文字は特殊文字になります。
特殊文字リスト
| 説明 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
\n | 出力テキストの新しい行を開始するために使用される改行文字。 |||||||||||||
| Windows## では ## を使用します# system #\r\n は改行を表します。つまり、新しい行に変更するには、カーソルが最初に行の先頭に移動し、次に次の行に移動する必要があります。他のシステムの場合は、\n を使用してください。 | \'||||||||||||
|
\\ | ||||||||||||
バックスラッシュも必要です。理由は \ です。 は特殊文字です。 | \ 自体を出力したい場合は、エスケープする必要があります。 | \b||||||||||||
\v |
\xXX | ||||||||||||
は、XX としてエンコードされた 16 進数の | Unicode 文字です。たとえば、 \x7A は z (16 進数) を意味します。 z の Unicode エンコードは 7A です)。 | \uXXXX||||||||||||
は、XXXX としてエンコードされた 16 進数の | Unicode 文字です。たとえば、\u00A9 は © を意味します。 | (||||||||||||
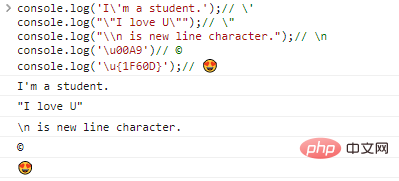
| #XX...X.举个例子: console.log('I\'m a student.');// \'console.log("\"I love U\"");// \"console.log("\\n is new line character.");// \nconsole.log('\u00A9')// ©console.log('\u{1F60D}');//ログイン後にコピー 代码执行结果:
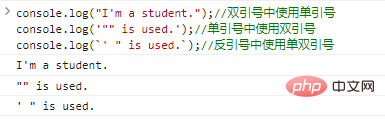
有了转义符 避免使用 对于字符串中的单双引号,我们可以通过在单引号中使用双引号、在双引号中使用单引号,或者直接在反引号中使用单双引号,就可以巧妙的避免使用转义符,例如: console.log("I'm a student.");
//双引号中使用单引号console.log('"" is used.');
//单引号中使用双引号console.log(`' " is used.`);
//反引号中使用单双引号ログイン後にコピー 代码执行结果如下:
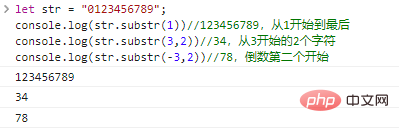
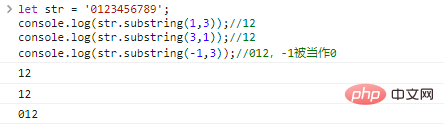
.length通过字符串的 console.log("HelloWorld\n".length);//11ログイン後にコピー 这里
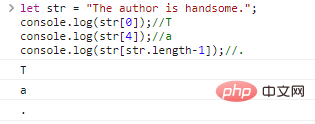
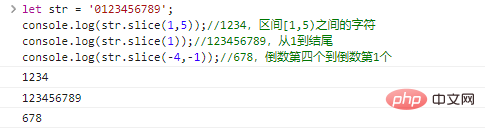
访问字符、charAt()、for…of字符串是字符组成的串,我们可以通过 let str = "The author is handsome."; console.log(str[0]);//Tconsole.log(str[4]);//aconsole.log(str[str.length-1]);//. ログイン後にコピー 代码执行结果:
我们还可以使用 let str = "The author is handsome.";console.log(str.charAt(0)); //Tconsole.log(str.charAt(4)); //aconsole.log(str.charAt(str.length-1));//. ログイン後にコピー 二者执行效果完全相同,唯一的区别在于越界访问字符时: let str = "01234";console.log(str[9]);//undefinedconsole.log(str.charAt(9));//""(空串) ログイン後にコピー 我们还可以使用 for(let c of '01234'){
console.log(c);}ログイン後にコピー 字符串不可变
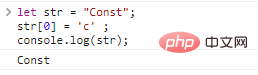
let str = "Const";str[0] = 'c' ;console.log(str); ログイン後にコピー 代码执行结果:
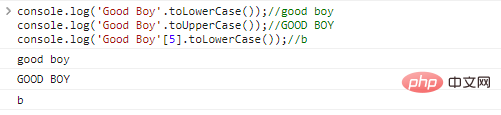
如果想获得一个不一样的字符串,只能新建: let str = "Const";str = str.replace('C','c');console.log(str);ログイン後にコピー 看起来我们似乎改变了字符串,实际上原来的字符串并没有被改变,我们得到的是 .toLowerCase()、.toUpperCase()转换字符串大小写,或者转换字符串中单个字符的大小写。 这两个字符串的方法比较简单,举例带过: console.log('Good Boy'.toLowerCase());//good
boyconsole.log('Good Boy'.toUpperCase());//GOOD
BOYconsole.log('Good Boy'[5].toLowerCase());//bログイン後にコピー 代码执行结果:
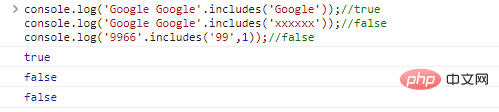
.indexOf()、.lastIndexOf() 查找子串
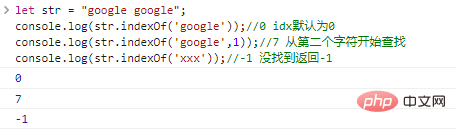
let str = "google google";console.log(str.indexOf('google'));
//0 idx默认为0console.log(str.indexOf('google',1));
//7 从第二个字符开始查找console.log(str.indexOf('xxx'));
//-1 没找到返回-1ログイン後にコピー 代码执行结果:
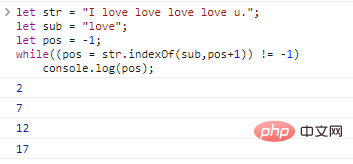
如果我们想查询字符串中所有子串位置,可以使用循环: let str = "I love love love love u.";let sub = "love";let pos = -1;while((pos = str.indexOf(sub,pos+1)) != -1) console.log(pos); ログイン後にコピー 代码执行结果如下:
let str = "google google";console.log(str.lastIndexOf('google'));//7 idx默认为0ログイン後にコピー 按位取反技巧(不推荐,但要会)由于 let str = "google google";if(~indexOf('google',str)){
...}ログイン後にコピー 通常情况下,我们不推荐在不能明显体现语法特性的地方使用一个语法,这会在可读性上产生影响。好在以上代码只出现在旧版本的代码中,这里提到就是为了大家在阅读旧代码的时候不会产生困惑。
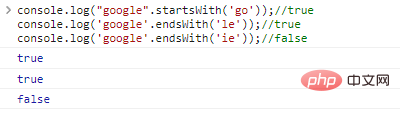
.includes()、.startsWith()、.endsWith()
.JavaScript 文字列の一般的な基本メソッドの詳細な紹介、.JavaScript 文字列の一般的な基本メソッドの詳細な紹介、.JavaScript 文字列の一般的な基本メソッドの詳細な紹介
对比三者的区别:
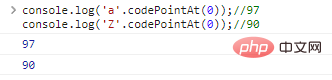
.JavaScript 文字列の一般的な基本メソッドの詳細な紹介、JavaScript 文字列の一般的な基本メソッドの詳細な紹介我们在前文中已经提及过字符串的比较,字符串按照字典序进行排序,每个字符背后都是一个编码, 例如: console.log('a'>'Z');//trueログイン後にコピー 字符之间的比较,本质上是代表字符的编码之间的比较。 console.log('a'.codePointAt(0));//97console.log('Z'.codePointAt(0));//90ログイン後にコピー 代码执行结果:
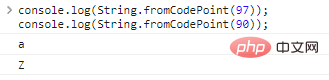
使用 console.log(String.fromCodePoint(97));console.log(String.fromCodePoint(90)); ログイン後にコピー 代码执行结果如下:
这个过程可以用转义符 console.log('\u005a');//Z,005a是90的16进制写法console.log('\u0061');//a,0061是97的16进制写法ログイン後にコピー 下面我们探索一下编码为 let str = '';for(let i = 65; i<p>代码执行部分结果如下:</p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/0f4e2a78ef52090d845bd32f6b72d01c-17.png" class="lazy" alt="JavaScript 文字列の一般的な基本メソッドの詳細な紹介"></p><p>上图并没有展示所有的结果,快去试试吧。</p><h2>.localeCompare()</h2><p>基于国际化标准<code>ECMA-402</code>,<code>JavaScript</code>已经实现了一个特殊的方法(<code>.localeCompare()</code>)比较各种字符串,采用<code>str1.localeCompare(str2)</code>的方式:</p><ol>
<li>如果<code>str1 ,返回负数;</code>
</li>
<li>如果<code>str1 > str2</code>,返回正数;</li>
<li>如果<code>str1 == str2</code>,返回0;</li>
</ol><p>举个例子:</p><pre class="brush:php;toolbar:false">console.log("abc".localeCompare('def'));//-1ログイン後にコピー 为什么不直接使用比较运算符呢? 这是因为英文字符有一些特殊的写法,例如, console.log('á' <p>虽然也是<code>a</code>,但是比<code>z</code>还要大!!</p><p>此时就需要使用<code>.localeCompare()</code>方法:</p><pre class="brush:php;toolbar:false">console.log('á'.localeCompare('z'));//-1ログイン後にコピー 常用方法
还有很多其他方法,我们可以访问手册获取更多知识。 进阶内容生僻字、JavaScript 文字列の一般的な基本メソッドの詳細な紹介、特殊符号
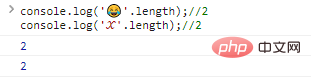
这种时候就需要扩展,使用更长的位数( console.log(''.length);//2console.log('?'.length);//2ログイン後にコピー 代码执行结果:
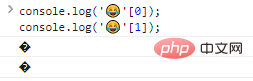
这么做的结果是,我们无法使用常规的方法处理它们,如果我们单个输出其中的每个字节,会发生什么呢? console.log(''[0]);console.log(''[1]);ログイン後にコピー 代码执行结果:
可以看到,单个输出字节是不能识别的。 好在 我们可以通过判断一个字符的编码范围,判断它是否是一个特殊字符,从而处理特殊字符。如果一个字符的代码在 举个例子: console.log(''.charCodeAt(0).toString(16));//d83
dconsole.log('?'.charCodeAt(1).toString(16));//de02ログイン後にコピー 代码执行结果:
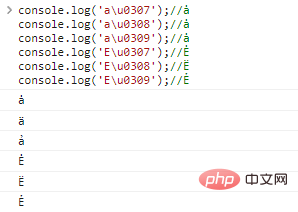
规范化在英文中,存在很多基于字母的变体,例如:字母 为了支持所有的变体组合,同样使用多个 console.log('a\u0307');//ȧ
console.log('a\u0308');//ȧ
console.log('a\u0309');//ȧ
console.log('E\u0307');//Ė
console.log('E\u0308');//Ë
console.log('E\u0309');//Ẻログイン後にコピー 代码执行结果:
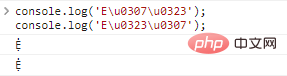
一个基础字母还可以有多个装饰,例如: console.log('E\u0307\u0323');//Ẹ̇
console.log('E\u0323\u0307');//Ẹ̇ログイン後にコピー 代码执行结果:
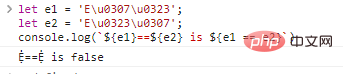
这里存在一个问题,在多个装饰的情况下,装饰的排序不同,实际上展示的字符是一样的。 如果我们直接比较这两种表示形式,却会得到错误的结果: let e1 = 'E\u0307\u0323';
let e2 = 'E\u0323\u0307';
console.log(`${e1}==${e2} is ${e1 == e2}`)ログイン後にコピー 代码执行结果:
为了解决这种情况,有一个** <span style="max-width:90%" microsoft yahei sans gb helvetica neue tahoma arial sans-serif>let e1 = 'E\u0307\u0323';<br>let e2 = 'E\u0323\u0307';<br>console.log(`${e1}==${e2} is ${e1.normalize() == e2.normalize()}`)</span><br>ログイン後にコピー 代码执行结果:
【相关推荐:javascript视频教程、web前端】 |
以上がJavaScript 文字列の一般的な基本メソッドの詳細な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



