

Redis 高可用性アーキテクチャの構築から原理分析まで

この記事では、Redis に関する関連知識を紹介しており、高可用性アーキテクチャの構築から原理分析まで、関連する内容を中心に紹介していますので、一緒に見ていきましょう。 . .

推奨学習: Redis ビデオ チュートリアル
会社の最近のシステム最適化により、大きなテーブルがいくつかのテーブルに分割されました。前に、今度は再び redis を実行します。 redis に関しては、redis サービスを Alibaba Cloud から自社サーバーに移行することが要件の 1 つです (会社の性質上)。この機会を利用して、Redis の高可用性クラスター アーキテクチャを確認してみました。 Redis クラスター モードには、マスター/スレーブ レプリケーション モード、センチネル モード、クラスター クラスター モードの 3 つがあり、一般的にはセンチネル クラスターとクラスター クラスターの使用頻度が高くなります。これら 3 つのモードについて簡単に理解しましょう。
永続化メカニズム
クラスター アーキテクチャを理解する前に、最初に Redis の永続化メカニズムを紹介する必要があります。これは、永続化が後続のクラスターに関係するためです。 Redis の永続性とは、Redis サービスがダウンしたときにクラスター アーキテクチャでのデータの回復やマスター/スレーブ ノードのデータ同期を防ぐために、いくつかのルールに従ってメモリにキャッシュされたデータを保存することです。 Redis 永続化には RDB と AOF の 2 つの方法があり、バージョン 4.0 以降、新しいハイブリッド永続化モードが導入されました。
RDB
RDB は、redis によってデフォルトで有効になっている永続化メカニズムです。その永続化メソッドは、ユーザーによって構成されたルールに基づいています。「X 秒以内に少なくとも Y 個の変更が発生しました」 、スナップショットを生成し、それを dump.rdb バイナリ ファイルに保存します。デフォルトでは、redis は 3 つの構成で構成されています: 900 秒以内に少なくとも 1 つのキャッシュ キーの変更が発生した、300 秒以内に少なくとも 10 のキャッシュ キーの変更が発生した、および 60 秒以内に少なくとも 10,000 の変更が発生した。

Redis の自動スナップショット永続データに加えて、メモリ データの手動スナップショットに役立つ 2 つのコマンドがあります。これらの 2 つのコマンドは、saveand# です。 ##bgs保存。

save: データ スナップショットを同期的に実行します。キャッシュされたデータの量が多い場合、キャッシュされたデータがブロックされます。他のコマンドの実行効率が低い。
bgsave: 非同期でデータ スナップショットを実行します。Redis メイン スレッドは、データ スナップショットを実行するために子プロセスをフォークアウトします。これにより、他のプロセスの実行がブロックされません。コマンドにより効率が向上します。非同期スナップショットが使用されるため、スナップショットのプロセス中に他のコマンドによってデータが変更される可能性があります。この問題を回避するために、reids ではコピーオンライト (Cpoy-On-Write) 方式を採用しており、このときスナップショットを取得するプロセスはメインスレッドによってフォークされるため、メインスレッドのリソースを享受することができます。スナップショット プロセス中にデータ変更が発生すると、データがコピーされてコピー データが生成され、子プロセスが変更されたコピー データを dump.rdb ファイルに書き込みます。
# appendonly no 关闭AOF持久化 appendonly yes # 开启AOF持久化 # The name of the append only file (default: "appendonly.aof") appendfilename "appendonly.aof" # 持久化文件名
appendfsync Everysec を使用します。
appendfsync always #每次有新的改写命令时,都会追加到磁盘的aof文件中。数据安全性最高,但效率最慢。 appendfsync everysec # 每一秒,都会将改写命令追加到磁盘中的aof文件中。如果发生宕机,也只会丢失1秒的数据。 appendfsync no #不会主动进行命令落盘,而是由操作系统决定什么时候写入到磁盘。数据安全性不高。


| ##RDB | AOF||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 低 | データセキュリティ | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 高 | スペース使用量 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 高 |
混合模式由于RDB持久化方式容易造成数据丢失,AOF持久化方式数据恢复较慢,所以在redis4.0版本后,新出来混合持久化模式。混合持久化将RDB和AOF的优点进行了集成,并而且依赖于AOF,所以在使用混合持久化前,需要开启AOF。在开启混合持久化后,当发生AOF重写时,会将内存中的数据以RDB的数据格式保存到aof文件中,在下一次的重写之前,混合持久化会追加保存每条改写命令到aof文件中。当需要恢复数据时,会加载保存的rdb内容数据,然后再继续同步aof指令。 # AOF重写配置,当aof文件达到60MB并且比上次重写后的体量多100%时自动触发AOF重写 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-use-rdb-preamble yes # 开启混合持久化# aof-use-rdb-preamble no # 关闭混合持久化 ログイン後にコピー AOF重写是指当aof文件越来越大时,redis会自动优化aof文件中无用的命令,从而减少文件体积。比如在处理文章阅读量时,每查看一次文章就会执行一次Incr命令,但是随着阅读量的不断增加,aof文件中的incr命令也会积累的越来越多。在AOF重写后,将会删除这些没用的Incr命令,将这些命令直接替换为set key value命令。除了redis自动重写AOF,如果需要,也可以通过 主从复制在生产环境中,一般不会直接配置单节点的redis服务,这样压力太大。为了缓解redis服务压力,可以搭建主从复制,做读写分离。redis主从复制,是有一个主节点Master和多个从节点Slave组成。主从节点间的数据同步只能是单向传输的,只能由Master节点传输到Slave节点。
环境配置准备三台linux服务器,其中一台作为redis的主节点,两台作为reids的从节点。如果没有足够的机器可以在同一台机器上面将redis文件多复制两份并更改端口号,这样可以搭建一个伪集群。
修改redis.conf文件中的replicaof,配置主节点的ip和端口号,并且开启从节点只读。
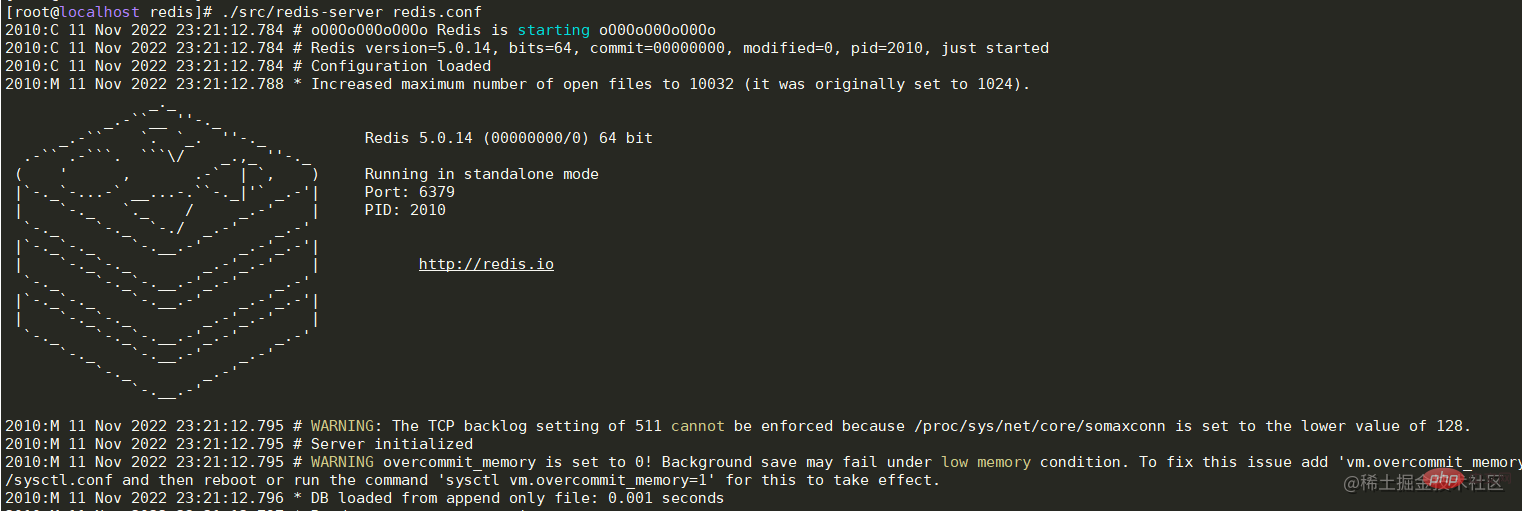
./src/redis-server redis.conf ログイン後にコピー ログイン後にコピー
./src/redis-server redis.conf ログイン後にコピー ログイン後にコピー 启动成功后可以看到日志中显示已经与Master节点建立的连接。
全部节点启动成功后,Master节点可以查看从节点的连接状态,offset偏移量等信息。 info replication # 主节点查看连接信息 ログイン後にコピー
数据同步流程
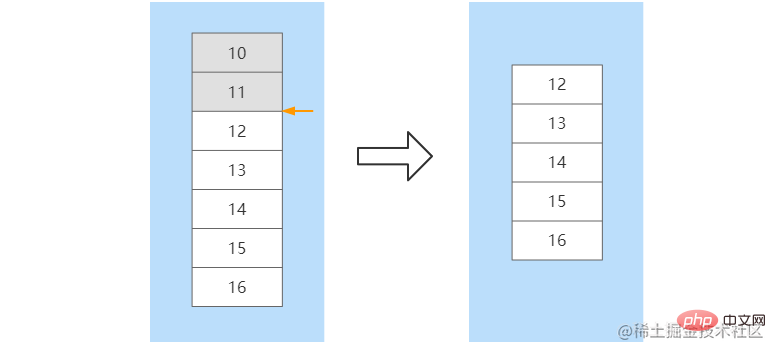
部分数据同步发生在Slave节点发生宕机,并且在短时间内进行了服务恢复。短时间内主从节点之间的数据差额不会太大,如果执行全量数据同步将会比较耗时。部分数据同步时,Slave会向Master节点建立socket长连接并发送带有一个offset偏移量的数据同步请求,这个offset可以理解数据同步的位置。Master节点在收到数据同步请求后,会根据offset结合buffer缓冲区内新的改写命令进行位置确定。如果确定了offset的位置,那么就会将这个位置往后的所有改写命令发送到Slave节点。如果没有确定offset的位置,那么会再次执行全量数据同步。比如,在Slave节点没有宕机之前命令已经同步到了offset=11这个位置,当该节点重启后,向Master节点发送该offset,Master根据offset在缓冲区中进行定位,在定位到11这个位置后,将该位置往后的所有命令发送给Slave。在数据同步完成后,后续Master节点的命令会不断的发送到该Slave节点
优缺点
Sentinel モードでは、マスター/スレーブがさらに最適化されます。アーキテクチャ内のサーバーの状態に関しては、ダウンタイムが発生すると、Sentinel が短期間で新しいマスター ノードを選択し、マスターとスレーブの切り替えを実行します。それだけでなく、マルチセンチネル ノードでは、各センチネルが相互に監視し、センチネル ノードがダウンしているかどうかを監視します。#環境構成
|


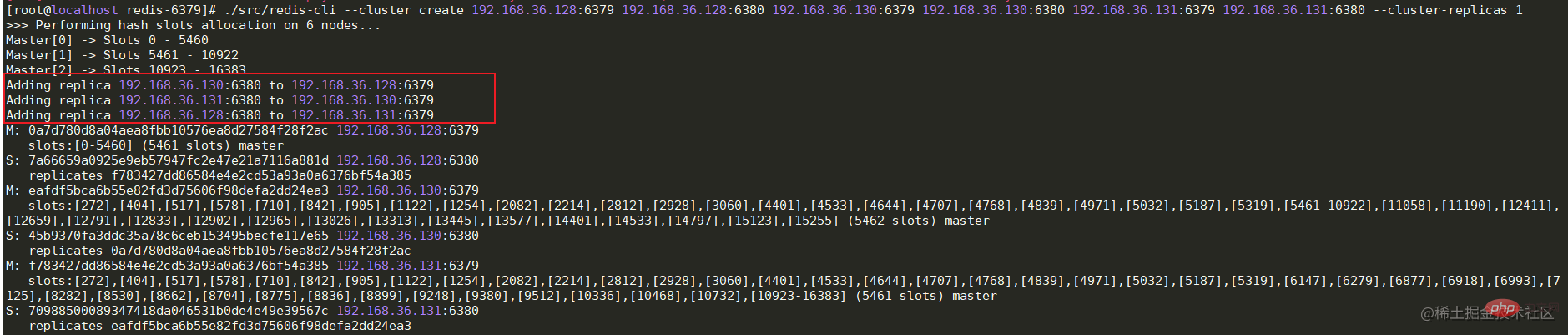
 3. 依次启动从节点36.130,36.131机器中的redis服务
3. 依次启动从节点36.130,36.131机器中的redis服务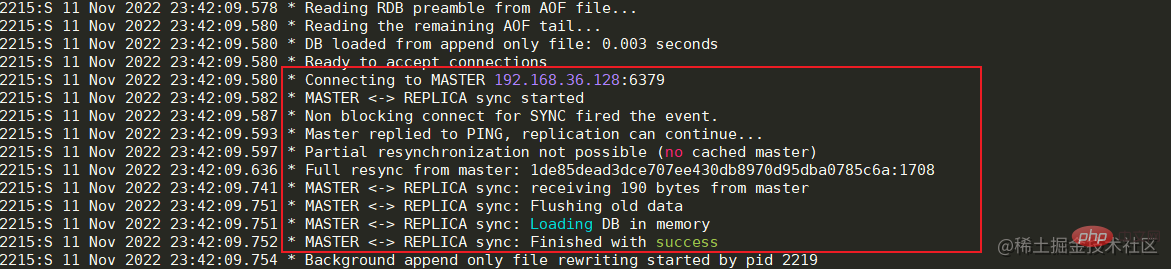 如果出现与Master节点的连接被拒,那么先检查Master节点的服务器是否开启防火墙,如果开启,可以开放6379端口或者关闭防火墙。如果防火墙被关闭但连接仍然被拒,那么可以修改Master节点服务中的redis.conf文件。将bing 127.0.0.1修改为本机对外的网卡ip或者直接注释掉即可,然后重启服务器即可。
如果出现与Master节点的连接被拒,那么先检查Master节点的服务器是否开启防火墙,如果开启,可以开放6379端口或者关闭防火墙。如果防火墙被关闭但连接仍然被拒,那么可以修改Master节点服务中的redis.conf文件。将bing 127.0.0.1修改为本机对外的网卡ip或者直接注释掉即可,然后重启服务器即可。

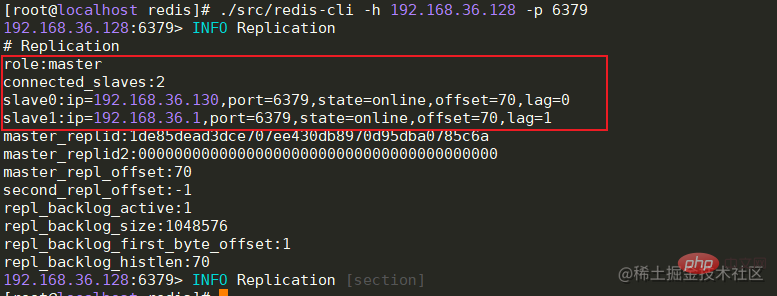
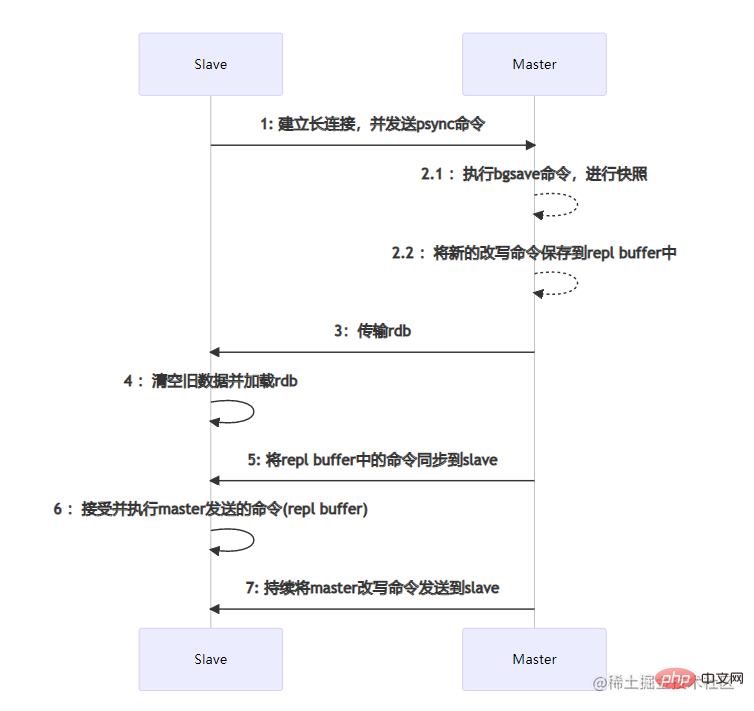 主从节点之间的数据同步是通过建立socket长连接来进行传输的。当Slave节点启动时,会与Master节点建立长连接,并且发送psync同步数据命令。当Master节点收到psync命令时,会执行pgsave进行rdb内存数据快照(这里的rdb快照与conf文件中是否开启rdb无关),如果在快照过程中有新的改写命令,那么Master节点会将这些命令保存到repl buffer缓冲区中。当快照结束后,会将rdb传输给Slave节点。Slave节点在接收到rdb后,如果存在旧数据,那么会将这些旧数据清除并加载rdb。加载完成后会接受master缓存在repl buffer中的新命令。在这些步骤全部执行完成后,主从节点已经算连接成功了,后续Master节点的命令会不断的发送到Slave节点。如果在高并发的情况下,可能会存在数据延迟的情况。
主从节点之间的数据同步是通过建立socket长连接来进行传输的。当Slave节点启动时,会与Master节点建立长连接,并且发送psync同步数据命令。当Master节点收到psync命令时,会执行pgsave进行rdb内存数据快照(这里的rdb快照与conf文件中是否开启rdb无关),如果在快照过程中有新的改写命令,那么Master节点会将这些命令保存到repl buffer缓冲区中。当快照结束后,会将rdb传输给Slave节点。Slave节点在接收到rdb后,如果存在旧数据,那么会将这些旧数据清除并加载rdb。加载完成后会接受master缓存在repl buffer中的新命令。在这些步骤全部执行完成后,主从节点已经算连接成功了,后续Master节点的命令会不断的发送到Slave节点。如果在高并发的情况下,可能会存在数据延迟的情况。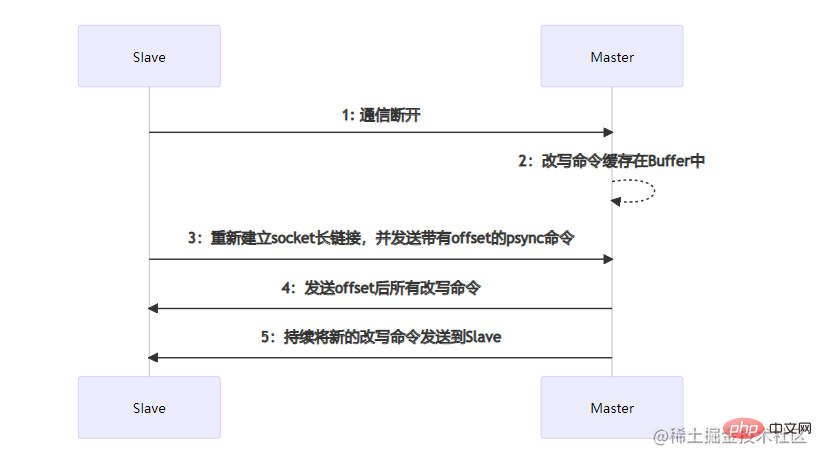
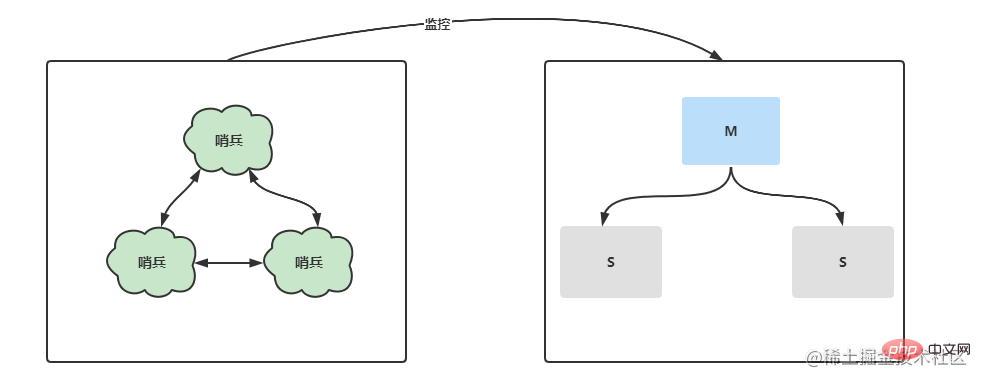


 搭建成功后,就来通过代码演示主节点宕机的情况下,哨兵是否会帮助系统自动进行主备切换。在springboot项目中引入对应的pom,并配置对应的redis哨兵信息。
搭建成功后,就来通过代码演示主节点宕机的情况下,哨兵是否会帮助系统自动进行主备切换。在springboot项目中引入对应的pom,并配置对应的redis哨兵信息。
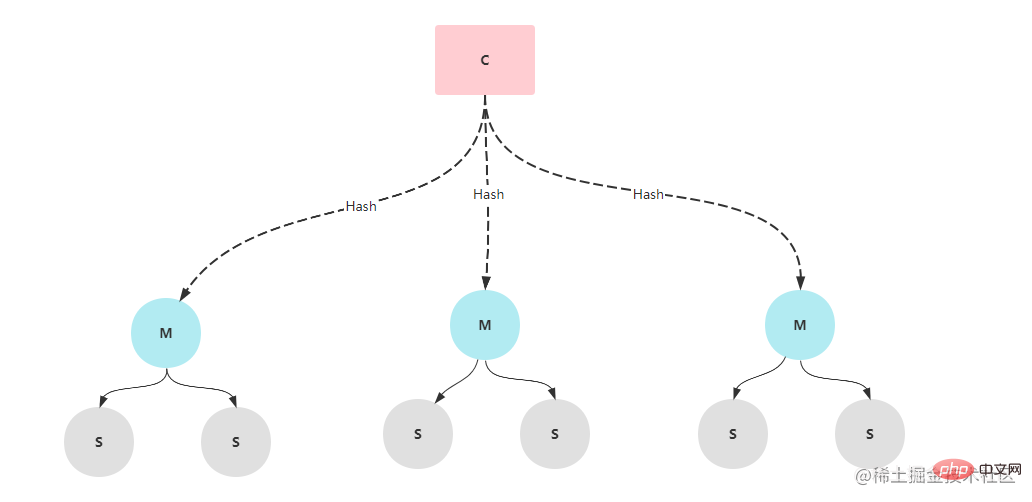
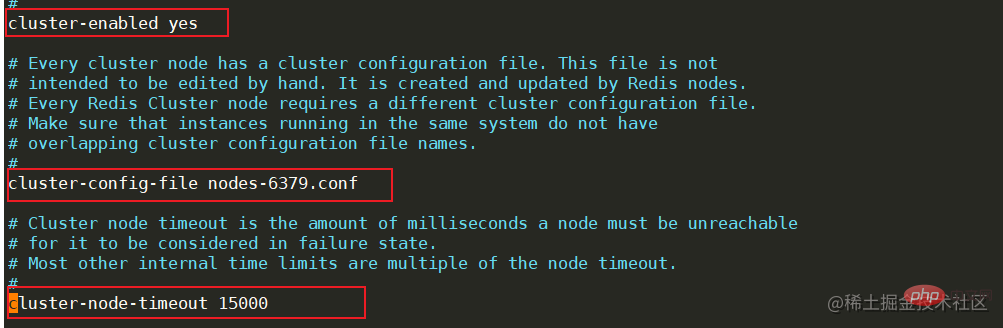




以上がRedis 高可用性アーキテクチャの構築から原理分析までの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7514
7514
 15
1378
52
79
11
19
64
15
1378
52
79
11
19
64

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
単一のスレッドレディスの使用方法
Apr 10, 2025 pm 07:12 PM
Redisは、単一のスレッドアーキテクチャを使用して、高性能、シンプルさ、一貫性を提供します。 I/Oマルチプレックス、イベントループ、ノンブロッキングI/O、共有メモリを使用して同時性を向上させますが、並行性の制限、単一の障害、および書き込み集約型のワークロードには適していません。
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示する方法
Apr 10, 2025 pm 07:15 PM
Redisのすべてのキーを表示するには、3つの方法があります。キーコマンドを使用して、指定されたパターンに一致するすべてのキーを返します。スキャンコマンドを使用してキーを繰り返し、キーのセットを返します。情報コマンドを使用して、キーの総数を取得します。
 Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisサーバーを起動する手順には、以下が含まれます。オペレーティングシステムに従ってRedisをインストールします。 Redis-Server(Linux/Macos)またはRedis-Server.exe(Windows)を介してRedisサービスを開始します。 Redis-Cli ping(Linux/macos)またはRedis-Cli.exePing(Windows)コマンドを使用して、サービスステータスを確認します。 Redis-Cli、Python、node.jsなどのRedisクライアントを使用して、サーバーにアクセスします。
