

Python クローラーは Web ページのデータをクロールし、データを解析します

この記事では、Python に関する関連知識をお届けします。主に、Python クローラーがどのように Web ページ データをクロールし、データを解析して、クローラーをより効果的に使用して Web ページを分析できるかを紹介します。一緒にやってみましょう。見てください、それが皆さんのお役に立てば幸いです。

Python3 ビデオ チュートリアル ]
1. Web クローラーの基本概念
Web クローラー (Web スパイダーおよびロボットとも呼ばれます) は、クライアントがネットワーク リクエストを送信し、リクエスト応答を受信することをシミュレートし、特定のルールに従ってインターネット情報を自動的に取得するプログラムです。ブラウザができることであれば、原理的にはクローラでもできます。
2. Web クローラーの機能
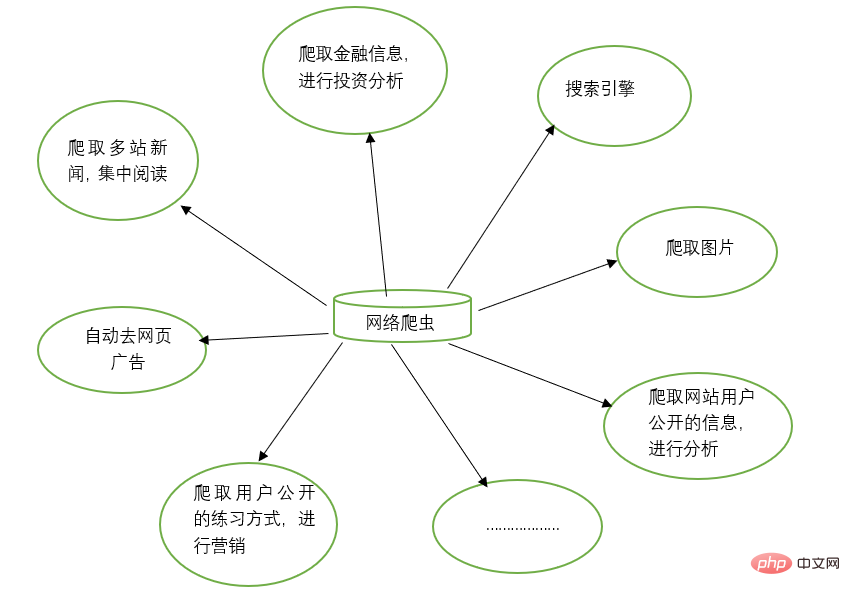
3. サードパーティ ライブラリのインストール
データをクロールしてデータを解析する前に、Python 実行環境にサードパーティ ライブラリ リクエストをダウンロードしてインストールする必要があります。 Windows システムでは、cmd (コマンド プロンプト) インターフェイスを開き、インターフェイスに pip install リクエストを入力し、Enter キーを押してインストールします。 (ネットワーク接続に注意してください) 以下に示すように
4. タオバオのホームページをクロールします# 请求库
import requests
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.textログイン後にコピー
実行結果は図に示すとおりです# 请求库
import requests
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text
5. クロールタオバオのホームページを解析します# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result,'html.parser')
# 具体标签
print("解析后的数据")
print(bs.span)
a={}
# 获取已爬取内容中的script标签内容
data=bs.find_all('script')
# 获取已爬取内容中的td标签内容
data1=bs.find_all('td')
# 循环打印输出
for i in data:
a=i.text
print(i.text,end='')
for j in data1:
print(j.text)ログイン後にコピー
図
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result,'html.parser')
# 具体标签
print("解析后的数据")
print(bs.span)
a={}
# 获取已爬取内容中的script标签内容
data=bs.find_all('script')
# 获取已爬取内容中的td标签内容
data1=bs.find_all('td')
# 循环打印输出
for i in data:
a=i.text
print(i.text,end='')
for j in data1:
print(j.text)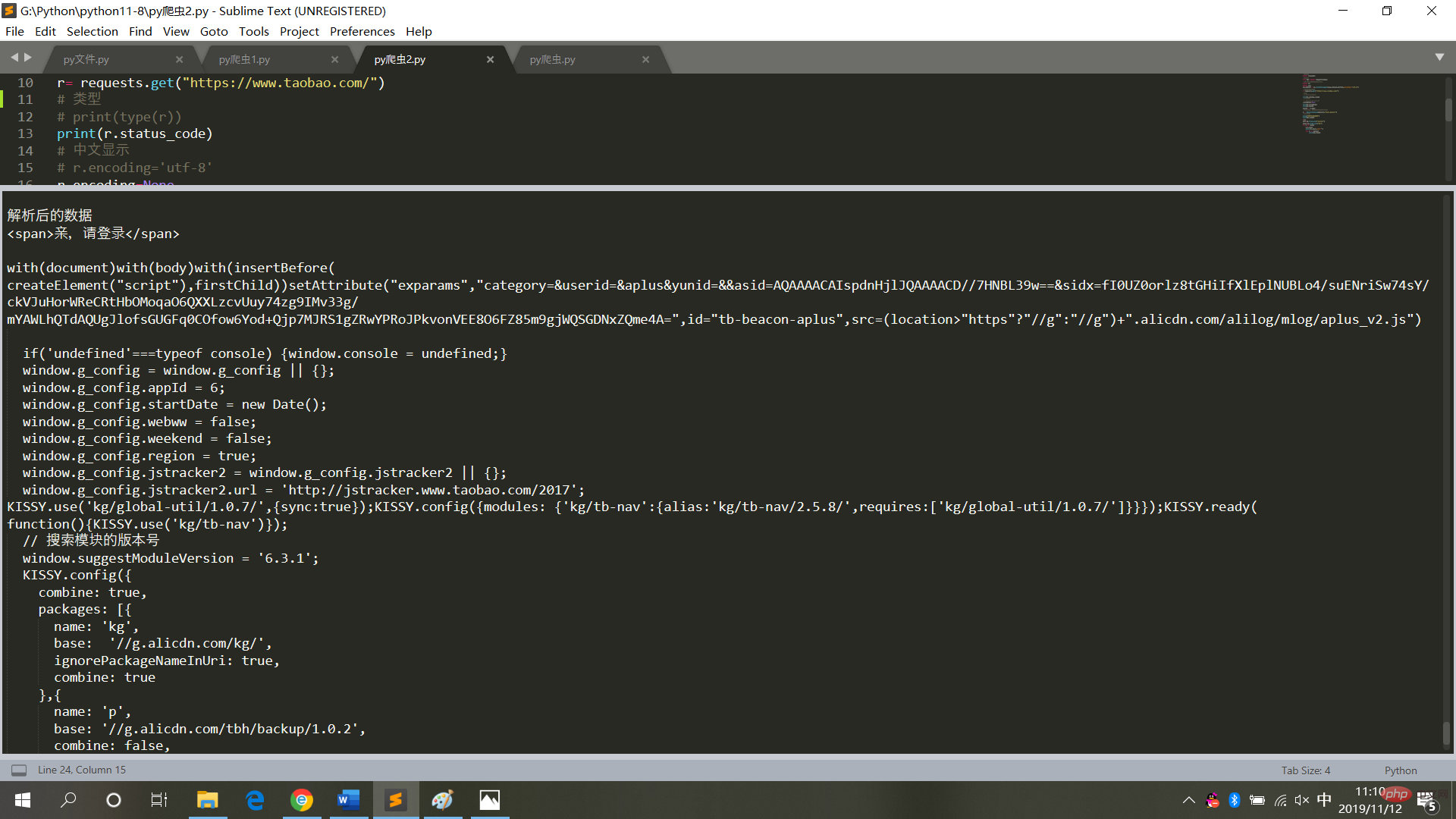
6に示すように、実行結果が表示されます。 Web ページのコードをクロールするときは、頻繁に操作を行わず、無限ループ モードに設定しないでください (各クロールは Web ページへのアクセスであり、頻繁に操作するとシステムがクラッシュし、法的責任が発生します)追求される)。
したがって、Web ページ データを取得した後、それをローカル テキスト モードで保存し、解析します (Web ページにアクセスする必要はなくなります)。 【関連する推奨事項:Python3 ビデオ チュートリアル
]以上がPython クローラーは Web ページのデータをクロールし、データを解析しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7321
7321
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29

 ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
多くのウェブサイト開発者は、ランプアーキテクチャの下でnode.jsまたはPythonサービスを統合する問題に直面しています:既存のランプ(Linux Apache MySQL PHP)アーキテクチャWebサイトのニーズ...
 Scapy Crawlerを使用するときにパイプラインの永続的なストレージファイルを書き込めない理由は何ですか?
Apr 01, 2025 pm 04:03 PM
Scapy Crawlerを使用するときにパイプラインの永続的なストレージファイルを書き込めない理由は何ですか?
Apr 01, 2025 pm 04:03 PM
Scapy Crawlerを使用する場合、パイプラインの永続的なストレージファイルを書くことができない理由は?ディスカッションデータクローラーにScapy Crawlerを使用することを学ぶとき、あなたはしばしば...
 PythonプロセスプールがTCPリクエストを同時に処理し、クライアントが立ち往生する理由は何ですか?
Apr 01, 2025 pm 04:09 PM
PythonプロセスプールがTCPリクエストを同時に処理し、クライアントが立ち往生する理由は何ですか?
Apr 01, 2025 pm 04:09 PM
Python Process Poolは、クライアントが立ち往生する原因となる同時TCP要求を処理します。ネットワークプログラミングにPythonを使用する場合、同時のTCP要求を効率的に処理することが重要です。 ...
 Python functools.partialオブジェクトによって内部的にカプセル化された元の関数を表示する方法は?
Apr 01, 2025 pm 04:15 PM
Python functools.partialオブジェクトによって内部的にカプセル化された元の関数を表示する方法は?
Apr 01, 2025 pm 04:15 PM
python functools.partialオブジェクトのpython functools.partialを使用してPythonを使用する視聴方法を深く探索します。
 Pythonクロスプラットフォームデスクトップアプリケーション開発:どのGUIライブラリが最適ですか?
Apr 01, 2025 pm 05:24 PM
Pythonクロスプラットフォームデスクトップアプリケーション開発:どのGUIライブラリが最適ですか?
Apr 01, 2025 pm 05:24 PM
Pythonクロスプラットフォームデスクトップアプリケーション開発ライブラリの選択多くのPython開発者は、WindowsシステムとLinuxシステムの両方で実行できるデスクトップアプリケーションを開発したいと考えています...
 Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python:Hourglassグラフィック図面と入力検証この記事では、Python NoviceがHourglass Graphic Drawingプログラムで遭遇する可変定義の問題を解決します。コード...
 Pythonで大規模な製品データセットを効率的にカウントしてソートするにはどうすればよいですか?
Apr 01, 2025 pm 08:03 PM
Pythonで大規模な製品データセットを効率的にカウントしてソートするにはどうすればよいですか?
Apr 01, 2025 pm 08:03 PM
データの変換と統計:大規模なデータセットの効率的な処理この記事では、製品情報を含むデータリストを別の含有しているものに変換する方法を詳細に紹介します...
 LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示する際の許可の問題の解決策PythonターミナルでPythonバージョンを表示しようとするとき、Pythonを入力してください...
