

ページングクエリの最適化方法: 1. サブクエリの最適化、ページング SQL ステートメントをサブクエリに書き換えることでパフォーマンスの向上を実現できます。 2. ID 制限の最適化により、クエリされたページ数とクエリされたレコード数に基づいてクエリされた ID の範囲を計算し、「との間の ID」ステートメントに基づいてクエリを実行できます。 3. インデックスの並べ替えに基づいて最適化し、インデックスを通じて関連するデータ アドレスを見つけ、テーブル全体のスキャンを回避します。 4. 遅延関連付けの最適化の場合、JOIN を使用して最初にインデックス列のページング操作を完了し、次にテーブルに戻って必要な列を取得できます。

このチュートリアルの動作環境: Windows7 システム、mysql8 バージョン、Dell G3 コンピューター。
ページング クエリの効率は、データ量が大きい場合に特に重要であり、フロントエンドの応答やユーザー エクスペリエンスに影響を与えます。
ページングクエリの最適化方法
1.サブクエリ最適化を利用する
こちらこのメソッドは、オフセット位置で ID を見つけてからクエリを実行するため、ID が増加する場合に適しています。
サブクエリ最適化の原則: https://www.jianshu.com/p/0768ebc4e28d
select * from sbtest1 where k=504878 limit 100000,5; クエリ プロセス:
まず、インデックス リーフ ノード データがクエリされ、次に、リーフ ノードの主キー値に従って、クラスター化インデックス上のすべての必須フィールド値がクエリされます。次の図の左側に示すように、インデックス ノードを 100,005 回クエリし、クラスター化インデックス データを 100,005 回クエリし、最後に最初の 100,000 項目から結果をフィルタリングして、最後の 5 項目を削除する必要があります。 MySQL は、クラスター化インデックス内のデータのクエリに大量のランダム I/O を費やし、100,000 のランダム I/O によってクエリされたデータは結果セットには表示されません。
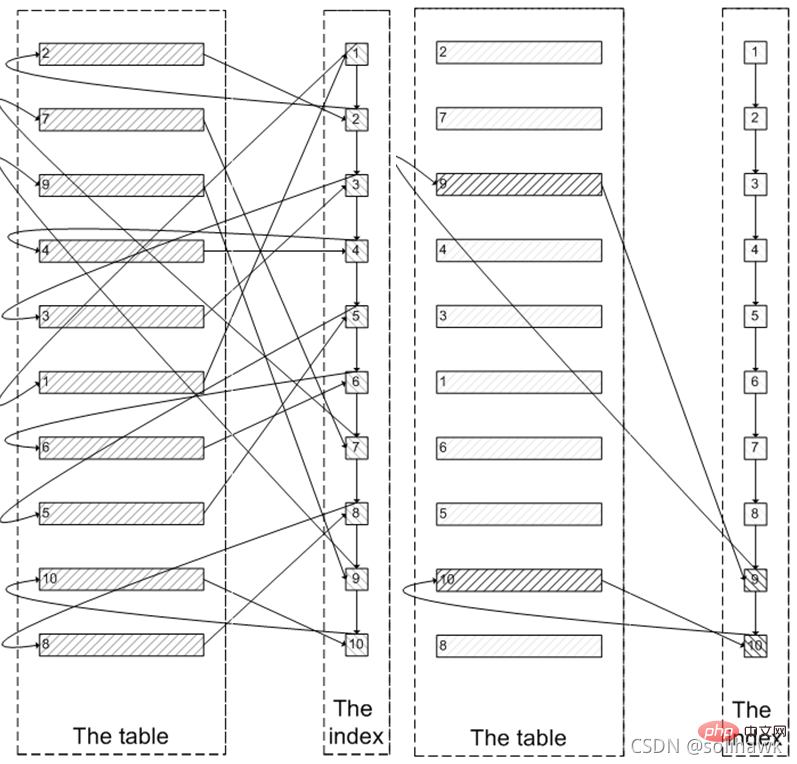
インデックスは最初に使用されるため、最初にインデックスのリーフ ノードに沿って必要な最後の 5 ノードまでクエリを実行してから、クラスター化インデックス内の実際のデータをクエリしてみてはいかがでしょうか。上の図の右側のプロセスと同様に、これには 5 つのランダム I/O のみが必要です。これはサブクエリの最適化で、オフセット位置にidを配置してからクエリを実行する方法で、idが増加する場合に適した方法です。以下に示すように:
mysql> select * from sbtest1 where k=5020952 limit 50,1; mysql> select id from sbtest1 where k=5020952 limit 50,1; mysql> select * from sbtest1 where k=5020952 and id>=( select id from sbtest1 where k=5020952 limit 50,1) limit 10; mysql> select * from sbtest1 where k=5020952 limit 50,10;
サブクエリの最適化では、述語の k にインデックスがあるかどうかがクエリの効率に大きな影響を与えます。上記のステートメントはインデックスを使用せず、テーブル全体のスキャンには 24.2 秒かかります。インデックスの場合は 24.2 秒かかりますが、0.67 秒かかります。
mysql> explain select * from sbtest1 where k=5020952 and id>=( select id from sbtest1 where k=5020952 limit 50,1) limit 10; +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ | 1 | PRIMARY | sbtest1 | NULL | index_merge | PRIMARY,c1 | c1,PRIMARY | 8,4 | NULL | 19 | 100.00 | Using intersect(c1,PRIMARY); Using where | | 2 | SUBQUERY | sbtest1 | NULL | ref | c1 | c1 | 4 | const | 88 | 100.00 | Using index | +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ 2 rows in set, 1 warning (0.11 sec)
ただし、この最適化方法には制限もあります。
この記述方法では、主キー ID が連続している必要があります
Where 句に他の条件を追加することはできません
2. ID 制限の最適化を使用します
このメソッドは、データの ID がテーブルは連続しています 増分的に、クエリされたページ数とクエリされたレコード数に基づいてクエリされた ID の範囲を計算でき、 と の間の ID を使用してクエリできます。
データベース内のテーブルの ID が継続的に増加すると仮定すると、クエリされた ID の範囲は、クエリされたページ数とクエリされたレコード数に基づいて計算され、ID に基づいてクエリされます。と の間のステートメント。 ID の範囲は、ページング式によって計算できます。たとえば、現在のページ サイズが m で、現在のページ番号が no1 の場合、ページの最大値は max=(no1 1)m-1 となります。 、最小値が min=no1m である場合、SQL ステートメントは min と max の間の id として表現できます。
select * from sbtest1 where id between 1000000 and 1000100 limit 100;
このクエリ方法はクエリ速度を大幅に最適化でき、基本的には数十ミリ秒以内に完了できます。 ID を明確に知る必要があるという制限がありますが、通常、ページング クエリのビジネス テーブルには基本的な ID フィールドが追加され、ページング クエリに大きな利便性をもたらします。上記の SQL を記述する別の方法もあります:
select * from sbtest1 where id >= 1000001 limit 100;
実行時間の違いがわかります:
mysql> show profiles; +----------+------------+--------------------------------------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------------------------------------------------------------------------------------------+ | 6 | 0.00085500 | select * from sbtest1 where id between 1000000 and 1000100 limit 100 | | 7 | 0.12927975 | select * from sbtest1 where id >= 1000001 limit 100 | +----------+------------+--------------------------------------------------------------------------------------------------------------+
また、複数のテーブルでよく使用される in メソッドを使用してクエリを実行することもできます。クエリを実行するときは、他のテーブル クエリの ID セットを使用してクエリを実行します。
select * from sbtest1 where id in (select id from sbtest2 where k=504878) limit 100;
クエリで使用する場合、一部の mysql バージョンは in 句での制限の使用をサポートしていないことに注意してください。
3. インデックスの並べ替えに基づく最適化
インデックスに基づいた並べ替えでは、インデックス クエリで最適化アルゴリズムを使用し、インデックスを通じて関連するデータ アドレスを見つけ、テーブルが完全になることを回避します。スキャンして、時間を大幅に節約します。また、Mysql には関連するインデックス キャッシュもあるので、同時実行性が高い場合にはキャッシュを使用するとよいでしょう。 MySQL では次のステートメントを使用できます:
SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) ORDER BY id_pk ASC LIMIT M
このメソッドは、データ量が多い状況 (数万のタプル) に適しています。ORDER BY の後の列オブジェクトがプライマリであることが最善です。キーまたは一意のインデックスを使用するため、インデックスを使用して ORDER BY 操作を排除できますが、結果セットは安定しています。たとえば、次の 2 つのステートメント:
mysql> show profiles; +----------+------------+--------------------------------------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------------------------------------------------------------------------------------------+ | 8 | 3.30585150 | select * from sbtest1 limit 1000000,10 | | 9 | 1.03224725 | select * from sbtest1 order by id limit 1000000,10 | +----------+------------+--------------------------------------------------------------------------------------------------------------+
インデックス フィールド ID に order by ステートメントを使用した後、パフォーマンスが大幅に向上しました。
4. 遅延関連付けを使用して最適化する
上記のサブクエリと同様に、JOIN を使用して最初にインデックス列のページング操作を完了し、その後 Get を返すことができます。テーブルから必要な列を選択します。
rreeee
从实验中可以得出,在采用JOIN改写后,上面的两个局限性都已经解除了,而且SQL的执行效率也没有损失。
5、记录上次查询结束的位置
和上面使用的方法都不同,记录上次结束位置优化思路是使用某种变量记录上一次数据的位置,下次分页时直接从这个变量的位置开始扫描,从而避免MySQL扫描大量的数据再抛弃的操作。
select * from t5 where id>=1000000 limit 10;

6、使用临时表优化
使用临时存储的表来记录分页的id然后进行in查询
这种方式已经不属于查询优化,这儿附带提一下。
对于使用 id 限定优化中的问题,需要 id 是连续递增的,但是在一些场景下,比如使用历史表的时候,或者出现过数据缺失问题时,可以考虑使用临时存储的表来记录分页的id,使用分页的id来进行 in 查询。这样能够极大的提高传统的分页查询速度,尤其是数据量上千万的时候。
【相关推荐:mysql视频教程】
以上がmysqlページングクエリを最適化する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



