

Oracle の例では、グループ化されたデータを詳しく説明しています

この記事では、主にグループ化されたデータに関連する問題を整理した Oracle に関する関連知識を提供します。グループ化により、データを論理的なグループに分割し、各グループを実行できるようになります。集計計算を見てみましょう. 皆様のお役に立てれば幸いです。

推奨チュートリアル: 「Oracle ビデオ チュートリアル 」
グループ化により、データを論理グループに分割し、各グループが集計を実行できるようになります。計算。
1. グループの作成
グループは、SELECT ステートメントの GROUP BY 句を使用して作成されます。
例:
SELECT vend_id, count(*) as num_prodsfrom productsgroup by vend_id;

GROUP BY を使用するため、評価する各グループを指定する必要はありません。計算され、自動的に完了します。 GROUP BY 句は、データをグループ化し、(結果セット全体ではなく) 各グループに対して集計を実行するように Oracle に指示します。
GROUP BY を使用する前に、GROUP BY の使用について知っておく必要がある重要なルールをいくつか説明します。
- GROUP BY 句には、必要な数の列を含めることができます。これにより、ネストされたグループ化が可能になり、データのグループ化方法をより詳細に制御できるようになります。
- group by 句にネストされたグループがある場合、データは最後に指定されたグループに集計されます。つまり、グループを構築するとき、指定されたすべての列が一緒に評価されます (そのため、個々の列ごとにデータは取得されません)。
- group by にリストされる各列は、取得された列または有効な式 (集計関数ではない) である必要があります。 select で式を使用する場合、同じ式を group by で指定する必要があります。エイリアスは使用できません。
- 集計計算ステートメントを除き、SELECT ステートメントの各列は GROUP BY 句に指定する必要があります。
- グループ化列に NULL 値を持つ列が含まれている場合、グループ化として NULL が返されます。 NULL 値を持つ行が複数ある場合、それらはすべてグループ化されます。
- GROUP BY 句は、WHERE 句の後、ORDER BY 句の前に指定する必要があります。
2. フィルターのグループ化
where 句は通常、行のフィルター処理にも使用されます。ただし、where は特定の行をグループ化するのではなくフィルターできるため、ここでは適用されません。実際、where はグループ化に適用できません。
Oracle では、このために別の句 HAVING を提供しています。 where 句と Hasting 句の唯一の違いは、where では行がフィルタされるのに対し、have ではグループがフィルタされることです。
**ヒント: **having はすべての where 演算子をサポートします
where と Have のルールは同じ構文を持ち、キーの下位部分のみが異なります。
#例:
SELECT cust_id, COUNT(*) AS ordersFROM ordersGROUP BY cust_idHAVING COUNT(*) >= 2;
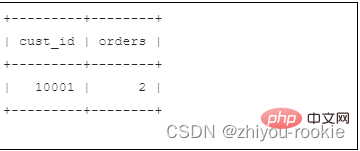
#have と where の違いを別の角度から見てみましょう。フィルタリングはデータの前に行われますが、have フィルタリングはデータのグループ化の後に行われます。これは重要な違いであり、where 句によって削除された行はグループ化に含まれません。これにより、having 句で使用される値に基づいて計算値が変更される可能性があり、その結果、どのグループがフィルタリングされるかに影響を与える可能性があります。
#where 句と have 句を同時に使用する例:
select vend_id, count(*), as num_prodsfrom productswhere prod_price>=10group by vend_idhaving count(*) > 2;
SELECT vend_id, COUNT(*) AS num_prodsFROM productsGROUP BY vend_idHAVING COUNT(*) >= 2;
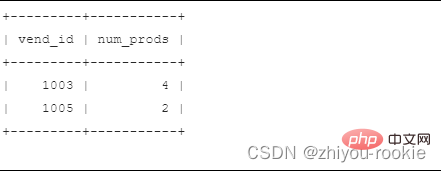

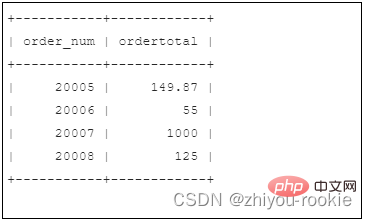
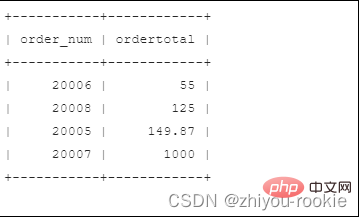
#次の表では、order by と group by の違いについて説明します
order by
| #生成された出力を並べ替える | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #任意の列を使用できます (選択されていない列も含む) | #選択された列または式のみが使用でき、選択されたすべての列の式が使用されます||||||||||||||||||||
| 集計関数で列 (または式) を使用する場合は必須 | ||||||||||||||||||||
| 子句 | 描述 | 是否必须 |
|---|---|---|
| select | 要返回的列或表达式 | Y |
| from | 要从中检索数据的表 | Y(在Oracle中是必须的;在大多数其他的DBMS中则不是) |
| where | 行级过滤(分组前过滤) | N |
| group by | 分组规范 | 仅当按分组计算聚合值时是必须的 |
| having | 分组级过滤(分组后过滤) | N |
| order by | 输出的排列顺序 | N |
推荐教程:《Oracle视频教程》
以上がOracle の例では、グループ化されたデータを詳しく説明していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7322
7322
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 Oracleで2つの日付の間の日数を計算する関数
May 08, 2024 pm 07:45 PM
Oracleで2つの日付の間の日数を計算する関数
May 08, 2024 pm 07:45 PM
2 つの日付の間の日数を計算する Oracle の関数は DATEDIFF() です。具体的な使用法は次のとおりです。 時間間隔の単位を指定します: 間隔 (日、月、年など) 2 つの日付値を指定します: date1 と date2DATEDIFF(interval, date1, date2) 日数の差を返します。
 Oracle データベースのログはどのくらいの期間保存されますか?
May 10, 2024 am 03:27 AM
Oracle データベースのログはどのくらいの期間保存されますか?
May 10, 2024 am 03:27 AM
Oracle データベース ログの保存期間は、次のようなログのタイプと構成によって異なります。 REDO ログ: 「LOG_ARCHIVE_DEST」パラメータで構成された最大サイズによって決定されます。アーカイブ REDO ログ: 「DB_RECOVERY_FILE_DEST_SIZE」パラメータで構成された最大サイズによって決まります。オンライン REDO ログ: アーカイブされず、データベースの再起動時に失われます。保持期間はインスタンスの実行時間と一致します。監査ログ: 「AUDIT_TRAIL」パラメータによって構成され、デフォルトで 30 日間保持されます。
 Oracle データベースの起動手順の順序は次のとおりです。
May 10, 2024 am 01:48 AM
Oracle データベースの起動手順の順序は次のとおりです。
May 10, 2024 am 01:48 AM
Oracle データベースの起動シーケンスは次のとおりです。 1. 前提条件を確認します。 3. データベース インスタンスを起動します。 5. データベースに接続します。サービスを有効にします (必要な場合)。 8. 接続をテストします。
 オラクルで間隔を使用する方法
May 08, 2024 pm 07:54 PM
オラクルで間隔を使用する方法
May 08, 2024 pm 07:54 PM
Oracle の INTERVAL データ型は、時間間隔を表すために使用されます。構文は INTERVAL <precision> <unit> です。INTERVAL の演算には、加算、減算、乗算、除算を使用できます。これは、時間データの保存などのシナリオに適しています。日付の差を計算します。
 oracle に 2 つの文字列が含まれているかどうかを判断する方法
May 08, 2024 pm 07:00 PM
oracle に 2 つの文字列が含まれているかどうかを判断する方法
May 08, 2024 pm 07:00 PM
Oracle では、ネストされた INSTR 関数を使用して、文字列に 2 つの部分文字列が同時に含まれているかどうかを判断できます。INSTR(string1, string2a) が 0 より大きく、INSTR(string1, string2b) が 0 より大きい場合、それは含まれます。それ以外の場合は含まれません。
 Oracle で特定の文字の出現数を確認する方法
May 09, 2024 pm 09:33 PM
Oracle で特定の文字の出現数を確認する方法
May 09, 2024 pm 09:33 PM
Oracle で文字の出現数を確認するには、次の手順を実行します。 文字列の全長を取得します。 文字が出現する部分文字列の長さを取得します。 部分文字列の長さを減算して、文字の出現数をカウントします。全長から。
 Oracle データベース サーバーのハードウェア構成要件
May 10, 2024 am 04:00 AM
Oracle データベース サーバーのハードウェア構成要件
May 10, 2024 am 04:00 AM
Oracle データベース サーバーのハードウェア構成要件: プロセッサ: マルチコア、少なくとも 2.5 GHz のメイン周波数 大規模なデータベースの場合は、32 コア以上が推奨されます。メモリ: 小規模データベースの場合は少なくとも 8 GB、中規模のデータベースの場合は 16 ~ 64 GB、大規模なデータベースまたは重いワークロードの場合は最大 512 GB 以上。ストレージ: SSD または NVMe ディスク、冗長性とパフォーマンスのための RAID アレイ。ネットワーク: 高速ネットワーク (10GbE 以上)、専用ネットワーク カード、低遅延ネットワーク。その他: 安定した電源、冗長コンポーネント、互換性のあるオペレーティング システムとソフトウェア、放熱と冷却システム。
 Oracle にはどれくらいのメモリが必要ですか?
May 10, 2024 am 04:12 AM
Oracle にはどれくらいのメモリが必要ですか?
May 10, 2024 am 04:12 AM
Oracle が必要とするメモリーの量は、データベースのサイズ、アクティビティー・レベル、および必要なパフォーマンス・レベル (データ・バッファー、索引バッファーの保管、SQL ステートメントの実行、およびデータ・ディクショナリー・キャッシュの管理) によって異なります。正確な量は、データベースのサイズ、アクティビティ レベル、および必要なパフォーマンス レベルによって影響されます。ベスト プラクティスには、適切な SGA サイズの設定、SGA コンポーネントのサイズ設定、AMM の使用、メモリ使用量の監視などが含まれます。
