仮想メモリの実装は、離散的に割り当てられたメモリ管理方式に基づいて行う必要があり、1. リクエスト ページング ストレージ管理方式、2. リクエスト セグメント ストレージ管理方式、3. セグメント ページ ストレージの 3 つの実装方式があります。管理方法。どの方法を使用する場合でも、特定のハードウェア サポートが必要です: 1. 特定の容量のメモリと外部メモリ、2. 主要なデータ構造としてのページ テーブル メカニズム (またはセグメント テーブル メカニズム)、3. ユーザーがアクセスしたときの割り込みメカニズムプログラムのニーズ アクセスされた部分がまだメモリに転送されていない場合、割り込みが発生します; 4. アドレス変換メカニズム、論理アドレスから物理アドレスへの変換。

#このチュートリアルの動作環境: linux7.3 システム、Dell G3 コンピューター。
1. 仮想メモリの概要
従来のストレージ管理では、複数のプロセスをメモリ内に同時に保持して、マルチプログラミングを可能にします。これらにはすべて、次の 2 つの共通の特徴があります:
-
1 回限り : ジョブは 1 回実行する必要がありますすべてがメモリにロードされた後、実行を開始します。これにより、次の 2 つの状況が発生します:
1) ジョブが大きくてメモリにロードできない場合、ジョブは実行できません;
2) 多数のジョブを実行する必要がある場合、メモリ不足のため、すべてのジョブで最初に実行できるジョブは少数のみとなり、その結果マルチプログラミングが減少します。
-
常駐: ジョブがメモリにロードされた後は、常に メモリ内に常駐し、その一部がスワップアウトされることはありません。ジョブが最後まで実行されるまで。実行中のプロセスは I/O を待機しているためにブロックされ、長期間待機状態になる可能性があります。
したがって、プログラムの動作中に使用されない、または一時的に使用されない多くのプログラム (データ) が大量のメモリ領域を占有し、実行する必要がある一部のジョブをロードして実行できなくなり、これは明らかに貴重なメモリやリソースを無駄にします。
1.1 仮想メモリの定義と特性
局所性原則に基づき、プログラムががロードされると、プログラムの 部分をメモリ にロードし、残りを外部メモリに残すことができ、プログラムの実行を開始できます。プログラムの実行中、アクセスされた情報がメモリにない場合、オペレーティングシステム は必要な部分をメモリ に転送し、プログラムの実行を続けます。一方、オペレーティング システムは、メモリ内の一時的に使用されていないコンテンツを外部ストレージにスワップアウトし、メモリに転送される情報を保存するためのスペースを解放します。 このように、システムは
部分読み込み、リクエスト転送、置換機能を提供するため (ユーザーに対して完全に透過的)、ユーザーはあたかも何かがあるかのように感じます。実際の物理メモリよりもはるかに大きいメモリは、
仮想メモリと呼ばれます。 仮想メモリの サイズはコンピュータのアドレス構造によって決まります 。メモリと外部メモリの単純な合計ではありません。
仮想ストレージには、次の 3 つの主な特徴があります。
複数回: ジョブの実行中に一度にすべてをインストールする必要はありません。ただし、複数回に分割してメモリにロードして実行することができます。
スワップ可能性- : ジョブの実行中にメモリ内に留まる必要はありませんが、ジョブの実行プロセス中にスワップインおよびスワップアウトが可能です。
仮想性 - : ユーザーから見えるメモリ容量が実際のメモリ容量よりもはるかに大きくなるように、メモリ容量を論理的に拡張します。
- 1.2 仮想メモリ テクノロジの実装
仮想メモリにより、 ジョブをメモリに複数回転送できます 。 連続割り当て方法を使用すると、メモリ空間のかなりの部分が一時的または「永続的な」アイドル状態になり、メモリ リソースが大幅に浪費され、論理的にメモリ領域を拡張することができなくなります。記憶容量。
したがって、仮想メモリの実装は、個別割り当て
メモリ管理方法
に基づく必要があります。仮想メモリを実装するには、次の 3 つの方法があります。
#リクエスト ページング ストレージ管理
リクエスト セグメンテーション
ストレージ管理-
#セグメント ページ タイプストレージ管理
-
どの方法を使用する場合でも、特定の ハードウェア サポート
が必要です。一般に必要なサポートには次の側面が含まれます: -
一定量のメモリと外部ストレージ。
ページ テーブル メカニズム (またはセグメント テーブル メカニズム)。主なデータ構造として使用されます。
割り込み機構では、ユーザプログラムがアクセスする部分がメモリ上に転送されていない場合に割り込みが発生します。
アドレス変換メカニズム、論理アドレスから物理アドレスへの変換。
-
-
- 連続割り当て方法
: - とは、ユーザープログラムに
連続したメモリ空間
を割り当てることを指します。
-
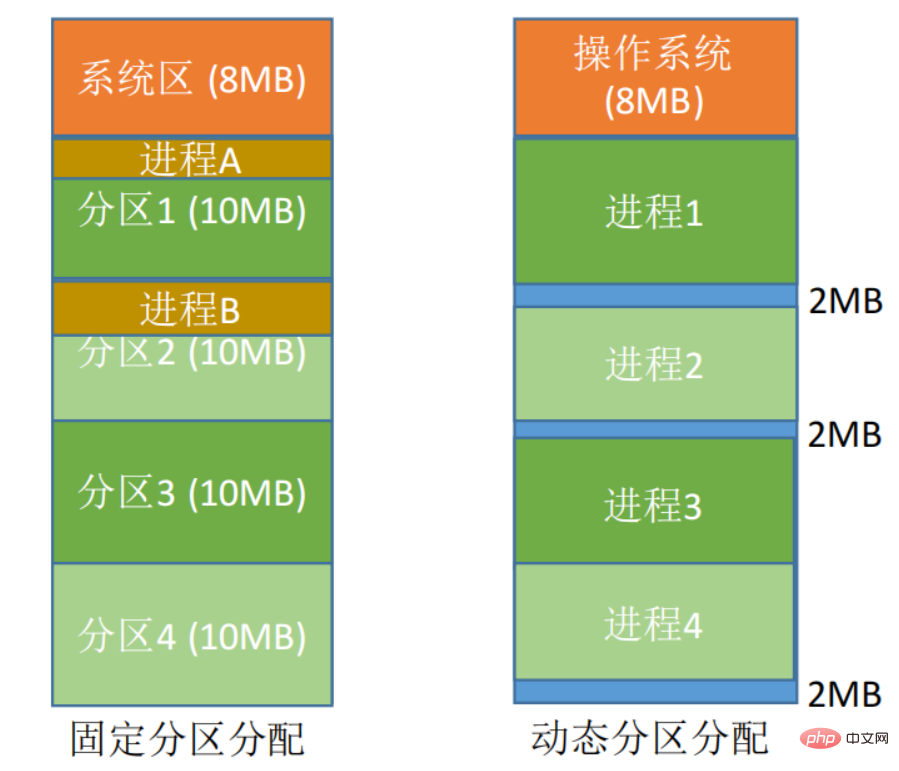
固定パーティション割り当て: メモリ空間をいくつかの固定サイズの領域に分割し、各パーティションにジョブを 1 つだけロードし、複数のジョブを同時に実行できます。柔軟性が欠如すると、大量の 内部断片化が発生し、メモリ使用率が非常に低くなります。
-
動的パーティション割り当て: 実際のニーズに応じてプロセスにメモリ空間を動的に割り当てます。ジョブがメモリにロードされると、使用可能なメモリがジョブの連続領域に分割され、パーティションのサイズがジョブのサイズに正確に適したものになります。大量の 外部デブリが生成されます。
離散割り当て方法: プロセス を離散分散にロードする 多数へ隣接しないパーティションでは、メモリを最大限に活用できます。
ページング ストレージの概念:
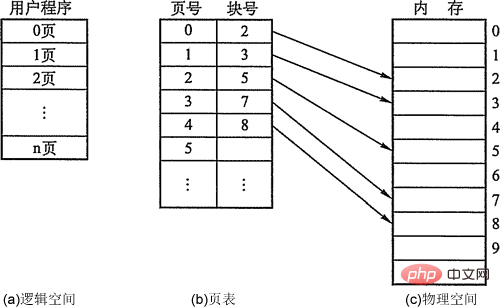
ページ、ページ フレーム、およびブロック。 - プロセス 内のブロックは ページまたはページ (ページ) と呼ばれ、ページ番号が付けられます。メモリ内のブロック は呼ばれます。 Page Frame (Page Frame, ページ フレーム = メモリ ブロック = 物理ブロック = 物理ページ ) には、ページ フレーム番号が入ります。 外部ストレージも同じユニットに分割されており、ブロックと直接呼ばれます。プロセスを実行するときは、メイン メモリ空間を適用する必要があります。つまり、各ページにはメイン メモリ内の利用可能なページ フレームを割り当てる必要があり、これにより、ページとページ フレームの間に 1 対 1 の対応関係が作成されます。各ページは連続して保存する必要はなく、隣接しないページ フレームに配置することができます。
- アドレス構造: 最初の部分は ページ番号 P、後半部分は ページ オフセット W です。アドレス長は 32 ビットで、ビット 0 ~ 11 はページ内アドレス、つまり各ページのサイズは 4KB、ビット 12 ~ 31 はページ番号で、アドレス空間は 2^20 まで許容されます。ページ。
- ページテーブル。メモリ内のプロセスの各ページに対応する物理ブロック を が見つけやすくするために、システムはプロセスごとにページ テーブルを確立し、メモリ内のページに対応する物理ブロック番号 ## を記録します。 #ページテーブル 通常はメモリに保存されます。ページテーブルを構成した後、プロセスを実行すると、テーブルを参照することでメモリ内の各ページの物理ブロック番号がわかります。ページ テーブルの役割は、ページ番号から物理ブロック番号への アドレス マッピングを実装することであることがわかります。
#2. 仮想メモリを実装するためのページング管理のリクエスト
ページングのリクエスト現在、仮想メモリを実装するために最も一般的に使用されている方法です。
リクエスト ページング システムは、基本ページング システムをベースにしており、仮想メモリ機能をサポートするために、
リクエスト ページング
機能と ページ置換#をサポートします。 # が追加されます。 リクエスト ページング システムでは、ジョブを開始する前に、現在必要なページの一部のみをメモリにロードする必要があります。 ジョブ実行中、アクセスするページがメモリ上にない場合、ページング機能によりアクセスするページを取り込むと同時に、一時的に使用されていないページを外部メモリにスワップアウトすることもできます。メモリ領域を解放するための置換関数。 リクエスト ページングを実装するには、システムが特定のハードウェア サポートを提供する必要があります。
一定容量のメモリと外部ストレージを必要とするコンピュータ システムに加えて、
ページ テーブル メカニズム、ページ フォールト割り込みメカニズム、およびアドレスも必要です。変換メカニズム
#。 2.1 ページ テーブルのメカニズム #リクエスト ページング システムのページ テーブルのメカニズムは、基本的なページング システムとは異なります。ジョブが実行される前に開始されません。すべてを一度にメモリにロードする必要があります。
したがって、ジョブの実行プロセス中に、アクセスするページがメモリにないという状況が必然的に発生します。この状況をどのように検出して対処するかが、リクエスト ページングの 2 つの基本的な問題です。システムが解決しなければなりません。この目的のために、次の 4 つのフィールドがリクエスト ページ テーブル エントリに追加されます。 リクエスト ページング システムのページ テーブル エントリ
ページ番号
物理ブロック番号
| ステータスビットP |
アクセスフィールドA |
ビット M |
外部ストレージ アドレス |
## を変更します
-
ステータス ビット P: プログラムがページにアクセスするときに、ページが参照用にメモリに転送されたかどうかを示すために使用されます。
-
アクセス フィールド A: 一定期間内にこのページがアクセスされた回数を記録するか、置換アルゴリズムが交換するためにこのページが最近アクセスされなかった期間を記録するために使用されます。ページ外を参照してください。
-
変更ビット M: ページがメモリに転送された後に変更されたかどうかを示します。
-
外部メモリ アドレス: ページをロードする際の参照用に、外部メモリ上のページのアドレス (通常は物理ブロック番号) を示すために使用されます。
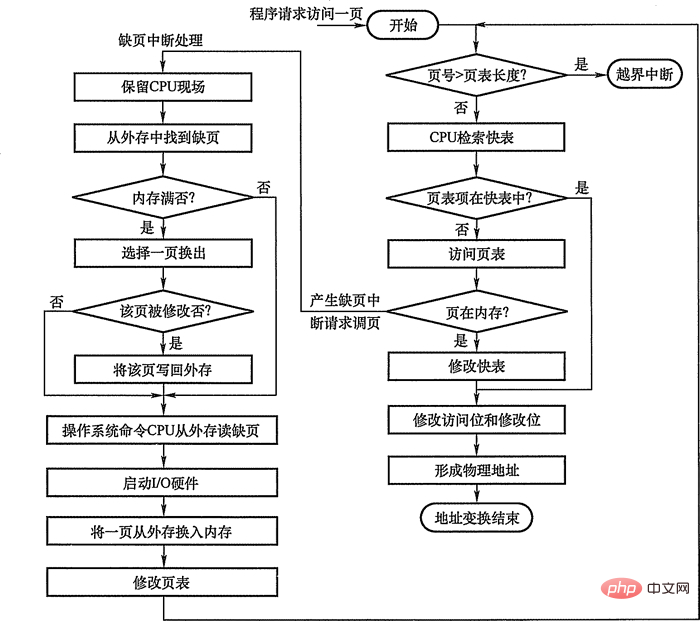
2.2 ページフォールト割り込みメカニズム
リクエストページングシステムでは、アクセスされるページが存在しないときは常に、メモリでは、ページ欠落割り込みが生成され、オペレーティング システムに欠落ページをメモリに転送するよう要求します。
このとき、ページフォールトが発生したプロセスはブロックされるはずです(ページング完了後にウェイクアップ) メモリに空きブロックがあればブロックを割り当て、そのブロックにロードするページをロードします、対応するページテーブルのページテーブルエントリを変更します。この時点でメモリに空きブロックがない場合、特定のページを削除する必要があります(削除されたページがメモリ期間中に変更された場合は、外部ファイルに書き戻す必要があります)メモリ)。
ページフォルト割り込みも、CPU環境の保護、割り込み原因の解析、ページフォルト割り込みハンドラへの移行、CPU環境の復元など、割り込みとして体験する必要があります。ただし、一般的な割り込みと比較すると、次の 2 つの明らかな違いがあります。
- 割り込み信号は、命令の実行後ではなく、命令の実行中に生成および処理されます。これは内部割り込みです。 。
- 命令の実行中に、複数のページフォルト割り込みが発生する可能性があります。
2.3 アドレス変換メカニズム
リクエストページングシステムのアドレス変換メカニズムは、ページングのアドレス変換メカニズムに基づいています。システム 、仮想メモリを実装するために特定の機能を追加することによって形成されます。
リクエストページングでのアドレス変換プロセス
アドレス変換を実行するときは、まず 高速テーブルを検索します。:
- アクセスするページが見つかった場合、ページ テーブル エントリのアクセス ビットが変更されます (書き込み命令も変更ビットをリセットする必要があります)、ページ テーブル エントリで指定された物理ブロック番号とページ内アドレスを使用して物理アドレスが形成されます。
- ページのページ テーブル エントリが見つからない場合は、ページ テーブルをメモリ内で検索し、ページ テーブル エントリのステータス ビット P と比較して、ページが転送されたかどうかを確認する必要があります。そうでない場合は、エラー メッセージが表示されます ページ フォルト割り込み。ページを外部メモリからメモリに転送するよう要求します。
ページテーブル論理アドレスのページ番号と占有メインメモリの物理ブロック番号の対応を示します。ページ ストレージ管理は、動的再配置を使用して操作をロードするときに、ページ テーブルを使用してアドレス変換を実行します。
高速テーブル (TLB、Translation Lookaside Buffer) は、キャッシュ メモリに格納される部分的なページ テーブルです。現在のプロセスのページ テーブルのキャッシュとして、その機能はページ テーブルと似ていますが、 アドレス マッピング速度を高速化し、アクセス速度を向上させます。
ページ テーブルはアドレス変換に使用されるため、CPU はメモリ データの読み書き時にメイン メモリに 2 回アクセスする必要があります (ページ テーブルのクエリと宛先アドレスへのアクセス)。 高速テーブルを使用すると、キャッシュ メモリとメイン メモリに 1 回アクセスするだけで済む場合があり、これにより検索が高速化され、命令の実行速度が向上します。
3. ページ置換アルゴリズム
プロセスの実行中に、アクセスするページがメモリにない場合は、そのページを取り込む必要があります。しかし、メモリに空き領域がない場合は、メモリからプログラムまたはデータのページをロードし、ディスクのスワップ領域に送信する必要があります。
呼び出すページを選択するアルゴリズムをページ置換アルゴリズム
と呼びます。優れたページ置換アルゴリズムでは、ページ置換頻度を低くする必要があります。つまり、将来再びアクセスされないページ、または将来長期間アクセスされないページが最初に呼び出される必要があります。
3.1 最適な置換アルゴリズム (OPT) ##最適な (最適、OPT) 置換アルゴリズム が選択されました 削除されたページは、今後使用されないか、長期間アクセスされないため、ページ フォールト率を最小限に抑えることができます。 しかし、現時点では、プロセスのメモリにある数千のページのうち、将来最も長い期間アクセスされなくなるのを人々が予測できないため、 このアルゴリズムでは不可能です。 が実装されますが、最適な置換アルゴリズムは 他のアルゴリズムを評価するために使用できます 。 システムが 3 つの物理ブロックを 1 つのプロセスに割り当てると仮定し、次のページ番号参照文字列を考慮します: 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1 プロセスの実行中、最初に 3 ページ 7、0、1 が順番にメモリにロードされます。プロセスがページ 2 にアクセスしようとすると、ページ フォールト割り込みが発生し、最適置換アルゴリズムに従って、18 回目のアクセス以降にのみ転送する必要があるページ 7 が選択され、削除されます。その後、ページ 0 がアクセスされるとき、ページ 0 はすでにメモリ内にあるため、ページ フォールト割り込みを生成する必要はありません。ページ 3 にアクセスすると、最適な置換アルゴリズムに基づいてページ 1 が削除されます...というように続きます。この図から、最適置換アルゴリズムを使用したときの状況がわかります。
#最適な変位アルゴリズムを使用した場合の変位グラフ
ページにアクセス70 | 1 | 2 | 0 | 3 | 0 | 4 | 2## 3 |
0 |
3 |
2 |
1 |
2 |
0 |
1 |
7 |
0 |
1 |
|
| #物理ブロック 1 | 7 7
7 | 2 |
| ##2 |
|
2
|
|
| 2 |
|
##2## #############################7############# ####### |
| #物理ブロック 2
|
0 |
0 |
0
|
#0 |
|
4 |
|
|
0
|
| ##0 |
|
|
|
| 0
|
|
| ##物理ブロック 3
|
|
##1 |
1
|
|
3
|
| 3
|
|
##3 |
|
| 1
|
|
|
##1 |
|
|
| #欠落ページなし | #√
|
√ |
√ |
| ##√
|
#√ |
|
| # #√
|
|
##√ |
|
| | #√
|
|
|
##ページフォルト中断回数が9回、ページ置換回数が6回であることがわかります。
3.2 先入れ先出し (FIFO) ページ置換アルゴリズム
最も早くメモリに入るページ が最初に削除されます。つまり、メモリ内に最も長く存在したページが削除されます。
このアルゴリズムの実装は簡単で、メモリ上に転送されたページを順番に従ってキューにリンクし、常に最も古いページを指すようにポインタを設定するだけです。ただし、プロセス中に一部のページが頻繁にアクセスされるため、このアルゴリズム はプロセスの実際の実行時間には適していません。
FIFO 置換アルゴリズムを使用した場合のディスプレイスメント グラフ
| ページにアクセス |
7 |
0 |
##1
|
2
| 0 | 3 | 0## 4 |
2 |
3 |
0 |
3 |
2 |
1 |
2 |
0 |
1 |
7 |
0 |
1 |
|
物理ブロック 1
| 7 |
7 |
7 |
2 |
|
2 |
2 |
| 4
4 |
4 |
0 |
|
|
#0
| 0 |
|
| ##7
7 |
7 |
|
物理ブロック 2 |
| 0
0 |
0 |
|
|
##3
|
33 | 2 | 2 | 2 |
|
|
##1
| 1
|
|
| ##1
0 |
0
|
| 物理的ブロック 3 |
|
| 1
1 |
|
1 |
#0 |
0 |
0 |
33 |
| |
|
3 |
2
|
|
| ##2 | 2
1 |
| 欠落ページ番号 | √ | √ | √ √ |
| ##√ | √##√ |
√ | √
| √ |
|
|
##√ |
√ |
|
|
√ |
√ |
√ |
|
FIFO アルゴリズムを使用すると、12 ページの置換が実行されます。これは、最適な置換アルゴリズムのちょうど 2 倍です。
FIFO アルゴリズムは、割り当てられた 物理ブロックの数が増加すると、ページ フォールトの数が減らずに 増加するという異常現象も引き起こします。これは 1969 年に Belady によって発見されました。したがって、以下の表に示すように、これは Belady 例外 と呼ばれます。
| ページにアクセス |
1 |
2 |
3 |
4 |
1 |
2 |
5 |
1 |
2 |
3 |
4 |
5 |
| 物理ブロック 1 |
1 |
1 |
1 |
4 | 4 |
4 |
5 |
|
| ##5 | 5 |
|
#物理ブロック 2
|
##2
| 2 | 2 | 1 | 1 | 1 |
|
| ##3
3 |
|
|
物理ブロック 3 |
|
| 3
3 |
3 |
2 |
2 |
|
|
| 2
4 |
|
|
##ページがありません
##√ | √
| √ |
√ |
√ | ##√ | √ |
|
|
##√ |
√
|
|
|
|
#物理的な数を増やして比較ブロック
|
#物理ブロック 1*
1
| 1 | 1
1 |
|
|
##5 |
5 |
5
| 5
4 | 4 |
|
物理ブロック 2* |
|
| 2 | 2
2 |
|
| 2 | 1 | 1
1 |
1
| 5 |
| 物理ブロック 3* |
|
|
| 3
3 |
|
##3 |
3 | 2 |
2
| 2
2 |
| ##物理ブロック 4* |
|
|
|
|
4
|
|
4 |
4 |
4 |
3 |
3 |
3 |
| 欠落ページなし |
√ |
√ |
√ |
√ |
|
|
√ |
√ |
√ |
√ |
√ |
√ |
##FIFO アルゴリズムのみ Belady 異常が発生する可能性がありますが、LRU および OPT アルゴリズムでは Belady 異常が発生することはありません。
3.3 最も最近使用されていない (LRU) 置換アルゴリズム
最も最近使用されていない (LRU) )置換アルゴリズムは、最も長期間アクセスされていないページを選択し、それを削除します。過去の期間にアクセスされていないページは、近い将来アクセスされなくなる可能性があると考えられます。
このアルゴリズムは、ページごとに 訪問フィールドを設定して、ページが最後に訪問されてからの経過時間を記録します。また、ページを削除するときに既存のページを選択します。ページ 中央値が最も高いものが除外されます。
LRU ページ置換アルゴリズム中のディスプレイスメント グラフ
| アクセス ページ |
7 |
0 | 1 |
2 |
0 |
3 |
0 | ## 4 | 2 | 3 | 0 | 3 | 2 | 1 | 2 | 0 | 1 | 7 | 0 | 1 |
物理ブロック 1 | 7 | 7 | 7 |
2
|
| 2 |
|
4##4 |
4 |
0 |
|
|
1
|
| ##1
| | 1
|
|
| 物理ブロック 2
|
# 0
| 0 |
0
|
|
0 |
|
0 | 0 |
3
| 3 |
|
|
##3 |
|
0
|
|
0
|
|
|
|
物理ブロック 3
|
|
##1 | 1
|
| 3 |
|
3 |
22 | 2
|
|
|
#2 |
|
2 |
| 7 |
|
|
##ページがありません |
# √ |
√
| √
√ |
| ##√ |
|
##√ |
√ |
√ |
√
|
|
| #√ |
| ##√ |
| ##√
|
| |
#LRU はパフォーマンスが優れていますが、レジスタとスタックのハードウェア サポートが必要であり、高価です。 #LRU は スタック クラス のアルゴリズムです。理論的には、スタック アルゴリズムでは Belady 例外が発生することは不可能であることが証明できます。 FIFO アルゴリズムは、スタック アルゴリズムではなくキューに基づいて実装されます。
3.4 クロック (CLOCK) 置換アルゴリズムLRU アルゴリズムのパフォーマンスは OPT に近いですが、実装が難しく、高価です; FIFO アルゴリズムは実装が簡単ですが、パフォーマンスは劣ります。したがって、オペレーティング システムの設計者は、比較的少ないオーバーヘッドで LRU のパフォーマンスに近づけようと、多くのアルゴリズムを試してきましたが、これらのアルゴリズムはすべて CLOCK アルゴリズムの変形です。
単純な CLOCK アルゴリズムは、使用ビットと呼ばれる追加ビットを各フレームに関連付けます。ページが最初にメイン メモリにロードされ、その後アクセスされると、使用ビットは 1 に設定されます。
ページ置換アルゴリズムの場合、置換に使用される 候補フレーム のセットは 循環バッファ として扱われ、それに関連付けられたポインタを持ちます。ページが置き換えられると、ポインタはバッファ内の次のフレームを指すように設定されます。 ページを置換する時期が来ると、オペレーティング システムはバッファをスキャンして、使用ビットが 0 の最初のフレームを見つけます。使用ビット 1 を持つフレームに遭遇すると、オペレーティング システムはそのビットを 0 にリセットします。すべてのフレームの使用ビットが 1 の場合、ポインタはバッファ内で 1 サイクルを完了し、すべての使用ビットをクリアします。0 に設定してそのままになります。元の位置で、フレーム内のページを置き換えます。このアルゴリズムは各ページのステータスを周期的にチェックするため、CLOCK アルゴリズムと呼ばれ、 最近使用されていない (NRU) アルゴリズムとも呼ばれます。 CLOCK アルゴリズムのパフォーマンスは LRU に比較的近く、使用するビット数を増やすことで CLOCK アルゴリズムをより効率的にすることができます。 変更ビット modified を 使用ビット used に追加すると、CLOCK 置換アルゴリズムが改善されます。 各フレームは、次の 4 つの状況のいずれかになります。
は最近アクセスされておらず、変更されていません (u=0、m=0)。
ポインタの現在位置から開始して、フレーム バッファをスキャンします。このスキャン中、使用ビットは変更されません。最初に遭遇したフレーム (u=0、m=0) が置換対象として選択されます。 変更されていないページを置換するときに変更されていないページを優先するという点で、単純な CLOCK アルゴリズムよりも優れています。 変更されたページは置換される前に に書き戻す必要があるため、これにより時間が節約されます。 4. ページ割り当て戦略
4.1 常駐セットのサイズページング仮想メモリの場合、実行の準備をするときに、プロセスのすべてのページをメイン メモリに読み込む必要はなく、また読み込むこともできないため、オペレーティング システムが読み込むページ数を決定する必要があります。言い換えると、 特定のプロセスにどのくらいのメイン メモリ スペースが割り当てられるか、これには次の点を考慮する必要があります。
固定割り当てのローカル置換- : It Eachプロセスには、実行中に
変更されない特定の数の物理ブロックが割り当てられます。プロセスの実行中にページ フォールトが発生した場合、プロセスのメモリ内にある ページから 1 ページだけを選択して交換し、必要なページを読み込むことができます。この戦略を実装する場合、各プロセスに割り当てる必要がある物理ブロックの数を決定するのは困難です。少なすぎるとページ フォールトが頻繁に発生し、多すぎると CPU やその他のリソースの使用率が低下します。 変数割り当てグローバル置換 : これは、システム内の各プロセスに特定の数の物理ブロックを割り当てる、最も簡単に実装できる物理ブロックの割り当てと置換戦略です。オペレーティング システム自体も、空き物理ブロックのキューを維持します。プロセスでページフォルトが発生した場合、システムは 空き物理ブロックキューから物理ブロックを取り出してプロセス- に割り当て、そこにロード対象のページをロードします。
可変割り当てローカル置換: 各プロセスに一定数の物理ブロックを割り当て、プロセス内でページフォルトが発生した場合、プロセスのメモリ上のページのみを割り当てます。他のプロセスの動作に影響を与えないように、ページを選択して入れ替えてください。プロセスの実行中にプロセス がページ ミスを頻繁に発生する場合、システム は、プロセスのページ ミス率が適切なレベルに達するまで、プロセスに物理ブロック を割り当てます。 、プロセス が実行中の場合 ページ フォールト率が特に低い場合は、 プロセスに割り当てられる物理ブロックの数 を適切に減らすことができます。
4.2 ページの読み込みのタイミング システムが処理時に欠落しているページを確実に転送するようにするため適切なタイミングで、次の 2 つのページング戦略を採用できます。
Pre-pagingStrategy: によると、局所性の原則、1 ページング戦略 複数の隣接するページは、一度に 1 ページをロードするよりも効率的である可能性があります。ただし、読み込まれたページのほとんどがアクセスされていない場合は、非効率的です。したがって、近い将来にアクセスされると予想されるページをメモリに事前にロードするには、予測ベースの事前ページング戦略を採用する必要があります。ただし、事前調整されたページの現在の成功率は約 50% にすぎません。したがって、この戦略は主にプロセスが初めてロードされるときに使用され、プログラマはどのページを最初にロードする必要があるかを指示します。 - リクエスト ページング
戦略 : プロセスが操作中にアクセスする必要がある ページがメモリ内にないため、リクエストが行われます。 , by システムは必要なページをメモリにロードします。この戦略で転送されたページには確実にアクセスがあり、実装も比較的容易なため、現在の仮想メモリでは主にこの戦略が使用されています。欠点は、 は一度に 1 ページしかロードしないことです。多くのページが読み込まれたり読み出されたりすると、I/O オーバーヘッドが過剰に消費されることになります。
4.3 ページをロードする場所ページング システムの 外部ストレージをリクエストします。 は、ファイルの保存に使用される ファイル領域 と、スワップ ページの保存に使用される スワップ領域 の 2 つの部分に分かれています。 スワップ領域は通常連続割り当て方式を使用しますが、ファイル領域は離散割り当て方式を使用するため、スワップ領域のディスクI/O速度はそれよりも高速です。ファイル領域の。quick。ページを転送できる状況は 3 つあります。
システムに十分なスワップ領域スペースがある - :
スワップ領域からすべて転送できるページング速度を向上させるには必須のページです。このため、プロセスを実行する前に、プロセスに関連するファイルをファイル領域 からスワップ領域 にコピーする必要があります。
システムには十分なスワップ領域スペースがありません- : 変更されないすべての
ファイルは、 ファイル領域#から直接コピーされます。 # #転送します (スワップアウト時に書き戻す必要はありません)。ただし、変更される可能性のあるパーツについては、スワップアウト時にスワップ領域に転送し、後で必要になったときにスワップ領域から元に戻す必要があります。 UNIX の方法 : プロセスに関連するファイルはファイル領域に配置されるため、実行されていない - ページはファイル領域から転送する必要があります。 ###。以前に実行されたがスワップアウトされたページはスワップ領域に配置されるため、次回ロードされるときに
がスワップ領域から転送される必要があります 。プロセスが要求した共有ページが他のプロセスによってメモリ上に転送された場合、スワップ領域から転送する必要はありません。 5. ページ ジッター (乱流) とワーキング セット (常駐セット)
5.1 ページ ジッター (乱流) )
ページ置換プロセス中の最悪の状況の 1 つは、スワップアウトされたばかりのページがすぐにスワップアウトされ、スワップインされたばかりのページもすぐにスワップアウトされることです。 、この 頻繁なページング動作はスラッシング、またはスラッシング と呼ばれます。プロセスが実行時間 よりも ページングに多くの時間を費やしている場合、プロセスはスラッシングしています。 頻繁なページ フォールト割り込み (ジッター) は、主に プロセスによって頻繁にアクセスされるページの数が、利用可能な物理ページ フレームの数よりも多いために発生します。仮想メモリ テクノロジにより、より多くのプロセスをメモリ内に保持して、システム効率を向上させることができます。定常状態では、メイン メモリのほぼすべてがプロセス ブロックによって占有されており、プロセッサとオペレーティング システムはできるだけ多くのプロセスに直接アクセスできます。しかし、適切に管理されていない場合、プロセッサの時間のほとんどは、プロセスの命令を実行するのではなく、ブロックのスワップ、つまりページのロード操作の要求に費やされることになり、システム効率が大幅に低下します。
5.2 ワーキング セット (常駐セット)
ワーキング セット (または常駐セット) は、プロセスが 特定の間隔内でアクセスするページのセット を指します。頻繁に使用されるページはワーキング セットに含める必要がありますが、長期間使用されなかったページはワーキング セットから破棄されます。システムのスラッシングを防ぐには、適切なワーキング セット サイズを選択する必要があります。
ワーキング セット モデルの原理は、オペレーティング システムが各プロセスのワーキング セットを追跡し、そのワーキング セットより大きい物理ブロックをプロセスに割り当てることです。空き物理ブロックがある場合は、別のプロセスをメモリに転送して、マルチプログラムの数を増やすことができます。すべてのワーキング セットの合計が増加して利用可能な物理ブロックの総数を超えると、オペレーティング システムはプロセスを一時停止し、ページアウトし、その物理ブロックを他のプロセスに割り当ててスラッシングを防ぎます。
ワーキング セットのサイズを正しく選択すると、 メモリ使用率とシステム スループットの向上 に重要な影響を与えます。
6. 概要
ページング管理メソッドと セグメンテーション管理メソッドは、メモリ内など多くの場所で類似しています。これらは不連続であり、アドレス マッピングなどを実行するためのアドレス変換メカニズムを備えています。表 3-20 は、ページング管理方式とセグメンテーション管理方式をさまざまな観点から比較したものです。
| ページング | #セクション |
目的 |
ページは情報の物理単位です。ページングは、メモリの外部部分を削減し、メモリ使用率を向上させるための 個別割り当て を実現する方法です。言い換えれば、ページングはユーザーのニーズではなく、システム管理のニーズによってのみ行われます。
| は情報の論理単位であり、意味が比較的完全な情報セットが含まれています。 。セグメンテーションの目的は、 ユーザーのニーズをより適切に満たすことです
|
length | ページの サイズは固定されており、次のように決定されます。システム では、システムは論理アドレスをページ番号とページ アドレスの 2 つの部分に分割します。これらはマシン ハードウェアによって実装されるため、システム
| には 1 つのサイズのページしか存在できません。 セグメントの長さは固定ではありません ユーザが作成したプログラムによって異なります 通常、コンパイラはストリームプログラムをコンパイルする際に、情報の性質に応じてアドレス空間を分割します。 #ジョブのアドレス空間は 1 次元、つまり単一の線形アドレス空間です。プログラマはアドレスを表すためにニーモニックを使用するだけで済みます。
| ジョブのアドレス空間は 2 次元です。プログラマはセグメント名とセグメント内のアドレスの両方を指定する必要がある場合
| フラグメント |
内部フラグメントはありますが、フラグメントはありません外部フラグメント |
| 外部フラグメンテーションあり、内部フラグメンテーションなし |
| 「共有」と「動的リンク」達成は簡単ではありません | 実装は簡単
|
#関連する推奨事項: 「 | Linux ビデオ チュートリアル」 |
|
|
|
以上がLinux は仮想メモリを実装するために何を使用しますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。








 #2. 仮想メモリを実装するためのページング管理のリクエスト
#2. 仮想メモリを実装するためのページング管理のリクエスト












![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



