

この記事では、Python に関する知識を紹介します。Python 言語を使ってメールの自動ダウンロードや添付ファイルの解析機能を実現する方法を詳しく紹介します。記事内のサンプルコードも詳しく説明しています。見てください。皆さんのお役に立てれば幸いです。

[関連する推奨事項: Python3 ビデオ チュートリアル ]
コーディングを開始する前に、まず 3 つの電子メール サービス プロトコルを理解しましょう :
#1. SMTP プロトコル##SMTP (Simple Mail Transfer Protocol)、単純なメール転送プロトコルです。中継局に相当し、クライアントにメールを送信します。
2. POP3 プロトコルポスト オフィス プロトコルの 3 番目のバージョンである POP3 (ポスト オフィス プロトコル 3) は、電子メールの最初のオフライン プロトコル標準です。このプロトコルは電子メールをローカル コンピュータにダウンロードし、サーバーと同期しないため、電子メールを紛失したり、同じ電子メールを複数回ダウンロードしたりする可能性が高くなるという欠点があります。
3. IMAP プロトコルIMAP (Internet Mail Access Protocol)、対話型メール アクセス プロトコルです。このプロトコルは、リモート メールボックスに接続して直接操作し、コンテンツをサーバーと同期します。
次に、電子メール パッケージを紹介します。このパッケージの中心的なコンポーネントは、電子メール メッセージを表す「オブジェクト モデル」です。アプリケーションは、主にメッセージ サブモジュールで定義されたオブジェクト モデル インターフェイスを通じてこのパッケージと対話します。アプリケーションはこの API を使用して、既存の電子メールについて質問したり、新しい電子メールを作成したり、同じオブジェクト モデル インターフェイスを使用する電子メール サブコンポーネントを追加または削除したりできます。つまり、電子メール メッセージとその MIME サブコンポーネントの性質に従って、電子メール オブジェクト モデルは、EmailMessage API を提供するすべてのオブジェクトのツリー構造になります。
次に、特定のコードを使用して、電子メール クライアントへのログイン、電子メールのダウンロード、電子メールの添付ファイルの内容の解析の機能を実装します。
最初に、電子メール解析クラスを定義する必要がありますが、これには 3 つの変数が必要です:
1. 電子メールが属する imap サービス アドレス;
2. 電子メール アカウント;
1. 電子メールが属する imap サービス アドレス。
3. 電子メールのパスワード [注: 電子メール アドレスが異なれば、セキュリティ ポリシーも異なります。たとえば、qq 電子メールでは、リモート クライアントにログインするためのクリア テキスト パスワードではなく、ログイン認証コードを取得するために SMS 認証が必要です]
class Email_parse:
def __init__(self,remote_server_url,email_url,password):
# imap服务地址
self.remote_server_url = remote_server_url
# 邮箱账号
self.email_url = email_url
# 邮箱密码
self.password = password次に、クラスにエントリ関数を定義し、リモートでログインし、デフォルトで最初のページにあるすべてのメールを取得します。電子メールの件名を取得して印刷します [電子メールの件名のエンコードは異なる場合があり、正しく表示するにはバイナリをトランスコードする必要があります]
def main_parse_Email(self):
"""入口函数,登录imap服务"""
server = imaplib.IMAP4_SSL(self.remote_server_url, 993)
server.login(self.email_url, self.password)
server.select('INBOX')
status,data = server.search(None,"ALL")
if status != 'OK':
raise Exception('read email error')
emailids = data[0].split()
mail_counts = len(emailids)
print("count:",mail_counts)
# 邮件的遍历是按时间从后往前,这里我们选择最新的一封邮件
for i in range(mail_counts - 1, mail_counts - 2, -1):
status, edata = server.fetch(emailids[i], '(RFC822)')
msg = email.message_from_bytes(edata[0][1])
#获取邮件主题title
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)その中で、msg 変数は本文を保存します。メッセージとティルトを行うには、メッセージとタイトルを返すクラス関数を構築します。
def get_email_title(msg):
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
return titleメールを解析する際、メール本文 [HTML] と添付ファイル [xlsx など] の 2 つの部分に分割し、添付ファイルがあると判断した場合は、固定パス。テーブルの解析については詳しく説明しませんが、パンダなどのパッケージで十分に処理できます。
def get_att(msg):
"""获取附件并下载"""
filename = Email_parse.get_email_name(msg)
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
data = part.get_payload(decode=True)
if data != None:
att_file = open('./src/' + filename, 'wb')
att_file.write(data)
att_file.close()
else:
passメール本文のコンテンツについては、HTML を直接解析し、読みやすいようにテキスト コンテンツを .txt ファイルに直接保存します。
def get_text_from_HTML(msg):
"""获取邮件中的html"""
filename = Email_parse.get_email_name(msg)
current_title = Email_parse.get_email_title(msg)
print("filename:",filename,type(filename))
for part in msg.walk():
if not part.is_multipart():
result = part.get_payload(decode=True)
result = result.decode('gbk')
f = open(f'./src/{current_title}.txt','w')
f.write(result)
f.close()
return result完全なコードは次のとおりです:
import email
import imaplib
from email.header import decode_header
import pandas as pd
import datetime
class Email_parse:
def __init__(self,remote_server_url,email_url,password):
self.remote_server_url = remote_server_url
self.email_url = email_url
self.password = password
def get_att(msg):
filename = Email_parse.get_email_name(msg)
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
data = part.get_payload(decode=True)
if data != None:
att_file = open('./src/' + filename, 'wb')
att_file.write(data)
att_file.close()
else:
pass
def get_email_title(msg):
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
return title
def get_email_name(msg):
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
h = email.header.Header(file_name)
dh = email.header.decode_header(h)
filename = dh[0][0]
if dh[0][1]:
value, charset = decode_header(str(filename, dh[0][1]))[0]
if charset:
filename = value.decode(charset)
print("附件名称:", filename)
return filename
def main_parse_Email(self):
server = imaplib.IMAP4_SSL(self.remote_server_url, 993)
server.login(self.email_url, self.password)
server.select('INBOX')
status,data = server.search(None,"ALL")
if status != 'OK':
raise Exception('read email error')
emailids = data[0].split()
mail_counts = len(emailids)
print("count:",mail_counts)
for i in range(mail_counts - 1, mail_counts - 2, -1):
status, edata = server.fetch(emailids[i], '(RFC822)')
msg = email.message_from_bytes(edata[0][1])
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
Email_parse.get_att(msg)
Email_parse.get_text_from_HTML(msg)
def get_text_from_HTML(msg):
filename = Email_parse.get_email_name(msg)
current_title = Email_parse.get_email_title(msg)
print("filename:",filename,type(filename))
for part in msg.walk():
if not part.is_multipart():
result = part.get_payload(decode=True)
result = result.decode('gbk')
f = open(f'./src/{current_title}.txt','w')
f.write(result)
f.close()
return result
if __name__ == "__main__":
remote_server_url = 'imap.qq.com'
email_url = "*********@qq.com"
password = "**********"
demo = Email_parse(remote_server_url,email_url,password)
demo.main_parse_Email()実行結果:
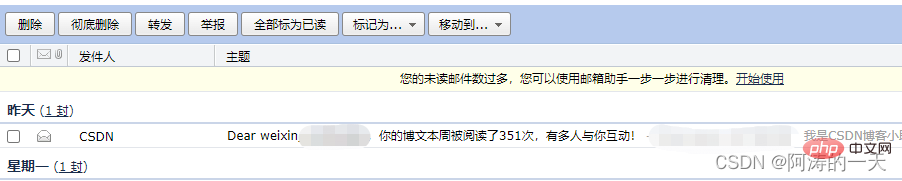
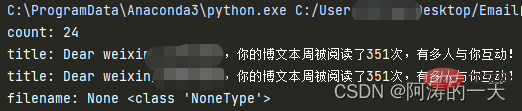
[関連推奨事項:Python3 ビデオ チュートリアル ]
以上がPythonでメールを自動ダウンロードする例を簡単に紹介しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



