

SQL のウィンドウ関数を 1 つの記事で理解する

この記事では、SQL サーバー に関する関連知識を提供します。分析関数とも呼ばれるウィンドウ関数には 2 種類あり、1 つは集計ウィンドウ関数、もう 1 つは並べ替えウィンドウ関数です。以下の記事では SQL のウィンドウ関数に関する関連情報を中心に、サンプルコードを通して詳しく紹介していますので、必要な方は参考にしてください。

推奨学習: 「SQL チュートリアル 」
OVER の定義
OVER は行の定義に使用されます。値のセットを操作する Window は、データをグループ化するために GROUP BY 句を使用する必要がなく、同じ行内の基本行列と集計列の両方を返すことができます。
OVER 構文
OVER ( [ PARTITION BY column ] [ ORDER BY culumn ] )
グループ化のための PARTITION BY 句;
ORDER BY 句を使用して並べ替えます。
ウィンドウ関数 OVER() は行のセットを指定し、ウィンドウ関数はウィンドウ関数から出力された結果セット内の各行の値を計算します。
ウィンドウ関数は、GROUP BY を使用せずにデータをグループ化でき、ベース行の列と集計列を同時に返すこともできます。
OVER の使用法
OVER ウィンドウ関数は、集計関数または並べ替え関数と併用する必要があります。集計関数とは、一般に SUM()、MAX()、MIN、COUNT()、AVG( ) およびその他の一般的な関数。並べ替え関数は通常、RANK()、ROW_NUMBER()、DENSE_RANK()、NTILE() などを指します。
集計関数での OVER の使用例
デモのための例として、SUM 関数と COUNT 関数を使用します。
--建立测试表和测试数据
CREATE TABLE Employee
(
ID INT PRIMARY KEY,
Name VARCHAR(20),
GroupName VARCHAR(20),
Salary INT
)
INSERT INTO Employee
VALUES(1,'小明','开发部',8000),
(4,'小张','开发部',7600),
(5,'小白','开发部',7000),
(8,'小王','财务部',5000),
(9, null,'财务部',NULL),
(15,'小刘','财务部',6000),
(16,'小高','行政部',4500),
(18,'小王','行政部',4000),
(23,'小李','行政部',4500),
(29,'小吴','行政部',4700);SUM後のウィンドウ関数
SELECT *,
SUM(Salary) OVER(PARTITION BY Groupname) 每个组的总工资,
SUM(Salary) OVER(PARTITION BY groupname ORDER BY ID) 每个组的累计总工资,
SUM(Salary) OVER(ORDER BY ID) 累计工资,
SUM(Salary) OVER() 总工资
from Employee(ヒント: コードを左右にスライドできます)
結果は次のとおりです:
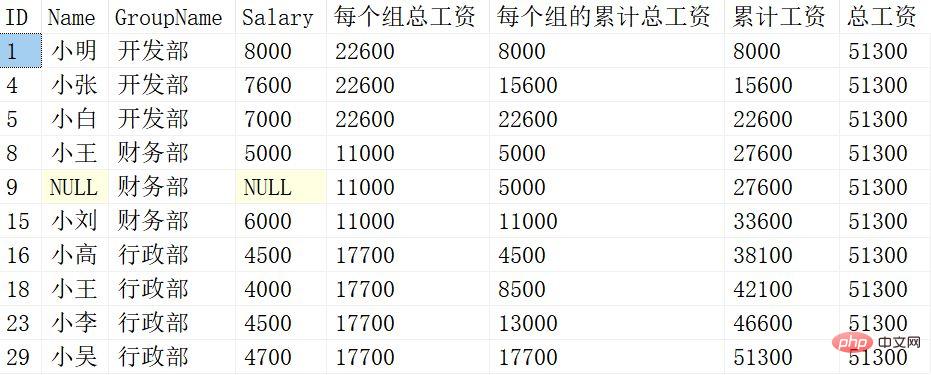
各ウィンドウ関数の意味は異なります。詳しく説明しましょう:
SUM(Salary) OVER (PARTITION BY Groupname)
PARTITION BY のみ 次の列 Groupname がグループ化され、Salary の合計はグループ化後に計算されます。
SUM(給与) OVER (PARTITION BY Groupname ORDER BY ID)
PARTITION BY の後の Groupname 列の場合グループ化し、ORDER BY以降のIDでソートし、グループ内のSalaryを累計します。
SUM(給与) OVER (ORDER BY ID)
ORDER BY のみ 並べ替えソート後のID内容を取得し、ソートされたSalaryを集計します。
SUM(Salary) OVER ()
Salary の集計処理
After COUNTウィンドウ関数
SELECT *,
COUNT(*) OVER(PARTITION BY Groupname ) 每个组的个数,
COUNT(*) OVER(PARTITION BY Groupname ORDER BY ID) 每个组的累积个数,
COUNT(*) OVER(ORDER BY ID) 累积个数 ,
COUNT(*) OVER() 总个数
from Employeeによって返される結果は次のとおりです:
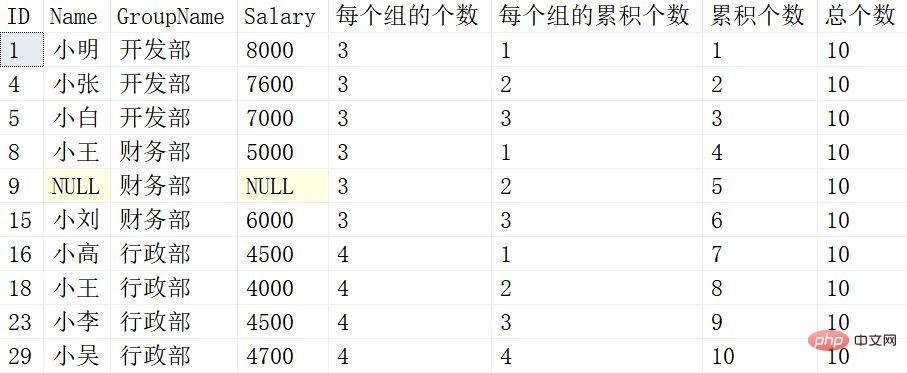
後続の各ウィンドウ関数は 1 つずつ解釈されなくなります。上記 SUM 以降のウィンドウ関数を 1 つずつ比較します。
ソート関数での OVER の使用例
4 つのソート関数を 1 つずつ説明します
--先建立测试表和测试数据 WITH t AS (SELECT 1 StuID,'一班' ClassName,70 Score UNION ALL SELECT 2,'一班',85 UNION ALL SELECT 3,'一班',85 UNION ALL SELECT 4,'二班',80 UNION ALL SELECT 5,'二班',74 UNION ALL SELECT 6,'二班',80 ) SELECT * INTO Scores FROM t; SELECT * FROM Scores
ROW_NUMBER()
定義 : ROW_NUMBER() 関数の機能は、SELECT でクエリされたデータを並べ替えることです。各データにはシリアル番号が追加されます。学生の成績のランク付けには使用できません。通常は、次のようなページング クエリに使用されます。上位 10 のクエリを 10 ~ 100 人の学生にクエリします。 ROW_NUMBER() は ORDER BY と一緒に使用する必要があります。そうしないと、エラーが報告されます。
学生のスコアを並べ替えます
SELECT *, ROW_NUMBER() OVER (PARTITION BY ClassName ORDER BY SCORE DESC) 班内排序, ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS 总排序 FROM Scores;
結果は次のとおりです:
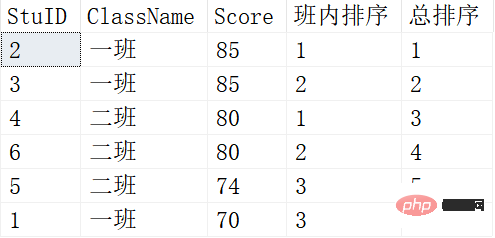
ここでの PARTITION BY と ORDER BY の機能は次と同じです。上で見たこと 集計関数は同じ機能を持ち、グループ化と並べ替えに使用されます。
さらに、ROW_NUMBER() 関数は、指定された順序でデータを取得することもできます。
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS 总排序 FROM Scores ) t WHERE t.总排序=2;
結果は次のとおりです:

RANK()
定義: RANK() 関数は、名前が示すように、特定のフィールドを順位付けできるランキング関数 ランキング、これとROW_NUMBER()の違いは何ですか? ROW_NUMBER()はソートです。同じ成績の生徒がいる場合、ROW_NUMBER()は順番にソートします。シリアル番号は異なりますが、Rank()は異なります。見た目が同じであれば、ランキングも同じです。以下の例を見てください:
Example
SELECT ROW_NUMBER() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores; SELECT RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
結果:
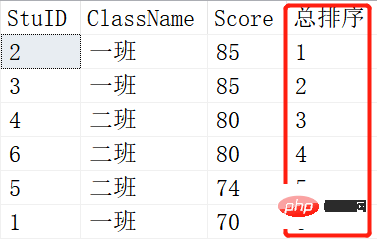
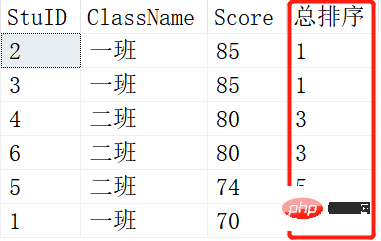
#上の図は ROW_NUMBER です。 ( ) の場合、下図は RANK() の結果です。 2 人の生徒が同じ成績の場合、変化が生じます。 RANK() は 1-1-3-3-5-6 ですが、ROW_NUMBER() は 1-2-3-4-5-6 のままです。これが RANK() と ROW_NUMBER() の違いです。
DENSE_RANK()
定义:DENSE_RANK()函数也是排名函数,和RANK()功能相似,也是对字段进行排名,那它和RANK()到底有什么不同那?特别是对于有成绩相同的情况,DENSE_RANK()排名是连续的,RANK()是跳跃的排名,一般情况下用的排名函数就是RANK() 我们看例子:
示例
SELECT RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores; SELECT DENSE_RANK() OVER (ORDER BY SCORE DESC) AS [RANK],* FROM Scores;
结果如下:
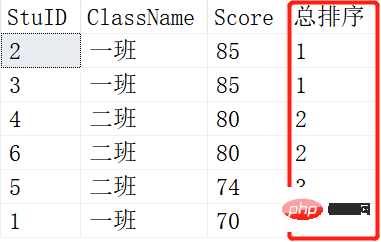
上面是RANK()的结果,下面是DENSE_RANK()的结果
NTILE()
定义:NTILE()函数是将有序分区中的行分发到指定数目的组中,各个组有编号,编号从1开始,就像我们说的'分区'一样 ,分为几个区,一个区会有多少个。
SELECT *,NTILE(1) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores; SELECT *,NTILE(2) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores; SELECT *,NTILE(3) OVER (ORDER BY SCORE DESC) AS 分区后排序 FROM Scores;
结果如下:
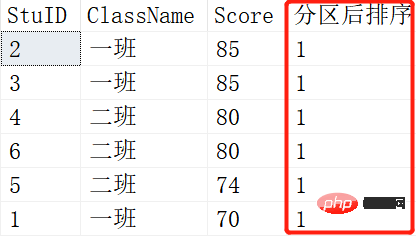
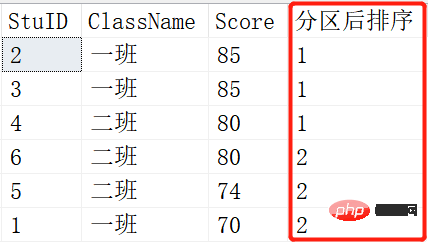
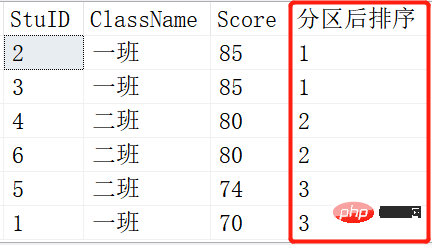
就是将查询出来的记录根据NTILE函数里的参数进行平分分区。
总结
OVER开窗函数是我们工作中经常要使用到的,特别是在做数据分析计算的时候,经常要对数据进行分组排序。上面我们额外介绍了聚合函数和排序函数的与OVER结合的使用方法,此外还有很多与OVER一起使用的函数,比如LEAD函数,LAG函数,STRING_AGG函数等等都会使用到开窗函数OVER,其使用方法也要务必掌握。
推荐学习:《SQL教程》
以上がSQL のウィンドウ関数を 1 つの記事で理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7529
7529
 15
1378
52
81
11
21
76
15
1378
52
81
11
21
76

 Hibernate フレームワークにおける HQL と SQL の違いは何ですか?
Apr 17, 2024 pm 02:57 PM
Hibernate フレームワークにおける HQL と SQL の違いは何ですか?
Apr 17, 2024 pm 02:57 PM
HQL と SQL は Hibernate フレームワークで比較されます。HQL (1. オブジェクト指向構文、2. データベースに依存しないクエリ、3. タイプ セーフティ)、SQL はデータベースを直接操作します (1. データベースに依存しない標準、2. 複雑な実行可能ファイル)。クエリとデータ操作)。
 Oracle SQLでの除算演算の使用法
Mar 10, 2024 pm 03:06 PM
Oracle SQLでの除算演算の使用法
Mar 10, 2024 pm 03:06 PM
「OracleSQLでの除算演算の使用方法」 OracleSQLでは、除算演算は一般的な数学演算の1つです。データのクエリと処理中に、除算演算はフィールド間の比率を計算したり、特定の値間の論理関係を導出したりするのに役立ちます。この記事では、OracleSQL での除算演算の使用法を紹介し、具体的なコード例を示します。 1. OracleSQL における除算演算の 2 つの方法 OracleSQL では、除算演算を 2 つの異なる方法で実行できます。
 Oracle と DB2 の SQL 構文の比較と相違点
Mar 11, 2024 pm 12:09 PM
Oracle と DB2 の SQL 構文の比較と相違点
Mar 11, 2024 pm 12:09 PM
Oracle と DB2 は一般的に使用される 2 つのリレーショナル データベース管理システムであり、それぞれに独自の SQL 構文と特性があります。この記事では、Oracle と DB2 の SQL 構文を比較し、相違点を示し、具体的なコード例を示します。データベース接続 Oracle では、次のステートメントを使用してデータベースに接続します: CONNECTusername/password@database DB2 では、データベースに接続するステートメントは次のとおりです: CONNECTTOdataba
 MyBatis動的SQLタグのSetタグ機能の詳細説明
Feb 26, 2024 pm 07:48 PM
MyBatis動的SQLタグのSetタグ機能の詳細説明
Feb 26, 2024 pm 07:48 PM
MyBatis 動的 SQL タグの解釈: Set タグの使用法の詳細な説明 MyBatis は、豊富な動的 SQL タグを提供し、データベース操作ステートメントを柔軟に構築できる優れた永続層フレームワークです。このうち、Set タグは、UPDATE ステートメントで SET 句を生成するために使用され、更新操作でよく使用されます。この記事では、MyBatis での Set タグの使用法を詳細に説明し、特定のコード例を通じてその機能を示します。 SetタグとはMyBatiで使用するSetタグです。
 SQL の ID 属性は何を意味しますか?
Feb 19, 2024 am 11:24 AM
SQL の ID 属性は何を意味しますか?
Feb 19, 2024 am 11:24 AM
SQL における Identity とは何ですか? 具体的なコード例が必要です。SQL では、Identity は自動インクリメント数値の生成に使用される特別なデータ型です。多くの場合、テーブル内のデータの各行を一意に識別するために使用されます。 Identity 列は、各レコードが一意の識別子を持つようにするために、主キー列と組み合わせてよく使用されます。この記事では、Identity の使用方法といくつかの実用的なコード例について詳しく説明します。 Identity の基本的な使用方法は、テーブルを作成するときに Identity を使用することです。
 SQL ステートメントを使用せずに Springboot+Mybatis-plus を実装して複数のテーブルを追加する方法
Jun 02, 2023 am 11:07 AM
SQL ステートメントを使用せずに Springboot+Mybatis-plus を実装して複数のテーブルを追加する方法
Jun 02, 2023 am 11:07 AM
Springboot+Mybatis-plus が SQL ステートメントを使用して複数テーブルの追加操作を実行しない場合、私が遭遇した問題は、テスト環境で思考をシミュレートすることによって分解されます: パラメーターを含む BrandDTO オブジェクトを作成し、パラメーターをバックグラウンドに渡すことをシミュレートします。 Mybatis-plus で複数テーブルの操作を実行するのは非常に難しいことを理解してください。Mybatis-plus-join などのツールを使用しない場合は、対応する Mapper.xml ファイルを設定し、臭くて長い ResultMap を設定するだけです。対応する SQL ステートメントを記述します。この方法は面倒に見えますが、柔軟性が高く、次のことが可能です。
 SQL の 5120 エラーを解決する方法
Mar 06, 2024 pm 04:33 PM
SQL の 5120 エラーを解決する方法
Mar 06, 2024 pm 04:33 PM
解決策: 1. ログインしているユーザーがデータベースにアクセスまたは操作するための十分な権限を持っているかどうかを確認し、ユーザーが正しい権限を持っているかどうかを確認します; 2. SQL Server サービスのアカウントに指定されたファイルまたはデータベースにアクセスする権限があるかどうかを確認します。 3. 指定されたデータベース ファイルが他のプロセスによって開かれているかロックされているかどうかを確認し、ファイルを閉じるか解放して、クエリを再実行します。管理者として試してください。Management Studio をなどとして実行します。
 MySQL でデータの集計と統計に SQL ステートメントを使用するにはどうすればよいですか?
Dec 17, 2023 am 08:41 AM
MySQL でデータの集計と統計に SQL ステートメントを使用するにはどうすればよいですか?
Dec 17, 2023 am 08:41 AM
MySQL でデータの集計と統計に SQL ステートメントを使用するにはどうすればよいですか?データの集計と統計は、データ分析と統計を実行する際の非常に重要な手順です。 MySQL は強力なリレーショナル データベース管理システムとして、データの集約と統計操作を簡単に実行できる豊富な集約機能と統計機能を提供します。この記事では、SQL ステートメントを使用して MySQL でデータの集計と統計を実行する方法を紹介し、具体的なコード例を示します。 1. カウントには COUNT 関数を使用します。COUNT 関数は最も一般的に使用されます。
