

ファイル作成時にエンコーディングを指定するJava実装方法

この記事では、ファイル作成時のエンコーディングを指定するJavaの実装方法を中心に、サンプルコードを交えて詳しく紹介するjavaに関する知識を提供するので、どなたにも役立ちます。勉強や仕事をする上で参考になる内容ですので、皆様のお役に立てれば幸いです。

推奨学習: 「java ビデオ チュートリアル 」
前書き: 最近、Java IO ストリームに関する知識を学びました。文書を読んだり書いたりすることで、学んだ知識を練習して定着させたいと考えています。 File クラスを使用してファイルを作成するときに、ファイルで使用されるエンコーディングをどのように指定すればよいのかをふと考えました。そこで、ファイルのエンコードを確認するにはどうすればよいのかと考えました。
1. 問題の分析
まず、インターネットにアクセスして答えを見つけます。結果は次のとおりです:
FileInputStream fis=new FileInputStream(“xxxx.txt”); OutputStreamWriter osw=new OutputStreamWriter(fis,“UTF-8”);
上記のコードは、おそらく、ファイルを書き込むときに、 UTF-8で書かれた文字が思っていたものと違うので、ファイル作成時にエンコードを指定したい。以下のように、
File myfile = new File("test.txt”, “UTF-8”);
if (!myfile.exists()) myfile.createNewFile();そこで、Java API 8 の公式ドキュメントを確認してみました。 ファイルには、文字エンコーディングを指定できるコンストラクターが提供されていません。

同時に、set や get などの文字エンコーディングにアクセスする他のメソッドは提供されていません。これは、文字エンコーディングがファイルの固有のプロパティではないことを示しています。 。ファイルの作成時間、ファイルの変更時間、読み取り可能、書き込み可能、実行可能かどうかなど、これらはファイルの固有の属性、またはメタ情報であり、ファイルの一部です。
2. 文字エンコード
コンピュータに保存されている情報はすべて 01 の文字列であり、テキストも例外ではありません。
文字の処理には 2 つのプロセスが含まれます。 エンコードとデコード
エンコード: 文字を 01 文字列に「マッピング」します。
デコード: 01文字列は文字
に「マップ」されます。GBK や UTF-8 などの文字エンコードが異なると、エンコードとデコードに異なるルールが使用されます。
同じテキスト文字列: 「中国」の場合、UTF-8 エンコーディングを使用して保存します。通常、中国語の文字 (基になる 01 文字列の 16 進数形式) を保存するには 3 バイトが使用されます。
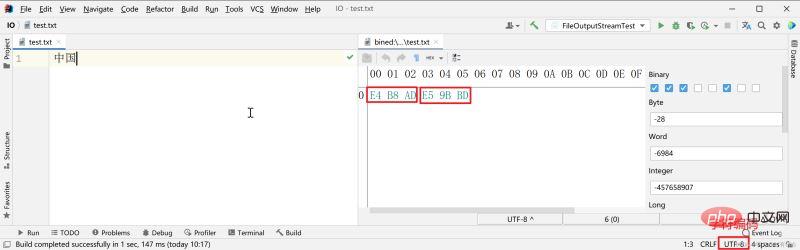
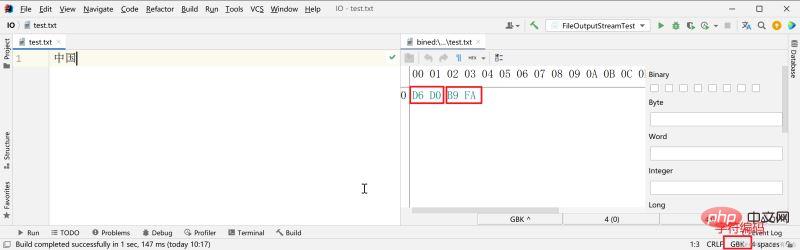
GBK エンコードを使用して保存し、中国語の文字を表す 2 バイトを使用します。
テキスト エディターでテキストを作成して保存すると、エディターは設定した文字エンコード タイプに従ってテキストを 01 文字列に「マッピング」します。
設定した文字タイプは、エディタがテキストを 10 個の文字列にエンコードするための単なる変換ルールであり、テキストの属性ではありません。
エディターがテキスト ファイルを開くと、基になる 01 文字列ではなくテキストが表示されます。これは、エディターが特定のテキスト エンコーディングを使用して 01 文字列を文字にデコードするためです。デコード時に使用される文字エンコードが一貫しているか、そのエンコードと互換性がある場合、テキストは正しく表示されます。デコード時の文字エンコーディングが一致していない、またはエンコーディングと互換性がない場合、文字化けが発生します。
たとえば、GBK エンコードを使用したテキスト ファイルがあります。内容は「明るい月はいつ出ますか」というものです。

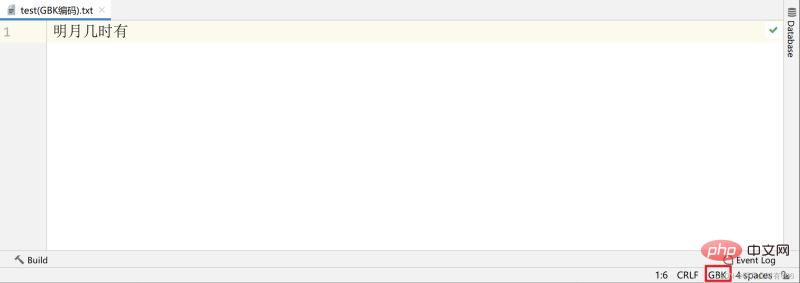
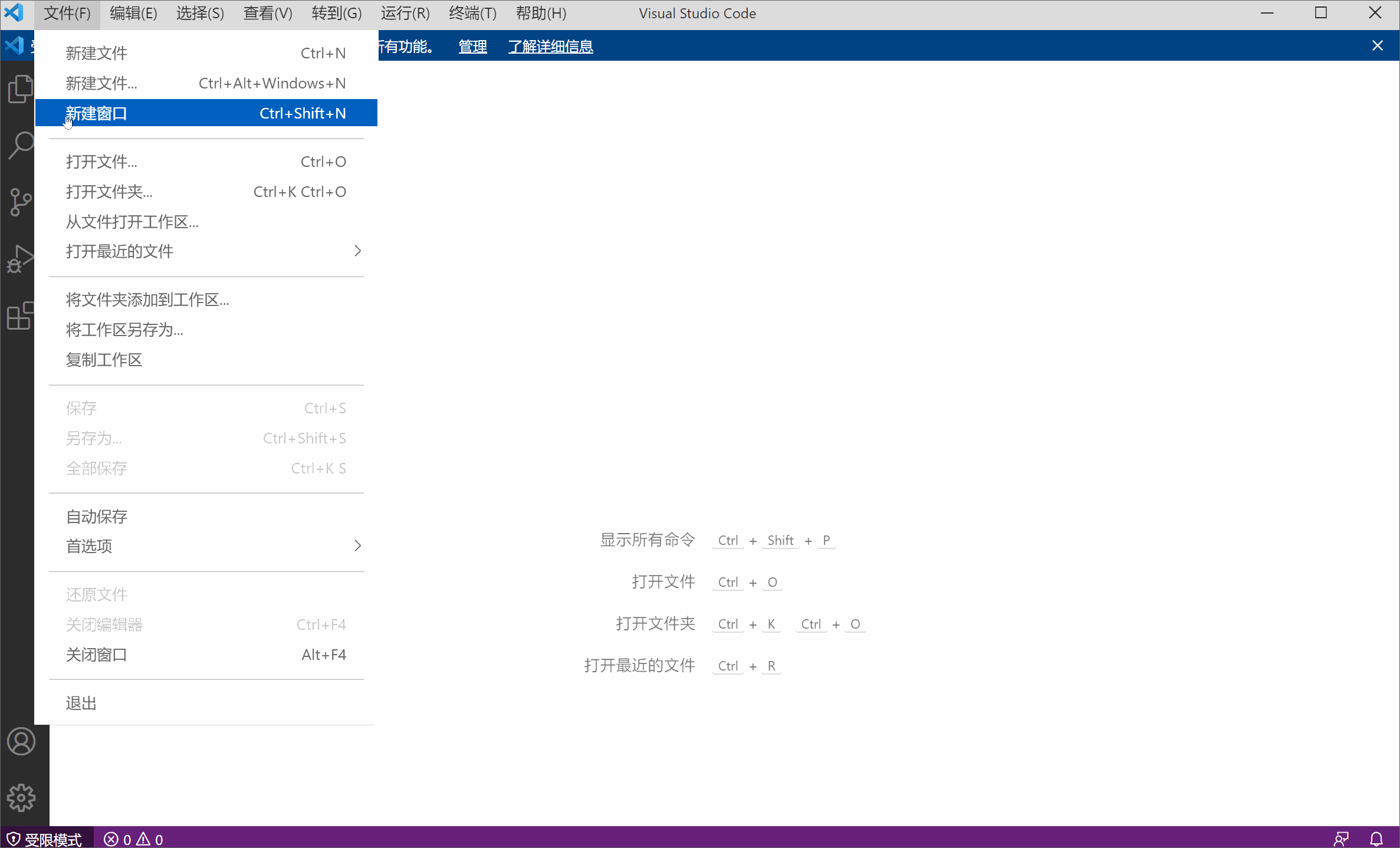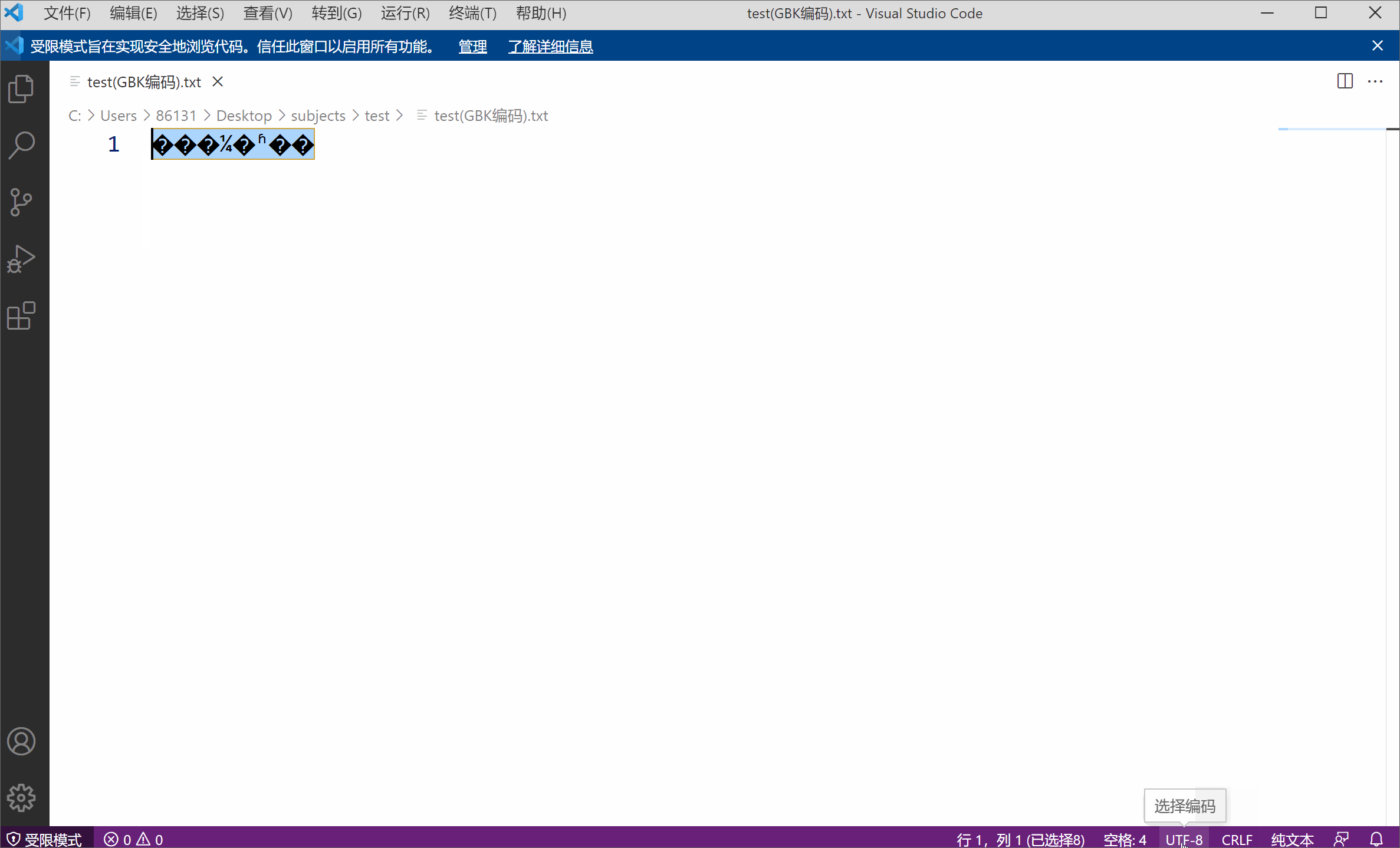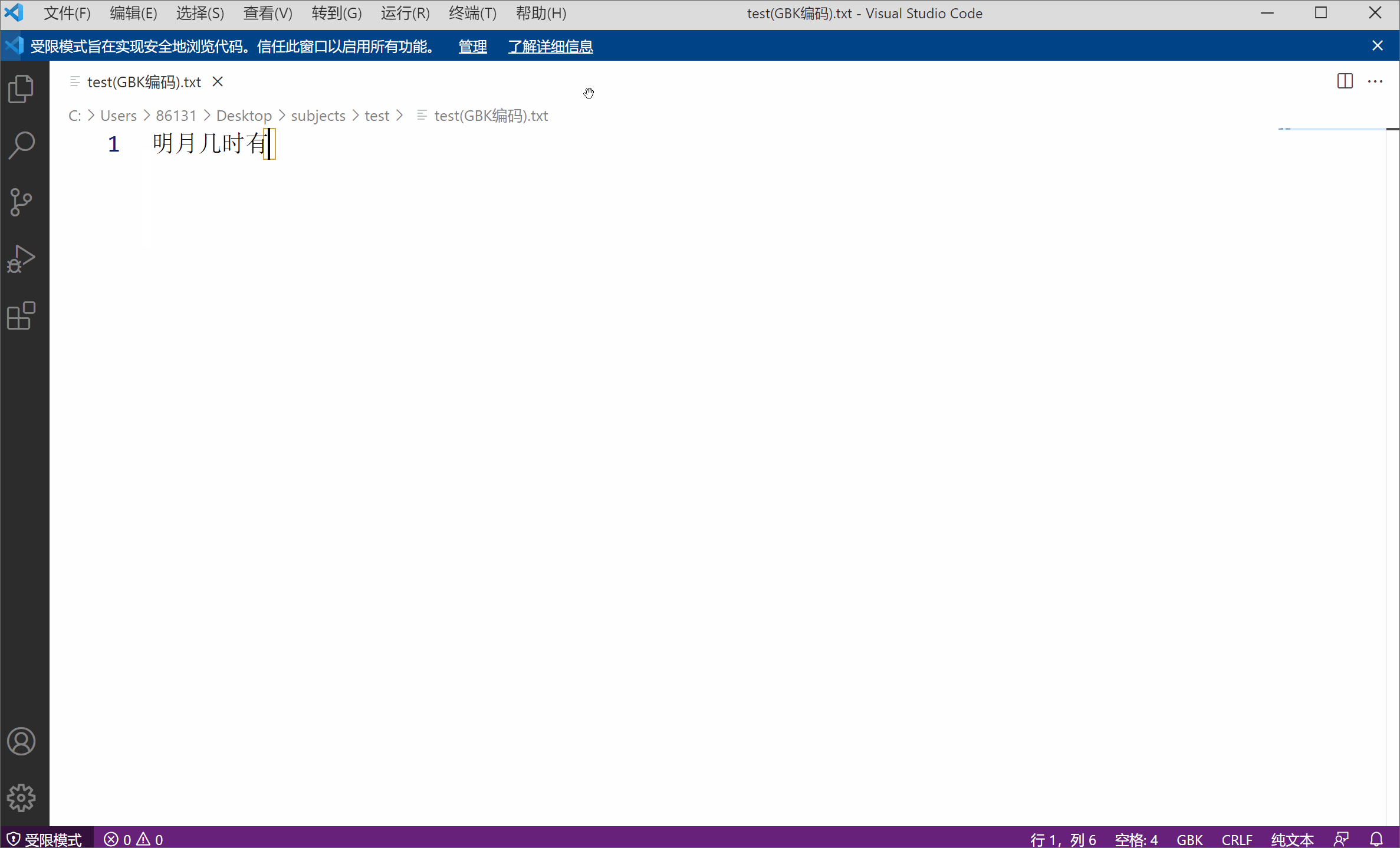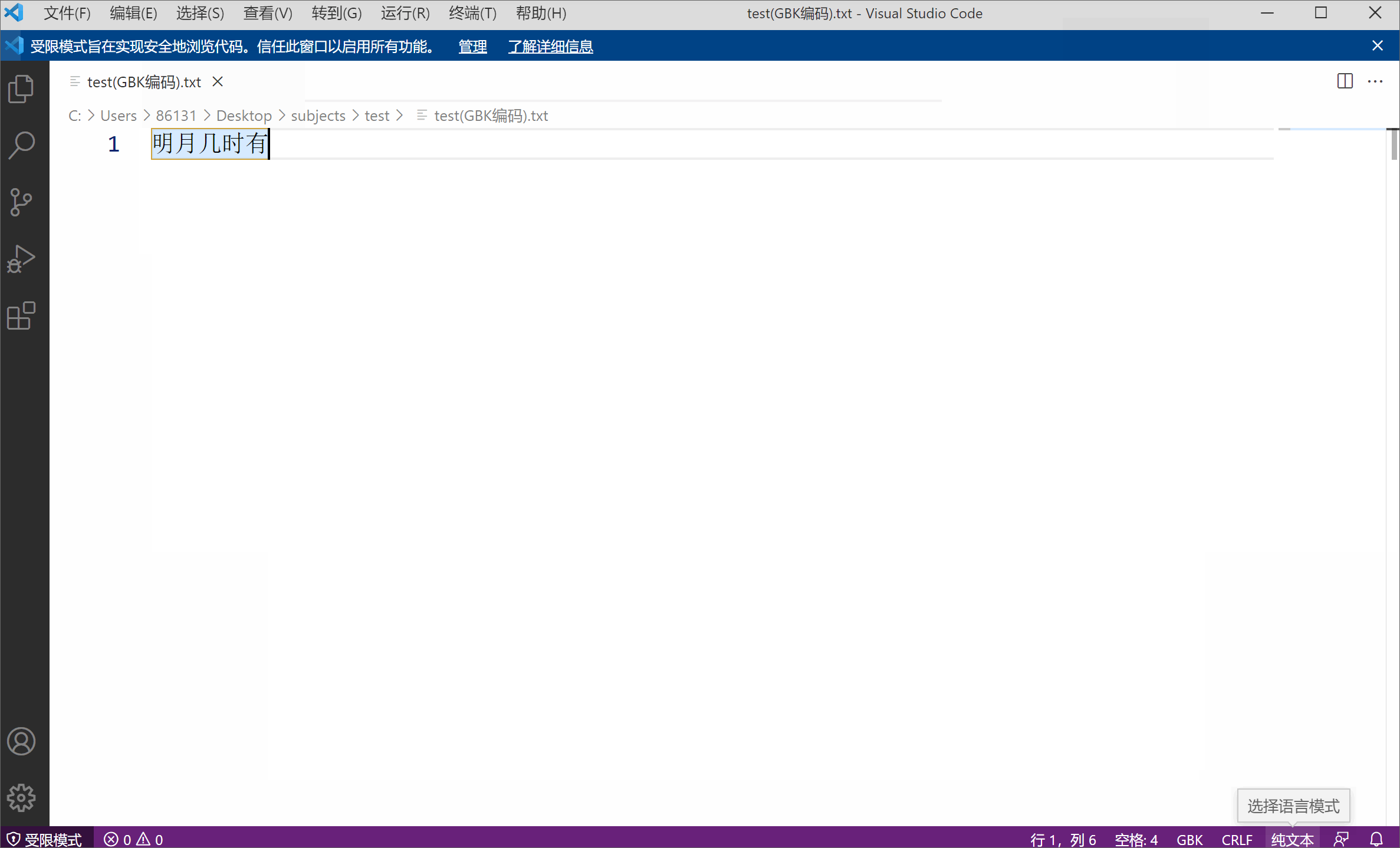
文字エンコーディングがファイル の固有の属性ではないことを側面から示しています。
私はこの点を説明するためだけにこれまで多くのことを話しました:文字エンコーディングはデコードおよびエンコード時に使用されるルールであり、ファイルの固有の属性ではありません。
なぜファイル属性の一部として文字エンコーディングを設定しなかったのか疑問に思わずにはいられません。GBK に設定して設定できると仮定すると、オペレーティング システムはその機能を維持する必要があります。ファイルが書き込みできないのと同じように、プログラムがファイルに書き込もうとすると、オペレーティング システムは書き込みを拒否します。オペレーティング システムが書き込む必要があるバイトは GBK エンコード要件を満たしている必要があります。その後、バイトが書き込まれるたびに、オペレーティング システムが一部の特殊なバイトは GBK または UTF-8 のいずれかを表す可能性があり、曖昧であるため、バイトの正当性のチェックには非常に大きなパフォーマンス オーバーヘッドが必要であり、実装すら不可能です。さて、これを行う意味は何でしょうか? ファイルを開くときにエディターがエンコードのプロパティに基づいて正しいエンコードを選択できるようにするためでしょうか?スマートなエディターは、コンテンツの最初の数バイトに基づいて、01 文字列が使用するエンコーディングを推測できます。また、デコードに使用する文字エンコードを手動で設定することもできます。
3. 問題解決方法
ファイル作成時にファイルのエンコーディングを指定できません。テキストをファイルに書き込むとき (たとえば、テキスト エディターの Ctrl S を押して保存します。これは基本的に書き込み操作を実行します)、テキストを 01 文字列のエンコード ルールに変換することを選択できます。
FileInputStream fis=new FileInputStream(“xxxx.txt”); OutputStreamWriter osw=new OutputStreamWriter(fis,“UTF-8”);
java ビデオ チュートリアル "
以上がファイル作成時にエンコーディングを指定するJava実装方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7465
7465
 15
1376
52
77
11
18
19
15
1376
52
77
11
18
19



 Java の乱数ジェネレーター
Aug 30, 2024 pm 04:27 PM
Java の乱数ジェネレーター
Aug 30, 2024 pm 04:27 PM
Java の乱数ジェネレーターのガイド。ここでは、Java の関数について例を挙げて説明し、2 つの異なるジェネレーターについて例を挙げて説明します。
 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
