

この記事では、mysql のインデックスの詳細な分析を提供し、mysql インデックスの原理を理解するのに役立ちます。お役に立てば幸いです。

インデックスは、MySQL がデータを効率的に取得するのに役立つソートされたデータ構造です。
前提条件:ツリーの高さが低いほど、クエリ効率が高くなります。
データ構造シミュレーション Web サイト: https://www.cs.usfca.edu/~galles/ html
(1) 二分木
問題点: 自己平衡化できず、極端な場合にはスキューが発生する クエリ効率はリンクリストと同等 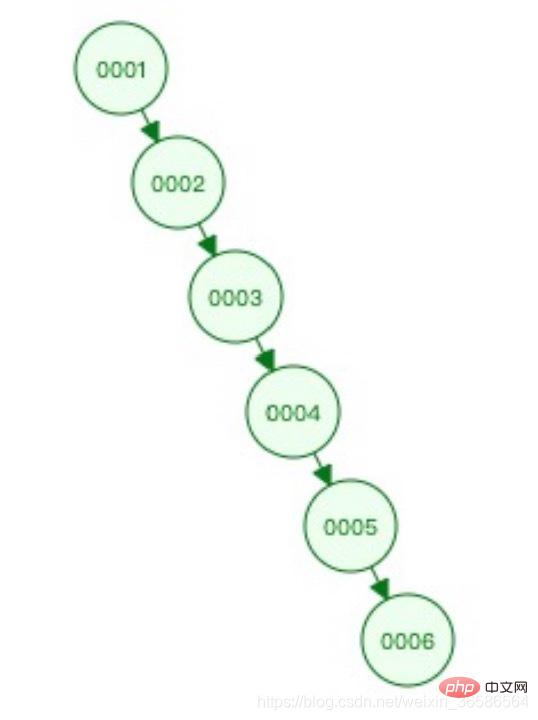
(2) 赤黒ツリー
赤と黒のツリーはデータのバランスをとり、一方的な成長の問題を解決します;
問題: 大量のデータには適していません。データが大きい、ツリーの高さを制御できない、ルートノードからリーフノードまで複数回の走査が必要であり、効率が低い。 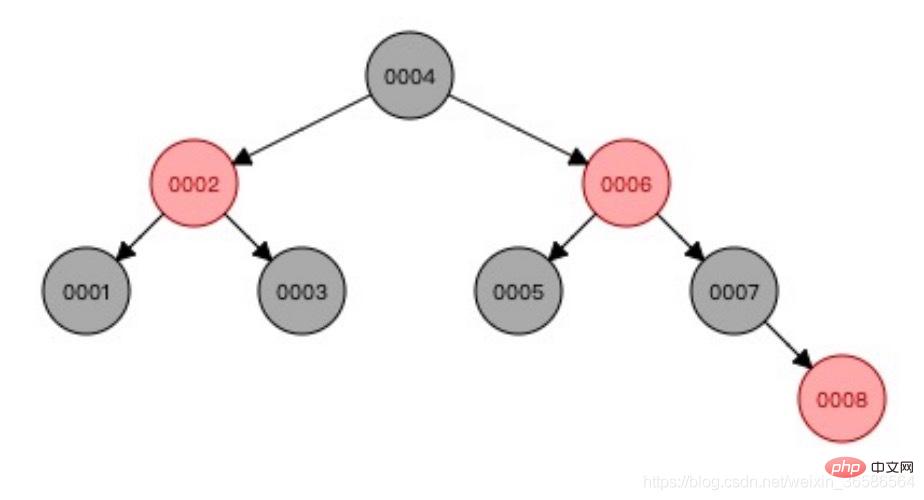
(3) ハッシュ
1. インデックス キーに対してハッシュ計算を実行して、データ ストレージの場所を特定します。
2. 多くの場合、ハッシュ インデックスの方が優れています。 B ツリーよりもインデックスは効率的です。
3. "= と "IN" のみを満たすことができ、範囲クエリはサポートされていません。
4. ハッシュの競合の問題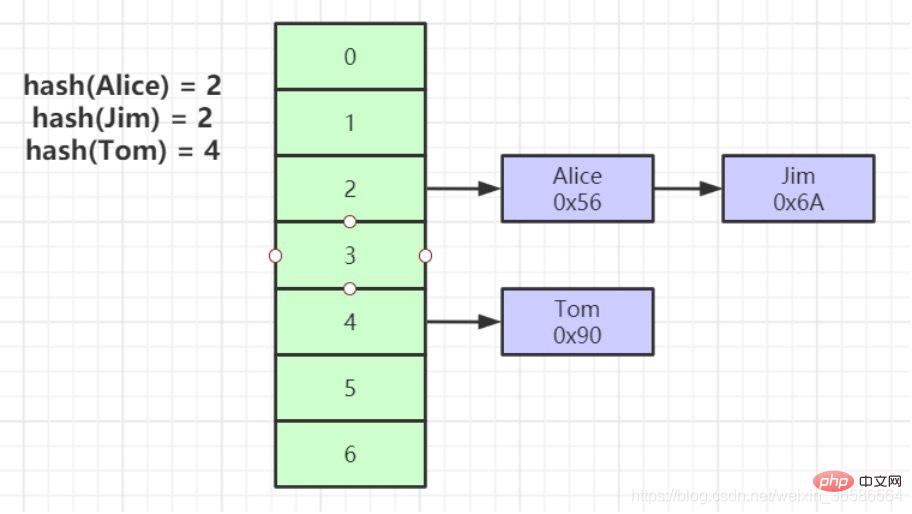
(4) B-Tree
1. リーフ ノードは同じ深さを持ち、リーフ ノードのポインタは空です;
2. すべてのインデックス要素は繰り返されません;
3. ノード内のデータ インデックス左から右へ昇順に配置されます; 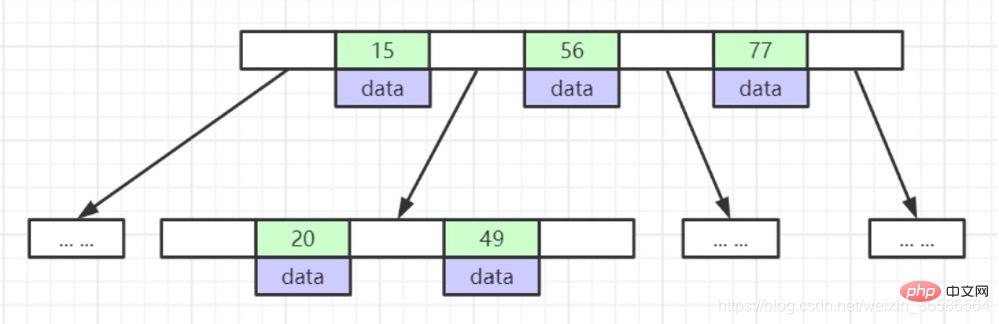
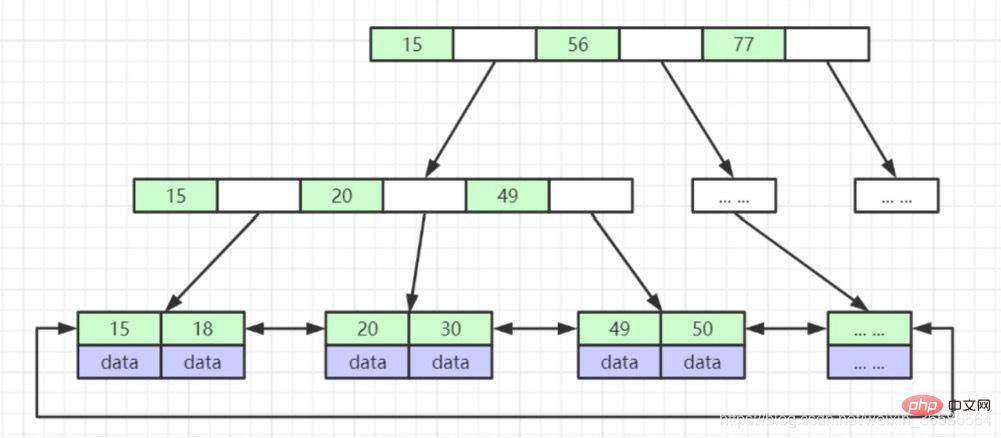
(5) B ツリー (B ツリーのバリアント)
1. 非リーフ ノードはデータを格納せず、インデックスのみを格納します (冗長)、より多くのインデックスを配置できます
2. リーフ ノードにはすべてのインデックス フィールドが含まれます
3. リーフ ノードはポインターで接続され、インターバル アクセスのパフォーマンスが向上します
この質問に対する簡単な答えは次のとおりです: 約 2,000 万
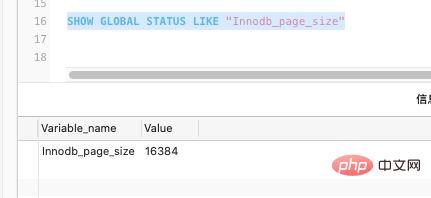
MySQL の InnoDB ページのデフォルト サイズは 16k ですが、もちろんパラメータを通じて設定することもできます:
SHOW GLOBAL STATUS LIKE "Innodb_page_size"
データ テーブルのデータはページに格納されます。1 ページには何行のデータを格納できますか?データ行のサイズが 1k であると仮定すると、1 ページにはそのようなデータを 16 行保存できます。
データベースがこの方法でのみ保存されている場合、データをどのように見つけるかが問題になります。
見つけたいデータがどのページに存在するかが分からず、横断することができないためです。全ページ、遅すぎます。
そこで人々は、このデータを B ツリーの形式で整理する方法を考えました。図に示すように: 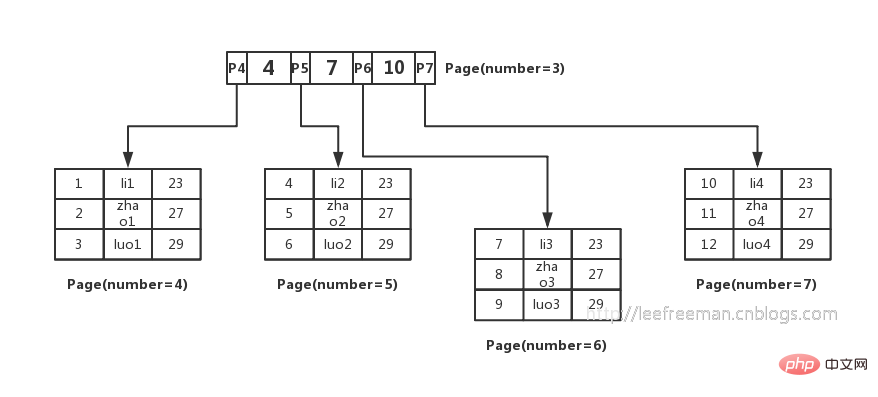
InnoDB のプライマリ キー インデックス B ツリーがどのようにデータを編成し、データをクエリするかを要約しましょう:
1. InnoDB ストレージの最小ストレージ ユニットEngine は page であり、ページはデータまたはキーと値のポインターを格納するために使用できます。B ツリーでは、リーフ ノードはデータを格納し、非リーフ ノードはキーと値のポインターを格納します。
2. 索引構成表は、非リーフ・ノードとポインターの二分検索方法によってデータがどのページにあるかを判別し、データ・ページ内で必要なデータを見つけます。それでは話を戻します。最初の疑問は、B ツリーには通常何行のデータを保存できるのかということです。
ここでは、最初に B ツリーの高さが 2、つまりルート ノードといくつかのリーフ ノードがあると仮定します。この場合、この B ツリーに格納されるレコードの総数は次のようになります。ルート ノード ポインタの数 * 単一のリーフ ノードのレコード行数。
1 つのリーフ ノード (ページ) 内のレコード数 = 16K/1K=16 であると上で説明しました。 (ここでは、レコードの1行のデータサイズを1Kと仮定しています。実際には、多くのインターネットビジネスデータのレコードサイズは通常1K程度です。)
それでは、非リーフ ノードに格納できるポインタの数を計算する必要があるでしょうか?
実際、これは簡単に計算できます。主キー ID は bigint 型で長さは 8 バイト、ポインター サイズは InnoDB ソース コードで 6 バイトに設定されていると仮定します。合計 14 バイト
1 ページに格納できるこのようなユニットの数は、実際に存在するポインターの数、つまり 16384/14=1170 を表します。
次に、高さ 2 の B ツリーには、1170*16=18720 個のデータ レコードを格納できると計算できます。
同じ原理に基づいて、高さ 3 の B ツリーには 1170* 1170 *16=21902400 件のレコードを保存できると計算できます。
したがって、InnoDB では、B ツリーの高さは通常 1 ~ 3 レイヤーであり、数千万のデータ ストレージを満たすことができます。
データを検索する場合、1 つのページ検索が 1 つの IO を表すため、主キー インデックスを介したクエリでは通常、データを見つけるために 1 ~ 3 回の IO 操作のみが必要です。
B ツリー
リーフ ノードの深さは同じで、リーフ ノードのポインタは空です。
すべてのインデックス要素は繰り返されません。
のデータ インデックスノードは左から右に配置されます。増分配置
B ツリー インデックス
非リーフ ノードはデータを格納せず、インデックスのみ (冗長) を格納します。さらに多くのインデックスを配置できます
リーフ ノードにはすべてのインデックス フィールドが含まれます
リーフ ノードはインターバル アクセスのパフォーマンスを向上させるためにポインタで接続されます
データ ノードがリーフ ノードに移動される理由は、1 つのノードがより多くのインデックスを格納できるためです
16^n=2000万, n ツリーの高さです。同じデータが格納されます。Bツリーの高さはBツリーよりもはるかに小さいです
Bツリーは葉ノードに関係なくデータを保存するため
ポインタが少ないときに大量のデータを保存するには、次のようにします。ツリーの高さは増やすことしかできませんが、その結果、IO 操作が増え、クエリのパフォーマンスが低下します。
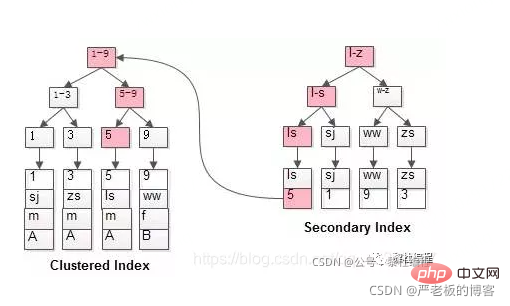
クラスター化インデックスの意味: リーフ ノードにインデックスが格納されます。クラスター化インデックスとも呼ばれるデータ。
非クラスター化インデックスはスパース インデックスとも呼ばれます。主キーインデックスはクラスター化インデックスです。
(1) MyISAM インデックス ファイルとデータ ファイルは分離されています (非集約)
MyISAM インデックス ファイルとデータ ファイルは分離され (非集約)、ストレージ エンジンはテーブル上で動作します。 # インデックス ファイルにはインデックスが保存され、データ ファイルにはデータが保存されます。インデックスとデータは一緒に保存されません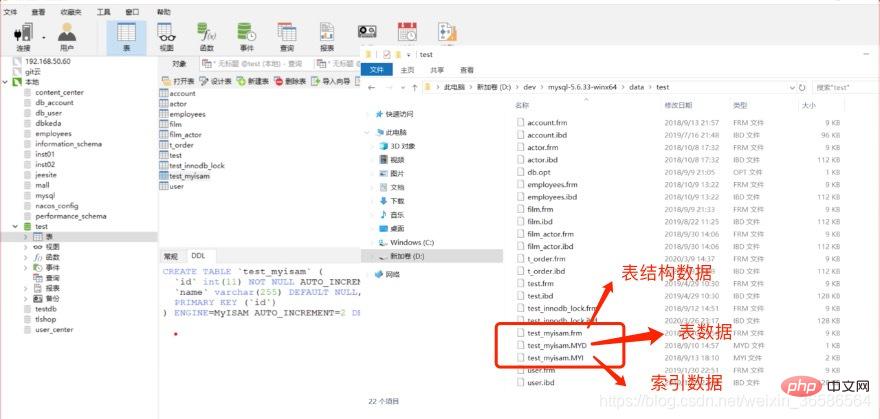 クエリ: 最初に B ツリー上のインデックスをクエリし、次に次を使用してデータ ファイルをクエリします。クエリされた場所
クエリ: 最初に B ツリー上のインデックスをクエリし、次に次を使用してデータ ファイルをクエリします。クエリされた場所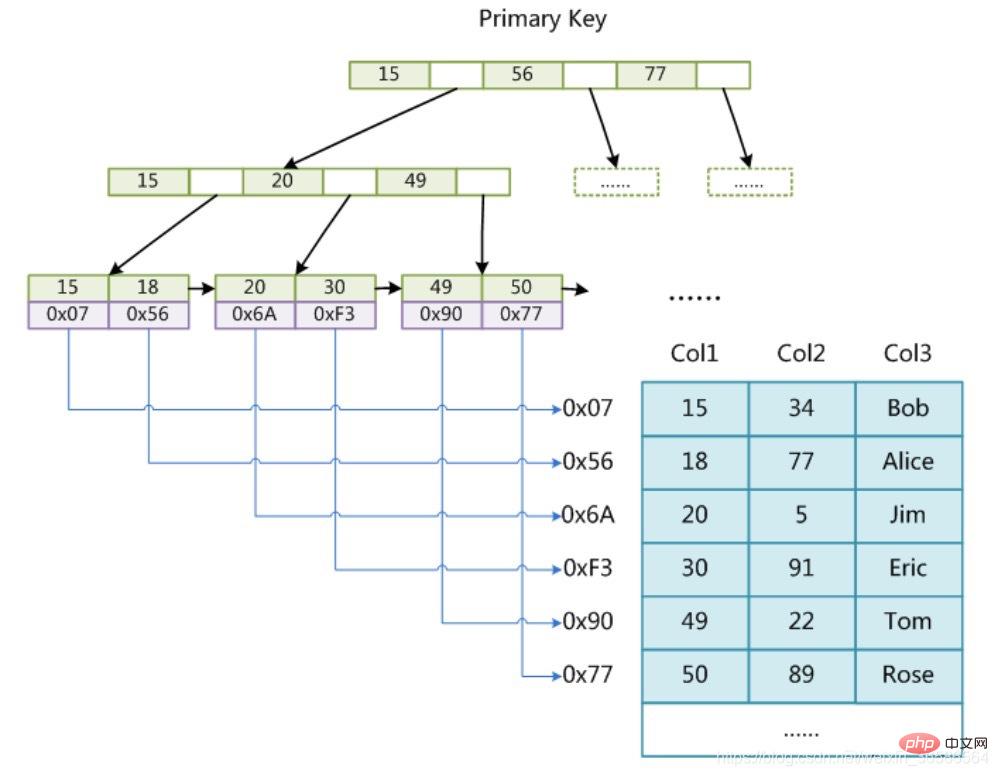
テーブル データのインデックス データは .ibd ファイル 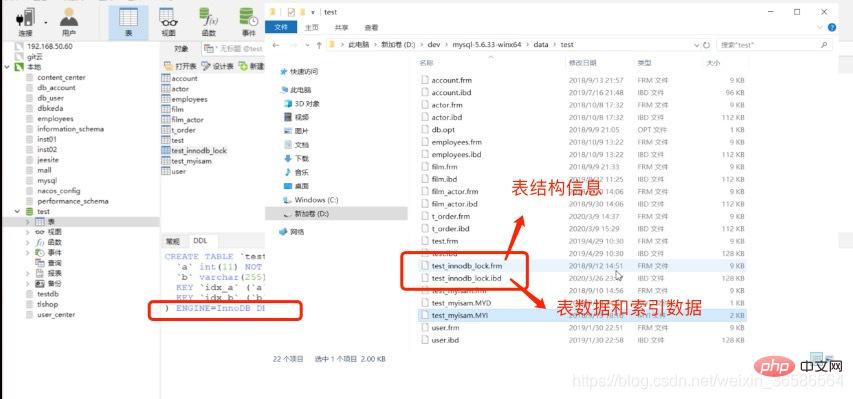
2. クラスター化インデックス - リーフ ノードには完全なデータ レコードが含まれます
(1) 主キー インデックス: 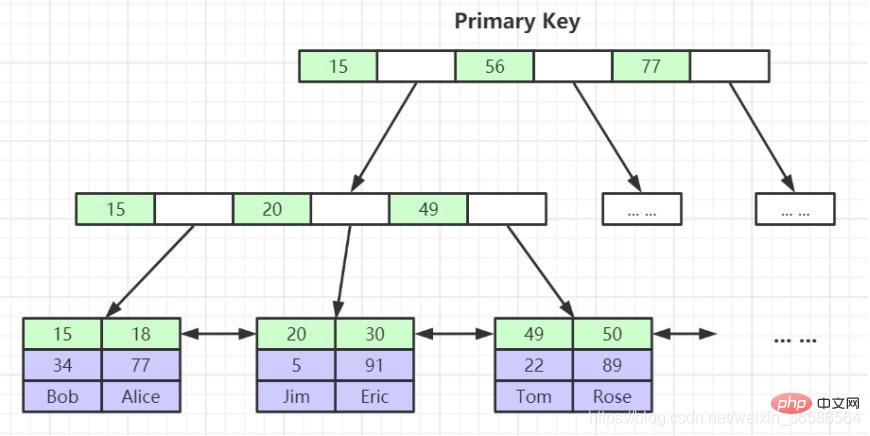
主キー インデックスのリーフ ノードには完全なデータ行が格納され、非主キー インデックスのリーフ ノードには主キー インデックス値が格納されます。キーインデックスの場合、まず主キーインデックスを見つけ、次に主キーインデックスを検索し、対応するデータを見つける処理をテーブルリターンと呼びます(後述)。
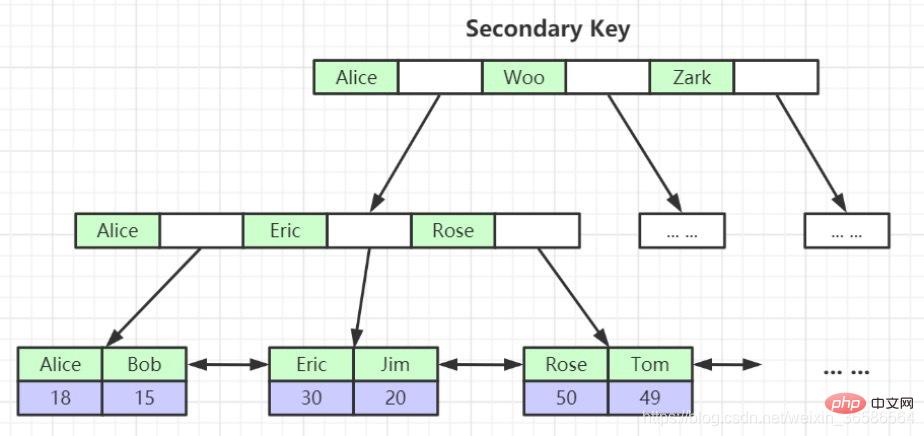 ## (3) 結合インデックス:
## (3) 結合インデックス:
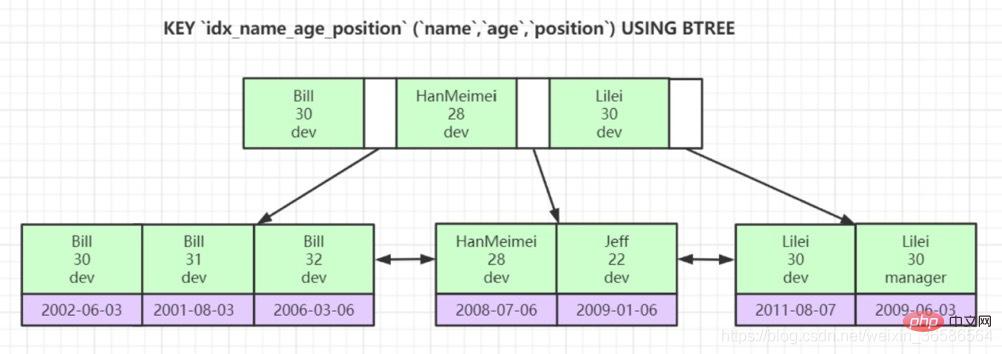
 3. InnoDB テーブルには主キーが必要であるのはなぜ、また整数の自動インクリメント主キーの使用が推奨されるのはなぜですか?
3. InnoDB テーブルには主キーが必要であるのはなぜ、また整数の自動インクリメント主キーの使用が推奨されるのはなぜですか?
(2) 整数の自動インクリメント主キーを使用せず、UUID を主キーとして使用するとどうなりますか?
UUID は文字列型です。クエリ操作には比較操作があります。整数の比較操作は高速です。整数の主キーは UUID よりもスペースを節約します。UUID は自動インクリメントされません。
(3) HASH インデックス: ハッシュ操作が実行されます。最終的な値と保存場所は 1 つずつマッピングされます
なぜハッシュを使用しないのですか?
ハッシュは範囲クエリを十分にサポートしていません。特定の列のデータは順序付けされていませんが、B ツリーを使用すると、構築時にデータを順序付けすることができます。
4. 非主キー インデックス構造のリーフ ノードに主キー値が格納されるのはなぜですか? (一貫性とストレージスペースの節約)
1. 各インデックスは B ツリーに対応します。ユーザー レコードは B ツリーのリーフ ノードに保存され、すべてのディレクトリ レコードは非リーフ ノードに保存されます。
2. InnoDB ストレージ エンジンは、主キーのクラスター化インデックスを自動的に作成します (存在しない場合は、自動的に追加されます)。クラスター化インデックスのリーフ ノードには、完全なユーザー レコードが含まれています。
3. 指定した列に対してセカンダリ インデックスを作成できます。セカンダリ インデックスのリーフ ノードに含まれるユーザー レコードは、インデックス列の主キーで構成されます。したがって、完全なユーザー レコードを検索したい場合は、セカンダリ インデックス、 が必要です。テーブルの戻り操作 を通じて、つまりセカンダリ インデックスを通じて主キー値を見つけた後、完全なユーザー レコードがクラスタード インデックスで見つかります。
4. B ツリーの各レベルのノードは、インデックス列の値に従って小さいものから大きいものまで並べ替えられ、 二重リンク リスト を形成し、各ページのレコード (ユーザー レコードまたはディレクトリ エントリ レコード)は、インデックス列値の昇順で単一リンク リストに形成されます。結合インデックスの場合、最初に結合インデックスの前の列でページとレコードがソートされ、列の値が同じ場合は結合インデックスの後の列でソートされます。
インデックスによるレコードの検索は、B ツリーのルート ノードから開始され、階層ごとに下方向に検索されます。各ページにはインデックス列の値に基づいたページ ディレクトリがあるため、これらのページ内の検索は非常に高速です。
ブログを見る: Mysql インデックスが失敗するいくつかの状況の概要
https:// blog.csdn.net/weixin_36586564/article/details/79641748
[関連する推奨事項: mysql ビデオ チュートリアル ]
以上がmysql のインデックスの詳細な分析 (原理の詳細な説明)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



