

Linux では、スタックは一連の形式のデータ構造です。このデータ構造の特徴は後入れ先出しであり、データはスタックの一方の端でのみプッシュおよびポップできます。 Linux のスタックは、プロセス スタック、スレッド スタック、カーネル スタック、および割り込みスタックに分類できます。

#このチュートリアルの動作環境: linux7.3 システム、Dell G3 コンピューター。
スタック(スタック)とは、シリアル形式のデータ構造です。このデータ構造の特徴はLIFO(Last In First Out)であり、データは文字列の片端(スタックの先頭と呼ばれます)でのみプッシュおよびポップできます。

[詳細情報] ARM レジスタの概要ARM プロセッサには 37 個のレジスタがあります。これらのレジスタは、部分的に重複するグループに配置されます。各プロセッサ モードには異なるレジスタ セットがあります。グループ化されたレジスタは、プロセッサ例外や特権操作を処理するための高速なコンテキスト切り替えを提供します。 次のレジスタが提供されます:1. 関数呼び出し関数呼び出しには次の 3 つの基本プロセスがあることがわかっています: 受信呼び出しパラメーター
- 30 個の 32 ビット汎用レジスタ:
- 15 個の汎用レジスタ存在します。r0 ~ r12、sp、lr
- sp (r13) はスタック ポインタです。 C/C コンパイラは、サブルーチンを呼び出すときにリターン アドレスを格納するスタック ポインタ
- lr (r14) として常に sp を使用します。戻りアドレスがスタックに格納されている場合、lr は汎用レジスタとして使用できます
#プログラム カウンタ (pc): 命令レジスタ- #アプリケーション ステータス レジスタ (APSR): 算術論理演算装置 (ALU) ステータス フラグのコピーを保存します。
- 現在のプログラム ステータス レジスタ (CPSR): APSR フラグ、現在のプロセッサ モード、
- 保存されたプログラム ステータス レジスタ (SPSR): 例外が発生すると、SPSR は CPSR を保存するために使用されます。
- 上記はスタックの原則と実装です。スタックが何を行うかを見てみましょう。スタックの役割は、関数呼び出しとマルチタスクのサポートという 2 つの側面に反映されます。
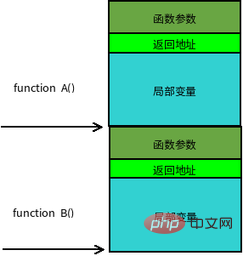
[詳細情報]: 関数スタック フレーム (Stack Frame)
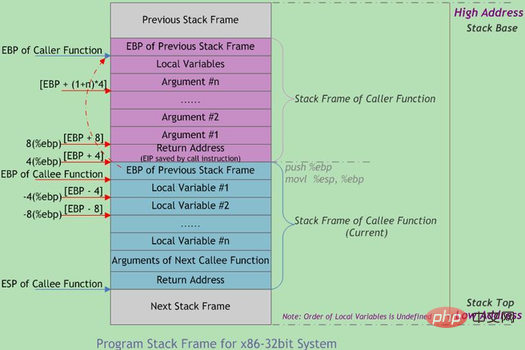
関数呼び出しは入れ子になることが多く、同時に複数のスタック フレームが存在します。 . 機能情報。未完成の各関数は、スタック フレームと呼ばれる独立した連続領域を占有します。スタック フレームには、関数のパラメータ、ローカル変数、および以前のスタック フレームを復元するために必要なデータが格納されます。関数が呼び出されたときにスタックにプッシュされる順序は、次のとおりです:
実際のパラメータ N~1 → メインの戻りアドレス呼び出し関数 → メイン呼び出し 関数フレームのベースポインタ EBP → 呼び出される関数のローカル変数 1~N
スタックフレームの境界は、スタックフレームのベースアドレスポインタ EBP とスタックポインタ ESP によって定義されます。現在のスタック フレームの最下位 (上位アドレス) スタック フレーム内の位置は固定されており、ESP は現在のスタック フレームの先頭 (下位アドレス) を指します。プログラムが実行されると、データがプッシュされると ESP は移動し、スタックから外します。したがって、関数内のデータ アクセスのほとんどは EBP に基づいています。関数呼び出しスタックの一般的なメモリ レイアウトを次の図に示します:
ただし、その意味はスタックの機能は関数呼び出しだけではなく、その存在によりオペレーティング システムのマルチタスク モードを構築できます。 main 関数の呼び出しを例に挙げると、main 関数には無限ループ本体が含まれており、ループ本体では、最初に関数 A が呼び出され、次に関数 B が呼び出されます。
func B():
return;
func A():
B();
func main():
while (1)
A();ユニプロセッサ状況では、プログラムが常にこの main 関数内に留まると想像してください。他の待ち状態のタスクがあっても、メイン関数から他のタスクにジャンプすることはできません。関数呼び出し関係であれば、本質的には依然として main 関数のタスクであり、マルチタスク切り替えとしてカウントできないためです。この時点では、実際には main 関数タスク自体がそのスタックにバインドされており、関数呼び出しがどれほどネストされていても、スタック ポインタはこのスタックのスコープ内で移動します。
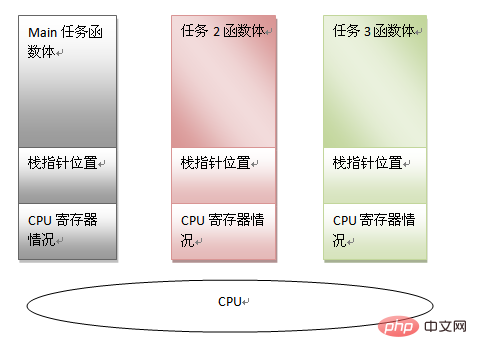
タスクは次の情報によって特徴づけられることがわかります:
main 関数本体コード
main function Stack pointer
現在の CPU レジスタ情報
上記の情報を保存できれば、CPU に他のタスクを処理させることができます。今後もこのメイン タスクの実行を継続したい場合は、上記の情報を復元できます。このような前提条件があれば、マルチタスクの存在基盤があり、スタックの存在の別の意味も見えてきます。マルチタスク モードでは、スケジューラがタスクを切り替える必要があると判断した場合、タスク情報 (つまり、上記の 3 つ) を保存するだけで済みます。別のタスクの状態を復元し、最後に実行された場所にジャンプして実行を再開します。
各タスクには独自のスタック スペースがあることがわかります。独立したスタック スペースを使用すると、コードを再利用するために、異なるタスクでタスク自体の関数本体を混在させることもできます。たとえば、1 つの main 関数に 2 つの関数を含めることができます。タスクインスタンス。この後、タスクがsleep()を呼び出して待機する際に積極的に他のタスクにCPUを譲ったり、タイムシェアリングのオペレーティングシステムタスクが強制的に実行されるなど、オペレーティングシステムの枠組みも形成されてきました。タイム スライスが使い果たされたため、CPU を放棄します。どの方法を使用する場合でも、タスクのコンテキスト空間を切り替えてスタックを切り替える方法を見つけてください。
[詳細情報]: タスク、スレッド、プロセスの関係
タスクとは、タスクを指す抽象的な概念です。アクティビティ、スレッドはタスクを完了するために必要なアクション、プロセスはこのアクションを完了するために必要なリソースの集合名を指します。この 3 つの関係には明確な比喩があります:
Linux にはスタックがいくつありますか?さまざまなスタックのメモリの場所は何ですか?
タスク=配送
- #スレッド=配送トラックの運転
##システム スケジュール=どの配送トラックが運転に適しているかを決定する- プロセス = 道路ガソリン スタンドの配送トラック修理工場
Linux 内核将这 4G 字节的空间分为两部分,将最高的 1G 字节(0xC0000000-0xFFFFFFFF)供内核使用,称为 内核空间。而将较低的3G字节(0x00000000-0xBFFFFFFF)供各个进程使用,称为 用户空间。每个进程可以通过系统调用陷入内核态,因此内核空间是由所有进程共享的。虽然说内核和用户态进程占用了这么大地址空间,但是并不意味它们使用了这么多物理内存,仅表示它可以支配这么大的地址空间。它们是根据需要,将物理内存映射到虚拟地址空间中使用。
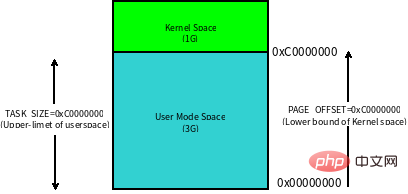
Linux 对进程地址空间有个标准布局,地址空间中由各个不同的内存段组成 (Memory Segment),主要的内存段如下:
程序段 (Text Segment):可执行文件代码的内存映射
数据段 (Data Segment):可执行文件的已初始化全局变量的内存映射
BSS段 (BSS Segment):未初始化的全局变量或者静态变量(用零页初始化)
堆区 (Heap) : 存储动态内存分配,匿名的内存映射
栈区 (Stack) : 进程用户空间栈,由编译器自动分配释放,存放函数的参数值、局部变量的值等
映射段(Memory Mapping Segment):任何内存映射文件

而上面进程虚拟地址空间中的栈区,正指的是我们所说的进程栈。进程栈的初始化大小是由编译器和链接器计算出来的,但是栈的实时大小并不是固定的,Linux 内核会根据入栈情况对栈区进行动态增长(其实也就是添加新的页表)。但是并不是说栈区可以无限增长,它也有最大限制 RLIMIT_STACK (一般为 8M),我们可以通过 ulimit 来查看或更改 RLIMIT_STACK 的值。
【扩展阅读】:如何确认进程栈的大小
我们要知道栈的大小,那必须得知道栈的起始地址和结束地址。栈起始地址 获取很简单,只需要嵌入汇编指令获取栈指针 esp 地址即可。栈结束地址 的获取有点麻烦,我们需要先利用递归函数把栈搞溢出了,然后再 GDB 中把栈溢出的时候把栈指针 esp 打印出来即可。代码如下:
/* file name: stacksize.c */
void *orig_stack_pointer;
void blow_stack() {
blow_stack();
}
int main() {
__asm__("movl %esp, orig_stack_pointer");
blow_stack();
return 0;
}$ g++ -g stacksize.c -o ./stacksize $ gdb ./stacksize (gdb) r Starting program: /home/home/misc-code/setrlimit Program received signal SIGSEGV, Segmentation fault. blow_stack () at setrlimit.c:4 4 blow_stack(); (gdb) print (void *)$esp $1 = (void *) 0xffffffffff7ff000 (gdb) print (void *)orig_stack_pointer $2 = (void *) 0xffffc800 (gdb) print 0xffffc800-0xff7ff000 $3 = 8378368 // Current Process Stack Size is 8M
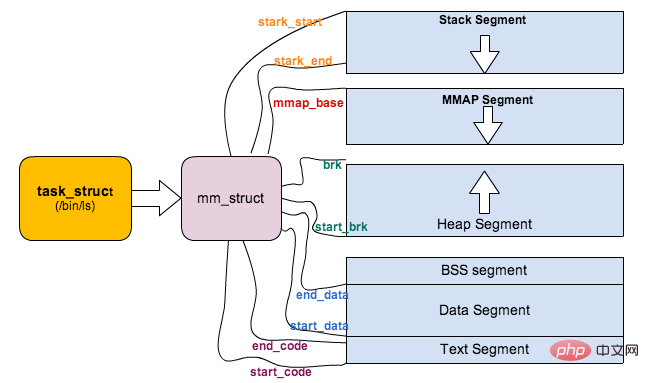
上面对进程的地址空间有个比较全局的介绍,那我们看下 Linux 内核中是怎么体现上面内存布局的。内核使用内存描述符来表示进程的地址空间,该描述符表示着进程所有地址空间的信息。内存描述符由 mm_struct 结构体表示,下面给出内存描述符结构中各个域的描述,请大家结合前面的 进程内存段布局 图一起看:
struct mm_struct {
struct vm_area_struct *mmap; /* 内存区域链表 */
struct rb_root mm_rb; /* VMA 形成的红黑树 */
...
struct list_head mmlist; /* 所有 mm_struct 形成的链表 */
...
unsigned long total_vm; /* 全部页面数目 */
unsigned long locked_vm; /* 上锁的页面数据 */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long shared_vm; /* 共享页面数目 Shared pages (files) */
unsigned long exec_vm; /* 可执行页面数目 VM_EXEC & ~VM_WRITE */
unsigned long stack_vm; /* 栈区页面数目 VM_GROWSUP/DOWN */
unsigned long def_flags;
unsigned long start_code, end_code, start_data, end_data; /* 代码段、数据段 起始地址和结束地址 */
unsigned long start_brk, brk, start_stack; /* 栈区 的起始地址,堆区 起始地址和结束地址 */
unsigned long arg_start, arg_end, env_start, env_end; /* 命令行参数 和 环境变量的 起始地址和结束地址 */
...
/* Architecture-specific MM context */
mm_context_t context; /* 体系结构特殊数据 */
/* Must use atomic bitops to access the bits */
unsigned long flags; /* 状态标志位 */
...
/* Coredumping and NUMA and HugePage 相关结构体 */
};
【扩展阅读】:进程栈的动态增长实现
进程在运行的过程中,通过不断向栈区压入数据,当超出栈区容量时,就会耗尽栈所对应的内存区域,这将触发一个 缺页异常 (page fault)。通过异常陷入内核态后,异常会被内核的 expand_stack() 函数处理,进而调用 acct_stack_growth() 来检查是否还有合适的地方用于栈的增长。
如果栈的大小低于 RLIMIT_STACK(通常为8MB),那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情,这是一种将栈扩展到所需大小的常规机制。然而,如果达到了最大栈空间的大小,就会发生 栈溢出(stack overflow),进程将会收到内核发出的 段错误(segmentation fault) 信号。
动态栈增长是唯一一种访问未映射内存区域而被允许的情形,其他任何对未映射内存区域的访问都会触发页错误,从而导致段错误。一些被映射的区域是只读的,因此企图写这些区域也会导致段错误。
从 Linux 内核的角度来说,其实它并没有线程的概念。Linux 把所有线程都当做进程来实现,它将线程和进程不加区分的统一到了 task_struct 中。线程仅仅被视为一个与其他进程共享某些资源的进程,而是否共享地址空间几乎是进程和 Linux 中所谓线程的唯一区别。线程创建的时候,加上了 CLONE_VM 标记,这样 线程的内存描述符 将直接指向 父进程的内存描述符。
if (clone_flags & CLONE_VM) {
/*
* current 是父进程而 tsk 在 fork() 执行期间是共享子进程
*/
atomic_inc(¤t->mm->mm_users);
tsk->mm = current->mm;
}虽然线程的地址空间和进程一样,但是对待其地址空间的 stack 还是有些区别的。对于 Linux 进程或者说主线程,其 stack 是在 fork 的时候生成的,实际上就是复制了父亲的 stack 空间地址,然后写时拷贝 (cow) 以及动态增长。然而对于主线程生成的子线程而言,其 stack 将不再是这样的了,而是事先固定下来的,使用 mmap 系统调用,它不带有 VM_STACK_FLAGS 标记。这个可以从 glibc 的 nptl/allocatestack.c 中的 allocate_stack() 函数中看到:
mem = mmap (NULL, size, prot, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0);
由于线程的 mm->start_stack 栈地址和所属进程相同,所以线程栈的起始地址并没有存放在 task_struct 中,应该是使用 pthread_attr_t 中的 stackaddr 来初始化 task_struct->thread->sp(sp 指向 struct pt_regs 对象,该结构体用于保存用户进程或者线程的寄存器现场)。这些都不重要,重要的是,线程栈不能动态增长,一旦用尽就没了,这是和生成进程的 fork 不同的地方。由于线程栈是从进程的地址空间中 map 出来的一块内存区域,原则上是线程私有的。但是同一个进程的所有线程生成的时候浅拷贝生成者的 task_struct 的很多字段,其中包括所有的 vma,如果愿意,其它线程也还是可以访问到的,于是一定要注意。
在每一个进程的生命周期中,必然会通过到系统调用陷入内核。在执行系统调用陷入内核之后,这些内核代码所使用的栈并不是原先进程用户空间中的栈,而是一个单独内核空间的栈,这个称作进程内核栈。进程内核栈在进程创建的时候,通过 slab 分配器从 thread_info_cache 缓存池中分配出来,其大小为 THREAD_SIZE,一般来说是一个页大小 4K;
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};thread_union 进程内核栈 和 task_struct 进程描述符有着紧密的联系。由于内核经常要访问 task_struct,高效获取当前进程的描述符是一件非常重要的事情。因此内核将进程内核栈的头部一段空间,用于存放 thread_info 结构体,而此结构体中则记录了对应进程的描述符,两者关系如下图(对应内核函数为 dup_task_struct()):
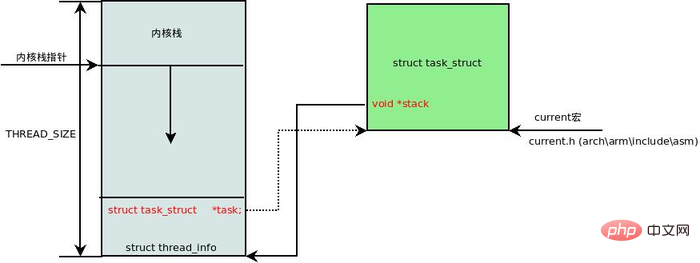
有了上述关联结构后,内核可以先获取到栈顶指针 esp,然后通过 esp 来获取 thread_info。这里有一个小技巧,直接将 esp 的地址与上 ~(THREAD_SIZE - 1) 后即可直接获得 thread_info 的地址。由于 thread_union 结构体是从 thread_info_cache 的 Slab 缓存池中申请出来的,而 thread_info_cache 在 kmem_cache_create 创建的时候,保证了地址是 THREAD_SIZE 对齐的。因此只需要对栈指针进行 THREAD_SIZE 对齐,即可获得 thread_union 的地址,也就获得了 thread_union 的地址。成功获取到 thread_info 后,直接取出它的 task 成员就成功得到了 task_struct。其实上面这段描述,也就是 current 宏的实现方法:
register unsigned long current_stack_pointer asm ("sp");
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1));
}
#define get_current() (current_thread_info()->task)
#define current get_current()进程陷入内核态的时候,需要内核栈来支持内核函数调用。中断也是如此,当系统收到中断事件后,进行中断处理的时候,也需要中断栈来支持函数调用。由于系统中断的时候,系统当然是处于内核态的,所以中断栈是可以和内核栈共享的。但是具体是否共享,这和具体处理架构密切相关。
X86 上中断栈就是独立于内核栈的;独立的中断栈所在内存空间的分配发生在 arch/x86/kernel/irq_32.c 的 irq_ctx_init() 函数中 (如果是多处理器系统,那么每个处理器都会有一个独立的中断栈),函数使用 __alloc_pages 在低端内存区分配 2个物理页面,也就是8KB大小的空间。有趣的是,这个函数还会为 softirq 分配一个同样大小的独立堆栈。如此说来,softirq 将不会在 hardirq 的中断栈上执行,而是在自己的上下文中执行。

而 ARM 上中断栈和内核栈则是共享的;中断栈和内核栈共享有一个负面因素,如果中断发生嵌套,可能会造成栈溢出,从而可能会破坏到内核栈的一些重要数据,所以栈空间有时候难免会捉襟见肘。
推奨学習: Linux ビデオ チュートリアル
以上がLinuxスタックとは何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



