

MySQL インデックス プッシュダウンを 1 つの記事で理解する

この記事では、mysql に関する関連知識を提供します。主にインデックス プッシュダウンに関する関連コンテンツを紹介します。インデックス条件プッシュダウンは、インデックス プッシュダウンとも呼ばれます。正式な英語名は、Index Condition Pushdown と呼ばれます。 ICP はデータ クエリを最適化するために使用されます。見てみましょう。皆さんのお役に立てれば幸いです。

推奨学習: mysql ビデオ チュートリアル
SELECT ステートメントの実行プロセス
MySQL データベースは、Server レイヤーと Engine レイヤーで構成されます。
-
Serverレイヤー:SQLアナライザー、SQLオプティマイザー、SQLエグゼキューターがあり、SQLステートメントの特定の実行プロセスを担当します。 。 -
エンジンレイヤー: 最も一般的に使用されるInnoDBストレージ エンジンなどの特定のデータの保存と、メモリへの一時データの保存を担当します。結果セット用のTempTableエンジン。
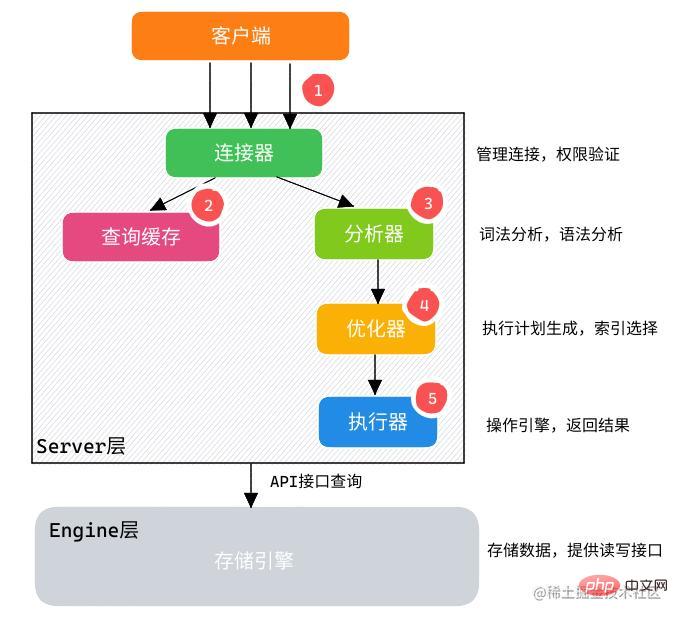
クライアント/サーバー通信プロトコルを通じて
MySQLへの接続を確立します。-
クエリ キャッシュ:
-
クエリ キャッシュが有効で、クエリ キャッシュが完全にクエリされている場合同じSQLステートメントが使用されている場合、クエリ結果はクライアントに直接返されます。 -
クエリ キャッシュがオンになっていない場合、またはまったく同じSQL # クエリは実行されません ## ステートメントはパーサーによって構文的および意味的に解析され、解析ツリーが生成されます。
-
- パーサーは新しい解析ツリーを生成します。
- クエリ オプティマイザーは実行プランを生成します。
- クエリ実行エンジンは
SQL
ステートメントを実行します。このとき、クエリ実行エンジンはSQL 内のテーブルのストレージ エンジン タイプを決定します。ステートメントと対応するAPIインターフェイスは、基礎となるストレージ エンジン キャッシュまたは物理ファイルと対話してクエリ結果を取得します。MySQL Serverでフィルタリングした後、クエリ結果はキャッシュされて返されます。クライアントに。クエリ キャッシュ
が有効になっている場合、SQLステートメントと結果は完全にクエリ キャッシュに保存されます。 #SQLステートメントが今後実行されると、結果が直接返されます。
ヒント: MySQL 8.0 では、クエリ キャッシュ (クエリ キャッシュ モジュール) が削除されました。
インデックス プッシュダウンとは何ですか?インデックス条件プッシュダウン
: ICP と呼ばれ、インデックス フィルタリング条件をストレージ エンジンにプッシュダウンすることで、# を削減します。 ##MySQL ストレージ エンジンがベース テーブルにアクセスする回数と MySQL サービス層がストレージ エンジンにアクセスする回数。 インデックス プッシュダウン VS カバリング インデックス: 実際には、どちらも
が、方法は異なります
カバーされたインデックス:- インデックスに必須フィールド (
- SELECT XXX
) が含まれている場合、クエリのためにテーブルにそれ以上のフィールドは返されません。
インデックス プッシュダウン: インデックスに含まれるフィールドを最初に判断します。 - 条件を満たさないレコードを直接除外します。
、そして、テーブルが返す行数を減らします。
ICP
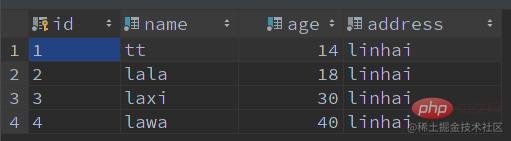
SQL: Give a Chestnut: 名前が la で始まり、経過時間が
<div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>SELECT * FROM user WHERE name LIKE &#39;la%&#39; AND age = 18;</pre><div class="contentsignin">ログイン後にコピー</div></div> であるレコードをクエリします。次のレコードがあります:
 ICP
ICP
対応するデータ行を見つけて読み取ります。 (実際にはテーブルを返すだけです)
- WHERE
- のフィールドを判断して、条件を満たさない行を除外します。
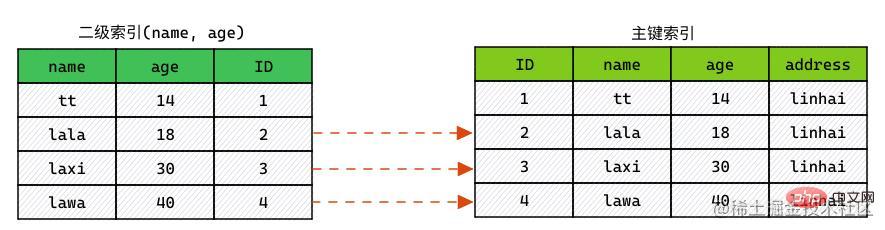 ICP
ICP
インデックス要素グループを取得します。
- WHERE
- のフィールドを判断し、インデックス列でフィルタリングします。
- 条件を満たすインデックスの場合、テーブルを返し、行全体をクエリします。
- のフィールドを判断して、条件に当てはまらない行を除外します。
- 关闭
ICP,再调用EXPLAIN查看语句: - 开启
ICP,再调用EXPLAIN查看语句: - 开启
ICP:Handler_read_next等于 1,回表查 1 次。 - 关闭
ICP:Handler_read_next等于 3,回表查 3 次。 当需要访问整个表行时,
ICP用于range、ref、eq_ref和ref_or_nullICP可以用于InnoDB和MyISAM表,包括分区表InnoDB和MyISAM表。对于
InnoDB表,ICP仅用于二级索引。ICP的目标是减少全行读取次数,从而减少I/O操作。对于InnoDB聚集索引,完整的记录已经读入InnoDB缓冲区。在这种情况下使用ICP不会减少I/O。在虚拟生成列上创建的二级索引不支持
ICP。InnoDB支持虚拟生成列的二级索引。引用子查询的条件不能下推。
引用存储功能的条件不能被按下。存储引擎不能调用存储的函数。
触发条件不能下推。
不能将条件下推到包含对系统变量的引用的派生表。(
MySQL 8.0.30及更高版本)。ICP仅适用于 二级索引。ICP目标是 减少回表查询。ICP对联合索引的部分列模糊查询非常有效。
动手实验:
实验:使用 MySQL 版本 8.0.16
-- 表创建 CREATE TABLE IF NOT EXISTS `user` ( `id` VARCHAR(64) NOT NULL COMMENT '主键 id', `name` VARCHAR(50) NOT NULL COMMENT '名字', `age` TINYINT NOT NULL COMMENT '年龄', `address` VARCHAR(100) NOT NULL COMMENT '地址', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT '用户表'; -- 创建索引 CREATE INDEX idx_name_age ON user (name, age); -- 新增数据 INSERT INTO user (id, name, age, address) VALUES (1, 'tt', 14, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (2, 'lala', 18, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (3, 'laxi', 30, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (4, 'lawa', 40, 'linhai'); -- 查询语句 SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;
新增数据如下:
-- 将 ICP 关闭 SET optimizer_switch = 'index_condition_pushdown=off'; -- 查看确认 show variables like 'optimizer_switch'; -- 用 EXPLAIN 查看 EXPLAIN SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;

-- 将 ICP 打开 SET optimizer_switch = 'index_condition_pushdown=on'; -- 查看确认 show variables like 'optimizer_switch'; -- 用 EXPLAIN 查看 EXPLAIN SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;

由上实验可知,区别是否开启 ICP: Exira 字段中的 Using index condition
更进一步,来看下 ICP 带来的性能提升:
通过访问数据文件的次数
-- 1. 清空 status 状态 flush status; -- 2. 查询 SELECT * FROM user WHERE name LIKE 'la%' AND age = 18; -- 3. 查看 handler 状态 show status like '%handler%';
对比开启 ICP 和 关闭 ICP: 关注 Handler_read_next 的值
-- 开启 ICP flush status; SELECT * FROM user WHERE name LIKE 'la%' AND age = 18; show status like '%handler%'; +----------------------------|-------+ | Variable_name | Value | +----------------------------|-------+ | Handler_commit | 1 | | Handler_delete | 0 | | Handler_discover | 0 | | Handler_external_lock | 2 | | Handler_mrr_init | 0 | | Handler_prepare | 0 | | Handler_read_first | 0 | | Handler_read_key | 1 | | Handler_read_last | 0 | | Handler_read_next | 1 | <---重点 | Handler_read_prev | 0 | | Handler_read_rnd | 0 | | Handler_read_rnd_next | 0 | | Handler_rollback | 0 | | Handler_savepoint | 0 | | Handler_savepoint_rollback | 0 | | Handler_update | 0 | | Handler_write | 0 | +----------------------------|-------+ 18 rows in set (0.00 sec) -- 关闭 ICP flush status; SELECT * FROM user WHERE name LIKE 'la%' AND age = 18; show status like '%handler%'; +----------------------------|-------+ | Variable_name | Value | +----------------------------|-------+ | Handler_commit | 1 | | Handler_delete | 0 | | Handler_discover | 0 | | Handler_external_lock | 2 | | Handler_mrr_init | 0 | | Handler_prepare | 0 | | Handler_read_first | 0 | | Handler_read_key | 1 | | Handler_read_last | 0 | | Handler_read_next | 3 | <---重点 | Handler_read_prev | 0 | | Handler_read_rnd | 0 | | Handler_read_rnd_next | 0 | | Handler_rollback | 0 | | Handler_savepoint | 0 | | Handler_savepoint_rollback | 0 | | Handler_update | 0 | | Handler_write | 0 | +----------------------------|-------+ 18 rows in set (0.00 sec)
由上实验可知:
这实验跟上面的栗子就对应上了。
索引下推限制
根据官网可知,索引下推 受以下条件限制:
小结下:
拓展:虚拟列
CREATE TABLE UserLogin ( userId BIGINT, loginInfo JSON, cellphone VARCHAR(255) AS (loginInfo->>"$.cellphone"), PRIMARY KEY(userId), UNIQUE KEY idx_cellphone(cellphone) );
列 cellphone :就是一个虚拟列,它是由后面的函数表达式计算而成,本身这个列不占用任何的存储空间,而索引 idx_cellphone 实质是一个函数索引。
好处: 在写 SQL 时可以直接使用这个虚拟列,而不用写冗长的函数。
举个栗子: 查询手机号
-- 不用虚拟列 SELECT * FROM UserLogin WHERE loginInfo->>"$.cellphone" = '13988888888' -- 使用虚拟列 SELECT * FROM UserLogin WHERE cellphone = '13988888888'
推荐学习:mysql视频教程
以上がMySQL インデックス プッシュダウンを 1 つの記事で理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7500
7500
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54

 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する手順:データベースに接続します。 SQLエディターウィンドウを作成します。 SQLクエリまたはスクリプトを書きます。 [実行]ボタンをクリックして、クエリまたはスクリプトを実行します。結果を表示します(クエリが実行された場合)。
 Navicatは、データベースエラーコードとソリューションに接続します
Apr 08, 2025 pm 11:06 PM
Navicatは、データベースエラーコードとソリューションに接続します
Apr 08, 2025 pm 11:06 PM
データベースに接続するときの一般的なエラーとソリューション:ユーザー名またはパスワード(エラー1045)ファイアウォールブロック接続(エラー2003)接続タイムアウト(エラー10060)ソケット接続を使用できません(エラー1042)SSL接続エラー(エラー10055)接続の試みが多すぎると、ホストがブロックされます(エラー1129)データベースは存在しません(エラー1049)
