

mysqlのディープページング問題を解決する方法

この記事では、mysql に関する関連知識を提供し、主に mysql ディープ ページングの問題に対するエレガントなソリューションを紹介します。この記事では、mysql テーブルに大量のデータがある場合にディープ ページングを最適化する方法について説明します。ページネーションの問題、および遅い SQL の問題を最適化する最近の事例の疑似コードを添付します。

推奨学習: mysql ビデオ チュートリアル
日々の需要の開発プロセスでは、制限については誰もがよく知っていると思いますが、制限を使用すると、オフセット (オフセット) が非常に大きい場合、クエリの効率がどんどん遅くなることがわかります。最初の制限が 2000 の場合、必要なデータのクエリに 200 ミリ秒かかる場合がありますが、制限が 4000 オフセット 100000 の場合、クエリの効率はすでに約 1 秒を必要としていることがわかります。ますます悪くなり、遅い。
概要
この記事では、mysql テーブルに大量のデータがある場合にディープ ページング問題を最適化する方法について説明し、遅い SQL 問題を最適化する最近の事例の疑似コードを添付します。 。
1. ディープページングの制限に関する問題の説明
最初にテーブル構造を見てみましょう (例を挙げるだけです。テーブル構造は不完全で、無駄なフィールドは表示されません)
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
クエリしたいディープ ページング SQL が次のようになっているとします。
select * from p2p_detail_record ppdr where ppdr .start_time_stamp >1656666798000 limit 0,2000

クエリ効率は 94 ミリ秒ですが、非常に高速です。したがって、100000 または 2000 に制限すると、クエリ効率は 1.5 秒となり、これはすでに非常に遅いことになります。

##この SQL の実行計画を見てみましょう
 もインデックスに到達しましたが、それでも遅いのはなぜですか?まず、mysql の関連知識ポイントを確認しましょう。
もインデックスに到達しましたが、それでも遅いのはなぜですか?まず、mysql の関連知識ポイントを確認しましょう。
クラスター化インデックスと非クラスター化インデックス
クラスター化インデックス:リーフ ノードにはデータの行全体が格納されます。
非クラスター化インデックス:リーフ ノードには、データ行全体に対応する主キー値が格納されます。
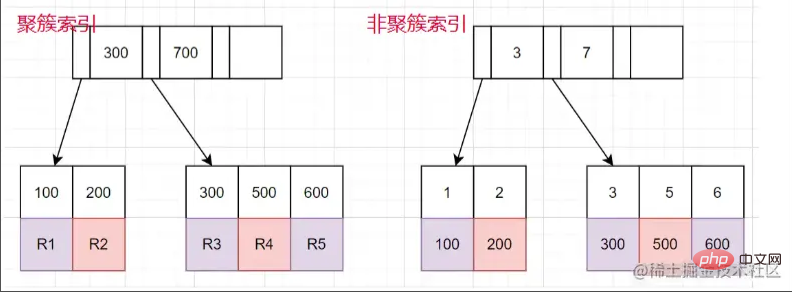 #非クラスター化インデックス クエリを使用するプロセス
#非クラスター化インデックス クエリを使用するプロセス
非クラスター化インデックスを使用して、対応するリーフ ノードを検索します。 Tree 、主キーの値を取得します。
- 次に、主キーの値を取得し、
- クラスター化インデックス ツリー に戻って、対応するデータ行全体を検索します。 (
- プロセス全体はテーブル リターンと呼ばれます)なぜこの SQL が遅いのかという質問に戻りますが、その理由は次のとおりです
limit 100000,10
は 100010 行をスキャンしますが、limit 0,10 は 10 行のみをスキャンします。ここでは 100010 回テーブルに戻る必要があり、テーブルを返すのに多くの時間がかかります。 ソリューションの核となるアイデア:
共通ソリューション
サブクエリによる最適化select *
from p2p_detail_record ppdr
where id >= (select id from p2p_detail_record ppdr2 where ppdr2 .start_time_stamp >1656666798000 limit 100000,1)
limit 2000
ログイン後にコピー
同じクエリ結果は、10W から始まる 2000 番目の項目でもあり、クエリ効率は 200ms とはるかに高速です。 select * from p2p_detail_record ppdr where id >= (select id from p2p_detail_record ppdr2 where ppdr2 .start_time_stamp >1656666798000 limit 100000,1) limit 2000
タグ記録方法
タグ記録方法:
実際には、前回クエリされたものをマークし、次回もう一度確認します。時間が来たら、このバーから下のスキャンを開始します。ブックマークの効果と同様です
select * from p2p_detail_record ppdr where ppdr.id > 'bb9d67ee6eac4cab9909bad7c98f54d4' order by id limit 2000 备注:bb9d67ee6eac4cab9909bad7c98f54d4是上次查询结果的最后一条ID
欠点があります。 1. クエリは連続したページでのみ実行でき、ページをまたいで実行することはできません。
- 2.
- continuous auto-increment のようなフィールドが必要です (ID による orber を使用できます)。
- ソリューションの比較
サブクエリ最適化による
の使用- 利点:
欠点:
はタグ記録方法 ほど効率的ではありません。 理由: たとえば、100,000 個のデータをチェックする必要がある場合、最初に非クラスター化インデックスに対応する 1000 番目のデータをクエリしてから、100,000 番目から始まる ID を取得する必要もあります。クエリ用の部分。
タグ記録方式を使用します- 利点:
欠点:
- 不跨页查询,
- 需要一种类似连续自增的字段
关于第二点的说明: 该点一般都好解决,可使用任意不重复的字段进行排序即可。若使用可能重复的字段进行排序的字段,由于mysql对于相同值的字段排序是无序,导致如果正好在分页时,上下页中可能存在相同的数据。
实战案例
需求: 需要查询查询某一时间段的数据量,假设有几十万的数据量需要查询出来,进行某些操作。
需求分析 1、分批查询(分页查询),设计深分页问题,导致效率较慢。
CREATE TABLE `p2p_detail_record` ( `id` varchar(32) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '主键', `batch_num` int NOT NULL DEFAULT '0' COMMENT '上报数量', `uptime` bigint NOT NULL DEFAULT '0' COMMENT '上报时间', `uuid` varchar(64) COLLATE utf8mb4_bin NOT NULL DEFAULT '' COMMENT '会议id', `start_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '开始时间', `answer_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '应答时间', `end_time_stamp` bigint NOT NULL DEFAULT '0' COMMENT '结束时间', `duration` int NOT NULL DEFAULT '0' COMMENT '持续时间', PRIMARY KEY (`id`), KEY `idx_uuid` (`uuid`), KEY `idx_start_time_stamp` (`start_time_stamp`) //索引, ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='p2p通话记录详情表';
伪代码实现:
//最小ID
String lastId = null;
//一页的条数
Integer pageSize = 2000;
List<P2pRecordVo> list ;
do{
list = listP2pRecordByPage(lastId,pageSize); //标签记录法,记录上次查询过的Id
lastId = list.get(list.size()-1).getId(); //获取上一次查询数据最后的ID,用于记录
//对数据的操作逻辑
XXXXX();
}while(isNotEmpty(list));
<select id ="listP2pRecordByPage">
select *
from p2p_detail_record ppdr where 1=1
<if test = "lastId != null">
and ppdr.id > #{lastId}
</if>
order by id asc
limit #{pageSize}
</select>这里有个小优化点: 可能有的人会先对所有数据排序一遍,拿到最小ID,但是这样对所有数据排序,然后去min(id),耗时也蛮长的,其实第一次查询,可不带lastId进行查询,查询结果也是一样。速度更快。
总结
1、当业务需要从表中查出大数据量时,而又项目架构没上ES时,可考虑使用标签记录法的方式,对查询效率进行优化。
2、从需求上也应该尽可能避免,在大数据量的情况下,分页查询最后一页的功能。或者限制成只能一页一页往后划的场景。
推荐学习:mysql视频教程
以上がmysqlのディープページング問題を解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7700
7700
 15
1640
14
1393
52
1287
25
1230
29
15
1640
14
1393
52
1287
25
1230
29

 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。
 MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをエレガントにインストールするための鍵は、公式のMySQLリポジトリを追加することです。特定の手順は次のとおりです。MYSQLの公式GPGキーをダウンロードして、フィッシング攻撃を防ぎます。 mysqlリポジトリファイルを追加:rpm -uvh https://dev.mysql.com/get/mysql80-community-rease-el7-3.noarch.rpm update yumリポジトリキャッシュ:yumアップデートインストールmysql:yumインストールmysql-server startup mysql sportin
