

MySQL で実行計画を表示する方法


推奨される学習: mysql ビデオ チュートリアル
Explain キーワードを使用して、SQL クエリ ステートメントを実行するオプティマイザをシミュレートします。 MySQL は、SQL ステートメントを処理し、クエリ ステートメントやテーブル構造のパフォーマンスのボトルネックを分析する方法です。
#実行計画に含まれる情報の説明
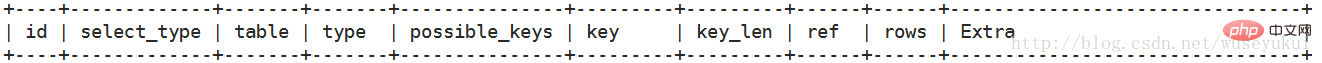
#最も重要なフィールドは次のとおりです: id、type、key、rows、Extra
each 詳細なフィールドの説明
id
クエリ内で選択句または操作テーブルが実行される順序を示す、一連の番号を含む選択クエリ シーケンス番号
3 つの状況:
1. 同じ ID: 上から下への実行順序

2. 異なる ID: 子の場合 クエリの場合、id の通し番号が大きくなり、id の値が大きいほど優先度が高く、より早く実行されます。
#3. ID は同じですが異なります (両方のケースが同時に存在します): ID が同じ場合、グループとみなされ、上から下へ順番に実行されます。すべてのグループで、ID 値が大きいほど優先順位が高く、より早く実行されます。 
select_type
クエリのタイプは主に次の目的で使用されます。通常のクエリ、結合クエリ、サブクエリなどの複雑なクエリを区別します。
: 単純な選択クエリ。クエリにはサブクエリやユニオンが含まれません
- 2. PRIMARY: クエリには複雑なサブパートが含まれており、最も外側のクエリはプライマリとしてマークされます
- 3. SUBQUERY: サブクエリは選択に含まれます
- 4. DERIVED: サブクエリが from リストに含まれています。派生としてマークされ、MySQL またはこれらのサブクエリが再帰的に実行され、結果がゼロ タイム テーブル
- 5, UNION: 2 番目の選択がユニオンの後に出現する場合は、ユニオンとしてマークされます。ユニオンが from 句のサブクエリに含まれる場合、外側の選択は派生 としてマークされます。
- 6, UNION RESULT: ユニオン テーブルから結果を取得する場合に選択します。
- type
アクセス タイプ、 SQL クエリの最適化における非常に重要な指標である、結果の値は最良から最悪まで次のとおりです。 
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般的に言えば、優れた SQL クエリは少なくとも範囲レベルに達し、できれば ref# に達します。
#1. system: テーブルには 1 行のレコード (システム テーブルと同じ) しかありません。これは const 型の特殊なケースであり、通常は表示されず、次のようにすることができます。無視されます
2. const: インデックスを通じて 1 回見つかったことを意味し、const は主キーまたは一意のインデックスを比較するために使用されます。 1 行のデータを照合するだけなので、非常に高速です。主キーが where リストに配置されている場合、mysql はクエリを const
##3, eq_ref: For each の一意のインデックス スキャンに変換できます。インデックス キーに一致するのはテーブル内の 1 つのレコードのみです。主キーまたは一意のインデックスのスキャンでよく見られます。

注: t1 テーブル
4、ref など、レコードが最も少ないテーブルの全テーブル スキャン:非固有インデックス スキャンして、単一の値に一致するすべての行を返します。基本的に、これは単一の値に一致するすべての行を返すインデックス アクセスでもありますが、条件を満たす複数の行が見つかる場合があるため、検索とスキャンを組み合わせて行う必要があります
5, range: インデックスを使用して行を選択し、指定された範囲内の行のみを取得します。キー列は、どのインデックスが使用されているかを示します。一般に、bettween、、in などのクエリは where ステートメントに現れます。インデックス列に対するこの範囲スキャンは、完全なインデックス スキャンよりも優れています。インデックス全体をスキャンする必要はなく、特定のポイントで開始し、別のポイントで終了するだけで済みます。

6,index
: フル インデックス スキャン、インデックスおよび ALL 違いは、インデックス タイプがインデックス ツリーのみをトラバースすることです。インデックス ファイルは通常データ ファイルよりも小さいため、これは通常 ALL ブロックです。 (Index と ALL は両方ともテーブル全体を読み取りますが、index はインデックスから読み取られ、ALL はハードディスクから読み取られます)
7, ALL
: フル テーブル スキャン。テーブル全体を走査して一致する行を検索します。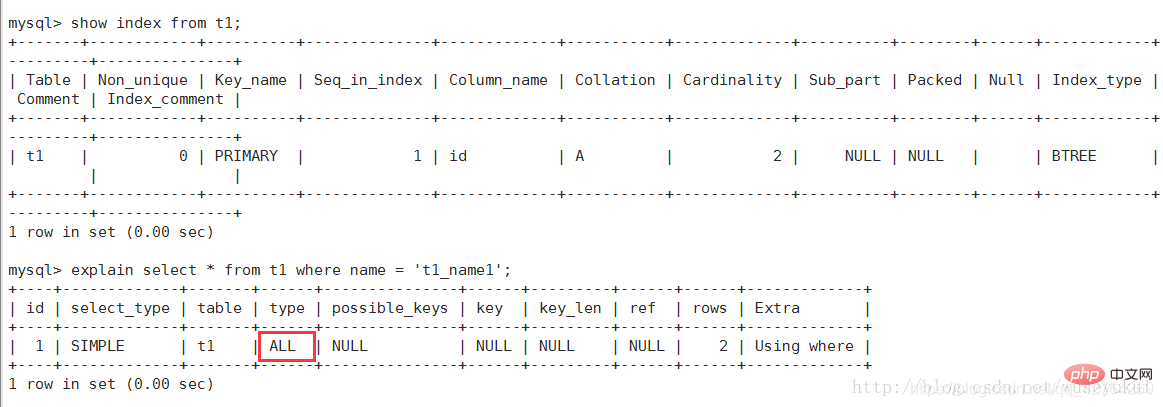
#カバリング インデックスがクエリで使用されている場合、インデックスはキー リストにのみ表示されます
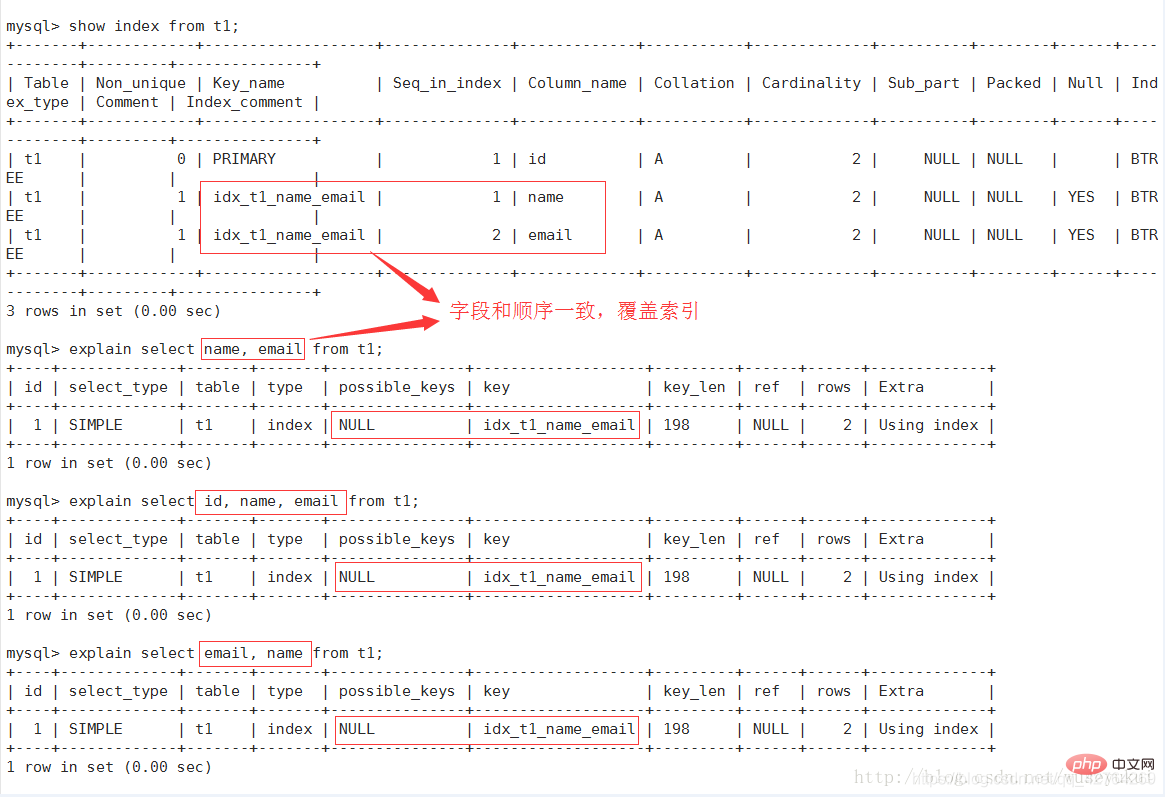

key_len は、実際に使用される長さではなく、インデックスで使用されるバイト数とクエリで使用されるインデックスの長さ (可能な最大長) を示します。長ければ長いほど良いです。 key_len はテーブルから取得するのではなく、テーブル定義に基づいて計算されます。refインデックスを示す列が使用されます。可能であれば定数 const です。 rowsテーブル統計とインデックス選択に基づいて、必要なレコードを見つけるために読み取る必要がある行数を大まかに見積もります追加他のフィールドでの表示には適していませんが、非常に重要な追加情報
1. filesort:
mysql の使用では、並べ替えではなく、外部インデックスを使用してデータを並べ替えます。テーブル内のインデックスはソートされた読み取りを実行します。つまり、mysql はインデックスを使用して「ファイルの並べ替え」になる並べ替え操作を完了することはできません。
2. 一時テーブルの使用:
一時テーブルを使用して、中間結果を保存します。つまり、mysql はクエリ結果を並べ替えるときに一時テーブルを使用します。これは、order by および group by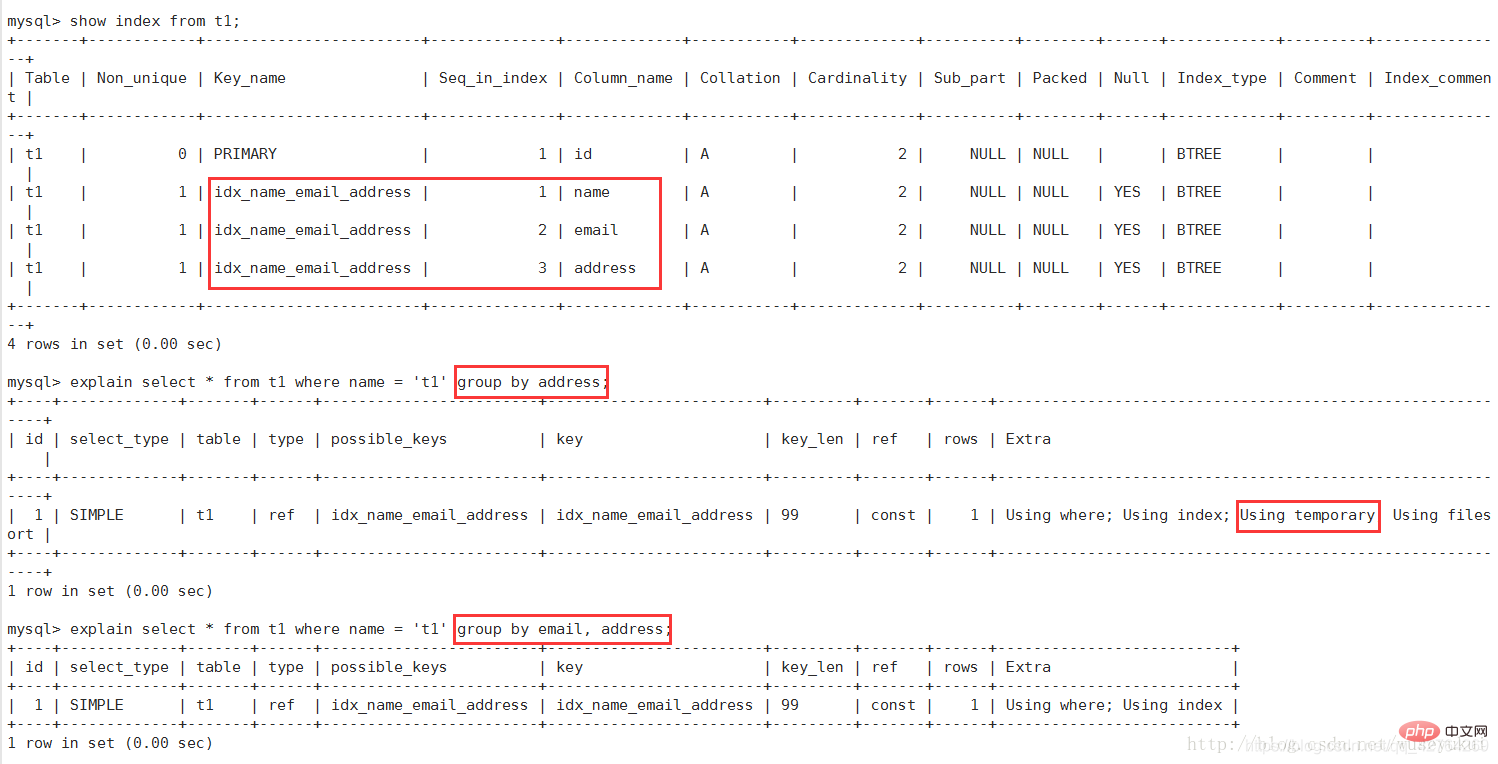
3 で一般的です。インデックスの使用:
Covering Index
(Covering Index) が対応する選択操作で使用され、テーブルのデータ行へのアクセスが回避され、非常に効率的であることを示します。 #Using where が同時に表示されている場合は、そのインデックスがインデックスキー値の検索に使用されていることを示します(上図参照)使用されておらず、「Using where」の場合同時に表示される場合は、インデックスが検索アクションの実行ではなくデータの読み取りに使用されることを示します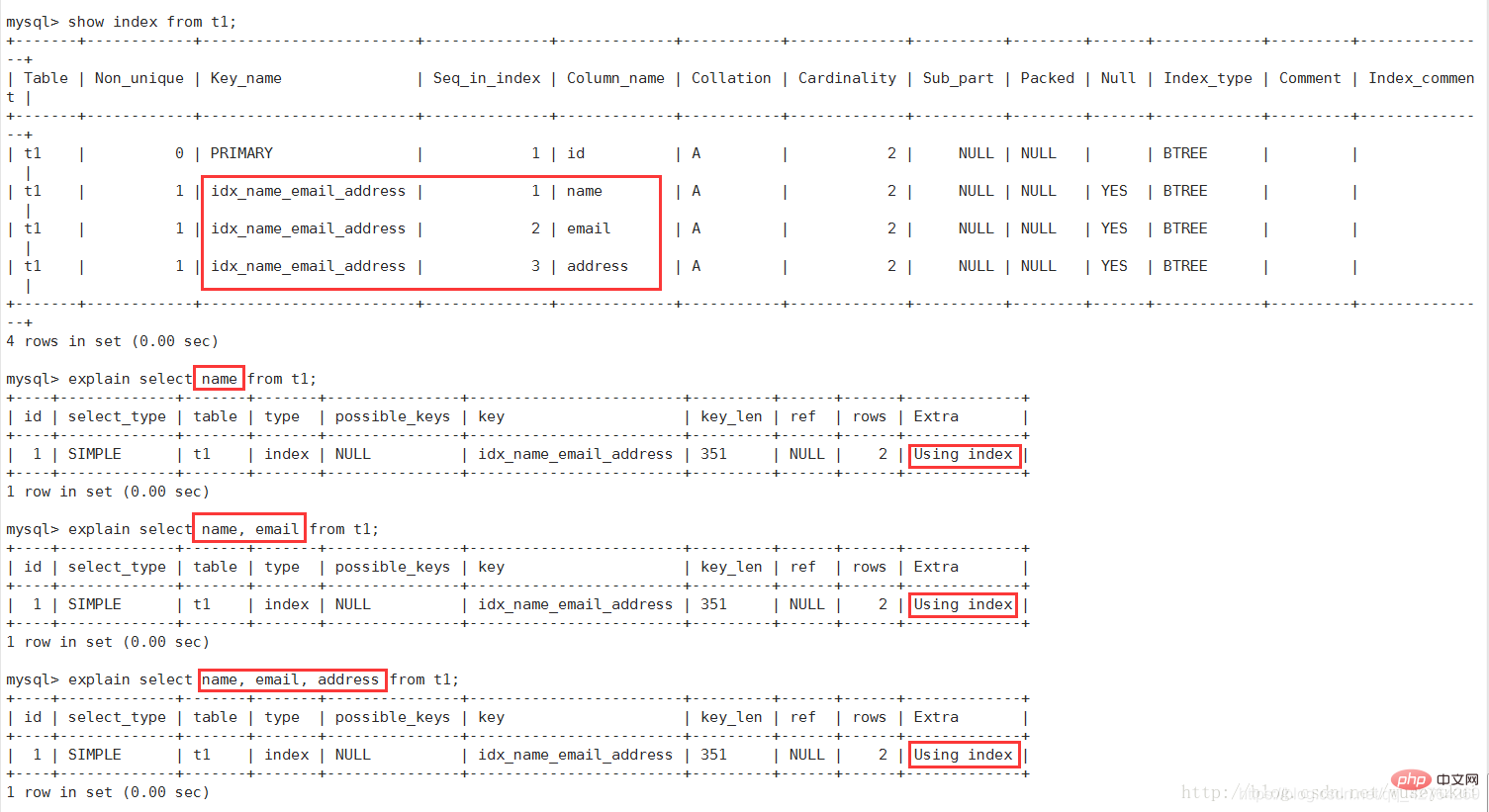
Covering Index (Covering Index):インデックスカバレッジと呼ばれます。選択リスト内のフィールドはインデックスからのみ取得できます。インデックスに従ってデータ ファイルを再度読み取る必要はありません。つまり、 クエリ列は構築されたインデックスでカバーされている必要があります 。
注:- a. カバーインデックスを使用する必要がある場合は、選択リストのフィールドから必要な列のみを取り出してください。選択 *
- は使用しないでください。 b. すべてのフィールドにインデックスを作成すると、インデックス ファイルが大きくなりすぎるため、パフォーマンスが低下します
4. where の使用:
where フィルタリングの使用5. 結合バッファの使用:
リンク キャッシュの使用##6. 不可能な WHERE:where 句 値は常に false であり、先祖を取得するために使用することはできません
 ##7. 最適化されたテーブルを選択します:
##7. 最適化されたテーブルを選択します:
group by なし 句の場合、インデックスに基づいて MIN/MAX 演算を最適化するか、MyISAM ストレージ エンジンの COUNT(*) 演算を最適化すると、計算を実行する実行フェーズまで待つ必要がありません。最適化は、クエリ実行プランの生成フェーズ中に完了できます
8. 個別:
個別の操作を最適化し、最初に一致する祖先を見つけた後は同等の価値のあるアクションの検索を停止します
包括的なケース

実行シーケンス
1 (id = 4), [select id, name from t2]: select_typeはunion、idを指定=4 の選択は、結合内の 2 番目の選択です。
2 (id = 3), [select id, name from t1 where address = '11']: これは from ステートメントに含まれるサブクエリであるため、DERIVED (派生) としてマークされます。 = '11' は複合インデックス idx_name_email_address を通じて取得できるため、タイプはインデックスです。
3 (id = 2), [select id from t3]: select に含まれるサブクエリであるため、SUBQUERY とマークされます。
4 (id = 1), [select d1.name, … d2 from … d1]: select_type は PRIMARY です。これは、クエリが最も外側のクエリであり、テーブル列が「derived3」としてマークされていることを意味します。これは、クエリ結果が派生テーブルから取得されることを意味します (id = 3 の結果を選択)。
5 (id = NULL), [... Union...]: ユニオンの一時テーブルから行を読み取る段階を表します。テーブル列の「ユニオン 1, 4」は、id=1 およびユニオン 4 を意味します。 id=4 選択結果に対してユニオン演算を実行します。
推奨学習: mysql ビデオ チュートリアル
以上がMySQL で実行計画を表示する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7488
7488
 15
1377
52
77
11
19
40
15
1377
52
77
11
19
40

 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICATでデータベースパスワードを取得できますか?
Apr 08, 2025 pm 09:51 PM
NAVICAT自体はデータベースパスワードを保存せず、暗号化されたパスワードのみを取得できます。解決策:1。パスワードマネージャーを確認します。 2。NAVICATの「パスワードを記憶する」機能を確認します。 3.データベースパスワードをリセットします。 4.データベース管理者に連絡してください。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 MariadBのNAVICATでデータベースパスワードを表示する方法は?
Apr 08, 2025 pm 09:18 PM
MariadBのNAVICATでデータベースパスワードを表示する方法は?
Apr 08, 2025 pm 09:18 PM
Passwordが暗号化された形式で保存されているため、MariadbのNavicatはデータベースパスワードを直接表示できません。データベースのセキュリティを確保するには、パスワードをリセットするには3つの方法があります。NAVICATを介してパスワードをリセットし、複雑なパスワードを設定します。構成ファイルを表示します(推奨されていない、高リスク)。システムコマンドラインツールを使用します(推奨されません。コマンドラインツールに習熟する必要があります)。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する手順:データベースに接続します。 SQLエディターウィンドウを作成します。 SQLクエリまたはスクリプトを書きます。 [実行]ボタンをクリックして、クエリまたはスクリプトを実行します。結果を表示します(クエリが実行された場合)。
