

SQL の order By ステートメントを最適化する方法について話しましょう

SQL の orderBy ステートメントを最適化するにはどうすればよいですか?以下の記事ではSQLのorderBy文を最適化する方法を紹介していますので、参考にしていただければ幸いです。

#データ クエリにデータベースを使用する場合、特定のフィールドに基づいてクエリ結果セットを並べ替える必要が必然的に発生します。 SQL では、通常、これを実現するために orderby ステートメントが使用されます。並べ替えが必要なフィールドはキーワードの後に配置します。複数のフィールドがある場合は、「,」で区切ります。
select * from table t order by t.column1,t.column2;
上記の SQL は、テーブル内のデータをクエリし、最初に列 1 で並べ替えることを示しています。列 1 が同じ場合は、列 2 で並べ替えます。デフォルトの並べ替え方法は降順です。もちろん、並び替え方法を指定することも可能です。並べ替えフィールドの後に DESC と ASE を追加して、それぞれ降順と昇順を示します。
このorderbyを利用することで、日々のソート操作を簡単に実装することができます。私はこれをよく使ってきましたが、皆さんもこのシナリオに遭遇したことがあるかどうかはわかりません: orderby を使用した後、SQL の実行効率が非常に遅くなる場合と、より高速になる場合があります。勉強する時間はありませんが、とにかくすごいと感じました。今週末は暇なので、mysql で orderby がどのように実装されるかを勉強しましょう。
説明をわかりやすくするために、まず次のようにデータ テーブル t1 を作成します。
CREATE TABLE `t1` ( `id` int(11) NOT NULL not null auto_increment, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`id`) , KEY `a` (`a`) USING BTREE ) ENGINE=InnoDB;
次にデータを挿入します。
insert into t1 (a,b,c) values (1,1,3); insert into t1 (a,b,c) values (1,4,5); insert into t1 (a,b,c) values (1,3,3); insert into t1 (a,b,c) values (1,3,4); insert into t1 (a,b,c) values (1,2,5); insert into t1 (a,b,c) values (1,3,6);
インデックスを有効にするため、10,000 行を挿入します 7,7, 7. データに関連がなく、データ量が少ない場合は、テーブル全体が直接スキャンされます
insert into t1 (a,b,c) values (7,7,7);
次に、a=1 のすべてのレコードを検索する必要があります。そして b フィールドに従って並べ替えます。
クエリ SQL は
select a,b,c from t1 where a = 1 order by b limit 2;
クエリ プロセス中のテーブル全体のスキャンを防ぐために、フィールド a にインデックスを追加しました。
まず、以下に示すように、ステートメント
explain select a,b,c from t1 where a = 1 order by b lmit 2;
を通じて SQL 実行プランを確認します。

追加の filesort の使用で確認できます。これは、SQL の実行中にソート操作が実行されることを意味します。ソート操作は、sort_buffer で完了します。sort_buffer は、mysql によって各スレッドに割り当てられたメモリ バッファです。このバッファは、ソートを完了するために特別に使用されます。サイズはデフォルトです。これは 1M で、そのサイズは変数 sort_buffer_size によって制御されます。
mysql が orderby を実装する場合、sort_buffer に入力されるさまざまなフィールドの内容に応じて、フル フィールドの並べ替えと ROWID の並べ替えという 2 つの異なる実装メソッドが実装されます。
完全なフィールドの並べ替え
まず、SQL の実行プロセスを図で見てみましょう:
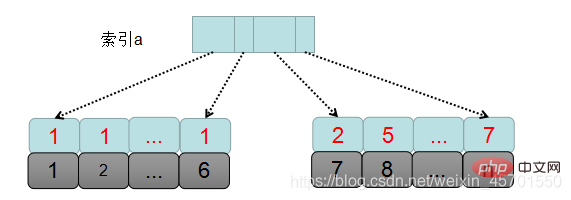
mysql が最初ですクエリ条件に基づいて決定されます。ソートが必要なデータセットは、テーブル内の a=1 のデータセット、つまり主キー ID が 1 ~ 6 のレコードです。
SQL 実行プロセス全体は次のとおりです:
1. sort_buffer を作成して初期化し、バッファーに配置する必要があるフィールドを決定します。 a、b、c これら 3 つのフィールド。
2. インデックスツリー a から a=1 を満たす最初の主キー ID、つまり id=1 を見つけます。
3. id インデックスまでのテーブルに戻り、データ行全体を取り出し、データ行全体から a、b、c の値を取り出して配置しますそれらをsort_bufferに入れます。
4. a=1 の次の主キー ID をインデックス a から順に探します。
5. a=1 の最後のレコード、つまり主キー id=5 が取得されるまで、手順 3 と 4 を繰り返します。
6. このとき、条件 a=1 を満たすすべてのレコードの a、b、c フィールドがすべて読み込まれ、sort_buffer に配置され、これらのデータが の値に従ってソートされます。 b. ソート方法はクイックソートです。これはインタビューで頻繁に遭遇するクイック ソートであり、クイック ソートの計算量は log2n です。
7. 次に、並べ替えられた結果セットから最初の 2 行のデータを取り出します。
上記はmsqlにおけるorderbyの実行処理です。 sort_buffer に入れられるデータは出力する必要があるすべてのフィールドであるため、このソートはフルソートと呼ばれます。
これを見て何か質問はありますか?ソートする必要があるデータの量が多く、sort_buffer に収まらない場合はどうすればよいでしょうか?
確かに、a=1 のデータ行が多数あり、sort_buffer に格納する必要があるフィールドが多数ある場合、a、b、c のフィールドが 3 つ以上存在する可能性があります。さらに多くのフィールドを出力する必要がある場合があります。その場合、デフォルト サイズが 1M しかない sort_buffer では、それを収容できない可能性があります。
sort_buffer がそれに対応できない場合、mysql は並べ替えを支援するために一時ディスク ファイルのバッチを作成します。デフォルトでは、12 個の一時ファイルが作成され、並べ替えられるデータは 12 の部分に分割されます。各部分は個別に並べ替えられて 12 個の内部データ順序付きファイルを形成し、これらの 12 個の順序付きファイルが順序付きファイルにマージされます。 . ファイルが大きくなり、ようやくデータの整理が完了します。
ファイル ベースの並べ替えは、メモリ ベースの並べ替えよりもはるかに効率が低くなります。並べ替えの効率を向上させるには、ファイル ベースの並べ替えを避けるようにしてください。ファイル ベースの並べ替えを回避したい場合は、 sort_buffer を作成する必要があります。 ソートする必要があるデータ量に対応します。
つまり、mysql は、sort_buffer が対応できない状況に合わせて最適化されています。ソート時にsort_bufferに格納されるフィールドの数を減らすためです。
具体的な最適化方法は次のrowIdソートです
RowId 排序
在全字段排序实现中,排序的过程中,要把需要输出的字段全部放到sort_buffer中,当输出的字段比较多的时候,可以放到sort_buffer中的数据行就会变少。也就增大了sort_buffer无法容纳数据的风险,直至出现基于文件的排序。
rowId排序对全字段排序的优化手段,主要是减少了放到sort_buffer中字段个数。
在rowId排序中,只会将需要排序的字段和主键Id放到sort_buffer中。
select a,b,c from t1 where a = 1 order by b limit 2;
在rowId的排序中的执行流程如下:
1.初始化并创建sort_buffer,并确认要放入的的字段,id和b。
2.从索引树a中找到第一个满足a=1的主键id,也就是id=1。
3.回表主键索引id,取出整行数据,从整行数据中取出id和b,存入sort_buffer中。
4.从索引a中取出下一条满足a=1的 记录的主键id。
5.重复步骤3和4,直到最后一个满足a=1的主键id,也就是a=6。
6.对sort_buffer中的数据,按照字段b排序。
7.从sort_buffer中的有序数据集中,取出前2个,因为此时取出的数据只有id和b,要想获取a和c字段,需要根据id字段,回表到主键索引中取出整行数据,从整行数据中获取需要的数据。
根据rowId排序的执行步骤,可以发现:相比全字段排序,rowId排序的实现方式,减少了存放到sort_buffer中的数据量,降低了基于文件的外部排序的可能性。
那rowid排序有不足的地方吗?肯定有的,要不然全字段排序就没有存在的意义了。rowid排序不足之处在于,在最后的步骤7中,增加了回表的次数,不过这个回表的次数,取决于limit后的值,如果返回的结果集比较小的话,回表的次数还是比较小的。
mysql是如何在全字段排序和rowId排序的呢?其实是根据存放的sort_buffer中每行字段的长度决定的,如果mysql认为每次放到sort_buffer中的数据量很大的话,那么就用rowId排序实现,否则使用全字段排序。那么多大算大呢?这个大小的阈值有一个变量的值来决定,这个变量就是 max_length_for_sort_data。如果每次放到sort_buffer中的数据大小大于该字段值的话,就使用rowId排序,否则使用全字段排序。
orderby的优化
上面讲述了orderby的两种排序的方式,以及一些优化策略,优化的目的主要就是避免基于磁盘文件的外部排序。因为基于磁盘文件的排序效率要远低于基于sort_buffer的内存排序。
但是当数据量比较大的时候,即使sort_buffer比较大,所有数据全部放在内存中排序,sql的整体执行效率也不高,因为排序这个操作,本身就是比较消耗性能的。
试想,如果基于索引a获取到所有a=1的数据,按照字段b,天然就是有序的,那么就不用执行排序操作,直接取出来的数据,就是符合结果的数据集,那么sql的执行效率就会大幅度增长。
其实要实现整个sql执行过程中,避免排序操作也不难,只需要创建一个a和b的联合索引即可。
alter table t1 add index a_b (a,b);
添加a和b的联合索引后,sql执行流程就变成了:
1.从索引树(a,b)中找到第一个满足a=1的主键id,也就是id=1。
2.回表到主键索引树,取出整行数据,并从中取出a,b,c,直接作为结果集的一部分返回。
3.从索引树(a,b)上取出下一个满足a=1的主键id。
4.重复步骤2和3,直到找到第二个满足a=1的主键id,并回表获取字段a,b,c。
此时我们可以通过查看sql的执行计划,来判断sql的执行过程中是否执行了排序操作。
explain select a,b from t1 where a = 1 order by b lmit 2;

通过查看执行计划,我们发现extra中已经没有了using filesort了,也就是没有执行排序操作了。
其实还可以通过覆盖索引,对该sql进一步优化,通过在索引中覆盖字段c,来避免回表的操作。
alter table t1 add index a_b_c (a,b,c);
添加索引a_b_c后,sql的执行过程如下:
1.从索引树(a,b,c)中找到第一个满足a=1的索引,从中取出a,b,c。直接作为结果集的一部分直接返回。
2.从索引(a,b,c)中取出下一个,满足a=1的记录作为结果集的一部分。
3.重复执行步骤2,直到查到第二个a=1或者不满足a=1的记录。
此时通过查看执行sql的的还行计划可以发现 extra中只有 Using index。
explain select a,b from t1 where a = 1 order by b lmit 2;

概要
この SQL の複数の最適化により、SQL の最終的な実行効率は、ソートなしの通常の SQL のクエリ効率と基本的に同じになります。 orderby ソート操作を回避できる理由は、インデックスの自然な順序付けの特性を利用するためです。
しかし、インデックスを使用するとクエリの効率が向上することは誰もが知っていますが、インデックスのメンテナンス コストは比較的高くなります。データ テーブル内のデータの追加と変更にはインデックスの変更が伴うため、インデックスの数が多いほど効果が高くなります。 . 場合によっては、一般的ではないクエリや並べ替えのためだけにインデックスを追加しすぎても意味がありません。
[関連する推奨事項: mysql ビデオ チュートリアル ]
以上がSQL の order By ステートメントを最適化する方法について話しましょうの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7540
7540
 15
1380
52
83
11
21
86
15
1380
52
83
11
21
86

 Hibernate フレームワークにおける HQL と SQL の違いは何ですか?
Apr 17, 2024 pm 02:57 PM
Hibernate フレームワークにおける HQL と SQL の違いは何ですか?
Apr 17, 2024 pm 02:57 PM
HQL と SQL は Hibernate フレームワークで比較されます。HQL (1. オブジェクト指向構文、2. データベースに依存しないクエリ、3. タイプ セーフティ)、SQL はデータベースを直接操作します (1. データベースに依存しない標準、2. 複雑な実行可能ファイル)。クエリとデータ操作)。
 Oracle SQLでの除算演算の使用法
Mar 10, 2024 pm 03:06 PM
Oracle SQLでの除算演算の使用法
Mar 10, 2024 pm 03:06 PM
「OracleSQLでの除算演算の使用方法」 OracleSQLでは、除算演算は一般的な数学演算の1つです。データのクエリと処理中に、除算演算はフィールド間の比率を計算したり、特定の値間の論理関係を導出したりするのに役立ちます。この記事では、OracleSQL での除算演算の使用法を紹介し、具体的なコード例を示します。 1. OracleSQL における除算演算の 2 つの方法 OracleSQL では、除算演算を 2 つの異なる方法で実行できます。
 Oracle と DB2 の SQL 構文の比較と相違点
Mar 11, 2024 pm 12:09 PM
Oracle と DB2 の SQL 構文の比較と相違点
Mar 11, 2024 pm 12:09 PM
Oracle と DB2 は一般的に使用される 2 つのリレーショナル データベース管理システムであり、それぞれに独自の SQL 構文と特性があります。この記事では、Oracle と DB2 の SQL 構文を比較し、相違点を示し、具体的なコード例を示します。データベース接続 Oracle では、次のステートメントを使用してデータベースに接続します: CONNECTusername/password@database DB2 では、データベースに接続するステートメントは次のとおりです: CONNECTTOdataba
 MyBatis動的SQLタグのSetタグ機能の詳細説明
Feb 26, 2024 pm 07:48 PM
MyBatis動的SQLタグのSetタグ機能の詳細説明
Feb 26, 2024 pm 07:48 PM
MyBatis 動的 SQL タグの解釈: Set タグの使用法の詳細な説明 MyBatis は、豊富な動的 SQL タグを提供し、データベース操作ステートメントを柔軟に構築できる優れた永続層フレームワークです。このうち、Set タグは、UPDATE ステートメントで SET 句を生成するために使用され、更新操作でよく使用されます。この記事では、MyBatis での Set タグの使用法を詳細に説明し、特定のコード例を通じてその機能を示します。 SetタグとはMyBatiで使用するSetタグです。
 SQL の ID 属性は何を意味しますか?
Feb 19, 2024 am 11:24 AM
SQL の ID 属性は何を意味しますか?
Feb 19, 2024 am 11:24 AM
SQL における Identity とは何ですか? 具体的なコード例が必要です。SQL では、Identity は自動インクリメント数値の生成に使用される特別なデータ型です。多くの場合、テーブル内のデータの各行を一意に識別するために使用されます。 Identity 列は、各レコードが一意の識別子を持つようにするために、主キー列と組み合わせてよく使用されます。この記事では、Identity の使用方法といくつかの実用的なコード例について詳しく説明します。 Identity の基本的な使用方法は、テーブルを作成するときに Identity を使用することです。
 SQL ステートメントを使用せずに Springboot+Mybatis-plus を実装して複数のテーブルを追加する方法
Jun 02, 2023 am 11:07 AM
SQL ステートメントを使用せずに Springboot+Mybatis-plus を実装して複数のテーブルを追加する方法
Jun 02, 2023 am 11:07 AM
Springboot+Mybatis-plus が SQL ステートメントを使用して複数テーブルの追加操作を実行しない場合、私が遭遇した問題は、テスト環境で思考をシミュレートすることによって分解されます: パラメーターを含む BrandDTO オブジェクトを作成し、パラメーターをバックグラウンドに渡すことをシミュレートします。 Mybatis-plus で複数テーブルの操作を実行するのは非常に難しいことを理解してください。Mybatis-plus-join などのツールを使用しない場合は、対応する Mapper.xml ファイルを設定し、臭くて長い ResultMap を設定するだけです。対応する SQL ステートメントを記述します。この方法は面倒に見えますが、柔軟性が高く、次のことが可能です。
 SQL の 5120 エラーを解決する方法
Mar 06, 2024 pm 04:33 PM
SQL の 5120 エラーを解決する方法
Mar 06, 2024 pm 04:33 PM
解決策: 1. ログインしているユーザーがデータベースにアクセスまたは操作するための十分な権限を持っているかどうかを確認し、ユーザーが正しい権限を持っているかどうかを確認します; 2. SQL Server サービスのアカウントに指定されたファイルまたはデータベースにアクセスする権限があるかどうかを確認します。 3. 指定されたデータベース ファイルが他のプロセスによって開かれているかロックされているかどうかを確認し、ファイルを閉じるか解放して、クエリを再実行します。管理者として試してください。Management Studio をなどとして実行します。
 MySQL でデータの集計と統計に SQL ステートメントを使用するにはどうすればよいですか?
Dec 17, 2023 am 08:41 AM
MySQL でデータの集計と統計に SQL ステートメントを使用するにはどうすればよいですか?
Dec 17, 2023 am 08:41 AM
MySQL でデータの集計と統計に SQL ステートメントを使用するにはどうすればよいですか?データの集計と統計は、データ分析と統計を実行する際の非常に重要な手順です。 MySQL は強力なリレーショナル データベース管理システムとして、データの集約と統計操作を簡単に実行できる豊富な集約機能と統計機能を提供します。この記事では、SQL ステートメントを使用して MySQL でデータの集計と統計を実行する方法を紹介し、具体的なコード例を示します。 1. カウントには COUNT 関数を使用します。COUNT 関数は最も一般的に使用されます。
