

Redis 永続性を完全にマスター: RDB と AOF

この記事では、Redis に関する関連知識を提供し、主に永続性が必要な理由、RDB 永続性、AOF 永続性など、永続性に関する関連問題を紹介します。皆さんのお役に立てば幸いです。

推奨学習: Redis ビデオ チュートリアル
1. 永続性が必要なのはなぜですか?
Redis のデータ操作はすべてメモリに基づいており、プロセスの終了やサーバーのダウンタイムなどの予期せぬ状況が発生した場合、永続化メカニズムがないと、Redis 内のデータが失われ、復元できなくなります。永続化メカニズムを使用すると、Redis は次回再起動するときに、以前に永続化されたファイルをデータ回復に使用できます。 Redis でサポートされる 2 つの永続化メカニズム:
RDB: 現在のデータのスナップショットを生成し、ハード ディスクに保存します。
AOF: データに対するすべての操作をハードディスクに記録します。
2. RDB 永続性
指定された時間内にメモリ上のデータセットのスナップショットをディスクに書き込み、リストアするとスナップショットファイルが保存されます。メモリ内で直接読み取ります。 RDB (Redis Database) の永続化とは、Redis 内のすべての現在のデータのスナップショットを生成し、ハードディスクに保存することです。 RDB 永続化は手動または自動でトリガーできます。
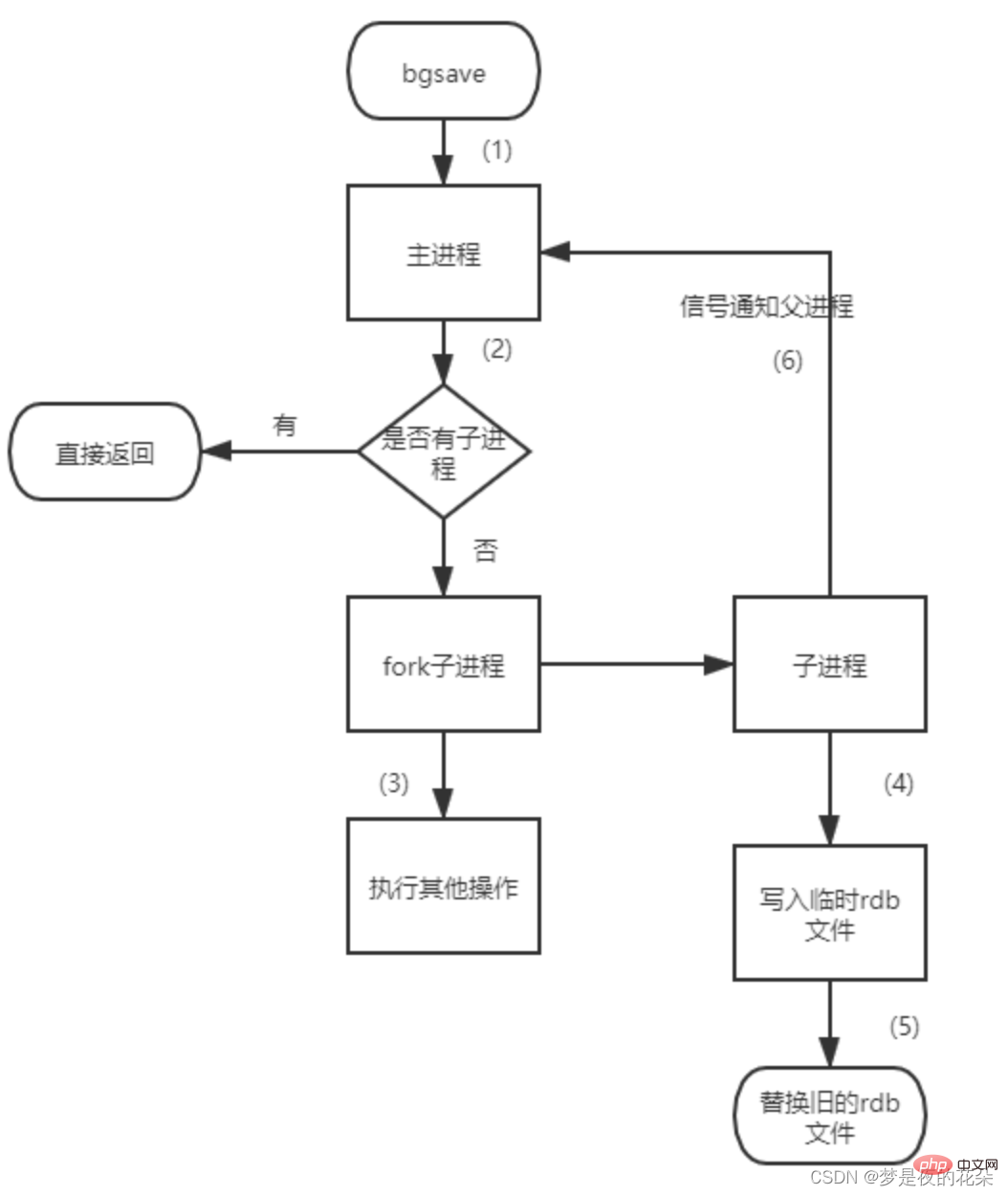
1.バックアップはどのように実行されますか?
Redis は永続化のために子プロセスを個別に作成 (フォーク) します。最初にデータを一時ファイルに書き込みます。永続化プロセスが完了した後、この一時ファイルは最後の永続性を置き換えるために使用されます。OKファイル。プロセス全体を通じて、メイン プロセスは IO 操作を実行しないため、非常に高いパフォーマンスが保証されます。大規模なデータ リカバリが必要で、データ リカバリの整合性がそれほど重要でない場合は、RDB 方式の方が AOF 方式よりも効率的です。 RDB の欠点は、最後に保存されたデータが失われる可能性があることです。
2. RDB 永続化プロセス
3. 手動トリガー
save 両方bgsave コマンドは、RDB 永続性を手動でトリガーできます。
-
save
saveコマンドを実行すると、RDB 永続化が手動でトリガーされますが、saveコマンドは、RDB の永続化が完了するまで Redis サービスをブロックします。 Redis サービスが大量のデータを保存すると、長期的な輻輳が発生するため、お勧めできません。 -
bgsave
bgsaveコマンドを実行すると、RDB 永続化も手動でトリガーされます。これは、save## とは異なります。 # command. : Redis サービスは通常、ブロックしません。 Redis プロセスはフォーク操作を実行して子プロセスを作成します。子プロセスは RDB の永続化を担当し、Redis サービス プロセスをブロックしません。 Redis サービスのブロックはフォーク フェーズでのみ発生し、一般に時間は非常に短いです。
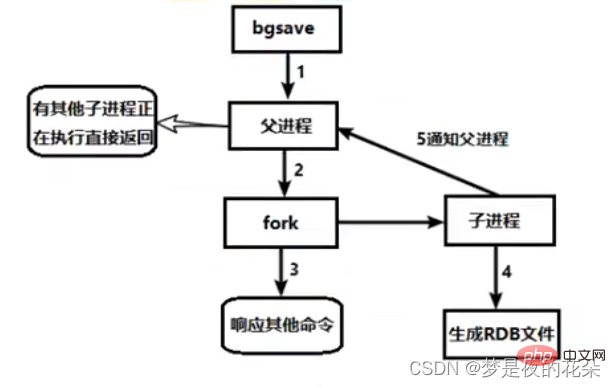
bgsaveコマンドの具体的な処理は次のとおりです: 1.
1.
bgsaveコマンドを実行します。プロセスはまず、現在実行中の RDB または AOF サブスレッドがあるかどうかを判断し、存在する場合は直接終了します。2. Redis プロセスは子スレッドを作成するためにフォーク操作を実行しますが、Redis プロセスはフォーク操作中にブロックされます。
3. Redis プロセスのフォークが完了すると、
bgsaveコマンドが終了し、それ以降、Redis プロセスはブロックされず、他のコマンドに応答できるようになります。4. 子プロセスは、Redis プロセスのメモリに基づいてスナップショット ファイルを生成し、元の RDB ファイルを置き換えます。
5. 同時に、rdb 永続化が完了したことをメインプロセスに通知するシグナルが送信され、メインプロセスは関連する統計情報 (info Persistence の rdb_* 関連オプション) を更新します。
 1.
1. bgsave を使用して Redis プロセスのブロックを軽減します。では、どのような状況で自動的に発動するのでしょうか?
- save
の関連構成は、sava m nなどの構成ファイルに設定されます。これは、データが m 以内に n 回変更されると、秒、bgsave操作を自動的にトリガーします。スレーブ ノードがフル レプリケーションを実行すると、マスター ノードは自動的に - bgsave
操作を実行し、生成された RDB ファイルをスレーブ ノードに送信します。 - debug reload
コマンドを実行すると、bgsave操作も自動的にトリガーされます。 - shutdown
コマンドを実行するときに、AOF 永続化が有効になっていない場合、bgsave操作が自動的にトリガーされます。
6. RDB の欠点
bgsave を実行するたびに、子を作成するためにフォーク操作を実行する必要があります。これは重量のある操作です。頻繁に実行するとコストがかかりすぎます。高いため、リアルタイム永続化、つまり第 2 レベルの永続性を実現できません。
さらに、Redis のバージョンが継続的に繰り返されるため、異なる形式の RDB バージョンが存在し、下位バージョンの RDB 形式が上位バージョンの RDB ファイルと互換性がないという問題が発生する可能性があります。
7. dump.rdb で RDB を構成します
スナップショット期間 : メモリ スナップショットは技術者が手動で実行できますが、SAVE または BGSAVE コマンドですが、ほとんどの実稼働環境では、定期的な実行条件が設定されます。
- Redis の新しいデフォルトのサイクル設定
# 周期性执行条件的设置格式为 save <seconds> <changes> # 默认的设置为: save 900 1 save 300 10 save 60 10000 # 以下设置方式为关闭RDB快照功能 save ""</changes></seconds>
上記の 3 つのデフォルト情報設定の意味は次のとおりです:
- 如果900秒内有1条Key信息发生变化,则进行快照;
- 如果300秒内有10条Key信息发生变化,则进行快照;
- 如果60秒内有10000条Key信息发生变化,则进行快照。读者可以按照这个规则,根据自己的实际请求压力进行设置调整。
- 其它相关配置
# 文件名称 dbfilename dump.rdb # 文件保存路径 dir ./ # 如果持久化出错,主进程是否停止写入 stop-writes-on-bgsave-error yes # 是否压缩 rdbcompression yes # 导入时是否检查 rdbchecksum yes
- dbfilename:RDB文件在磁盘上的名称。
- dir:RDB文件的存储路径。默认设置为“./”,也就是Redis服务的主目录。
- stop-writes-on-bgsave-error:上文提到的在快照进行过程中,主进程照样可以接受客户端的任何写操作的特性,是指在快照操作正常的情况下。如果快照操作出现异常(例如操作系统用户权限不够、磁盘空间写满等等)时,Redis就会禁止写操作。这个特性的主要目的是使运维人员在第一时间就发现Redis的运行错误,并进行解决。一些特定的场景下,您可能需要对这个特性进行配置,这时就可以调整这个参数项。该参数项默认情况下值为yes,如果要关闭这个特性,指定即使出现快照错误Redis一样允许写操作,则可以将该值更改为no。
- rdbcompression:该属性将在字符串类型的数据被快照到磁盘文件时,启用LZF压缩算法。Redis官方的建议是请保持该选项设置为yes,因为“it’s almost always a win”。
- rdbchecksum:从RDB快照功能的version 5 版本开始,一个64位的CRC冗余校验编码会被放置在RDB文件的末尾,以便对整个RDB文件的完整性进行验证。这个功能大概会多损失10%左右的性能,但获得了更高的数据可靠性。所以如果您的Redis服务需要追求极致的性能,就可以将这个选项设置为no。
8、 RDB 更深入理解
-
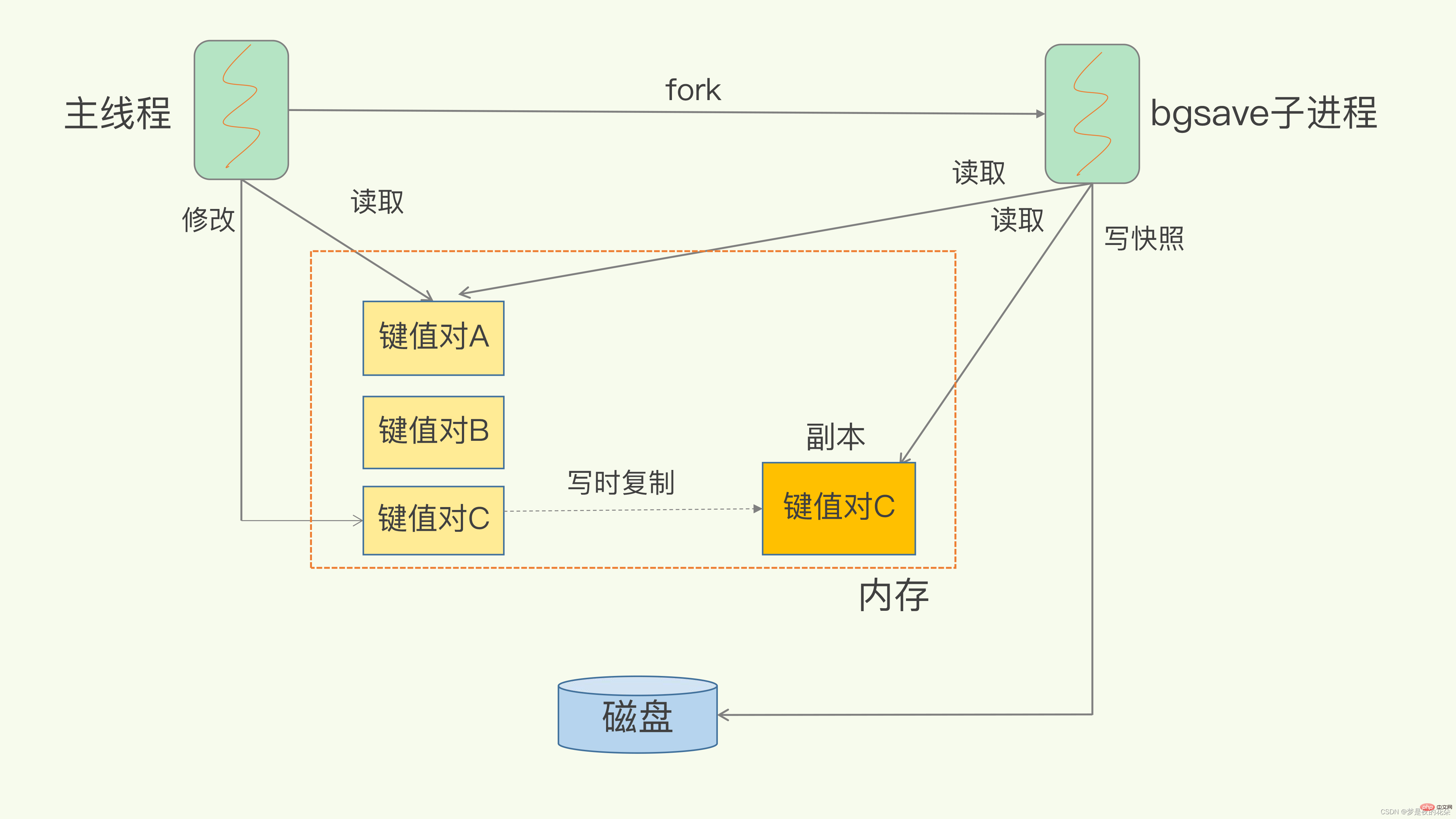
由于生产环境中我们为Redis开辟的内存区域都比较大(例如6GB),那么将内存中的数据同步到硬盘的过程可能就会持续比较长的时间,而实际情况是这段时间Redis服务一般都会收到数据写操作请求。那么如何保证数据一致性呢?
RDB中的核心思路是Copy-on-Write,来保证在进行快照操作的这段时间,需要压缩写入磁盘上的数据在内存中不会发生变化。在正常的快照操作中,一方面Redis主进程会fork一个新的快照进程专门来做这个事情,这样保证了Redis服务不会停止对客户端包括写请求在内的任何响应。另一方面这段时间发生的数据变化会以副本的方式存放在另一个新的内存区域,待快照操作结束后才会同步到原来的内存区域。
举个例子:如果主线程对这些数据也都是读操作(例如图中的键值对 A),那么,主线程和bgsave子进程相互不影响。但是,如果主线程要修改一块数据(例如图中的键值对 C),那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
-
在进行快照操作的这段时间,如果发生服务崩溃怎么办?
很简单,在没有将数据全部写入到磁盘前,这次快照操作都不算成功。如果出现了服务崩溃的情况,将以上一次完整的RDB快照文件作为恢复内存数据的参考。也就是说,在快照操作过程中不能影响上一次的备份数据。Redis服务会在磁盘上创建一个临时文件进行数据操作,待操作成功后才会用这个临时文件替换掉上一次的备份。 -
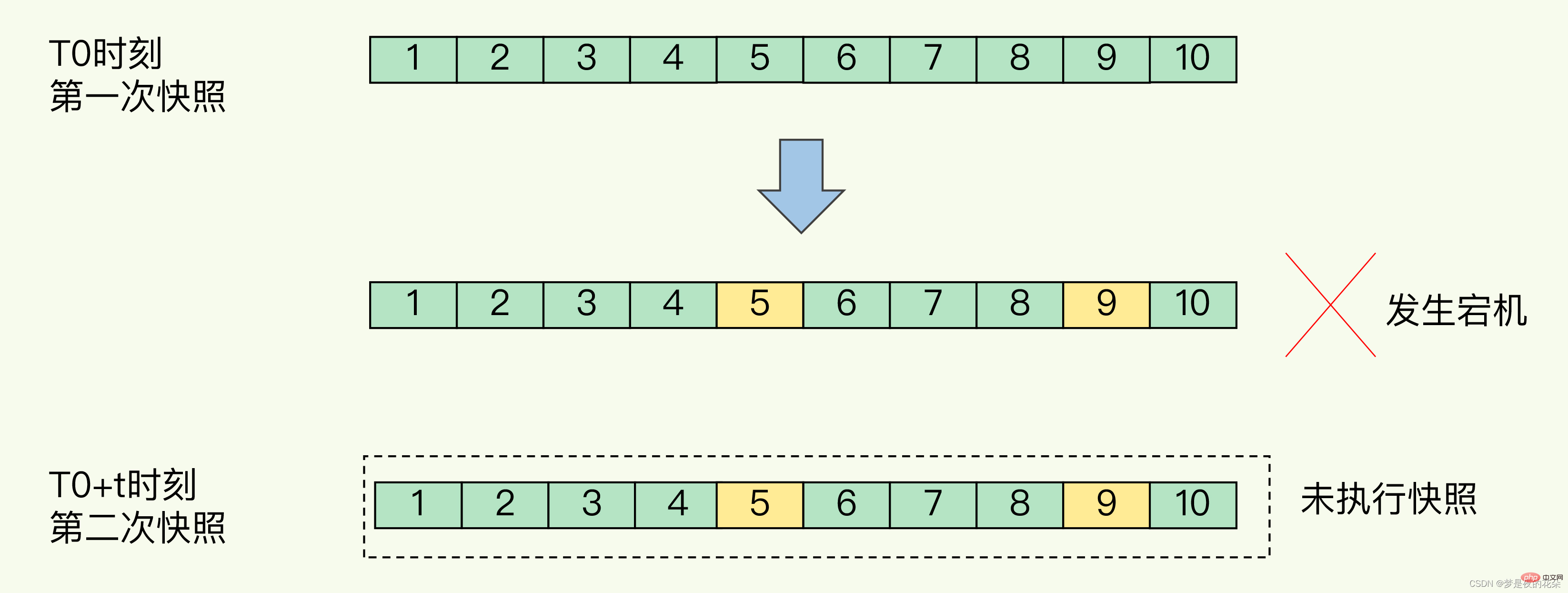
可以每秒做一次快照吗?
对于快照来说,所谓“连拍”就是指连续地做快照。这样一来,快照的间隔时间变得很短,即使某一时刻发生宕机了,因为上一时刻快照刚执行,丢失的数据也不会太多。但是,这其中的快照间隔时间就很关键了。
如下图所示,我们先在 T0 时刻做了一次快照,然后又在 T0+t 时刻做了一次快照,在这期间,数据块 5 和 9 被修改了。如果在 t 这段时间内,机器宕机了,那么,只能按照 T0 时刻的快照进行恢复。此时,数据块 5 和 9 的修改值因为没有快照记录,就无法恢复了。
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决
三、AOF持久化
AOF(Append Only File)持久化是把每次写命令追加写入日志中,当需要恢复数据时重新执行AOF文件中的命令就可以了。AOF解决了数据持久化的实时性,也是目前主流的Redis持久化方式。
Redis是“写后”日志,Redis先执行命令,把数据写入内存,然后才记录日志。日志里记录的是Redis收到的每一条命令,这些命令是以文本形式保存。PS: 大多数的数据库采用的是写前日志(WAL),例如MySQL,通过写前日志和两阶段提交,实现数据和逻辑的一致性。
而AOF日志采用写后日志,即先写内存,后写日志。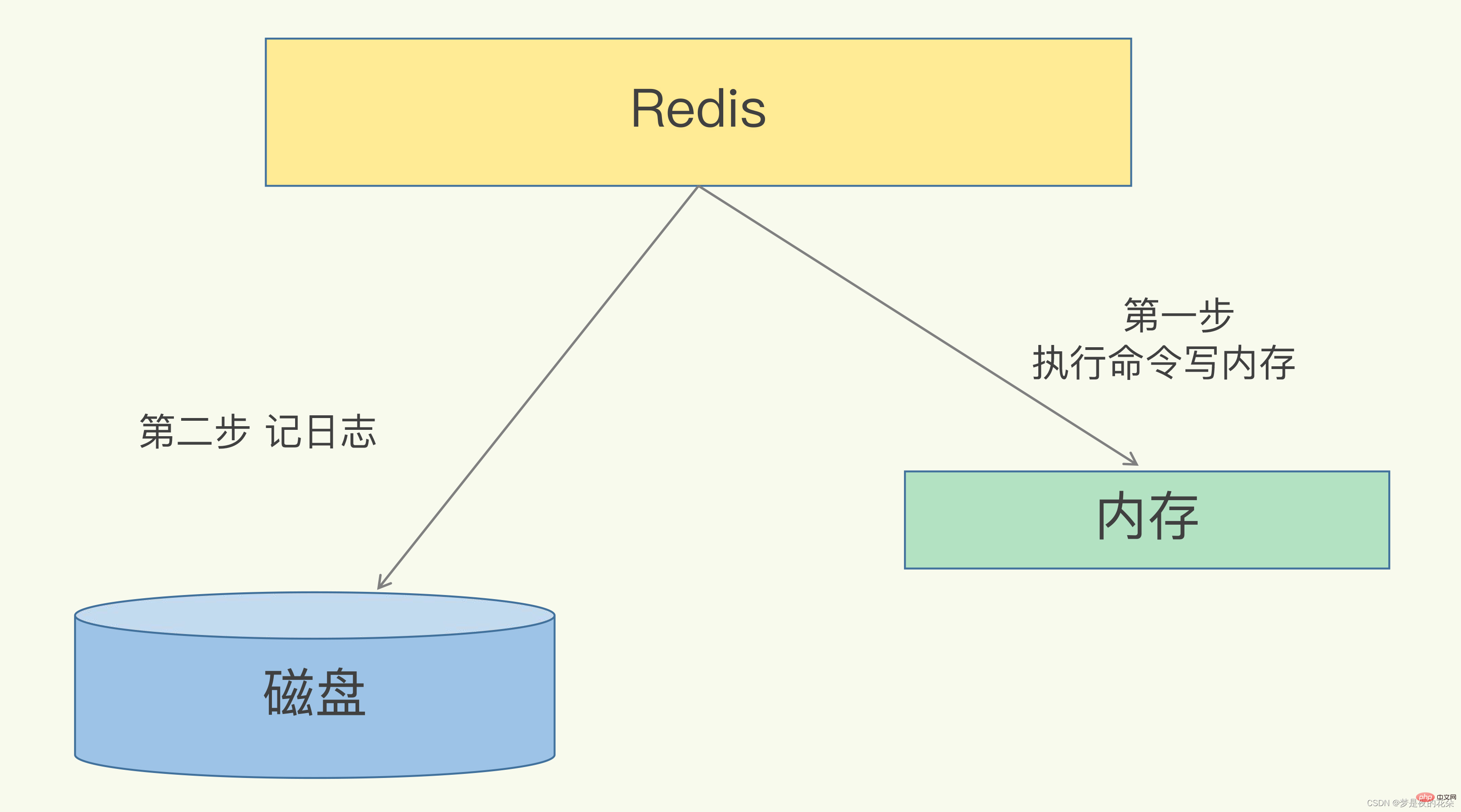
为什么采用写后日志?
Redis要求高性能,采用写日志有两方面好处:
- 避免额外的检查开销:Redis 在向 AOF 里面记录日志的时候,并不会先去对这些命令进行语法检查。所以,如果先记日志再执行命令的话,日志中就有可能记录了错误的命令,Redis 在使用日志恢复数据时,就可能会出错。
- 不会阻塞当前的写操作
但这种方式存在潜在风险:
- 如果命令执行完成,写日志之前宕机了,会丢失数据。
- 主线程写磁盘压力大,导致写盘慢,阻塞后续操作。
1、如何实现AOF?
AOF日志记录Redis的每个写命令,步骤分为:命令追加(append)、文件写入(write)和文件同步(sync)。
- 命令追加 当AOF持久化功能打开了,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器的 aof_buf 缓冲区。
-
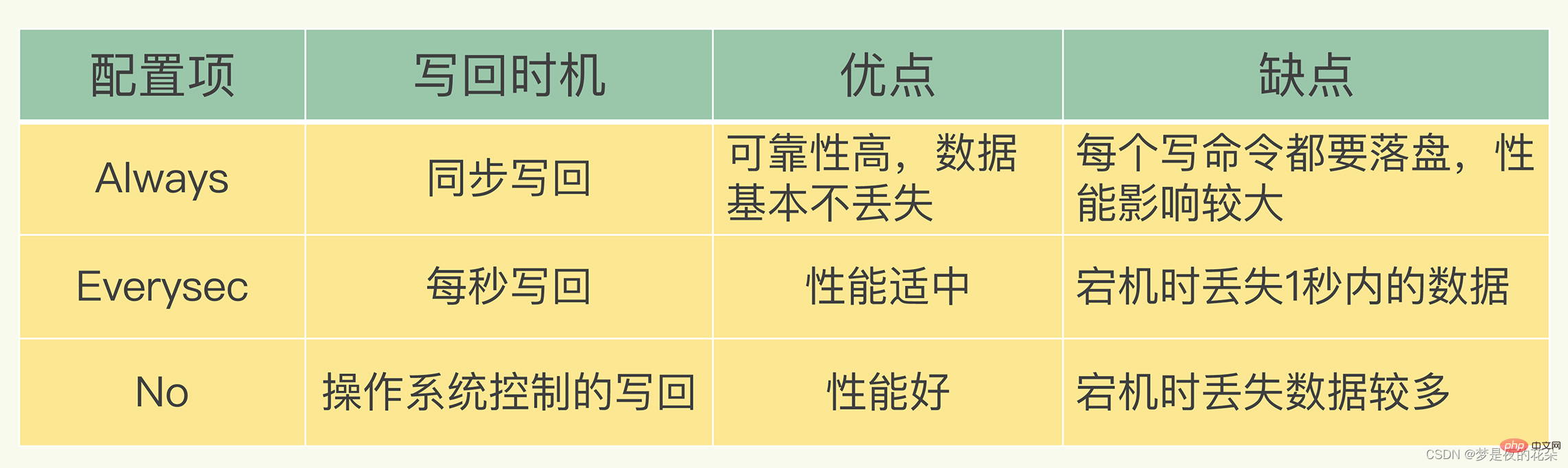
文件写入和同步 关于何时将 aof_buf 缓冲区的内容写入AOF文件中,Redis提供了三种写回策略:
- Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
- Everysec,每秒写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
- No,操作系统控制的写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
2、redis.conf中配置AOF
默认情况下,Redis是没有开启AOF的,可以通过配置redis.conf文件来开启AOF持久化,关于AOF的配置如下:
# appendonly参数开启AOF持久化 appendonly no # AOF持久化的文件名,默认是appendonly.aof appendfilename "appendonly.aof" # AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的 dir ./ # 同步策略 # appendfsync always appendfsync everysec # appendfsync no # aof重写期间是否同步 no-appendfsync-on-rewrite no # 重写触发配置 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb # 加载aof出错如何处理 aof-load-truncated yes # 文件重写策略 aof-rewrite-incremental-fsync yes
以下是Redis中关于AOF的主要配置信息:
appendfsync:这个参数项是AOF功能最重要的设置项之一,主要用于设置“真正执行”操作命令向AOF文件中同步的策略。
什么叫“真正执行”呢?还记得Linux操作系统对磁盘设备的操作方式吗? 为了保证操作系统中I/O队列的操作效率,应用程序提交的I/O操作请求一般是被放置在linux Page Cache中的,然后再由Linux操作系统中的策略自行决定正在写到磁盘上的时机。而Redis中有一个fsync()函数,可以将Page Cache中待写的数据真正写入到物理设备上,而缺点是频繁调用这个fsync()函数干预操作系统的既定策略,可能导致I/O卡顿的现象频繁 。
与上节对应,appendfsync参数项可以设置三个值,分别是:always、everysec、no,默认的值为everysec。
no-appendfsync-on-rewrite:always和everysec的设置会使真正的I/O操作高频度的出现,甚至会出现长时间的卡顿情况,这个问题出现在操作系统层面上,所有靠工作在操作系统之上的Redis是没法解决的。为了尽量缓解这个情况,Redis提供了这个设置项,保证在完成fsync函数调用时,不会将这段时间内发生的命令操作放入操作系统的Page Cache(这段时间Redis还在接受客户端的各种写操作命令)。
auto-aof-rewrite-percentage: 前述したように、運用環境では、技術者が「BGREWRITEAOF」コマンドを使用することはできません。いつでもどこでも AOF ファイルを書き換えます。そのため、Redis の AOF ファイルの自動書き換え戦略に依存する必要が多くなります。 Redis には、AOF ファイルの自動書き換えをトリガーするための 2 つの設定が用意されています。
auto-aof-rewrite-percentage 現在の AOF ファイルのサイズが特定の書き換え後の最後のサイズを超えるかどうかを意味します。 AOF ファイルのパーセンテージに達したら、AOF ファイルの書き換えを再度開始します。たとえば、このパラメータ値のデフォルト設定値は 100 です。これは、AOF ファイルのサイズが最後の AOF ファイル書き換えサイズの 1 倍を超えた場合に、書き換え操作が開始されることを意味します。
auto-aof-rewrite-min-size: 設定項目は、AOF ファイルの書き換え操作を開始する AOF ファイルの最小サイズを示します。 AOF ファイルのサイズがこの値より小さい場合、再書き込み操作はトリガーされません。 auto-aof-rewrite-percentage と auto-aof-rewrite-min-size は、Redis での AOF ファイルの自動再書き込みを制御するためにのみ使用されることに注意してください。技術者が手動で「BGREWRITEAOF」コマンドを呼び出した場合、コマンドは無効になります。これら 2 つの制限が適用されます。
3. AOF 書き換えについての深い理解
AOF は、各書き込みコマンドを AOF ファイルに記録します。時間の経過とともに、AOF ファイルはますます大きくなります。制御しないと、Redis サーバーやオペレーティング システムにさえ影響を及ぼし、さらに、AOF ファイルが大きくなるほど、データの回復が遅くなります。 AOF ファイル サイズの拡大の問題を解決するために、Redis は AOF ファイルを「スリム化」するための AOF ファイル書き換えメカニズムを提供します。
AOF 書き換えを説明する図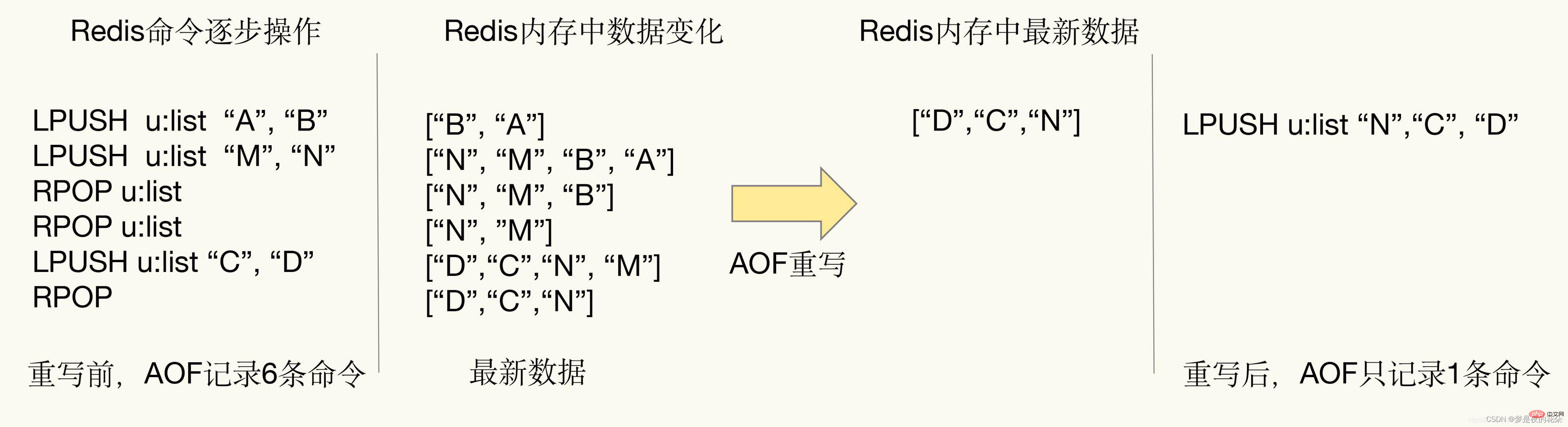
AOF 書き換えはブロックされますか?
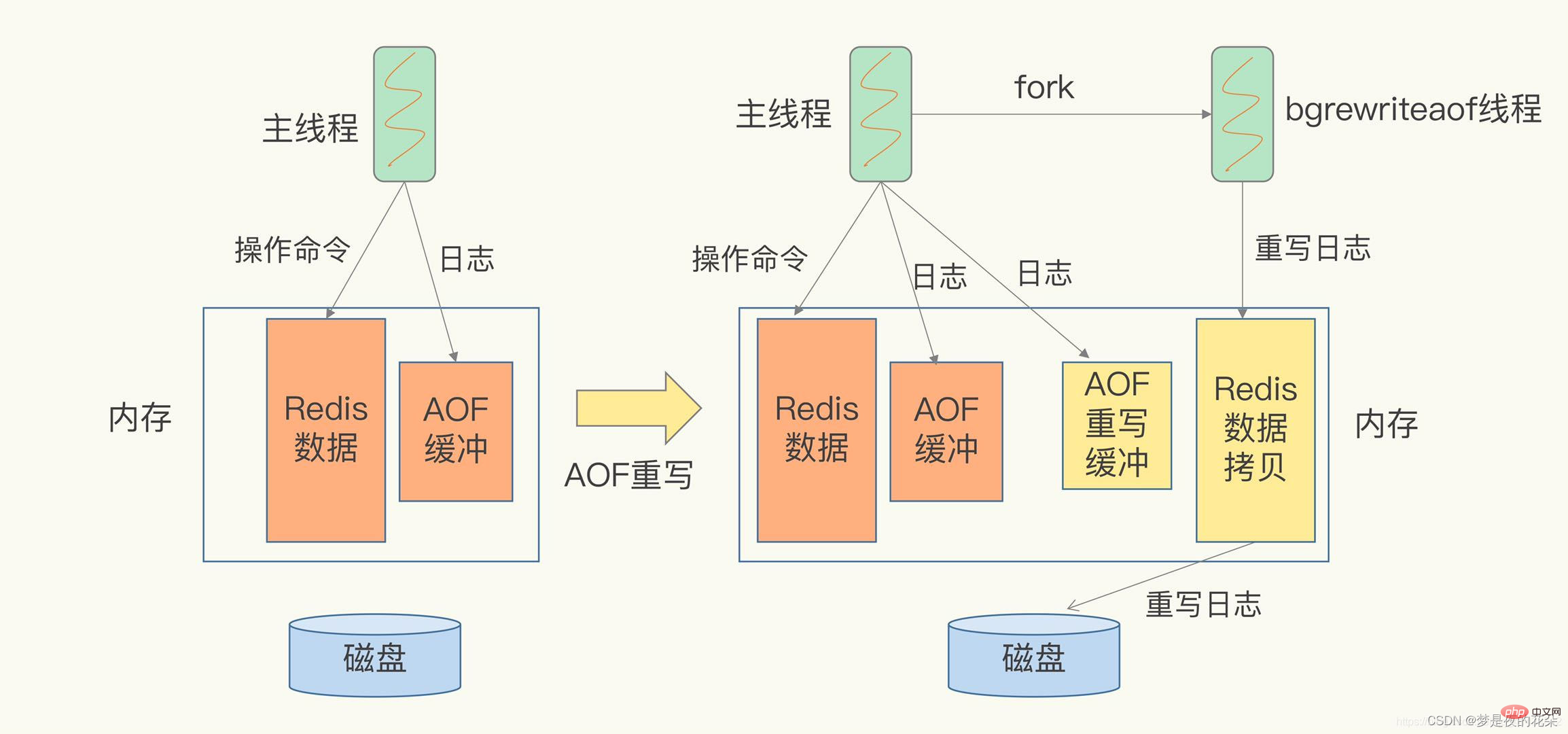
AOF 書き換えプロセスは、バックグラウンド プロセス bgrewriteaof によって完了します。メイン スレッドはバックグラウンドで bgrewriteaof 子プロセスからフォークし、データベースの最新データを含むメイン スレッドのメモリを bgrewriteaof 子プロセスにコピーします。次に、bgrewriteaof サブプロセスは、メインスレッドに影響を与えることなく、コピーされたデータを 1 つずつオペレーションに書き込み、書き換えログに記録できます。したがって、aof が書き換えられると、プロセスをフォークするときにメインスレッドがブロックされてしまいます。
AOF ログはいつ書き換えられますか?
AOF リライトのトリガーを制御する構成項目は 2 つあります:
auto-aof-rewrite-min-size: 実行時のファイルの最小サイズを示します。 AOF 書き換え、デフォルトは 64MB です。
auto-aof-rewrite-percentage: この値は、現在の aof ファイル サイズと最後の書き換え後の aof ファイル サイズの差を、前回の書き換え後の aof ファイル サイズで割ることによって計算されます。書き換えるサイズを変更します。つまり、最後に書き換えられた AOF ファイルと比較した現在の AOF ファイルの増分サイズ、および最後の書き換え後の AOF ファイル サイズの比率です。
ログを書き換える際に新しいデータが書き込まれた場合はどうすればよいですか?
書き換えプロセスは、「1 つのコピー、2 つのログ」のように要約できます。子プロセスからフォークアウトするとき、および再書き込みするとき、新しいデータが書き込まれると、メインスレッドはコマンドを 2 つのログ メモリ バッファに記録します。 AOF ライトバック ポリシーが常に設定されている場合、コマンドは古いログ ファイルに直接書き戻され、コマンドのコピーが AOF 書き換えバッファに保存されます。これらの操作は新しいログ ファイルには影響しません。 (古いログ ファイル: メイン スレッドで使用されるログ ファイル、新しいログ ファイル: bgrewriteaof プロセスで使用されるログ ファイル)
bgrewriteaof 子プロセスがログ ファイルの書き換え操作を完了すると、プロンプトが表示されます。書き換え操作が完了すると、メインスレッドは AOF 書き換えバッファ内のコマンドを新しいログ ファイルの末尾に追加します。現時点では、高い同時実行条件下では、AOF 書き換えバッファーの蓄積が非常に大きくなり、ブロッキングが発生する可能性があります。Redis は後に Linux パイプライン テクノロジを使用して、AOF 書き換え中の同時再生を可能にしました。残りわずかなデータを再生する必要があります。最後に、ファイル名を変更することで、ファイル切り替えのアトミック性が確保されます。
AOF ログの書き換え中にダウンタイムが発生した場合、ログ ファイルが切り替えられていないため、データのリストア時に古いログ ファイルが引き続き使用されます。
概要操作:
- メインスレッドは子プロセスをフォークアウトし、aof ログを書き換えます
- 子プロセスの書き換え ログの完了後、メイン スレッドは aof ログ バッファを追加します
- ログ ファイルを置き換えます
注意喚起
ここでのプロセスとスレッド この概念は少しわかりにくいです。バックグラウンドの bgreweiteaof プロセスでは動作するスレッドが 1 つだけであり、メイン スレッドは Redis 動作プロセスであり、これも単一スレッドであるためです。ここで言いたいのは、Redis メイン プロセスがバックグラウンド プロセスをフォークした後は、バックグラウンド プロセスの操作はメイン プロセスと何の関係もなく、メイン スレッドをブロックしないということです。
#メインスレッドはどのようにして子プロセスをフォークアウトし、メモリデータをコピーするのでしょうか?
Fork は、オペレーティング システムが提供するコピー オン ライト メカニズムを使用して、大量のメモリ データを一度にコピーして子プロセスをブロックすることを回避します。子プロセスをフォークするとき、子プロセスは親プロセスのページ テーブル、つまり仮想と実のマッピング関係 (仮想メモリと物理メモリ間のマッピング インデックス テーブル) をコピーしますが、物理メモリはコピーしません。このコピーは大量の CPU リソースを消費し、コピーが完了する前にメイン スレッドがブロックされます。ブロック時間はメモリ内のデータ量によって異なります。データ量が増えるほど、メモリ ページ テーブルも大きくなります。コピーが完了すると、親プロセスと子プロセスは同じメモリ アドレス空間を使用します。
ただし、メインプロセスはデータを書き込むことができ、このとき物理メモリ内のデータがコピーされます。以下に示すように (プロセス 1 をメインプロセス、プロセス 2 を子プロセスとみなします): 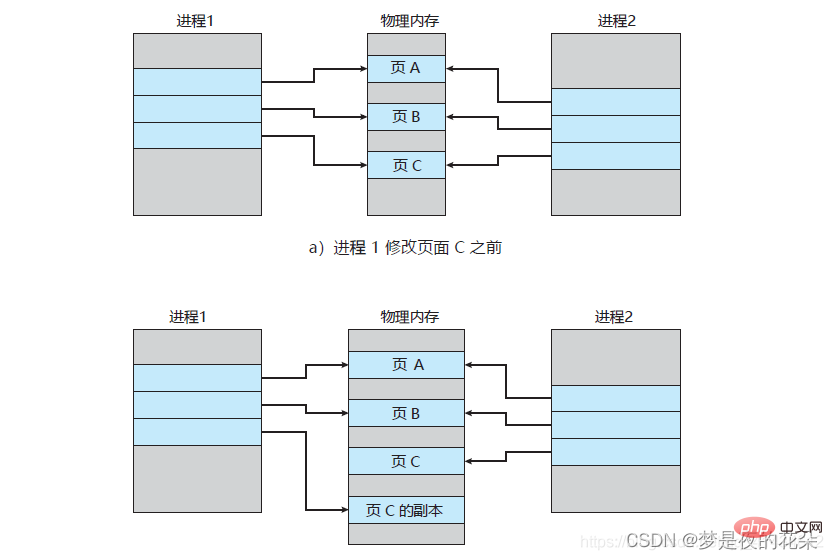
メインプロセスにデータが書き込まれており、そのデータがたまたまページ c にある場合、オペレーティング システムは、このページのコピー (ページ c のコピー) を作成します。つまり、現在のページの物理データをコピーしてメイン プロセスにマップしますが、子プロセスは引き続き元のページ c を使用します。
ログプロセス全体を書き換える場合、メインスレッドはどこでブロックされますか?
- 子プロセスをフォークするときは、仮想ページ テーブルをコピーする必要があります。これにより、メイン スレッドがブロックされます。
- メイン プロセスが bigkey を書き込むと、オペレーティング システムはページのコピーを作成し、元のデータをコピーします。これにより、メイン スレッドがブロックされます。
- サブプロセスの書き換えログが完了した後、メイン プロセスが aof 書き換えバッファーを追加すると、メイン スレッドがブロックされる可能性があります。
AOF 書き換えでは元の AOF ログが再利用されないのはなぜですか?
- 親プロセスと子プロセス間で同じファイルを書き込むと、競合の問題が発生し、親プロセスのパフォーマンスに影響します。
- AOF 書き換えプロセスが失敗した場合、それは元の AOF ファイルが汚染されたことと同じであり、リカバリ データとして使用することはできません。
3. RDB と AOF のハイブリッド方式 (バージョン 4.0)
Redis 4.0 では、AOF ログとメモリ スナップショットを混合して使用する方式が提案されています。簡単に言うと、メモリ スナップショットは特定の頻度で実行され、2 つのスナップショットの間に AOF ログを使用して、この期間中のすべてのコマンド操作が記録されます。
このようにすると、スナップショットを頻繁に実行する必要がなくなり、メインスレッドでの頻繁なフォークの影響が回避されます。また、AOFログは2つのスナップショット間の操作のみを記録するため、すべての操作を記録する必要がないため、ファイルサイズが大きくなりすぎず、書き換えのオーバーヘッドも回避できます。
次の図に示すように、T1 と T2 での変更は AOF ログに記録されます。2 番目の完全なスナップショットが取得されると、この時点でのすべての変更が記録されているため、AOF ログをクリアできます。スナップショットにある場合、ログはリカバリ中に使用されなくなります。 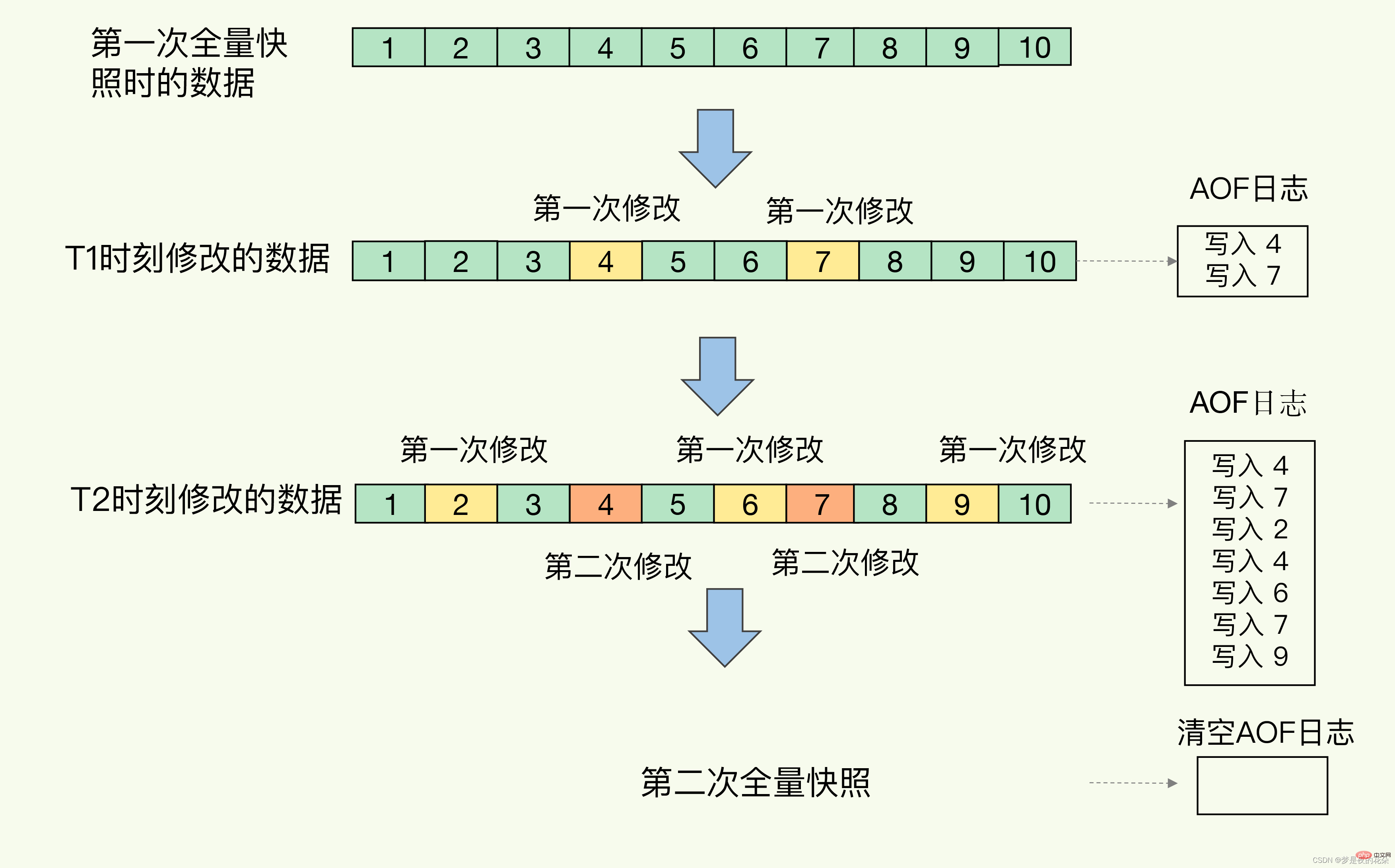
この方法は、RDB ファイルの高速復旧のメリットを享受できるだけでなく、操作コマンドを記録するだけの AOF というシンプルなメリットも享受できるため、実環境で広く使用されています。
4. 永続化からデータを復元する
データのバックアップと永続化が完了した後、これらの永続化ファイルからデータを復元するにはどうすればよいでしょうか?サーバー上に RDB ファイルと AOF ファイルの両方がある場合、どちらをロードする必要がありますか?
実際、これらのファイルからデータを回復したい場合は、Redis を再起動するだけで済みます。 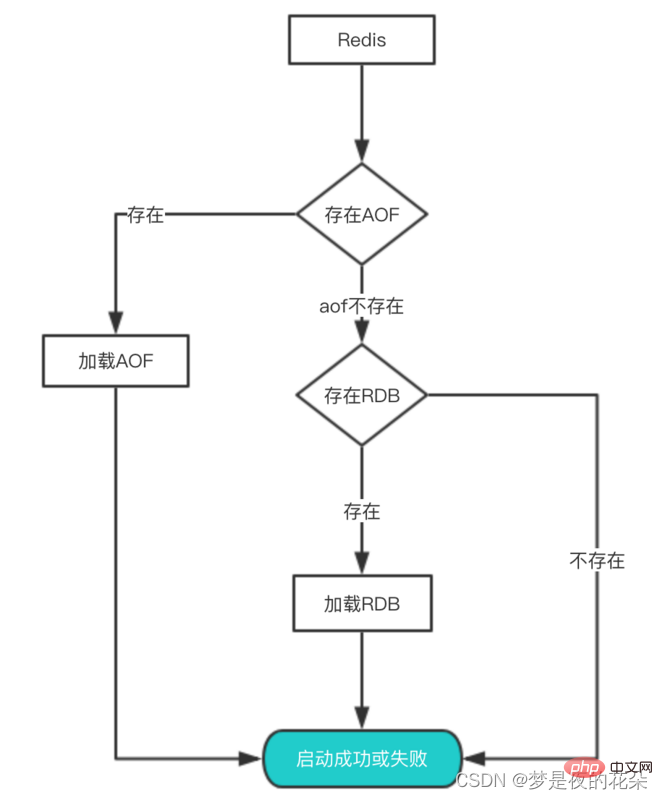
- ## Redis が再起動されると、aof を有効にするかどうかが決定されます。aof が有効な場合は、aof ファイルが最初にロードされます。
- aof が存在する場合は、aof ファイルをロードします。ロードが成功すると、redis が正常に再起動します。aof ファイルのロードに失敗した場合は、起動が失敗したことを示すログが出力されます。この時点で修復できます。 aof ファイルを作成して再起動します;
- If aof ファイルが存在しない場合、redis は代わりに rdb ファイルをロードします。rdb ファイルが存在しない場合、redis は直接正常に開始されます;
- If rdb ファイルが存在する場合、rdb ファイルをロードしてデータを復元します。ロードが失敗した場合、印刷ログに起動が失敗したことが示されます。ロードが成功した場合、redis は正常に再起動し、rdb ファイルを使用してデータを復元します。 ;
では、なぜ AOF が最初に読み込まれるのでしょうか? AOF によって保存されたデータはより完全であるため、上記の分析を通じて、AOF では基本的に最大 1 秒のデータが失われることがわかります。
推奨学習:以上がRedis 永続性を完全にマスター: RDB と AOFの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7316
7316
 9
1625
14
1349
46
1261
25
1208
29
9
1625
14
1349
46
1261
25
1208
29

 Windows 11 10.0.22000.100 のインストール時の 0x80242008 エラーの解決策
May 08, 2024 pm 03:50 PM
Windows 11 10.0.22000.100 のインストール時の 0x80242008 エラーの解決策
May 08, 2024 pm 03:50 PM
1. [スタート]メニューを起動し、[cmd]と入力し、[コマンドプロンプト]を右クリックし、[管理者として実行]を選択します。 2. 次のコマンドを順番に入力します (注意してコピーして貼り付けてください): SCconfigwuauservstart=auto、Enter キーを押す SCconfigbitsstart=auto、Enter キーを押す SCconfigcryptsvcstart=auto、Enter キーを押す SCconfigtrustedinstallerstart=auto、Enter キーを押す SCconfigwuauservtype=share、Enter キーを押す netstopwuauserv 、enter netstopcryptS を押す
 PHP機能のボトルネックを分析し、実行効率を向上
Apr 23, 2024 pm 03:42 PM
PHP機能のボトルネックを分析し、実行効率を向上
Apr 23, 2024 pm 03:42 PM
PHP 関数のボトルネックはパフォーマンスの低下につながります。これは、ボトルネック関数を特定し、パフォーマンス分析ツールを使用するという手順で解決できます。結果をキャッシュして再計算を減らします。タスクを並列処理して実行効率を向上させます。文字列の連結を最適化し、代わりに組み込み関数を使用します。カスタム関数の代わりに組み込み関数を使用します。
 Golang API のキャッシュ戦略と最適化
May 07, 2024 pm 02:12 PM
Golang API のキャッシュ戦略と最適化
May 07, 2024 pm 02:12 PM
GolangAPI のキャッシュ戦略により、パフォーマンスが向上し、サーバーの負荷が軽減されます。一般的に使用される戦略は、LRU、LFU、FIFO、TTL です。最適化手法には、適切なキャッシュ ストレージの選択、階層型キャッシュ、無効化管理、監視とチューニングが含まれます。実際には、データベースからユーザー情報を取得する API を最適化するために LRU キャッシュが使用されます。それ以外の場合は、データベースからデータを取得した後にキャッシュを更新できます。
 erlang と golang ではどちらのパフォーマンスが優れていますか?
Apr 21, 2024 am 03:24 AM
erlang と golang ではどちらのパフォーマンスが優れていますか?
Apr 21, 2024 am 03:24 AM
Erlang と Go にはパフォーマンスの違いがあります。 Erlang は同時実行性に優れていますが、Go はより高いスループットとより高速なネットワーク パフォーマンスを備えています。 Erlang は高い同時実行性を必要とするシステムに適しており、Go は高スループットと低遅延を必要とするシステムに適しています。
 PHP 開発におけるキャッシュ メカニズムとアプリケーションの実践
May 09, 2024 pm 01:30 PM
PHP 開発におけるキャッシュ メカニズムとアプリケーションの実践
May 09, 2024 pm 01:30 PM
PHP 開発では、キャッシュ メカニズムにより、頻繁にアクセスされるデータがメモリまたはディスクに一時的に保存され、データベース アクセスの数が削減され、パフォーマンスが向上します。キャッシュの種類には主にメモリ、ファイル、データベース キャッシュが含まれます。キャッシュは、組み込み関数またはサードパーティのライブラリ (cache_get() や Memcache など) を使用して PHP に実装できます。一般的な実用的なアプリケーションには、データベース クエリ結果をキャッシュしてクエリ パフォーマンスを最適化したり、ページ出力をキャッシュしてレンダリングを高速化したりすることが含まれます。キャッシュ メカニズムにより、Web サイトの応答速度が効果的に向上し、ユーザー エクスペリエンスが向上し、サーバーの負荷が軽減されます。
 PHP 配列のページネーションで Redis キャッシュを使用するにはどうすればよいですか?
May 01, 2024 am 10:48 AM
PHP 配列のページネーションで Redis キャッシュを使用するにはどうすればよいですか?
May 01, 2024 am 10:48 AM
Redis キャッシュを使用すると、PHP 配列ページングのパフォーマンスを大幅に最適化できます。これは、次の手順で実現できます。 Redis クライアントをインストールします。 Redisサーバーに接続します。キャッシュ データを作成し、データの各ページをキー「page:{page_number}」を持つ Redis ハッシュに保存します。キャッシュからデータを取得し、大規模な配列での高コストの操作を回避します。
 Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法_Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法
May 08, 2024 pm 05:10 PM
Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法_Win11 英語 21996 を簡体字中国語 22000 にアップグレードする方法
May 08, 2024 pm 05:10 PM
まず、システム言語を簡体字中国語表示に設定して再起動する必要があります。もちろん、以前に表示言語を簡体字中国語に変更したことがある場合は、この手順をスキップできます。次に、レジストリ regedit.exe の操作を開始し、左側のナビゲーション バーまたは上部のアドレス バーで HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsLanguage に直接移動し、InstallLanguage キーの値と Default キーの値を 0804 に変更します (英語に変更する場合)。まずシステムの表示言語を en-us に設定し、システムを再起動してから、すべてを 0409 に変更します) この時点でシステムを再起動する必要があります。
 navicat は redis に接続できますか?
Apr 23, 2024 pm 05:12 PM
navicat は redis に接続できますか?
Apr 23, 2024 pm 05:12 PM
はい、Navicat は Redis に接続できます。これにより、ユーザーはキーの管理、値の表示、コマンドの実行、アクティビティの監視、問題の診断が可能になります。 Redis に接続するには、Navicat で「Redis」接続タイプを選択し、サーバーの詳細を入力します。
