

インタビューの答え: 各 MySQL テーブルのデータ数は 2,000 万以下が最適ですよね?

MySQL の各テーブルにはどれくらいのデータを保存できますか?実際には、テーブルごとにフィールドやフィールドが占める領域が異なり、最適なパフォーマンスで格納できるデータ量も異なるため、手動で計算する必要があります。
内容は次のとおりです
以下は私の友人のインタビュー記録です:
このステートメントには何の問題もないようですよね? 心配しないで、読み続けましょう:インタビュアー: 教えてくださいインターンでは何をしていたんですか?
友人: インターンシップ中に、ユーザーの操作記録を保存する機能を構築しましたが、主に上流サービスから送られてくるユーザーの操作情報をMQから取得し、MySQLに保存してデータウェアハウスに提供する機能です。 . 同僚が使用します。
友人: データ量が比較的多く、毎日 4,000 ~ 5,000 万件のエントリがあるため、それに対してサブテーブル操作も実行しました。 3 つのテーブルが毎日定期的に生成され、テーブル内の過剰なデータによってクエリ速度が低下することを防ぐために、データがモデル化されてこれら 3 つのテーブルにそれぞれ格納されます。
インタビュアー: では、なぜそれを 3 つの表に分割するのでしょうか。 ? 2 つのテーブルは機能しません。テーブルが 4 つあれば機能しないでしょうか? 友人: 各 MySQL テーブルのデータは 2,000 万個を超えてはなりません。そうしないと、クエリ速度が低下し、パフォーマンスに影響します。 1 日あたりのデータは約 5,000 万個であるため、3 つのテーブルに分割する方が安全です。 インタビュアー: 他に何かありますか? 友人: もうだめです...話し終えましたが、何か見えましたか?私の友人の答えに何か問題があると思いますか?何してるの、痛い
インタビュアー: それなら戻って通知を待ちます。
序文
多くの人は、各 MySQL テーブルのデータが 2,000 万個を超えないようにするのが最善だと言います。そうしないと、パフォーマンスの低下につながります。 Alibaba の Java 開発マニュアルには、単一テーブルの行数が 500 万を超える場合、または単一テーブルの容量が 2GB を超える場合にのみ、データベースとテーブルを分割することをお勧めすると記載されています。
しかし、実際には、この 2,000 万または 500 万は単なる大まかな数字であり、すべてのシナリオに当てはまるわけではありません。テーブル データが 2,000 万を超えない限り、盲目的に考えると、問題ありませんが、システムのパフォーマンスが大幅に低下する可能性があります。
この記事を読むには、特定の MySQL 基盤が必要です。 InnoDB と B-tree についてのある程度の理解、MySQL の学習経験が 1 年以上 (1 年くらい?)、「一般的に B-tree の高さを維持する方が良い」という理論的知識を知っている必要があるかもしれません。 InnoDB のツリーは 3 レベル以内にあります。」
この記事では「InnoDBの高さ3のBツリーにはどのくらいのデータを格納できるのか?」というテーマを中心に説明します。さらに、この記事のデータの計算は比較的厳密です (少なくとも、インターネット上の関連ブログ投稿の 95% 以上よりも厳密です)。これらの詳細が気になり、現時点ではよくわからない場合は、読み続けてください。 この記事を読むのにかかる時間は 10 ~ 20 分程度ですが、読みながらデータを確認すると 30 分ほどかかる場合があります。 #この記事のマインドマップ##基礎知識の簡単な復習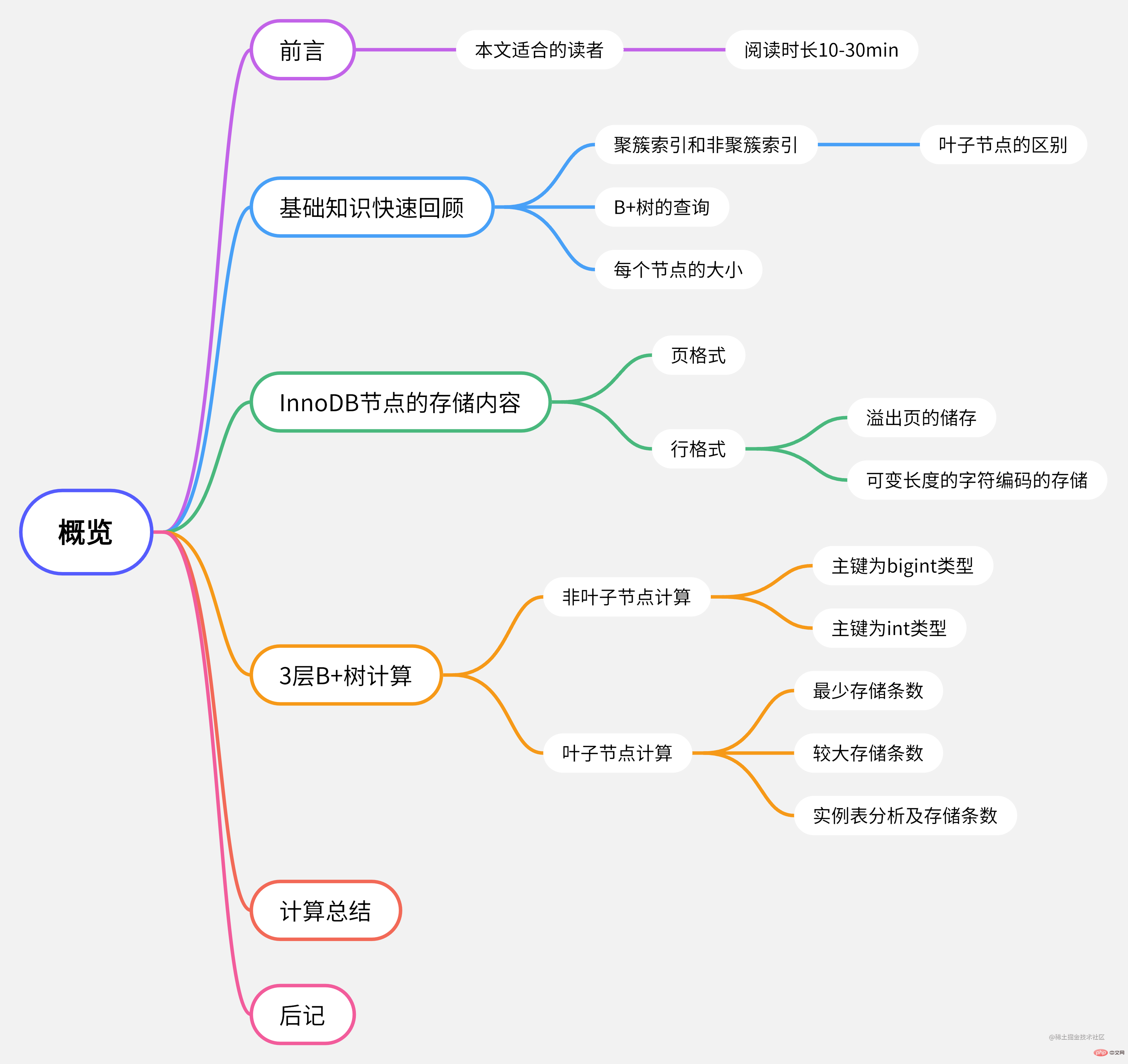
ご存知のとおり、MySQL における InnoDB のストレージ構造は B ツリーです。特徴は大まかに以下の通りなので、一緒に簡単におさらいしていきましょう!
注: 次の内容は本質です。読んだり理解できない学生は、まずこの記事を保存し、知識ベースを取得した後に戻って読むことをお勧めします。 ##。 ??
データ テーブルは通常、1 つ以上のツリーのストレージに対応します。ツリーの数はインデックスの数に関連します。各インデックスには個別のツリーがあります。
- クラスター化インデックスと非クラスター化インデックス:
-
主キー インデックスもクラスター化インデックスであり、非主キー インデックスは非クラスター化インデックスです。
形式情報を除き、両方のインデックスの非リーフ ノードはインデックス データのみを格納します たとえば、インデックスが id の場合、非リーフ ノードは id データを格納します。 -
リーフ ノード間の違いは次のとおりです:
- クラスター化インデックスのリーフ ノードには、通常、このデータの すべてのフィールド情報が格納されます。したがって、id = 1
のテーブルからselect * を実行すると、常にリーフ ノードに移動してデータを取得します。 - 非クラスター化インデックスのリーフ ノードには、このデータに対応する 主キーとインデックス列の情報が格納されます。たとえば、この非クラスター化インデックスがユーザー名で、テーブルの主キーが id の場合、非クラスター化インデックスのリーフ ノードにはユーザー名と ID が格納されますが、他のフィールドは格納されません。 これは、まず非クラスター化インデックスから主キーの値を検索し、次に主キー インデックスに基づいてデータの内容をチェックすることと同じです。通常、(インデックスがカバーされていない限り) 2 回チェックする必要があります。 Back to the table とも呼ばれます。これは、データが保存されている実際のアドレスを指すポインターの保存に少し似ています。
- クラスター化インデックスのリーフ ノードには、通常、このデータの すべてのフィールド情報が格納されます。したがって、id = 1
-
B ツリーのクエリは上から下へ階層ごとにクエリされます。一般的に、B ツリーの高さは 3 階層以内に抑えるのがよいと考えられます。つまり、上の 2 つの層はインデックスであり、最後の層はデータを格納します。このようにして、テーブルを検索するときに必要なディスク IO は 3 回だけです (ルート ノードがメモリ内に常駐するため、実際には 1 回少なくなります)。 、保存できるデータ量も非常に印象的です。
データ量が多すぎてBの数が4レベルになると、各クエリに4回のディスクIOが必要となり、パフォーマンスが低下します。 だからこそ、InnoDB の 3 層 B ツリーが保存できるデータの最大数を計算します。
-
各 MySQL ノードのデフォルト サイズは 16 KB です。つまり、各ノードは最大 16 KB のデータを保存でき、そのデータは変更可能で、最大 64 KB で、最小 4KB。
拡張: 特定の行のデータが特に大きく、ノードのサイズを超えた場合はどうなりますか?
MySQL5.7 ドキュメントでは次のように説明されています:
4KB、8KB、16KB、および 32KB 設定の場合、最大行長はデータベース ページの半分よりわずかに小さくなります。たとえば、デフォルトの 16KB ページ サイズの場合、最大行長は 8KB よりわずかに小さくなり、デフォルトの 32KB ページ サイズの場合、最大行長は 16KB よりわずかに小さくなります。
64KB ページの場合、最大行長は 16KB よりわずかに小さくなります。
行が最大行長を超える場合、行が最大行長制限に達するまで、可変長列は外部ページに格納されます。 つまり、この行のデータ長を減らすために、可変長の varchar と text が外部ページに格納されます。

MySQL :: MySQL 5.7 リファレンス マニュアル :: 14.12.2 ファイル スペース管理
- MySQL のクエリ速度は、主にディスクの読み取りおよび書き込み速度に依存します。これは、MySQL が一度に 1 つのノードのみをメモリに読み取り、データを通じて次のターゲットを見つけるためです。ノードの位置を読み取り、必要なデータがクエリされるかデータが存在しないまで、次のノードのデータを読み取ります。 各ノードのデータをクエリする必要はないのではないかと疑問に思う人もいるでしょう。ここで所要時間が計算されないのはなぜですか? これは、ノード データ全体を読み取った後、メモリに保存されるためです。メモリ内のノード データのクエリには、実際には非常に短い時間がかかります。MySQL クエリ メソッドと組み合わせると、時間の複雑さはほぼゼロになります。
MySQL InnoDB ノード ストレージのコンテンツ
Innodb の B ツリーでは、私たちがよく参照するノードは ページ (ページ) と呼ばれます。 )、各ページにはユーザー データが保存され、すべてのページがまとめて B ツリーを形成します (もちろん、実際にはさらに複雑になりますが、保存できるデータの数を計算する必要があるだけなので、当面はこうなるかもしれません、わかりますか?)
Page は、InnoDB ストレージ エンジンがデータベースを管理するために使用する最小のディスク ユニットです。各ノードは 16 KB であるとよく言われますが、実際には各ページのサイズを意味します。は16KBです。
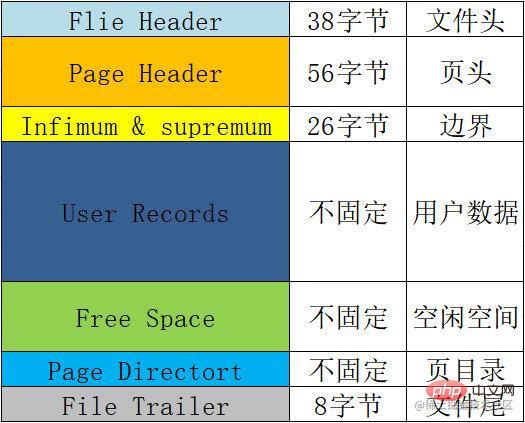
この 16KB のスペースには、ページ形式情報と 行形式情報を保存する必要があります。行形式情報には、メタデータとユーザー データも含まれています。したがって、計算するときは、これらすべてのデータを含める必要があります。
ページ形式
各ページの基本的な形式、つまり各ページに含まれる情報の概要表は次のとおりです。 :
| 名前 | スペース | 意味や機能など |
|---|---|---|
ファイル ヘッダー |
38 バイト | ファイル ヘッダー。ページのヘッダー情報を記録するために使用されます。 チェックサム、ページ番号、前後のノードへの 2 つのポインター、 ページ タイプ、テーブル スペースなどが含まれます。 |
ページ ヘッダー |
56 バイト | ページ ヘッダー。ページのステータス情報を記録するために使用されます。 ページ ディレクトリ内のスロットの数、空き領域のアドレス、このページのレコード数、 削除されたレコードが占有しているバイト数などが含まれます。 |
上限と上限 |
26 バイト | は、現在のページ レコードの境界値を制限するために使用されます。最小値と最大値。 |
ユーザー レコード |
未修正 | ユーザー レコード、挿入したデータはここに保存されます。 |
#空きスペース | 未修正空きスペース。ユーザー レコードが追加されるときにここからスペースを取得します。 | |
ページ ディレクトリ | Unfixedページ ディレクトリは、ページ内のユーザー データの位置情報を保存するために使用されます。 | 各スロットには 4 ~ 8 個のユーザー データが格納され、1 スロットは 1 ~ 2 バイトを占有します。 1 スロットが 8 データを超えると、自動的に 2 つのスロットに分割されます。 |
ファイル トレーラー | 8 バイトファイルの終わりの情報。主にページの整合性を検証するために使用されます。 |
| 名前 | スペース | 意味や働きなど |
|---|---|---|
| 行レコードのヘッダー情報 | 5 バイト | 行レコードのヘッダー情報 いくつかのフラグ ビット、データ型、その他の情報が含まれます 削除フラグ、最小レコード フラグ、ソートなどレコード、データ型、 ページ内の次のレコードの位置など。 |
| 可変長フィールド リスト | は固定されていません | 保存できるものを保存します varchar、text、blob などの可変長フィールドが占めるバイト数。 可変長フィールドの長さが 255 バイト未満の場合は、 1 バイト で表され、255 バイトを超える場合は、 2 で表されます。バイト。 テーブルフィールドに複数の可変長フィールドがある場合、リストには複数の値が存在しますが、何もない場合は保存されません。 |
| null 値リスト | 未修正 | null になり得るフィールドが null かどうかを格納するために使用されます。 ここでは、Null 許容フィールドはそれぞれ 1 ビットを占有します。これがビットマップの考え方です。 このリストが占めるスペースはバイト単位で増加します。たとえば、NULL にできる 列が 9 ~ 16 個ある場合、1.5 バイトではなく 2 バイトが使用されます。 |
| トランザクション ID とポインター フィールド | 6 7 バイト | MVCC を知っている人は、データ行に 6 バイトのトランザクション ID が含まれていることを知っているはずです。および は 7 バイトのポインター フィールドです。 主キーが定義されていない場合は、追加の 6 バイトの行 ID フィールドが存在します。 もちろん、誰もが主キーを持っているため、この行 ID は計算しません。 |
| 未修正 | この部分は実際のデータです。 |


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 PHPがMySQLに接続された後、ページは空白です。無効なDIE()関数の理由は何ですか?
Apr 01, 2025 pm 03:03 PM
PHPがMySQLに接続された後、ページは空白です。無効なDIE()関数の理由は何ですか?
Apr 01, 2025 pm 03:03 PM
PHPがMySQLに接続した後、ページは空白になり、DIE()関数が失敗する理由。 PHPとMySQLデータベースの間の接続を学習するとき、あなたはしばしばいくつかの混乱することに遭遇します...

 ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
多くのウェブサイト開発者は、ランプアーキテクチャの下でnode.jsまたはPythonサービスを統合する問題に直面しています:既存のランプ(Linux Apache MySQL PHP)アーキテクチャWebサイトのニーズ...
 PCとモバイル側で同じページを共有し、キャッシュの問題を処理する方法は?
Apr 01, 2025 pm 01:57 PM
PCとモバイル側で同じページを共有し、キャッシュの問題を処理する方法は?
Apr 01, 2025 pm 01:57 PM
PCとモバイル側で同じページを共有し、キャッシュの問題を処理する方法は? Nginxでは、Baotaの背景を使用して構築されたPHP MySQL環境、PCサイドの作成方法と...
 Debian文字列は、複数のブラウザと互換性があります
Apr 02, 2025 am 08:30 AM
Debian文字列は、複数のブラウザと互換性があります
Apr 02, 2025 am 08:30 AM
「DebianStrings」は標準的な用語ではなく、その特定の意味はまだ不明です。この記事は、ブラウザの互換性について直接コメントすることはできません。ただし、「DebianStrings」がDebianシステムで実行されているWebアプリケーションを指す場合、そのブラウザの互換性はアプリケーション自体の技術アーキテクチャに依存します。ほとんどの最新のWebアプリケーションは、クロスブラウザーの互換性に取り組んでいます。これは、次のWeb標準と、適切に互換性のあるフロントエンドテクノロジー(HTML、CSS、JavaScriptなど)およびバックエンドテクノロジー(PHP、Python、Node.jsなど)を使用することに依存しています。アプリケーションが複数のブラウザと互換性があることを確認するには、開発者がクロスブラウザーテストを実施し、応答性を使用する必要があることがよくあります
 DockerはLNMP環境を構築します:単一のDockerFileまたはDockerの構成はより良いですか?
Apr 01, 2025 pm 02:09 PM
DockerはLNMP環境を構築します:単一のDockerFileまたはDockerの構成はより良いですか?
Apr 01, 2025 pm 02:09 PM
dockerfileのベストプラクティスLNMP環境学習のためのベストプラクティスDocker中に、多くの開発者は独自のLNMP(Linux、Nginx、MySQL、PHP)を構築しようとします...
 RedisキューとMySQLの安定性の比較:なぜRedisはデータ損失になりやすいのですか?
Apr 01, 2025 pm 02:24 PM
RedisキューとMySQLの安定性の比較:なぜRedisはデータ損失になりやすいのですか?
Apr 01, 2025 pm 02:24 PM
RedisキューとMySQLの安定性の比較:なぜRedisはデータ損失になりやすいのですか?開発環境では、php7.2とthinkphpフレームワークを使用して、私たちはしばしば協力の選択に直面しています...
 DjangoとMySQLを使用して、数十万から100万個のデータを処理する場合、4コア8Gメモリサーバーはどのようなキャッシュソリューションを選択する必要がありますか?
Apr 01, 2025 pm 11:36 PM
DjangoとMySQLを使用して、数十万から100万個のデータを処理する場合、4コア8Gメモリサーバーはどのようなキャッシュソリューションを選択する必要がありますか?
Apr 01, 2025 pm 11:36 PM
DjangoとMySQLを使用して、DjangoおよびMySQLデータベースを使用するときに大量のデータボリュームを処理します。データボリュームが数十万から100万または200万に達すると...