

React と Vue は両方とも仮想 DOM を備えていますが、仮想 DOM の本質をどのように理解し、使いこなすべきでしょうか?次の記事では仮想 DOM について詳しく説明していますので、お役に立てれば幸いです。
仮想 DOM の本質を理解し、習得するにはどうすればよいでしょうか?私は皆さんに Snabbdom プロジェクトを学ぶことをお勧めします。
Snabbdom は仮想 DOM 実装ライブラリです。推奨の理由は、コードが比較的小さく、コア コードが数百行しかないことです。2 つ目は、Vue がこのプロジェクトのアイデアを利用して実装していることです。仮想 DOM、3 つ目は、このプロジェクトの設計/実装と拡張のアイデアが参考になる価値があることです。
snabb /snab/、スウェーデン語で「速い」という意味です。
快適な座り姿勢を調整して、元気を出して始めましょう~ 仮想 DOM を学ぶには、まず DOM の基礎知識と、JS で DOM を直接操作する際の問題点を知る必要があります。
DOM (Document Object Model) は、オブジェクト ツリー構造を使用して HTML/XML ドキュメントを表すドキュメント オブジェクト モデルです。ツリーの各枝の端はノードであり、各ノードにはオブジェクトが含まれます。 DOM API のメソッドを使用すると、このツリーを特定の方法で操作でき、ドキュメントの構造、スタイル、コンテンツを変更できます。
DOM ツリー内のすべてのノードは最初に Node であり、Node は基本クラスです。 Element、Text、および Comment はすべてそれを継承します。
つまり、Element、Text、Comment は 3 つの特別な Node であり、それぞれ ELEMENT_NODE と呼ばれます ,TEXT_NODE および COMMENT_NODE は、要素ノード (HTML タグ)、テキスト ノード、およびコメント ノードを表します。このうち、Element には HTMLElement というサブクラスもあります。HTMLElement と Element の違いは何ですか? HTMLElement は、<span>、<img> などの HTML の要素を表します。ただし、一部の要素は HTML 標準ではありません。 <svg></svg>。次のメソッドを使用して、この要素が HTMLElement であるかどうかを判断できます:
document.getElementById('myIMG') instanceof HTMLElement;ブラウザにとって DOM の作成には非常に「コスト」がかかります。古典的な例を見てみましょう。document.createElement('p') を通じて単純な p 要素を作成し、すべての属性を出力できます:
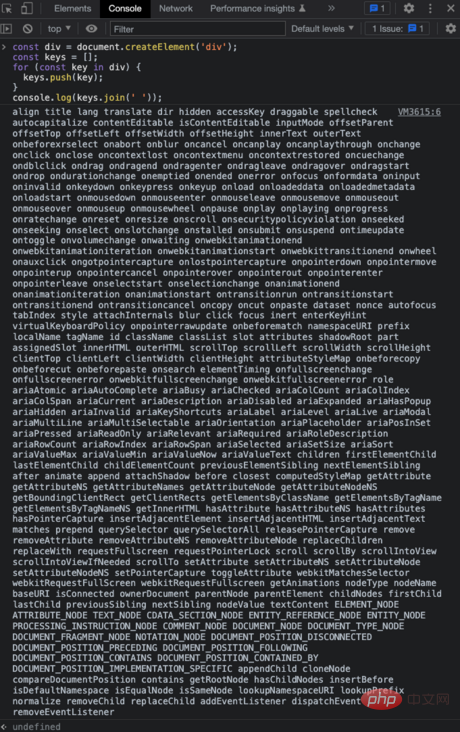
表示される属性が多いことがわかりますが、複雑な DOM ツリーを頻繁に更新すると、パフォーマンスの問題が発生します。仮想 DOM はネイティブ JS オブジェクトを使用して DOM ノードを記述するため、JS オブジェクトの作成は DOM オブジェクトを作成するよりもはるかに低コストです。
VNode は Snabbdom の仮想 DOM を記述するオブジェクト構造で、内容は次のとおりです:
type Key = string | number | symbol;
interface VNode {
// CSS 选择器,比如:'p#container'。
sel: string | undefined;
// 通过 modules 操作 CSS classes、attributes 等。
data: VNodeData | undefined;
// 虚拟子节点数组,数组元素也可以是 string。
children: Array<VNode | string> | undefined;
// 指向创建的真实 DOM 对象。
elm: Node | undefined;
/**
* text 属性有两种情况:
* 1. 没有设置 sel 选择器,说明这个节点本身是一个文本节点。
* 2. 设置了 sel,说明这个节点的内容是一个文本节点。
*/
text: string | undefined;
// 用于给已存在的 DOM 提供标识,在同级元素之间必须唯一,有效避免不必要地重建操作。
key: Key | undefined;
}
// vnode.data 上的一些设置,class 或者生命周期函数钩子等等。
interface VNodeData {
props?: Props;
attrs?: Attrs;
class?: Classes;
style?: VNodeStyle;
dataset?: Dataset;
on?: On;
attachData?: AttachData;
hook?: Hooks;
key?: Key;
ns?: string; // for SVGs
fn?: () => VNode; // for thunks
args?: any[]; // for thunks
is?: string; // for custom elements v1
[key: string]: any; // for any other 3rd party module
}たとえば、vnode を定義します次のようなオブジェクト:
const vnode = h(
'p#container',
{ class: { active: true } },
[
h('span', { style: { fontWeight: 'bold' } }, 'This is bold'),
' and this is just normal text'
]);h(sel, b, c) 関数を通じて vnode オブジェクトを作成します。 h() コードの実装では、主に b パラメーターと c パラメーターが存在するかどうかを判断し、それらをデータと子に処理します。子は最終的に配列の形式になります。最後に、上で定義した VNode 型形式が vnode() 関数を通じて返されます。
実行プロセスの簡単な例の図から始めて、一般的なプロセスの概念を理解しましょう:
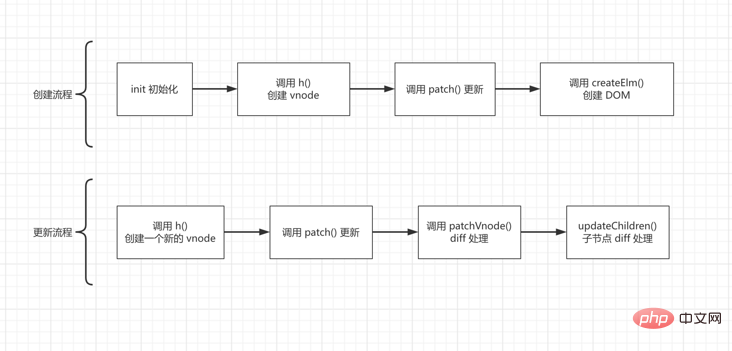
diff 処理は、新旧ノードの差分を計算する処理です。
Snabbdom の動作のサンプル コードを見てみましょう:
import {
init,
classModule,
propsModule,
styleModule,
eventListenersModule,
h,
} from 'snabbdom';
const patch = init([
// 通过传入模块初始化 patch 函数
classModule, // 开启 classes 功能
propsModule, // 支持传入 props
styleModule, // 支持内联样式同时支持动画
eventListenersModule, // 添加事件监听
]);
// <p id="container"></p>
const container = document.getElementById('container');
const vnode = h(
'p#container.two.classes',
{ on: { click: someFn } },
[
h('span', { style: { fontWeight: 'bold' } }, 'This is bold'),
' and this is just normal text',
h('a', { props: { href: '/foo' } }, "I'll take you places!"),
]
);
// 传入一个空的元素节点。
patch(container, vnode);
const newVnode = h(
'p#container.two.classes',
{ on: { click: anotherEventHandler } },
[
h(
'span',
{ style: { fontWeight: 'normal', fontStyle: 'italic' } },
'This is now italic type'
),
' and this is still just normal text',
h('a', { props: { href: ''/bar' } }, "I'll take you places!"),
]
);
// 再次调用 patch(),将旧节点更新为新节点。
patch(vnode, newVnode);プロセス図とサンプル コードからわかるように、Snabbdom の動作プロセスは次のように記述されます。
最初に初期化のために init() を呼び出します。初期化中に、使用する必要があるモジュールを構成する必要があります。たとえば、classModule モジュールはオブジェクトの形式で要素のクラス属性を構成するために使用され、eventListenersModule モジュールはイベント リスナーなどを構成するために使用されます。 init() は、呼び出し後に patch() 関数を返します。
h() 関数を通じて初期化された vnode オブジェクトを作成し、patch() 関数を呼び出して更新し、最後に # を使用します。 ##createElm() 実際の DOM オブジェクトを作成します。
patch() 関数を呼び出して更新します。 updateChildren() このノードと子ノードの差分更新を完了します。
Snabbdom 是通过模块这种设计来扩展相关属性的更新而不是全部写到核心代码中。那这是如何设计与实现的?接下来就先来康康这个设计的核心内容,Hooks——生命周期函数。
Snabbdom 提供了一系列丰富的生命周期函数也就是钩子函数,这些生命周期函数适用在模块中或者可以直接定义在 vnode 上。比如我们可以在 vnode 上这样定义钩子的执行:
h('p.row', {
key: 'myRow',
hook: {
insert: (vnode) => {
console.log(vnode.elm.offsetHeight);
},
},
});全部的生命周期函数声明如下:
| 名称 | 触发节点 | 回调参数 |
|---|---|---|
pre |
patch 开始执行 | none |
init |
vnode 被添加 | vnode |
create |
一个基于 vnode 的 DOM 元素被创建 | emptyVnode, vnode |
insert |
元素被插入到 DOM | vnode |
prepatch |
元素即将 patch | oldVnode, vnode |
update |
元素已更新 | oldVnode, vnode |
postpatch |
元素已被 patch | oldVnode, vnode |
destroy |
元素被直接或间接得移除 | vnode |
remove |
元素已从 DOM 中移除 | vnode, removeCallback |
post |
已完成 patch 过程 | none |
其中适用于模块的是:pre, create,update, destroy, remove, post。适用于 vnode 声明的是:init, create, insert, prepatch, update,postpatch, destroy, remove。
我们来康康是如何实现的,比如我们以 classModule 模块为例,康康它的声明:
import { VNode, VNodeData } from "../vnode";
import { Module } from "./module";
export type Classes = Record<string, boolean>;
function updateClass(oldVnode: VNode, vnode: VNode): void {
// 这里是更新 class 属性的细节,先不管。
// ...
}
export const classModule: Module = { create: updateClass, update: updateClass };可以看到最后导出的模块定义是一个对象,对象的 key 就是钩子函数的名称,模块对象 Module 的定义如下:
import {
PreHook,
CreateHook,
UpdateHook,
DestroyHook,
RemoveHook,
PostHook,
} from "../hooks";
export type Module = Partial<{
pre: PreHook;
create: CreateHook;
update: UpdateHook;
destroy: DestroyHook;
remove: RemoveHook;
post: PostHook;
}>;TS 中 Partial 表示对象中每个 key 的属性都是可以为空的,也就是说模块定义中你关心哪个钩子,就定义哪个钩子就好了。钩子的定义有了,在流程中是怎么执行的呢?接着我们来看 init() 函数:
// 模块中可能定义的钩子有哪些。
const hooks: Array<keyof Module> = [
"create",
"update",
"remove",
"destroy",
"pre",
"post",
];
export function init(
modules: Array<Partial<Module>>,
domApi?: DOMAPI,
options?: Options
) {
// 模块中定义的钩子函数最后会存在这里。
const cbs: ModuleHooks = {
create: [],
update: [],
remove: [],
destroy: [],
pre: [],
post: [],
};
// ...
// 遍历模块中定义的钩子,并存起来。
for (const hook of hooks) {
for (const module of modules) {
const currentHook = module[hook];
if (currentHook !== undefined) {
(cbs[hook] as any[]).push(currentHook);
}
}
}
// ...
}可以看到 init() 在执行时先遍历各个模块,然后把钩子函数存到了 cbs 这个对象中。执行的时候可以康康 patch() 函数里面:
export function init(
modules: Array<Partial<Module>>,
domApi?: DOMAPI,
options?: Options
) {
// ...
return function patch(
oldVnode: VNode | Element | DocumentFragment,
vnode: VNode
): VNode {
// ...
// patch 开始了,执行 pre 钩子。
for (i = 0; i < cbs.pre.length; ++i) cbs.pre[i]();
// ...
}
}这里以 pre 这个钩子举例,pre 钩子的执行时机是在 patch 开始执行时。可以看到 patch() 函数在执行的开始处去循环调用了 cbs 中存储的 pre 相关钩子。其他生命周期函数的调用也跟这个类似,大家可以在源码中其他地方看到对应生命周期函数调用的地方。
这里的设计思路是观察者模式。Snabbdom 把非核心功能分布在模块中来实现,结合生命周期的定义,模块可以定义它自己感兴趣的钩子,然后 init() 执行时处理成 cbs 对象就是注册这些钩子;当执行时间到来时,调用这些钩子来通知模块处理。这样就把核心代码和模块代码分离了出来,从这里我们可以看出观察者模式是一种代码解耦的常用模式。
接下来我们来康康核心函数 patch(),这个函数是在 init() 调用后返回的,作用是执行 VNode 的挂载和更新,签名如下:
function patch(oldVnode: VNode | Element | DocumentFragment, vnode: VNode): VNode {
// 为简单起见先不关注 DocumentFragment。
// ...
}oldVnode 参数是旧的 VNode 或 DOM 元素或文档片段,vnode 参数是更新后的对象。这里我直接贴出整理的流程描述:
调用模块上注册的 pre 钩子。
如果 oldVnode 是 Element,则将其转换为空的 vnode 对象,属性里面记录了 elm。
这里判断是不是 Element 是判断 (oldVnode as any).nodeType === 1 是完成的,nodeType === 1 表明是一个 ELEMENT_NODE,定义在 这里。
然后判断 oldVnode 和 vnode 是不是相同的,这里会调用 sameVnode() 来判断:
function sameVnode(vnode1: VNode, vnode2: VNode): boolean {
// 同样的 key。
const isSameKey = vnode1.key === vnode2.key;
// Web component,自定义元素标签名,看这里:
// https://developer.mozilla.org/zh-CN/docs/Web/API/Document/createElement
const isSameIs = vnode1.data?.is === vnode2.data?.is;
// 同样的选择器。
const isSameSel = vnode1.sel === vnode2.sel;
// 三者都相同即是相同的。
return isSameSel && isSameKey && isSameIs;
}patchVnode() 做 diff 更新。createElm() 创建新的 DOM 节点;创建完毕后插入 DOM 节点并删除旧的 DOM 节点。调用上述操作中涉及的 vnode 对象中注册的 insert 钩子队列, patchVnode() createElm() 都可能会有新节点插入 。至于为什么这样做,在 createElm() 中会说到。
最后调用模块上注册的 post 钩子。
流程基本就是相同的 vnode 就做 diff,不同的就创建新的删除旧的。接下来先看下 createElm() 是如何创建 DOM 节点的。
createElm() 是根据 vnode 的配置来创建 DOM 节点。流程如下:
调用 vnode 对象上可能存在的 init 钩子。
然后分一下几种情况来处理:
如果 vnode.sel === '!',这是 Snabbdom 用来删除原节点的方法,这样会新插入一个注释节点。因为在 createElm() 后会删除老节点,所以这样设置就可以达到卸载的目的。
如果 vnode.sel 选择器定义是存在的:
解析选择器,得到 id、tag 和 class。
调用 document.createElement() 或 document.createElementNS 创建 DOM 节点,并记录到 vnode.elm 中,并根据上一步的结果来设置 id、tag 和 class。
调用模块上的 create 钩子。
処理 children 子ノード配列:
children が配列の場合、再帰的に呼び出します createElm() 子ノードを作成した後、appendChild を呼び出して vnode.elm にマウントします。
children が配列ではなく、vnode.text が存在する場合、この要素の内容がテキストであることを意味し、createTextNode# がこの時点で呼び出されます。 ## テキスト ノードを作成し、vnode.elm の下にマウントします。
create フックを呼び出します。そして、vnode の insert フックを insert フック キューに追加します。
vnode.sel が存在しないことです。これは、ノード自体がテキストであることを示しており、その後、createTextNode を呼び出します。 テキスト ノードを作成し、vnode.elm に記録します。
vnode.elm が返されます。
createElm() が sel## のさまざまな設定に基づいて DOM ノードの作成方法を選択していることがわかります。 #セレクター。ここに追加する詳細があります: patch() で説明されている insert フック キュー。この insert フック キューが必要な理由は、実行前に DOM が実際に挿入されるまで待機する必要があり、# 内の要素を計算できるように、すべての子孫ノードが挿入されるまで待機する必要があるためです。 ##insert サイズと位置情報は正確です。上記の子ノードを作成するプロセスと組み合わせると、createElm() は子ノードを作成するための再帰呼び出しであるため、キューは最初に子ノードを記録し、次にキュー自体を記録します。こうすることで、patch() の最後にこのキューを実行するときに順序を保証できます。 patchVnode()
patchVnode() の処理フローは次のとおりです。
children のいくつかの状況を処理します:
の両方が存在し、同じではない場合。次に、updateChildren を呼び出して更新します。
は存在しません。 oldVnode.text が存在する場合は、まずそれをクリアしてから、addVnodes を呼び出して新しい vnode.children を追加します。
は存在します。 removeVnodes を呼び出して oldVnode.children を削除します。
も存在しない場合。 oldVnode.text が存在する場合は空です。
とは異なる場合。 oldVnode.children が存在する場合は、removeVnodes を呼び出してクリアします。次に、textContent を使用してテキスト コンテンツを設定します。 最後に、vnode で
diff で自身のノードの関連する属性 (
、など) に変更する処理を見るとわかります。など、モジュールに依存します 更新するつもりですが、ここでは拡張しただけなので、必要に応じてモジュール関連のコードを見てください。 diff の主要なコア処理は children に焦点を当てており、Kangkang diff は children に関連するいくつかの関数を処理します。 addVnodes()
removeVnodes()
フックが最初に呼び出されます。 this 呼び出しロジックと 2 つのフックの違い。 destroy
remove、このフックは、現在の要素が親から削除された場合にのみトリガーされ、削除された要素内の子要素はトリガーされず、モジュールおよび vnode オブジェクトはこのフックはモジュール上で呼び出されます。その順序は、最初にモジュールを呼び出し、次に vnode を呼び出すことです。さらに特別なのは、すべての 上記のことから、これら 2 つのフックの呼び出しロジックが異なることがわかります。特に removeupdateChildren() 是用来处理子节点 diff 的,也是 Snabbdom 中比较复杂的一个函数。总的思想是对 oldCh 和 newCh 各设置头、尾一共四个指针,这四个指针分别是 oldStartIdx、oldEndIdx、newStartIdx 和 newEndIdx。然后在 while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) 循环中对两个数组进行对比,找到相同的部分进行复用更新,并且每次比较处理最多移动一对指针。详细的遍历过程按以下顺序处理:
如果这四个指针有任何一个指向的 vnode == null,则这个指针往中间移动,比如:start++ 或 end--,null 的产生在后面情况有说明。
如果新旧开始节点相同,也就是 sameVnode(oldStartVnode, newStartVnode) 返回 true,则用 patchVnode() 执行 diff,并且两个开始节点都向中间前进一步。
如果新旧结束节点相同,也采用 patchVnode() 处理,两个结束节点向中间后退一步。
如果旧开始节点与新结束节点相同,先用 patchVnode() 处理更新。然后需要移动 oldStart 对应的 DOM 节点,移动的策略是移动到 oldEndVnode 对应 DOM 节点的下一个兄弟节点之前。为什么是这样移动呢?首先,oldStart 与 newEnd 相同,说明在当前循环处理中,老数组的开始节点是往右移动了;因为每次的处理都是首尾指针往中间移动,我们是把老数组更新成新的,这个时候 oldEnd 可能还没处理,但这个时候 oldStart 已确定在新数组的当前处理中是最后一个了,所以移动到 oldEnd 的下一个兄弟节点之前是合理的。移动完毕后,oldStart++,newEnd--,分别向各自的数组中间移动一步。
如果旧结束节点与新开始节点相同,也是先用 patchVnode() 处理更新,然后把 oldEnd 对应的 DOM 节点移动 oldStartVnode 对应的 DOM 节点之前,移动理由同上一步一样。移动完毕后,oldEnd--,newStart++。
如果以上情况都不是,则通过 newStartVnode 的 key 去找在 oldChildren 的下标 idx,根据下标是否存在有两种不同的处理逻辑:
如果下标不存在,说明 newStartVnode 是新创建的。通过 createElm() 创建新的 DOM,并插入到 oldStartVnode 对应的 DOM 之前。
如果下标存在,也要分两种情况处理:
如果两个 vnode 的 sel 不同,也还是当做新创建的,通过 createElm() 创建新的 DOM,并插入到 oldStartVnode 对应的 DOM 之前。
如果 sel 是相同的,则通过 patchVnode() 处理更新,并把 oldChildren 对应下标的 vnode 设置为 undefined,这也是前面双指针遍历中为什么会出现 == null 的原因。然后把更新完毕后的节点插入到 oldStartVnode 对应的 DOM 之前。
以上操作完后,newStart++。
遍历结束后,还有两种情况要处理。一种是 oldCh 已经全部处理完成,而 newCh 中还有新的节点,需要对 newCh 剩下的每个都创建新的 DOM;另一种是 newCh 全部处理完成,而 oldCh 中还有旧的节点,需要将多余的节点移除。这两种情况的处理在 如下:
function updateChildren(
parentElm: Node,
oldCh: VNode[],
newCh: VNode[],
insertedVnodeQueue: VNodeQueue
) {
// 双指针遍历过程。
// ...
// newCh 中还有新的节点需要创建。
if (newStartIdx <= newEndIdx) {
// 需要插入到最后一个处理好的 newEndIdx 之前。
before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].elm;
addVnodes(
parentElm,
before,
newCh,
newStartIdx,
newEndIdx,
insertedVnodeQueue
);
}
// oldCh 中还有旧的节点要移除。
if (oldStartIdx <= oldEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx);
}
}我们用一个实际例子来看一下 updateChildren() 的处理过程:
初始状态如下,旧子节点数组为 [A, B, C],新节点数组为 [B, A, C, D]:
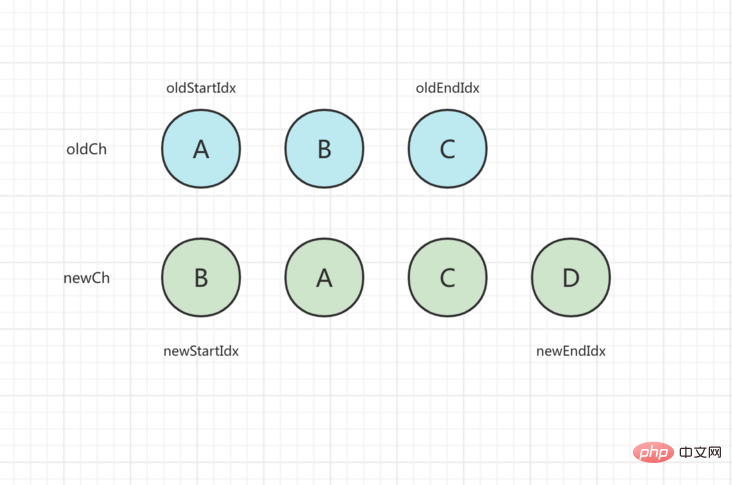
第一轮比较,开始和结束节点都不一样,于是看 newStartVnode 在旧节点中是否存在,找到了在 oldCh[1] 这个位置,那么先执行 patchVnode() 进行更新,然后把 oldCh[1] = undefined,并把 DOM 插入到 oldStartVnode 之前,newStartIdx 向后移动一步,处理完后状态如下:
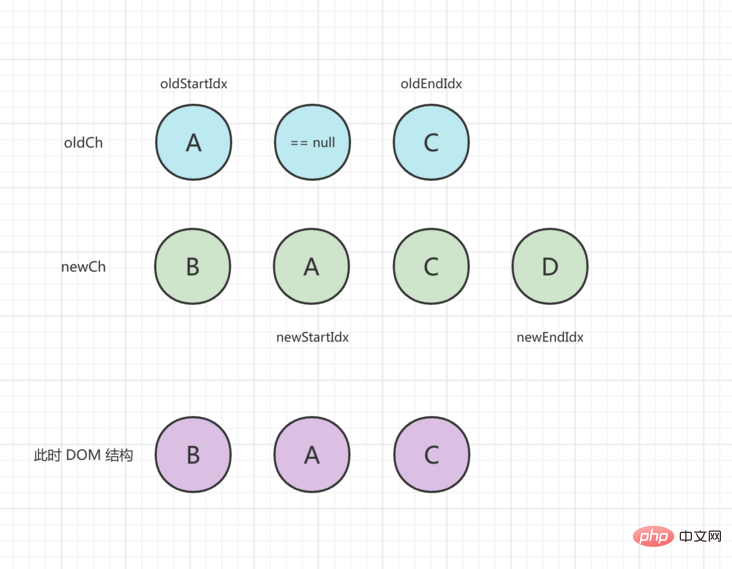
2 回目の比較 oldStartVnode は newStartVnode と同じです。patchVnode() を実行して更新します。 oldStartIdx と newStartIdx が中央に移動し、処理後のステータスは次のようになります。
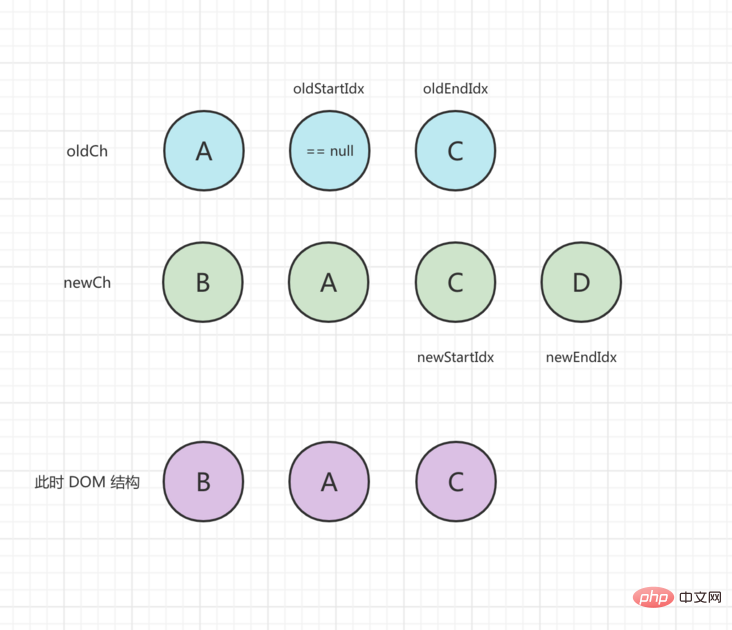
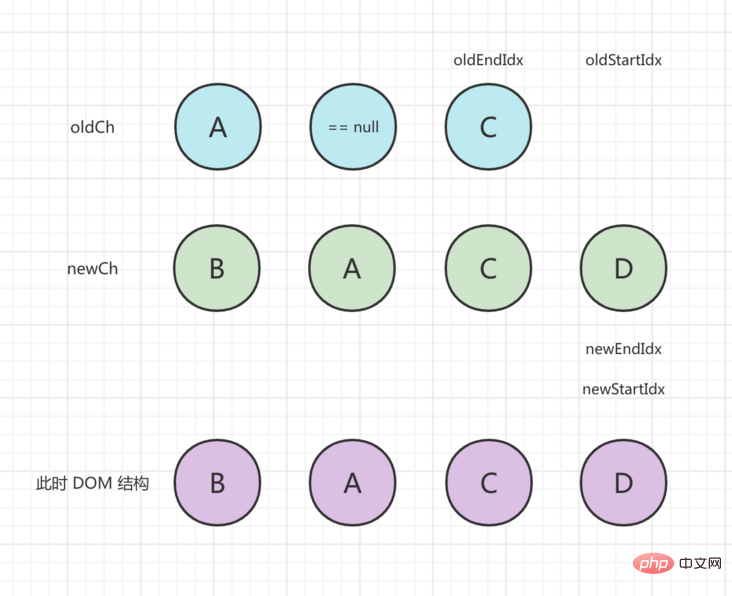
oldStartVnode == null、oldStartIdx は中央に移動し、ステータスは次のように更新されます:
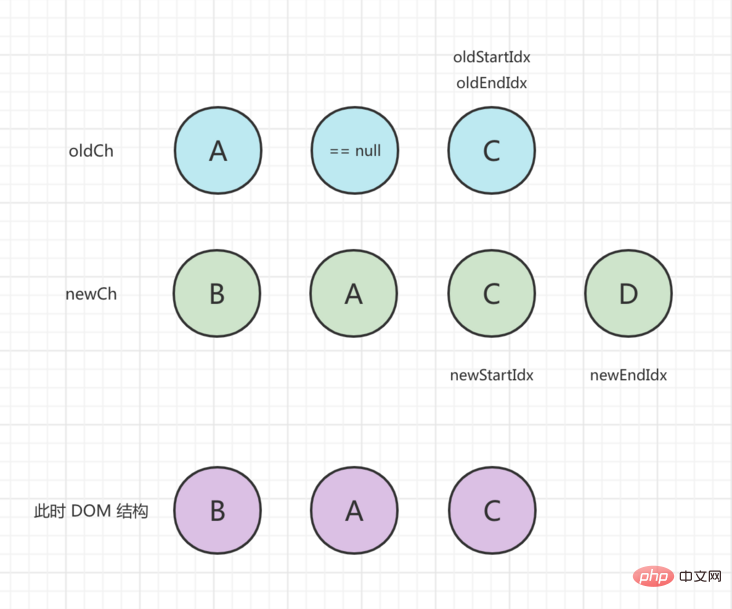
oldStartVnode は newStartVnode と同じです。patchVnode() を実行します。 update、oldStartIdx、newStartIdx 真ん中に移動します。処理後のステータスは次のとおりです。
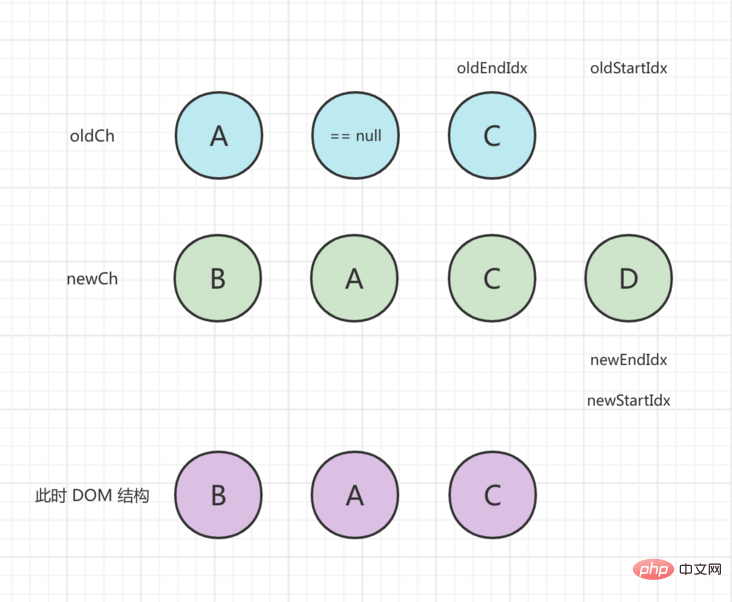
が oldEndIdx より大きいため、ループは終了します。現時点では、newCh にまだ処理されていない新しいノードが存在します。挿入するには、addVnodes() を呼び出す必要があります。最終的なステータスは次のとおりです:
プログラミング関連の知識について詳しくは、
プログラミング ビデオ以上が仮想 DOM を理解するにはどうすればよいですか?この記事をチェックしてください!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



