

5 つの一般的な MySQL 高可用性ソリューションを整理して要約する

この記事では、mysql に関する関連知識を提供します。主に一般的な高可用性ソリューションに関連する問題を紹介します。ここでは、一般的に使用される高可用性ソリューションと高可用性の長所と短所についてのみ説明します。解決策の選択をご覧ください。皆様のお役に立てれば幸いです。

推奨学習: mysql ビデオ チュートリアル
1. 概要
MySQL の高可用性を検討しています。データベース アーキテクチャを設計するときは、主に次の側面を考慮する必要があります。
- データベースがダウンした場合、または予期せず中断された場合、データベースの可用性をできるだけ早く復元し、ダウンタイムを短縮することができます。データベースの障害によってビジネスが中断されないように、可能な限り削減されます。
- バックアップや読み取り専用レプリカなどの機能に使用される非プライマリ ノードのデータは、リアルタイムまたは最終的にプライマリ ノードのデータと一致する必要があります。
- 業務上でデータベースの切り替えが発生した場合、データの欠落や不整合によって業務に影響を与えないよう、切り替え前後のデータベースの内容が一致している必要があります。
ここでは、高可用性の分類については詳しく説明しません。一般的に使用される高可用性ソリューションの長所と短所、および高可用性ソリューションの選択についてのみ説明します。
2. 高可用性ソリューション
2.1. マスター/スレーブまたはマスター/マスターの半同期レプリケーション
2 ノード データベースを使用して、一方向または双方向のレプリケーションを構築します。準同期レプリケーションの方法。 5.7 以降のバージョンでは、ロスレス レプリケーションや論理マルチスレッド レプリケーションなどの一連の新機能の導入により、MySQL のネイティブの半同期レプリケーションの信頼性が向上しています。
一般的なアーキテクチャは次のとおりです: 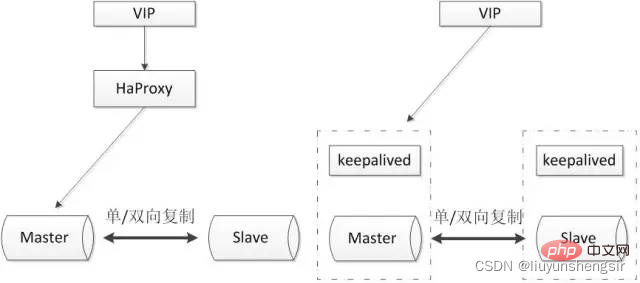
通常、プロキシやキープアライブなどのサードパーティ ソフトウェアと一緒に使用され、データベースの健全性を監視するために使用でき、一連の管理コマンドを実行します。プライマリ データベースに障害が発生した場合でも、スタンバイ データベースに切り替えた後もデータベースを使用できます。
利点:
- アーキテクチャは比較的シンプルで、データ同期の基礎としてネイティブの半同期レプリケーションを使用します。
- デュアルノード、マスターはありません。ホストがダウンした後の選択の問題。直接切り替えることができます。
- デュアル ノードは必要なリソースが少なく、展開が簡単です。
欠点:
- 準同期レプリケーションに完全に依存. 準同期レプリケーションが非同期レプリケーションに縮退し、データの整合性が保証できない場合;
- haproxy や keepalived の高可用性機構も追加で考慮する必要があります。
2.2. 準同期レプリケーションの最適化
準同期レプリケーション メカニズムは信頼性があります。半同期レプリケーションが常に有効であれば、データは一貫していると見なすことができます。しかし、ネットワーク変動などの客観的な理由により、準同期レプリケーションがタイムアウトし、非同期レプリケーションに切り替わる場合、データの整合性は保証できません。したがって、可能な限り準同期レプリケーションを確保することで、データの一貫性を向上させることができます。
このソリューションも 2 ノード アーキテクチャを使用していますが、元の準同期レプリケーションに基づいて機能が最適化されており、準同期レプリケーション メカニズムの信頼性が向上しています。
参照できる最適化ソリューションは次のとおりです:
2.2.1. デュアルチャネル レプリケーション
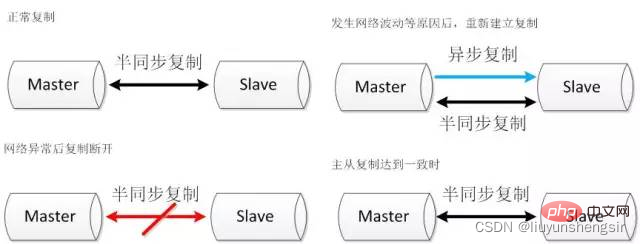
準同期レプリケーションは、次の理由によりタイムアウトします。その後、レプリケーションが切断されます。レプリケーションが再度確立されると、2 つのチャネルが同時に確立されます。準同期レプリケーション チャネルの 1 つは、スレーブが確実に認識できるように、現在の位置からレプリケーションを開始します。現在のホスト実行の進行状況。別の非同期レプリケーション チャネルがスレーブの遅れたデータに追いつき始めます。非同期レプリケーション チャネルが準同期レプリケーションの開始位置に追いつくと、準同期レプリケーションが再開されます。
2.2.2. binlog ファイル サーバー
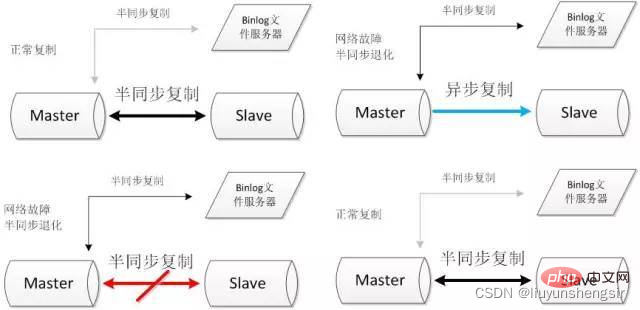
2 つの半同期レプリケーション チャネルを構築します。ファイル サーバー 通常の状況では有効になっていませんが、ネットワークの問題によりマスター/スレーブの準同期レプリケーションが低下すると、ファイル サーバーとの準同期レプリケーション チャネルが開始されます。マスター/スレーブの準同期レプリケーションが再開したら、ファイル サーバーとの準同期レプリケーション チャネルを閉じます。
利点:
デュアルノードは必要なリソースが少なく、導入が簡単です;
アーキテクチャはシンプルで、マスターの選択に問題はなく、直接切り替えるだけです;
比較ネイティブ レプリケーションを使用する場合、最適化された半同期レプリケーションにより、データの一貫性をより確実に確保できます。
欠点:
カーネル ソース コードを変更するか、mysql 通信プロトコルを使用する必要があります。ソースコードをある程度理解し、ある程度の二次開発ができる必要があります。
依然として半同期レプリケーションに依存しているため、データの一貫性の問題は根本的に解決されていません。
2.3. 高可用性アーキテクチャの最適化
デュアルノード データベースをマルチノード データベースまたはマルチノード データベース クラスターに拡張します。ニーズに応じて、1 つのマスターと 2 つのスレーブ、1 つのマスターと複数のスレーブ、または複数のマスターと複数のスレーブを含むクラスターを選択できます。
準同期レプリケーションの特性上、スレーブからの成功応答を受信した場合に準同期レプリケーションが成功したとみなす特徴があるため、単一スレーブの準同期レプリケーションの信頼性よりもマルチスレーブの準同期レプリケーションの信頼性が高くなります。 -slave 半同期レプリケーション。また、複数のノードが同時にダウンする確率は、単一のノードがダウンする確率よりも低いため、マルチノード アーキテクチャはデュアルノードよりもある程度高可用性が高いと考えることができます。建築。
ただし、データベースの数が多いため、データベースの保守性を確保するにはデータベース管理ソフトウェアが必要です。 MMM、MHA、またはさまざまなバージョンのプロキシなどを選択できます。一般的な解決策は次のとおりです:
2.3.1. MHA マルチノード クラスター
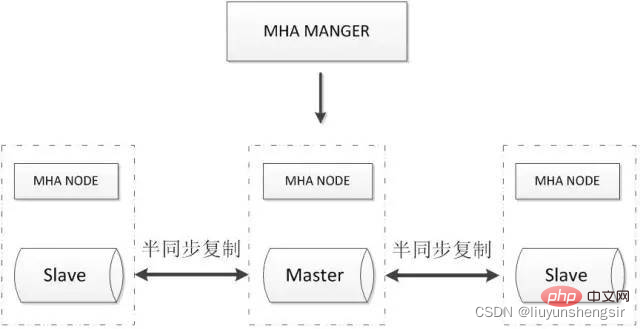
MHA マネージャーはクラスター内のマスター ノードを定期的に検出します。マスターが表示されるとき 障害が発生した場合、最新のデータを持つスレーブを新しいマスターに自動的に昇格させ、他のすべてのスレーブを新しいマスターにリダイレクトできます。フェイルオーバー プロセス全体は、アプリケーションに対して完全に透過的です。
MHA ノードは各 MySQL サーバー上で実行されます。その主な機能は、スイッチオーバー中にバイナリ ログを処理して、スイッチオーバーによるデータ損失を最小限に抑えることです。
MHA は次のマルチノード クラスタにも拡張できます: 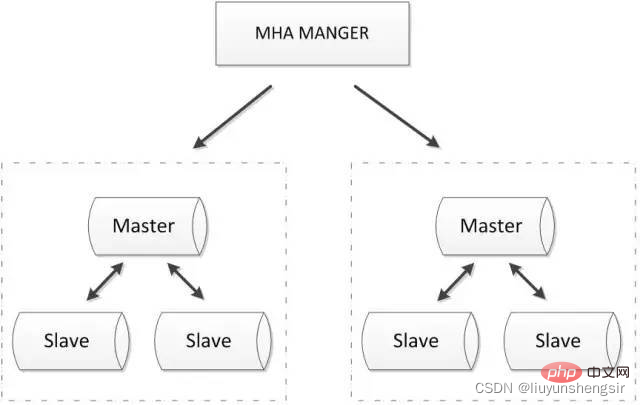
利点:
障害の自動検出と転送を実行できます;
スケーラビリティMySQL ノードの数と構造は必要に応じて拡張できます。
2 ノードの MySQL レプリケーションと比較して、3 ノード/マルチノードの MySQL は使用できなくなる可能性が低くなります。
欠点:
少なくとも 3 つのノードが必要であり、2 つのノードよりも多くのリソースが必要になります。
ロジックがより複雑になり、障害発生後のトラブルシューティングと問題の特定がより困難になります。
データの一貫性は、ネイティブの半同期レプリケーションによって引き続き保証されますが、データの不整合のリスクは依然として存在します;
ネットワークの分割によりスプリット ブレインが発生する可能性があります;
2.3.2. Zookeeper プロキシ
Zookeeper は分散アルゴリズムを使用してクラスタリングを保証します。 データの一貫性を確保するために、Zookeeper を使用するとプロキシの高可用性を効果的に確保し、ネットワークの分断をより適切に回避できます。
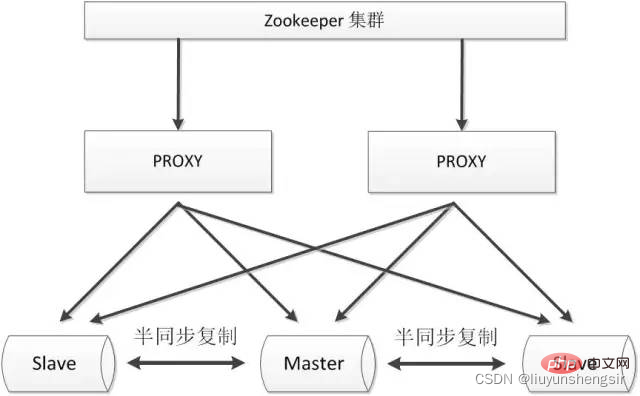
利点:
プロキシ、MySQL を含むシステム全体の高可用性がより確実に保証されます。
優れたスケーラビリティにより、大規模な拡張が可能です。スケール クラスター;
欠点:
データの一貫性は依然としてネイティブの mysql 半同期レプリケーションに依存しています;
zk の導入により、システム全体のロジックがより複雑になります;
2.4. 共有ストレージ
共有ストレージは、データベース サーバーとストレージ デバイスの分離を実現します。異なるデータベース間のデータ同期は、MySQL のネイティブ レプリケーション機能に依存せず、ディスク データ同期を通じて行われます。一貫性。
2.4.1. SAN 共有ストレージ
SAN の概念により、ストレージ デバイスとプロセッサ (サーバー) の間に直接高速ネットワークを確立できます (従来のものと比較して) LAN ) 接続により、データの集中ストレージが実現されます。
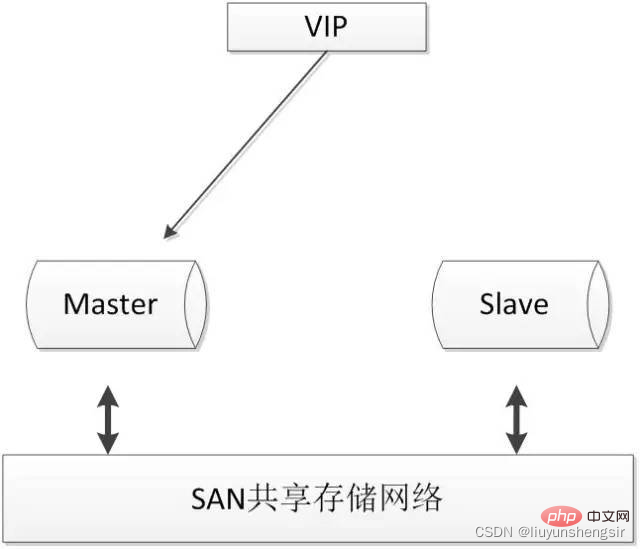
共有ストレージを使用する場合、MySQL サーバーはファイル システムを通常どおりマウントして操作できますが、メイン データベースがダウンした場合は、スタンバイ データベースがファイル システムをマウントできます。同じファイル システムなので、プライマリ データベースとスタンバイ データベースが同じデータを使用することが保証されます。
利点:
2 つのノードで十分、シンプルなデプロイメント、シンプルな切り替えロジック;
データの強力な一貫性が十分に保証されている;
MySQL データの不整合による論理エラーは発生しない;
欠点:
共有ストレージの高可用性を考慮する必要がある;
高価;
2.4.2. DRBD ディスクのレプリケーション
DRBD は、ソフトウェアベースのネットワークベースのブロック レプリケーション ストレージ ソリューションです。主に、サーバー間のディスク、パーティション、論理ボリュームなどのデータ ミラーリングに使用されます。ユーザーがローカルにデータを書き込むとき、ディスクが接続されているとき、の場合、データはネットワーク内の別のホストのディスクにも送信されるため、ローカル ホスト (プライマリ ノード) とリモート ホスト (スタンバイ ノード) のデータをリアルタイムで同期できます。一般的に使用されるアーキテクチャは次のとおりです。 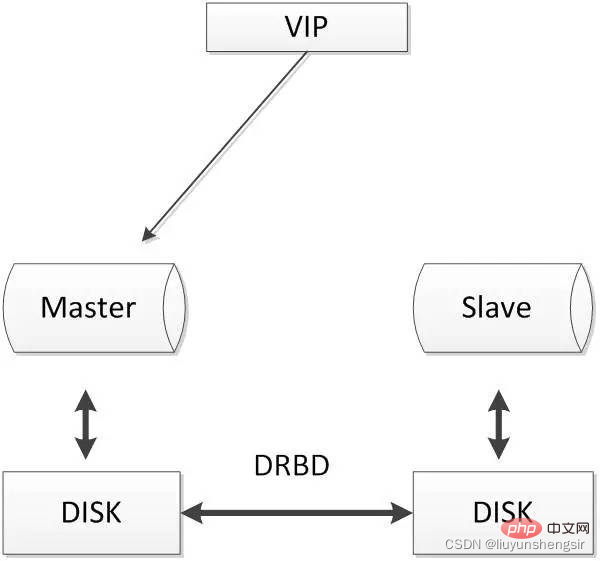
ローカル ホストで問題が発生した場合でも、同じデータのコピーがリモート ホストに保持され、引き続き使用できるため、データセキュリティ。
DRBD は、Linux カーネル モジュールによって実装された高速レベルの同期レプリケーション テクノロジであり、SAN と同じ共有ストレージ効果を実現できます。
利点:
必要なノードは 2 つだけで、展開とスイッチング ロジックがシンプルです。
SAN ストレージ ネットワークと比較して、価格が安価です。
データの強力な一貫性を確保します。
欠点:
IO パフォーマンスに大きな影響を与える;
スレーブ ライブラリは読み取り操作を提供しません;
2.5. 分散プロトコル
分散プロトコル データの一貫性の問題をうまく解決できます。より一般的な解決策は次のとおりです:
2.5.1. MySQL クラスター
MySQL クラスターは、公式のクラスター展開ソリューションであり、NDB ストレージ エンジンを使用して冗長データをリアルタイムでバックアップし、高可用性とデータを実現します。データベースの一貫性。 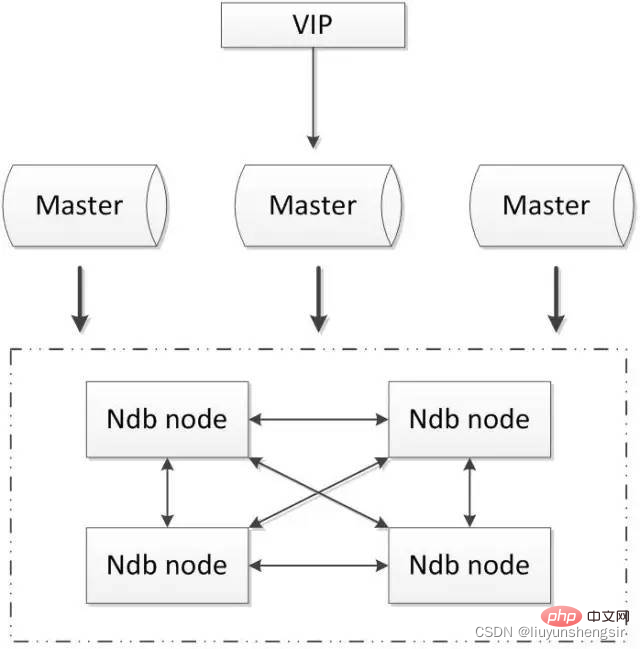
利点:
すべて公式コンポーネントを使用し、サードパーティ ソフトウェアに依存しません;
データの強力な一貫性を実現できます;
欠点:
中国ではほとんど使用されません;
構成はより複雑で、通常の MySQL エンジンとは多少異なる NDB ストレージ エンジンの使用が必要です;
少なくとも 3 つのノード。
2.5.2. Galera
Galera ベースの MySQL 高可用性クラスターは、マルチマスター データ同期のための MySQL クラスター ソリューションです。単一障害点がなく、高可用性を備えています。一般的なアーキテクチャは次のとおりです:
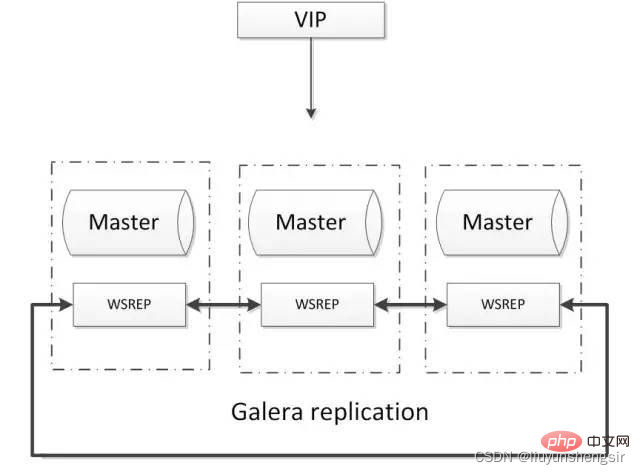
利点:
マルチマスター書き込み、遅延のないレプリケーション、強力なデータ一貫性の確保;
成熟したコミュニティ、大規模なインターネット企業によって使用されます;
自動フェイルオーバー、ノードの自動追加と削除;
欠点:
ネイティブ MySQL ノードに wsrep パッチが必要です
のみサポートされる innodb ストレージ エンジン
少なくとも 3 つのノード;
2.5.3. POAXS
Paxos アルゴリズムによって解決される問題は、分散システムが特定の値 (解像度) についてどのように合意に達するかです。 )。このアルゴリズムは、この種のアルゴリズムの中で最も効率的であると考えられています。 Paxos と MySQL を組み合わせると、分散 MySQL データの強力な一貫性を実現できます。一般的なアーキテクチャは次のとおりです:
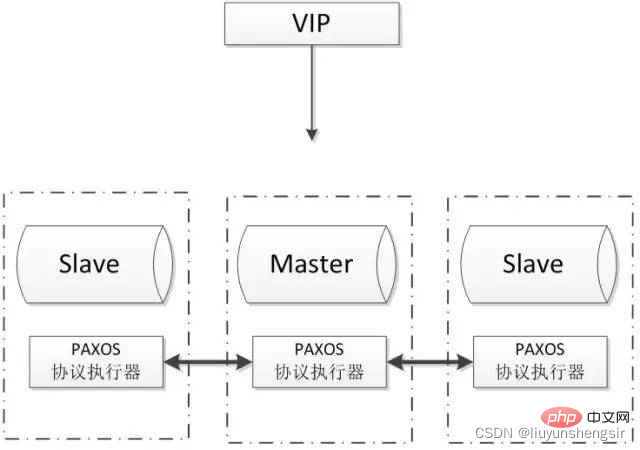
利点:
マルチマスター書き込み、遅延のないレプリケーション、強力なデータ一貫性の保証;
成熟した理論的基盤があります。
自動フェイルオーバー、ノードの自動追加と削除;
欠点:
innodb ストレージ エンジンのみをサポート
少なくとも 3 つのノード;
3. 概要
データの一貫性に対する人々の要求が高まり続けるにつれ、分散データの一貫性の問題を解決するために、MySQL 自体の最適化、MySQL クラスター アーキテクチャの最適化、Paxos、Raft、 2PCアルゴリズムの導入など。
分散アルゴリズムを使用して MySQL データベースのデータ一貫性の問題を解決する方法は、人々にますます受け入れられてきており、PhxSQL、MariaDB Galera Cluster、Percona XtraDB Cluster などの一連の成熟した製品が登場しています。ますます人気が高まっており、大規模に使用されることが増えています。
MySQL グループ レプリケーションの正式 GA により、分散プロトコルを使用してデータの一貫性の問題を解決することが主流の方向になりました。より多くの優れたソリューションが提案され、MySQL の高可用性の問題がより適切に解決されることが期待されます。
推奨学習: mysql ビデオ チュートリアル
以上が5 つの一般的な MySQL 高可用性ソリューションを整理して要約するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1662
1662
 14
1419
52
1312
25
1262
29
1235
24
14
1419
52
1312
25
1262
29
1235
24

 MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。
 Laravelは紹介例
Apr 18, 2025 pm 12:45 PM
Laravelは紹介例
Apr 18, 2025 pm 12:45 PM
Laravelは、Webアプリケーションを簡単に構築するためのPHPフレームワークです。次のような強力な機能を提供します。インストール:Laravel CLIを作曲家にグローバルにインストールし、プロジェクトディレクトリにアプリケーションを作成します。ルーティング:ルート/web.phpのURLとハンドラーの関係を定義します。ビュー:リソース/ビューでビューを作成して、アプリケーションのインターフェイスをレンダリングします。データベース統合:MySQLなどのデータベースとのすぐ外側の統合を提供し、移行を使用してテーブルを作成および変更します。モデルとコントローラー:モデルはデータベースエンティティを表し、コントローラーはHTTP要求を処理します。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 MySQLおよびPHPMYADMIN:コア機能と関数
Apr 22, 2025 am 12:12 AM
MySQLおよびPHPMYADMIN:コア機能と関数
Apr 22, 2025 am 12:12 AM
MySQLとPHPMyAdminは、強力なデータベース管理ツールです。 1)MySQLは、データベースとテーブルを作成し、DMLおよびSQLクエリを実行するために使用されます。 2)PHPMyAdminは、データベース管理、テーブル構造管理、データ操作、ユーザー許可管理のための直感的なインターフェイスを提供します。
 データベース接続の解決問題:Minii/DBライブラリを使用する実用的なケース
Apr 18, 2025 am 07:09 AM
データベース接続の解決問題:Minii/DBライブラリを使用する実用的なケース
Apr 18, 2025 am 07:09 AM
小さなアプリケーションを開発する際には、軽量データベース操作ライブラリをすばやく統合する必要性という厄介な問題に遭遇しました。複数のライブラリを試した後、私はそれらがあまりにも多くの機能を持っているか、あまり互換性がないかのどちらかであることがわかりました。最終的に、私は問題を完全に解決したYii2に基づいた単純化されたバージョンであるMinii/DBを見つけました。
 MySQL対その他のプログラミング言語:比較
Apr 19, 2025 am 12:22 AM
MySQL対その他のプログラミング言語:比較
Apr 19, 2025 am 12:22 AM
他のプログラミング言語と比較して、MySQLは主にデータの保存と管理に使用されますが、Python、Java、Cなどの他の言語は論理処理とアプリケーション開発に使用されます。 MySQLは、データ管理のニーズに適した高性能、スケーラビリティ、およびクロスプラットフォームサポートで知られていますが、他の言語は、データ分析、エンタープライズアプリケーション、システムプログラミングなどのそれぞれの分野で利点があります。
 Laravel Frameworkインストール方法
Apr 18, 2025 pm 12:54 PM
Laravel Frameworkインストール方法
Apr 18, 2025 pm 12:54 PM
記事の概要:この記事では、Laravelフレームワークを簡単にインストールする方法について読者をガイドするための詳細なステップバイステップの指示を提供します。 Laravelは、Webアプリケーションの開発プロセスを高速化する強力なPHPフレームワークです。このチュートリアルは、システム要件からデータベースの構成とルーティングの設定までのインストールプロセスをカバーしています。これらの手順に従うことにより、読者はLaravelプロジェクトのための強固な基盤を迅速かつ効率的に築くことができます。
 初心者向けのMySQL:データベース管理を開始します
Apr 18, 2025 am 12:10 AM
初心者向けのMySQL:データベース管理を開始します
Apr 18, 2025 am 12:10 AM
MySQLの基本操作には、データベース、テーブルの作成、およびSQLを使用してデータのCRUD操作を実行することが含まれます。 1.データベースの作成:createdatabasemy_first_db; 2。テーブルの作成:createTableBooks(idintauto_incrementprimarykey、titlevarchary(100)notnull、authorvarchar(100)notnull、published_yearint); 3.データの挿入:InsertIntoBooks(タイトル、著者、公開_year)VA
