

Redis のメモリ削除戦略と期限切れ削除戦略の違い


推奨される学習: Redis ビデオ チュートリアル
はじめに
Redis はキーの有効期限を設定できます。したがって、期限切れのキーと値のペアを削除するための対応するメカニズムが必要であり、これを行うのが期限切れのキーと値の削除戦略です。
Redis の "メモリ削除戦略" と "有効期限削除戦略" は、多くの人が混同しやすいものです。これら 2 つのメカニズムは両方とも削除操作を実行しますが、トリガー条件と使用される戦略が異なります。
今日は「メモリ消去戦略」と「期限切れ削除戦略」について説明します。
期限切れ削除ポリシー
Redis はキーの有効期限を設定できるため、対応するポリシーが必要です。期限切れのキーと値のペアを削除するためのメカニズムであり、このジョブが行うのは期限切れのキーと値の削除戦略です。
有効期限を設定するにはどうすればよいですか?
まず、キーの有効期限を設定するコマンドについて説明します。キーの有効期限を設定するには 4 つのコマンドがあります:
- expire
: n 秒後にキーが期限切れになるように設定します。たとえば、expire key 100 はキーを設定することを意味します。 ; - pexpire
: n ミリ秒後に期限切れになるようにキーを設定します。たとえば、pexpire key2 100000 は、key2 が 100000 ミリ秒 (100 秒) 後に期限切れになるように設定することを意味します。 - expireat
: 特定のタイムスタンプ (秒単位の精度) 後にキーが期限切れになるように設定します。たとえば、expirat key3 1655654400 は、key3 がタイムスタンプ 1655654400 (秒単位の精度) 後に期限切れになることを意味します。 ##pexpireat
- set
- setex
: キーと値のペアを設定するときは、有効期限 (秒単位の精度)。
# 设置键值对的时候,同时指定过期时间位 60 秒 > setex key1 60 value1 OK # 查看 key1 过期时间还剩多少 > ttl key1 (integer) 56 > ttl key1 (integer) 52
# 取消 key1 的过期时间 > persist key1 (integer) 1 # 使用完 persist 命令之后, # 查下 key1 的存活时间结果是 -1,表明 key1 永不过期 > ttl key1 (integer) -1
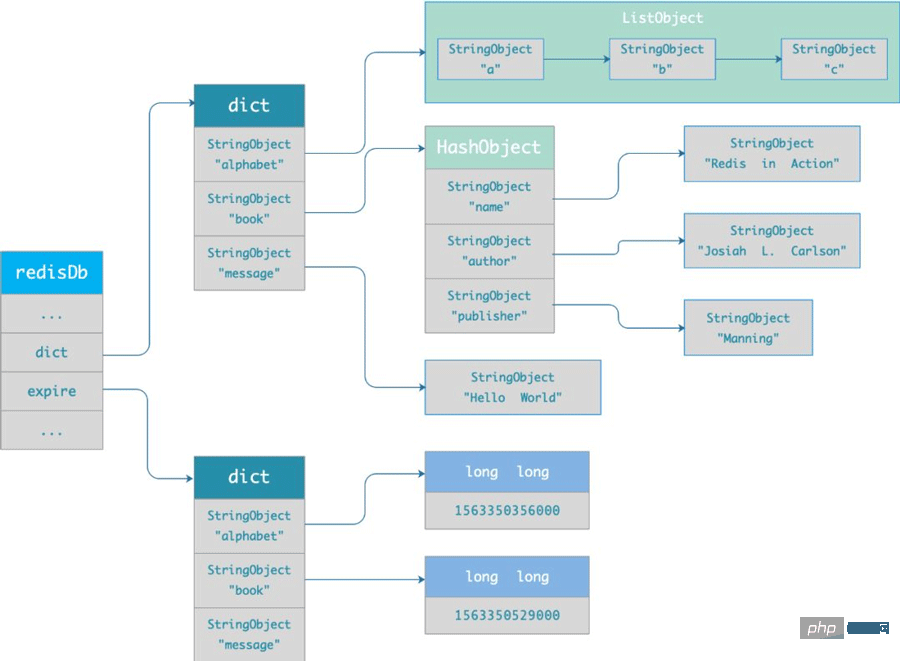
期限切れの辞書は、次のように redisDb 構造に保存されます:
typedef struct redisDb {
dict *dict; /* 数据库键空间,存放着所有的键值对 */
dict *expires; /* 键的过期时间 */
....
} redisDb;期限切れの辞書のデータ構造は次のとおりです:
- 期限切れの辞書のキーは、キー オブジェクトを指すポインタです; 期限切れの辞書の値は、キーの有効期限を格納する Long Long 型の整数です;
期限切れの辞書のデータ構造を次の図に示します。
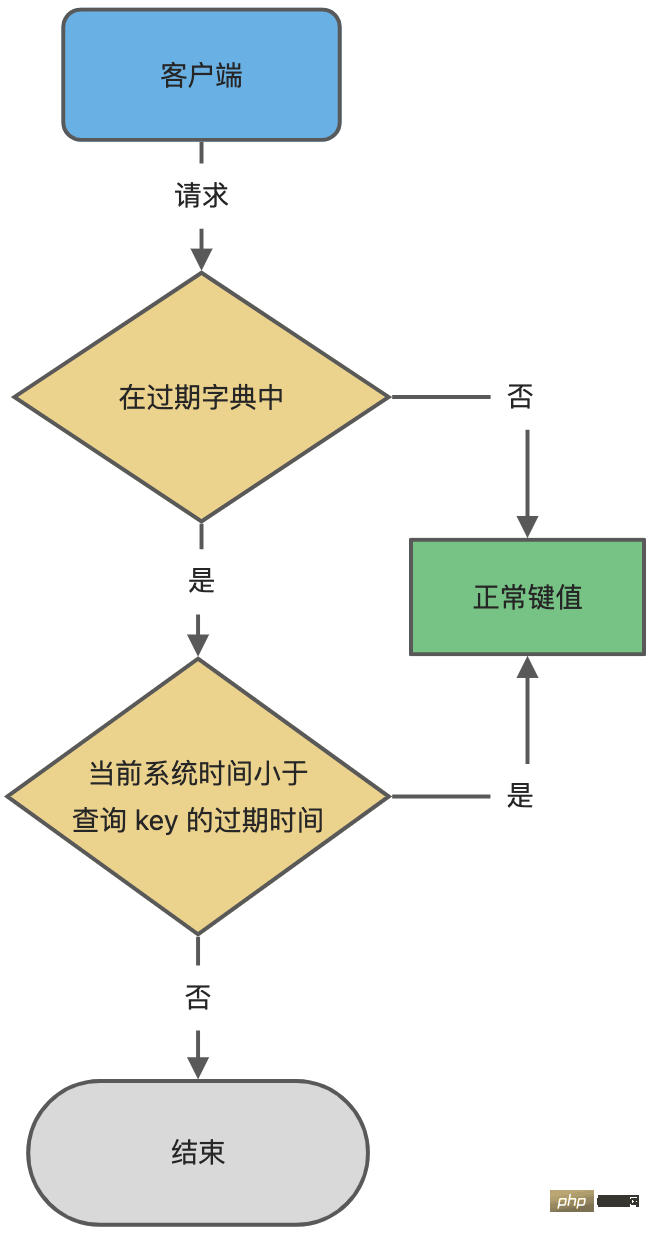
- 存在しない場合は、キー値が通常どおり読み取られます。存在する場合は、キー値が読み取られます。次に、キーの有効期限を現在のシステム時刻と比較し、システム時刻より大きければ有効期限が切れていないと判断し、そうでない場合はキーの有効期限が切れていると判断します。
有効期限キーの判定処理を次の図に示します。
Redis の有効期限削除戦略について説明する前に、まず 3 つの一般的な有効期限削除戦略を紹介します。
- 定时删除;
- 惰性删除;
- 定期删除;
接下来,分别分析它们的优缺点。
定时删除策略是怎么样的?
定时删除策略的做法是,在设置 key 的过期时间时,同时创建一个定时事件,当时间到达时,由事件处理器自动执行 key 的删除操作。
定时删除策略的优点:可以保证过期 key 会被尽快删除,也就是内存可以被尽快地释放。因此,定时删除对内存是最友好的。
定时删除策略的缺点:在过期 key 比较多的情况下,删除过期 key 可能会占用相当一部分 CPU 时间,在内存不紧张但 CPU 时间紧张的情况下,将 CPU 时间用于删除和当前任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。所以,定时删除策略对 CPU 不友好。
惰性删除策略是怎么样的?惰性删除策略的做法是,不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。
惰性删除策略的优点:因为每次访问时,才会检查 key 是否过期,所以此策略只会使用很少的系统资源,因此,惰性删除策略对 CPU 时间最友好。
惰性删除策略的缺点:如果一个 key 已经过期,而这个 key 又仍然保留在数据库中,那么只要这个过期 key 一直没有被访问,它所占用的内存就不会释放,造成了一定的内存空间浪费。所以,惰性删除策略对内存不友好。
定期删除策略是怎么样的?定期删除策略的做法是,每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
定期删除策略的优点:通过限制删除操作执行的时长和频率,来减少删除操作对 CPU 的影响,同时也能删除一部分过期的数据减少了过期键对空间的无效占用。
定期删除策略的缺点:
- 内存清理方面没有定时删除效果好,同时没有惰性删除使用的系统资源少。
- 难以确定删除操作执行的时长和频率。如果执行的太频繁,定期删除策略变得和定时删除策略一样,对CPU不友好;如果执行的太少,那又和惰性删除一样了,过期 key 占用的内存不会及时得到释放。
Redis 过期删除策略是什么?
前面介绍了三种过期删除策略,每一种都有优缺点,仅使用某一个策略都不能满足实际需求。
所以, Redis 选择「惰性删除+定期删除」这两种策略配和使用,以求在合理使用 CPU 时间和避免内存浪费之间取得平衡。
Redis 是怎么实现惰性删除的?
Redis 的惰性删除策略由 db.c 文件中的 expireIfNeeded 函数实现,代码如下:
int expireIfNeeded(redisDb *db, robj *key) {
// 判断 key 是否过期
if (!keyIsExpired(db,key)) return 0;
....
/* 删除过期键 */
....
// 如果 server.lazyfree_lazy_expire 为 1 表示异步删除,反之同步删除;
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
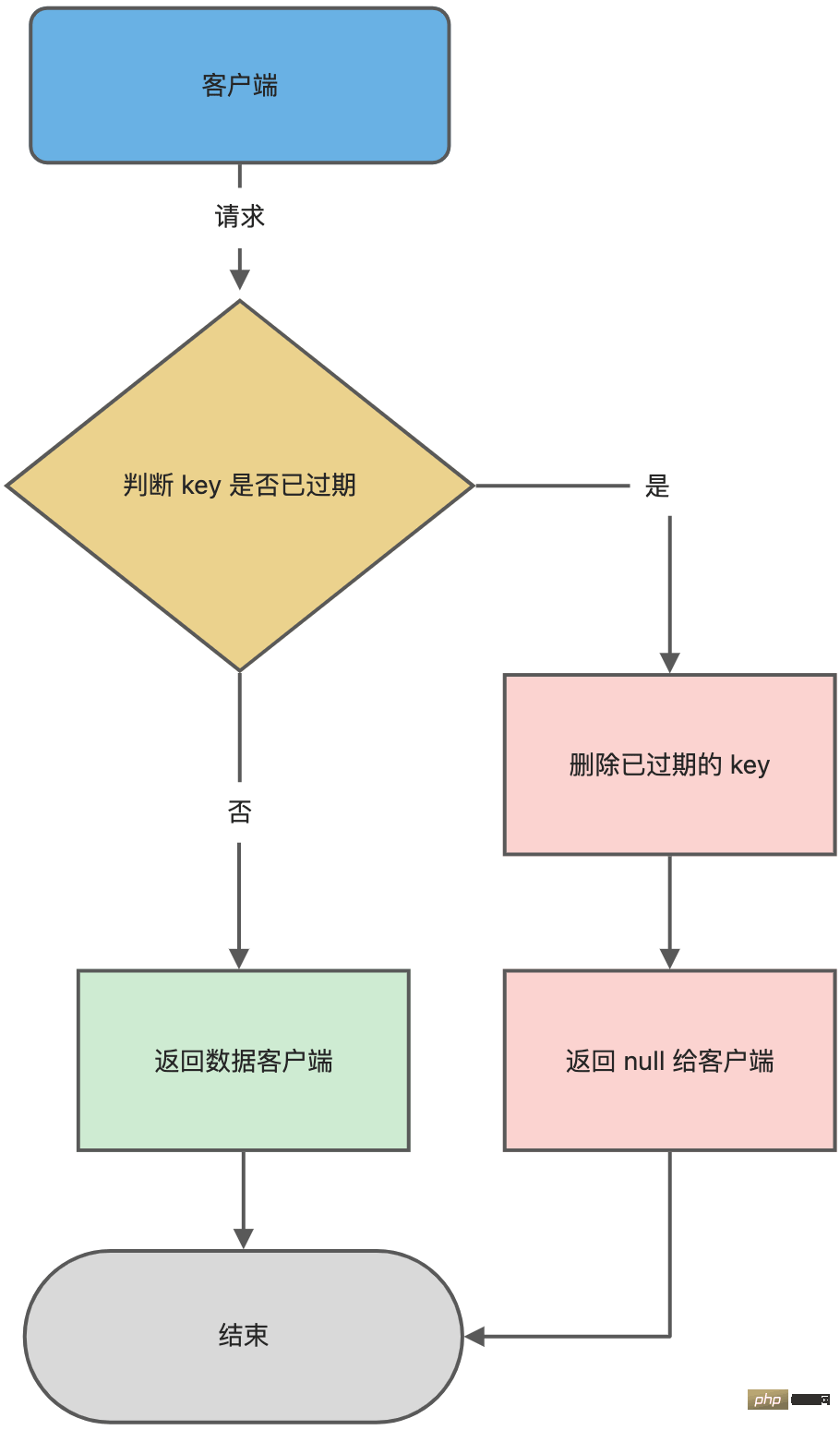
}Redis 在访问或者修改 key 之前,都会调用 expireIfNeeded 函数对其进行检查,检查 key 是否过期:
- 如果过期,则删除该 key,至于选择异步删除,还是选择同步删除,根据lazyfree_lazy_expire 参数配置决定(Redis 4.0版本开始提供参数),然后返回 null 给客服端;
- 如果没有过期,不做任何处理,然后返回正常的键值对给客户端;
惰性删除的流程图如下:
Redis 是怎么实现定期删除的?
再回忆一下,定期删除策略的做法:每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
1.这个间隔检查的时间是多长呢?
在 Redis 中,默认每秒进行 10 次过期检查一次数据库,此配置可通过 Redis 的配置文件 redis.conf 进行配置,配置键为 hz 它的默认值是 hz 10。
特别强调下,每次检查数据库并不是遍历过期字典中的所有 key,而是从数据库中随机抽取一定数量的 key 进行过期检查。
2.随机抽查的数量是多少呢?
我查了下源码,定期删除的实现在 expire.c 文件下的 activeExpireCycle 函数中,其中随机抽查的数量由 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 定义的,它是写死在代码中的,数值是 20。
也就是说,数据库每轮抽查时,会随机选择 20 个 key 判断是否过期。
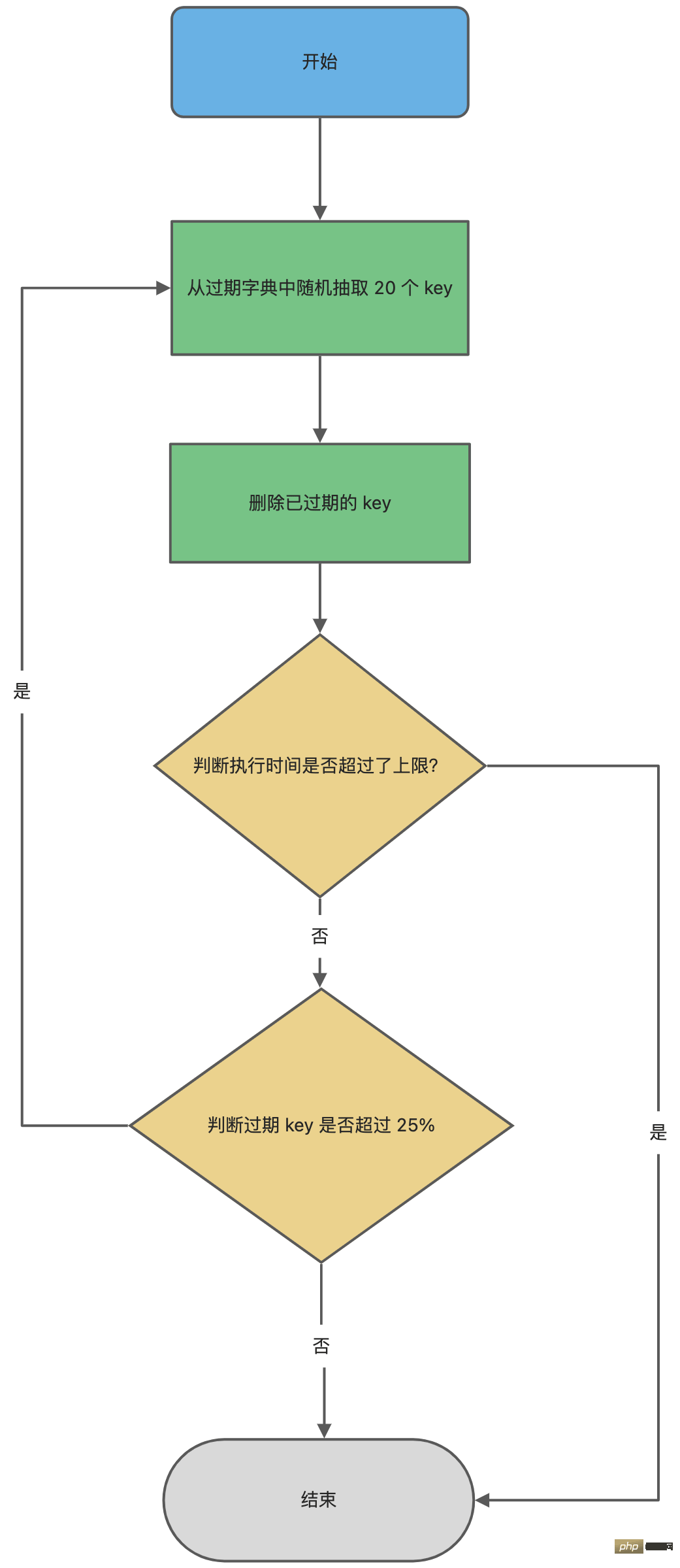
接下来,详细说说 Redis 的定时删除的流程:
- 从过期字典中随机抽取 20 个 key;
- 检查这 20 个 key 是否过期,并删除已过期的 key;
- 如果本轮检查的已过期 key 的数量,超过 5 个(20/4),也就是「已过期 key 的数量」占比「随机抽取 key 的数量」大于 25%,则继续重复步骤 1;如果已过期的 key 比例小于 25%,则停止继续删除过期 key,然后等待下一轮再检查。
可以看到,定时删除是一个循环的流程。
那 Redis 为了保证定时删除不会出现循环过度,导致线程卡死现象,为此增加了定时删除循环流程的时间上限,默认不会超过 25ms。
针对定时删除的流程,我写了个伪代码:
do {
//已过期的数量
expired = 0;
//随机抽取的数量
num = 20;
while (num--) {
//1. 从过期字典中随机抽取 1 个 key
//2. 判断该 key 是否过期,如果已过期则进行删除,同时对 expired++
}
// 超过时间限制则退出
if (timelimit_exit) return;
/* 如果本轮检查的已过期 key 的数量,超过 25%,则继续随机抽查,否则退出本轮检查 */
} while (expired > 20/4);定时删除的流程如下:
内存淘汰策略
前面说的过期删除策略,是删除已过期的 key,而当 Redis 的运行内存已经超过 Redis 设置的最大内存之后,则会使用内存淘汰策略删除符合条件的 key,以此来保障 Redis 高效的运行。
如何设置 Redis 最大运行内存?
在配置文件 redis.conf 中,可以通过参数 maxmemory
不同位数的操作系统,maxmemory 的默认值是不同的:
- 在 64 位操作系统中,maxmemory 的默认值是 0,表示没有内存大小限制,那么不管用户存放多少数据到 Redis 中,Redis 也不会对可用内存进行检查,直到 Redis 实例因内存不足而崩溃也无作为。
- 在 32 位操作系统中,maxmemory 的默认值是 3G,因为 32 位的机器最大只支持 4GB 的内存,而系统本身就需要一定的内存资源来支持运行,所以 32 位操作系统限制最大 3 GB 的可用内存是非常合理的,这样可以避免因为内存不足而导致 Redis 实例崩溃。
Redis 内存淘汰策略有哪些?
Redis 内存淘汰策略共有八种,这八种策略大体分为「不进行数据淘汰」和「进行数据淘汰」两类策略。
1.不进行数据淘汰的策略
noeviction(Redis3.0之后,默认的内存淘汰策略) :它表示当运行内存超过最大设置内存时,不淘汰任何数据,而是不再提供服务,直接返回错误。
2.进行数据淘汰的策略
针对「进行数据淘汰」这一类策略,又可以细分为「在设置了过期时间的数据中进行淘汰」和「在所有数据范围内进行淘汰」这两类策略。
在设置了过期时间的数据中进行淘汰:
- volatile-random:随机淘汰设置了过期时间的任意键值;
- volatile-ttl:优先淘汰更早过期的键值。
- volatile-lru(Redis3.0 之前,默认的内存淘汰策略):淘汰所有设置了过期时间的键值中,最久未使用的键值;
- volatile-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰所有设置了过期时间的键值中,最少使用的键值;
在所有数据范围内进行淘汰:
- allkeys-random:随机淘汰任意键值;
- allkeys-lru:淘汰整个键值中最久未使用的键值;
- allkeys-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰整个键值中最少使用的键值。
如何查看当前 Redis 使用的内存淘汰策略?
可以使用 config get maxmemory-policy 命令,来查看当前 Redis 的内存淘汰策略,命令如下:
127.0.0.1:6379> config get maxmemory-policy 1) "maxmemory-policy" 2) "noeviction"
可以看出,当前 Redis 使用的是 noeviction 类型的内存淘汰策略,它是 Redis 3.0 之后默认使用的内存淘汰策略,表示当运行内存超过最大设置内存时,不淘汰任何数据,但新增操作会报错。
如何修改 Redis 内存淘汰策略?
设置内存淘汰策略有两种方法:
- 方式一:通过“config set maxmemory-policy <策略>”命令设置。它的优点是设置之后立即生效,不需要重启 Redis 服务,缺点是重启 Redis 之后,设置就会失效。
- 方式二:通过修改 Redis 配置文件修改,设置“maxmemory-policy <策略>”,它的优点是重启 Redis 服务后配置不会丢失,缺点是必须重启 Redis 服务,设置才能生效。
LRU 算法和 LFU 算法有什么区别?
LFU 内存淘汰算法是 Redis 4.0 之后新增内存淘汰策略,那为什么要新增这个算法?那肯定是为了解决 LRU 算法的问题。
接下来,就看看这两个算法有什么区别?Redis 又是如何实现这两个算法的?
什么是 LRU 算法?
LRU 全称是 Least Recently Used 翻译为最近最少使用,会选择淘汰最近最少使用的数据。
传统 LRU 算法的实现是基于「链表」结构,链表中的元素按照操作顺序从前往后排列,最新操作的键会被移动到表头,当需要内存淘汰时,只需要删除链表尾部的元素即可,因为链表尾部的元素就代表最久未被使用的元素。
Redis 并没有使用这样的方式实现 LRU 算法,因为传统的 LRU 算法存在两个问题:
- 需要用链表管理所有的缓存数据,这会带来额外的空间开销;
- 当有数据被访问时,需要在链表上把该数据移动到头端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
Redis 是如何实现 LRU 算法的?
Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是在 Redis 的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。
当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
Redis 实现的 LRU 算法的优点:
- 不用为所有的数据维护一个大链表,节省了空间占用;
- 不用在每次数据访问时都移动链表项,提升了缓存的性能;
但是 LRU 算法有一个问题,无法解决缓存污染问题,比如应用一次读取了大量的数据,而这些数据只会被读取这一次,那么这些数据会留存在 Redis 缓存中很长一段时间,造成缓存污染。
因此,在 Redis 4.0 之后引入了 LFU 算法来解决这个问题。
什么是 LFU 算法?
LFU 全称是 Least Frequently Used 翻译为最近最不常用的,LFU 算法是根据数据访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
所以, LFU 算法会记录每个数据的访问次数。当一个数据被再次访问时,就会增加该数据的访问次数。这样就解决了偶尔被访问一次之后,数据留存在缓存中很长一段时间的问题,相比于 LRU 算法也更合理一些。
Redis 是如何实现 LFU 算法的?
LFU 算法相比于 LRU 算法的实现,多记录了「数据的访问频次」的信息。Redis 对象的结构如下:
typedef struct redisObject {
...
// 24 bits,用于记录对象的访问信息
unsigned lru:24;
...
} robj;Redis 对象头中的 lru 字段,在 LRU 算法下和 LFU 算法下使用方式并不相同。
在 LRU 算法中,Redis 对象头的 24 bits 的 lru 字段是用来记录 key 的访问时间戳,因此在 LRU 模式下,Redis可以根据对象头中的 lru 字段记录的值,来比较最后一次 key 的访问时间长,从而淘汰最久未被使用的 key。
在 LFU 算法中,Redis对象头的 24 bits 的 lru 字段被分成两段来存储,高 16bit 存储 ldt(Last Decrement Time),低 8bit 存储 logc(Logistic Counter)。
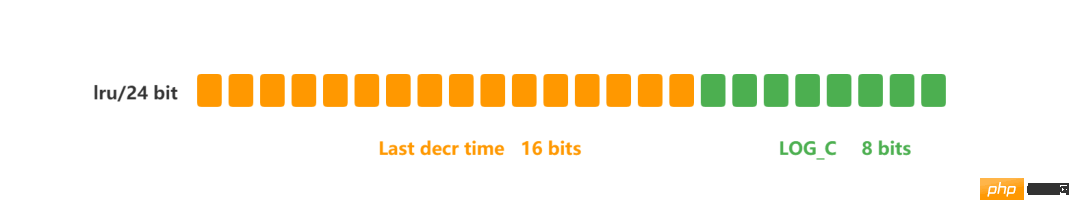
- ldt 是用来记录 key 的访问时间戳;
- logc 是用来记录 key 的访问频次,它的值越小表示使用频率越低,越容易淘汰,每个新加入的 key 的logc 初始值为 5。
注意,logc 并不是单纯的访问次数,而是访问频次(访问频率),因为 logc 会随时间推移而衰减的。
キーにアクセスされるたびに、最初に logc に対して減衰操作が実行されます。減衰の値は、前後のアクセス時間の差に関連します。最後のアクセス時間に大きな差がある場合は、値が大きいほど、この方法で実装された LFU アルゴリズムは、アクセス数だけでなくアクセス頻度に基づいてデータを削除します。アクセス頻度は、キーアクセスが発生する時間を考慮する必要があります。キーへの前回のアクセスが現在時刻から長くなるほど、このキーのアクセス頻度はそれに応じて減少し、削除される可能性が高くなります。
logc の減衰操作が完了したら、logc の増加操作を開始します。増加操作は単純に 1 ではなく、確率に基づいて増加します。logc のキーが大きい場合、logc はより困難になります。増える、増える。
したがって、Redis がキーにアクセスすると、logc は次のように変化します:
- 最初に、最後のアクセスから現在のアクセスまでの時間の長さに応じて logc を減衰します。 #次に、特定の確率に従って logc の値を増やします。
- #redis.conf には、LFU アルゴリズムを調整して logc の増大と減衰を制御するための 2 つの設定項目が用意されています。
lfu-decay-time は、logc の減衰速度を調整するために使用されます。これは分単位の値です。デフォルト値は 1 です。lfu-decay-time 値が大きいほど、減衰は遅くなります。
- lfu-log-factor は logc の増加速度を調整するために使用され、lfu-log-factor の値が大きいほど、logc の増加が遅くなります。
- 概要
Redis で使用される期限切れの削除戦略は「遅延削除と定期的な削除」であり、削除されたオブジェクトは期限切れのキーです。
 メモリ削減戦略は、過剰なメモリの問題を解決するためのものであり、Redis の実行メモリが最大実行メモリを超えると、メモリ削減戦略がトリガーされます。 Redis 4.0 以降に実装された 8 種類のメモリ削減戦略。また、これら 8 種類の戦略を分類します。
メモリ削減戦略は、過剰なメモリの問題を解決するためのものであり、Redis の実行メモリが最大実行メモリを超えると、メモリ削減戦略がトリガーされます。 Redis 4.0 以降に実装された 8 種類のメモリ削減戦略。また、これら 8 種類の戦略を分類します。
## 推奨学習: 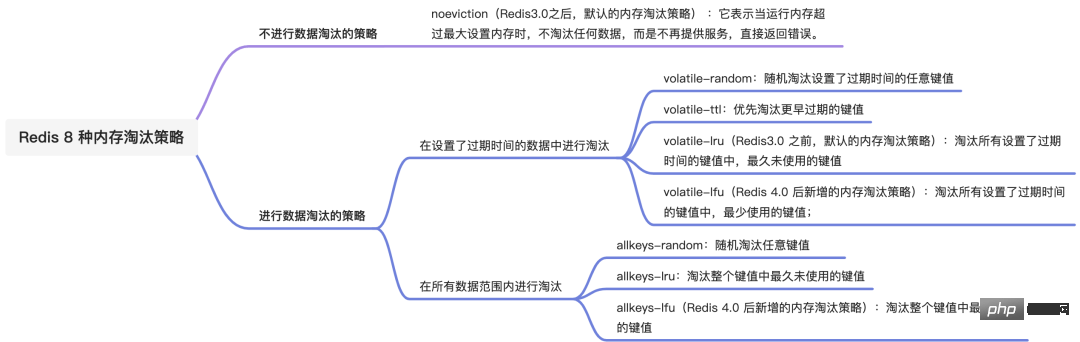 Redis ビデオ チュートリアル
Redis ビデオ チュートリアル
以上がRedis のメモリ削除戦略と期限切れ削除戦略の違いの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7476
7476
 15
1377
52
77
11
19
32
15
1377
52
77
11
19
32

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 Redis-Serverが見つからない場合はどうすればよいですか
Apr 10, 2025 pm 06:54 PM
Redis-Serverが見つからない場合はどうすればよいですか
Apr 10, 2025 pm 06:54 PM
Redis-Serverが見つからない問題を解決するための手順:インストールを確認して、Redisが正しくインストールされていることを確認します。環境変数Redis_hostとredis_portを設定します。 Redis Server Redis-Serverを起動します。サーバーがRedis-Cli pingを実行しているかどうかを確認します。
 Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示するには、3つの方法があります。キーコマンドを使用して、指定されたパターンに一致するすべてのキーを返します。スキャンコマンドを使用してキーを繰り返し、キーのセットを返します。情報コマンドを使用して、キーの総数を取得します。
 Redisのバージョン番号を表示する方法
Apr 10, 2025 pm 05:57 PM
Redisのバージョン番号を表示する方法
Apr 10, 2025 pm 05:57 PM
Redisバージョン番号を表示するには、次の3つの方法を使用できます。(1)情報コマンドを入力し、(2) - versionオプションでサーバーを起動し、(3)構成ファイルを表示します。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisでデータをクリアする方法
Apr 10, 2025 pm 08:03 PM
Redisでデータをクリアする方法
Apr 10, 2025 pm 08:03 PM
次の2つの方法を使用して、Redisのデータをクリアすることができます。Flushallコマンド:データベース内のすべてのキーと値を削除します。 Config ResetStatコマンド:データベースのすべての状態(キー、値、その他の統計を含む)をリセットします。
