

MySQL トランザクション ワークフローの原則を一緒に分析しましょう

この記事では、mysql に関する関連知識を提供します。主に、トランザクションのアトミック性は UNDO ログによって実現され、トランザクションの永続性は REDO ログによって実現され、トランザクションのワークフローの原則に関連する問題が紹介されます。などなど、見ていきましょう。皆さんのお役に立てれば幸いです。

推奨される学習: mysql ビデオ チュートリアル
- トランザクションのアトミック性は、UNDO ログを通じて実現されます
- トランザクションの耐久性は、REDO ログによって実現されます。
- トランザクションの分離は、(読み取り/書き込みロック MVCC) によって実現されます。
- そして、トランザクションの究極の一貫性は、アトミック性、永続性、そして孤立! ! !
1. 永続性を実現するための redo ログ
問題1: REDO ログが必要なのはなぜですか?
InnoDB は MySQL のストレージ エンジンです。データはディスクに保存されます。ただし、データの読み書きに毎回ディスク IO が必要な場合は、効率が低下します。非常に低いです。このため、InnoDB はデータベースにアクセスするためのバッファーとしてキャッシュ (バッファー プール) を提供します。データベースからデータを読み取るときは、まずバッファー プールから読み取られます。バッファー プールがない場合は、バッファー プールから読み取られます。ディスクに保存され、バッファ プールに置かれます。データベースにデータを書き込む場合、データは最初にバッファ プールに書き込まれ、バッファ プール内の変更されたデータは定期的にディスクに更新されます。
バッファ プールを使用すると、データの読み取りと書き込みの効率が大幅に向上しますが、新たな問題も生じます。MySQL がダウンし、バッファ プール内の変更されたデータがディスクにフラッシュされていない場合、データ損失とトランザクションの耐久性は保証できません。
質問 2: REDO ログはトランザクションの耐久性をどのように保証しますか?
REDO ログは、単純に次の 2 つの部分に分けることができます。
最初の部分は、メモリ内の REDO ログ バッファ ( REDO ログ バッファ ) は揮発性でメモリに保存されます。タイミング:
データ ページの変更が完了した後、ダーティ ページがディスクからフラッシュされる前に、REDO ログが書き込まれます。データが最初に変更され、ログが後で書き込まれることに注意してください。
REDO ログはデータ ページの前にディスクに書き戻されます。
クラスター化インデックス、セカンダリ インデックス、および元に戻すページの変更すべてを Redo ログに記録する必要があります
MySQL では、すべての更新操作をディスクに書き込む必要がある場合、ディスクにも書き込む必要があります。対応するレコードを見つけて更新するため、プロセス全体の IO コストと検索コストが非常に高くなります。この問題を解決するために、MySQL 設計者は REDO ログを使用して更新効率を向上させました。 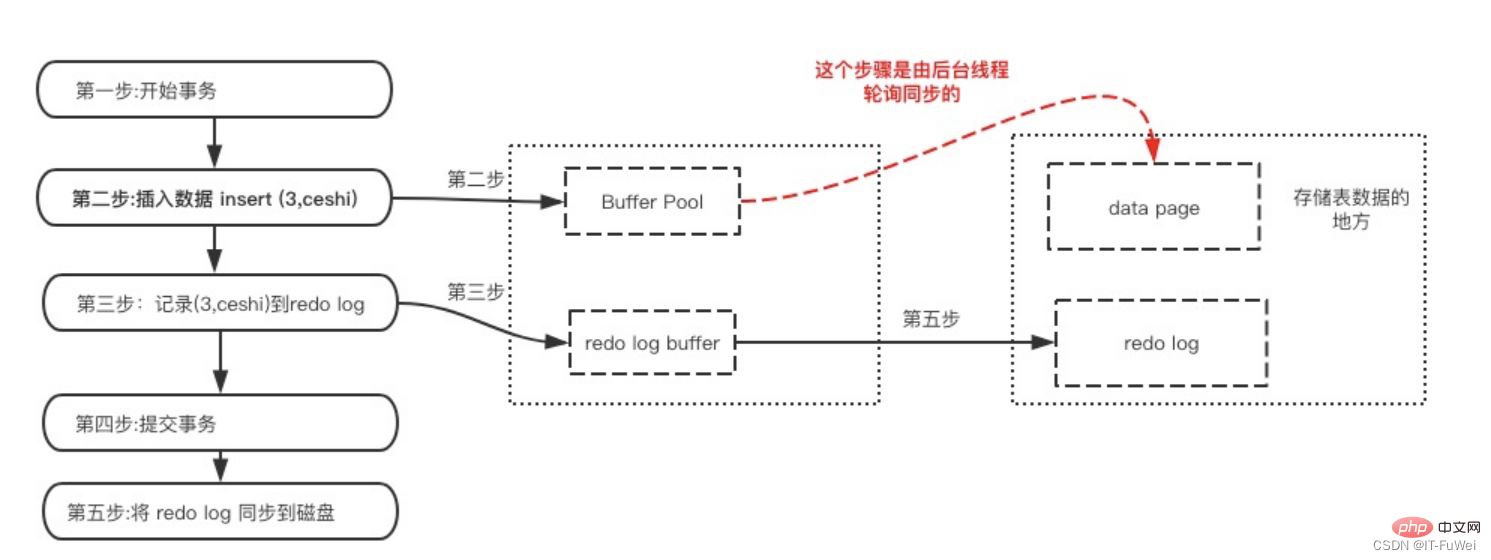
具体的には、レコードを更新する必要がある場合、InnoDB エンジンはまずレコードを REDO ログ (REDO ログ バッファ) に書き込み、メモリ (バッファ プール) を更新します。この時点で更新は完了します。 . .同時に、InnoDB エンジンは、適切なタイミング (システムがアイドル状態のときなど) に、この操作レコードをディスクに更新します (ダーティ ページをフラッシュします)。
1 つのトランザクションで複数のページを変更できます。先行書き込みログは、単一のデータ ページの一貫性を保証できますが、トランザクションの耐久性は保証できません。強制ログアットコミットでは、トランザクションの実行時にそれが必要です。がコミットされている場合、それによって生成されたすべてのミニトランザクション ログをディスクにフラッシュする必要があります。ログのフラッシュが完了した後、バッファ プール内のページが永続ストレージ デバイスにフラッシュされる前にデータベースがクラッシュした場合、データベースが再起動されると、ログはデータの整合性を確保するために使用できます。
質問 3: ログを書き換えるプロセスは何ですか?
上図は REDO ログの書き込みプロセスを示しています。各ミニトランザクションは、更新ステートメントなどの各 DML 操作に対応しており、ミニトランザクションによって保証されています。データが変更された後、REDO1 が生成されます、まずミニトランザクションのプライベート バッファに書き込み、update ステートメントが終了したら、redo1 をプライベート バッファからパブリック ログ バッファにコピーします。外部トランザクション全体がコミットされると、REDO ログ バッファが REDO ログ ファイルにフラッシュされます。 (REDO ログは順次に書き込まれ、ディスクの順次読み取りおよび書き込みは、ランダムな読み取りおよび書き込みよりもはるかに高速です)
質問 4:データ書き込み 最終配置はREDOログまたはバッファプールから更新されますか?
実際、REDO ログにはデータ ページの完全なデータが記録されないため、ディスク データ ページを更新する機能はありません。 REDO ログによって更新された過去のデータが最終的にディスク上に配置される場合があります。
① データ ページが変更されると、ディスク上のデータ ページと不一致になり、ダーティ ページと呼ばれます。最後のデータ フラッシュでは、メモリ内のデータ ページをディスクに書き込みます。このプロセスは REDO ログとは関係ありません。
② クラッシュ リカバリ シナリオでは、InnoDB がクラッシュ リカバリ中にデータ ページの更新が失われた可能性があると判断した場合、データ ページをメモリに読み取り、REDO ログでメモリの内容を更新します。更新が完了すると、メモリ ページはダーティ ページになり、最初の状態に戻ります。
質問 5: REDO ログとは何ですか?バッファ?最初にメモリを変更するべきですか、それとも最初に REDO ログ ファイルを書き込むべきですか?
#トランザクションの更新プロセス中に、ログを複数回書き込む必要があります。たとえば、次のトランザクション: Copybegin;INSERT INTO T1 VALUES ('1', '1');INSERT INTO T2 VALUES ('1', '1 ');commit;このトランザクションは、2 つのテーブルにレコードを挿入します。データの挿入プロセス中、生成されたログを最初に保存する必要がありますが、ログを保存する前にコミットすることはできません。時間が来たら、REDO ログ ファイルに直接書き込みます。 したがって、REDO ログ バッファが必要になります。これは、最初に REDO ログを保存するために使用されるメモリです。つまり、最初の挿入が実行されると、データ メモリが変更され、REDO ログ バッファもログに書き込まれます。 ただし、REDO ログ ファイルへの実際のログの書き込みは、commit ステートメントの実行時に行われます。 redo ログ バッファは本質的に単なるバイト配列ですが、このバッファを維持するには、他の多くのメタデータを設定する必要があり、それらはすべて log_t 構造にカプセル化されます。
#質問 6: REDO ログはディスクに順番に書き込まれますか?
REDO ログはファイルに順番に書き込みます。すべてのファイルがいっぱいになると、最初のファイルの対応する開始位置に戻ります。上書きを実行すると、各トランザクションが送信された後、関連する操作ログが最初に REDO ログ ファイルに書き込まれ、ファイルの末尾に追加されます。これはシーケンシャル I/O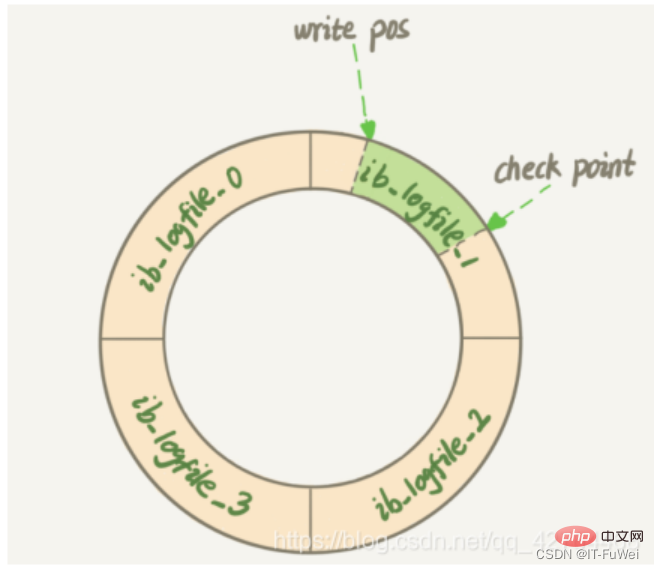
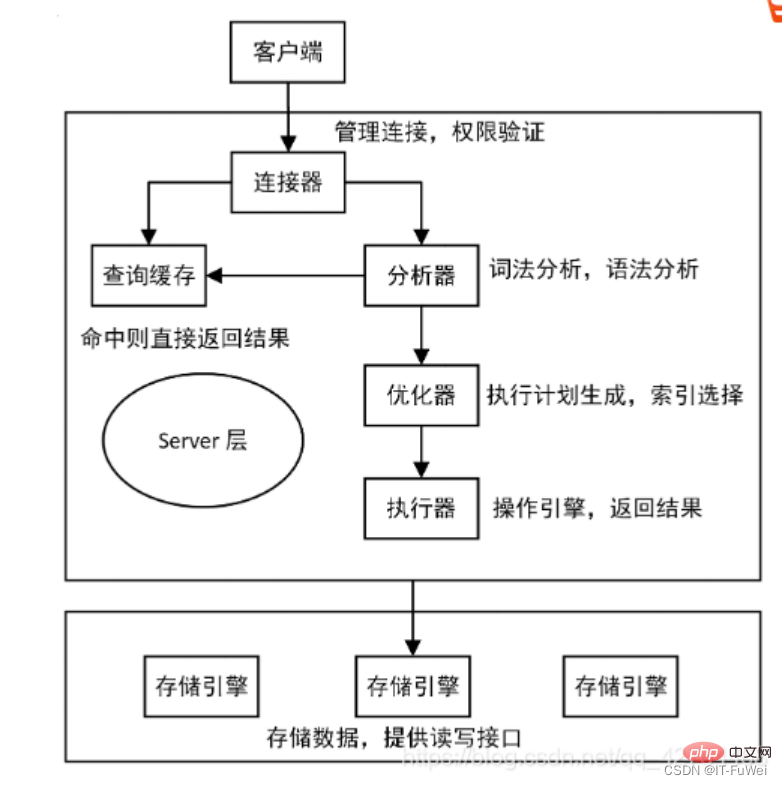
MySQL 全体として、実際には 2 つあります。部分: 1 つはサーバー層で、主に MySQL の機能レベルで処理を行い、もう 1 つはエンジン層で、特定のストレージ関連の問題を担当します。上で説明した REDO ログは InnoDB エンジンに固有のログであり、サーバー層にも binlog (アーカイブ ログ) と呼ばれる独自のログがあります。REDO ログを使用すると、データベースが異常に再起動した場合に、REDO ログに基づいてデータベースを復元できるため、クラッシュセーフになります。
REDO ログは、クラッシュセーフ機能を確保するために使用されます。 innodb_flush_log_at_trx_commit パラメータが 1 に設定されている場合、各トランザクションの REDO ログがディスクに直接保存されることを意味します。 MySQL が異常に再起動した後にデータが失われないように、このパラメータを 1 に設定することをお勧めします
2. Bin log
ログが 2 つあるのはなぜですか?
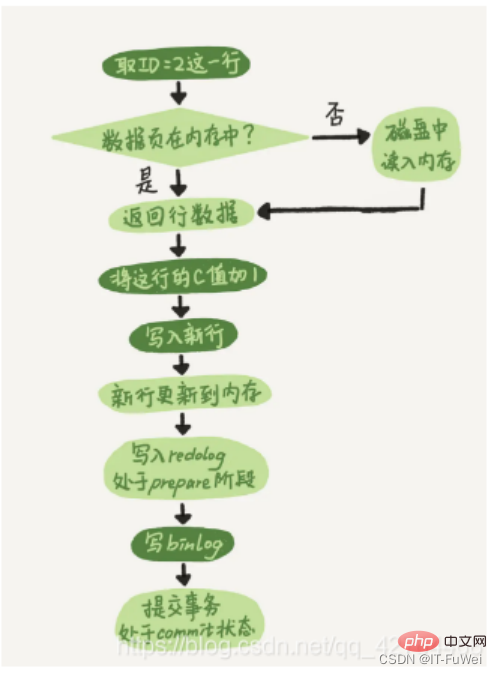
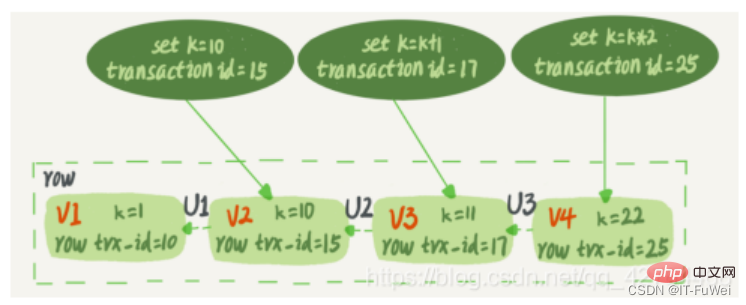
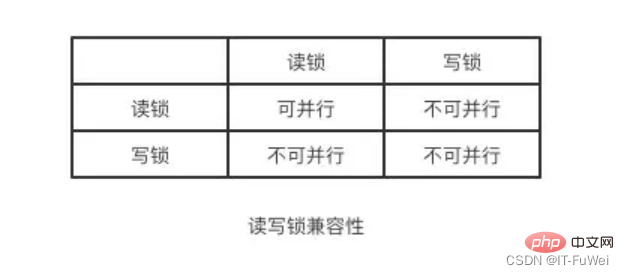
MySQL には最初から InnoDB エンジンがなかったからです。 MySQL 独自のエンジンは MyISAM ですが、MyISAM にはクラッシュセーフ機能がなく、binlog ログはアーカイブにのみ使用できます。 InnoDB は、他社によってプラグインの形で MySQL に導入されましたが、binlog のみに依存するとクラッシュ セーフ機能がないため、InnoDB は別のログ システム、つまり REDO ログを使用してクラッシュ セーフ機能を実現します。 2 つのログには次の 3 つの違いがあります。 ① REDO ログは InnoDB エンジンに固有であり、binlog は MySQL のサーバー層によって実装され、すべてのエンジンで使用できます。 ② REDO ログは、「特定のデータ ページにどのような変更が加えられたか」を記録する物理ログであり、binlog は、「ID=2 を指定する」など、このステートメントの元のロジックを記録する論理ログです。 this 行の c フィールドが 1 ずつインクリメントされます。 ③ REDO ログはループで書き込まれるため、必ず容量が消費されますが、binlog は追加で書き込むことができます。 「追加書き込み」とは、binlog ファイルが特定のサイズに達した後、次のファイルに切り替わり、前のログを上書きしないことを意味します。 これら 2 つのログの概念を理解した後、この更新ステートメントを実行するときのエグゼキューターと InnoDB エンジンの内部プロセスを見てみましょう。 。 ① エグゼキュータはまずエンジンを探して行 ID=2 を取得します。 ID が主キーであり、エンジンはツリー検索を直接使用してこの行を見つけます。 ID=2 の行が配置されているデータ ページがすでにメモリ内にある場合は、そのデータ ページが直接エグゼキュータに返されます。そうでない場合は、最初にディスクからメモリに読み込まれてから返される必要があります。 ② エグゼキューターは、エンジンによって指定された行データを取得し、この値に 1 を加算します。たとえば、以前は N でしたが、現在は N 1 になり、新しいデータ行を取得して、呼び出します。この新しいデータ行を書き込むためのエンジン インターフェイス。 ③ エンジンは、この新しいデータ行をメモリ (InnoDB バッファ プール) に更新し、更新操作を REDO ログに記録します。この時点で、REDO ログは準備状態になります。次に、実行が完了し、いつでもトランザクションを送信できることを実行者に通知します。 ④ エグゼキュータは、この操作のバイナリログを生成し、バイナリログをディスクに書き込みます。 ⑤ エグゼキューターはエンジンのコミット トランザクション インターフェイスを呼び出し、エンジンは書き込まれたばかりの REDO ログをコミット状態に変更し、更新が完了します。 REDO ログの書き込みを準備とコミットの 2 つのステップに分割します。これは 2 フェーズ コミット (2PC) です。 問題 1 :二段階提出の原則とは何ですか? MySQL は、主に binlog と redo ログのデータ整合性の問題を解決するために 2 フェーズ コミットを使用します。 2 段階コミットの原則の説明: ① REDO ログがディスクに書き込まれ、InnoDB トランザクションが準備状態に入ります。 ② 前の準備が成功し、バイナリ ログがディスクに書き込まれた場合は、トランザクション ログをバイナリ ログに永続化し続けます。永続化が成功すると、InnoDB トランザクションはコミット状態になります。 redo ログと binlog には、XID と呼ばれる共通のデータ フィールドがあります。クラッシュリカバリ中に、REDO ログは次の順序でスキャンされます: ① prepare と commit の両方を含む REDO ログが見つかった場合は、直接送信されます; ② のみが見つかった場合は、 parepare と commit コミット REDO ログがない場合は、XID を使用して、binlog 内の対応するトランザクションを見つけます。 バイナリログにレコードがありません、トランザクションをロールバックします バイナリログにレコードがあります、トランザクションをコミットします 質問 2 : なぜ「2 フェーズ コミット」が必要なのでしょうか? 2 フェーズ送信が使用されない場合は、ID=2 の現在の行のフィールド c の値が 0 であると仮定します。 update ステートメントの実行中に、最初のログを書き込んだ後、2 番目のログが書き込まれる前にクラッシュが発生すると仮定します。 **最初に REDO ログを書き込み、次に binlog を書き込みます。 **REDO ログが書き込まれたとき、バイナリログが書き込まれる前に、MySQL プロセスが異常に再起動したとします。前に述べたように、REDO ログが書き込まれた後は、システムがクラッシュしてもデータを回復できるため、回復後のこの行の c の値は 1 になります。 しかし、バイナリログが完了する前にクラッシュしたため、このステートメントは現時点ではバイナリログには記録されませんでした。したがって、後でログをバックアップするときに、このステートメントは保存されたバイナリログには含まれません。 次に、このバイナリログを使用して一時ライブラリを復元する必要がある場合、このステートメントのバイナリログが失われるため、一時ライブラリはこの更新を失い、復元された行の c の値も失われることがわかります。は 0 となり、元のライブラリの値とは異なります。 **最初に binlog を書き込み、次に redo ログを書き込みます。 **binlog の書き込み後にクラッシュが発生した場合、REDO ログはまだ書き込まれていないため、クラッシュ回復後のトランザクションは無効になるため、この行の c の値は 0 になります。ただし、binlog には「c を 0 から 1 に変更する」というログが記録されています。そのため、後で binlog を使用して復元すると、トランザクションが 1 つ増えてしまい、復元された行の c の値は 1 となり、元のデータベースの値とは異なります。 「2 フェーズ コミット」が使用されていない場合、データベースの状態が、ログを使用して復元されたライブラリの状態と一致しない可能性があることがわかります。 簡単に言えば、REDO ログと binlog の両方を使用してトランザクションのコミット ステータスを表すことができ、2 フェーズ コミットは 2 つの状態の論理的な一貫性を保つことです。 Undo ログには、ロールバックとマルチバージョン制御 (MVCC) の提供という 2 つの機能があります データが変更されると、REDO だけでなく、対応する UNDO も記録されます。UNDO ログには主にデータのロジックが記録されます。変更点として、エラー発生時に以前の操作をロールバックするには、以前の操作をすべて記録し、エラー発生時にロールバックする必要があります。 アンドゥ ログは、データベースを論理的に元の状態に復元するだけです。ロールバック中は、実際には逆の作業が行われます。たとえば、INSERT は DELETE に対応し、各 UPDATE は逆の UPDATE に対応します。変更前の行に戻ります。 UNDO ログは、トランザクションのアトミック性を確保するためにトランザクションのロールバック操作に使用されます。 原子性を実現する鍵は、トランザクションがロールバックされたときに、正常に実行されたすべての SQL ステートメントを元に戻せることです。 InnoDB は、UNDO ログに依存してロールバックを実装します。トランザクションがデータベースを変更すると、InnoDB は対応する UNDO ログを生成します。トランザクションの実行が失敗するかロールバックが呼び出され、トランザクションがロールバックされると、UNDO ログ内の情報がデータは変更前の状態にロールバックされます。 InnoDB ストレージ エンジンでは、undo ログは次のように分割されます。 insert undo log update undo log insert undo log は挿入操作を指します。元に戻すログが生成されるのは、挿入操作の記録がトランザクション自体にのみ表示され、他のトランザクションには表示されないためです。したがって、UNDO ログはトランザクションの送信後に直接削除でき、パージ操作は必要ありません。 更新取り消しログには、削除および更新操作によって生成された取り消しログが記録されます。取り消しログには MVCC メカニズムを提供する必要がある場合があるため、トランザクションのコミット時に削除することはできません。送信するときは、それを元に戻すログ リストに入れて、パージ スレッドが最終的な削除を実行するまで待ちます。 補足: パージ スレッドの 2 つの主な機能は、元に戻すページのクリーンアップと、ページ内の Delete_Bit 識別子を持つデータ行のクリアです。 InnoDB では、トランザクションの Delete オペレーションは実際にはデータ行を削除しませんが、レコードを削除せずにレコードの Delete_Bit をマークする Delete Mark オペレーションです。これはマークが付けられただけの一種の「偽の削除」であり、実際の削除作業はバックグラウンドのパージ スレッドによって完了する必要があります。 Innodb はインデックス データ構造として B ツリーを使用し、主キーが配置されるインデックスは ClusterIndex (クラスター化インデックス) であり、対応するデータ コンテンツは ClusterIndex のリーフ ノードに格納されます。テーブルには主キーを 1 つだけ持つことができるため、クラスタ化インデックスも 1 つだけ作成できます。テーブルに主キーが定義されていない場合は、最初の NULL 以外の一意のインデックスがクラスタ化インデックスとして選択されます。クラスタ化インデックスが存在しない場合は、非表示のインデックスが作成されます。 id 列はクラスター化インデックスとして生成されます。 クラスターインデックス以外のインデックスはセカンダリインデックス(補助インデックス)です。補助インデックスのリーフ ノードには、クラスター化インデックスのリーフ ノードの値が格納されます。 先ほど述べた rowid に加えて、InnoDB 行レコードには trx_id と db_roll_ptr も含まれます。trx_id は最近変更されたトランザクションの ID を表し、db_roll_ptr は undo セグメント内の undo ログを指します。 トランザクション ID は、新しいトランザクションが追加されると増加します。trx_id は、トランザクションが開始される順序を示すことができます。 アンドゥ ログは挿入と更新の 2 種類に分かれており、削除はレコード上の削除マークを変更する特別な更新とみなすことができます。 更新取り消しログには以前のデータ情報が記録されており、これを通じて以前のバージョンの状態を復元できます。 挿入操作を実行する場合、生成された挿入取り消しログはトランザクションのコミット後に削除できます。これは、他のトランザクションがこの取り消しログを必要としないためです。 操作を削除および変更すると、対応する元に戻すログが生成され、現在のデータ レコード内の db_roll_ptr は新しい元に戻すログを指します MVCC (MultiVersion Concurrency Control) は、マルチバージョン同時実行制御と呼ばれます。 InnoDB の MVCC は、レコードの各行の背後に 2 つの非表示列を保存することによって実装されます。これら 2 つの列のうち、1 つは行の作成時刻を保存し、もう 1 つは行の有効期限を保存します。もちろん、保存されるのは実際の時間値ではなく、システムのバージョン番号です。 主な実装アイデアは、複数のバージョンのデータの読み取りと書き込みを分離することです。これにより、ロックフリーの読み取りと並列読み取りと書き込みが可能になります。 mysql での MVCC の実装は、undo ログと読み取りビューに依存します MVCC の実装時に InnoDB によって使用される一貫した読み取りビュー、つまり一貫した読み取りビューは、RC をサポートするために使用されます。 (Read Committed 、読み取りコミット) および RR (Repeatable Read、反復可能読み取り) 分離レベルの実装。 #InnoDB の各トランザクションには、トランザクション ID と呼ばれる一意のトランザクション ID があります。これはトランザクションの開始時に InnoDB トランザクション システムに適用され、適用の順序で厳密に増分されます。 データの各行にも複数のバージョンがあります。トランザクションがデータを更新するたびに、新しいデータ バージョンが生成され、トランザクション ID がこのデータ バージョンの行 trx_id に割り当てられます。同時に、古いデータバージョンを保持する必要があり、新しいデータバージョンでは直接取得できる情報が存在する可能性があります。 データ テーブル内のレコードの行には、実際には複数のバージョン (行) が含まれる場合があり、各バージョンには独自の行 trx_id があります。複数のトランザクションによってレコードが更新され続けた後の状態です。 ステートメントの更新により、元に戻すログ (ロールバック ログ) が生成されますか?では、元に戻すログはどこにあるのでしょうか? 実際には、図 2 の 3 つの点線の矢印はアンドゥ ログです。V1、V2、および V3 は物理的に存在しませんが、現在のバージョンとアンドゥ ログに基づいて必要になるたびに計算されます。たとえば、V2 が必要な場合は、U3、U2 から V4 までを順番に実行することで計算されます。 Repeatable Read の定義によれば、トランザクションが開始されると、送信されたすべてのトランザクション結果が表示されます。ただし、このトランザクションの実行中は、他のトランザクションからの更新は認識されません。したがって、トランザクションは開始時に宣言するだけで済みます。「トランザクションを開始した瞬間に基づいて、開始前にデータ バージョンが生成されていれば認識されますが、開始後にデータ バージョンが生成されていれば認識されません」認識します。」、以前のバージョンを見つける必要があります。もちろん、「前のバージョン」も表示されない場合は、前を向き続ける必要があります。また、データがトランザクション自体によって更新された場合でも、それを認識する必要があります。 これら 2 つのロックは次のように呼ばれます: (共有ロック) は、「読み取りロック」とも呼ばれ、読み取りロックを共有したり、複数の読み取り要求がロックを共有してブロックを引き起こすことなくデータを読み取ることができます。 (排他的ロック)、「書き込みロック」とも呼ばれます。書き込みロックは、ロックを取得する他のすべてのリクエストを除外し、書き込みが完了してロックが解除されるまでブロックします。解放されました。 概要: 読み取り/書き込みロックにより、読み取りと読み取りは並行して実行できますが、書き込みと読み取り、書き込みと書き込みは並行して実行できます。分離は読み取り/書き込みロックによって実現されます。 ! ! 推奨学習: mysql ビデオ チュートリアル
3. Undo ログは原子性を実現します
4. MVCC は分離を実装します
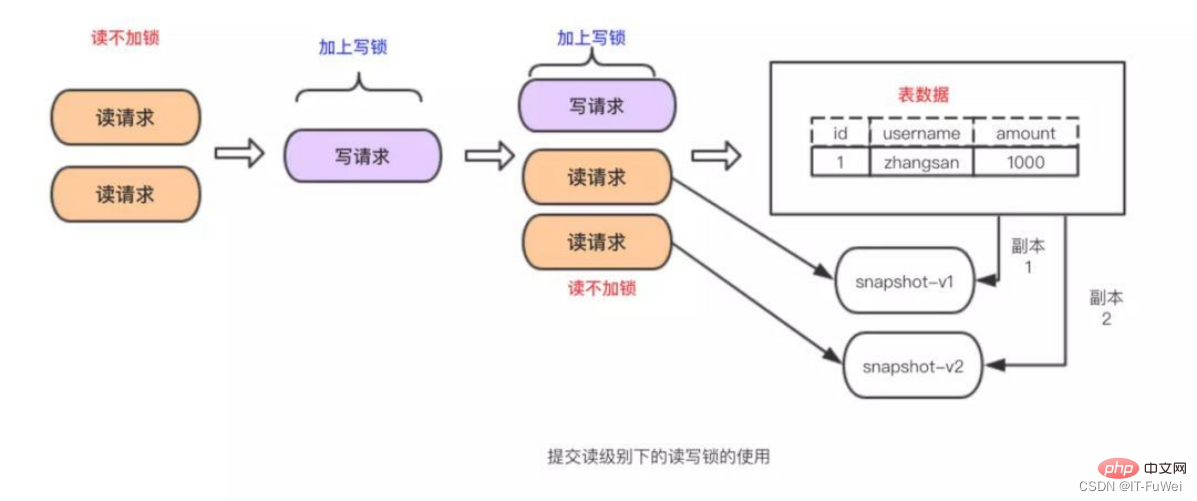

テーブル内のデータを読み取る複数のリクエストがある場合、アクションは実行できませんが、複数のリクエストの間に読み取りリクエストが存在します。変更リクエストがある場合には、同時実行性を制御する手段が必要です。そうしないと、不整合が発生する可能性があります。読み取り/書き込みロックで上記の問題を解決するのは非常に簡単です。読み取りリクエストと書き込みリクエストを制御するには、2 つのロックを組み合わせて使用するだけです。
以上がMySQL トランザクション ワークフローの原則を一緒に分析しましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7555
7555
 15
1384
52
83
11
28
96
15
1384
52
83
11
28
96

 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 SQLデータベースの構築方法
Apr 09, 2025 pm 04:24 PM
SQLデータベースの構築方法
Apr 09, 2025 pm 04:24 PM
SQLデータベースの構築には、DBMSの選択が必要です。 DBMSのインストール。データベースの作成。テーブルの作成;データの挿入;データの取得。データの更新。データの削除。ユーザーの管理。データベースのバックアップ。
